

Привет, Хабр! Меня зовут Марк Лебедев, работаю архитектором в GlowByte. В июне 2022 года на митапе DataPeople мы с командой рассказывали о наших планах в части GreenPlum (запись выступления). Если коротко, тогда мы сфокусировались на развитии open-source и собирались выложить в публичный доступ наши наработки относительно мониторинга кластера и мониторинга запросов, плейбуки по инсталляции и наши подходы для нагрузочного тестирования. Собственно, про них и хотелось бы поговорить подробно. В этой статье мы подведём итоги, что нам удалось сделать за прошедшие 6 месяцев, и расскажем о планах на будущий год. В конце статьи укажем все ссылки на репозитории.
Мониторинг кластера
В репозитории “ванильного” GreenPlum пока что есть мониторинг “из коробки”, но для того, чтобы он стал удобен, необходимо тратить достаточно много времени: над метриками нужно писать набор запросов, а результаты их выполнения где-то хранить и визуализировать.
Для этих целей мы выбрали следующие популярные компоненты:
Prometheus – для сбора и хранения метрик,
Grafana – для визуализации и построения дашбордов,
-
набор Prometheus-экспортёров:
a. Node Exporter – для сбора метрик с хостов, на которых развернута система,
b. SQL Exporter – для сбора метрик из БД,
c. API PXF – для получения метрик от PXF.
На данный момент у нас есть следующие дашборды:
-
Агрегатный дашборд о здоровье кластера Greenplum:
a. статус кластера, сегментов и сервисов,
b. информация о потреблении CPU на всех хостах кластера,
c. информация о потреблении RAM на всех хостах кластера,
d. информация об использовании дисков и swap на всех хостах кластера,
e. список созданных ресурсных групп и расписание их действия,
f. информация о запущенных сессиях и пользовательской активности.
Детальный дашборд о состоянии хостов кластера. Тут используется стандартный дашборд Node Exporter из библиотеки Grafana.
Стандартный дашборд мониторинга Prometheus.
-
Дашборд для мониторинга PXF:
a. список серверов PXF,
b. текущее и историческое количество соединений,
c. количество полученных и отправленных байт,
d. использование RAM в разрезе инстанса.
-
Детальный дашборд о состоянии ресурсных групп:
a. текущее потребление CPU в разрезе ресурсной группы, а также история этого потребления,
b. текущее потребление RAM в разрезе ресурсной группы, а также история этого потребления,
c. текущее и историческое значение активных запросов в разрезе ресурсной группы,
d. текущий объём spill-файлов в разрезе ресурсной группы,
e. количество распределенных ресурсных кластера между ресурсными группами
f. актуальные квоты ресурсных групп и расписание их изменений.
Все сборщики и дашборды можно легко обогащать дополнительными метриками, что позволяет собрать свой идеальный мониторинг.
Инструкция по установке:
Скачать собранный дистрибутив GPMonitoring.
Установить Ansible 2.14.1 и Python 3.9 на хост, с которого будет выполняться установка.
Заполнить файл inventory.
-
Запустить Ansible-плейбук с необходимым тегом (либо без указания тега для установки всех компонент):
a. exporters – установка обоих экспортёров;
b. node_exporter – установка Node Exporter;
c. sql_exporter – установка SQL Exporter;
d. monitoring – установка Prometheus и Grafana;
e. prometheus – установка Prometheus;
f. grafana – установка Grafana.
Пример установки и настройки только экспортёров:
ansible-playbook playbook.yml --tags exportersПример установки всего, кроме SQL Exporter:
ansible-playbook playbook.yml --skip-tags sql_exporterМониторинг запросов
С мониторингом кластера всё более-менее понятно, а вот для мониторинга активных запросов средств “из коробки” в “ванильном” GreenPlum не предусмотрено. Тут нам на помощь приходит механизм расширения через динамически загружаемые библиотеки, которые являются наследием PostgreSQL.
