
Можно писать запросы на уровне абстракций, не вникая в процесс оптимизации, а можно осознанно, понимая алгоритмы соединения сущностей. Каждый разработчик сталкивался с тем, что его запросы не выполняются, но не каждый глубоко погружается в проблемы «тяжелых» запросов.
Оптимизация — это тонкая работа с каждой конкретной СУБД, иначе не существовало бы множество методов для оптимизации. Моя заметка подразумевает некоторый уровень в понимании архитектуры запросов. Она для разработчиков, которые уже сталкивались с подобными задачами.
СУБД TERADATA проектировалась как MPP система и хорошо работает с большими таблицами >> 1 Тб.
Напомню, что аппаратное обеспечение, поддерживающее программное обеспечение базы данных TERADATA, основано на технологии симметричной многопроцессорной обработки (SMP). Аппаратное обеспечение может быть объединено с коммуникационной сетью, которая соединяет системы SMP для формирования систем массовой параллельной обработки (MPP). Компоненты аппаратных платформ SMP и MPP включают следующее
Компонент |
Описание |
Функция |
Processor Node |
Аппаратная сборка, содержащая несколько тесно связанных центральных процессоров (ЦП) в конфигурации SMP. Узел SMP подключён к одному или нескольким дисковым массивам со следующими, установленными на узле: · Программное обеспечение базы данных TERADATA · Программное обеспечение клиентского интерфейса · Операционная система · Несколько процессоров с общей памятью · Отказоустойчивое питание Конфигурация MPP — это конфигурация из двух или более слабо связанных узлов SMP. |
Служит аппаратной платформой, на которой работает программное обеспечение базы данных. |
BYNET |
Аппаратная межпроцессорная сеть для связи узлов в системе MPP. Одноузловые системы SMP используют программно настроенный виртуальный драйвер BYNET для реализации служб BYNET. |
Реализует широковещательную, многоадресную или двухточечную связь между процессорами в зависимости от ситуации. |
Эти платформы используют виртуальные процессоры (vprocs), которые также называют процессорами модуля доступа (AMP). Они запускают набор программных процессов на узле под Parallel Database Extensions (PDE)

TERADATA распределяет строки данных для каждой таблицы по узлам и всякий раз, когда необходимо прочитать таблицу, TERADATA должна прочитать части таблицы, хранящиеся на разных узлах. Если узлов много, и каждый узел имеет одинаковое количество строк, то параллельная обработка работает лучше всего.
Эта параллельная обработка начинается с первичного индекса (PI).
Первичный индекс (PI) играет три важные роли:
Распределение данных по узлам;
Именно первичный ключ (а точнее специальная функция от него однозначно определяет тот узел, на котором будет храниться соответствующая строка данных, и благодаря правильно выбранному первичному ключу достигается равномерное распределение данных по узлам
Получение данных максимально быстрым способом;
При размещении данных по узлам в соответствии со значением первичного ключа данные еще и сортируются. Если в запросе в условии отбора данных требуется найти сроку по первичному ключу, то это будет происходить максимально быстро.
Соединение таблиц в запросах.
Соединение данных двух таблиц по их первичным ключам тоже будет осуществляться быстро по причине того, что все данные в соединении будут находиться на одних и тех же узлах и перемещение данных будет минимально.
Характеристики первичного индекса:
PI в таблице будет определять, на каком AMP будет храниться строка. PI заполненной таблицы нельзя изменить, но можно изменить для пустой таблицы.
В качестве PI для таблицы можно добавить не более 64 столбцов.
PI не является первичным ключом и допускает NULL.
В таблице можно определить только один PI.
Существует два типа первичных индексов:
Уникальный первичный индекс (UPI)
Неуникальный первичный индекс (NUPI
Уникальный первичный индекс (UPI) означает, что значения для выбранного столбца должны быть уникальными.
UPI всегда будет хранить строки таблицы равномерно между AMP.
Доступ к UPI всегда является операцией с одним AMP.

