

Одной каноничной синей изоленты может не хватить
Каждый раз, когда появляется новая технология, на очередной конференции вам показывают отполированного коня в вакууме, который сияет своей красотой и логичностью. Но, как правило, дьявол кроется в деталях. Гравитация оказывается бессердечной дамой, а «сова» ваших бизнес-процессов не так красиво натягивается на «глобус» новой технологии, как хотелось бы.
Первая часть статьи вызвала живое обсуждение. Мысль, что git является не единственным источником истины при наличии связанных артефактов во внешних системах (особенно если эти артефакты имеют потенциальные проблемы с повторяемостью сборок), встретила некоторые возражения. Но в этом вопросе я предлагаю следовать закону Мерфи: если неприятность может случиться, то она случается. Рано или поздно не отображаемые в git проблемы внешних зависимостей выстрелят вам в ногу. Эти риски нужно постоянно держать в голове и по возможности митигировать.
Какие ещё потенциальные сложности могут встретить вас при следовании пути GitOps и какие могут быть альтернативы? Давайте разберёмся вместе.
Проблема нескольких окружений
Мы уже разобрались с flux workflow, теперь пойдём дальше. Вот наш Helm-релиз:
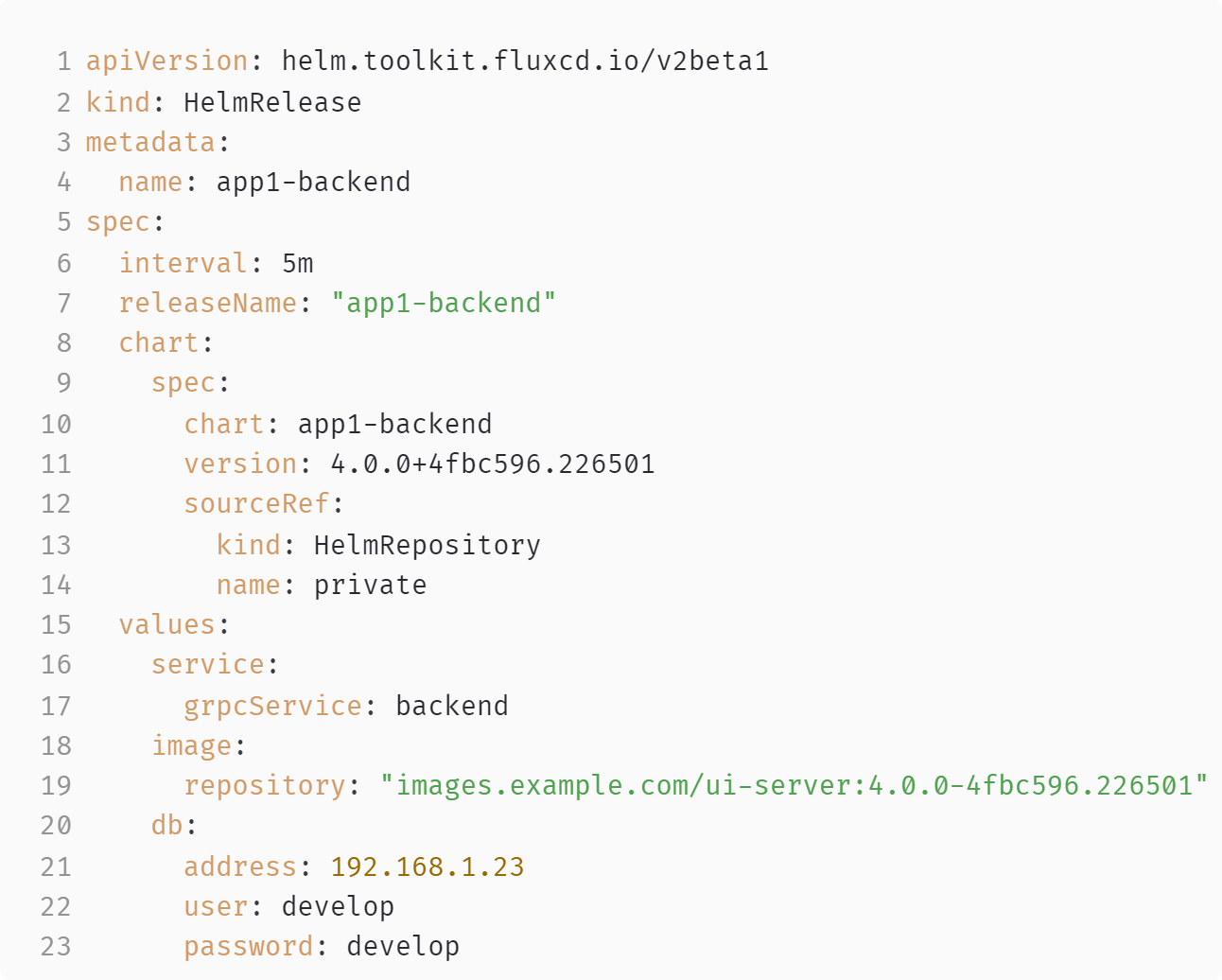
Допустим, мы выкатили изменения в develop-окружение, протестировали всё и хотим выкатиться в stage. Каким образом мы можем это сделать? У нас — GitOps, поэтому мы, очевидно, хотим по максимуму использовать git-подход, то есть выполнить merge кода из dev в stage. Но в такой конфигурации Helm-релиза мы не можем этого сделать, так как (например) в stage-окружении у нас другая база (строки 20...23).
А что у нас GitOps говорит по поводу управления окружениями? А GitOps говорит: «А давайте у вас будет всего одно окружение, и вы не будете маяться дурью». Я, например, не уверен, у многих ли команд только одно окружение. GitOps-идеологи, похоже, тоже в этом не уверены. Поэтому они говорят: «Ну если вам очень нужен multistage, то сделайте это где-нибудь outside of the GitOps scope. В рамках вашей CI/CD-системы например».
Values from
И мы уходим думать, перебираем варианты и находим несколько из них.
Первый — valuesFiles (строки 15, 16, 17):

