
Продолжим строить подобие JSON-RPC сервера, начатого в части 1 и анализировать его плюсы и минусы. В прошлой статье был описан механизм отделения бизнес логики бэкенда от транспортного протокола (HTTP) через шаблон проектирования "Front Controller", роль которого исполняет в нашем случае JsonRpcController.
API gateway
Бэкенд API до передачи запроса в код, отвечающий за бизнес логику, обычно предоставляет частичный функционал API шлюза (API gateway) - он может делать аутентификацию, авторизацию, роутинг, валидацию данных, логгирование, кэширование, обеспечивать меры безопасности и другое.
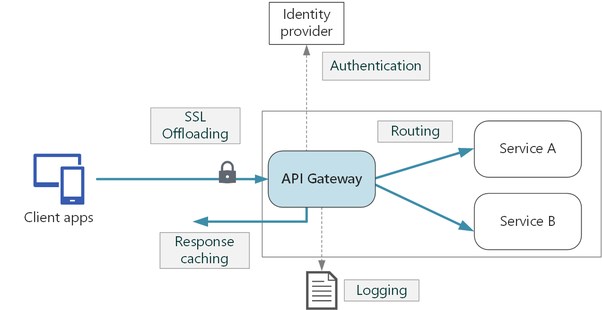
Часть указанных сервисов работает на уровне транспортного протокола (здесь HTTP), другие от него не зависят.
Оба случая можно реализовать в виде фильтров/интерсепторов. Например, аутентификация происходит при перехвате запроса внутри фреймворка (у большинства есть свои методы для создания подобных фильтров) до передачи его контроллеру, а авторизация - уже после отработки JsonRpcController. Добавить свой функционал фильтров перед передачей запроса в код бизнес логики полезно, потому что могут понадобиться и другие сервисы - например, дополнительная валидация параметров, защита от SQL инъекций, кэширование, логгирование, шифрование и прочее. Фильтры, которые могут потребоваться на уровне HTTP - управление CORS политикой, защита от CSRF, throttler, определение ботов/спайдеров.
Разделение кода на бэкенде на часть, работающую с транспортным протоколом, и чисто бизнес логику позволяет достаточно безболезненно не только поменять фреймворк, но и перейти при необходимости с HTTP на, скажем, Websockets или gRPC. При этом нужно будет переделать только то, что связано с HTTP - фильтр аутентификации, например. А код бизнес логики, включая фильтры авторизации и кэширования, останутся как есть. В случае с обычным фреймворком и реализации бэкенд API как RESTful работы будет намного больше.
Authentication & Authorization
Аутентификация (как проверка пользователя) и авторизация (как проверка разрешения конкретного пользователя на доступ к конкретному ресурсу) в случае с JSON-RPC полностью разделяются. Аутентификация обычно жестко привязана к протоколу передачи данных - для JWT, например, рефреш токен должен храниться в http-only куках, токены могут передаваться в HTTP заголовках и прочее. Авторизация же зависит от установленных правил доступа и определяется идентификатором текущего пользователя, вызываемым методом и его параметрами. Грубо говоря, по этим параметрам идет просто валидация. Аутентификация происходит до передачи запроса JsonRpcController контроллеру, авторизация - после его отработки, но до передачи выполнения программы коду бизнес логики. Аутентификация реализуется частично средствами бэкенд фреймворка, авторизация к фреймворку не привязана.
Встает вопрос, каким образом передать расшифрованную информацию об аутентифицированном пользователе дальше в бизнес логику? Варианта видится два - либо добавить параметр в тело JSON-RPC запроса внутри JsonRpcController, что сделает его формат несколько выбивающимся из спецификации, либо через контекст фреймворка. Выбор конкретной реализации особо ни на что не влияет.
File upload/download
Пожалуй, единственное, для чего кажется что требуются стандартные средства HTTP протокола - загрузка и скачивание файлов. Можно это реализовать отдельными эндпойнтами на бэкенде и специальным контроллером, можно отдельным фильтром перед JsonRpcController, но, на самом, деле любые файлы можно вполне несложно передавать как данные внутри JSON-RPC params используя средства JavaScript на фронте. Недавно стояла задача сгенерировать на бэке несколько отчетов в CSV формате, зазиповать и передать клиенту для скачивания, - так передать текстом всё на фронт, там сформировать архив и дать на сохранение оказалось проще и короче по коду.
Бинарные данные пакуем в base64. Если не нужно постоянно гонять туда-сюда десятки мегабайт файлов, то решение вполне эффективное. Не забываем настроить на вебсервере компрессию потока JSON-RPC данных.
