

Битрикс24 — корпоративное SaaS-решение (Software as a Service, программное обеспечение как услуга), которым пользуются компании разного масштаба и профиля для коммуникации между сотрудниками, хранения файлов, документов, ведения CRM. Битрикс24 используют тысячи клиентов, каждый из которых генерирует и хранит на базе сервиса гигабайты и даже терабайты данных. Для их хранения используется объектное S3-хранилище Cloud Storage от VK Cloud.
Директор направления облачных сервисов Битрикс24 Александр Демидов рассказал команде VK Cloud, зачем понадобилось S3-хранилище, как его внедряли и интегрировали в архитектуру облачного сервиса Битрикс24.
Предпосылки использования S3
До выхода на рынок сервиса Битрикс24 в 2012 году мы предлагали коробочное решение «Корпоративный портал», которое клиенты могли скачать и развернуть на своих мощностях. Оно оказалось удобным для развертывания и полностью решало задачи пользователей.
Со временем мы заметили, что коробочное решение подходит не всем: оставался большой сегмент клиентов, которым был интересен наш продукт, но они не могли его использовать из-за отсутствия своей инфраструктуры/ИТ-специалистов или просто не хотели брать администрирование на себя. Видя запрос, мы решили переработать «Корпоративный портал» и запустить на его базе облачный сервис. Так появился Битрикс24.
С переходом к SaaS-решению нам надо было тщательно проработать архитектуру сервиса. Для нового продукта мы хотели использовать облачную инфраструктуру: было важно быстро получать нужные ресурсы и не отвлекаться постоянно на задачи администрирования, которые прямо не относятся к продукту, а являются побочными.
При выборе облачных сервисов под Битрикс24 один из акцентов мы делали на поиск оптимального решения для хранения данных. Почему?
- В коробочной версии каждый клиент хранит данные (отчёты, таблицы, внутреннюю документацию, планы, другие файлы и данные) в своём хранилище. 100 ГБ или 1 ТБ — не важно. Всё ограничивается масштабом собственной инфраструктуры. При выборе облачного сервиса клиент делегирует задачи хранения данных провайдеру. Их размещение — наша задача. С учётом количества клиентов и динамики их прироста нам нужно было хранилище, которое можно масштабировать практически бесконечно.
- В облачном сервисе, в отличие от коробочной On-prem-версии, важна динамичность масштабирования: каждая отдельная компания может прогнозировать рост объёма хранения. Но мы не можем предугадать, как он будет изменяться у всех клиентов в каждый момент времени. То есть нужно не просто облачное хранилище, а такое, которое может быстро масштабироваться под текущие нагрузки.
- Для всех пользовательских данных необходимо использовать внешнее хранилище, которое не связано с серверами приложений и кодом.
Резюмируя: мы нуждались в бесконечном облачном хранилище, которое можно было использовать из любого региона, где размещался бы наш продукт.
Под эти требования без развёртывания собственной инфраструктуры подходило только объектное S3-хранилище — облачный сервис для хранения файлов любого типа и объёма, вне зависимости от их структурированности.
S3 было доступно и облаке Amazon, на основе которого изначально строился весь сервис. Поэтому в качестве основного хранилища мы выбрали Amazon S3. Одновременно с этим на уровне кода продукта мы обеспечили поддержку любых S3-хранилищ для всех версий — как On-prem, так и облачного сервиса.
Реализация хранилища на основе S3
При построении архитектуры решили развернуть общее низкоуровневое хранилище для всех компонентов экосистемы Битрикс24. Такая реализация позволяет пользователям строить собственное файловое хранилище во внутреннем контуре Битрикс24 и пользоваться файлами из него при работе с любым компонентом экосистемы: мессенджером, CRM, задачами и другими.
Такое хранилище было построено на основе Amazon S3. Оно способно принимать петабайты данных и выдерживать миллионы запросов. Доступ к хранилищу организован через Bitrix Framework.

А благодаря внедрённой на уровне кода совместимости пользователь коробочного Битрикс24 может подключить S3-хранилище другого вендора или выбрать другой вариант хранения: для пользователей On-prem-решений выбор почти не ограничен.