Мы можем описывать отдельные values-файлы для отдельных окружений и подключать их в HelmRelease, но эта схема также не очень хорошо ложится на git merge.
Следующий вариант — valuesFrom:

То есть в namespace нашего окружения может быть один или несколько config map и/или secret (строки 22...25). И из них Helm-контроллер может взять Values и кастомизировать наш Helm chart. И нам это нравится. Мы даже заводим отдельный Helm chart, в котором делаем конфигурацию всех наших микросервисов, связываем его с чартами приложения ключом dependsOn (строка 16) и гордо называем это единой точкой конфигурации платформы.
А потом происходит следующее: у нас появляется несколько кластеров Kubernetes. к нам приходят коллеги и говорят: «А давайте мы ещё один config map запилим, и там будут кластер- специфичные — Values (строки 26...28):

Например, имя кластера, суффикс Ingress, регион, права доступа. И создавать этот config map мы будем через terraform вместе с созданием кластера».
Когда это случится, вам нужно взять
Тут могу дать вам совет. Если вы хотите завязывать на Values from, то в ваших переменных и в config map должно быть всего одно значение — имя окружения, куда вы деплоитесь. Всё остальное должно делаться внутри Helm chart’а при помощи механизмов шаблонизации.
Проблема секретов
Следующий момент. У нас — Helm-релиз, в котором есть строчка, которой там быть не должно, — пароль от базы данных (строка 23):
Что нам говорит GitOps по поводу управления секретами? А GitOps нам говорит: «Никогда не храните ваши пароли открытым текстом в Git-репозитории». Что можно сказать? Спасибо, кэп!

Следующее, что предлагает нам GitOps: «А давайте вы будете генерировать ваши пароли рандомно при создании окружения. И все объекты, которые требуют парольной защиты, вы будете делать на основе этих паролей. Таким образом, пароль никогда не будет выходить из окружения, и всё будет секьюрно, все будут довольны».
Хорошо, конечно. Но у многих ли, например, SQL-база находится в Kubernetes? Или там crossplane установлен? Как правило, мы не создаём тяжёлых персистентных сервисов внутри или изнутри кластера Kubernetes.
Поэтому читаем дальше и видим следующие подходы: «А давайте вы будете использовать инструменты типа Mozilla SOPS или Bitnami Sealed Secrets, когда мы делаем открытый и закрытый ключи. Закрытый ключ записан в кластер, открытым ключом шифруем наши пароли и коммитим в Git-репозиторий. В момент деплоя какой-то инструмент внутри Kubernetes расшифровывает это и отдаёт приложениям. А записывать этот ключик в кластер будет специально обученный спец из команды Ops. Пусть секьюрно носит его распечатку во внутреннем кармане пиджака и потом тщательно вбивает руками».
О`кей, это выглядит наиболее удачным вариантом.
А теперь давайте подумаем. В широко известном в узких кругах тесте Лимончелли «32 вопроса к вашей команде сисадминов», стареньком, но ещё актуальном, есть, например, 31-й вопрос: «Можете ли вы отключить учётную запись пользователя во всех системах за один час?» Ваш Ops guy уволился. И если ваши кластеры Kubernetes — не под единой системой входа, то вы должны пробежаться по всем кластерам и поудалять его учётную запись отовсюду.
Следующий вопрос: «Можете ли вы сменить все привилегированные пароли за один час?» Вот этот секретный ключ, который ваш Ops guy скомпрометировал своим увольнением, и есть тот рутовый пароль. И для того, чтобы его изменить, вы должны сделать определённые действия:
- Извлечь закрытый ключ из кластера.
- Расшифровать им то, что у нас в Git-репозитории.
- Сделать новые ключи.
- Записать секретный ключ в кластер.
- Зашифровать пароли.
- Закоммитить их в git.
- Провести по релизному циклу и задеплоиться.
Причём вы должны это сделать в определённом порядке, потому что у нас асинхронная пул-модель, и любой неосторожный выкат может превратить ваше окружение в тыкву. И откат здесь не поможет.
Пара слов — для любителей внешних хранилищ секретов наподобие Hashicorp Vault: не нашёл единого мнения насчёт них, но с точки зрения банальной эрудиции использование внешних хранилищ секретов делает git ещё более неединственным источником истины и тем самым идёт вразрез с GitOps-подходом.
CI Ops vs GitOps
В рамках пиара концепции GitOps WaveWorks очень часто называли классический CI Ops устаревшим подходом и антипаттернoм. Почему? Потому что в рамках GitOps мы можем выделить stage деплоя, защитить и более чётко им управлять.

