
Назначение std::string_view заключается в том, чтобы избежать копирования данных, которые уже чему-то принадлежат и для которых требуется только лишь неизменяемое представление. Как вы уже могли догадаться, этот пост будет посвящен производительности.
Сегодня речь пойдет об одной главных фич C++17.
Я предполагаю, что вы уже имеет базовое представление о std::string_view. Если нет, то можете сперва прочитать мой предыдущий пост “C++17 - Что нового в библиотеке”. Строка C++ похожа на тонкую обертку, которая хранит свои данные в куче. Поэтому, когда вы имеете дело со строками в C и C++, выделение памяти - самое заурядное явление. Давайте же разберемся с этим.
Оптимизация небольших строк
Очень скоро вы увидите, почему я назвал этот абзац оптимизацией небольших строк.
// sso.cpp
#include <iostream>
#include <string>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
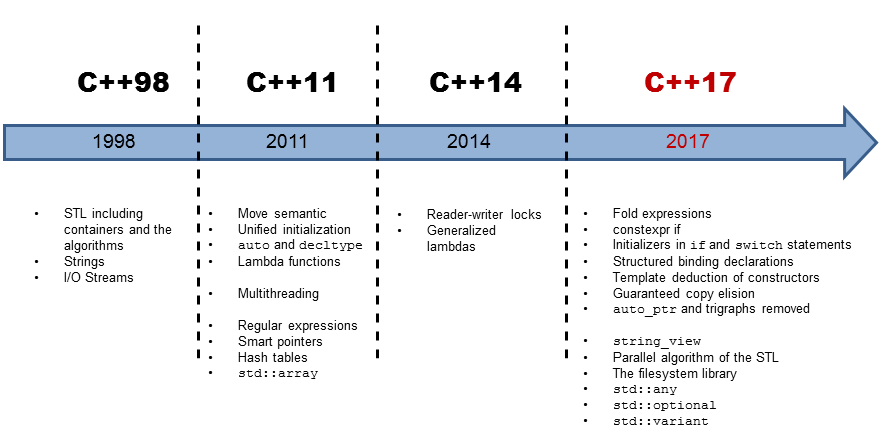
std::string small = "0123456789";
std::string substr = small.substr(5);
std::cout << " " << substr << std::endl;
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(small);
getString("0123456789");
const char message []= "0123456789";
getString(message);
std::cout << std::endl;
}Я перегрузил глобальный оператор new в строках 6-9. Таким образом, вы сможете увидеть, какая операция вызывает выделение памяти. Да ладно, это проще пареной репы. Конечно же выделение памяти вызывают строки 19, 20, 28 и 29. А теперь давайте посмотрим на вывод:
Что за ...? Я говорил, что строки хранят свои данные в куче. Но это верно только в том случае, если длина строки превышает некоторый размер, зависящий от реализации. Этот размер для std::string составляет 15 в MSVC и GCC и 23 в Clang.
Это означает, что небольшие строки на самом деле хранятся непосредственно в самом объекте строки. Поэтому выделение памяти не требуется.
Хорошо, отныне мои строки всегда будут содержать не менее 30 символов, чтобы мне не нужно было отвлекаться на оптимизацию небольших строк. Давайте начнем с начала, но на этот раз с более длинными строками.
Выделение памяти не требуется
Теперь назад к лучезарному std::string_view. В отличие от std::string, std::string_view не выделяет память. И вот тому доказательство:
// stringView.cpp
#include <cassert>
#include <iostream>
#include <string>
#include <string_view>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
void getStringView(std::string_view strView){}
int main() {
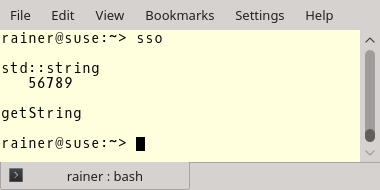
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string large = "0123456789-123456789-123456789-123456789";
std::string substr = large.substr(10);
std::cout << std::endl;
std::cout << "std::string_view" << std::endl;
std::string_view largeStringView{large.c_str(), large.size()};
largeStringView.remove_prefix(10);
assert(substr == largeStringView);
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(large);
getString("0123456789-123456789-123456789-123456789");
const char message []= "0123456789-123456789-123456789-123456789";
getString(message);
std::cout << std::endl;
std::cout << "getStringView" << std::endl;
getStringView(large);
getStringView("0123456789-123456789-123456789-123456789");
getStringView(message);
std::cout << std::endl;
}Еще раз. Выделение памяти происходит в строках 24, 25, 41 и 43. Но что происходит в соответствующих вызовах в строках 31, 32, 50 и 51? Никакого выделения памяти не происходит!
Это впечатляет. Вы можете даже не сомневаться, что это значительный прирост производительности, потому что выделение памяти — очень затратная операция. Особенно хорошо заметен этот прирост производительности, когда вы создаете подстроки на основе существующих строк.
