
C++ — это язык программирования, основы которого были заложены более 40 лет назад, но который по-прежнему повсеместен. В этой статье мы с вами разберемся, где и почему он используется, и порассуждаем, есть ли у него будущее.
Где сегодня используется C++?
С++ повсюду. Код, написанный на C++, можно найти в вашем телефоне, в вашей стиральной машине, в вашем автомобиле, в самолетах, в банках и вообще везде, где только можно представить.
Но давайте будем более конкретными. Многие приложения для работы с изображениями, такие как Adobe Photoshop или Illustrator, написаны на C++. 3D-игры также часто пишут на C++. Программное обеспечение для 3D-анимации, моделирования и рендеринга также в основном написано на C++. Манипуляции с изображениями — довольно сложная и ресурсоемкая область, требующая скорости и близости к аппаратной части C++.
Но работа с изображениями — далеко не единственная область, в которой доминирует C++. С большой долей вероятности браузер, который вы используете для чтения этой статьи, также был написан на C++, как, например, Chrome и Firefox.
Если мы спустимся еще ниже и посмотрим на компиляторы и операционные системы, то многие из них написаны на C++. Если нет, то, скорее всего, это C.
Но это все пока только примеры в пределах десктопного мира.
В мире корпоративного программного обеспечения вы, конечно, найдете и другие языки, но там, где критична производительность, вполне обоснованно выбирают C и C++.
В мире встраиваемых систем, где и память, и ЦП более ограничены, чем у десктопных компьютеров, C++ процветает. Независимо от того, смотрите ли вы на свои умные часы, телефон, включаете ли вы стиральную машину, садитесь ли в автомобиль и включаете зажигание, вам следовало бы испытывать немного благодарности в отношении неизвестного C++ разработчика, который сумел не испортить все из-за ошибки сегментации сразу после запуска.
Почему С++ используется до сих пор?
Итак, мы увидели, что C++ по-прежнему используется почти везде. Но почему? Можно встретить очень много скептиков, которые считают, что это чистой воды легаси и его следует удалять из кодовой базы большинства современных компаний.
Так все-таки это легаси?
Некоторые люди утверждают, что C++ все еще используется только потому, что это технология, унаследованная от старых приложений. Под “старым” я часто подразумеваю программное обеспечение десятилетней давности.
Это правда только отчасти.
Давайте порассуждаем о Cobol-ковбоях. Мало кто хорошо владеет Cobol, поэтому, если на него есть спрос, то они могут заработать кучу денег.
А спрос есть!
Cobol по-прежнему широко используется в финансовой индустрии. Эти системы были написаны много десятилетий назад и до сих пор работают довольно хорошо. Может быть, они не соответствуют всем современным требованиям, но они устойчивы, надежны и настолько сложны, что никто не осмеливается их переписывать.
C++ не так уж плох, он не так стар, как Cobol, и все больше людей изучают его и знают, более или менее, как его использовать.
Но иногда он используется только потому, что компания уже очень много в него инвестировала. У нее вокруг C++ уже развились целые экосистемы. Мигрировать их было бы слишком дорого. Даже руководители, которые по каким-либо причинам не в восторге от C++, сочтут такую миграцию экономически бессмысленной.
Но является ли C++ таким уж прям легаси?
C++ эволюционирует
Вовсе нет! C++ развивается совершенно предсказуемым образом. Как я подробно объяснял в одной из своих предыдущих статей, с 2011 года C++ следует модели подобной отправлению поездов. Каждые три года выпускается новая версия с новыми языковыми фичами и библиотеками, а также с исправлениями ошибок и доработками более ранних фич.
Четкий график релизов и стандартизированная работа гарантируют, что новые версии являются результатом продуманных дополнений, а не разовых решений. У разработчиков компиляторов есть время, чтобы реализовать их должным образом, а у сообщества - чтобы адаптироваться.
В то же время одной из суперсил C++ является обратная совместимость. Код, скомпилированный вчера, скорее всего, скомпилируется и завтра. Даже больше - код, который можно было скомпилировать в 1985 году, скорее всего, можно будет скомпилировать и в 2025 году.
Эволюция C++ была направлена на то, чтобы минимизировать головную боль разработчиков и сделать написание более безопасного кода проще.
Одной из важнейших особенностей C++ является предсказуемое управление памятью. Тут нет сборки мусора, которая в конечном итоге происходит (или нет). Когда и как память будет освобождена и возвращена операционной системе - абсолютно детерминировано. Хотя все всегда было абсолютно детерминировано, было также довольно легко выстрелить себе в ногу и испортить все, не высвобождая память или наоборот пытаясь высвободить ее дважды или даже больше раз...
Современный C++ предоставляет интеллектуальные указатели, которые сделали динамическое управление памятью менее подверженным ошибкам за счет добавления указателей, которые могут “убирать за собой”.
Еще одним поводом для головной боли у многих разработчиков выступают шаблоны. SFINAE, невероятно длинные и трудные для чтения сообщения об ошибках, перестают быть такой большой проблемой с введением концептов в C++20, которые помогают нам ограничивать типы, принимаемые шаблонами, и предоставлять релевантные и относительно легко читаемые сообщения об ошибках, если что-то все-таки идет не так.
В последние годы была проделана большая работа по внедрению библиотеки <ranges>, с помощью которой мы можем переписать иначе очень процедурные циклы в функциональном стиле.
Экономическое преимущество
C++ близок к аппаратному обеспечению, может легко манипулировать ресурсами, поддерживает процедурное программирование для функций, интенсивно использующих ЦП, и является очень быстрым. Он также также отлично справляется со сложностями 3D-игр и позволяет создавать многослойные сетевые конфигурации. Все эти преимущества делают его главным выбором для разработки игровых систем, а также инструментария для разработки игр.
Если вы используете так называемый “современный” язык, такой как Python или Javascript, зачастую вам придется прибегать к написанию некоторых важных функций или библиотек на C или C++, просто чтобы сделать их скорость приемлемой.
Существует очень мало языков, которые могут конкурировать с C++ по скорости, и один из них это - C.
Но скорость — это еще не все.
Вы можете сказать, что вы не так сильно заботитесь о скорости. Вам нужно обрабатывать относительно небольшое количество транзакций, и у вас нет серьезных требований к скорости. Вы предпочитаете код, который легче в написании.
Вас можно понять.
Как мы уже говорили ранее, C++ становится все проще в разработке. Конечно, легкость написания современного C++ не идет ни в какое сравнение с Python, но все не так однозначно.
Некоторые современные языки ориентированы на простоту написания кода, другие — на большие функциональные возможности.
Когда вы выбираете автомобиль, вы думаете не только о комфорте или скорости, хотя они могут быть очень важны. Скорее всего вам также придется учитывать расход топлива. Делаем ли мы то же самое, когда разрабатываем приложения? Думаем ли мы о том, сколько энергии они будут потреблять? В этом смысле трио C/C++/Rust работает намного лучше, чем все остальные языки. По сути, они находятся совершенно на другом уровне.
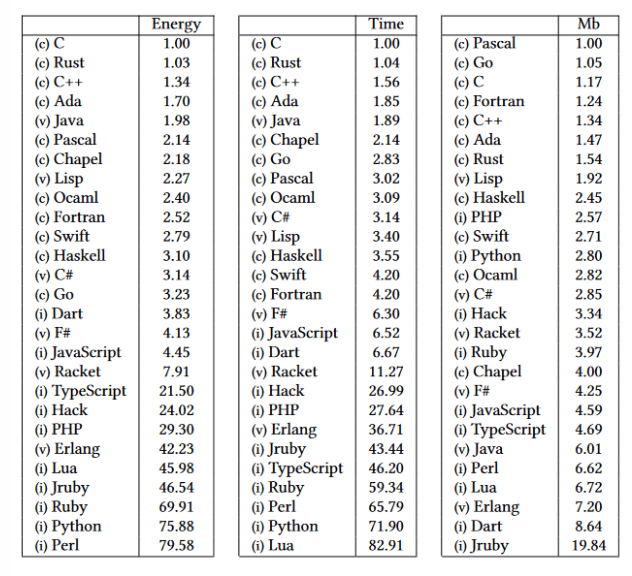
Приведенные выше цифры впечатляют.
Теперь давайте посмотрим на слайд, который был представлен на CPPP Дэмиеном Булом (Damien Buhl).

Используя C++, мы можем значительно сократить выбросы CO2. Удивительно, не правда ли?
Получается, что по большей части, даже если ваши требования к производительности не являются определяющим фактором, энергопотребление и защита окружающей среды все-таки подталкивают вас к использованию C++.
Каковы его недостатки?
Если C++ так развивается и становится проще в работе, и, кроме того, если он даже позитивно сказывается на счетах за электроэнергию и, следовательно, на нашей родной планете, то в чем проблема? Почему многие люди так не хотят с ним связываться?
Давайте обсудим пару моментов.
Плохая реклама
Нужно признать, что C++ имеет плохую репутацию.
Если вы читали Coders At Work, то могли отметить, что многие писали о том, что C и C++ слишком сложны в использовании, и вообще существует всего несколько причин чтобы их использовать в принципе. С C очень легко выстрелить себе в ногу, с C++ это немного сложнее, но когда это происходит, вы можете отстрелить себе ногу целиком.
Не очень обнадеживающие заявления, правда?
Эти комментарии определенно были небезосновательны, но их актуальность постепенно угасает.
Язык развивается, но старые книги и интервью никуда не денутся. Очень сложно изменить общественное мнение, особенно среди тех, кто больше не пишет код. Как, например, большинство нынешних руководителей.
По мере того, как язык развивается, его становится все труднее изучать
Как я уже несколько раз говорил ранее, C++ развивается. Он получает все больше и больше фич, и на нем становится все проще писать выразительный код.
То, что раньше было стандартным циклом, сегодня можно записать таким вот функциональным образом:
const std::vector<int> numbers = {1, 2, 3, 4, 5};
// вместо
auto count = 0;
for (const auto& n : numbers) {
if ( n % 2 == 0) {
++count;
}
}
// теперь мы можем написать
auto isEven = [](auto number) { return number % 2 == 0; };
auto count = std::ranges::count_if(numbers, isEven);Хотя это все очень модно и прекрасно, это также означает, что те, кто хочет писать лучший код на C++, должны больше учиться. Многие считают, что самая большая суперсила C++ заключается в том, что он почти полностью обратно совместим. Такая важная фича, что Мэтт Годболт (Matt Godbolt) посвятил ей почти весь свой главный доклад на CPPP 2021!
Также правда, что некоторые старые лучшие практики со временем стали антипаттернами. Но они по-прежнему компилируются, их синтаксис по-прежнему валиден, и обычно это базовый синтаксис, поэтому мы изучаем их. Возможно, вам больше не нужно заниматься арифметикой указателей, по крайней мере, не в такой степени, как раньше, но вам все равно нужно в этом разбираться. То же самое касается ручного управления памятью, C-массивов и так далее.
Я лично думаю, что такие темы больше не должны преподаваться настолько глубоко, но, как я могу наблюдать, в большинстве университетов преподают устаревший C++, и людям приходится заново изучать современный C++, когда они начинают работать в реальных компаниях. Если конечно компания использует более современную версию...
Интеллектуальная небрежность
Как поделился со мной в Твиттере Марек Краевски (Marek Krajewski), некоторые люди просто не стали бы использовать C++ из-за интеллектуальной инертности. Да, его сложнее изучать, чем Python или Javascript. Да, вы можете создавать отличные вещи с более простыми в освоении альтернативами. И на самом деле вам не всегда нужны возможности C++. Это все правда.
Вы должны использовать самый подходящий инструмент для конкретной работы.
Проблема в том, что многим просто лень изучать эти инструменты или даже признать, что иногда это правильные инструменты. Это происходит часто из-за фанатизма, из-за ограниченности и, в основном, из-за интеллектуальной небрежности.
Наша работа — показать и объяснить, когда C++ (или Rust...) — излишен, а когда — правильное решение. Что еще более важно, мы должны показать, что это уже не тот язык, которым он когда-то был.
Экосистема
В своем докладе на C++ MythBusters Виктор Чиура (Victor Ciura) развеял миф о том, что у C++ не все так гладко с вспомогательными инструментами. Они есть, и их в нашем распоряжении достаточно много. Но Виктор считает, что у нас никогда не будет “стандартизированных” инструментов, нам всегда нужно искать подходящий инструмент, разбираться, как он работает, и только потом использовать его.
Хоть я и разделяю его точку зрения, мы должны признать, что в других языках есть более простые решения простых проблем. Если вы работаете с Python, вы точно знаете, как и откуда вы должны получать свои пакеты. Похожая ситуация и с Java, не говоря уже о Javascript. Эти языки не стандартизированы, но в них есть стандартные способы простой доставки и использования библиотек, совместного использования и создания кода, которые не требует много времени и сил на то, чтобы разобраться с ними.
C++ этим похвастаться не может.
Написание мейкфайлов - не самая простая задача. Многие де-факто принимают CMake за стандарт для написания скриптов сборки, но это явно не так. Многим он не нравится из-за его синтаксиса, и существует множество других способов создания скриптов сборки. У многих компаний даже есть собственные системы, в том числе у Amadeus.
А как насчет управления пакетами?
Ну, есть Conan, vcpkg, но а ни не такие развитые, как yarn, npm, PyPI или maven.
C++ в этом плане еще есть куда расти.
Так что на счет будущего C++?
Я опросил некоторых выдающихся представителей сообщества C++, и вот что они сказали:
C++ сегодня как никогда верен своей первоначальной миссии по предоставлению абстракций с нулевой стоимостью над низкоуровневым системным кодом, где это возможно, и недорогих абстракций, за которые вы платите только тогда, когда используете, когда первое невозможно. И мы получаем это вместе с совместимостью с C и более ранними версиями C++, несмотря на то, что язык постоянно развивается и внедряет современные языковые фичи. — Фил Нэш (Phil Nash), автор Catch2, главный организатор C++ On Sea
C++ — это и наше наследие, и наше будущее. Несмотря на все его недостатки и исторические проблемы, он имеет множество современных фич, многие из которых специально разработаны для смягчения/замены старых идиом/конструкций. В настоящее время C++ программисты могут легко писать программы, полностью избегая таких опасных старых вещей. [...] STL C++ значительно выросла благодаря стандартам ISO 11,14,17,20, а C++23 принесет еще ряд очень ценных дополнений. От новых алгоритмов и диапазонов (ranges) до различных утилит и вспомогательных библиотек для IO, сетей, корутин, параллелизма, гетерогенного параллелизма и многого другого. Да, есть более специализированные вещи, которые могут понадобиться программисту, но здесь приходит на помощь экосистема C++, которая заполняет пробелы множеством стабильных библиотек коммерческого качества практически под каждую потребность. Каждая ключевая часть программного обеспечения, которое мы используем сегодня, содержит в себе C++: может быть, это целиком C++, может быть, там там только некоторые важные компоненты написаны на C++, может быть, его библиотека изначально скомпилирована на C++, может быть, его компилятор/среда выполнения написаны на C++, ...
C++ по-прежнему остается королем языков программирования. Да здравствует король! — Виктор Сиура, старший инженер-программист команды Visual C++ в Microsoft
C++, широко используется в разработке игр, в частности, игр для консолей и ПК. Он обеспечивает прямой доступ к аппаратному обеспечению через абстракции с нулевой стоимостью. Мощь и гибкость, которые он предоставляет, делают его трудным для изучения, потому что в вашем распоряжении оказывается огромное количество возможных решений широчайшего спектра задач. Глядя на международный стандарт с обязательством обратной совместимости, вы уверены, что не будет ситуации Python2/Python3. Будущее выглядит радужным, параллелизм и работа в сети выглядят очень многообещающими в C++26, не говоря уже о множестве фич, предназначенных для рационализации и упрощения языка. — Джей. Гай Дэвидсон (J. Guy Davidson), руководитель инженерной практики Creative Assembly, соавтор книги Beautiful C++, член с правом голоса комитета ISO C++
Заключение
C++ мог бы считаться устаревшим в глазах тех, кто был знаком только со старыми шаблонами, со старыми стандартами, но язык постоянно развивается. С 2011 года, начиная с C+11, каждые 3 года мы получаем новую версию с исправлениями ошибок и новыми фичами. Экосистема растет, хотя она далеко не так проста, как у некоторых других новых языков, где, например, управление пакетами везде выполняется очень похожим образом.
Тем не менее, язык и экосистема растут, сообщество очень большое, а C++ неизбежно повсеместен. Так или иначе, его хотя бы частично можно найти почти в каждом написанном на сегодня программного обеспечения. Я не говорю, что C++ — это молоток, который должен превратить все вокруг вас в гвозди, но его все же стоит изучить и освоить. Даже в 2022 году и далее.
Мир фракталов породил много интересных изображений, которые описываются простыми математическими формулами. Для построения этих изображений нам потребуется язык программирования и в рамках открытого урока мы рассмотрим, как можно написать программу для генерации фракталов на C++. Приглашаем всех желающих присоединиться.
Комментарии (220)