В рамках CI Ops stage деплоя становится своеобразной частью монолитного пайплайна. И из-за этого возникает ряд недостатков, которые мы сейчас разберём.

Но! Чтобы получить честное сравнение, нам надо выбрать «бойца» со стороны CI-систем. Давайте возьмём популярный и привычный многим Gitlab, который реализует концепцию пайплайнов как кода.

При этом ваш CI-код лежит в том же репозитории, что и ваше приложение, и фактически является его частью. Это позволяет повысить прозрачность CI/CD, делать самодокументирующиеся пайплайны и наладить передачу знаний в команде…
Безопасность
Первая проблема — плохая безопасность. Вроде как в рамках CI Ops у нас — CI-система, и разработчики посредством неё имеют полный доступ к Kubernetes, и это несекьюрно. А в рамках GitOps у нас — асинхронный пул-исполнитель, к которому нет непосредственного доступа, и это сильно повышает защиту системы. Давайте поставим Flux и посмотрим, что там в действительности с безопасностью:
По умолчанию Flux даёт права администратора кластера всем своим контроллерам:

Очевидно, что это не очень секьюрно.
Попробуем улучшить эту ситуацию. Находим статью про multi-tenancy для многопользовательского использования Flux. Создаём tenant и видим, что сгенерировались namespace и ServiceAccount.

И контроллеры Flux получают права администратора на этот namespace, причём не все, а только Kustomize controller.

Для ограничения Helm-контроллера Flux ранее рекомендовали использовать Kyverno, а сейчас предлагают какой-то странный механизм с патчингом деплойментов контроллера, чтобы он всё-таки начал подхватывать сервис аккаунта из namespace, куда деплоится.
Но давайте просто подумаем, абстрагируясь от инструментария. У нас есть две схемы: синхронная пуш-модель и асинхронная пул-модель. И какая из них безопаснее при условии, что они обе имеют админские права? Это риторический вопрос. Потому что админские права есть админские права.
Но даже если мы ограничим инфраструктурные права, то эти схемы будут иметь примерно ОДИНАКОВЫЕ доступы к инфраструктуре, паролям, персистентным данным и могут навредить.
Если посмотреть на проблему немного со стороны, то можно увидеть, что в обоих случаях у вас есть Git-репозиторий. При этом он содержит как код приложения, так и инфраструктурный код. И, наверное, единственный способ пресечь здесь все злоупотребления — это контролировать то, что попадает к вам в Git. В Gitlab есть механизм Merge request approvals(правда, пока только в платной версии, но, как мы знаем, платные фичи у Gitlab достаточно быстро переходят в community-версию).

Этот механизм не даст вам выполнить merge своих изменений в рабочую ветку вашего репозитория, пока нужное количество коллег не просмотрит ваши изменения и не подтвердит, что с ними всё хорошо. Этот довольно простой механизм в разы поднимает безопасность. Существенно более значимо, нежели даёт разница между pull- и push-моделями.
Процедура отката
Другой минус, который приводят идеологи GitOps, — сложность отката в CI. В своих гайдах они говорят, что CI-система не предназначена для того, чтобы быть единственным источником истины, а значит, при работе с CI-системой мы не можем определить, что у нас задеплоено в кластер и на что будем откатываться. А в рамках GitOps у нас есть инфраструктурный репозиторий, который синхронизируется с инфраструктурой, поэтому делаем git revert — и всё хорошо.
Давайте подумаем. GitOps покрывает только stage деплоя. Но, поскольку git не может являться единственным источником истины, про откат мы должны думать на стадии сборки наших артефактов. Кроме того, во Flux есть всё, чтобы затруднить откаты или сделать их вообще невозможными. Например, мы можем хреново тегировать docker image (строка 19 — имидж назван по имени ветки). Кроме того, мы можем использовать диапазон версий Helm chart’а (строка 11):