NUPI означает, что значение для выбранного столбца может быть НЕУНИКАЛЬНЫМ. Повторяющиеся значения могут существовать. NUPI почти никогда не распределяет строки таблицы равномерно.
Операция полного перебора данных в таблице займёт больше времени, если данные распределены неравномерно, но вы можете выбрать NUPI вместо UPI, потому что столбцы NUPI могут быть более эффективными для доступа к запросам и соединений.

TERADATA также использует для организации данных вторичные индексы (SI), которые необязательны для таблиц, но они часто могут повысить производительность системы.
Создание вторичного индекса приводит к тому, что база данных TERADATA создаёт отдельную внутреннюю подтаблицу, содержащую строки индекса, тем самым добавляя ещё один набор строк, который требует обновления каждый раз, когда строка таблицы вставляется, удаляется или обновляется.
")
")
В TERADATA также используются партиции, которые задают дополнительный уровень секционирования данных на узлах. Такое секционирование данных позволяет производить более быструю выборку данных по диапазонам, которые участвуют в секционировании данных.

Для быстрой обработки большого массива данных в параллельном режиме в TERADATA нужно таким образом определить необходимые первичные ключи индексы и патриций, чтобы данные распределились по узлам максимально равномерно и с точки зрения предполагаемых запросов обрабатывались максимально параллельным образом.
Скорость выполнения запросов в Teradata напрямую связано с наличием и качеством статистик на таблицы, которые участвуют в запросе. Попытаюсь объяснить, что представляют собой статистики и для чего они нужны TERADATA.
Статистики — это интервальные гистограммы распределения данных, и они показывают, как данные в среднем распределяются по узлам.
Оптимизатор также использует данные счётчика UDI из DBC.ObjectUsage для оценки количества элементов.
Напомним, что основная информация, хранящаяся в стандартном интервале равной высоты, выглядит следующим образом:
Максимальное значение в интервале.
Наиболее часто встречающееся значение в интервале (записывается как модальное значение интервала).
Мощность наиболее часто встречающегося значения в интервале (записывается как модальная частота для интервала).
Количество различных значений в интервале, определенное при сканировании всей таблицы.
Мощность значений в интервале не равна наиболее частому значению (это число является постоянным для интервалов, когда используются интервалы равной высоты).
Его величина рассчитывается следующим образом:

Количество строк, не содержащих наиболее часто встречающееся значение в интервале (записывается как покадровая частота для интервала).
Я приведу несколько примеров как работают статистики для простых запросов.
Данные, использованные для примеров, сведены в следующую таблицу. Обратите внимание, что общее количество различных значений (заштрихованные ячейки таблицы) одинаково для всех пяти интервалов. Теоретически это является определяющим для гистограмм интервалов равной высоты.
Надо учесть, что как правило данные распределены по частотам не так равномерно, как в представленном примере
Для упрощения примеров интервалы истории не показаны.
Переменная |
Номер интервала |
||||
1 |
2 |
3 |
4 |
5 |
|
Экземпляры наиболее часто встречающегося значения в интервале |
16 |
36 |
39 |
60 |
67 |
Количество значений, не равных наиболее часто встречающемуся значению в интервале |
10 |
10 |
10 |
10 |
10 |
Количество различных значений в интервале |
11 |
11 |
11 |
11 |
11 |
Количество строк в интервале с наиболее частым значением |
50 |
70 |
20 |
30 |
50 |
Количество строк в интервале, не имеющих наиболее часто встречающегося значения |
200 |
150 |
250 |
100 |
200 |
Количество строк в интервале |
250 |
220 |
270 |
130 |
250 |
Максимальное значение в интервале |
25 |
37 |
50 |
63 |
76 |
Следующие изображение иллюстрирует эти числа графически. Заштрихованная область представляет количество строк для других значений в интервале. Некоторые значения имеют надстрочные пояснительные примечания, которые определены в таблице после иллюстрации.