Batch
Отправка запросов в пакете (batch) кажется довольно экзотичной задачей, но только поначалу. Представим себе страницу с товарами. Для её отображения используется метод products:list. У любого товара менеджер может поменять цену - соответственно, product:update. Можно сделать универсальный доступ к CRUD ресурсам с помощью resources:list и resources:update и в параметрах уже передаем product как имя ресурса, и цену как параметр апдейта (в данном примере это не существенно, можно так не делать, но к примеру).
При изменении цены возможны сбои - из-за сети, из-за нарушения внутренних бизнес ограничений, проблем с БД. Соответственно, после вызова update нужно удостовериться, что цена изменилась - получить подтверждение в каком-то виде. Для определенных ресурсов нужно такое подтверждение, для других - нет. Значит нужно ввести параметр в запрос, который говорит, получать ли в виде ответа новое значение из БД или нет (это ведь дополнительный запрос в БД, дополнительная ненужная нагрузка). Кроме того, при добавлении в update функционала read теряется идеология CRUD и унижается буковка S в термине SOLID.
Также теперь на фронте нам нужно добавить код, который проапдейтит конкретный продукт по пришедшему ответу. Код компонента легко может увеличиться раза в два.
Самый простой способ избежать всех этих усложнений - послать два запроса: сперва чистый update, а потом list; Но это два последовательных сетевых запроса, клиентский UX страдает.
И тут приходит JSON-RPC batch. Посылаем два запроса в одном пакете - [resources:update, resources:list]. На сервере они обрабатываются последовательно, и мы получаем на фронте актуальные данные. Ресурсы по-прежнему CRUD, всё хорошо.
Теперь представим, что на определенных ресурсах у нас есть кэширование. Бэкенд фреймворки часто прозрачно позволяют использовать Memcashed, Redis или простой файловый кэш для ускорения на порядок-другой доступа к данным по сравнению с БД. Если мы обновили данные, нам нужно обновить/очистить и кэш этого ресурса. И тут всего лишь нужно добавить третью команду: [resources:update, cache:clear, resources:list]. Возможны возражения, что таким образом бизнес логика частично переносится на клиент, но код реально становится проще, красивей и лаконичней. И не будем забывать, что с чистым REST CRUD вся логика на клиенте.
Обработка ошибок
Ответ на JSON-RPC запрос приходит с сервера либо в виде result, либо error. Вместо мучений с HTTP кодами ошибок и квази-ошибок 3хх-5хх транспортного протокола, можно определить свои коды ошибок уровня приложения и спокойно работать с ними, оставив сову и глобус в покое. Это намного удобней и намного естественней.
Кэширование
В современных SPA приложениях, использующих backend API, кэширование ресурсов может происходить:
На клиенте с помощью Service Worker.
На сервере, используя Redis и прочие соответствующие сервисы.
Оба эти варианта дают управляемое кэширование, когда разработчик точно знает где и какие у него данные, в отличие от неуправляемого браузерного HTTP кэширования, которое может быть, а может не быть. Полагаться на него нельзя, поэтому, в 99% случаях оно просто не нужно, а часто и приносит только проблемы. За 30 лет веб достаточно сильно развился, чтобы заменить HTTP кэширование на что-то более удобное и надежное, если сайт не простой "Hello world".
Developer eXpirience
Наверное, самый неприятный для разработчика момент работы с JSON-RPC - это отладка запросов в браузерных DevTools. Вкладка Network показывает только запросы к /rpc эндпойнту, и приходится лезть в секцию payload и смотреть детали запроса. Теряется визуальное восприятие потока выполнения программы, тратятся время и нервы.
Есть варианты решения этого через расширение браузера, которое будет показывать в списке сетевых соединений дополнительную информацию. Но можно поступить намного проще. При отправке запроса преобразуем его, добавив в конец URI название вызываемого метода JSON-RPC или что-то еще подходящее по смыслу. А на бэке просто редиректим все запросы по /rpc/(.+) на /rpc. Это можно сделать на уровне вебсервера (Apache или Nginx), либо сам фреймворк бэкенда может предоставлять такой функционал, как и в случае с CI:
$routes->post('rpc/(.+)', 'JsonRpcController::index');
Можно задавать данный URI опционально явно при вызове ( здесь {uri: 'updateSetting'} ):
Код Batch запроса примера выше
async updateSetting(keyName: string, keyValue: string | number) {
const resp = await http.jsonRpc(
[
{
method: 'utils.resources:updateByKey',
params: {
resource: 'settings',
key: 'name',
value: keyName,
data: { value: keyValue },
},
},
{
method: 'utils.resourceCache:clear',
params: {
name: 'settings',
},
},
{
method: 'utils.resources:getByKey',
params: {
resource: 'settings',
key: 'name',
value: keyName,
},
id: 'resource',
},
],
{ uri: 'updateSetting' }
);
return resp.find((resp: JsonRpcResponseMessage) => {
return resp.id === 'resource';
}).result?.data[0].value;
}В данном примере используется id для определения нужного ответа, потому что ответы для batch приходят тоже как массив. Для единичных запросов id особо не нужен, а для batch - вполне.