А если мы используем Helm chart из репозитория приложения, то нам, возможно, потребуется откатить репозиторий приложения, чтобы откатить наше окружение.
Вдобавок не забываем про возможные зависимости valuesFrom в отдельном репозитории, которые тоже, возможно, придётся откатить.
Кроме того, у Flux есть рекомендации по организации инфраструктурных репозиториев.
Например, Monorepo, когда в одной ветке в разных папках у нас лежит инфраструктура для всех наших окружений:

Откатывали продакшн, откатили стейджинг внезапно.
Или, например, Repo per team — когда на каждую команду своя папочка в общем инфраструктурном репозитории:
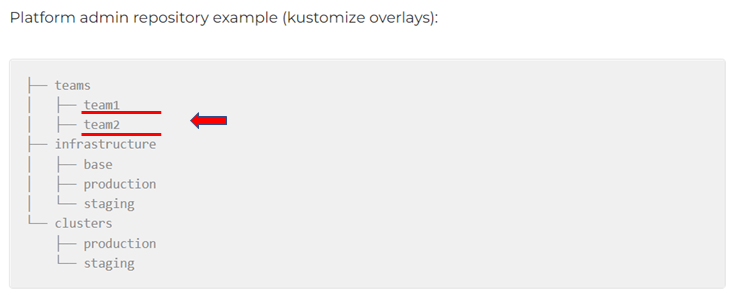
И здесь нужно быть очень внимательными при откате, чтобы не зацепить лишнего.
Что же касается CI Ops, то Gitlab может быть единственным источником истины. В Gitlab есть так называемый механизм environment, когда мы указываем имя окружения в шаге деплоя пайплайна и видим его состояние в трекинге окружений:

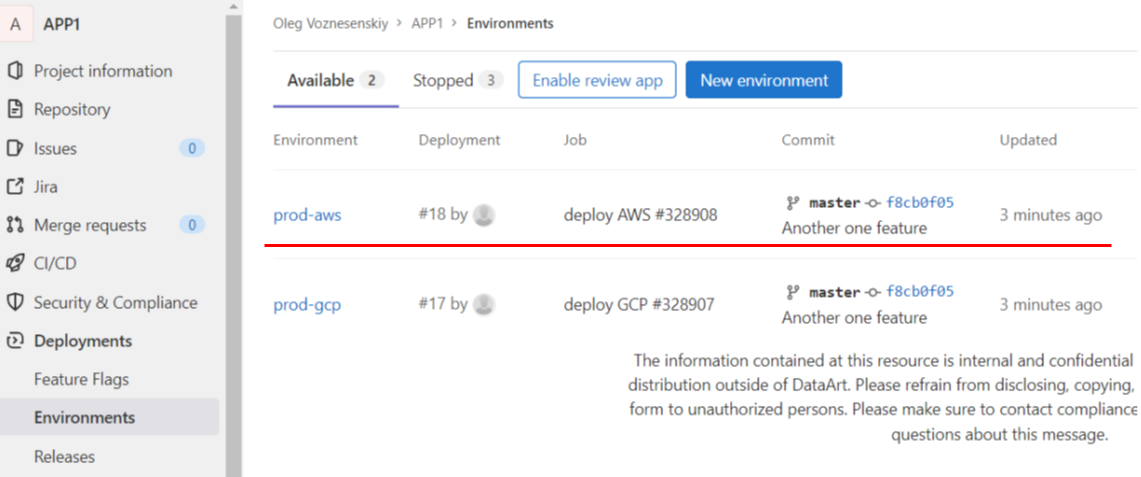
Сразу становится прозрачным, какой пайплайн, с какой ветки и с какого коммита выкачен.
Кроме того, у нас есть визуальное отображение пайплайнов, где мы можем увидеть, что туда каталось и прошли ли эти стейджи, и откатиться на нужный стейдж, что решительно невозможно сделать, глядя на историю коммитов в инфраструктурном репозитории в концепции GitOps:
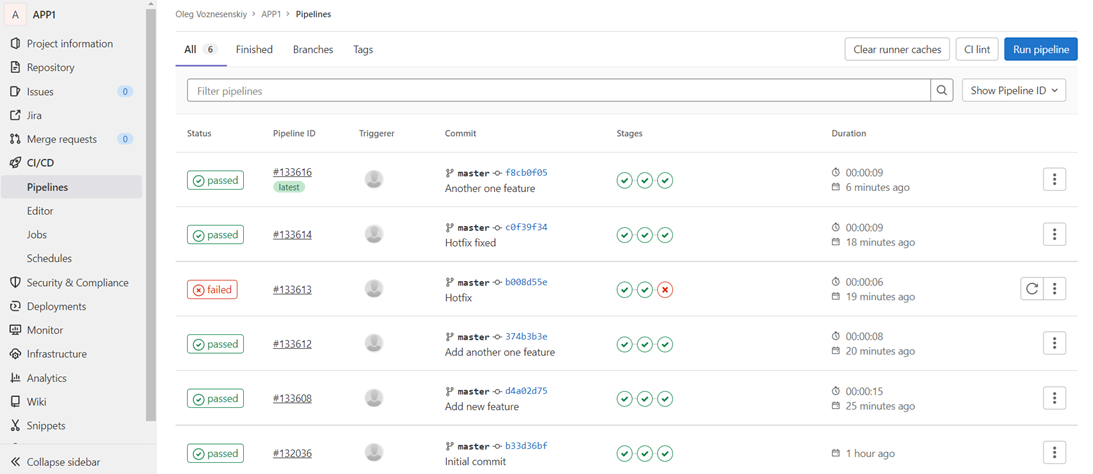
Кроме того, мы можем сохранить docker image как артефакт в пайплайн, сделав таким образом пайплайн атомарным. И вот это действительно будет единственным источником истины.
В итоге для отката в рамках описанной выше реализации вам достаточно будет просто перезапустить Job выката в истории пайплайнов в визуальном интерфейсе Gitlab.
Проблема нескольких кластеров
По мнению разработчиков концепции GitOps, в CI Ops сложно распространять изменения на несколько кластеров. Якобы в рамках CI-системы нам нужно скриптить, скриптить и скриптить. А вот в прекрасном GitOps мы просто ставим Flux в новый кластер и даём ему инфраструктурный репозиторий. Раз — и наше приложение уже в новом кластере.
Начинаем анализировать. Вот наш кастомный ресурс Helm-релиз в каком-то инфраструктурном репозитории:
У меня при взгляде на этот Helm-релиз возникает два вопроса:
- Откуда это приложение взялось? Где его репозиторий, где логи сборки и результаты прогона тестов? Вообще с какой ветки, с какого коммита оно развёрнуто?
- Куда приложение развёрнуто? Сколько флюксов в каких кластерах смотрят на этот инфраструктурный репозиторий и тянут оттуда конфигурацию?
На первый вопрос мы можем ответить «out of GitOps scope», написав правильный скрипт пуша HelmRelease, который в commit message будет записывать всю нужную нам информацию.
На второй вопрос Flux предлагает механизм bootstrap с созданием инфраструктурного репозитория (flux-fleet) для управления конкретно Flux. Перед установкой Flux в кластер мы сперва коммитим туда все YAML, описывающие инсталляцию контроллеров flux и связанные custom resources, а потом применяем их к целевому кластеру. Когда нам требуется подключить git-репозиторий и Kustomize на новый инфраструктурный репозиторий, мы опять коммитим его в этот инфраструктурный репозиторий.
Таким образом, в одном репозитории у нас есть весь список наших кластеров и всех доступов. И это работает прекрасно, пока не случается каких-то ручных операций. Например, ваш Ops guy уволился. Допустим, где-то есть кластер Kubernetes, в котором он поставил Flux и дал ему вручную в обход flux-fleet доступ в ваши инфраструктурные репозитории. Если вы забили на отзыв доступов и перегенерацию ключей, то можете об этом никогда не узнать. Поэтому вот этот пункт, создание flux-fleet репозитория и bootstrap Flux, я бы порекомендовал записать нулевым шагом в наш чек-лист. В противном случае вы получите тайное знание, которое может быть однажды утеряно вместе с сотрудником.
А что у нас в CI-ops? В Gitlab мы можем объявлять переиспользуемые куски кода (строки 1...9). Когда делаем новое окружение, можем наследоваться от этих кусков кода (строки 13, 19, 25), объявлять какие-то дополнительные переменные (строки 15, 21, 27). В данном случае — имя кластера, относительно которого будем менять функционирование наших скриптов. Таким образом мы будем деплоиться в новое окружение и получать его автоматический трекинг:
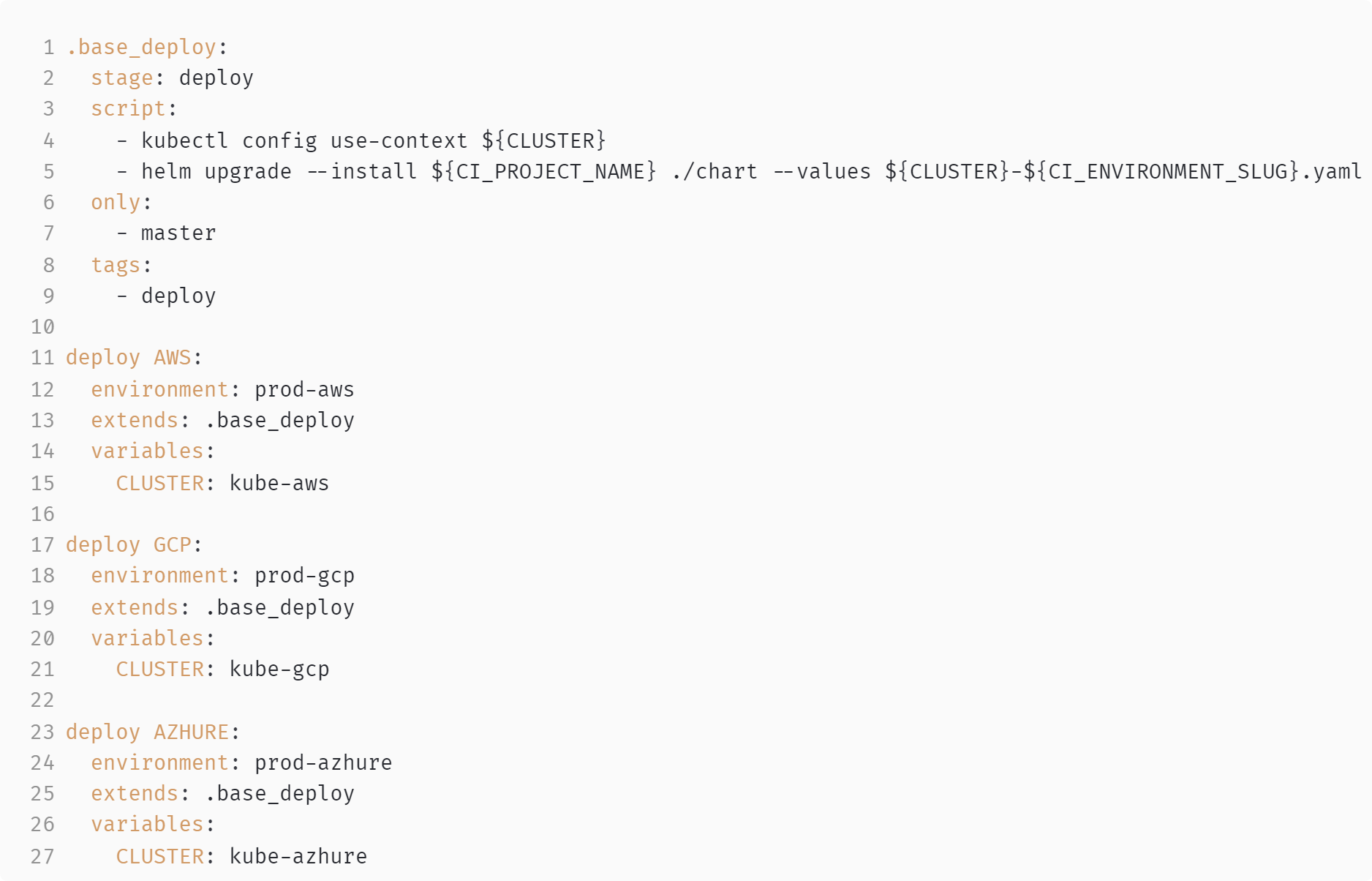
Итого
Чего ещё нам не хватает для полного счастья? Нам явно не хватает нотификаций. У нас асинхронная pull-модель. В этой модели нам совершенно непонятно, чем именно занят этот pull-исполнитель на своей стороне, если он явно об этом не сообщит. Поэтому добавим инсталляцию и настройку notification-контроллера в наш чек-лист и подобьём его. Итак, для работы с GitOps нам нужно сделать:
- Flux-fleet-репозиторий.
- Bootstrap flux в кластере Kubernetes, используя репозиторий flux-fleet.
- Скрипт для сборки и пуша имиджей в Docker registry.
- Инфраструктурный Git-репозиторий.
- Аккаунт для доступа CI-системы в инфраструктурный GIT-репозиторий.
- Скрипт для генерации и пуша HelmRelease-файла.
- Репозиторий Helm.
- Аккаунт для доступа CI-системы в репозиторий Helm.
- Скрипт для сборки и публикации Helm chartʼа.
- Аккаунт Flux для инфраструктурного репозитория.
- Аккаунт Flux для репозитория Helm чартов.
- Аккаунт Flux для репозитория приложения.
- Аккаунт для доступа к кластерам для инженера из команды Ops.
- GIT-репозиторий «единой точки конфигурации платформы».
- Аккаунт Flux для доступа к репозиторию «единой точки конфигурации платформы».
- Канал Slack/Teams для уведомлений о деплое для Notification Controller.
Большинство этих пунктов — «out of GitOps scope», и это вроде как не проблема методологии. Но мы как опытные инженеры понимаем, что без этих пунктов не можем полноценно делать GitOps.
А что у нас насчёт CI Ops? В рамках CI Ops на Gitlab нам не нужно делать кучу дополнительных телодвижений для обеспечения функционирования GitOps. Нам нужно:
- Сделать CI-скрипт сборкой и публикаций докер-образа.
- Добавить в скрипт деплой Helm-релиза через Helm apply.