№ |
Описание |
1 |
Количество строк, которые имеют наиболее частое значение в интервале в качестве значения для столбца или индекса |
2 |
Наиболее часто встречающееся значение для столбца или индекса в интервале |
3 |
Количество строк, которые не имеют наиболее часто встречающееся значение в интервале в качестве значения для столбца или индекса |
4 |
Количество уникальных значений в интервале, которые не равны наиболее часто встречающемуся значению для столбца или индекса |
5 |
Максимальное значение в интервале |
Если количество элементов, полученных для этого простого запроса, не нужно оценивать, поскольку статистика по набору столбцов актуальна, то оптимизатор точно знает это количество элементов. В таблице есть 30 экземпляров значения 60. Это значение известно, потому что оно является подсчётом количества строк в интервале, имеющих наиболее часто встречающееся значение, 60, для столбца, указанного в условии.

Этот пример иллюстрирует простое условие равенства.
Если есть какие-либо строки, удовлетворяющие условию, в котором значение именованного столбца равно 55, они находятся в диапазоне между 51, нижней границей интервала и его верхней границей 63.

Оптимизатор знает об этом условии следующее:
Это равенство.
Равенство распространяется на один интервал.
Наиболее часто встречающееся значение в интервале не определяет его строки для включения в набор ответов.
Оптимизатор должен оценить существенность набора ответов для этого примера, потому что в отличие от предыдущего примера, здесь нет точных статистических данных для его описания. Эвристика, используемая для оценки мощности набора ответов, состоит в делении количества строк в интервале, не имеющих наиболее часто встречающегося значения, на количество значений в интервале, не равное наиболее частому значению.

Если статистика актуальная, то в этом интервале есть 100 строк, не имеющих значения 30 для столбца, заданного условием, и есть 10 значений, не равных наиболее часто встречающемуся значению в интервале. Оптимизатор делит количество строк в интервале, не имеющих значения 30, на количество значений в интервале, не равное максимальному значению, равному 10. Мощность набора ответов оценивается как 10 строк.

Пусть в качестве условия отбора данных выбирается некий диапазон их возможных значений,
Методы статистической гистограммы являются особенно мощным средством для оценки мощностей наборов ответов на запрос диапазона.

Оптимизатор знает, что количество строк, имеющих значение столбца условия от 51 до 57, должно быть найдено в одном интервале, ограниченном значениями 51 и 63.
Ключевое слово BETWEEN является сокращением SQL для значения ≥ нижний предел и ≤ верхний предел, поэтому оно означает условие неравенства.
Оптимизатор знает об этом условии следующее:
Это неравенство.
Неравенство распространяется на один интервал.
Наиболее часто встречающееся значение в интервале не определяет его строки для включения в набор ответов.
Оптимизатор должен оценить количество элементов набора ответов для этого примера, потому что нет точных статистических данных для его описания. Эвристика, используемая для оценки мощности набора ответов, состоит в том, чтобы разделить количество строк, не имеющих наиболее часто встречающегося значения в интервале, пополам.

Предполагая текущую статистику, в интервале есть 100 строк, которые не имеют значения 30 для столбца, заданного условием, поэтому Оптимизатор делит количество строк, не имеющих значения 60, что равно 100, пополам.

Мощность набора ответов оценивается в 50 строк.
Этот пример несколько сложнее предыдущего, поскольку в нем указывается предикат диапазона, включающий наиболее часто встречающееся значение в интервале