Когда uri явно не указан, используется алгоритм его построения через вызываемый метод. Для batch запросов названия методов соединяются с разделителем.
В итоге в DevTools Network получаем всю нужную информацию.
/rpc/productCategories:list
/rpc/batch[utils.products:update+utils.products:list]
/rpc/sendEmailНа бэкенде в логах вебсервера информация также будет в удобоваримом виде.
В prod env эту штуку можно отключить и использовать только /rpc эндпойнт.
Документирование
Для документирования JSON-RPC API существует спецификация OpenRPC. Но из-за того, что точка входа бэкенд API является по сути точкой входа в некий блок кода на каком-то языке и не зависит от HTTP, документировать можно чем угодно. Например, javadoc-ом для бэка на java. Бэкендер просто пишет код бизнес логики, а JSON-RPC работает именно как RPC (remote procedure call), позволяя фронту прозрачно вызывать функцию на бэке не заботясь о транспортных посредниках.
Также у OpenRPC есть небольшая экосистема в виде генераторов, расширения для VS Сode и прочий инструментарий.
Минусы JSON-RPC
Неизвестны. Может кто напишет в комментариях.
Заключение
С моей точки зрения внедрение JSON-RPC в проект является очень полезным улучшением его архитектуры, позволяя отвязать бизнес логику бэкенда от транспортного протокола, внося ясность и чистоту как в код, так и во интерфейс между фронтенд и бэкенд разработчиками, облегчая развитие и поддержку приложения. Код как asset приобретет бо́льшую ценность.
qertis
Минусы:
Некоторых не устраивает наличие одного AP эндпоинта.
Нет нормального генератора API.
Каждый волен создавать свои кастомные ошибки. Из-за этого, переключаясь в другом проекте на JSON-RPC, будет тяжелее ориентироваться (условно, каждый придумывает свою ошибку 404) Думаю, это можно решить семантическими кодами.
JSON - человекочитаемый текстовый формат, некоторым нужны бинарные данные, что ускоряет передачу данных и позволяет повесить любую схему типов.
JSON-RPC может не подойти для очень сложных реквестов или респонсов, тут GraphQL выигрывает.
Еще - коммьюнити у JSON-RPC меньше, описанные выше минусы можно было бы исправить в JSON-RPC 3, но бигтеху это не надо, а свободное сообщество предпочло REST.
SWATOPLUS
REST, это что-то про что спрашивают на собеседовании, а на деле каждый клепает свой REST, когда появляется не круд или фильтров настолько много, что они не влазит query-parameters. Поэтому лучше использовать что-то, что более-менее стандартизированно. Ибо под REST каждый понимает, что-то своё. Мало кто говорит про рест читал что-то в духе https://restfulapi.net/ Поэтому RPC/graphql лучше чем неразбериха с REST.
gmtd Автор
Большая часть указанных минусов вроде адресована в статье
Генератор API для вебсайтов с личным бэком (именно про такие я писал и сделал на это ссылку) не нужен. Для public API - возможно
Про передачу бинарных данных в статье есть. Объем трафика с компрессией потока будет примерно такой же. Да и не так часто это нужно делать - бинарники пересылать.
Про GraphQL не понял - что не может JSON-RPC по сравнению с GraphQL? Вопрос некорректный, потому что первое - формат передачи данных, второе - языка запросов, и через JSON-RPC можно передать какой угодно сложный SQL запрос с указанием как отформатировать на бэке результат перед возвратом. Но всё-таки?
Насчет комьюнити - у JSON есть комьюнити? Нету. Его просто используют, потому что это простой как валенок и настолько же удобный формат. Точно так же JSON-RPC - простой формат передачи данных, который просто нужно использовать. То, что я описал в статьях - не какие-то секреты и бест практики, это непосредственная выгода, которую сразу получаешь начиная использовать JSON-RPC. Единственный хинт - с переделкой эндпойнта
Комьюнити нужна сложным вещам, чтобы можно было зайти и поделиться своей болью или задать вопрос на который нет простого или однозначного решения - вот для REST-a нужна комьюнити