
С распространением практики доставки непрерывных обновлений время сборки приложений стало критически важным параметром как для разработчиков, так и для бизнеса компании в целом. В данной статье описан мой опыт ускорения Frontend пайплайна Jenkins в Kubernetes на базе yarn и nx
Disclaimer В данной статье делается упор на один из вариантов ускорения сборки UI без описания причин выбранной инфраструктуры, а также без детального описания настройки всей сборки
Что у нас есть?
Для сборки всех приложений (ui, backend) используется Jenkins, развернутый внутри Kubernetes кластера (данный подход позволяет лучше утилизировать используемые ресурсы). Таким образом каждая сборка стартует в индивидуальном поде внутри одного или нескольких контейнерах.
В день на конкретно нашем Jenkins может проходить до 5000 сборок. Не так уж и много если бы не одно но - некоторые сборки занимают непропорционально много времени.
На Frontend сборки приходится 1/20 часть ~ 250 в день. Средняя продолжительность сборки ~ 26 минут, однако до четверти из них может занимать больше часа.
Практически все ресурсы UI у нас находятся в одном репозитории (monorepo), а те что не находятся, активно туда подтягиваются
Все необходимые шаги сборки запускаются с помощью yarn и nx
Проблема
Чертовски медленная сборка Frontend для большой части пайплайнов, которая продолжает замедляться по мере добавления новых модулей в monorepo.
Пример полной пересборки проекта с прогоном всех тестов и проверок (некоторая часть шагов опущена ввиду нерепрезентативности)
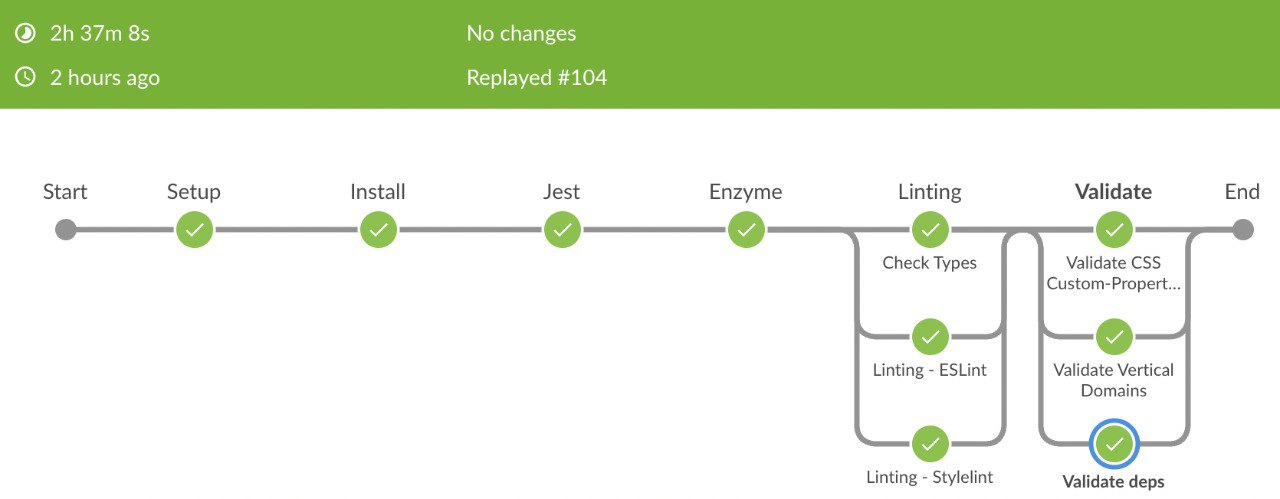
Попытка № 1
Из описания проблемы самым очевидным решением является распараллеливание сборки. Распараллеливание может быть как на уровне сборщика nx и yarn внутри контейнера, так и на уровне модулей параллельно собирающихся в разных контейнерах, но по-прежнему в том же поде. Первый способ уже был настроен и использовался при сборке.
Пример одного из шагов сборки:
yarn nx affected --target='test' --parallel=2 --nx-bail --runInBandВторой же способ не принесет ожидаемого результата, так как почти бессмысленно запускать сборки в разных контейнерах того же пода, если можно все распараллелить в одном контейнере, т.к. все контейнеры запускаются на одной и той же машине.
Отсюда следует решение, что вся сборка должна иметь возможность быть максимальна распределена по разным машинам, в случае с Kubernetes - подам. Благо nx позволяет легко получить список affected модулей:
yarn nx print-affected --target='test'чтобы потом легко раскидать их по подам:
yarn nx run-many --target=test --projects=${projects}При переходе к такому подходу необходимо учитывать, что мы теряем преимущества использования общего локального кэша, так как сборка будет разнесена по различным машинам. Для того, чтобы не терять данную возможность необходимо предусмотреть использование общего хранилища между подами. В случае с Kubernetes это может быть persistent volume, поддерживающий режим использования ReadWriteMany или же использование third-party хранилища по аналогии с Nx Cloud (рассматривались хранилища поддерживающие s3 api). В данном случае провайдером инфраструктуры выступал AWS, поэтому в качестве поставщика для shared volume подов был выбран EFS. EFS поддерживает протокол NFS. При использовании сетевых файловых систем необходимо помнить что наилучшая производительность достигается при записи больших файлов.
После распараллеливания сборки по подам и использования shared volume на EFS время сборки … увеличилось (yarn install стал занимать 37 минут вместо 2-3)

