
Привет! Меня зовут Дима Вагин, я бэкенд-инженер в Авито. Сегодня расскажу, как мы работаем с БД PostgreSQL из Go. Покажу, какие библиотеки и пулеры соединений мы используем для доставки в код параметров подключения и как мы их настраиваем. А ещё расскажу про проблемы, к которым приводит отмена контекста, и о том, как мы с ними справляемся.

Доставка паролей и параметров подключения в продакшн
Прежде чем подключаться к PostgreSQL, нужно определиться, как безопасно и удобно передавать пароли от БД и параметры подключения.
Вот, как предлагает подключаться к PostgreSQL одна из первых ссылок в гугле:
package main
import (
"database/sql"
"fmt"
_ "github.com/lib/pq"
)
const (
host = "localhost"
port = 5432
user = "postgres"
password = "your-password"
dbname = "calhounio_demo"
)
func main() {
psqlInfo := fmt.Sprintf("host=%s port=%d user=%s "+
"password=%s dbname=%s sslmode=disable",
host, port, user, password, dbname)
db, err := sql.Open("postgres", psqlInfo)
if err != nil {
panic(err)
}
defer db.Close()
err = db.Ping()
if err != nil {
panic(err)
}
fmt.Println("Successfully connected!")
}Тут сразу бросается в глаза ряд очевидных проблем: откуда брать пароли и параметры подключения? Просто закоммитить их в код нельзя: они меняются. Ещё есть не совсем очевидные проблемы: соединение с базой проверяется только единожды, и не экранируется пароль.
Мы используем простую обвязку, которую написали сами. Вот так выглядит подключение у нас в коде:
package main
import (
"fmt"
"go.avito.ru/gl/psql/v4"
)
func main() {
db, err := psql.Connect(psql.WithConnectionWaiting())
if err != nil {
panic(err)
}
defer db.Close()
fmt.Println("Successfully connected!")
}
Такая обвязка решает проблему с паролями и подключением:
Параметры в прод доставляются через переменные окружения.
Пароли автоматически подтягиваются из Vault. Разработчик без одобренного доступа их не видит.
Происходит настройка пула драйвера.
Производится проверка доступности соединения.
Ещё пароль нужно периодически менять, но если изменить его на лету, приложение перестанет работать. Поэтому наша обвязка использует два логина: когда приложение задеплоено под одним пользователем, у второго меняется пароль. При следующей выкатке используемый логин поменяется. Так происходит ротация паролей.
Локальный и серверный PgBouncer
В Авито микросервисная архитектура — у нас больше 1,5 тысяч микросервисов и 500 инстансов PostgreSQL, у каждого из которых есть по 2–3 реплики. Все бэкенд-приложения на Go связаны с БД по сети при помощи пулеров соединения PgBouncer:

У каждого Go-приложения есть локальный (клиентский) PgBouncer, а у каждого инстанса или реплики PostgreSQL ещё по одному — серверному.
Локальный PgBouncer вместе с кодом находятся внутри k8s пода. Это сделано, чтобы приложение и другие контейнеры, например, pgeon на схеме, могли не ходить за каждым коннектом к северному PgBouncer по сети.

Серверный PgBouncer находится в lxc-контейнере в одном из датацентров. Там же и другие приложения: например, которые собирают метрики с БД — metric-scrapper на схеме. Клиентский PgBouncer по сети соединён с серверным.
Подключение к PostgreSQL
Давайте рассмотрим на диаграммах последовательности, как происходит подключение к PostgreSQL из наших Go-приложений:
В приложении вызываем db.Query().
Клиентский пул драйвера подключается к локальному PgBouncer.
Локальный PgBouncer подключается к серверному PgBouncer.
Серверный PgBouncer подключается к PostgreSQL.
PostgreSQL форкает процесс и возвращает PID и секретную строчку aka secret key.
PID и секретная строчка доходят до пула драйвера.
Драйвер отправляет запрос, который по цепочке доходит до базы данных.
Результат возвращается в код, где мы через
rows.Scan()иNext()вычитываем данные.Вызываем
rows.Close(), чтобы освободить ресурсы и вернуть коннект в пул драйвера.