Starl1ght
24.11.2022 15:27+1При всем уважении к C++ и моему опыту на нем - не надо писать на нем вообще ничего сейчас, кроме очень-очень редких вещей, типа виндовых кернел драйверов (никсовые на расте уже можно).
Отсутствие кучи всего из коробки, боль с депендами даже при использовании депенденс менеджера, сложность отладки, УБ, зоопарк из систем сборки, где нормальная ровно одна (нет, не CMake) и прочее - вы поняли.
LuggerFormas
24.11.2022 15:51+28Если писать только для десктопа последних поколений перекладывание джсонов и подобное - может быть и согласен, но C/C++:
универсален, кроссплатформ (да, #ifndef, и что? Kotlin, where are you?)
есть ВСЕ, не из коробки, да, но есть
управление памятью, быстродействие, опыт и понимание механизмов выгодно отличают от новомодных детищ, которые часто сами в себе не разобрались
работало в 2000-м - заработает и сейчас (см.: питон2, питон3)
не зоопарк, а ассортимент, отладка бывает сложна только в связке с каким-нибудь Fortran, но где еще так быстр __matmul?
-
дружит со всеми БД, интегрируется со всем подряд
Но если мы пойдем чуть подальше в эмбед:
запускается на любом утюге
тулчейны на ВСЕ,
автоген доков (вообще найс)
-
миддлов есть много, поддержка недорога
Чем cmake не угодил?
прост как три копейки без всяких JIT, easy to start, hard to master
вечно молод, не надо каждые лет 5 смотреть на очередной Ruby on Crooked Rails
Starl1ght
24.11.2022 15:59+19Вместо срача - просто рекомендую попробовать современный C#. Вот уж где реально универсален, кроссплатформен, есть ВСЕ, быстрый, депенденс менеджер нормальный и встроенный. одна система сборки человеческая, работающая везде.
Вот таким должен быть язык, а не ифдефы, симейк, управление памятью и прочие ужасы.
tenzink
24.11.2022 16:50+17Если говорить про "лучший" C++, то это будет не C#, а Rust. Там по-человечески сделана система управления ресурсами/lifetimes - исправлено то, за что справедливо критикуют C++ в области работы с памятью. При этом отсутствуют ужасы null-values и есть явное разделение ссылочной и by-value семантики

vanxant
24.11.2022 17:42+12Если бы ещё синтаксис расту разрабатывали без цели увеличения дохода офтальмологов...

0xd34df00d
24.11.2022 22:21+15template<typename Не, typename = в:: плюсах>
auto на(это) -> decltype([]() { жаловаться })

unC0Rr
24.11.2022 22:32-4В нынешнее время с обилием тулинга не составит труда написать переводчик синтаксиса во что душе угодно и обратно.

singalen
25.11.2022 00:23+9Написав на Rust относительно немного кода, после лет в С++, не вижу проблем в его синтаксисе вообще, особенно по сравнению с С++.
Разве что то, что он пошёл не только от С, как в PHP или Javascript.
Другими словами, да, программист на С++ может выучить PHP за выходные, а Rust не может. Но это не проблема Rust, а следствие из более продвинутых фич, которых в С++ не существует: expression syntax, rich enums, borrow checker, и что там ещё.

AnthonyMikh
26.11.2022 07:57+3Каждый раз, когда кто-то в очередной раз ругает синтаксис Rust, я предлагаю указать, что именно с синтаксисом не так. Где-то 90% отваливаются на этом вопросе, а те, что таки отвечают по существу, в итоге предлагают что-то значительно хуже.
vanxant
26.11.2022 14:10+2Ну вот берём прям первое, что видит программист, заинтересовавшийся растом:
println!("Hello World!");Почему посреди фразы здесь знак "!"? Как мне прочитать это вслух? Люди привыкли к синтаксису английского языка, практически все языки программирования пытаются так или иначе к нему приблизиться.
Ок, берём задачку чуть сложнее: посчитать количество символов "_" и "-" в строке.
Код из cargo, каноничнее некуда:
impl<'s> UncanonicalizedIter<'s> { fn new(input: &'s str) -> Self { let n = input.chars().filter(|&c| c == '_' || c == '-').count() as u32;Что означает весь этот мусор? <'s>, |&c| c - зачем всё это? Как это прочитать вслух?
Я понимаю, что можно быстро привыкнуть и всё такое... но вот у многих это нелюбовь с первого взгляда. Не прёт язык и всё тут.

Mingun
26.11.2022 16:14+5Т.е. это вслух читается на ура? А знаки "меньше" странно сгруппированные по двое ну вот совсем никого не смущают.
std::cout << "Hello world!" << std::endl;std::map,std::string,std::vector,std::cout,std::endl,…
Ужас. Зачем тут постоянно повторяетсяstd::, зачем этот мусор?vanxant
26.11.2022 18:24+2Потому что руко**опы из комитета не смогли сделать нормальный using namespace. Теперь везде этот std::мусор.
Впрочем, если вы точно знаете что делаете, вы всё ещё можете написать
using namespace std;, и тогда всё будет вполне понятно и красиво:cout << "Hello, world!" << endl;
DistortNeo
26.11.2022 18:37Потому что руко**опы из комитета не смогли сделать нормальный using namespace.
Да потому что невозможно похоронить тянущееся с 60-х годов прошлого века наследие в виде include-файлов и препроцессора.
Впрочем, если вы точно знаете что делаете, вы всё ещё можете написать using namespace std;
Как альтернативу, комитет предложил модули, где каждый файл — отдельный translation unit, и где вы вполне можете делать подобные вещи.
vanxant
27.11.2022 13:54И что мешало в том девяносто лохматом году, когда вводили
namespace, объявить, что теперь каждый неймспейс компилится как независимая либа и подключается как либа? Тулинг это поддерживал и тогда, просто это требовало дополнительных приседаний по настройке сборки, а программистам, как обычно, лень.
DistortNeo
26.11.2022 18:28+2Времена, когда язык программирования выглядел как текст на английском (COBOL), уже давно прошли. Это слишком многословно и все равно вынуждает учить синтаксис язык программирования.
Ваша претензия заключается только в том, что вы привыкли к C-подобному синтаксису, характерному для большинства мейнстримных языков, и просто отказываетесь принимать всё остальное.
AnthonyMikh
26.11.2022 19:55+3А зачем это читать вслух?
vanxant
27.11.2022 13:34Ну, знаете, некоторые люди иногда общаются. Голосом:)
А ещё, некоторые человеки, наткнувшись на непонятное место в тексте, непроизвольно начинают проговаривать прочитанное вслух (хоть и про себя).

DarkEld3r
27.11.2022 00:39+2Почему посреди фразы здесь знак "!"?
То, что это макрос объясняется в первой же главе книги по языку. Ну да, с какой-то теорией придётся ознакомится, иначе, в зависимости от предыдущего опыта, можно очень до многого докопаться. Например, зачем в С++ нужно
->? Вон в С# всё через точку. Если что, не надо мне объяснять, а на С++ много писал, это просто пример.Ок, берём задачку чуть сложнее: посчитать количество символов "_" и "-" в строке.
К "задаче" относится только часть приведённого фрагмента кода, поэтому можно упростить до
input.chars().filter(|&c| c == '_' || c == '-').count(). Ну или, по крайней мере, до вот такой функции:fn num_chars(input: &str) -> usize { input.chars().filter(|&c| c == '_' || c == '-').count() }Не всё так страшно, не правда ли? Кажется, остаётся только претензия к
|&c|. Если амперсанд забыть, то компилятор точно скажет, что не так, ну а различать значения и ссылка вполне нормально для системного языка. Ну и наконец синтаксис лямбд в С++ тоже достаточно страшный/перегруженный и ничего.vanxant
27.11.2022 13:49Да всё понятно. Меня просили объяснить, что не так с синтаксисом раста - я объясняю. Когда первый раз открываешь код на расте, возникает ощущение, что у кого-то по клавиатуре прошёл кот и нажал рандомные кнопки, включая хоткеи с автокомплитом.

Kelbon
24.11.2022 19:13-9судя по "null-values" вы совершенно не знаете ни раст, ни С++.
Раст это язык, который дизайнили для отсутствия сегфолтов(спойлер - не вышло, см. unsafe который ВЕЗДЕ).
С++ дизайнили для качества получаемого кода: инкапсуляции сложности в больших системах, масштабирования.
Что уж говорить, если весь синтаксис раста заточен чтобы его легче было парсить(КОМПИЛЯТОРУ!), а не человеку(а нейминг просто -10 из 10)
ijsgaus
24.11.2022 20:30+8Вот вы похоже Rust не знаете. Там unsafe не такой как C++ - то есть совсем. И дает кучу гарантий. А с синтаксисом. Просто он не сишный в своей основе - а парсить современные плюсы человеку вообще невозможно - одни темплейты вышибают напрочь на часы.
Kelbon
24.11.2022 20:43У меня отлично получается парсить шаблоны, никаких проблем.
А unsafe в расте, да, даёт кучу гарантий. Неявных гарантий которые вы обязаны соблюдать, иначе УБ.
Требований к unsafe коду в расте БОЛЬШЕ чем к коду С++ и требования не такие очевидные, как не обращаться к невыделенной памяти. Например создание ещё одной ссылки на то на что уже есть ссылка это уже убP.S. то что вам сложно парсить в С++ просто невыразимо в расте, т.к. там нет многих возможностей шаблонов и совсем нет вариадиков.
Смешно, в языке где в синтаксисе есть туплы количество типов в тупле ограничено!
P.P.S. если вы попробуете распарсить растовый макрос, то окажется что он значительно сложнее любого шаблона. Имеет синтаксис который вовсе зависит от левой пятки программиста его писавшего.(а макросы там буквально ВЕЗДЕ, например нет способа создать вектор без макроса)DarkEld3r
24.11.2022 21:06например нет способа создать вектор без макроса
Создал:
Vec::new(). Сейчас будет уточнение, что надо создать вектор с элементами?.. Ну ладно:Vec::from([1, 2, 3]).Kelbon
24.11.2022 21:24+1Вау, только вот это пожалуй самые непопулярные конструкторы вектора.
Там штук 10 макросов для его создания и среди них нет возможности создать с кастомным аллокатором, собственно поддержка аллокаторов в расте это плевок какой-то, она лишь на бумагеDarkEld3r
25.11.2022 00:35+2Вау, только вот это пожалуй самые непопулярные конструкторы вектора.
Утверждалось, что вообще без макросов создать нельзя, оказалось, что можно. Теперь давай про десять макросов уточним. Так-то он всего один.
Kelbon
24.11.2022 21:28+2К слову, о читаемости раст макросов:


freecoder_xx
24.11.2022 22:11+3Вообще язык декларативных макросов в Rust очень простой. Но от символов в глазах рябит, это правда. Сделано как проще, чтобы меньше было пересечений в обозначениях макрокоманд с остальным кодом на Rust, так как они смешиваются в макросе.