Мы разработали с нуля библиотеку greenplum.metric.hook, которая работает следующем образом: в ядре PostgreSQL предусмотрен набор глобальных переменных с указателями на список функций. Эти переменные проверяются в различные моменты работы СУБД, после чего производится запуск всей цепочки функций.
Мы используем следующие переменные и соответствующие им цепочки функций:
void ExecutorStart_hook(QueryDesc * queryDesc) – вызывается в начале выполнения любого плана запроса;
void ExecutorRun_hook(QueryDesc * queryDesc, ScanDirection direction, long count) – вызывается во время выполнения любого плана запроса после ExecutorStart_hook;
void ExecutorFinish_hook(QueryDesc * queryDesc) – вызывается после последнего ExecutorRun_hook;
void ExecutorEnd_hook(QueryDesc * queryDesc) – вызывается в конце выполнения любого плана запроса;
-
void query_info_collect_hook(QueryMetricsStatus status, void * args) – дополнительный хук, который добавлен только в ядро GreenPlum. Вызывается на следующих стадиях выполнения запроса и узлов графа запроса, когда приходит соответствующий status:
METRICS_QUERY_SUBMIT – инициализация запроса,
METRICS_QUERY_START – старт запроса,
METRICS_PLAN_NODE_INITIALIZE – инициализация расчёта вершины графа плана запроса,
METRICS_PLAN_NODE_EXECUTING – расчёт вершины графа запроса,
METRICS_PLAN_NODE_FINISHED – запускается при окончании расчёта каждой вершины графа запроса,
METRICS_QUERY_DONE – завершение запроса,
METRICS_INNER_QUERY_DONE – завершение подзапроса,
METRICS_QUERY_ERROR – возникновение ошибки,
METRICS_QUERY_CANCELING – во время отмены запроса,
METRICS_QUERY_CANCELED – после отмены запроса.

Структура QueryDesc является основным источником информации о запросе и обновляется на протяжении всего жизненного цикла процесса. На каждом этапе выполнения запроса мы получаем текущее состояние как раз из этой структуры.
Полученные метрики отправляются в отдельное приложение по протоколу gRPC. Спецификация gRPC-протокола находится в нашем репозитории, что даёт возможность реализовать свой собственный агрегатор и использовать разные методы для хранения и обработки данных на любом удобном языке.
В нашей реализации за обработку полученных метрик отвечает greenplum.metric.agent, который сохраняет данные по запросу в отдельный инстанс PostgreSQL. А для интеграции реализовано промежуточное API greenplum.metric.api.
За визуализацию и работу с собранными метриками у нас отвечает ClusterManager. Это отдельный продукт, который объединяет в себе функции по администрированию, мониторингу и управлению кластерами GreenPlum.

На данный момент мы открыли только репозиторий библиотеки greenplum.metric.hook. Репозитории агента и API пока закрыты.
Установка библиотеки производится в рамках установки ядра GreenPlum.
Инсталлятор GreenPlum
Дисклеймер
Для корректной установки необходим доступ в интернет либо настроенный локальный пакетный репозиторий.
Мониторинг – это хорошо, но сначала нужно установить сам GreenPlum. Для упрощения развёртывания мы разработали набор утилит для автоматизации установки и компонент вокруг него. За основу были взяты Ansible-скрипты, так как они удобны для задач одновременного конфигурирования множества серверов.
На данный момент мы умеем решать ряд задач, в числе которых:
-
Установка и первичная настройка кластера GreenPlum:
подготовка окружения на кластере,
установка пакетов зависимостей,
установка ядра GreenPlum,
установка расширений, в том числе PXF,
установка библиотеки хуков.
-
Установка и настройка компонент мониторинга:
установка экспортёров,
установка Prometheus,
установка Grafana.
Установка библиотеки хуков.
-
Установка и настройка фреймворка нагрузочного тестирования:
подготовка хоста и установка необходимого ПО,
генерация тестовых данных,
запуск нагрузочного тестирования.
