
В дата-центре стоит куча x86-машин и серьёзная хайэндовая система хранения данных (СХД). В филиалах реализована сеть с центральным сервером или мини-кластером (+ резервным сервером и low-end хранилищем), с дисковой корзиной. Бекап общих данных делается на ленте (и вечером в сейф) или же на другой сервак рядом с первым. Критичные данные (финансовые транзакции, например), асинхронно реплицируются в центр. На сервере работает Exchange, AD, антивирус, файловый сервер и так далее. Есть ещё данные, которые не являются критичными для банковской сети (это не прямые транзакции), но всё ещё очень важны — например, документы. Они не реплицируются, но иногда бекапятся по ночам, когда филиал не работает. Через полчаса после окончания рабочего дня все сессии гасятся, и начинается большое копирование.
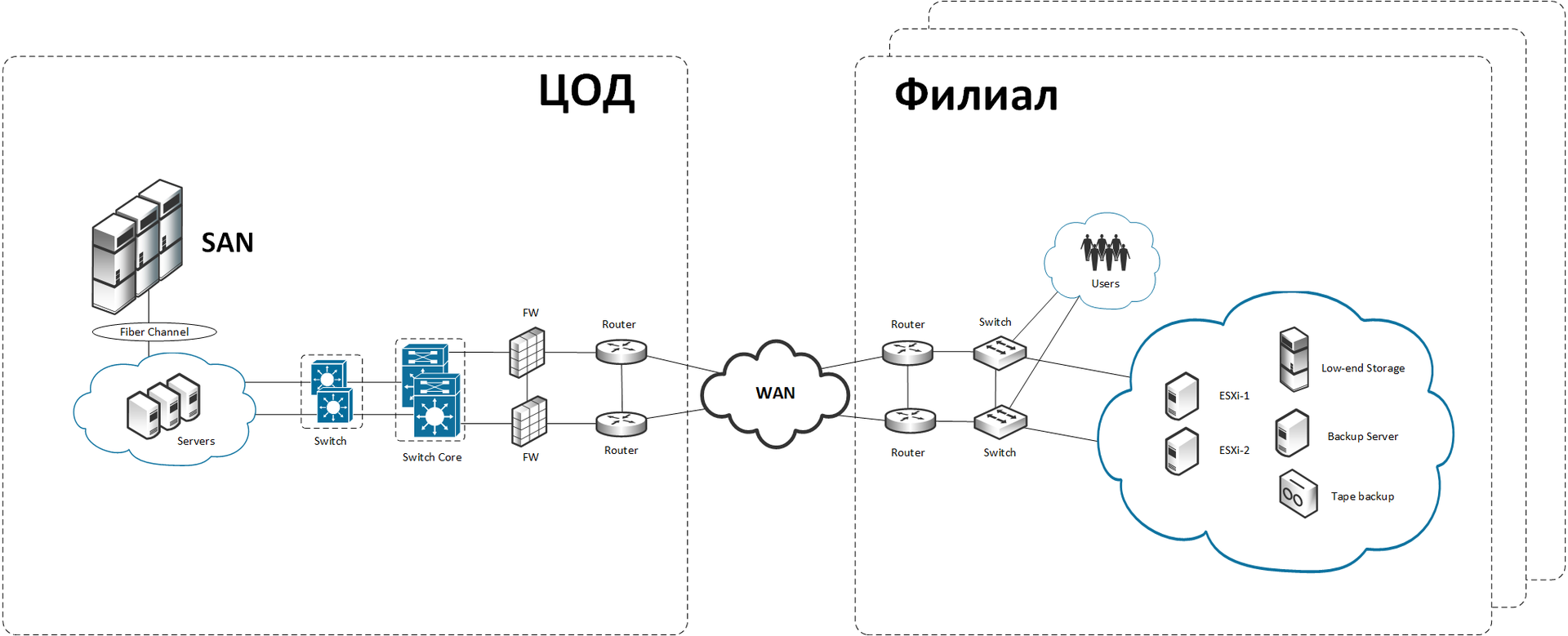
Вот примерно так это было устроено до начала работ
Проблема, конечно, в том, что всё это начинает медленно увеличивать технологический долг. Хорошим решением было бы сделать VDI-доступ (это избавило бы от необходимости держать огромную сервисную команду и сильно облегчило бы администрирование), но VDI требует широких каналов и малых задержек. А это в России не всегда получается элементарно из-за отсутствия магистральной оптики в ряде городов. С каждым месяцем увеличивается количество неприятных «предаварийных» инцидентов, постоянно мешают ограничения железа.