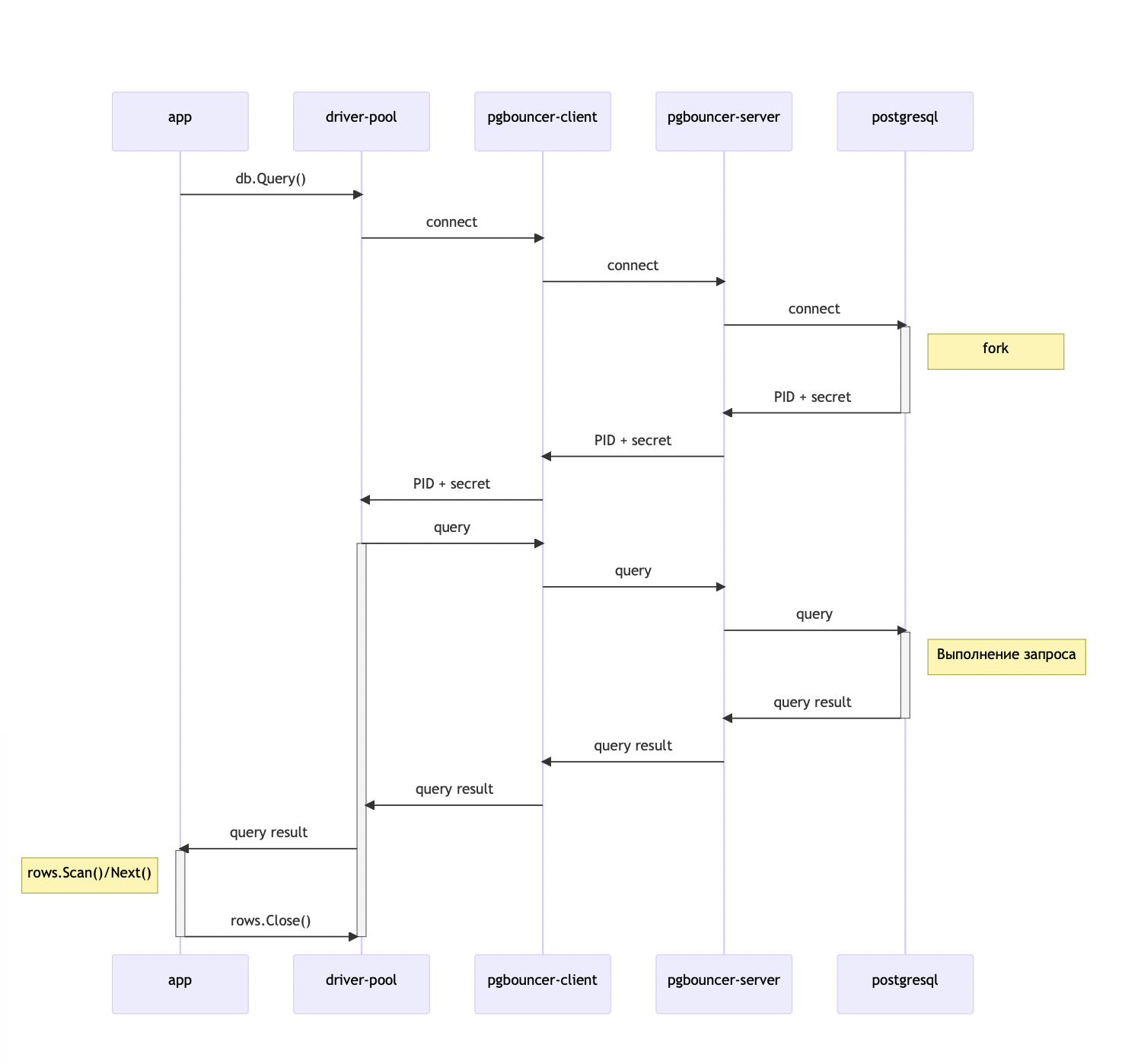
Подключение, форк и возврат PID с секретной строчкой (шаги 2–6) занимают много времени и ресурсов. На схеме видно, что непосредственно выполнение запроса происходит гораздо быстрее. Поэтому шаги 2–6 выполняются только при первом запросе.