Оптимизатор знает, что количество строк, имеющих значение столбца условия от 51 до 60, должно быть найдено в одном интервале, ограниченном значениями 51 и 63.
Оптимизатор знает об этом условии следующее:
Условие представляет собой неравенство.
Неравенство распространяется на один интервал.
Наиболее часто встречающееся значение в интервале определяет его строки для включения в набор ответов.
Оптимизатор должен оценить количество уникальных записей в наборе ответов для этого примера, потому что для его описания имеются только частичные точные статистические данные. Эвристика, используемая для оценки мощности набора ответов, состоит в том, чтобы разделить количество строк, не имеющих наиболее часто встречающегося значения в интервале, пополам, а затем добавить это число к количеству строк в интервале, имеющих наиболее частое значение.
Поскольку это количество точно известно, если статистика актуальна, расчетное количество уникальных значений в наборе ответов должно быть более точным, чем в предыдущем примере.
В интервале есть 100 строк, которые не имеют значения 30 для столбца, заданного условием, поэтому оптимизатор делит количество строк, не имеющих значения 60, то есть 100, пополам, а затем добавляет 30 строк, о которых известно, что они существуют, где условие = 60.

Этот пример представляет собой немного более сложный запрос диапазона, чем предыдущий, поскольку набор ответов охватывает 2 интервала гистограммы.

Оптимизатор знает, что количество строк, имеющих значение столбца условия от 45 до 55, должно быть найдено в двух соседних интервалах, ограниченных значениями 38 и 63.
Оптимизатор знает об этом условии следующее:
Это неравенство.
Неравенство простирается на 2 интервала.
Наиболее часто встречающееся значение ни в одном из интервалов не определяет его строки для включения в набор ответов.
Оптимизатор должен оценить количество элементов набора ответов для этого примера, потому что нет точных статистических данных для его описания. Эвристика состоит в том, чтобы оценить количество уникальных значений набора ответов для каждого интервала отдельно, разделив количество строк, не имеющих наиболее часто встречающихся значений в интервале, на половину, а затем суммировав эти два количества.
В нижнем интервале есть 250 строк, которые не имеют значения 20 для столбца, заданного условием, поэтому оптимизатор делит количество строк, не имеющих значения 20, то есть 250, пополам, получая оценку в 125 строк, удовлетворяющие условию для этого интервала.
В более высоком интервале есть 100 строк, которые не имеют значения 30 для столбца, заданного условием, поэтому оптимизатор делит количество строк, не имеющих значения 60, что равно 100, пополам, получая оценку в 50 строк, удовлетворяющих условие для этого интервала.
Общая оценка получается путём сложения оценок для каждого из двух интервалов.

В последнем примере указывается диапазонный запрос, который охватывает три интервала и включает наиболее часто встречающееся значение в среднем интервале.

Оптимизатор знает, что количество строк, имеющих значение столбца условия от 45 до 50, должно находиться в интервале, ограниченном значениями 38 и 50.
Оптимизатор также знает, что все строки в следующем более высоком интервале, который ограничен значениями 51 и 63, включены в набор ответов. Оценка вычисляется путём суммирования количества строк со значениями, которые не встречаются чаще всего в интервале с количеством строк, имеющих наиболее часто встречающееся значение, или 100 + 30. Если статистика актуальна, это значение является точным.
Количество строк, имеющих значения столбца условия в диапазоне от 64 до 65, должно быть оценено с использованием половины числа значений, которые не являются наиболее часто встречающимися в интервале. Оценка составляет половину от 200 или 100 строк.
Оптимизатор знает об этом условии следующее:
Это неравенство.
Неравенство охватывает три интервала.
Наиболее часто встречающиеся значения в самом низком и самом высоком интервалах не определяют их строки для включения в набор ответов.
Наиболее часто встречающееся значение в среднем интервале действительно определяет его строки для включения в набор ответов.
Оптимизатор должен оценить количество уникальных количества в наборе ответов для этого примера, потому что для его описания имеются только частичные точные статистические данные. Эвристика, используемая для оценки размера набора ответов, приведена в следующем списке:
1. Оценить объем набора ответов, возвращённого из первого интервала, разделив количество строк, не имеющих наиболее часто встречающегося значения, пополам.
2. Посчитать количество строк, имеющих наиболее частое значение, из второго интервала.
3. Посчитать количество строк, не имеющих наиболее часто встречающегося значения, из второго интервала.
4. Оценить объем результатов, возвращённого из третьего интервала, разделив количество строк, не имеющих наиболее часто встречающегося значения, пополам.
5. Сложить числа, полученные на этапах с 1 по 4, чтобы получить общую оценку объема набора ответов.
Общая оценка получается путём сложения оценок для каждого из трех интервалов: 125 + 130 + 100, или 355 строк.