И вот банк решил сделать то, что, вроде бы, дороже по внедрению, если считать напрямую, но сильно упрощает обслуживание серверной инфраструктуры в филиалах и гарантирует сохранность данных филиала: консолидировать все данные в одну центральную СХД. Только не простую, а ещё с умным локальным кэшем.
Исследование
Естественно, мы обратились к мировому опыту — всё-таки такие задачи решались уже несколько раз для горнодобывающих компаний наверняка. Первой нашлась корпорация Alamos Gold, которая копает золото в Мексике и разведывает месторождения в Турции.
Данные (а их довольно много, особенно сырых от геологоразведки) нужно передавать в головной офис в Торонто. WAN-каналы узкие, медленные и часто зависят от погоды. В итоге они писали на флешки и болванки и отправляли данные физической почтой или физическими курьерами. ИТ-поддержка была натуральным «сексом по телефону», только ещё с поправкой на 2–3 языковых прыжка через переводчиков. Из-за необходимости сохранять данные локально одно только повышение скорости WAN не решило бы проблемы. Компания Alamos смогла избежать затрат на развёртывание физических серверов на каждом руднике, использовав Riverbed SteelFusion — специализированное устройство Riverbed SFED, совмещающее возможности повышения скорости WAN, среду виртуализации Virtual Services Platform (VSP) и решение SteelFusion для периферийной виртуальной серверной инфраструктуры (edge-VSI). VSP дал локальные вычислительные ресурсы. Без модернизации каналов удалось после получения мастер-слепка тома нормально передавать данные туда-сюда. Окупаемость инвестиций — 8 месяцев. Появилась нормальная процедура аварийного восстановления.
Начали ковырять данное решение и нашли у производителя железа ещё два случая, почти в точности описывающих нашу ситуацию.
Корпорации Bill Barrett Corporation понадобилось обновить оборудование на удалённых площадках, она сначала рассматривала традиционное решение на «половину стойки», которое стоило дорого, но не решило бы многих текущих проблем. Кроме того, скорее всего, потребовалось бы увеличить полосу пропускания канала к этим площадкам, что в два раза увеличивало расходы. Высокие затраты — не единственный недостаток этого подхода. ИТ-квалификация персонала на удалённых площадках была ограничена, а предполагаемое решение требовало, чтобы кто-то управлял серверами, коммутаторами и оборудованием резервного копирования. Поставили тоже Riverbed SteelFusion, в итоге кейс получился втрое дешевле традиционного решения, а места в стойках — существенно меньше.