Во всех последующих запросах мы используем уже существующее подключение и тот же процесс. Так выглядит повторный запрос на диаграмме последовательности:

Важно не забыть шаг 9 — rows.Close(), потому что иначе коннект не вернётся в пул драйвера и не сможет использоваться для других запросов, и это приведёт к отказу сервиса, если пул ограничен.
func missingClose() {
age := 27
rows, err := db.Queryx("SELECT name FROM users WHERE age = ?", age)
if err != nil {
log.Fatal(err)
}
// defer rows.Close()
names := make([]string, 0)
for rows.Next() {
var name string
if err := rows.Scan(&name); err != nil {
log.Fatal(err)
}
names = append(names, name)
}
// Check for errors from iterating over rows.
if err := rows.Err(); err != nil {
log.Fatal(err)
}
}Чтобы избегать такой ошибки, мы используем линтер sqlclosecheck. Он проверяет код на наличие rows.Close() и предупреждает об его отсутствии на этапе сборки. В коде выше линтер подскажет ошибку missing_close.go:3:24: Rows/Stmt was not closed.
Настройки клиентской и серверной части pgbouncer, которые мы используем в Авито
PgBouncer на клиентской части
pool_mode = transaction. В этом режиме соединение возвращается в общий пул после завершения транзакции.
pool_size = 5. Одновременно можно выполнять не больше 5 транзакций. Этого обычно достаточно: 5 бэкендов могут за 1 секунду выполнить 5000 транзакций при длине транзакции в 1 мс.
query_wait_timeout = 10s. При попытке выполнить транзакцию придётся ждать, пока не освободится один из бэкендов. Если время ожидания превысит 10 секунд, приложение получит ошибку
query_wait_timeout.max_client_conn = 200. Максимально разрешённое количество подключений. По умолчанию 100, мы выставляем 200.
client_idle_timeout = 7200. PgBouncer закрывает соединения, которые простаивают дольше 2 часов.
Пул драйвера
Размер — 5, по размеру пула локального PgBouncer:
db.SetMaxOpenConns(5)
db.SetMaxIdleConns(5)Время жизни и простоя коннекта — 5 минут. Эти значения должны быть меньше
client_idle_timeoutв PgBouncer, иначе Go-драйвер может попытаться выполнить запрос на соединении, которое уже закрыто локальным PgBouncer.
db.SetConnMaxLifeTime(5 * time.Minute)
db.SetConnIdleTime(5 * time.Minute)PgBouncer на серверной части
У серверного PgBouncer настройки почти такие же, как и у локального.
pool_mode = transaction.pool_size = 10.query_wait_timeout = 15s.
Работа с транзакциями
При работе с транзакциями мы поняли, что чем она короче — тем эффективнее используется база данных. Расскажу, почему так происходит и как добиться максимальной эффективности.
Короче транзакция — лучше
Это обычный код на Go, который работает с транзакцией. Мы открываем транзакцию, делаем запрос и коммитим.
func tx() error {
tx, err := db.Begin()
if err != nil {
return err
}
defer tx.Rollback()
_, err = tx.Exec("update t set age = age + 1 where user_id = $1", 10)
if err != nil {
return err
}
row := tx.QueryRow("select * from t where user_id = $1", 10)
if row.Err() != nil {
return err
}
// ...
_ = tx.Commit()
return nil
}
Это работа того же кода на диаграмме последовательности. Обратите внимание, что локального PgBouncer нет на схеме. На самом деле он есть, но не влияет на результат и усложняет схему.

Реальное время работы БД — это лишь маленькие промежутки времени, которые на диаграмме отмечены как «Выполнение запроса». Всё остальное время база простаивает: пул занят, и выполняться ничего больше не может. Более того, строки которые эта транзакция изменила - заблокированы, и параллельные транзакции которым тоже надо изменить эти строки вынуждены дожидаться её завершения.
Заблокированные строки и пул освободятся, только когда мы сделаем коммит. Значит, нужно сократить время между началом транзакции и коммитом.
Вывод: чем короче транзакция, тем лучше. При короткой транзакции БД меньше простаивает в бесполезном ожидании, а значит вы можете выполнять больше запросов в единицу времени.
Способы сократить транзакцию
Чтобы сделать транзакцию короче, мы используем:
returning.Общие табличные выражения (CTE).
Хранимые процедуры.
Давайте немного перепишем код выше:
func tx() error {
row := tx.QueryRow(
"update t set age = age + 1 where user_id = $1 returning *", 10)
if row.Err() != nil {
return err
}
// .....
return nil
}Как вы видите, транзакция стала значительно короче. Значит, можно выполнять больше запросов в единицу времени.