Arenoros
27.11.2022 07:28+2Да в чем проблема символов? Тут все так пишут словно это уже устоявшийся факт что много разных символов это плохо. Я наоборот терпеть не могу языки типа lua потому что их сложнее парсить визуально большими кусками, так как все сливается в одно оргомное сочинение. И тот же знак '!', для макросов был бы отличной штукой в C++ по которому даже без подсветки было бы легко понять что это за конструкция.
singalen
25.11.2022 00:34+3У меня отлично получается парсить
шаблонымакросы, никаких проблем. (спасибо за аргумент)Даже со старта с этим не было проблем. Если быть немного знакомым с синтаксисом старых скриптовых языков, шелла, например, где переменные и выражения берутся в
${}и$(), то вообще читается без запинки.Kelbon
25.11.2022 09:41у шаблонов такой же синтаксис как у обычного кода, у макросов - нет
читается без запинки.
в этом чтении нет никакой информации о том какой тип ожидается, тогда как в аналогичном конструкторе std::vector из С++ чётко написано, что это size_type или что-то такое
singalen
25.11.2022 10:53+2у шаблонов такой же синтаксис как у обычного кода, у макросов - нет
Пусть бросит камень тот, кто совсем-совсем не использует препроцессор. Ни в новом коде, ни в том, который просто приходится читать.
в этом чтении нет никакой информации о том какой тип ожидается, тогда как в аналогичном конструкторе std::vector из С++ чётко написано, что это size_type или что-то такое
Ну, я бы не сказал, что вот это: https://doc.rust-lang.org/src/alloc/macros.rs.html#63 намного хуже, чем вот это: https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/stl_vector.h#L84. Да, я помню, кастомные аллокаторы.
И да, макросы могут не давать возможности сразу прочитать типы в сигнатуре. По этому критерию, специально сконструированному так, чтобы отсечь Rust, признаю, Rust проиграет. Хотя лисперы ещё поспорят.
Правда, выиграет сразу на следующем шаге, при проверке типов при компиляции, и диагностике. Мой С++ заржавел, я ещё помню сотни строк ошибок в загадочных местах при простой опечатке в тексте - этого в современном С++ уже совсем-совсем нет?
Kelbon
25.11.2022 10:58-1Препроцессор С ничего общего с синтаксическими макросами раста не имеет. И присутствует он там т.к. это библиотека сразу на все версии С++ начиная с незапамятных времён(а нейминг переменных специально таков, чтобы не пересекаться с именами из кода пользователей, что кстати уже не нужно начиная с С++20 модулей)
В остальном там обыкновенный код с таким же синтаксисом как в любой другой части С++.Чтобы писать на С++ необязательно использовать макросы, в расте без них и строки написать невозможно.
А какие ошибки будут при опечатке в макросе - ну посмотрите, проверьте.

mayorovp
25.11.2022 11:10+2Ну вот я посмотрел, проверил: https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=93eff61c9e43b0c207a7cf05c825ee27
Вроде ничего сложного в этих ошибках.
singalen
25.11.2022 11:00+1Хотя, честности ради: процедурные макросы я ещё не осилил, и да, они гораздо сложнее, и завязаны на API AST. Впрочем, я слышал, что старые лисперы ими крайне довольны.
Kelbon
25.11.2022 11:03лисп из-за этого и загнулся, никто не хочет чтобы в каждой библиотеке и проекте был свой язык, что собственно и происходит если есть синтаксические макросы
tenzink
25.11.2022 14:31+1судя по "null-values" вы совершенно не знаете ни раст, ни С++.
Ярлыки навешивать вы умеете. А по существу скажете какие есть ужасы null-values в rust/С++? Система типов там достаточно мощная, чтобы явно выразить, что значение может или не может отсутствовать
LuggerFormas
24.11.2022 17:20-13Оу май. Это какой с#? Который тащит .NET весом 4,5Г в инсталлере? UWP или WPF? Mono? Я там был, так они в 5 или 6 емнип указатели вернули как желаемые, хотя вроде весь шарп делался чтоб от этого сбежать, лул
Только на десктоп как UI вида 90-х, проблемы с чертовым nuget (из чего там наггетсы - да из того что в маке, ага)
JIT, ГАДСТВО, С%*?:, JIT!
С железом вообще лютый облом, за обновами того же Postgre не успеваем, фронт (если это можно так назвать) каждые пару лет новый. Да и не на виндах это тот еще гемор (я не пробовал, тут уж чисто по слухам)
Where is my c# openBLAS?
Сразу про читаемость и переносимость и поддержку комментатору внизу напинаю:
вон питон читаемый ага, для тех кто под капот не глядел. в поддержке очень дешев (лул) - бери кластер там, где на С хватило бы малинки
@Einherjar - что в питоне делает оператор @? Если на крестах не заморачиваться чрезмерной оптимизацией через интринсики (что делают только гики, если дело не касается векторных инструкций, но и там есть либы) - читается влет, STL во все поля. Да я даже буст не юзаю - нет надобности. Читается хорошо если дробить на мелкие хорошо названные методы и не оверинжинирить. Но тут конечно да - не для новисов, можно ногу того этого.
Добавлю: взгляни на JS+REDUX+TS - вот там очень читаемо, война и мир

F0iL
24.11.2022 19:48+5Который тащит .NET весом 4,5Г в инсталлере
JIT, ГАДСТВО, С%*?:, JIT!
Вылезайте из криокамеры, для C# есть AOT-компилятор, и установленного рантайма не требуется.
Только на десктоп как UI вида 90-х
Вас кто-то насильно заставляет писать на WinForms, а не на чем-то более современном?
так они в 5 или 6 емнип указатели вернули как желаемые
щито?

yatanai
27.11.2022 06:20Там сейчас для новых фреймворков UI, от микрософта, прикрутили фичи в виде прекомпиленных точек входа, от чего лаг при входе в приложение должен пропадать. Вот настолько там в курсе таких проблем.
(За JIT/AOT)
Kelbon
24.11.2022 19:06В современном мире предлагать вендорлокнутый язык, который уж точно проигрывает плюсам в скорости...

alexdesyatnik
24.11.2022 20:54+5Он уже давно opensource. Вендор лок там разве что в том, что лучшая среда разработки проприетарная и под винду. Разница в скорости же там не такая существенная по сравнению с разницей в скорости разработки, удобстве инструментов и надёжности кода.

sav13
25.11.2022 05:46-2Это только для прикладных программистов есть выбор между C/C++ и C#
Для системных программистов, разработчиков встраиваемых систем собственно и выбора никакого нет.
С# никогда не сравнится по производительности с нативным компилятором.
https://habr.com/ru/post/266163/
Да и по переносимости/тиражируемости кода тоже.
Einherjar
25.11.2022 13:06+6Ссылке 7 лет. Вы бы еще .net 1.0 откопали.
Конечно задачи где разница в производительности очевидна найти можно, но таких довольно мало.
По переносимости как раз ровно наоборот, c++ требуется компилировать под каждую платформу с кучей #ifdef, имея на выходе 100500 разных бинарников зачастую с зависимостями от разных библиотек. Причем с кросс-компиляцией все очень плохо - собрать на винде приложение например под мак в большинстве случаев ни разу не получится и наоборот. Тогда как должным образом написанное .net приложение просто запускается на любой операционке как есть.

v4e
25.11.2022 11:15-4Как можно сравнивать C++ и C#? Совершенно разные задачи решают. С# забудут, C/C++ останется, потому что всё также надо будет писать компиляторы, игровые движки, игрушки консолей - с выдавливанием всех возможностей железа, драйвера, прошивки контроллеров и встраиваемых устройств, встраиваемые модулии в критические места приложений на других, более высокоуровневых языках (тот же C#). Например в тот же фронтенд: https://developer.mozilla.org/ru/docs/WebAssembly/C_to_wasm
Можете возразить, что игры и на C# пишут, на Unity, к которому куча модулей на C#. Ок, но runtime Unity опять же C++.DistortNeo
25.11.2022 19:42Можете возразить, что игры и на C# пишут, на Unity, к которому куча модулей на C#. Ок, но runtime Unity опять же C++.
Рантайм C# тоже на C/C++ написан. Не вижу здесь никаких проблем.
Совершенно разные задачи решают.
Вот именно. Просто надо понимать, что нет языка, который был бы хорош абсолютно везде. Поэтому хорошим решением в больших проектах будет не жрать кактус и не писать всё на C++, равно как и не писать всё на C#, а использовать сразу несколько языков.
0xd34df00d
25.11.2022 22:52+11C/C++ останется, потому что всё также надо будет писать компиляторы
«C/C++» для написания компиляторов — возможно, один из худших выборов из возможных.
Einherjar
24.11.2022 16:37+6Это все конечно верно, но читаемый код на С++ это довольно большая редкость, потому если только все вышеперечисленное не требуется в проекте одновременно, то если отбросить религию будет логичнее выбирать более удобные и более дешевые в поддержке варианты.

beeptec
25.11.2022 20:09Я не работаю на С++.
Меня раздирает профессиональное любопытство по части одного из моих программных продуктов, который был построен в среде, ядро которой почти на 95% в свое время было построено на С++.
Вопрос состоит в том, сколько времени ушло бы у кодера С++ на написание аналогичного продукта (настраиваемый фреймворк в абстракции графического интерфейса и инструкциями для автономного программирования и управления FSM под OS Win 10) что по сути является симулятором контроллера с расширенными функциями для работы с I/O (USB - 160/1600).
mayorovp
24.11.2022 17:45+7работало в 2000-м — заработает и сейчас
…если было написано в соответствии со стандартом. А это, скорее всего, не так.
vanxant
24.11.2022 17:49-4Не, ну если найти компилятор из 2000 года - то заработает.
Впрочем, с остальными языками та же фигня.
DistortNeo
24.11.2022 18:01+6Мало найти компилятор. Надо ещё и древние зависимости откопать, ведь компилятор 2000 года не сможет скопилировать современный код. А потом окажется, что древние зависимости работают только со старыми либами, которые уже не работают в современной операционной системе. Или или сам компилятор запустить не получится.
vanxant
24.11.2022 17:46+15дружит со всеми БД
простите, взоржал :) Возможность слинковаться с сишной либой (и потом работать в стиле С, как хочешь так и приседай) не есть "дружит". Все остальные языки, вы не поверите, тоже под капотом линкуются с сишными либами всех БД, только они ещё мапят SQL-типы данных в свои нативные.
std::variant нужно было завозить в 1990, а не в 2020
LuggerFormas
24.11.2022 18:35Поинт тэйкен конечно. Может это и не "дружит", но всегда на том же компиляторе можно залезть внутрь и поправить, когда postgre в очередной раз поменяет oid. В случае с другими лезть что-то править или не представляется возможным, или начинаются войны "пакет манагер, плиз не трожь это", либо Soon(tm). Линковаться с сишной либой не из-под с/с++ - мне лично не очень приятно. Нативные типы не такая уж проблема, хуже когда на каждый чих нужно по пакету, которые еще и могут превратиться в тыкву в обновке следующего месяца.

WondeRu
24.11.2022 18:00+4ну, нет много миддлов уже на С++. для меня всегда был затык в том, чтобы взять проект на плюсах: хрен найдешь разработчиков, причем, любого уровня.

tandzan
24.11.2022 19:51Почему-то у меня обратное впечатление. Писать на плюсах - верный путь умереть от голода.
F0iL
24.11.2022 19:57+2Если говорить про рынок труда в РФ, то проблема в том, что на C++ примерно 70% вакансий - это полукустарный embedded, заводы и всякие госухи с их legacy, и там с деньгами и условиями действительно нередко полное дно, если их избегать за километр, то остальные предложения по деньгам будут весьма неплохие, не особо меньше чем на других языках.

september669
24.11.2022 18:09+2Kotlin, where are you?
https://kotlinlang.org/docs/multiplatform-dsl-reference.html#targets
Плюс compose для мультиплатформы тоже пилится

iboltaev
24.11.2022 18:27+2по большей части плюсану)
но вот
есть ВСЕ, не из коробки, да, но есть
Это "все" часто вырвиглазно, нередко с сишным интерфейсом, в абсолютно разных coding-style'ах, без нормального репозитория, часто хочется плеваться.
универсален, кроссплатформ
Только пересобирать каждый раз надо под каждую платформу. А если платформ >2, то уже проблемы.
Дополню:
Геморой с зависимостями. Авторы либы X сломали бинарную совместимость, а рассказать об этом забыли? welcome to hell. Java аккуратненько вальнется с исключением, по которому тут же, сразу же все будет понятно, в случае плюсов получите segfault хз пойми где. Надежно выручает только докер.
Но все же, в плюсах мне всегда нравился STL, он зачастую удобнее джавовых и скаловых коллекций. Задачи на том же литкоде до сих пор на плюсах решаю. Boost, я тут недавно глянул, за 6 лет, что я на плюсах не пишу, распух раза в полтора.

freedbrt
24.11.2022 18:49+3Проблемы начинаются когда мы пытаемся на с++ работать с вебом. Где websockets, socket.io, где нормальная работа с базами, удобная работа с json ? Все это делается через ужасные либы, и жутко не удобно.
В остальным С++ хорош конечно, но только если вы держите его далеко от веба.
F0iL
24.11.2022 19:52Где websockets ... через ужасные либы, и жутко не удобно.
Популярный websocketpp действительно адски замудреный, а вот ixwebsocket имеет довольно простой и логичный API и работает без проблем (есть небольшые приколы с TLSv1.3 при использовании OpenSSL и нет поддержки проксей, но над этим работают).
0xd34df00d
24.11.2022 22:19+19да, #ifndef, и что
И компилятор даже не проверяет синтаксическую корректность кода под платформы, отличные от текущей.
есть ВСЕ, не из коробки, да, но есть
Что всё? Хочу нормальную систему типов с завтипами. Ну ладно, хотя бы с Хиндли-Милнером.
Ладно, давайте поговорим о библиотеках. Хочу парсеры на монадических комбинаторах (буст.спирит, наверное, тут ближе всего, но нельзя так жить в 2022-м, да и даже в 2012-м уже нельзя было). Хочу примитивы для dataflow analysis. Хочу монадическое вероятностное программирование. Где оно всё, желательно с той же степенью выразительности и удобством пользования?
управление памятью
Сразу после исправления всех UB.
быстродействие
Есть далеко не только у него.
опыт и понимание механизмов
Опыт в чём и понимание механизмов чего?
Опыт программиста на C++ — это опыт перепрыгивания через грабли и костыли и извлечения пуль из ног. 90% этого опыта не переносится на другие языки вообще никак. Плюсы были моим основным языком лет 15, с 12 лет, как я впервые за них взялся, и лет 10 они были моим единственным языком. Весь этот опыт по борьбе с компилятором, по штудированию стандарта на предмет UB, по дрочке вприсядку с темплейтами — это всё можно выкинуть при переходе на другие языки.
работало в 2000-м — заработает и сейчас (см.: питон2, питон3)
Во-первых, не факт что заработает даже соответствующий стандарту код.
Во-вторых, в 2000-м соответственно стандарту почти не писали, и я не встречался ни с одним проектом (от опенсорса до кровавого тырпрайза), в котором ваше утверждение бы выполнялось.Более того, в тырпрайзе на практике даже gcc 4.7 обновить на gcc 5.1 (или что там было в рхеловском DTS-2 и DTS-4 соответственно) — уже проблема на несколько лет работы выделенной команды специально обученных людей, некоторые из которых при этом заседают в Комитете.
не зоопарк, а ассортимент, отладка бывает сложна только в связке с каким-нибудь Fortran
Охохо. Отладка бывает сложна, когда перед вами приложение, начатое в тех самых 2000-х, где в одном месте возникают циклы из шаред_птров и не удаляются, а в другом месте возникают висячие ссылки, в итоге эта хрень через несколько суток работы начинает подтекать, а потом валится. Воспроизвести баг — несколько суток работы под продовой нагрузкой. Запустить под санитайзерами, валгриндом, етц — не хватает хипа и производительности. Успехов.
В итоге Настоящие Программисты просто прикручивают автоперезапуск сервиса раз в сутки, пока не сильно много утекло.

Stalkerx777
25.11.2022 10:23+1Практически всё что вы перечислили - это просто результат того что 30 лет не было достойных альтернатив, а задачи нужно было решать. Конечно за столько времени чего только не напишут.