Юридическая фирма Paul Hastings LLP разрасталась, открывая офисы в Азии, Европе и США, увеличивалось и количество её центров обработки данных (четыре центральных ЦОДа и множество небольших ЦОДов на 19 офисов). Хотя такая архитектура и обеспечивала работоспособность удалённых офисов, но для каждого ЦОДа был нужен менеджер и 1–2 аналитика, а также физические хост-серверы и ленточные системы резервного копирования. Это требовало больших затрат, а в некоторых регионах защита данных была не такой надёжной, как фирме хотелось бы. Решили так же, только вторым мотивом была безопасность.
Соответственно, просчитали это и ещё пару вариантов в традиционных архитектурах и показали заказчику. Заказчик долго думал, считал, задал кучу вопросов и выбрал этот вариант с условием тестового развёртывания одного «филиала» (до закупки железа основного проекта) на тестовых же базах.
Вот что мы сделали
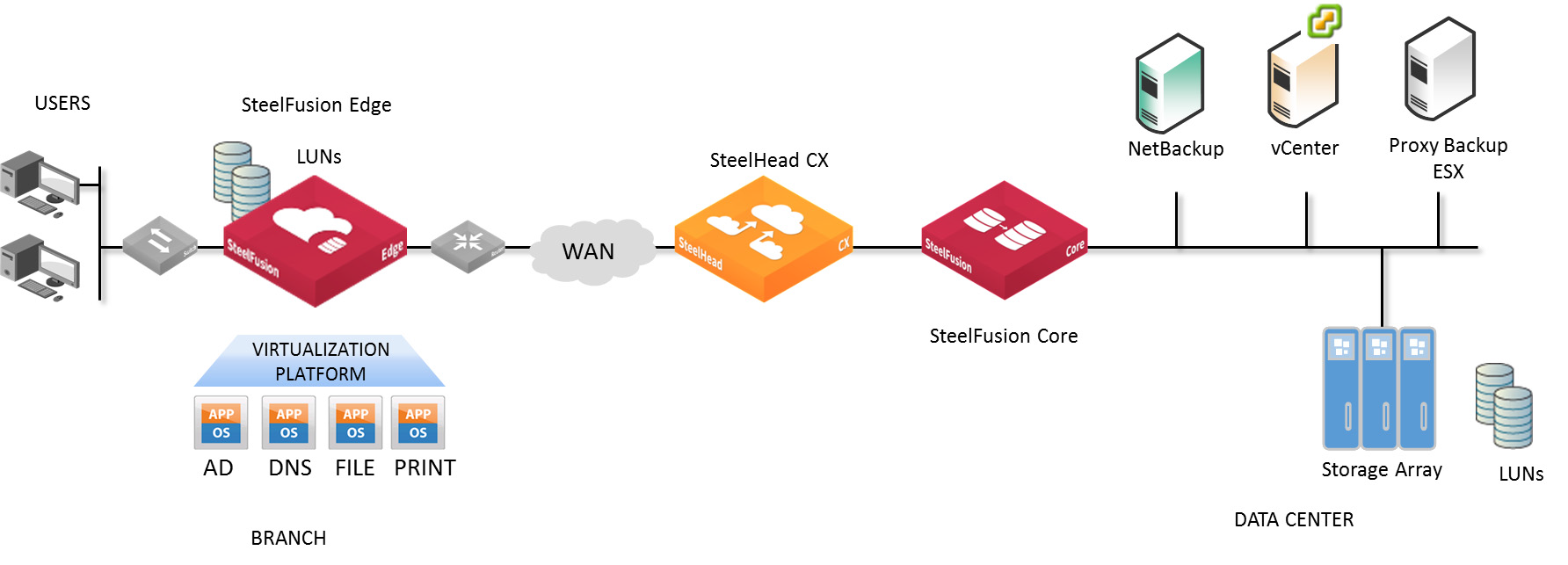
Мы не имеем возможности менять каналы, но можем ставить железо и на стороне ЦОДа, и на стороне филиала. СХД в дата-центре нарезана на множество томов, и с 2–4 из них работает каждый филиал (связь инъективная: с одним и тем же томом не может работать несколько филиалов). Дисковые полки и немного серваков на местах выкидываем, они в роли СХД и контроллеров репликации уже не нужны. В дата-центре мы ставим простые оптимизаторы трафика Riverbed Steelhead CX + виртуальные устройства SteelFusion Core, на местах устанавливается пара Riverbed SFED (SteelFusion Edge).
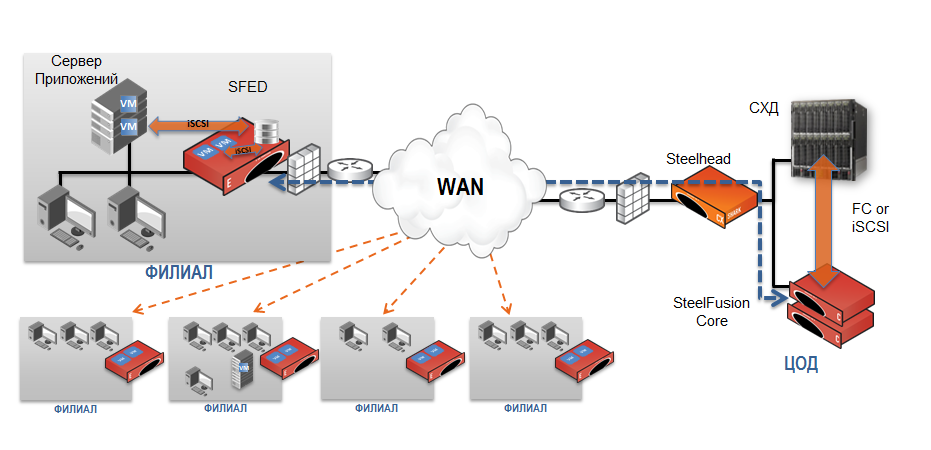
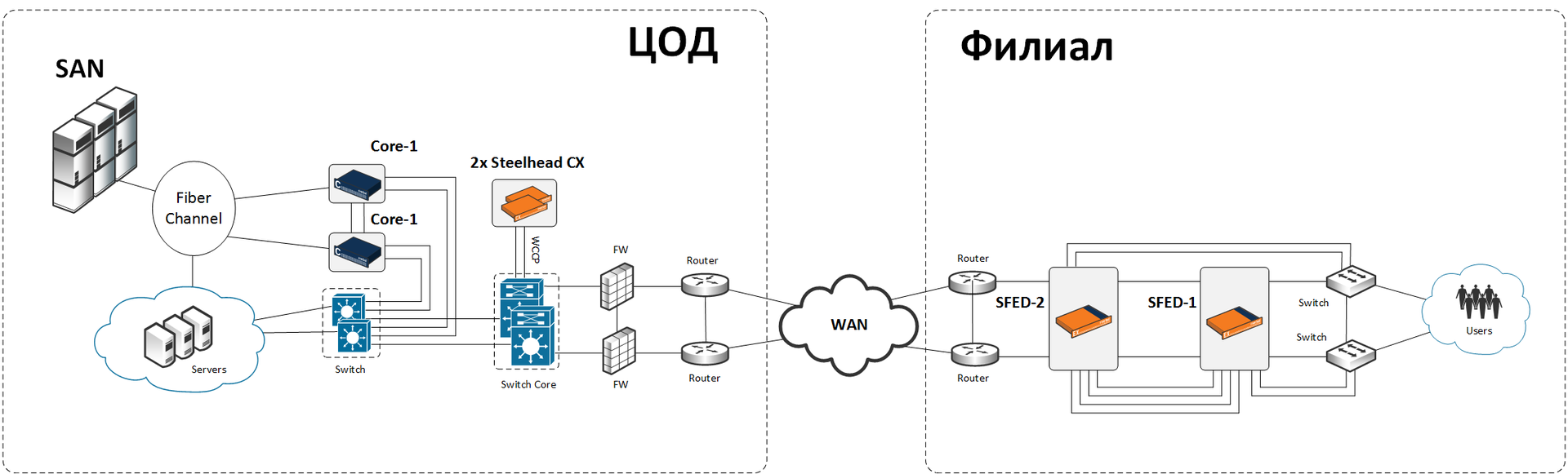
Раньше серверы работали с данными, находящимися локально (на локальных дисках или на low-end СХД). Теперь серверы работают с данными центрального СХД через локальную проекцию LUN-ов, обеспечиваемую SteelFusion. При этом серверы «думают», что работают с локальными томами в локальной же сети филиала.
Основная железка филиала называется Riverbed SFED (SteelFusion Edge), она состоит из трёх компонент. Это SteelHead (оптимизация + сжатие трафика), SteelFusion Edge (элемент системы централизации данных) и VSP (виртуализация встроенным гипервизором ESXi).
Что получилось
- Адресация для филиала — единая LAN с центральной СХД (точнее, парой её томов). Сервера обращаются к центральной СХД как к инстансу внутри LAN.
- При первом запросе блоки данных начинают транслироваться из центра до филиала (медленно, но только один раз). Забегая чуть вперёд — мы используем режим Pin the LUN, когда кэш (blockstore) равен размеру LUN, то есть сразу снимаем полный слепок данных с центральной СХД на первом запуске.