Новое соединение внутри транзакции
Довольно распространённая ошибка — попытка выделить ещё один коннект из пула внутри транзакции. В коде это выглядит так:
package main
func tx() error {
tx, err := db.Begin()
if err != nil {
return err
}
defer tx.Rollback()
_, err = tx.Exec(“update t set age = age + 1 where user_id - $1”, 10)
if err != nil {
return err
}
// тут ошибочное использование db вместо tx
row := db.QueryRow(“select * from t where user_id = $1”, 10)
if row.Err() != nil {
return err
}
_ = tx.Commit()
return nil
}Такая ошибка может приводить к deadlock. Транзакция не может завершиться, потому что нужно выполнить запрос. А он не обрабатывается, потому что пул занят и не может выделить ему коннект.
Попытки создать новое соединение внутри транзакции можно отслеживать статическим анализатором. Но только в теории — его пока никто не написал.
У меня есть самописный линтер который я реализовал на одном из внутренних хакатонов в Авито. Он проверяет простейшие случаи. Но профита от него в реальных сценариях мало. Вызов db.Query может оказаться глубоко внутри — например, на десятом уровне вложенности в каком-нибудь репозитории.
Без линтера приходится либо отсматривать, нет ли db.Query() внутри транзакции, либо обкладывать всё тайм-аутами.
Отмена запроса при отмене контекста
Отмена запроса при отмене контекста — не самая очевидная штука в Golang, которая удивляет тех, кто раньше не работал из Go с PostgreSQL. Рассмотрим на конкретном примере.
func getSomeData(ctx context.Context) error {
rows, err := db.QueryContext(ctx, "select * from t")
if err != nil {
return err
}
defer rows.Close()
// ...
return nil
}Здесь мы в db.QueryContext() передаём контекст, который приходит из хэндлера. Если хэндлер отвалится по таймауту, контекст отменится, а это приведёт к отмене запроса.
Давайте разберёмся, почему так происходит, почему мы в итоге отключили этот механизм и как с ним лучше работать.
Почему отменяется запрос при отмене контекста