Lebets_VI
24.11.2022 15:57+1Согласно Вашему мнению, кроме "виндовых кернел драйверов ", в нашей жизни, ничего не осталось :)
Starl1ght
24.11.2022 16:03Все остальное лучше писать на других языках, если это не махровое легаси.
Ну ок, мб эмбед, я от него далеко.
Lebets_VI
24.11.2022 16:16+1Когда-то была реклама жвачки и в ней была фраза "не айс". Она стала мемом.
Так вот, не обижайтесь, но Ваш пост звучит как "не айс" в отношении к данному языку. Т.е., по вашему, он умер, по этому некроманты (а их по другому не назвать) пытаются, что бы о них не забыли, создавать новые стандарты. Ну, ок, чё.
Что касается "Все остальное лучше писать на других языках" - мой пример (не показатель, но уверен, что я не одинок), так вот даже сейчас я использую, в том числе, и MFC о котором уже наверное никто не знает (саркакзм для серьезных ;)).
P.S. вы троллите? (глянул Ваш профиль)Starl1ght
24.11.2022 16:28+10> вы троллите? (глянул Ваш профиль)
Нет. Я правда так считаю. Медовый месяц с языком спустя несколько лет перетек во всё большее раздражение от его использования.А потом я познакомился с шарпом, и увидел, как можно писать код без запоминания кучи правил, без страданий с кросскомпиляцией, без борьбы с симейком, где из коробки (в нугете) есть вообще все, без мейнтенанса своего миррора с зависимостями, без кучи бойлерплейта (а-ля енум-ту-стринг или парсинг джсонов)
Заканчивая такими приятными мелочами, как компиляция за секунду для быстрых итераций разработки (и нативная компиляция для прода на CI в .net 7), сплит строки из коробки и прочие очень приятные мелочи, которые снова позволяют получать удовольствие от программирования.Ну и сишное OS-апи все еще дергается без проблем, чуть-чуть сложнее, чем в крестах, но это та цена, на которую я готов.
Lebets_VI
24.11.2022 17:09+1А вот я с шарпом и не подружился, хотя писал на нем лет 5. Было много споров с коллегами по поводу разницы в понимании базовых парадигм языка относительно С (++), но пишу, нет, не нравится. Это всегда так :)
Starl1ght
24.11.2022 18:21Минорный смешной референс про "троллинг" и мой профиль - я с Шандором (автором статьи) знаком, помогал ему на последнем C++ Russia в онлайне.

Racheengel
24.11.2022 16:05+9По сути, у C++ есть реально только два основных плюса: производительность скомпилированного приложения и непосредственный доступ к железу.
Мы используем С++ ровно из-за этих причин. Наши приложения должны работать в RealTime и постоянно общаться с внешними устройствами.
Системы сборки и зависимости библиотек и инклудов - это ад. Проблема с зависимостями более-менее решена в Linux, но почти никак в Windows. Из-за этого приходится в свои танцы с бубном.
Хорошо, что есть Qt на свете - по крайней мере, многие проблемы переносимости она решает (но не все).
DistortNeo
24.11.2022 17:56+5Не решена проблема с зависимостями в Linux. Точнее, она переложена на пакетный менеджер самой операционной системы. Какие-то популярные пакеты так поставить можно, но не более того.



DistortNeo
24.11.2022 17:18+1Но работа с изображениями — далеко не единственная область, в которой доминирует C++. С большой долей вероятности браузер, который вы используете для чтения этой статьи, также был написан на C++, как, например, Chrome и Firefox.
А разве Firefox не был переписан на Rust?

KanuTaH
24.11.2022 17:26+2Нет, servo так и не взлетел и остался экспериментальным движком, а затем растаманы были уволены из умирающей Mozilla в большинстве своём. Сейчас судя по истории коммитов servo пилится парой человек с большими перерывами - месяцами там вообще не бывает коммитов за исключением автокоммитов от dependabot'а.

skozharinov
24.11.2022 18:00+7Из Servo вроде как повыдёргивали компоненты, которые сейчас используются (Quantum)
KanuTaH
24.11.2022 18:18Ну да, действительно, что-то интегрировали, папочка servo появилась, но по сравнению с активностью в репозитории gecko-dev servo выглядит мертвецом. Потыкал в несколько коммитов наугад в gecko-dev - либо C++, либо js, либо служебные скрипты на питоне, активной разработки на расте не видно.
freecoder_xx
24.11.2022 22:20Мое личное мнение: Servo утонул под тяжестью растового легаси. Он активно писался ещё во времена не очень стабильного Rust, когда и экосистема была не развита, и практик не было выработано. Собственно, благодаря Servo (в том числе) это со временем устаканилось. Servo выполнил свою функцию. Даже удивительно, что кое-что попало из него в Firefox. В настоящей момент в Servo невозможно контрибьютить - нужно переписывать заново.


webhamster
24.11.2022 17:28+1Интеллектуальная небрежность
Как поделился со мной в Твиттере Марек Краевски (Marek Krajewski), некоторые люди просто не стали бы использовать C++ из-за интеллектуальной инертности.
Так небрежность или инертность?
Прям по Фрейду...

maeris
24.11.2022 17:34+2Приведенные выше цифры впечатляют.
Да я аж офигел, когда увидел, что TypeScript в 5 раз медленнее интерпретирует (?) тот же самый JS код на той же самой VM. Это ж как нагло надо врать статистикой, чтобы миллиону разработчиков говорить такое в лицо?
Kelbon
24.11.2022 19:19+1Да, цифры этой статистики крайне тупые(сделаны фанатами раста, судя по цифрам).
Сделать чтобы С++ был в 1.6 раза медленнее С, при том что в нём компилируется ТОТ ЖЕ код это нереально тупо конечно
sshemol
24.11.2022 20:39-1Ну почему же, С++ это еще и CRT.
Kelbon
24.11.2022 22:03+2Зачем вы общаетесь магическими словами? Вы можете раскрыть мысль? С++ быстрее С за счёт больших требований и возможности писать генерализованный нормальный код с теми же стл алгоритмами. В С ради этого вам придётся писать под каждую мелкую задачу дико оптимизированный код, что просто невозможно физически
sshemol
25.11.2022 06:27-3Ок, обьясню проще. В С++ присутствуют накладные расходы на выполнение под капотом CRT. В чистом С можно писать код без этого, наиболее приближенный к платформе, стало быть, более эффективный и производительный. Не зря ядра ОС и большинство системных библиотек пишутся на С.

arteast
25.11.2022 08:15+51) CRT - это C runtime library, оно как раз для C.
2) код, написанный на C, обычно без особого геморроя можно скомпилировать C++ компилятором. Вы утверждаете, что код, скомпиленный компилятором C, выполняется быстрее, чем тот же код, скомпиленный компилятором C++?
3) В windows ядро в основном написано на C++. Если говорить про *nix, то системные библиотеки пишут на C потому, что а) у него более стабильный ABI и б) их начали писать 40 лет назад - традиция-с.
DistortNeo
25.11.2022 19:52+1Если говорить про *nix, то системные библиотеки пишут на C потому, что а) у него более стабильный ABI и б) их начали писать 40 лет назад — традиция-с.
Добавлю ещё и тот факт, что компилятор C есть в каждом утюге, тогда как компилятора C++ под целевую платформу может попросту не существовать. Язык C даёт оптимальный баланс между уровнем абстракций и охватом различных платформ.
sshemol
25.11.2022 23:52+1Вы утверждаете, что код, скомпиленный компилятором C, выполняется быстрее, чем тот же код, скомпиленный компилятором C++?
Нет, я утверждаю, что С++ код с классами и сопутствующими конструкторам\деструкторами и таблицами методов\свойств не может быть быстрее, чем без всего этого.

viordash
26.11.2022 00:26+3а если конструктор/деструктор без кода? я не тролю, не смотрел дизассемблер, но предполагаю что затраты около нуля. А если в конструкторе/деструкторе чтото есть, то наверно по логике и в подобном Си коде будет иницилизация/освобождение?
vanxant
26.11.2022 01:05+2Таблицы свойств в С++? Хм...
Тривиальные конструкторы и деструкторы в плюсах отлично инлайнятся. С другой стороны, нетривиальные конструкторы/деструкторы есть и в С, просто они называются blabla-open или *-init, и вместо new/delete вам надо залезть в документацию и выяснить название соответствующего метода.
Открою страшную тайну, но ядро линукса написано на Си, но с использованием олдскульного ООП. Примерно все драйверы и модули представлены в рантайме объектами известной структуры, которые реализуют необходимые интерфейсы при помощи таблиц указателей на функции с известной сигнатурой.
Таблицы виртуальных методов могут быть и быстрее, чем сишный switch, который компилится в кучу условных переходов. Это зависит от конкретной ситуации, ну и как бы в школе рассказывают, что "не плоди виртуальных методов без реальной надобности".

rukhi7
26.11.2022 16:54Открою страшную тайну, но ядро линукса написано на Си, но с использованием олдскульного ООП
Это как это чистый Си поддерживает ООП??? Это получается чистый Си это ООП язык?
Как же вас тут ООП специалисты не забодали еще :) ?
vanxant
26.11.2022 18:27+3Чистый Си не мешает писать в ООП-стиле, хотя и не помогает. По крайней мере в нём есть всё необходимое - структуры и указатели на функции - для реализации примитивов ООП вручную.
arteast
26.11.2022 09:46C++ код с классами, конструкторами и деструкторами будет столь же быстрым, как и аналогичный ему C код, но будет более коротким (если код написан правильно, с обработкой ошибок) и читабельным - это если не пользоваться идиоматическими C++ возможностями, а именно виртуальными функциями и исключениями (отключить вообще исключения опциями компилятора).
Если брать более идиоматический код и добавить виртуальные функции, то они будут либо чуть-чуть медленнее, чем применяемые в таких ситуациях C ссылки на функции (если ссылки лежат прямо в структуре - но тогда C-шный вариант будет более прожорлив по памяти), либо такими же по скорости (если C-шный вариант применяет эрзац таблицы виртуальных методов по типу struct ..._ops), либо даже чуть быстрее (32-битный Windows ABI - thiscall более оптимально использует регистры, чем cdecl)
Если добавить исключения как идиоматическую замену кодам ошибок, то код становится еще компактнее и быстрее в "обычном" случае безошибочной работы (т.к. большинство ABI обеспечивают бесплатный try/except, а в C требуется проверка кода ошибки везде). Исключение - тот же 32-битный Windows ABI, где try не бесплатен.
F0iL
24.11.2022 20:42Зависит от того, как писать. Если писать в стиле "Си с классами", то выхлоп будет примерно одинаковый, если активно использовать exceptions, RTTI, std::shared_ptr, std::string (которые, как известно, в наше время без COW), и подобное, то итоговый код может получиться сильно жирнее.
Kelbon
24.11.2022 20:55+4Во первых, все эти ексепшн ртти и шаред поинтеры если используются, то очевидно в С коде использовалось что-то чтобы их заменить.
Во вторых, там простейший код с каким то алгоритмом чего-то там считать.
Перечисленные вещи не медленные и не "жирные", это распространённое заблуждение, повлиять на перфоманс в плохую сторону могут разве что исключения при неправильном их использовании(в качестве логики, а не индикации исключительной ситуации) и rtti при постоянных динамик кастах - но это чудовищно плохой код
Зачем вам в строке COW вообще непонятно
F0iL
24.11.2022 21:15+1то очевидно в С коде использовалось что-то чтобы их заменить.
Например, в качестве аналога тех же исключений в Си-коде зачастую используют тупо goto на нужную метку и присваивание соответствующего errno/errstr. По сути дела - одна JMP и одна MOV-инструкция. Код, который генерируется C++ для обработки исключений даже с -O3 гораздо больше и сложнее, более того, там происходит аллокация памяти, можно на godbolt проверить и убедиться.
Зачем вам в строке COW вообще непонятно
До GCC 5 у std::string вполне себе был CoW, потом его пришлось выкинуть (ибо это было нарушение стандарта, т.к. банальный [] инвалидировал итераторы), и многим взгрустнулось. Зависит от конкретной задачи и конкретного алгоритма. Например, вот тут разработчики одного большого и сложного продукта самостоятельно впиливали CoW в строки, ибо с ним им было сильно лучше.
vanxant
24.11.2022 21:31+5одна JMP и одна MOV-инструкция
И как, хорошо JMP работает, если нужно перейти в неизвестный обработчик, который определён на десяток уровней вверх по стеку, и не забыть по дороге освободить ресурсы и память?
F0iL
24.11.2022 22:09-2А если мне не надо переходить на обработчик в десяти уровнях выше по стеку, а хватит того, который вот здесь рядом?
vanxant
24.11.2022 22:45+2Если у вас обработчик вот здесь рядом, и к нему можно перейти через goto / if-ы, то вам и исключения не нужны. Собственно, в плюсах по этой причине и нет finally, чтобы не злоупотребляли исключениями в рамках одной функции.
Вы напишите goto с errno в какой-нибудь асинхронной функции, потом сравнивайте.
maeris
25.11.2022 05:42В плюсах есть finally. Деструктор называется. При большом желании можно даже передавать лямбду в конструктор класса finally, и вызывать её в деструкторе. Более того, деструкторами пользуется приблизительно каждый контейнер в стандартной библиотеке.
А так вы, конечно, правы, и я не понимаю, что вам тут доказать пытаются.
vanxant
25.11.2022 12:35+5В плюсах есть finally
Нет. Это утверждение из серии про "дружит со всеми БД" выше.
В плюсах есть костыль для эмуляции finally. Иногда задача легко и красиво ложится на деструктор, особенно если вы заранее упоролись по RAII (это так же требует, чтобы подкапотный код, какие-нибудь сишные либы или интерфейсы, хорошо натягивались на идею RAII). Замечу, я не против RAII самого по себе, просто не всегда это оптимальное решение. А других по факту нет.
Бывают случаи, когда у ресурса больше двух состояний (он может быть не только открыт/закрыт), и вы не уничтожаете объект при ошибке, а переводите его в некое другое состояние. Бывает, что объект нельзя закрывать повторно - например, double free это UB. Наконец, чаще всего бывает, что у нас просто есть протокол, который требует после операции А обязательно сделать операцию В, не зависимо от успеха А, а А швыряется исключениями.
Во всех перечисленных случаях нам нужно либо копипастить, либо создавать аж целый класс ради вызова операции В в его деструкторе, либо колхозить флаги и if-ы c goto. Сравните с finally или, особенно, с Gо-шным defer. Язык должен помогать, а не заставлять учить паттерны ради паттернов.