Скрипты автоматизации тестируются на следующих системах:
RHEL 7,
Ubuntu 18.04.
Они вполне могут запуститься и на других дистрибутивах схожих семейств, но тестировались пока только на этих, так как они целевые для GreenPlum. В планах добавить тесты для более новых версий ОС.
Подробные инструкции по запуску плейбуков можно найти в README репозитория.
Фреймворк нагрузочного тестирования
У нас уже были свои внутренние наработки для сравнения различных СУБД именно в контексте OLAP-задач. Теперь мы адаптировали их для GreenPlum, автоматизировали установку и запуск.
В процессе тестирования моделируются данные и процессы, которые являются типовыми в задачах ETL-вычислений, ad hoc запросов и, самое главное, в режиме высококонкурентного пользовательского доступа.
Тестирование производится на синтетических данных, которые генерируются отдельным шагом плейбука. Количество данных можно задать в инвентаре, по умолчанию генерируется приблизительно 8TB данных со следующей логической моделью данных:
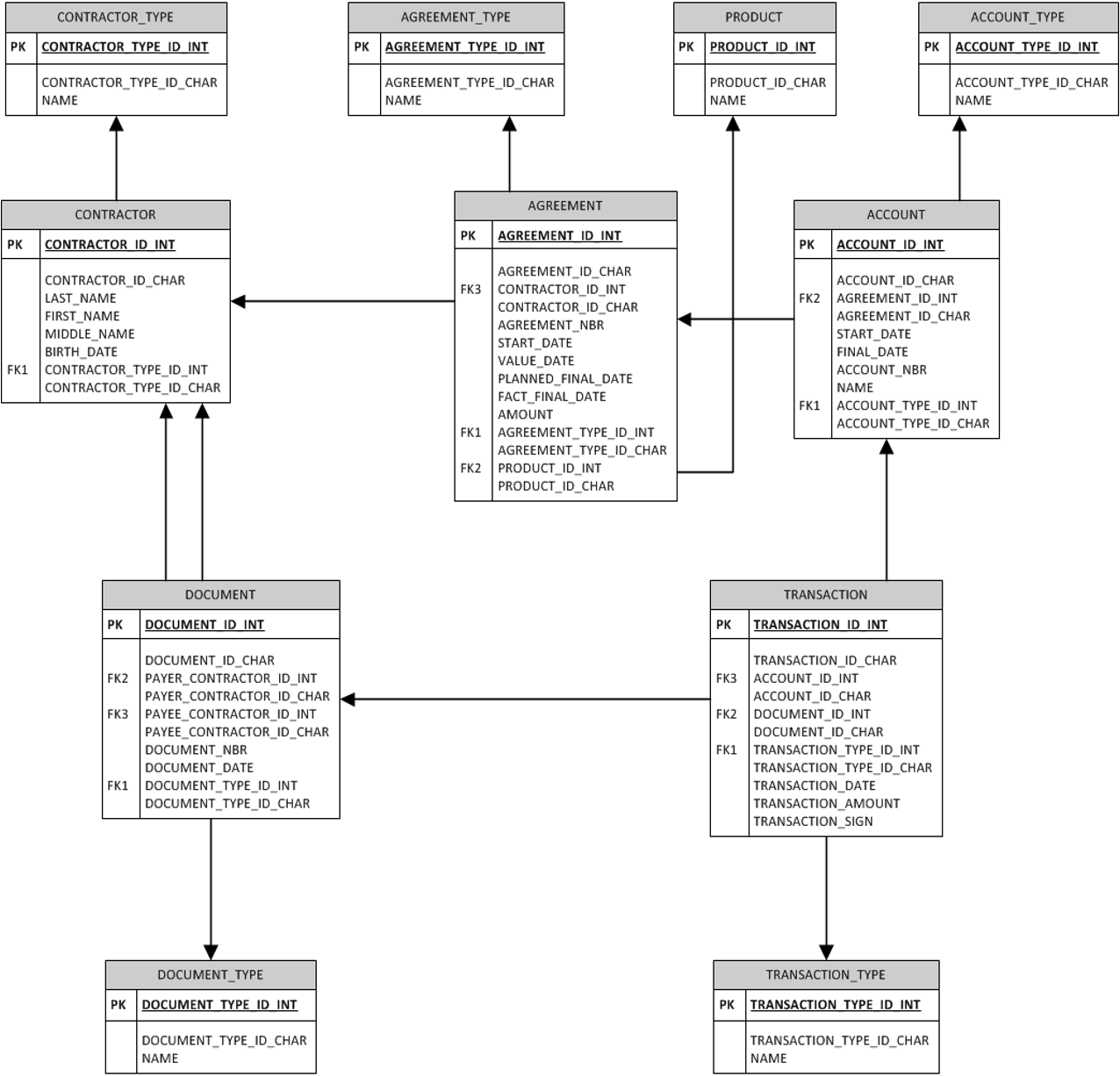
Шаг тестирования представляет из себя запуск Jmeter-сценариев, в которых реализованы типовые SQL-запросы:
-
ETL-запросы:
a. группировка данных большой таблицы по полям с разной селективностью,
b. операции сортировки данных большой таблицы,
c. построение агрегатной витрины.
-
Запросы, которые имитируют типовую работу пользовательского ad hoc анализа с целью получения конкретной выборки либо отчёта:
a. запросы с аналитическими функциями,
b. построение одного большого результирующего набора на основании соединения больших и маленьких таблиц с фильтрацией по полям с разной селективностью.
-
Типовые запросы, являющиеся частью общего процесса либо решающие задачи материализации предварительной выборки для последующего анализа данных:
a. операции вида Create Table As Select из большой таблицы.