Возможность отменять запущенный запрос есть наверное в каждой СУБД, это не является чем-то особенным. Этот механизм широко применяется в десктопных клиентах, таких как PgAdmin3/4, psql и DataGrip. Но то, что он применяется ещё и в драйвере go, было большим сюрпризом.
Вот как работает механизм отмены запроса на диаграмме состояния:
Вызываем
db.Query().Отменяем контекст.
Драйвер создаёт новое подключение к базе данных.
Процесс СУБД форкается.
Через новое подключение отправляется cancel-запрос для остановки выполнения ранее запущенного запроса.
Посылается сигнал к оригинальному процессу по PID с запросом на завершение.
Завершённый процесс отправляет ошибку с сообщением об отмене запроса пользователем.
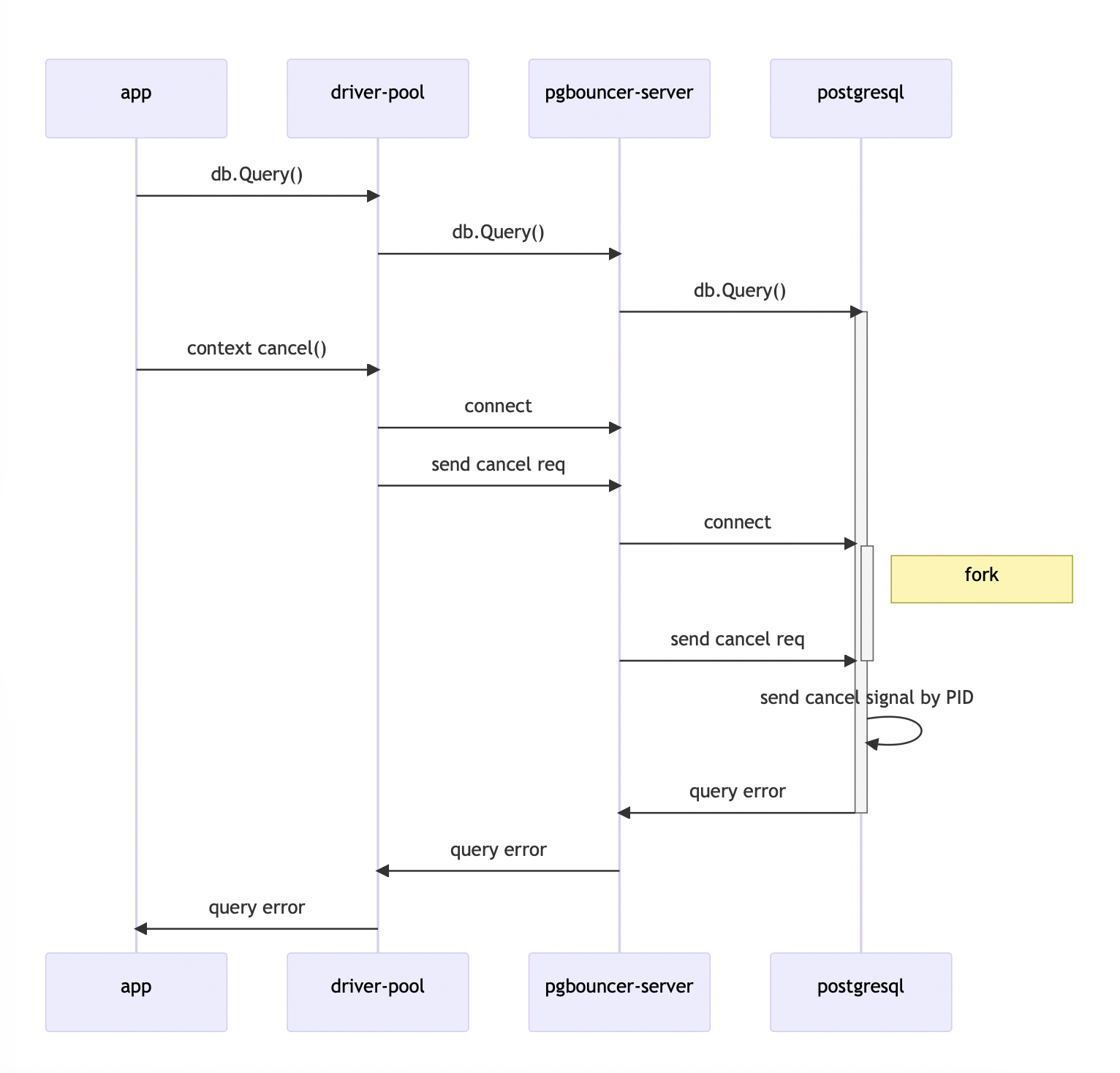
Подробнее о том, как работает этот механизм со стороны СУБД, можно почитать в официальной документации PostgreSQL.
Почему мы отключили отмену запросов
Мы обнаружили очень высокую нагрузку на БД в сервисе объявлений и долго не могли понять, в чём дело. У нас были только логи, заваленные сообщениями об отменённых запросах. Нормальных метрик в PgBouncer тогда ещё не было — они появились только в версии 1.18.0, которая вышла недавно. Хотя даже и добавленных метрик мало.
Оказалось, механизм отмены запроса создавал огромную нагрузку на базу данных. Из-за того, что каждый раз необходимо форкать процесс (шаг 4) и посылать дополнительный сигнал (шаг 5), вся эта процедура занимает много времени.
А ещё периодически отменялся не тот запрос. Поскольку изначально этот механизм был придуман для IDE, никакой проверки на то, нужный ли запрос убивается, нет. Поэтому в быстрых приложениях с высоким RPS эта функциональность работает плохо.
В итоге мы отключили механизм отмены запросов в критических сервисах.
Как обойти отмену запросов в pgx
В Авито мы используем pgx/v3 (deprecated с 2020 года) и pgx/v4. Вот, как мы справлялись с отменой запросов там.
В pgx/v3 можно отключить механизм отмены запросов с помощью пары строчек в коде:
pgx.Config.CustomCancel = func(_ *pgx.Conn) error {
return nil
}В pgx/v4 нельзя отключить механизм отмены запросов. На GitHub по этому поводу есть Issue#679. Там в том числе отметились инженеры Reddit, Adjust, Авито.