Обратите внимание, что все эти примеры предназначены только для демонстрации того, как интервальные гистограммы используются в оптимизации запросов. Они не учитывают методы, используемые производной статистикой и подсчётами UDI, чтобы сделать оценки количества уникальных значений ещё более точными.
Надо также понимать, что сбор статистик — это ресурсоёмкая операция. Так как TERADATA для сбора статистик выполняет отдельный запрос с агрегацией данных и чем больше таких данных, тем дольше будет выполняться такой запрос.
Поэтому для случаев, когда нужно собрать статистику по большому объёму данных, TERADATA предлагает возможность собирать не всю статистику, а статистику по некоторому, заданному проценту исходных данных, которые отбираются или случайным образом из всей в таблицы или берутся первые N записей, полученных в запросе. Потом по отобранным данным формируются необходимые агрегаты.
Такая статистика называется семплированной и отбирается командой:
COLLECT STATISTICS USING SAMPLE N PERCENTПри использовании семплированных статистик, надо иметь в виду, что их гистограммы будут лучше соответствовать гистограммам распределения всех данных, чем больше семпл будет репрезентативен. И как правило такие данные должны быть достаточно однородными как по своей структуре и распределению их по узлам, так и по динамике их наполнения/изменения.
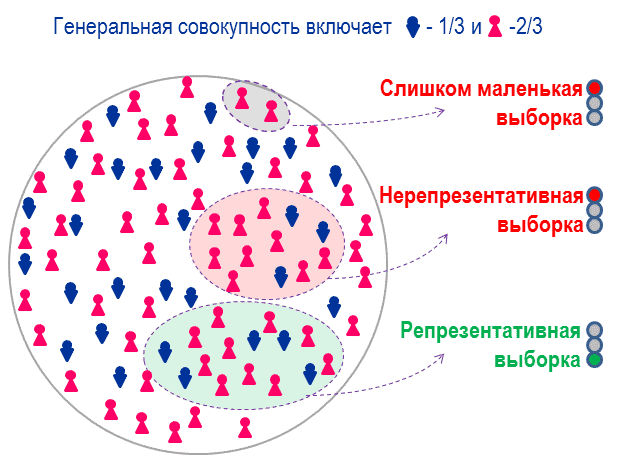
Не все статистики являются одинаково полезны. И при выполнении запроса, будет ли TERADATA использовать статистики зависит от особенностей построения запроса:
Как соединяются между собой таблицы — различные виды join-ов (INNER JOIN, LEFT/RIGHT/FULL OUTER JOIN, CROSS JOIN), если условие соединения таблиц неуникально.
Какие ограничения на данные задаются в разделе where (по неиндексированным атрибутам)
Какие агрегатные и аналитические функции используются - group by, qualify, distinct, sum, count…
Также рекомендую собирать статистики по колонке PARTITION всех таблиц в запросе независимо от того, секционированы они или нет.
Так как целью сбора статистики является вычисление статистических данных, которые TERADATA использует для оптимизации доступа к таблицам и планов соединения рамках выполняемого запроса, то в зависимости от построенного плана запроса оптимизатору может понадобиться тот или иной определенный набор статистик. Это может приводить к тому, что некоторые статистики, которые могли использоваться раньше, после изменения запроса и как следствие его плана будут больше не нужны.
Такие статистики можно удалить командой:
DROP STATISTICS…Если в запросах используются сложные связи между таблиц или ограничения на данные, то более эффективными будут не статистики, собираемые на отдельные атрибуты, а статистики, показывающие одновременное распределение двух и более атрибутов.
Так, статистика, полученная для столбца_1 и столбца_2 при совместном сборе, отличается от статистики, полученной при отдельном сборе статистики по тем же столбцам. Например, предположим, что у вас есть два столбца с именами FirstName и LastName. В частности, статистика, собранная для FirstName, сама по себе даёт оценку количества лиц, носящих имя John, например, а статистика, собранная для LastName, даёт оценку количества лиц, носящих фамилию Smith.
Эти статистические данные могут не дать хороших оценок количества людей по имени John Smith. Для этого нужно собрать статистику по двум столбцам совместно. Этот пример приведён только для того, чтобы чётко разграничить сбор статистики по отдельным столбцам и сбор статистики по тем же столбцам вместе.