O(n) vs. O(1)
std::string и std::string_view оба содержат метод substr. Метод std::string возвращает подстроку, а метод std::string_view возвращает представление подстроки. Это звучит не так захватывающе, но между этими методами есть существенная разница. std::string::substr имеет линейную сложность, а std::string_view::substr — константную сложность. Это означает, что производительность операции над std::string напрямую зависит от размера подстроки, а производительность операции над std::string_view — не зависит.
Вот теперь мне действительно любопытно. Давайте проведем простое сравнение производительности.
// substr.cpp
#include <chrono>
#include <fstream>
#include <iostream>
#include <random>
#include <sstream>
#include <string>
#include <vector>
#include <string_view>
static const int count = 30;
static const int access = 10000000;
int main(){
std::cout << std::endl;
std::ifstream inFile("grimm.txt");
std::stringstream strStream;
strStream << inFile.rdbuf();
std::string grimmsTales = strStream.str();
size_t size = grimmsTales.size();
std::cout << "Grimms' Fairy Tales size: " << size << std::endl;
std::cout << std::endl;
// случайные значения
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<> uniformDist(0, size - count - 2);
std::vector<int> randValues;
for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine));
auto start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTales.substr(randValues[i], count);
}
std::chrono::duration<double> durString= std::chrono::steady_clock::now() - start;
std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl;
std::string_view grimmsTalesView{grimmsTales.c_str(), size};
start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTalesView.substr(randValues[i], count);
}
std::chrono::duration<double> durStringView= std::chrono::steady_clock::now() - start;
std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl;
std::cout << std::endl;
std::cout << "durString.count()/durStringView.count(): " << durString.count()/durStringView.count() << std::endl;
std::cout << std::endl;
} Прежде чем я представлю вам результаты, позвольте мне сказать пару слов о моем тесте производительности. Основная идея этого теста производительности заключается в том, чтобы считать большой файл в качестве std::string и создать много подстрок с помощью std::string и std::string_view. Здесь меня конкретно интересует, сколько времени займет создание этих подстрок.
В качестве своего длинного файла я использовал “Сказки братьев Гримм”. А что еще мне было использовать? Строка grimmTales (строчка 24) содержит внутренности файла. Я заполняю std::vector<int> в строчке 37 с количеством access (10'000'000) значений в диапазоне [0, размер - количество - 2] (строчка 34). А теперь начинается сам тест производительности. Я создаю в строчках с 39 по 41 access подстрок фиксированной длины count. count равно 30. Следовательно, оптимизация небольших строк не будет мешаться под ногами. Я делаю то же самое в строчках с 47 по 49 с применением std::string_view.
Вот результаты. Ниже вы можете видеть длину файла, показатели для std::string::substr и std::string_view::substr, и соотношение между ними. В качестве компилятора я использовал GCC 6.3.0.
Для строк размером в 30 символов
Только из любопытства. Показатели без оптимизации.
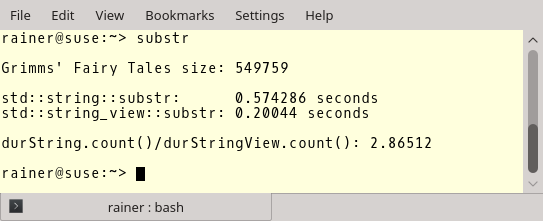
Но теперь к более важным показателям. GCC с полной оптимизацией.