Почему? Ответ находится чуть выше - а именно, низкая производительность сетевой файловой системы (EFS) при записи маленьких файлов, которые хранятся в кэше nx и node_modules. Первой идеей решения данной проблемы было включение Provisioned Throughput режима для EFS c тарификацией по выделенным мегабайтам. Однако данное решение обладало 2 существенными недостатками: предварительный счет за необходимый throughput впечатлял (в нашем случае сборки запускаются достаточно часто и практически без перерыва); даже отбросив материальный аспект мы уперлись в лимиты EFS (по запросу AWS может их увеличить). Совокупность данных факторов сделало использование EFS безумным, особенно учитывая то, что объем используемого дискового пространства весьма небольшой (~ 10 Гб).
Попытка № 2
Принимая во внимание невозможность использования EFS. а также просчитав цену использования s3 для хранения и чтения (в данном случае цена базируется на занимаемом место и количестве запросов; в нашем случае данный подход оказался существенно дешевле подхода с EFS) было принято решение отказаться от стратегии кэширования для сборки. Т.е. каждый раз при старте нового пода требовалось вызывать команду yarn install, которая загружала все зависимости из внешнего мира. В итоге без использования общего кэша в EFS сборка была намного быстрее, но зависимости загружались из вне в каждом новом поде, что вызывало определенный дискомфорт
Попытка № 3 и итоговое решение
Казалось бы, что задача выполнена и сборка ускорена, однако невозможность использования общего кэша не давала мне покоя, так как скачивание и пересборка одних и тех же библиотек внутри каждого пода отнимали время и впустую использовали внешний траффик. На этом моменте снова вспомнился не бесплатный aws s3 в который можно было бы складывать кэш и в каждом новом поде его доставать. В целях экономии трафика я даже стал рассматривать использование minio внутри kubernetes кластера конкретно для этой задачи. При использовании minio мы бы смогли использовать s3 api и не платить за входящий/исходящий трафик, так как он бы циркулировал внутри кластера (но никто не отменял оплату дополнительных ресурсов необходимых для minio). Оценивая преимущества/недостатки использования minio, меня посетила идея: “А что если просто копировать кэш с одного пода на другой во время его старта?”. Jenkins всегда запускает так называемый базовый под для всей сборки и по мере необходимости, для распараллеливания, создает дополнительные поды. Потенциальным бутылочным горлышком данного решения могла оказаться пропускная способность сети kubernetes кластера при копировании файлов, однако, мы запускали Frontend пайплайны в отдельной Instance Group, пропускная способность которой имела хороший запас. Данная концепция выглядит следующим образом:

В данном случае у нас есть parent-pod, на котором выполняется
клонирование репозитория -
git cloneпервоначальная сборка -
yarn installсоздание снэпшота сборки -
tar --exclude=".git" -czf \$CACHE_DIR/project.tar.gz ./
Внутри этого пода запущен nginx-контейнер, выполняющий роль файлового сервера.
Пример декларативного описания parent pod'a:
apiVersion: v1
kind: Pod
metadata:
labels:
scheduled_by: jenkins
build_number: ${env.BUILD_NUMBER}
repo_name: $repo_label
branch_name: $branch_label
spec:
nodeSelector:
instancegroup: frontend
containers:
- name: yarn
image: jenkins-node-lts:lts-16.13.0
imagePullPolicy: Always
resources:
requests:
memory: "4Gi"
limits:
memory: "4Gi"
command:
- /bin/sh
- -c
args:
- cat
tty: true
env:
- name: CACHE_DIR
value: "/usr/share/nginx/html"
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: cache-static
mountPath: /usr/share/nginx/html
- name: static-server
image: nginx
imagePullPolicy: Always
resources:
limits:
memory: "256Mi"
ports:
- name: http
containerPort: 80
volumeMounts:
- name: cache-static
mountPath: /usr/share/nginx/html
volumes:
- name: cache-static
emptyDir:
medium: ""Шаг сборки в Jenkins:
stage('Install') {
steps {
script {
sh 'yarn install --immutable'
sh 'tar --exclude=".git" -czf \$CACHE_DIR/project.tar.gz ./'
}
}
}
Остальные поды пайплайна при своем старте скачивают кэш parent-poda и запускают необходимые задачи:
stage("Parallel stage") {
script {
podTemplate(
yaml: "${multistage_pod}"
) {
node(POD_LABEL) {
stage("Parallel stage") {
container('yarn') {
sh "wget -qO- http://$parentHost/project.tar.gz | tar xz"
sh 'yarn install --immutable' # for linkage
sh "yarn nx run-many --target=$target --projects=${projects.join(',')}"
}
}
}
}
}
}
Внедрение такого подхода не меняет времени сборки по сравнению с вариантом без использования общего кэша, однако позволяет свести к минимуму взаимодействие с внешним миром при скачивании зависимостей.
Итоговый пайплайн для полной пересборки и проверки выглядит теперь так:

Выглядит лучше, не правда ли? Однако здесь нужно быть осторожным и не перегружать машины данными задачами, иначе весь профит от распараллеливания сойдет на нет. Конкретно этот пайплайн запускался всего лишь на 2-х машинах, имеющихся в пуле. В более продуктивное время у нас в пуле запущено около 5-7 машин, что может в теории дать неплохой прирост к ускорению сборки. Также в данном случае распределение задач по подам происходит не эффективно (некоторые задачи завершаются намного раньше и параллельный stage прекращает работу).
Помимо этого требовалось не навредить небольшим сборкам, когда распараллеливание не требуется. Для этого просто был введен лимит на минимальное количество модулей, запускаемое на одном поде. Если количество не превышает этот лимит, то все тяжеловесные шаги запускаются последовательно.
Маленькие сборки до рефакторинга:

И после:

UPD: Попытка № 4 или доработать нельзя оставить
И все таки неравномерное распределение сборки модулей по параллельным шагам не давало мне покоя. Некоторые шаги выполнялись довольно долго, а некоторые завершались достаточно быстро. Разница могла достигать двукратного размера. Появилась идея внедрить программную очередь для равномерного распределения задач. Получилось довольно интересно и каждый параллельный шаг одинакового типа теперь занимает +- одинаковое время. Общее время сборки также заметно упало (33 минуты против 56).

Ниже приведен код реализации такого поведения
def install() {
sh 'yarn install --immutable'
}
class NxTask {
public String name
public String target
public String args = ""
List<String> affected
public def affected(def pipeline) {
if(!affected) {
String raw = pipeline.sh(script: "yarn nx print-affected --target=${target}", returnStdout: true)
def data = pipeline.readJSON(text: raw)
affected = Collections.unmodifiableList(data['tasks'].collect { it['target']['project'] } as List<String>)
}
affected
}
public def cmd(List<String> projects) {
"yarn nx run-many --target=$target --projects=${projects.join(',')} $args"
}
}
class NxStage {
public static final NxStage TESTS = new NxStage(name: "Tests", tasks: [
new NxTask(name: "Jest", target: "test", args: "--runInBand --nx-bail --parallel=4"),
new NxTask(name: "Enzyme", target: "test-enzyme", args: "--runInBand --nx-bail --parallel=4")
])
public static final NxStage LINTING = new NxStage(name: "Linting", tasks: [
new NxTask(name: "Check Types", target: "check-types"),
new NxTask(name: "ESLint", target: "lint", args: "--parallel=4"),
new NxTask(name: "Stylelint", target: "stylelint", args: "--parallel=4")
], minTasksPerBin: 20)
static needDistribute(def pipeline, NxStage ...stages) {
stages.any {it.tasks(pipeline).size() > 1}
}
static String parentHost
String name
List<NxTask> tasks
int maxBins = 3
int minTasksPerBin = 10
def buildStages(String name, def taskProjects, def pipeline) {
taskProjects.collect { task, projects ->
if (!projects.isEmpty()) {
pipeline.stage("$name: ${task.name}") {
pipeline.script {
while (!projects.isEmpty()) {
def batch = []
while (!projects.isEmpty() && batch.size() < minTasksPerBin) {
def project = projects.poll()
if (project != null) {
batch << project
}
}
pipeline.sh "${task.cmd(batch)}"
}
}
}
}
}
}
def tasks(def pipeline) {
def taskProjects = tasks.collectEntries { [it, it.affected(pipeline).collect(new java.util.concurrent.ConcurrentLinkedDeque(), { it })] }
def size = taskProjects.collect { it.value.size() }.sum()
if (size == 0) {
return [:]
}
def bins = Math.min(Math.max((int)(size/ minTasksPerBin), 1), maxBins)
def firstStageName = "$name - Stage 1"
def tasks = [(firstStageName): {
pipeline.stage(firstStageName) {
buildStages(firstStageName, taskProjects, pipeline)
}
}]
if (bins > 1) {
if (parentHost == null) {
parentHost = pipeline.sh(script: "echo -n \${POD_IP}", returnStdout: true)
}
(2..bins).toList().each { idx ->
def stage = "$name - Stage ${idx}"
tasks[stage] = {
pipeline.stage(stage) {
pipeline.script {
pipeline.podTemplate(
yaml: "${pipeline.multistage_pod}"
) {
pipeline.node(pipeline.POD_LABEL) {
pipeline.container('yarn') {
pipeline.sh "wget -qO- http://$parentHost/project.tar.gz | tar xz"
pipeline.install()
buildStages(stage, taskProjects, pipeline)
}
}
}
}
}
}
}
}
tasks['failFast']=true
tasks
}
}А также как это выглядит в Jenkins пайплайне
stage('Install') {
steps {
script {
install()
if (env.BRANCH_NAME != 'master' && NxStage.needDistribute(this, NxStage.TESTS, NxStage.LINTING)) {
sh 'tar --exclude=".git" -czf \$CACHE_DIR/project.tar.gz ./'
}
}
}
}
stage('Tests') {
when {
not {
branch 'master'
}
}
steps {
script {
parallel NxStage.TESTS.tasks(this)
}
}
}
stage('Linting') {
when {
not {
branch 'master'
}
}
steps {
script {
parallel NxStage.LINTING.tasks(this)
}
}
}
stage('Validate') {
parallel {
stage('Validate - CSS Custom-Properties') {
steps {
sh 'yarn validate:css'
}
}
stage('Validate deps') {
steps {
sh 'yarn deps:validate'
}
}
stage('Validate Vertical Domains') {
steps {
sh 'node ./scripts/validate-package-domain.mjs'
}
}
}
}Заключение
Итоговое решение имеет как плюсы:
быстрая сборка
отсутствие трат на сторонние сервисы, внешний трафик или ресурсы необходимые, для развертывания внутренних сервисов)
данное решение применимо к большинству kubernetes кластерам
так и минусы:
достаточно большая сетевая нагрузка на родительский под, как следствие машину на которой он расположен, что может негативно влиять на другие поды расположенные на этой машине
Таким образом, в моем случае оптимальным оказалось решение не использующие сторонние сервисы, но дающее дополнительную нагрузку на throughput кластера и повышающее утилизацию ресурсов данного кластера. C финансовой точки зрения данное решение оказалось самым выгодным, так как расходы на внешние сервисы отсутствуют.. Очевидно, что данное решение и подход является идеальным конкретно для одного конкретного случая, надеюсь, что некоторые идеи могут быть полезными для кого-то еще. Однако, не стоит забывать, что каждое решение должно быть просчитано и протестировано с точки зрения ресурсов и финансов.
Комментарии (5)