Иногда, когда в условиях участвуют не сами атрибуты, а результаты некоторых математических или текстовых преобразований с этими атрибутами, то эффективнее собирать статистику не на сами атрибуты, а на используемые в запросе трансформации этих атрибутов, и в этом случае статистики будут именные.
Если при построении плана запроса используется директива:
DIAGNOSTIC HELPSTATS ON FOR SESSION;То помимо самого плана запроса TERADATA выведет рекомендации по сбору необходимых статистик.
diagnostic helpstats on for session;
explain select * from customer where customerid in
( select customerid from sales );
begin recommended stats for this relation->
-- "collect statistics column (customerid) on dwhpro.customer"
(high confidence)
-- "collect statistics column ( customerid ) on dwhpro. sales"
(medium confidence)
<-end recommended stats
Эти статистики TERADATA распределяет по двум уровням High Confidence или Medium Confidence. И особое внимание надо обратить на те рекомендуемые TERADATA статистикам, которые имеют уровень High Confidence.
Все свои рекомендации TERADATA строит на основании сформированного плана запроса и существующих на среде (где выполняется запрос) статистик.
Это может приводить к недоразумениям, если дистрибуция данных и наборы статистик на разных стендах участвующих в DEVOPS процессе различаются.
Также стоит обратить внимание на тот факт, что TERADATA актуализирует статистики только по прямому запросу пользователя командой:
COLLECT STATISTICS…И даже в этом случае TERADATA сначала проверит актуальность имеющейся статистики в соответствии с некоторыми преднастроенными критериями:
Срок прошедший с последнего сбора статистик.
Процент изменения в данных по сравнению с последним сбором статистик.
И только в случае, если TERADATA определит статистику как протухшую, произойдёт её повторный сбор, иначе команда COLLECT STATISTICS… будет проигнорирована.
В случае отсутствия необходимых статистик на атрибуты для определения демографии данных и как следствие построения оптимального плана запроса в TERADATA предусмотрен механизм «Dynamic AMP samples». Этот механизм позволяет автоматически собирать семплы на индексные атрибуты участвующие в запросе при выполнении этого запроса. Правда при этом формируется только несколько ключевых статистик.
Ограничение на определение некоторых основных показателей необходимо, поскольку эти агрегаты должны быть созданы во время создания плана выполнения (т. е. быстро), если они ещё не доступны.
По умолчанию динамическая выборка выполняется на одном, случайно выбранном узле. Это поведение можно изменить и собирать динамический семплы на 2, 5 или на всех узлах. Для этого необходимо внести изменения в системные настройки.
Не путайте статистическую и динамическую статистики, которые собирает TERADATA, когда у него нет статистики, на которой можно построить план запроса. Статистические выборки, взятые по всем узлам, вероятно, будут намного точнее, чем динамические выборки AMP.
В следующей таблице описаны некоторые различия между двумя методами сбора статистики:
COLLECT STATISTICS USING SAMPLE |
Dynamic AMP samples |
|
Собирает статистику по небольшой выборке строк со всех узлов. Если столбцы не проиндексированы, то строки располагаются случайным образом на каждом узле, поэтому база данных TERADATA просто сканирует первые n процентов строк, которые она находит, где значение n определяется относительным наличием или отсутствием перекоса в данных. Можно предположить, что вся выборка может быть взята из первого блока данных на каждом узле, в зависимости от конфигурации системы и мощности таблицы, из которой производится выборка. Если столбцы проиндексированы, то выполняется более сложная выборка, чтобы воспользоваться преимуществом упорядочения строк с хэш-последовательностью. |