Оптимизация не имеет особого значения в случае std::string, но мы наблюдаем большую разницу в случае std::string_view. Создание подстроки с помощью std::string_view примерно в 45 раз быстрее, чем при использовании std::string. Что это, если не повод использовать std::string_view?
Для строк других размеров
Теперь мне стало еще интереснее. Что будет, если я поиграю с размером count подстроки? Разумеется, все показатели для максимальной оптимизацией. Я округлил их до 3-го знака после запятой.

Я не удивлен, цифры отражают гарантии сложности std::string::substr в противопоставление std::string_view::substr. Сложность первого линейно зависит от размера подстроки; второй не зависит от размера подстроки. В конечном итоге, std::string_view радикальным образом превосходит std::string.
Сегодня вечером состоится открытый урок, на котором разберемся, какие основные алгоритмы включены в STL. В ходе занятия познакомимся с алгоритмами поиска и сортировки. Записаться можно на странице курса "C++ Developer. Professional".
Комментарии (21)

bfDeveloper
00.00.0000 00:00+5Шёл 2023 год, а в статьях GCC 6.3. Не удивительно при оригинале статьи из 2017 года. При этом ни про устройство, ни про гарантии и потенциальный UB от повисших указателей. `string_view` - замечательная вещь, но хоть какие-нибудь размышления и сравнения с char* не помешали бы.
Ну и воспользуюсь случаем и порекламмирую panda::string. CopyOnWrite(CoW), все те же substr тоже без копирований и аллокаций, но с полной гарантией безопасности. Тот же SSO на 23 байта. Цена полной безопасности дешёвого subbstr - CoW не лучшим образом дружит с потоками. Но если не шарить стейт и передавать копии данных аккуратно, ну или как мы вообще не использовать потоки, то это совсем не цена.

Biga
00.00.0000 00:00Просто любопытно, sizeof(panda::string) vs sizeof(std::string) - одинаковые или нет?
bfDeveloper
00.00.0000 00:00+2Сложно утвержать сразу про все реализации std, но скорее нет, чем да. На 64-битной архитектуре sizeof(panda::string) == 40. Стандартная у меня 32 (Debian 11, GCC 10.2). То есть просто так передавать по значению тоже может быть чуть-чуть дороговато, лучше бы по ссылке. Но скопировать себе для хранения - ни о чём на фоне аллокации и копии в std.

Tujh
00.00.0000 00:00+1CopyOnWrite(CoW)
А разве это не запрещено последними стандартами?
Strong Proposal
This change disallows copy-on-write implementations. For those implementations using copy-on-write implementations, this change would also change the Application Binary Interface (ABI).
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2534.html
bfDeveloper
00.00.0000 00:00Запрещено. В силу требований потоковой безопасности в первую очередь. Вот только не всем она нужна, особенно с учётом её цены. Такой же пример - std::shared_ptr, его атомарный счётчик слишком уж дорог для многих применений. Имхо, это нарушение базового принципа "не платить за то, что не используешь". Поэтому мы отказались от этих довольно слабых гарантий (класс в целом всё равно не thread-safe) в пользу производительности в одном потоке.
P.S. Струкутуру проекта поправили, ссылка изменилась panda::string