- Создать аккаунт для доступа CI-системы в Kubernetes.
При этом лишённые иллюзии, что это защищено, мы подойдём более ответственно к настройке доступов к CI-системе и кластеру.
Кроме того, мы получаем встроенный интегрированный docker registry, встроенную работу с окружениями, встроенную работу с секретами, встроенную нотификацию выполнения стадий пайплайна и кучу интеграций.
Резюмируем
Итак, вооружённые новыми знаниями, пройдёмся по пунктам bullshit bingo, которые заинтересовали нас в самом начале статьи:
- Улучшенная гарантия безопасности. Здесь, наверное, большой минус авторам идеи, потому что, на мой взгляд, это большое преувеличение и введение в заблуждение.
- Простой и быстрый откат. Будет возможным, только если это очень хорошо спроектировано, причём «out of GitOps scope». В рамках GitOps мы легко можем сделать откат невозможным.
- Более простое управление доступами. В реальности доступов надо больше. Нужно больше телодвижений по управлению доступами. Так что это скорее минус.
- Самодокументирующиеся деплои и передача знаний в команде. Работает, только если это хорошо спроектировано опять-таки «out of GitOps scope». По умолчанию GitOps рвёт ваш пайплайн и порождает тайные знания.
- Улучшение консистентности и стандартизация. Поскольку в GitOps у нас асинхронный пул-исполнитель, который постоянно синхронизирует наш инфраструктурный репозиторий с кластером, то он следит за тем, чтобы система была консистентная. Flux будет постоянно синхронизировать ваш кастомный ресурс HelmRelease, который вы держите в инфраструктурном репозитории. Он будет возвращать его назад в случае удаления или порчи. Но ему абсолютно наплевать на то, что развёрнуто в кластере по описанному в нём чарту. С этими объектами вы можете делать всё что угодно до появления новой версии CR HelmRelease(до деплоя нового релиза чарта). Это, на мой взгляд, делает идею асинхронного пул-исполнителя практически бесполезной (по крайней мере, в варианте с flux с HELM’ом).
Кому реально нужен GitOps?
Есть несколько случаев, когда GitOps-подход может быть, на мой взгляд, оправдан:
- У вас нет CI/CD-системы или она по каким-то причинам не может обеспечить нормального деплоя.
- Улучшение безопасности. GitOps, действительно может дополнить комплекс мер по улучшению безопасности вашей инфраструктуры. Львиная часть вопросов безопасности всё-таки находится out of gitops scope, и должна решаться перед или совместно с внедрением GitOps.
- У вас большая многокомпонентная платформа, которая тестируется и деплоится как единое целое. В этом смысле инраструктурный репозиторий GitOps — хороший способ сделать «стабильную» версию платформы и оперировать ей как единым целым.
- У вас есть процессы, в которых pull-модель имеет преимущества над push-моделью (например, canary deployments).
Так что же такое GitOps? Для любителей точных формул GitOps = Continuous Delivery — Continuous Deployment. То есть это не CD-концепция, это просто (ещё один) способ организовать автоматический деплой.
По большому счёту, эта методология не принесла почти ничего нового. Авторы методологии взяли идеи Infrastructure as code, добавили PULL-основанный подход с reconciliation loop из SCM прошлого поколения(puppet, chef), сделали обязательным требование держать конфигурацию в GIT.
Действительно, новым и ключевым понятием GitOps стала концепция git как единого источника истины, но концепция эта явно проработана посредственно и имеет ряд недостатков. Фактически это попытка взять шаг деплоя из пайплайна доставки приложения и положить его в git.
Одним из ключевых принципов DevOps является постулат о том, что нет плохих исполнителей, есть плохие процессы. Отсюда вытекает blameless culture и понимание того, что нужно организовать процессы так, чтобы проблема стала невозможна.
Но из-за ограниченности концепции GitOps она имеет слишком много пробелов и потенциальных проблем, слишком много вещей, которые нужно делать «out of GitOps scope». Всё это приводит к непониманию, как правильно организовать процессы, и, соответственно, к костылям и велосипедам со всеми вытекающими.
Мне очень понравился этот комментарий к статье. Действительно, для построения хорошего GitOps-процесса компании нужна высокая зрелость ИТ, в том числе потому, что авторы концепции оставили без внимания слишком много важных вещей.
IMHO, GitOps не даёт какого-то существенного преимущества перед хорошо организованным CI Ops-процессом, хотя существенно повышает итоговую сложность системы и цифру трудозатрат. И, на мой взгляд, многие GitOps-инструменты это понимают, реализуя GitOs в нагрузку к сборке образов, например, Gitkube и JenkinsX.
Но дальше всех пошла Werf от компании Flant. Они придумали свою концепцию и назвали её Gitermenism. Их посыл в том, что GitOps в текущем виде неидеален, а вот Gitermenism — это как бы расширенная концепция. Она интересна тем, что покрывает всё наше CI/CD и даже немножко больше. В целом werf — это скорее попытка пошарить лучшие практики крутой DevOps-команды в виде отдельного продукта. Рекомендую хотя бы ознакомиться.
Комментарии (138)