Поэтому чтобы обойти отмену запросов в pgx/v4, мы прокидываем пустой или изменённый контекст в запросы:
func getSomeData(_ context.Context) error {
ctx, cancel := context.WithTimeout(context.Background(), 500*time.Millisecond)
defer cancel()
rows, err := db.QueryContext(ctx, "select * from t")
if err != nil {
return err
}
defer rows.Close()
// ...
return nil
}Советы по использованию отмены запросов
Вот, что мы выяснили в процессе работы с отменой запросов, и что советуем вам:
Используйте механизм отмены запросов для OLAP-нагрузки.
Если используете отмену запросов для OLTP-нагрузки, увеличивайте таймаут.
Следите за метриками и нагрузкой при использовании отмены запросов.
Отслеживайте Issues в библиотеках.
Предыдущая статья: Как развивать внутренние сообщества с пользой для компании и людей
Комментарии (15)

guryanov
00.00.0000 00:00Query сильно ухудшает читаемость кода, лучше по-максимуму использовать Select, в котором и ошибиться нереально и занимает он всего 3-4 строчки. Писать-читать такой код очень легко и понятно.

YourChief
00.00.0000 00:00Скажите, пожалуйста, а как так у Вас именованные параметры у функций работают? В вашем коде:
psqlInfo := fmt.Sprintf(format: "host=%s port=%d user=%s "+ "password=%s dbname=%s sslmode=disable", host, port, user, password, dbname)Однако, даже передовая версия компилятора Go не допускает такого синтаксиса: https://go.dev/play/p/OgWVn9Tkc8i?v=gotip

Zuy
00.00.0000 00:00Задам вопрос, раз тут специалисты собрались.
Как правильно организовывать хранение данных в базах для разных аккаунтов?
Вот у меня в системе для каждого аккаунта есть набор таблиц, где накапливаются данные приходящие от разных приборов. Все приборы однотипные, но у каждого аккаунта их разное число и параметры. Далее клиент через приложение может видеть что там накопилось.
Сейчас при создании аккаунта я для нового клиента создаю отдельную БД в PostgreSQL. Потом когда он логинится, получает JWT и далее на каждый REST API запрос, бэкенд по JWT понимает к какой БД подключаться.
Смущает отдельная БД для каждого аккаунта. Это норально или все это делается каким-то другим способом? По нагрузке планируется порядка сотен тысяч клиентов и запросы с периодом раз в 1 или 5 сек.
Timosha Автор
00.00.0000 00:00+1зависит от требований. если надо жёстко изолировать данные одних пользователей от других, то можно сделать под каждого пользователя базу, и даже, отдельные инстансы, только это будет очень очень неэффективно. Зато легко масштабируется.
Есть вариант чуть более эффективный - поиграться с
row_securityвPostgreSQL- но это тоже будет малоэффективно. по сравнению с предыдущим вариантом чуть более эффективно, потому что данные нескольких пользователей можно сгруппировать в одной базе, и чуть поднять "плотность" пользователей.обычно разграничение прав делают на уровне кода, в каждой таблице есть колонка, типа userId и все запросы должны быть в стиле
select * from table where user_id = SOME_USER_ID.Чтобы исключить возможность разработчику случайно, или намеренно, получить доступ к чужим данным можно закрыть прямой доступ к таблицам, а работу с данными организовать через хранимые процедуры которые создаются и изменяются проверенными разработчиками, имеют доступ к таблицам благодаря опции
security definer, принимают на входjwtтокен, и скрывают внутри себя всё операции по получению и изменению данных. Это было бы крутым решением, если бы не планируемые 100k запросов в секунду, для одной физической машины это выглядит многовато, данные придётся шардировать на несколько физических машин, это приведёт к тому чтоjwtтокен придётся заменить наuser_id(чтобы бэкэнд понимал к какому шарду коннектиться для выполнения запросов), а связкуjwt -> user_idпридётся хранить в отдельном сторадже.вот как-то так :)


ErgoZru
00.00.0000 00:00Спасибо за статью! Интересно было бы еще посмотреть на вашу обертку открытия соединений с чтением из vault, и разделяете ли вы соединения с мастером и слейвом, если да то как? 2 соединения и пакет для работы с конкретной базой куда передается 2 соединения и выбирается в зависимости от того что делает метод (читает или пишет). Или реплика только для фейловера (HA), а не для балансировки нагрузки?