- При любом изменении данных на нашей стороне они встают в очередь на синхронизацию и сразу же становятся доступными «как будто в центре», но из кэша SteelFusion Edge, расположенного локально.
- При трансфере данных в любую из сторон используется эффективное сжатие, дедупликация и оверрайды протоколов для их оптимизации (громоздкие и «болтливые» протоколы транслируются устройствами в оптимизированные для узких каналов с большой задержкой).
- В общем случае все данные всегда хранятся в системе хранения данных в центральном дата-центре.
- «На десерт» появился крутой префетчинг на уровне блоков. Читая содержание блоков и применяя знания о файловых системах, SteelFusion способен определить, что OS фактически делает (например, загружается, запускает приложение, открывает документ). Затем она может определить, какие блоки данных понадобятся для чтения, и загружает их, прежде чем ОС их запросит. Что гораздо быстрее, чем делать всё последовательно.
На практическом уровне софт заработал почти без задержек, репликация по ночам забыта как страшный сон. Ещё одна особенность — в центре реально все данные филиала. То есть если раньше на локальных дисках могли быть традиционно «файлопомоечные» сканы документов, презентации, разные некритичные документы и всё то, что дорого обычным пользователям, — теперь оно тоже лежит в центре и тоже легко восстанавливается при сбоях. Но об этом и повышении отказоустойчивости чуть ниже. И естественно, одну СХД обслуживать куда проще, чем десяток. Больше никакого «секса по телефону» с «программистом» из далёкого небольшого городка.

Монтируются они вот так:
Что получилось:
- Так называемые квазисинхронные репликации (это когда для филиала они выглядят как синхронные, а для центра — как быстрые асинхронные).
- Появились быстрые и удобные точки восстановления до минут, а не «минимум на сутки назад».
- Ранее при пожаре в филиале была утеряна локальная файловая шара и почта сотрудников города. Теперь всё это тоже синхронизируется и при аварии не потеряется.
- Новая коробка упростила все процедуры branch recovery — новый офис разворачивается на новом железе за считанные минуты (точно так же разворачивается новый город из готовых образов).
- Пришлось убрать из инфраструктуры серваки на местах, плюс выкинуть малые ленточные накопители для бекапа тоже на местах. Вместо этого было докуплено железо Riverbed, дозаполнена дисками центральная СХД и куплена новая большая ленточная библиотека для бекапа, установленная в другом московском дата-центре.