eao197
25.11.2022 16:27+1Во всех перечисленных случаях нам нужно либо копипастить, либо создавать аж целый класс ради вызова операции В в его деструкторе, либо колхозить флаги и if-ы c goto. Сравните с finally или, особенно, с Gо-шным defer
Если вы после C++11 не можете сделать аналог Go-шного defer-а сами, то его можно взять, например, в GSL.
Язык должен помогать, а не заставлять учить паттерны ради паттернов.
Чтобы язык помогал, его нужно освоить. Хотя бы.
vanxant
25.11.2022 17:28Если вы после C++11 не можете сделать аналог Go-шного defer-а сами, то его можно взять, например, в GSL.
Ну так а я о чём? 27 строк бойлерплейта, причём ну не джуниорского уровня (эксплисит конструкторы, удаление операторов по умолчанию, не самая простая концепция std::decay_t ). Для операции, которую в других языках посчитали достаточно распространённой, чтобы ввести в язык отдельное ключевое слово.
И вот в плюсах со всем так. В любой программе у вас будет минимум два вида строк, минимум два вида массивов, и вместо того, чтобы думать над бизнес-логикой, вы будете бороться с языком и гуглить, как это реализовали сверхразумы из крупнейших компаний.
eao197
25.11.2022 18:07Ну так а я о чём?
Я хз. Есть ощущение, что о том, в чем не разбираетесь.
27 строк бойлерплейта
И что? Этот бойлерплейт пишется один раз в какой-нибудь пространстве имен utils и используется по мере надобности. Причем не так часто, как вам может показаться.
В C++ это обычное дело. Точно так же было с хэш-таблицами до C++11 (да и после, т.к. std::unordered_map не всех устраивает), со string_view до C++17, с std::expected до C++23 и т.д., и т.п.
причём ну не джуниорского уровня
Проекты не пишутся джуниорами. Ну это я так, если вы вдруг не знали.
Причем вне зависимости от языка программирования. А уж на C++ тем более.Для операции, которую в других языках посчитали достаточно распространённой, чтобы ввести в язык отдельное ключевое слово.
В других языках посчитали нужным и сборщик мусора в язык затащить. Давайте C++у в вину еще и отсутствие GC поставим.
В любой программе у вас будет минимум два вида строк, минимум два вида массивов
В современных условиях такое возможно только если:
a) вы имеете дело с легаси.
b) вам реально нужны эти разные типы строк и массивов. Скажем, исходя из требований по производительности/предсказуемости.
вместо того, чтобы думать над бизнес-логикой, вы будете бороться с языком и гуглить, как это реализовали сверхразумы из крупнейших компаний
Вы эти сказки таким же знатокам C++ как вы расскажите. Тогда найдете благодарную аудиторию.
На практике же приходится гуглить не какие-то особенности C++ или реализацию каких-то утилитарных вещей, а детали работы условного FFMPEG и SDL. Или пояснения к спецификациям каких-то протоколов. Или еще что-то в таком же роде, что гораздо ближе к проблемам бизнес-логики, чем отсутствие finally в языке.
vanxant
26.11.2022 01:37+2Не то чтобы я очень хотел участвовать в дискуссии с аргументами уровня "если вы такие умные, почему вы
строем не хоплюсы не учите", но ок.Этот бойлерплейт пишется один раз
Он (конкретно finally/defer) должен быть если не ключевым словом, то хотя бы в стандартной библиотеке. Так же, как какой-нибудь парсинг json и функциональные литералы.
В C++ это обычное дело.
Вот именно. В этой части проекта у нас QT, в этой eastl, здесь кто-то скопипастил неизвестно что со stackoverflow, здесь мы сами наколхозили, а теперь мы попробуем найти ещё одного неудачника в нашу команду.
Проекты не пишутся джуниорами.
Ага, а миддлы с сеньёрами размножаются клонированием. (spoiler: увы, нет)
Из миддла-плюсовика можно сделать миддла-гофера за две недели. Ещё через пару месяцев он запомнит наименования местных функций, все три "паттерна программирования", станет синьёром и будет счастлив. А вот обратный процесс займёт пару лет боли и страданий.
Давайте C++у в вину еще и отсутствие GC поставим.
А давайте! Сколько там уже было попыток сделать хотя бы тупейший подсчёт ссылок в стандартной библиотеке? Не считая испытательных полигонов уровня mfc, qt, boost, mc++ и так далее? И чсх до сих пор нормально не осилили.
И да, в расте тоже нет GC, но качество управления памятью в нём просто с другой планеты.
вы имеете дело с легаси ...
Мне трудно себе представить новый (без легаси) проект на плюсах, который бы не взаимодействовал с ОС, системными либами, не использовал бы интринсики и т.д. А там везде массивы в стиле С, строки в стиле С, обработка ошибок в стиле С (вместо исключений) и так далее.
Вы эти сказки таким же знатокам C++ как вы расскажите
Ну, раз дошло до личных советов, посоветую вам высунуть голову из ... норы и поинтересоваться, что там в индустрии за последние 20 лет случилось. А там, блин, долбаный js развивается в 10 раз быстрее плюсов. А там плюсы — последний популярный язык, который не умеет нормально в utf8 "из коробки". (Да-да, сейчас мне расскажут, что умеет - на том же уровне, что и finally и дружит со всеми БД)
eao197
26.11.2022 09:14+1Не то чтобы я очень хотел участвовать в дискуссии с
Не то, чтобы я очень хотел участвовать в дискуссии с тем, кто C++ видел разве что в подобных срачах, но...
Он (конкретно finally/defer) должен быть если не ключевым словом, то хотя бы в стандартной библиотеке.
Не должен. finally/defer нужны языкам без детерминированого времени жизни объектов, т.к. там без finally/defer сложно детерминировано управлять ресурсами. Да и то, в Java к finally в итоге добавили try-with-resources, а в C# -- using. Так что сам по себе finally не так уж хорош.
В C++ с детерминированным управлением ресурсами все хорошо с самого начала, так что надобность в finally всегда была гораздо ниже, чем в языках с GC. В тех редких случаях, когда finally таки был нужен, можно было пользоваться паллиативами (BOOST_SCOPE_EXIT, gsl::finally и т.д.) Причем язык позволял создавать эти паллиативы на коленке. Попробуйте на коленке сделать defer для Go.
Впрочем, в C++ный стандарт сейчас так активно пихают всякое разное, что я не удивлюсь появлению finally в стандартной библиотеке где-нибудь в C++26 или C++29.
Так же, как какой-нибудь парсинг json
Вот этого не нужно. Во-первых, кроме JSON есть XML, YAML, TOML. И еще неизвестно что появится позже. Кстати говоря, лет 15 назад про JSON мало кто знал, а вот сожаления об отсутствии XML-я в stdlib высказывались. Сейчас вот XML уже не вспоминают особо, а будь он в stdlib, кому-то все бы это пришлось поддерживать.
Во-вторых, я не верю в то, что для того же JSON-а сделают библиотеку, которая одновременно будет и быстрой, и удобной в использовании. Включат в stdlib RapidJSON, будут ругать за неудобство, включат в stdlib nlohman::json, будут ругать за тормознутость.
Такие вещи лучше под условия конкретного проекта выбирать.
функциональные литералы.
Что это такое?
Вот именно.
Вот именно что? Если для GUI вы взяли Qt а для около реалтаймовой части EASTL, то в чем собственно проблема?
Ага, а миддлы с сеньёрами размножаются клонированием. (spoiler: увы, нет)
И какой вывод из того, что они не размножаются клонированием? Дать порулить C++ным проектом джуниору?
Из миддла-плюсовика можно сделать миддла-гофера за две недели.... А вот обратный процесс займёт пару лет боли и страданий.
А зачем вам обратный процесс? Неужели из-за того, что на Go сложно будет решать задачи, которые решаются на C++?
А давайте!
Предлагать добавить GC в C++ и жалеть об отсутствии GC в С++ в конце 2022-го года можно только от небольшого ума, уж простите. Время уже давно все расставило по своим местам: C++ с GC не нужен. Благо альтернатив с GC, хоть managed, хоть native, в достатке.
И чсх до сих пор нормально не осилили.
И не осилят. ЕМНИП, последние кусочки из стандарта, которые хоть как-то предполагали наличие опционального GC, были в конце-концов выброшены.
И да, в расте тоже нет GC, но качество управления памятью в нём просто с другой планеты.
Ну было бы странно, если бы язык, создававшийся на замену C++ и с учетом проблем C++, был бы в этом отношении хуже C++.
Мне трудно себе представить новый (без легаси) проект на плюсах, который бы не взаимодействовал с ОС, системными либами, не использовал бы интринсики и т.д. А там везде массивы в стиле С, строки в стиле С, обработка ошибок в стиле С (вместо исключений) и так далее.
Вы не поверите, но массивы в стиле С и строки в стиле C прекрасно закрываются std::vector и std::basic_string. И обработка ошибок несложно трансформируется либо в использование исключение, либо в применение чего-то вроде std::expected.
Ну, раз дошло до личных советов, посоветую вам высунуть голову из ... норы и поинтересоваться, что там в индустрии за последние 20 лет случилось.
Да я как бы наслышан. Вот только C++, местами, все еще актуален.
А там, блин, долбаный js развивается в 10 раз быстрее плюсов.
C++ всегда развивался быстрее, чем поспевали компиляторостроители. За редким исключением в районе C++14/C++17 стандартов, когда реализация подъезжала практически одновременно с выходом фиальной версии стандарта.
А так-то уже C++20 два года назад принят, но только один компилятор сейчас его более-менее поддерживает. С принятия C++17 уже почти пять лет прошло, а в GCC/clang еще не все хорошо с поддержкой stdlib из C++17 (например, std::to_chars/std::from_chars).
И это еще не говоря о том, что в мире C++ многие еще даже на C++17 перейти не могут в силу разных обстоятельств.
Так что C++ развивается, как по мне, даже быстрее, чем хотелось бы.
Ну и да, еще на счет "за последние 20 лет случилось".
Это ведь еще сильно зависит от предметной области. Если вам в 2022-ом потребуется сделать форк Greenplum или MariaDB, заточенный под специфические нужды, или нужно будет начать делать кроссплатформенный видеоредактор, то скорость обрастания фичами JS-а или нововведения в Go вам вряд ли помогут.
DistortNeo
25.11.2022 19:59+3либо создавать аж целый класс ради вызова операции В в его деструкторе
И вишенка на торте: из деструкторов нельзя бросать исключения.
Если операция B, равно как операция A, может бросить исключение, придётся забыть про RAII и писать очень кривой код.
Kelbon
24.11.2022 22:08+3goto и метки с глобальным еррор кодом это медленнее, чем С++ исключения. Потому что еррор коды нужно проверять постоянно при каждом вызове, тогда как исключения используют особый свой механизм, позволяющий избежать оверхеда на эти проверки
goto не задействует RAII и сильно сказывается на возможности оптимизации кода, который выпрыгнул хз куда
Ну и да, goto так не работает, вы либо имели в виду setjmp, либо непонятно что
std::string ЛУЧШЕ чем cow строка, именно поэтому отказались от cow и сделали то что сейчас. cow это вообще крайне стрёмная херня, пользы от неё примерно 0
F0iL
24.11.2022 22:15+1Ну и да, goto так не работает, вы либо имели в виду setjmp
Простой goto в сишных проектах встречается для обработки ошибок гораздо чаще, чем setjmp.
именно поэтому отказались от cow
Неа. Отказались потому что это нарушало требование стандарта об инвалидации итераторов. Пруф: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=21334#c45
пользы от неё примерно 0
Выше приведен вполне реальный пример, когда благодаря CoW-строкам мужики неплохо ужались по памяти. Ну и во многих других языках (например, в Swift) CoW-строки вполне себе живут.
Kelbon
24.11.2022 22:20Выше приведен вполне реальный пример, когда благодаря CoW-строкам мужики неплохо ужались по памяти.
Такое может произойти только в очень плохом коде, где вместо стринг вью или ссылки делают новую строку копируя или что-то такое
Отказались от cow потому что оно по всем параметрам хуже. Инвалидация итераторов это лишь малая часть
Простой goto в сишных проектах встречается для обработки ошибок гораздо чаще, чем setjmp.
goto не может заменить исключения. Его в С используют только потому что там нет RAII и нужно прыгать на clear_rcrs или что-то такое
maeris
25.11.2022 05:51+2У стандартизаторов есть такая мысль, что алгоритмы должны работать одинаково во всех случаях. Например, есть более эффективные в обычных применениях алгоритмы сортировки, а ещё можно было бы специализировать сортировку на конкретные типы численные типы и сделать её на них за O(n), но в С++ намеренно сделано не так. Сделано это из соображений стабильности (чтобы не было внезапных лагов как в языках с GC) и безопасности (чтобы нельзя было подобрать предельный случай и поломать приложение).
CoW-строками, потребляют слишком рандомное время на ряд операций. Банальное обращение к элементу может в зависимости от имплементации быть O(log N) или O(N), хотя пользователь ожидает O(1). Именно это стреляет по ногам джаваскриптерам при работе со строками (это же совершенно очевидно, что их нужно сплитить в массив по одной букве перед тяжёлыми вычислениями). Именно поэтому их нет в стандартной библиотеке С++, и не будет.
0xd34df00d
25.11.2022 08:10+7CoW-строками, потребляют слишком рандомное время на ряд операций.
Шаред_птры тоже потребляют рандомное время — деструктор может выполниться за несколько тактов, если счётчик ссылок ненулевой, и достаточно его декрементировать, и за много-много тактов, если надо прибить объект и вернуть память.
Про зависимость потребления памяти от того, выделен ли он через
make_sharedили нет, и говорить не стоит.
MariyaNUB
24.11.2022 17:53+1Работа на С++, конечно, не сахар, но хорошо что он развивается, тем самым облегчает жизнь.

YungFlaeva
24.11.2022 17:54+1Хотелось бы добавить пару слов об образовательной части C++ — это отличный способ углубиться в понимание устройства процессов железа, особенно после таких языков, как C# и Java. Более того, после изучения курса по алгоритмам и структурам данных, начинаешь более вдумчиво и ответственно писать код, предварительно успев отстрелить себе несколько раз ногу. Однако C++ не стоит рассматривать как первый для изучения ЯП. Для новичков лучше начинать свой путь с Python (можно без ООП), далее перейти на C# или Java, а затем уже погрузиться в мир указателей, динамической памяти и множественного наследования.
WondeRu
24.11.2022 17:56+2по поводу слайда сравнения используемых ресурсов (СО и прочего), вспоминается анекдот:
Жизнь слишком коротка, чтобы писать на
ассемблереС++ (с)maeris
25.11.2022 05:59+1Есть даже широкоизвестный закон Проебстинга: компиляторы увеличивают производительность кода в два раза каждые 18 лет.
Использование С++ не имеет никакого смысла, если размер задач не подразумевает миллионные убытки на электроэнергию и вычислительные мощности.

orcy
24.11.2022 18:39+1Зачем писать на C++ в 2022 году?
Потому что это лучший язык на земле?
Но статья немного странная, если честно, обычно когда у вас есть проект вы уже представляете какие варианты по языкам. Даже если очень любишь C++, есть задачи явно не для этого языка, как и наоборот.
Mingun
24.11.2022 18:58+3В то же время одной из суперсил C++ является обратная совместимость.
Суперсилы нужно правильно применять. Вот в расте покумекали-покумекали, и сделали редакции. Старый код на старой, новый — на новой. Очень сомневаюсь, что возможность раз в десятилетие скомпилировать чей-то курсовик 40-летней давности стоит того, чтобы все остальные разработчики хватались за голову, разбираясь, что же сейчас стоит использовать, а что уже нет.
Более того, что мешает скомпилировать объектники старым компилятором и подать их на вход новому линкеру? Думаю, их формат действительно совместимый, т.к. меняться там скорее всего особо нечему.
sshemol
24.11.2022 21:37Обратная совместимость очень важная вещь. В каком нибудь линуксе PHP написанный на 5 версии, отказывается работать на 7 (следующей). Так быть не должно.