Локализация, или Переход в российское цифровое пространство
Amazon S3 был основным хранилищем для Битрикс24 несколько лет. Но с ростом количества клиентов и объёма хранимых данных стало очевидно, что для российских клиентов сервиса оптимально перейти на объектное хранилище российского вендора. Предпосылок к этому было несколько:
- Вступление в силу закона № 242-ФЗ. Он предусматривает локализацию баз персональных данных (ПД): ПД граждан РФ должны храниться и обрабатываться на территории Российской Федерации. Файлы в Битрикс24 не относятся к персональным данным, но, поскольку вся инфраструктура для клиентов уже была локализована в России, мы решили перенести и файлы.
- Скорость отклика зависит от удалённости центральных серверов с данными. Чем дальше клиент, тем больше задержки. Чтобы обеспечить быстрый доступ к данным и высокую скорость скачивания, хранилище должно быть расположено в России.
- Для исключения риска сбоев и потери данных важно организовать резервное копирование на уровне двух провайдеров. Репликация существенно повышает отказоустойчивость: клиенты не заметят, даже если на стороне одного из провайдеров будут сбои.
У нас было около одного петабайта данных, поэтому требовалось надёжное и масштабируемое хранилище. Нам хотелось не купить решение, разработанное специально под нас, а найти провайдера, который предоставляет хранилище как сервис в публичном облаке. Это позволило бы снизить затраты на размещение данных и быть уверенными в стабильной работе.
Но основным фактором при выборе российского объектного хранилища были технические требования. Так как на уровне продукта, платформы и фреймворка в Битрикс24 уже была реализована поддержка всего API Amazon S3, было важно, чтобы решение российского провайдера было совместимо с S3 по API. Зависимость простая: чем шире совместимость, тем меньше изменений кода требуется при миграции.
Кроме того, протокол работы с Amazon S3 сложный. В нём изначально прописаны компоненты и функции вроде Multipart Upload, выставления пользовательских свойств, попытки многократного повторения операций в случае ошибок и другие. Для удобства работы с объектным хранилищем у Amazon есть клиентская библиотека, протоколы в которой можно легко переделать под свои задачи, в том числе для миграции на другие платформы. Многим из этого мы пользовались. Поэтому, чтобы продолжать работу с готовыми и преднастроенными протоколами, которые мы уже задействовали, новая платформа тоже должна была поддерживать клиентские библиотеки. В таком случае настройка при миграции свелась бы к замене небольшого количества параметров.
После сравнения всех вариантов российских объектных хранилищ с поддержкой готовых клиентских библиотек и совместимостью с S3 по API выбрали Cloud Storage от VK Cloud — никто другой не был готов сразу разместить петабайт данных и обеспечить выполнение наших запросов.
Процесс внедрения Cloud Storage от VK Cloud
Интеграция Cloud Storage — объектного хранилища S3 от VK Cloud — началась в 2017 году. Она проходила в несколько этапов.
Тест
Перед внедрением хранилища было важно убедиться в реальном соответствии заявленным нами требованиям. Лучший способ для этого — тест. Мы подключили Cloud Storage к Битрикс24 и провели:
- синтетические тесты;
- тесты на совместимость с нашим API.
Результаты синтетических тестов нас полностью устроили. Проверка показала, что Cloud Storage не только совместим на уровне базовых API, но и поддерживает нужные нам сложные функции вроде Multipart Upload. Пользовательские свойства, заголовки, возвращение ошибок в случае перегрузки, превышение лимитов — в Cloud Storage всё есть «из коробки». Это позволило обеспечить бесшовную миграцию.
Развёртывание хранилища для бэкапов
Для снижения рисков при переходе на Cloud Storage миграция была поэтапной. Первый из этапов — совместное использование S3-хранилищ от разных вендоров:
- Amazon S3 — в качестве основного;
- Cloud Storage — в качестве резервного для хранения бэкапов.
Для этого мы задействовали механизм репликации данных в реальном времени из Amazon S3 в Cloud Storage: все файлы, которые попадали в Amazon S3, на лету копировались в Cloud Storage. Сначала для отладки процесса мы запустили репликацию только новых файлов. Она выполнялась кодом в Lambda по срабатыванию триггеров в S3: ObjectCreated и ObjectRemoved. Код написан на Java — изначально использовали Node.js, но отказались от него из-за частой потери событий.