- Улучшилась безопасность данных благодаря единым и легко контролируемым правилам доступа и более стойкому шифрованию канала.
- При катастрофе филиала, сопровождающейся уничтожением инфраструктуры, появилась простая возможность запустить виртуальные сервера в самом ЦОДе. В результате чего стремительно уменьшаются RTO и RPO.
Что бывает при коротком обрыве связи?
В текущей инфраструктуре — ничего особенного. Данные продолжают записываться в кэш SFED, при восстановлении канала синхронизируются. Пользователям при запросе «в центр» отдаётся локальный кэш. Стоит добавить, что проблема «шизофрении» не возникает, поскольку доступ к LUN-у есть только через SFED конкретного филиала, то есть со стороны ЦОДа в наш том никто не пишет.
Что бывает при обрыве связи больше 4 часов?
При длительном обрыве связи может наступить такой момент, когда локальный кэш SFED заполнится, и файловая система будет сигнализировать о том, что места для записи недостаточно. Нужные данные не смогут быть записаны, о чем система предупредит пользователя или сервер.
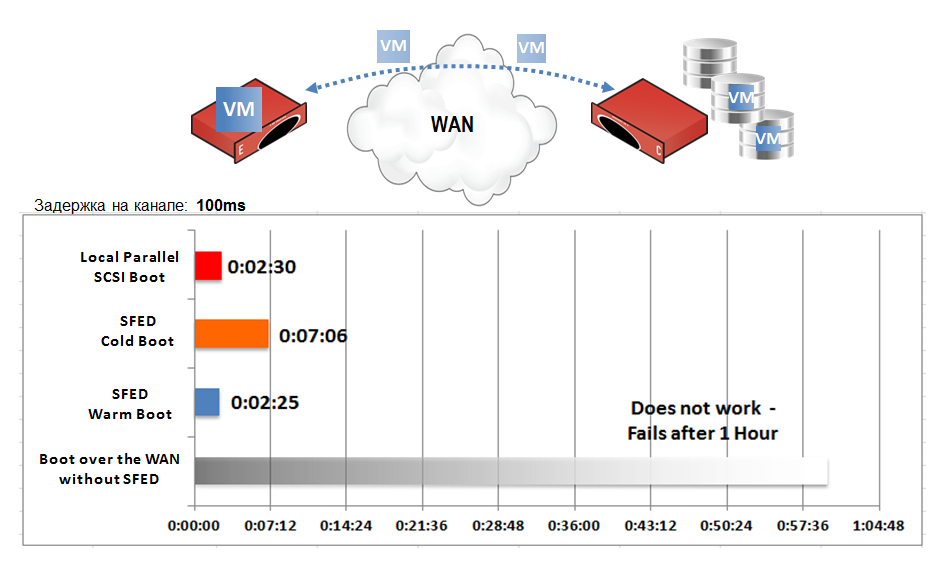
Мы несколько раз тестировали такую схему аварийного филиала в Москве. Расчёт времени такой:
- Время доставки ЗИП.
- Время начальной конфигурации SFED (< 30 минут).
- Время загрузки ОС виртуальных серверов через канал связи при пустом кэше.
Время загрузки Windows на канале связи с задержками в 100 миллисекунд составляет менее 10 минут. Фишка в том, что для загрузки ОС не нужно ждать, пока все данные с диска C будут переданы в локальный кэш. Загрузку ОС, естественно, ускоряют интеллектуальный поблочный префетчинг, о котором говорилось выше, и продвинутая оптимизация Riverbed.