BugM
24.11.2022 22:42+5Вы видели процесс обновления С++ компилятора в большом проекте? Это месяцы работы большой специально выделенной команды. И с практически 100% багами в проде после перехода.
Это не совместимость.

allcreater
24.11.2022 23:32-1Похоже, что зависит от степени запущенности проекта.
Повырубав кучу ворнингов заставить компиляться и работать не так уж сложно и долго. А потом да, постепенно эти ворнинги исправлять параллельно с разработкой в течение месяцев. Самое удивительное, что когда потом включаешь обратно эти трактуемые как ошибки предупреждения, оказывается, что они вообще-то были очень даже по делу, и фактически работа проводилась вовсе не ради галочки, а сделала продукт стабильнее и лучше.
Другими словами, при переходе на новый стандарт основные проблемы, кмк, возникают именно из-за более чувствительных к ошибкам и нарушению стандарта компиляторов, а отнюдь не прихоти.
Тяжелее всего должен быть переход C++98 на 11, поскольку в древнем C++ очень многие вещи делались абы как и с явным уб, без которого жить было невозможно в принципе(те же потоки)

CrashLogger
24.11.2022 23:54+1А при чем тут линукс вообще ?
sshemol
25.11.2022 06:53Ну там это вообще принято, не обеспечивать обратную совместимость, такой юникс-стайл )
maeris
25.11.2022 06:04Вы мне напомнили, как в универе нам однажды выдали пример интерпретатора на Си. На таком древнем Си, что он уже даже компиляторами не компилируется. Там типы аргументов объявлялись между ) и {, например.

mapnik
24.11.2022 19:30+2Если исключить из всех существующих программерских задач веб-разработку, то, собственно, какие ещё останутся пригодные языки, кроме C и C++?

shiru8bit
24.11.2022 19:48+1Java и Python.
mapnik
24.11.2022 19:54+4Можете из головы назвать пяток более-менее широкоупотребляемых программ, написанных на питоне?
shiru8bit
24.11.2022 20:01+1Не могу, но это не значит, что язык не применяется в разработке. В Blender'е на нём скрипты, например, реализующие часть функционала. Есть игровой движок PyGame с мелким, но всё же какими-то реальными проектами (Frets of Fire), и в целом в различных игровых движках скриптовая часть нередко реализована на нём. Разнообразный научный софт часто написан на Питоне.
mapnik
24.11.2022 20:13О, точно, Ren'Py же и всё на нём написанное, включая БЛ!
Ещё знаю Electrum и производные от него.
Вот уже целых две питонопрограммы. Ура.Сложность питоноскриптов блендера надо посмотреть - вдруг они тоже реально что-то делают. Будет три.
vanxant
24.11.2022 20:25-1sublime (был несколько лет назад вполне себе популярным текстовым редактором)
setevik
24.11.2022 23:47+1Кроме массы всего связанного с data science, ML и т.д. где Python стандарт де-факто?
Ansible, Manim, micropython, httppie, localstack.
Go тоже вариант иногда



Psychosynthesis
24.11.2022 21:32+3Я конечно люблю кресты, но мне одному кажется (?) что вот это:
// теперь мы можем написатьПример того как писать не надо? Ну окей, это короче, но совершенно нечитаемо... Может я застрял в embedded конечно, но выглядит гораздо хуже тривиального цикла приведённого выше.
auto isEven = [](auto number) { return number % 2 == 0; };
auto count = std::ranges::count_if(numbers, isEven);F0iL
24.11.2022 22:04+2Согласен, нечитаемо. Зачем отдельно объявлять isEven?
Вот так гораздо лучше:auto count = std::ranges::count_if(numbers, [](auto n) { return n % 2 == 0; });(благо, во многих проекта о maxcols=80 уже давно забыли как страшный сон)
freecoder_xx
24.11.2022 22:32+10Холивара ради: а ведь говорят, что у Rust ужасный синтаксис.
let count = numbers.iter().filter(|number| *number % 2 == 0).count();0xd34df00d
24.11.2022 22:37+3count = length . filter ((== 0) . (`rem` 2))BugM
24.11.2022 22:48+4Это на любом нормальном языке примерно одинаково выглядит.
Завидовать можно дотнетовскому LINQ. Вот он хорош и совсем не везде такой же есть.
0xd34df00d
24.11.2022 22:58+1Это на любом нормальном языке примерно одинаково выглядит.
section'ы и частичное применение из коробки есть, мягко скажем, не везде.
Завидовать можно дотнетовскому LINQ. Вот он хорош и совсем не везде такой же есть.
Частный случай do-нотации.
BugM
24.11.2022 23:07+4section'ы и частичное применение из коробки есть, мягко скажем, не везде.
Явно есть много где. Бойлерплейт это печально, но это терпимая плата за упрощение языка.
Частный случай do-нотации.
Сделанная для людей, а не как обычно. И то много жалоб что слишком сложно.
0xd34df00d
24.11.2022 23:34+2Явно есть много где.
Везде, где есть анонимные функции, понятное дело. Но зачем их каждый раз писать явно?
Бойлерплейт это печально, но это терпимая плата за упрощение языка.
Самый простой язык — либо брейнфак, либо лямбда-исчисление, смотря из какого вы лагеря, но вот что-то ими особо никто не пользуется. Наверное, потому, что простота языка — далеко не единственный и даже не монотонный критерий.
Создавать лямбду просто для того, чтобы частично применить функцию — это синтаксический мусор и рябь в глазах. Читать
map (`rem` 2) numbersимхо проще, чем
map (\n -> n `rem` 2) numbersСделанная для людей, а не как обычно.
А do-нотация чем не для людей? Зато куда более общая концепция, и ей можно что в SQL-базу ходить, что парсеры описывать. На LINQ парсеры люди, конечно, тоже пишут, вроде даже на хабре статья была, но это уже совсем извращение ИМХО.
И то много жалоб что слишком сложно.
Это всё от, как там, интеллектуальной небрежности.
BugM
24.11.2022 23:49+4Наверное, потому, что простота языка — далеко не единственный и даже не монотонный критерий
Смотрю я на популярность Go и начинаю сомневаться.
Я за баланс. До уровня Go падать не стоит, а вот тот же С++ или Хаскель (смотря из какого вы лагеря) это перебор. Лучше всего посередине.
На LINQ парсеры люди, конечно, тоже пишут, вроде даже на хабре статья была, но это уже совсем извращение ИМХО
Пишут. Нормально выходит вообще. Опять не идеально, но нормально.
Для массового языка это достижение. На других массовых языках в среднем хуже выходит.
Это всё от, как там, интеллектуальной небрежности.
Мир не совершенен.
0xd34df00d
25.11.2022 00:05+2Смотрю я на популярность Go и начинаю сомневаться.
Популярность — это вообще вопрос такой, неоднозначный. Вокруг меня нет ни одного проекта на go, например, какие выводы можно сделать? Ну, да, какие-то там докеры-кубернетесы на нём написаны, кто-то что-то внутри компаний, говорят, пишет, но о популярности языка тут выводы сделать тяжело.
а вот тот же С++ или Хаскель (смотря из какого вы лагеря) это перебор
С C++ всё понятно, а с хаскелем что слишком сложно?
Пишут. Нормально выходит вообще. Опять не идеально, но нормально.
То есть, делать закат солнца вручную на неприспособленных к этому инструментах (метапрограммирование на темплейтах, парсеры на linq, etc) — это норм, а потратить вечер на специально созданную для соответствующих задач концепцию — сложно?
BugM
25.11.2022 00:20+1Популярность — это вообще вопрос такой, неоднозначный
Я обычно по количеству вакансий смотрю. Остальное зависит от окружения.
а с хаскелем что слишком сложно?
Концепции слишком сложные. Люди их не понимают. Я бы сказал что средний мидл может не понять. Возможно учат плохо, не знаю.
Я на собеседованиях на Джаву уже отчаялся и больше не прошу собеседующихся на мидла своими словами рассказать мне как работает и что делает flatMap. Валятся в общем-то нормальные разработчики.
То есть, делать закат солнца вручную на неприспособленных к этому инструментах (метапрограммирование на темплейтах, парсеры на linq, etc) — это норм, а потратить вечер на специально созданную для соответствующих задач концепцию — сложно?
Ага. Я беру типичного мидла и отправляю его дописать очередной визитор в существующий проект. Со второго раза он точно справится. Две недели на обучение, наверно.
А вот в том что он за хотя бы пару месяцев освоит специальный язык на уровне достаточном чтобы понять и дописать тот же визитор в существующий проект немаленького размера я совсем не уверен.
Как-то глобально что-то поменять в существующем проекте он не сможет ни в том ни в другом случае. Тут равенство.
А те кто могут и пишут просто смирились уже. В конце концов бывает и хуже. Люди вон на плюсах пишут такие же штуки еще и с мутирующим стейтом где-то глубоко внутри. Вот это настоящее страдание.
0xd34df00d
25.11.2022 00:31+3Я обычно по количеству вакансий смотрю. Остальное зависит от окружения.
Количество вакансий тоже зависит. Вы ж не ищете просто вакансии «программист», наверное?
Концепции слишком сложные. Люди их не понимают. Я бы сказал что средний мидл может не понять. Возможно учат плохо, не знаю.
Если объяснять через всякие буррито, то и я бы не понял. Но для программирования это не нужно, всякие там монады — это просто интерфейсы. У вас же нет проблем с тем, что «IComparable — это такой-то интерфейс с такими-то требованиями»? Ну вот и «монада — это такой-то интерфейс с такими-то требованиями».
Причём я бы ещё сказал, что вся эта функциональщина — это куда проще, чем ООП. Всякие эти адаптеры, фасады, прочее подобное — это какие-то тяжело формально определимые концепции, которые скорее пахнут чем-то чувственным, гуманитарным, чем нормальным программированием. Что проще объяснить — чем адаптер отличается от фасада, или чем аппликативный функтор отличается от монады?
Не, я охотно верю, что есть люди, которые не могут осознать, что такое IComparable, как должны быть связаны сравнения и хешкоды, и всё такое, но что они делают в программировании? Зачем они вам нужны как нанимателю? Зачем вам как работнику работать среди таких людей? Зачем вам как клиенту пользоваться софтом, произведённым такими людьми? Похоже, языки, в которых невозможно делать вид, являются отличным фильтром!
Я на собеседованиях на Джаву уже отчаялся и больше не прошу собеседующихся на мидла своими словами рассказать мне как работает и что делает flatMap. Валятся в общем-то нормальные разработчики.
ЧТД, действительно был бы отличный фильтр.
Ну и, то есть, сама концепция flatMap (который есть и в Джаве, и в JS, и много где ещё) для них слишком сложная? Так тут не язык виноват, концепции-то есть вне языков.
BugM
25.11.2022 00:48+1Количество вакансий тоже зависит. Вы ж не ищете просто вакансии «программист», наверное?
Да. По настроению добавляю зарплата не указана и вычеркиваю все окологос конторы. Они не указывают зарплаты от бедности.
Причём я бы ещё сказал, что вся эта функциональщина — это куда проще, чем ООП
ООП хорошо вдалбливают в институтах. Прям несколько лет обычно. С кучей экзаменов, курсовых и прочего.
А функциональщина остается на уровне полугода Лиспа в лучшем случае. И то там не придираются к тому что человек не смог обычную курсовую написать. Когда пишут за него это хорошо видно.
Не, я охотно верю, что есть люди, которые не могут осознать, что такое IComparable, как должны быть связаны сравнения и хешкоды, и всё такое, но что они делают в программировании? Зачем они вам нужны как нанимателю? Зачем вам как работнику работать среди таких людей? Зачем вам как клиенту пользоваться софтом, произведённым такими людьми?
Джейсоны должны быть переложены. Для этого не очень много знаний надо. Про квадрат и мапы знает, несложный код в режиме live coding написать может и ладно. И то люди даже без такого уровня знаний приходят регулярно.
ЧТД, действительно был бы отличный фильтр.
Для людей с сеньорами, архитекторами и еще много страшных слов в резюме на вакансию программиста я оставил этот вопрос. Даже из них отсеивается немало. Прям сразу за 5-10 минут все понятно.
Ну и, то есть, сама концепция flatMap (который есть и в Джаве, и в JS, и много где ещё) для них слишком сложная? Так тут не язык виноват, концепции-то есть вне языков.
Да. Скопипастить готовый кусок и немного подправить под свой случай могут. Объяснить как работает нет. Концепцию не понимают. Синтаксис пофиг. Я именно про концепции.
maeris
25.11.2022 06:14+2Концепции слишком сложные
Да, там на первых порах случайно ввели в язык монады, а надо было вводить какие-нибудь эффекты, но тогда люди ещё не знали. И с ленивостью по умолчанию тоже вышло так себе. Ну и там с monomorphism restriction стрёмно немного. И в целом compile-type prolog в тайпклассах это немного не то, чем должен заниматься человек, которому нужно код в продакшен писать.
Зато во всех остальных отношениях Haskell элементарен и прост.
0xd34df00d
25.11.2022 08:07+1И с ленивостью по умолчанию тоже вышло так себе.
Ну хз, практика показывает, что рассуждать о производительности в ФП вообще сложновато. Но человеку вон жсоны перекладывать надо, так что не страшно.
Ну и там с monomorphism restriction стрёмно немного.
Ну это туповатое решение, да, без которого можно было бы обойтись. К счастью, есть
-XNoMonomorphismRestriction, это ошибка компиляции, и так далее.И в целом compile-type prolog в тайпклассах это немного не то, чем должен заниматься человек, которому нужно код в продакшен писать.
Ну в джаве дженерики так-то тоже Тьюринг-полные, но это не значит, что джава-программист обязан на них писать программы.
maeris
25.11.2022 10:30+1Ну в джаве дженерики так-то тоже Тьюринг-полные
Так в Haskell и без Тьюринг-полноты оно недружелюбно. Без MPTC и FunDeps не типизируется и весьма простой код, а с ними как-то более хардкорно, чем хотелось бы ожидать от банальной перегрузки.
К счастью, есть
-XNoMonomorphismRestrictionНо он же никак не решает коренную проблему: неявную мемоизацию, включаемую только чисто синтаксически. Вроде бы как язык чистый, а тут какой-то стейт появляется.
рассуждать о производительности в ФП вообще сложновато
Вообще практика показывает, что только в ФП и можно вообще о ней рассуждать, потому что как раз через equational reasoning можно выводить алгебраически (формализмом Бёрда-Меертенса, например) алгоритмы с лучшей асимптотикой, чем в спецификации, а без ФП можно только что-то эдакое наваять и понадеяться, что нигде нет ошибок.
Проблема только в конкретном сорте ФП, с нормальным порядком редукции, который меняет асимптотику от малейших правок и рандомно.