icCE
00.00.0000 00:00Все верно. Вообще подход gitflow для IaS не очень подходит. Поэтому переменные окружения лежат в одном git, helm , роли , манифесты и все остальное в другом. Монорепозиториев почти нет. Но, что бы к этому всему прийти, надо пройти несколько кругов ада.

funca
00.00.0000 00:00Насколько я понял, идея была в том чтобы разделить build и deploy пайплайны, а так же использовать git в качестве хранилища исходного кода и конфигураций со всей историей их изменения (CMDB уровня бомж).
В этом случае ответственность Dev команды ограничивается сборкой приложения в виде артефакта (допустим в виде docker image). Как и куда оно будет раскатано уже не их забота - этим занимается DevOps команда в отдельном репозитории (или репозиториях), где описывает инфраструктуру и правила обновления приложений в ней.
Вопрос с деплоем в несколько environments можно решить маршрутизацией билдов в разные release train. Реализация будет зависеть от конкретной технологии. Например, docker images можно помечать специфичными тегами, на основе которых будет приниматься решение в какое окружение деплоить конкретную сборку. Таким образом сложность выгоняется на уровень управления версиями, где тактики уже давно хорошо проработаны.
Секреты и конфигурации точно так же версионируются как и сборки приложений. Вероятно вам потребуется специфичное хранилище, позволяющее адресовать секреты не только по имени, но и номеру версии (как GCP Secret Manager). Имя и номер версии секрета вы можете хранить в git, как часть текущего описания environment, что обеспечит нужный уровень воспроизводимости, а сами значения извлекать (или генерировать) в момент деплоя.