После подтверждения корректности репликации была запущена синхронизация всех имеющихся клиентских файлов — около петабайта данных, 1,5 млрд объектов. В итоге Cloud Storage стал полностью синхронизированным и пополняемым резервным хранилищем.
Полный переход на Cloud Storage
После переноса всех файлов клиентов в Cloud Storage мы провели нагрузочные тесты, проверили производительность и пропускную способность S3-хранилища. Результаты не отличались от первичных тестов.
На следующем этапе работа с файлами для клиентов на уровне кода и продукта была постепенно переведена на хранилище Cloud Storage: сначала для небольшой группы с целью проверки корректности и отладки всех процессов, а потом для всех пользователей.
Репликация данных из Cloud Storage в Amazon S3
Для обеспечения надёжности хранения и доступности файлов Cloud Storage мы также предусмотрели и обратную схему синхронизации. В таком случае Cloud Storage используется в качестве основного хранилища, а Amazon S3 — для хранения бэкапов.
Актуальная архитектура решения и принцип взаимодействия с S3
В итоге схема работы с несколькими провайдерами объектных хранилищ выглядит следующим образом:
- S3-хранилище доступно на всех уровнях архитектуры. Оно отвечает за получение и хранение файлов, обработку всех поступающих событий.
- При репликации из Amazon S3 в Cloud Storage события о работе с файлами в bucket-е передаются в автомасштабируемые лямбда-функции Amazon, где Java-обработчик сразу копирует их или направляет в очередь доставки. События обрабатываются асинхронно. Одновременно на серверах Битрикс24 подняты обработчики очередей, которые пересылают большие файлы и события DLQ (Dead Letter Queue, очередь недоставленных сообщений). Сейчас в Cloud Storage хранится около трёх петабайт данных и более четырёх млрд объектов.
- Для обработки событий о работе с файлами в Cloud Storage на стороне Битрикс24 подняты воркеры. Они используют асинхронно-неблокирующую библиотеку Java Netty «на 200 %» для многопоточной интенсивной заливки файлов из Cloud Storage в Amazon S3. По сути, мы своими силами воспроизвели архитектуру лямбда-сервиса Amazon над хранилищем Cloud Storage на связке Java/Netty/очереди.
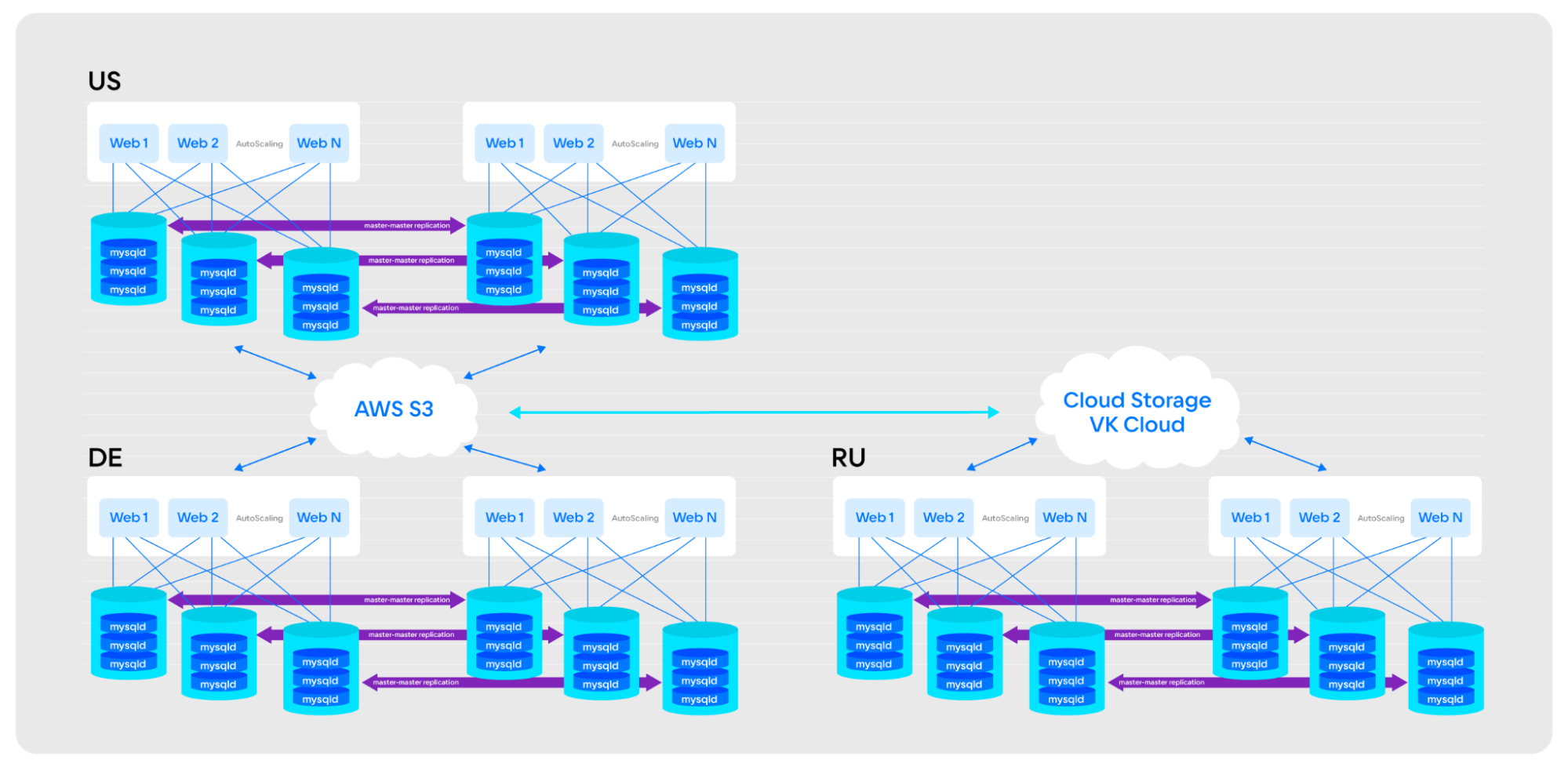
При этом:
- На серверах приложений нет пользовательского контента, все ноды абсолютно идентичны.
- Пользовательские данные не пишутся и не сохраняются на веб-нодах, так как в любой момент времени любая машина может быть выключена, или стартует новая из «чистого» образа.