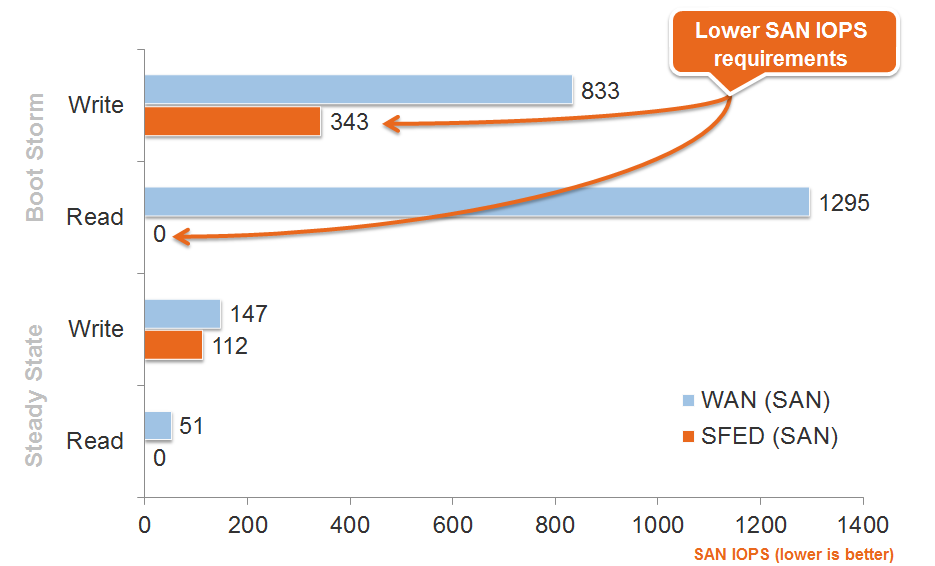
Нагрузка на СХД
Естественно, падает нагрузка на центральную СХД, ведь большая часть работ ложится на устройства в филиалах. Вот картина от производителя на тестах оптимизации работы СХД, ведь к ней теперь куда меньше обращений:
Пояснение про режимы квазисинхронной репликации
До этого я говорил про Pin the LUN, когда кэш равен LUNу. Поскольку кэш на устройствах в филиалах не апгрейдится (нужно покупать новую железку или ставить вторую рядом, и к тому моменту, когда это потребуется — через 4–5 лет, они уже будут нового поколения, скорее всего), нужно учесть и требование резкого повышения количества данных в филиале. Плановое рассчитано и уложено на много лет вперёд, а вот неплановое будет решаться переключением в режим Working Set.

Это когда blockstore (локальный кэш-словарь) меньше данных филиала. Обычно доля кэша в сравнении с общим количеством данных — 15–25%. Здесь нет возможности работать полностью автономно, используя кэш как копию центрального LUNа: в этот момент в режиме отказа канала связи запись идет, но ставится в буфер. Канал восстановится — отдадим запись в центре. При запросе блока, которого нет в локальном хранилище, генерируется обычная ошибка соединения. Если блок есть — данные отдаются. Я предполагаю, что через те 5 лет, когда объём данных превысит ёмкость кэша филиалов, админы не будут докупать железо, а просто централизуют почту и переведут файлшару в режим Working Set, критичные данные оставят в режиме Pin the LUN.
И ещё одно. Доукомплектация вторым SFED создаёт отказоустойчивый кластер, что также может быть важно в перспективе.
Тесты и опытная эксплуатация
Мы делали такое достаточно необычное объединение и виртуализацию СХД впервые — от других проект отличается именно настройкой локальных blockstore, увязанных в ПАК с оптимизаторами трафика и серверами виртуализации. Я несколько раз разваливал и собирал кластеры из устройств, чтобы посмотреть возможные проблемы в процессе. Пару раз на существенном перекофигурировании поймал полный прогрев кэша на филиале, но нашёл способ обходить это (когда не требуется). Из подводных камней — достаточно нетривиально делается полное обнуление blockstore на одном конкретном устройстве, этому лучше научиться на тестах до работы с боевыми данными. Плюс на тех же тестах поймали один экзотический креш ядра на центральной машине, детально описали ситуацию, отправили производителю, они прислали патч.
По времени восстановления — чем шире канал, тем быстрее данные восстановятся в филиале.
Важно, что ядро не даёт возможности в приоритете отдавать данные конкретным SFED, то есть операции СХД и каналы используются равномерно — дать «зелёный» на быстрый трансфер данных в упавший филиал средствами этого ПАК не выйдет. Поэтому ещё одна рекомендация — оставлять небольшой запас мощности СХД для таких случаев. В нашем случае мощности СХД хватает за глаза. Тем не менее, можно конфигурациями QoS на тех же SteelHead или других сетевых устройствах выделить полосу пропускания под каждый филиал. И с другой стороны, ограничить трафик синхронизации SteelFusion, чтобы не страдал трафик централизованных бизнес-приложений.
Второй по важности — устойчивость к обрывам. Как я понимаю, голос за проект добавили и их безопасники, которым идея держать все данные в центре пришлась очень даже по душе. Админы рады, что больше не летают на места, но, конечно, некоторая часть локальных «эникеев» пострадала, потому что ленту и серваки уже не надо было обслуживать.
Сама по себе вот эта архитектура на железе Riverbed позволяет ещё делать кучу всего, в частности, шарить принтеры по городам, делать не совсем обычные прокси и файрволлы, использовать серверные мощности других городов для больших просчётов и т. п. Но нам в проекте это не требуется (по крайней мере пока), поэтому остаётся только порадоваться и удивляться, сколько ещё фич можно наковырять.