Собирает статистику по небольшой выборке строк из одного узла. Это системное значение по умолчанию. Вы можете изменить количество узлов, из которых берётся динамическая выборка узлов, изменив значение внутреннего поля управления DBS. За подробностями обратитесь к представителю центра поддержки TERADATA. |
Собирает полную статистику и сохраняет её в интервальных гистограммах в DBC.StatsTblStatsTbl. |
Собирает оценки количества различных значений индекса и некоторых других статистических данных и сохраняет их в дескрипторе блока данных. Также собирает и сохраняет оценки уникальности данных на отдельных узлах и на всех узлах в интервальных гистограммах в DBC.StatsTblStatsTbl. |
Динамически расширяет размер выборки, чтобы компенсировать перекос. |
Чувствителен к перекосу. |
Даёт достаточно точные оценки всех статистических параметров. |
Предоставляет довольно точные оценки базовой таблицы и количества уникальных значений NUSI, если выполняются следующие условия. · Объем данных большой · Распределение значений не перекошено · Данные взяты не из нетипичного образца Другие стандартные статистические параметры менее точны. |
При анализе плана запроса обращайте внимание на то, сколько записей TERADATA планирует получить на каждом его шаге. Если эти цифры радикально отличаются от реального количества данных, то вероятно TERADATA имеет неточную информацию о количестве и демографии данных в запросе. И эту ситуацию лучше всего может исправить сбор всех необходимых статистик.
Explain
sel * from sandbox.comapny_employees ce
left join
sandbox.comapny_age ca
on ce.age=ca.age and ce.age>41) First, we lock sandbox.ca for read on a reserved RowHash to
prevent global deadlock.
2) Next, we lock sandbox.ce for read on a reserved RowHash to prevent
global deadlock.
3) We lock sandbox.ca for read, and we lock sandbox.ce for read.
4) We do an all-AMPs RETRIEVE step from sandbox.ce by way of an
all-rows scan with no residual conditions into Spool 2 (all_amps),
which is redistributed by the hash code of (sandbox.ce.age) to all
AMPs. Then we do a SORT to order Spool 2 by row hash. The size
of Spool 2 is estimated with high confidence to be 3 rows (81
bytes). The estimated time for this step is 0.01 seconds.
5) We do an all-AMPs JOIN step from sandbox.ca by way of a RowHash
match scan with a condition of ("sandbox.ca.age >= 43"), which is
joined to Spool 2 (Last Use) by way of a RowHash match scan.
sandbox.ca and Spool 2 are right outer joined using a merge join,
with condition(s) used for non-matching on right table ("age >= 43"),
with a join condition of ("age = sandbox.ca.age"). The result
goes into Spool 1 (group_amps), which is built locally on the AMPs.
The size of Spool 1 is estimated with low confidence to be 4 rows
(176 bytes). The estimated time for this step is 0.02 seconds.
6) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
-> The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.
Проверить статистики на таблицу можно командой
SHOW STATS ON <table_name>и
HELP STATS ON <table_name>Практика показывает, что грамотный сбор статистик позволяет сократить время выполнения некоторых запросов с нескольких часов до нескольких минут или даже секунд.
Такая, иногда недооценённая вещь как правильно построенный сбор статистик может кардинальном образом повысить скорость выполнения запросов и как следствие скорость расчетов, не требуя трудозатрат на переписывание кода запросов и затрат на повышение производительности работы аппаратных средств.
Автор статьи: Сергей Анисимов.