- Статические данные пользователей хранятся в облачном хранилище.
- Для каждого созданного портала использованы отдельные токены для доступа к данным только этого портала: данные каждого портала полностью изолированы друг от друга.
Этот высоконагруженный сервис мы контролируем с помощью сбора и анализа десятков метрик. Это позволяет нам отслеживать динамику работы всех компонентов архитектуры и предупреждать любые сбои до их появления.
Наша выгода от локализации хранилища и построения Multicloud
Локализация данных пользователей и, как следствие, реализация мультиоблачной стратегии позволили получить несколько значимых преимуществ:
-
Независимость от одного провайдера. Поскольку мы используем услуги разных вендоров, сервис не остановится, даже если один из них прекратит работу.
-
Повышение надёжности и отказоустойчивости сервиса. Репликация данных между Amazon S3 и Cloud Storage повысила отказоустойчивость сервиса и позволила гарантировать доступность файлов, даже если на стороне одного из вендоров произойдёт сбой.
-
Повышение доступности файлов. Миграция позволила повысить скорость работы Битрикс24 и скорость доступа к файлам в хранилище для пользователей. Сейчас параметры доступности зависят во многом от скорости клиентского подключения.
Главные выводы из нашего опыта
- Объектные хранилища отлично подходят для построения высоконагруженных сервисов, способны хранить петабайты данных, обеспечивать доступность файлов и высокую скорость работы сервиса при любой динамике нагрузки.
- Благодаря возможности одновременной обработки тысяч запросов и высокой пропускной способности на базе S3 можно строить низкоуровневые хранилища, доступные сразу нескольким независимым сервисам. В нашем случае этот сценарий полностью себя оправдал.
- Чем ближе хранилище к конечному пользователю, тем лучше. Пользовательские файлы в Битрикс24 не относятся к категории персональных данных и не требуют хранения на территории РФ, но мы локализовали хранилище для данных пользователей. В результате получили независимость от вендоров, повысили надёжность сервиса и доступность файлов.
- Внедрять новый компонент архитектуры следует пошагово. Мы разделили весь процесс подключения Cloud Storage от VK Cloud на несколько этапов с постоянными проверками. Это позволило избежать потери данных и даунтайма Битрикс24 в момент переключения на объектное хранилище VK Cloud.