Железо
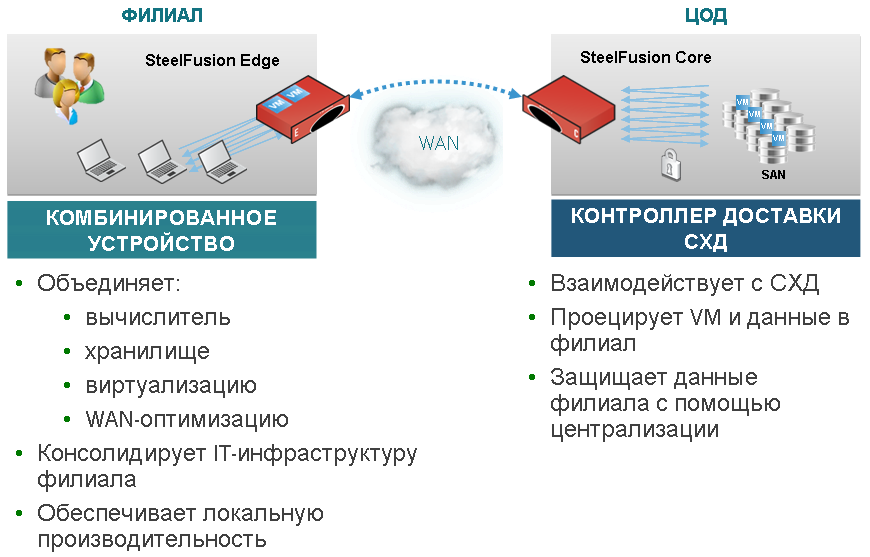
SteelFusion Edge: конвергентное устройство, которое объединяет сервера, хранилища, сеть и виртуализацию для работы локальных приложений филиала. Никакая другая инфраструктура в филиале больше не требуется.
SteelFusion Core: контроллер доставки СХД размещается в ЦОДе и взаимодействует с СХД. SteelhFusion Core проецирует централизованные данные в филиалы, устраняя бекапы в филиалах, и обеспечивает быстрое разворачивание новых филиалов и восстановление после катастроф.
Ссылки
Собственно, возможно, вам будет ещё интересно узнать:
- Про базовое использование оптимизаторов трафика с локальным blockstore.
- Практическое решение по оптимизации трафика там, где не надо было делать скорости LAN в филиалах (спутниковые каналы).
- Про сетевой детектив с поиском аномалии (это был учебный детектив, никто не пострадал).
- Вот тут можно скачать общее описание решения и вариантов применения от вендора (но там придётся заполнить форму с почтой).
- И моя почта, если ваш вопрос не для комментариев, или если вам нужно предварительно прикинуть стоимость похожего решения для себя: AVrublevsky@croc.ru
- Ещё послезавтра, 12 ноября, мы проводим вебинар про то, как уменьшить затраты на эту часть ИТ-инфраструктуры. Там всё подробно, с практическими выкладками и с обзором разных вариантов действий.
Комментарии (12)

BAV_Lug
10.11.2015 14:30+1А мне импонирует подход который внедрил украинский приватбанк. Они вынесли работу отделений полностью в веб. В результате локально в принципе ничего не хранится.
AVrublev
10.11.2015 15:15+2Если Приватбанк полностью отказался от файловых шар, централизовал Exchange, переложил все бизнес приложения на WEB — это замечательно! Однако стоит сравнить размеры Украины и России, как станет понятно, что в России это будет практически невозможно. Задержки протяженных каналов связи настолько замедлят работу, что встанет вопрос о целесообразности данной миграции. Хотя с другой стороны обычные оптимизаторы трафика Riverbed отлично справляются с задачей ускорения HTTP на каналах с большими задержками (в том числе спутниковых). В общем вычислитель должен быть в LAN-сети, иначе LAN-скорости попросту не получить.

Botkin
11.11.2015 08:33Спасибо за информацию, я даже не подозревал о существовании подобного класса устройств. Скажите, есть ли аналоги Riverbed в этой сфере? И есть ли у Riverbed железки для очень маленьких бранчей в 15-20 человек?

BigD
11.11.2015 08:59Bluecoat возможно и Citrix.
AVrublev
12.11.2015 10:41Вы имеете ввиду оптимизаторы bluecoat и citrix? Или citrix VDI? Это совсем другие решения. Идея вынести из филиалов/отделений данные приложений в ЦОД, а вычислительные мощности приложений оставить на периферии реализована только Riverbed-ом. Прямых аналогов этому решению нет.