dexec
30.12.2022 14:55+1Cпасибо за статью. Впервые вижу практическое использование jenkins внутри kubernetes (до этого на хабре было пару статей о том как развернуть jenkins внутри k8s).
Подход с minio внутри кластера выглядит интересным и перспективным, по-моему опыту он вполне прост в поддержке, жалко что автор не провел эксперименты с ним, есть ли в планах какое-либо использование minio?arkashaErema Автор
30.12.2022 15:04Добрый день, спасибо за замечание. Действительно минио неплохой инструмент, однако в нашей команде довольно много сервисов на поддержке и добавление еще одного согласовать проблематично. Особенно только для какой-то одной задачи. Поэтому данный вариант нам не подходил
yzhar
30.12.2022 16:54+1Вообще минио можно использовать для различных целей :) Например в нашей компании мы его используем как прокси кэш для докер образов. Очень полезно, особенно для кластеров со spot instances
vitaly_il1
Спасибо, интересно!
1) К сожалению, на первом скрееншоте нет тайминга всех ступеней pipeline. Что было самое тяжелое?
2) А всесто распараллеливания по десятку подов вы не пробовали scale up (запускать на мощном сервере)?
arkashaErema Автор
Добрый день, спасибо за комментарий!
1) Да, прошу прощения, не нашел как в дженкинсе отобразить время выполнения всех шагов для наглядности. Самые тяжеловесные это тесты jest и enzyme + linting тоже не всегда легковесный и занимает достаточно времени
2) Совсем забыл в статье упомянуть какая еще проблема решалась. Стабильность. В такой сборке довольно непросто контролировать память и кол-во порождаемых сборщиком процессов. А так-как мы вращаем все сборки в k8s на одном пуле машин, то мы явно задаем лимиты для пода по используемой памяти. Ответ на вопрос - да, сначала так и делали, но на больших сборках тесты были нестабильные и часто валились по OOM, т.к. на больших сборках часто выставлялись большие значения
--parallel, чтобы хоть как-то ее ускорить. На самом деле после рефакторинга стоит переосмыслить такой вариант и как-то гибко распределять тяжеловесные задачи по более мощным инстансам, которые можно поднимать по требованию. Спасибо за идею!