rukhi7
00.00.0000 00:00+1вот интересно, автор проводит какие то исследования производительности и не пишет в какой конфигурации он этот тестовый пример компилировал в Release или в Debug. И если это Release то с какими ключами оптимизации?
Может я отстал от жизни и эти настройки какие-то стандартные что ли теперь? Или эти настройки теперь (для новых стандартов С++) не влияют на производительность?
Может кто-то пояснить?
Из своего опыта я помню что в Release компилятор не то что вызовы к переопределенной функции может выкинуть, он может и целые переменные проигнорировать в коде.
crea7or
00.00.0000 00:00Назовите три причины почему надо передавать std::string_view в функции по значению? :)

sergio_nsk
00.00.0000 00:00+1
Из-за этого так бы задан вопрос?
Развёрнутые ответы с ассемблером: https://quuxplusone.github.io/blog/2021/11/09/pass-string-view-by-value/

webhamster
00.00.0000 00:00Там в тексте есть такой пассаж:
In the
byvaluecase, thestring_viewis passed in the register pair(%rdi, %rsi), so returning its “size” member is just a register-to-register move.Стал искать, что это за регистровая пара
%rdi, %rsi? В других процессорах бывает, что два регистра объединяются в регистровую пару, представляя как бы один регистр в два раза большего размера. Если действительно в x86 существует регистровая пара из 64-х битных rdi и rsi, то эта пара должна иметь размер 128 бит.Но команда
movq %rsi, %raxперебрасывает значение из 64-битного rsi в 64-х битный rax. При чем тут регистровая пара?Кроме того, я нигде не нашел информации что rdi и rsi способны объединяться в пару. Да, у них есть связь, потому что rsi - это регистр-источник (source), а rdi - это регистр-приемник (destination), и, видимо они индексные (i) потому что используются в командах типа repe movsb. Но это же не регистровая пара.
В общем, автор меня запутал. Что он хотел сказать?

BadHandycap
00.00.0000 00:00+1Имеется в виду System V AMD64 ABI calling convention. В нём первые два аргумента передаются через регистры rdi и rsi. Но в примере возвращается только размер строки, т.ч. используется только один регистр. Типичная проблема "писарей" доходчиво излагать свои мысли.


dyadyaSerezha
00.00.0000 00:00-1Блин, неужели было сложно поставить номера строчек в примерах кода?
Давно не писал на С++, но там все такой же древний, архаичный вывод сообщений в std::cout, как этот?
std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl;
Нормального, удобного форматирования до сих пор нет?

Dima_Sharihin
00.00.0000 00:00-1Вообще, стандартному С++ давно не хватает строкового пула. Как в Lua. Всё настолько сурово, что я уже всерьез хочу прикрутить рантайм Luajit к С/С++ проекту просто ради ссылочной системы на иммутабельные строки.

domix32
00.00.0000 00:00Так если есть список строковых литералов, то оно и так оптимизировалось и складировалось в .rodata. Или речь про динамически считываемые строки которые потом не меняются?
Dima_Sharihin
00.00.0000 00:00std::string совершенно плевать на строковые литералы в чистом виде
сравнение строк все равно через memcmp идет
std::string в поле класса все равно хранит копию данных
строка может прийти из внешнего документа (json, например) Суть строкового пула, что память на "ещё одну" строку выделяться не будет (кроме ссылки). А когда 95% времени выполнения процесса занимает malloc() - это становится существенно
domix32
00.00.0000 00:00Ближайшее, я так понимаю, boost::pool. А так согласен, с иммутабельными вещами в плюсах довольно плохо, но если очень хочется, то можете написать некоторый пропозал в стандарт.

cdriper
00.00.0000 00:00ух ты!
оказывается, что если вместо данных хранить указатель на них, то копирование будет работать быстрее!
Rio
Я понимаю, что перевод, но в статье прям не хватает краткого описания, как собственно string_view устроен. Что он просто хранит, условно, адреса первого и последнего байта исходных строковых данных. Большинство итоговых выводов статьи стали бы очевидны уже после этой информации (как и подводные камни такой реализации, вроде UB при изменении содержимого исходной строки).