AVrublev
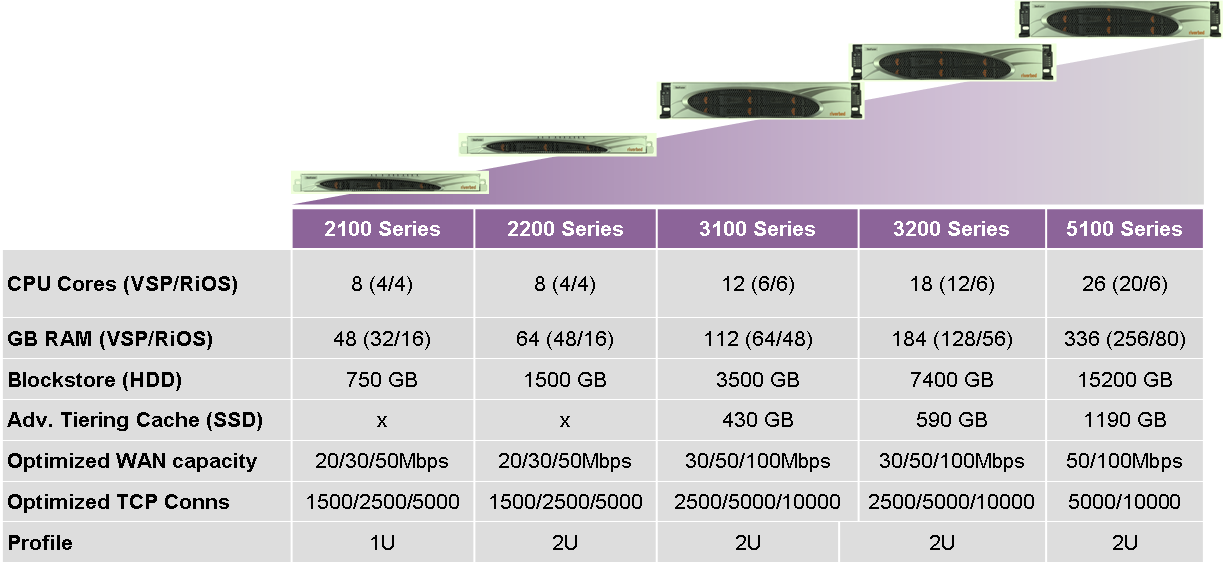
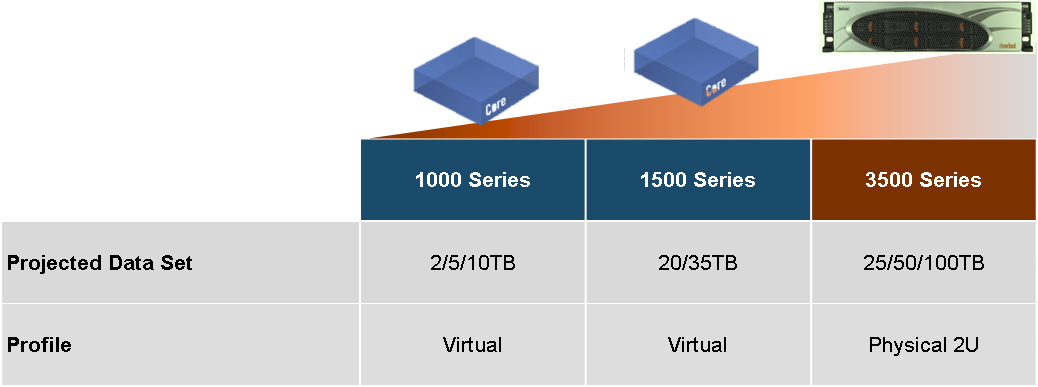
12.11.2015 10:40Прямых налогов нет. Это действительно уникальное решение. Недавно Riverbed обновили линейку подобных устройств. Теперь самая маленькая железка этого класса SFED-2100. Вы можете посмотреть её характеристики на картинке в посте. Чтобы подобрать подходящую железку недостаточно просто кол-ва пользователей. Нужны подробности: кол-во серверов которые требуется на ней запустить, требования по железу у каждой VM, количество данных которые ежедневно записываются на диски/СХД пользователями филиала, полоса пропускания канала связи, требования к IOPS, количество соединений которые нужно оптимизировать, полоса пропускания канала связи и тд.

TimsTims
А точно «сотни филиалов»? Что-то не знаю ни одного банка, у которого было бы больше 100 филиалов, разве что Сбер может быть) да и тот филиальную структуру еще несколько лет назат укрупнял, объединяя филиалы.
Возможно, имелось ввиду сотни отделений банков?
htol
Вот например альфа под 1000 филиалов/отделений. И это далеко не самый крупный банк.
TimsTims
Все отделения банков принадлежат какому-то филиалу.
Филиал != отделение
Филиал=>отделения
У альфы всего 7 филиалов http://www.cbr.ru/credit/coinfo.asp?id=450000036
BAV_Lug
Мне кажется, в контексте данной статьи это не принципиально, и вы просто цепляетесь к словам.