По поводу контекста, чтобы копировать, но без cancel можно вытащить код detach метода, вроде так называется, из пакета context (почему он там приватный так и не понял, крайне полезная штука), позволяет копировать контекст (все что в нем, включая трейс, логгер и прочие переменные) не боясь что он отменится (приходилось с таким играться в errgroup).
Люблю разные новые тулзы находить и тут увидел pgeon - что это и где можно почитать? Гугл мне что-то не очень в этом помог :)
Timosha Автор
00.00.0000 00:00+1про
vaultв статье рассказано не совсем полно. на самом деле есть обёртка которая прокидывает секреты изvaultв переменные окружения, и потом уже логины/пароли из переменных окружения используются как параметры для подключения внутриpsql.Connect()про
detach, спасибо, посмотрю внимательнее. ещё я находил https://github.com/goinsane/xcontext/blob/master/xcontext.go#L14 по описанию может пригодиться, но использовать ещё не довелосьpgeon- это часть механизмаCDC(change data capture) и доставки данных в Data Warehouse. если в двух словах - это триггер на таблице который логгирует изменения в pgq-очередь и обвязка над этим механизмом которая позволяет разработчику не задумываться о внутреннем устройстве. В общих чертах я рассказывал об этом на pgConf 2022, но, кажется, организаторы не публиковали видео, и вообще не уверен что опубликуют. Если аудитория проявит интерес к этой теме, то можно подумать о том чтобы рассказать более подробно в одной из статей.ErgoZru
00.00.0000 00:00Спасибо за ответ :) про vault понял. За delay спасибо, не натыкался, посмотрю. Ну и по pgeon надеюсь все таки выложат. Вообще с CDC в пг все сложно))) это не тарантул ????

alekciy
00.00.0000 00:00В pgq-очередь это случайно не на listen/notify ли строится?
Timosha Автор
00.00.0000 00:00Нет, listen/notify для такого не подходят, там нет гарантий доставки, там потеря событий при отсоединении подписчика, и, кажется, есть какие-то ограничения на размер payload. Я, честно говоря, даже и не знаю где можно применять listen/notify, мы в своё время использовали как способ доставки метрик изнутри хранимых процедур, но это было ещё во времена когда много логики было скрыто в них. Вот, кстати, статья, на эту тему https://habr.com/ru/company/avito/blog/323900/.
А что про pgq, то мы используем вот это https://github.com/pgq . Ранее это было частью пакета утилит skytools которым skype в своё время реализовывал логическую репликацию londiste. Мы ранее тоже использовали, но отказались вообще от использования логической репликации в компани.
alekciy
00.00.0000 00:00А отказ от логической по причине скорости? Видимо используется физическая, но каким образом делается обновление серверов, ведь там нужно соблюдать полное совпадение версий РСУБД? Я понимаю когда проект небольшой и серверов несколько штук всего, можно побыстрому стопнуть. Но когда их очень много? Какой путь был выбран? Предположу, что какую-то логику пришлось заложить в PgBouncer.
Timosha Автор
00.00.0000 00:00+1логическая репликация londiste отличная штука, мы научились ей пользоваться там где она действительно нужна, пришлось правда создать достаточно много инструментов вокруг неё чтобы она удовлетворяла нашим требованиям. есть хорошее видео 2017-го года с воркшопа на хайлоаде где Миша, Костя, и Сергей подробно рассказывают как что устроено и что пришлось доработать
https://www.youtube.com/watch?v=vCYGOVa3w1g . Было круто, но... со временем компания выросла, скорость внедрения новых "фич" тоже, и все эти "кастомные" штуки, стали очень дороги в поддержке и скорее мешали, чем помогали. Поэтому целенаправленно пошли в сторону упрощения. И теперь нет никаких логических репликаций средствами DBA, никакого чтения с физических реплик. Реплики только для поддержания High Availability.Не очень понял вопрос про обновление. Если имеется в виду обновление минорных версий, то схема примерно такая, поочерёдно обновляются физические реплики, потом одна из них становится мастером и обновляется оставшаяся реплика. Переключение мастера для приложения выглядит как обрыв коннекта с базой и небольшой даунтайм. С обновлением мажорных версий конечно всё чуточку сложнее, но схема примерно такая же. pgbouncer во всём этом не участвует и работает как простой прокси.
yarkov
Мда... Хабр это не Пикабу. До сих пор про фамилию жены автора никто не спросил ))
P.S. За статью спасибо.