Все запросы запускаются с заданным количеством одновременных подключений.
Инструкция по установке:
Скачать собранный дистрибутив.
Установить Ansible 2.14.1 и Python 3.9 на хост, с которого будет выполняться установка.
Заполнить файл inventory.
-
Запустить Ansible-плейбук с необходимым тегом (либо без указания тега для установки всех компонент):
a. configure_gp_test_server – подготовка хоста и установка необходимого ПО;
b. gp_tests_data – генерация тестовых данных;
c. gp_tests_load – запуск нагрузочного тестирования.
Планы на 2023
Во-первых, будем ждать обратной связи по нашим открытым репозиториям и дорабатывать функционал.
Во-вторых, мы планируем научить наши хуки работать с процедурами, чтобы это не было чёрной коробочкой, и управлять переключением запросов в ресурсных группах.
Ещё в 2022 году мы начали активно разрабатывать функционал репликации на базе WAL-логов, сейчас мы его интенсивно тестируем и планируем в 2023 году продолжить развитие.
И, конечно, 7-я версия GreenPlum, уже вышла её beta. Мы ещё её не собирали из исходников, пока только поставили и начали исследовать. Теперь будем учиться собирать дистрибутив и дорабатывать все наши продукты для корректной работы с новой версией.
—-------
Ссылки на репозитории:
https://git.angara.cloud/gbgreenplum/greenplum.monitoring – репозиторий мониторинга кластера,
https://git.angara.cloud/gbgreenplum/greenplum.metric.hook – репозиторий библиотеки хуков,
https://git.angara.cloud/gbgreenplum/greenplum.playbook.core – репозиторий для плейбуков установки ядра GreenPlum,
https://git.angara.cloud/gbgreenplum/greenplum.playbook.monitoring – репозиторий для плейбуков установки мониторинга,
https://git.angara.cloud/gbgreenplum/greenplum.playbook.loadtest – репозиторий для плейбуков установки фреймворка нагрузочного тестирования.
barloc
Классно, молодцы.