kosmonaFFFt
25.11.2022 11:53+3Почитал тут вашу ветку, и хочу кинуть камень в огород Haskell. Ни в каком другом языке я не встречал настолько отвратительной документации к библиотекам, как там. У плюсовых библиотек тоже часто с этим печально бывает, но обычно не настолько. Пример - дока по Lens - дается куча каких-то выражений на Haskell, и разбирайся с этим сам. Ну и нейминг зачастую как в математике - куча каких то одиночных букв и операторов, от которых глаза слезятся.
0xd34df00d
25.11.2022 23:08+1По крайней мере, часто из типов всё понятно, и в первую очередь стоит читать именно их. А в плюсах уже возникают проблемы с тем, чтобы понять, кто чем владеет и кто что от кода ожидает.
0xd34df00d
25.11.2022 23:08+1Без MPTC и FunDeps не типизируется и весьма простой код, а с ними как-то более хардкорно
Так «как-то более хардкорно» или «надо играть в пролог»? Окей, возьмём, что там у нас с MPTC и фундепсами сразу, ну возьмём какой-нибудь
MonadError e m | m -> e. Где тут игра в пролог?чем хотелось бы ожидать от банальной перегрузки.
Банальной перегрузки чего?
И, к слову, тайпклассы — это не перегрузка. Тайпклассы — это такой сахарок для передачи словарей функций + алгоритм их разрешения + некоторые правила, чтобы результаты разрешения были когерентными.
Но он же никак не решает коренную проблему: неявную мемоизацию, включаемую только чисто синтаксически.
В этом наборе слов нет смысла — здесь нет ни мемоизации, ни неявности, ни каких-либо синтаксических особенностей.
Коренная проблема в том, что в некоторых случаях type inference по стандарту должен вывести не наиболее общий тип (который был бы полиморфным), а зафиксировать конкретные значения метапеременных. Зачем так сделано — действительно непонятно.
Но кидать этот камень в огород хаскеля несколько странно, учитывая, что с одной стороны спектра тип указывать надо вообще всегда (напишите в плюсах функцию, не указывая её тип, ага), а с другой стороны спектра (в агде, идрисе и так далее) — в общем, тоже всегда (по крайней мере, в локальных where-байндингах, где люди как раз обычно натыкаются на обсуждаемое поведение).
Вроде бы как язык чистый, а тут какой-то стейт появляется.
Вас не смущает, что чистота — она в, собственно, языке, а стейт (который не стейт, а на самом деле вывод не-most-general-type, который в этой решётке оказывается, удивительно, не единственным) — в движке вывода типов?
Вообще практика показывает, что только в ФП и можно вообще о ней рассуждать, потому что как раз через equational reasoning можно выводить алгебраически (формализмом Бёрда-Меертенса, например) алгоритмы с лучшей асимптотикой, чем в спецификации, а без ФП можно только что-то эдакое наваять и понадеяться, что нигде нет ошибок.
А потом у вас η-редукция в компиляторе отвалилась, и всё, приплыли. Идрис — строгий, кстати.
Проблема только в конкретном сорте ФП, с нормальным порядком редукции, который меняет асимптотику от малейших правок и рандомно.
Проблема в том, что написать хорошо оптимизирующий компилятор сложно. Просто в не-ФП люди меньше полагаются на хорошую оптимизацию (что, впрочем, не совсем корректное утверждение, потому что в ФП вам никто не мешает наваять eDSL для описания достаточно низкоуровневых вещей, но это совсем другая история).
maeris
26.11.2022 05:37-1Где тут игра в пролог?
Очевидно, в том месте, где инстансы матчатся по типу, а не в определении класса.
Тайпклассы — это такой сахарок для передачи словарей функций + алгоритм их разрешения
Это и называется перегрузкой. Вам бы надо обязательно попросить Simon Peyton Jones тоже использовать расово верные эпитеты, а то у него иногда проскакивает. От недостатка образования в ФП, наверное.
Зачем так сделано — действительно непонятно.
Вас не смущает, что чистота — она в, собственно, языке, а стейт (который не стейт, а на самом деле вывод не-most-general-type, который в этой решётке оказывается, удивительно, не единственным) — в движке вывода типов?
Вас не смущает, что вы вообще не представляете, о чём говорите? :)
Ознакомьтесь, пожалуйста, с матчастью хотя бы в haskellwiki и спилите мушку.
0xd34df00d
26.11.2022 08:56+1Очевидно, в том месте, где инстансы матчатся по типу, а не в определении класса.
Если честно, не очевидно. Ну матчатся и матчатся — пока поведение достаточно ожидаемое, и пока вам не приходится лезть в дебри instance resolution'а, то никакой проблемы в этом нет.
А, кстати, когда вы какой-нибудь
std::beginв плюсах пишете, вы не играете в пролог случаем?Это и называется перегрузкой.
А когда я в идрисе пишу
{auto foo : Bar}, что примерно то же самое с точностью до гарантий когерентности (и возможной неуникальности найденного инстанса), это тоже перегрузка, что ли?Вам бы надо обязательно попросить Simon Peyton Jones
Апелляции к авторитету — ну такое.
Вас не смущает, что вы вообще не представляете, о чём говорите? :)
Меня не смущают несуществующие вещи. Ну, в смысле, я-то как раз понимаю, о чём говорю.
Давайте вы как-то будете по существу говорить, хорошо? А то нашли какой-то стейт, какую-то мемоизацию…
Ознакомьтесь, пожалуйста, с матчастью хотя бы в haskellwiki и спилите мушку.
А, это многое объясняет (включая другие некоторые ваши перлы)!
Вы, видимо, быстренько погуглили, что там в хаскеле неок, открыли для себя в том числе monomorphism restriction, сходили на ту самую вики, выцепили какие-то слова про мемоизацию, совершенно не понимая, причём она там и к чему… Так вот, хотя пересечение мемоизации (на самом деле возможности шарить вычисления, но неважно) и обсуждаемой «фичи», конечно, ненулевое, но очень-очень маленькое, и фокусироваться на этом не стоит.
maeris
26.11.2022 22:59это тоже перегрузка, что ли?
Любой случай, когда у вас имплементация при вызове выбирается на основе типа, принято называть перегрузкой. Спор о терминах -- ну такое. Можно с тем же успехом утверждать, что Java -- не ООП, потому что в ней LSP не работает, или что Си -- функциональный язык, потому что там есть first-class function pointers. Эта казуистика на практике бессмысленна, и вам ничем не поможет.
Апелляции к авторитету — ну такое.
Ну да, апеллировать к автору тайпклассов и HaskellWiki нельзя. Их только неудачники читают, чтобы вас публично уязвить.
Ну, в смысле, я-то как раз понимаю, о чём говорю.
Хорошо, давайте по существу, если Даннинг и Крюгер не позволяют вам разобраться самостоятельно.
Когда тайпклассы имплементят через dictionary passing, получается проблемка: вещи, которые раньше были просто значениями, становятся функциями. Например, когда мы пишем
fib = 0 : 1 : zipWith (+) fib (tail fib)и для него (гипотетически) выводится тип
(Num a) => [a], то на самом деле получаетсяfib d@{fromInteger, add} = fromInteger 0 : fromInteger 1 : zipWith add (fib d) (tail $ fib d)исполняющийся за экспоненциальное время. Собственно, об этом нам прямым текстом пишут в секции 4.5.5 стандарта языка, которую вы так и не удосужились прочесть.
С тех пор, конечно же, ребята догадались, что мономорфизация/инлайнинг, в общем-то, не сильно хуже, чем dictionary passing, разве только с полиморфной рекурсией не работают, и GHC сейчас компилирует код иначе.
Мемоизация (на самом деле, CAF, но неважно), кстати, довольно часто используется, чтобы гарантировать, что какой-то код исполнился не больше одного раза, и вопрос "не выведутся ли тут типы, которые превратят этот код в экспоненциальный" внезапно становится крайне важным.
Вам бы пришлось узнать, как оно там на самом деле работает, если бы попробовали всё-таки сфокусироваться на этом и написать хоть какой-то тривиальный производительный код. На практике это полезнее, чем разбираться в тонкостях
Has.
0xd34df00d
26.11.2022 23:51+1Любой случай, когда у вас имплементация при вызове выбирается на основе типа, принято называть перегрузкой.
Ок, вывод аргументов — это тоже перегрузка, как и разные сорта proof search'а. Буду иметь в виду!
Ну да, апеллировать к автору тайпклассов и HaskellWiki нельзя.
Апеллируйте к тому, что говорится, а не кем говорится.
Когда тайпклассы имплементят через dictionary passing, получается проблемка: вещи, которые раньше были просто значениями, становятся функциями.
Да, я знаю, о чём и писал выше.
Например, когда мы пишем [...] исполняющийся за экспоненциальное время.
Во-первых, никто не мешает компилятору сделать из
fib :: Num a => [a] fib = 0 : 1 : zipWith (+) fib (tail fib)что-нибудь в духе
fib :: Num a => [a] fib = go where go :: [a] go = 0 : 1 : zipWith (+) go (tail go)Во-вторых, ничего там экспоненциально не исполняется, потому что компилятор это на самом деле спокойно делает. Возьмите
это{-# LANGUAGE TypeApplications #-} {-# LANGUAGE ScopedTypeVariables #-} {-# LANGUAGE ViewPatterns #-} import System.Environment fib1 :: Num a => [a] fib1 = 0 : 1 : zipWith (+) fib1 (tail fib1) fib1' :: forall a. Num a => [a] fib1' = go where go :: [a] go = 0 : 1 : zipWith (+) go (tail go) fib2 :: (a -> a -> a) -> (Integer -> a) -> [a] fib2 add mk = mk 0 : mk 1 : zipWith add (fib2 add mk) (tail $ fib2 add mk) fib3 :: (a -> a -> a) -> (Integer -> a) -> [a] fib3 add mk = go where go = mk 0 : mk 1 : zipWith add go (tail go) main :: IO () main = do [arg, read -> cnt] <- getArgs case arg of "1" -> print $ fib1 @Int !! cnt "1'" -> print $ fib1' @Int !! cnt "2" -> print $ fib2 @Int (+) fromInteger !! cnt "3" -> print $ fib3 @Int (+) fromInteger !! cntЗдесь
fib3иfib1'всегда исполняется быстро,fib2всегда исполняется медленно, аfib1исполняется медленно без оптимизаций и быстро — с ними.В-третьих, это — половина истории, и иногда шаринг вообще-то бывает и вреден, например, потому что от него получается мусор в памяти, который GC не прибирает вовремя. Вон, смотрите, как люди приседают, чтобы этого не допустить.
И в этом на самом деле сложность — невозможно написать оптимизирующий компилятор для ФП-языка, который будет сам шарить когда надо, а когда не надо — не шарить. Ленивость тут ни при чём, иначе все бы давно делали
{-# LANGUAGE Strict #-}и не знали проблем. Это я ещё в прошлом комментарии хотел написать, но забыл, увы.С тех пор, конечно же, ребята догадались, что мономорфизация/инлайнинг, в общем-то, не сильно хуже, чем dictionary passing, разве только с полиморфной рекурсией не работают
И с конструированием этих словарей в рантайме (через костыли в случае хаскеля, конечно), но не суть. В чём суть — «ребята тогда не догадались, а сейчас догадались» для меня не является ответом на вопрос «нафига так делать», поэтому я и N комментариев назад и писал, что «непонятно».
вопрос "не выведутся ли тут типы, которые превратят этот код в экспоненциальный" внезапно становится крайне важным
Для того, чтобы этот вопрос не был при этом и сложным, достаточно просто указывать типы подобных байндингов. Ну а возвращаясь к нашему исходному вопросу о пригодности х-ля для перекладывания жсонов — как часто при среднем перекладывании этих самых жсонов вам надо делать подобные Фибоначчи, завязывать узлы из двусвязных списков, и заниматься прочими непотребствами, где приходилось бы думать о том, что, когда и как именно будет вычисляться?
BugM
27.11.2022 00:10-2перекладывания жсонов — как часто при среднем перекладывании этих самых жсонов вам надо делать подобные Фибоначчи, завязывать узлы из двусвязных списков, и заниматься прочими непотребствами, где приходилось бы думать о том, что, когда и как именно будет вычисляться
Вообще бывает. Не то чтобы каждый раз, но встречается временами. Бизнес логика довольно веселой бывает. А докинув немного бигдаты и хайлоада в эту бизнес логику вообще весело получается.
Гарантия сложности не хуже логарифма в случаях когда программист явно не написал более медленный алгоритм обязательно нужна. Ловить внезапный и тем более неявный квадрат в проде не хочется. Это ничем не лучше ловли медленно текущей памяти.
Теперь у меня есть хороший аргумент почему Хаскелю не место в проде. Будем и дальше писать на более обычных языках. Где все проблемы производительности довольно очевидны.
0xd34df00d
27.11.2022 00:25+2Не то чтобы каждый раз, но встречается временами. Бизнес логика довольно веселой бывает. А докинув немного бигдаты и хайлоада в эту бизнес логику вообще весело получается.
У вас как-то интересно получается. То люди без развитых когнитивных навыков для возможности понять flatMap пригождаются (и это аргумент против «сложных» языков), то надо писать сложные алгоритмы бигдата хайлоад бизнес-логика (и это снова аргумент против «сложных» языков).
Теперь у меня есть хороший аргумент почему Хаскелю не место в проде. Будем и дальше писать на более обычных языках. Где все проблемы производительности довольно очевидны.
Ну да, не так давно статья про go пробегала, где от замены одного символа она в полтора раза быстрее работать стала. Проблемы довольно очевидны!
Отладкой проблем производительности в плюсах я вообще отчасти зарабатывал себе на жизнь некоторое время. Джава-люди вон тоже себе всё время то бенчмаркают что-то, то GC тюнят. Было бы всё очевидно — наверное, они бы этим не занимались.
BugM
27.11.2022 00:35-1У вас как-то интересно получается. То люди без развитых когнитивных навыков для возможности понять flatMap пригождаются (и это аргумент против «сложных» языков), то надо писать сложные алгоритмы бигдата хайлоад бизнес-логика (и это снова аргумент против «сложных» языков).
Плодить языки в проекте без надобности не надо. Значит большая часть будет на одном языке. А это и простое перекладывание и что-то хитро наверченное рядом. Писать могут разные люди, это да. Проект не без нормальных сеньоров.
Ну да, не так давно статья про go пробегала, где от замены одного символа она в полтора раза быстрее работать стала. Проблемы довольно очевидны!
Отладкой проблем производительности в плюсах я вообще отчасти зарабатывал себе на жизнь некоторое время. Джава-люди вон тоже себе всё время то бенчмаркают что-то, то GC тюнят. Было бы всё очевидно — наверное, они бы этим не занимались.
Все таким занимаются. Я даже знаю пару мест куда готовы нанимать просто на оптимизацию людей. Хоть команду возьмут. На очень неплохие деньги.
Но это оптимизация критического пути или еще чего-то еще очень маленького от общего количества кода. В большей части кода это все не играет роли. Полтора раза от пары миллисекунд в каком-то методе на который нагрузка 1 рпс? Не интересно.
А вот квадраты взрываются во всем коде. Миллион штук пользователи запихнуть во все дырки догадаются. В нет ни одной причины почему это не должно нормально не отработать.
0xd34df00d
27.11.2022 00:40+1Писать могут разные люди, это да. Проект не без нормальных сеньоров.
Ну вот нормальные синьоры нормально и напишут.
А вот квадраты взрываются во всем коде.
Так обсуждаемые вещи вылезают плюс-минус настолько же редко, как критические пути. Примерно на уровне захвата тяжёлого объекта в плюсах в лямбду по значению, а не по ссылке, или чему-нибудь подобному.
BugM
27.11.2022 00:49Ну вот нормальные синьоры нормально и напишут.
Конечно. Но хочется чтобы язык им в этом не мешал.
Так обсуждаемые вещи вылезают плюс-минус настолько же редко, как критические пути. Примерно на уровне захвата тяжёлого объекта в плюсах в лямбду по значению, а не по ссылке, или чему-нибудь подобному.
Проблема в неявности этого. Глядя на код тяжелый объект можно увидеть. Критический путь обычно известен еще на этапе разработки и тестирования. А вот такая подстава от языка/компилятора может прилететь в любой момент в любом месте. Как ее увидеть заранее я пока не понимаю. Прям UB родной.
0xd34df00d
27.11.2022 01:12+1Но хочется чтобы язык им в этом не мешал.
Так он не мешает, он, напротив, помогает. Вы тратите меньше времени на выражение мыслей, на отладку корректности, на прочее, и у вас остаётся больше времени на то, чтобы подумать над задачей, подумать над алгоритмами, и ликвидировать узкие места, причём, в каком угодно смысле — от читаемости и архитектуры до производительности.
Проблема в неявности этого. Глядя на код тяжелый объект можно увидеть.
Ага, когда у вас в лямбде написано
[=] ..., или когда вы используете какую-тоstd::unordered_map, в которой может быть 3 значения, а может быть 300000.Или компилятор может воспользоваться (N)RVO и не копировать строку/вектор/етц при возвращении, а может не воспользоваться и копировать, что даст O(n) вместо O(1).
BugM
27.11.2022 01:30Ага
Убедили. Бывает совсем неочевидно.
В итоге заменяем одни сложно обнаруживаемые проблемы на другие.
От всей функциональщины хочется гарантий, а не вот таких проблем. Гарантия корректности это великолепно. А можно еще гарантию неквадратности при прямых руках разработчика приложить? Ругань при компиляции с каким-нибудь ключиком подойдет.
maeris
27.11.2022 01:43+1Теперь у меня есть хороший аргумент почему Хаскелю не место в проде. Будем и дальше писать на более обычных языках. Где все проблемы производительности довольно очевидны.
Так Х-ь в продакшен тащить без надобности никто и не рекомендует. Посмотрите, где его большие компании используют.
Например, Github на нём сделал Semantic для эдакого IntelliSense, поддерживающего дофига языков. У них есть статейка "зачем хаскелл", в которой на много слов объясняется, что они бы на чём-то другом просто не смогли написать по причине большого количества букв. Гитхаб -- вполне бигдата.
Facebook'у нужно было разгребать тонны спама и прочего модерируемого контента, быстро модифицировать код под очередные хитрости спамеров и не ошибаться. Так нужно, что они автора рантайма Haskell наняли процессом руководить. Каждый пост на фейсбуке тоже звучит вполне как бигдата.
Другое дело, что если посмотреть, какой уровень профессионализма должен быть у людей, которые этим занимаются, сразу становится немного грустно.
maeris
27.11.2022 01:37Для того, чтобы этот вопрос не был при этом и сложным, достаточно просто указывать типы подобных байндингов.
О том же, блин, речь и шла, что вот такие детские грабли положены, и наступать на них ну очень неприятно.
Ну а возвращаясь к нашему исходному вопросу о пригодности х-ля для перекладывания жсонов — как часто при среднем перекладывании этих самых жсонов вам надо делать подобные Фибоначчи, завязывать узлы из двусвязных списков, и заниматься прочими непотребствами, где приходилось бы думать о том, что, когда и как именно будет вычисляться?
Как раз при перекладывании
жсоновAST и наступал. Я лично считаю, что тут очень хорошее место для того, чтобы передизайнить язык.
viordash
24.11.2022 22:38+4:) к вашему рефакторингу теперь комменты нужны. а иначе нужно голову включать что предикат делает
F0iL
24.11.2022 22:40+2Программисту может быть непонятно, что делает 'return n % 2 == 0', серьезно? Я бы понял замешательство, если бы там хотя бы 'return n & 1 == 0' было написано...
BugM
24.11.2022 22:50+4Эта строчка многих читающих код заставит споткнуться на ней и думать что же там происходит. Зачем это надо? Можно же нормально написать. Чтобы человек читающий код не думал, а просто шел дальше.
Я бы на кодревью зарубил с комментарием "Надо переписать понятнее"
viordash
24.11.2022 22:50+3все таки есть разница между
isEvenи каким-либо выражением, независимо от его сложности

adeshere
25.11.2022 02:47+1Согласен, нечитаемо. Зачем отдельно объявлять isEven?
Как представитель племени мамонтов, я бы все-таки предпочел сначала объявить isEven, хотя в нашем заповеднике это требует отдельного танца:
MODULE MyNumericTests ... CONTAINS ... logical elemental function isEven(i) integer, intent(in) :: i isEven=(mod(i,2) == 0) end function isEven ... END MODULE MyNumericTestsДа, многословно... но обычно модуль типа MyNumericTests содержит не одну функцию, а целую кучу, а заодно и структуры данных, с которыми они работают (по сути, это очень похоже на описание класса). И он пишется один раз. Зато в программе будет:
use MyNumericTests integer :: iArray(5)=(/1,2,3,4,5/) ... ... =count(is_even(iarray)) ...О вкусах не спорят, но на мое скромное имхо этот синтаксис и компактнее, и понятнее приведенных выше примеров. Причем даже для тех, кто не знает, на каком языке это написано (надо только иметь самое общее представление о массивных операциях).
Желающие, конечно, могут обойтись и без isEven:
integer :: iArray(5)=(/1,2,3,4,5/) integer :: counter counter=count(mod(iArray,2) == 0)Но с точки зрения фортраниста (который сам когда-то писал GO TO), фразу "вот так гораздо лучше" применительно к этому коду стоило бы все же сопроводить тегом </сарказм>
Для холивара
А чтобы не слишком отклоняться от темы статьи, выскажу еще одно провокационное мнение: если речь идет о простом перемалывании чисел (и только о нем!), то "писать на C++ в 2022 году" действительно незачем ;-) Так как фортран позволяет написать то же самое и настолько же эффективно программисту гораздо более низкой квалификации. Ибо современный фортран явно проще, чем современный же С++. А главное, при одинаковом уровне программиста понятность (читаемость) фортран-программы будет получше за счет массивных операций и более тривиального синтаксиса. Ну и отлаживать фортран явно проще, если только не стрелять себе в ногу умышленно (впрочем, это на любом языке можно сделать ;-).
allcreater
24.11.2022 22:08Рискну предположить, что застряли не в embedded (где вполне можно писать так же, причем еще и практически zero-cost, так как операции над рейнджами очень хорошо инлайнятся и оптимизируются как по производительности, так и размеру исполняемого кода, то, в чем C++ реально хорош и почему все готовы терпеть медленную компиляцию), а в процедурном подходе и старой версии стандарта.
Современный подход, причем не только в C++, а почти во всех языках, подразумевает больший упор в функциональную парадигму: неизменяемые значения, широкое использование функций (в том числе анонимных), в частности в качестве аргументов и возвращаемых значений, отсутствие глобального состояния и декларативность. Привыкнув к этому, можно писать гораздо более надежные и читаемые программы как для микроконтроллеров, так и суперкомпьютеров.
Psychosynthesis
24.11.2022 23:03Отнюдь, в современном JS как раз всё перечисленное (кроме может глобального состояния, но смотря что вы под этим понимаете) вполне привычно.
Однако, из того что вы перечислили "использование функций в качестве аргументов и возвращаемых значений", надежнее (что?) и читаемее код не делает никак.
К этому конечно можно привыкнуть (вопрос практики, разумеется), но это зачем, если на выходе компилятор выдаст ровно то же самое, а времени на понимание кода у среднестатистического разработчика уйдёт больше.
CrashLogger
24.11.2022 23:57-1Что-то мне этот однострочник не кажется более читаемым. Обычный цикл сразу интуитивно понятен, а тут надо глаза и мозг ломать.

ababo
25.11.2022 02:20+6Статья не поднимает один важный вопрос. Зачем начинать новый большой проект на C++, если есть Rust?
maeris
25.11.2022 06:20+2Затем, что новый большой проект на Rust будет компилироваться даже дольше С++, потому что ребята на голубом глазу накоммитили тайпчекер за квадрат от количества определений алгоритмом Робинсона. Именно это, например, не позволило использовать Rust в OpenBSD.
tenzink
25.11.2022 12:24+1Вот это, кстати, очень интересно. Есть ли какие-то исследования насчёт времени сборки? Работал с большими проектами на плюсах и хорошо представляю как это больно
AnthonyMikh
26.11.2022 08:51Там претензия скорее в другом: кто-то предложил "а давайте всё на Rust перепишем!", при этом сам не желая что-либо делать. Ну и ещё у автора текста требование, чтобы компилятор Rust компилировался на i386, что, честно говоря, странное требование.

jakor
25.11.2022 10:27-1я читал coders at work и там говорили, что С++ слишком сложен. А не С/С++. И это писал человек, который каждый день 20 языков использует:-)

k0rsh
25.11.2022 11:48+2Немного отвлеченный вопрос про углеродный след и его снижение. Приведен даже слайд с разницей в 10 раз между платформой на С/С++ и платформой на пхп/питоне/руби. А где оценка углеродного следа во время разработки этой платформы? Видится мне, что по энергозатратам на разработку сравнение будет не в пользу С++.
DinoZavr3
25.11.2022 13:55-2Вообще, на с++ писать не очень то и удобно. Рекомендую С#, это будет пожалуй получше чем С++. Кстати, можно и JavaScript компилировать в С# и использовать. 1 строка в js = 20 строк в С++
beeptec
25.11.2022 15:18+1Тема больше из области споров толщины библии, корана, торы, и т.д. на разных языках, что по сути не отменяет то, что выше этого, а так же конечные цели и то, что способствует и продвигает источник в массы. Кодеры разных языков подобны служителям храма своей религии и яростно отстаивают ее перед вероотступничеством и палят, предают анафеме, вешают ярлыки вероотступничества... Но бога ради, скажет ли мне 1 из всех кодеров, что самое важное в софтах, как мы умеем в скрипте донести к желу или в управлении данными, то, что нужно покупателю - цена, сроки, минимум рекламаций, большой жизненный цикл без проприетарных зависимостей.

GarryC
26.11.2022 13:48Старая фраза : Все языки делятся на две группы - одну все ругают, на второй никто не работает.

svcoder
27.11.2022 08:52+1На мой взгляд, главная проблема C++ в том, что сделав его суперуниверсальным, его создатели не подумали о том, что часть этой универсальности стоило ограничить. В итоге получилось, что на каждую возможность стало появляться огромное количество антипаттернов. Язык накопил огромный технический долг, который сначала решался энтузиастами и потом через долгое время становился частью стандарта.
Вторая проблема, то что язык так и не оброс нормальными кросс-платформенными библиотеками, например для работы с сетью, БД или десктопом. Разрабатывая на C++ под винду и перейдя на линукс можно испытать огромную боль и гнев. В этом смысле С++ очень привязывает разраюотчика к компании. Мысли о смене работы улетучиваются, когда представляешь сколько всего предстоит сделать, изменить или изучить, чтобы создать для себя комфортные условия для работы на новом месте.
Racheengel
Как язык C++ довольно ужасен и неоднозначен. И с точки зрения концепций, и с точки зрения синтаксиса, и с точки зрения инфраструктуры.
Новые стандарты его, к сожалению, особо лучше не делают. Нет, конечно, и хорошие вещи приходят, но часто это "OMG WTF"?
Но это практически единственный ОО-язык высокого уровня, на котором можно напрямую общаться с железом, писать сервера, игры, да и вообще всё подряд, используя ресурсы машины по максимуму. Так что хоронить дедушку рано.
Lebets_VI
Вы забыли поставить запятую после "Как язык".
Что касается "ужасен и неоднозначен", Вы хотите начать "священную войну" ? :)
Но, ... Вы сами ответили на данный вопрос. Да, "единственный ОО-язык высокого уровня, на котором можно напрямую общаться с железом...".
GospodinKolhoznik
Objective-c, например.
Lebets_VI
Отстой
Kelbon
Какие конкретно концепции С++ вам не нравятся? Время показывает, что они крайне хороши.
Претензия по синтаксису тоже непонятна
> Но это практически единственный ОО-язык высокого уровня,
С++ это не ооп язык
allcreater
Мультипарадигменный, как и большинство современных языков. Да, в идиоматическом C++ писать в чисто ООП стиле не принято и не особо-то эффективно, но формально C++ вполне себе ООП, равно как и процедурный, структурный, функциональный язык.
0xd34df00d
Не нравится концепция UB и, как следствие, невозможность писать код, которому можно доверять.
CrashLogger
Так пишите код, в котором нет UB. Оно проявляется в таких конструкциях, за которые и так бы по рукам надавали.
0xd34df00d
Я бы с радостью, но вот что-то не получалось, по крайней мере, малой кровью. И у моих коллег не получалось. И у людей из гугла не получается. И у людей, пишущих ядро линукса, openssl и так далее, тоже не получается.
vanxant
Писать на плюсах код без UB очень легко! Но ровно до тех пор, пока не вляпаешься в своё первое UB на продакшене (в дебажном билде они обычно не случаются)
yatanai
Когда я с 0 учил язык, он выглядел просто как очередной язык программирования, просто с более строгой структурой описания алгоритмов. Но когда в конце циклов статей осталась последняя глава "шаблоны и STL"... Я перестал мыслить как нормальный человек. Ты буквально делаешь компилятор в компиляторе, где остановит тебя только фантазия, а твой код всегда заботливо оптимизирует компилятор))
Ps Делал свойства как в С#. Делал запись типа int x = classT.at[4] валидной, где classT { void* ptr; };