past
00.00.0000 00:00Опять Вы путаете GitOps и Helm. Это никак не связанные вещи. Helm очень плохо подходит для GitOps.

seasadm Автор
00.00.0000 00:00Можете пояснить свою мысль? Почему helm плохо подходит для GitOps?
past
00.00.0000 00:00+1Для GitOps хорошо подходят "плоские" манифесты. В идеале готовые к применению в кластер. Хелм же делает свою магию в процессе применения. Есть темплейты и вельюсы. Проблемы с этим Вы хорошо описали в первой части статьи
seasadm Автор
00.00.0000 00:00Не совсем. Перед применением хелм делает плоский "релиз" и записывает его в release backend. По умолчанию это secret в неймспейсе релиза. Тоесть мы в любое время можем посмотреть ямлики, которые были применены в кластер. Причем хелм обычно хранит несколько последних релизов - мы можем делать откат например.
Теперь вопрос - у нас в секрете в кластере лежит эталонный ямлик текущего релиза. Какие проблемы в рамках общего reconciliation loop следить за дрифтом актуальной конфигурации?
past
00.00.0000 00:00Как, например, будет раскатываться релиз, если кто-то руками поменял configMap в приложении?
Или релиз в состоянии Failed?
Тут GitOps кончается и инженер идет в куб править рукамиseasadm Автор
00.00.0000 00:00Как, например, будет раскатываться релиз, если кто-то руками поменял configMap в приложении?
Мне несколько раз в рамках обсуждения статей писали коментарии вида:
Ручные операции в кластере это ваши проблемы, а не проблемы гитопс. Просто отберите у всех доступ в кластер. У вас же гитопс. Он безопасен и не требует раздавать права.
Вы с этим не согласны?
Или релиз в состоянии Failed?
Тут GitOps кончается и инженер идет в куб править рукамиНене. У нас же гитопс. Git revert и всё в порядке. Это вот прям на сайте gitops.tech на главной странице в первых строках написано. Вы не согласны что гитопс решает эту проблему?
past
00.00.0000 00:00Ладно, расскажу как у нас сделано
Есть репозитории с аддонами. Если там лежит вендорский софт, поставляемый в виде хелм чарта (например istio или cilium), то в папочке положены манифесты, сделанные посредством `helm template`. Если манифесты самописные, то kustomize.
Есть стейт репа, в которой через kustomize собираются аддонны ссылками на конкретный тег в репы аддонов.
И есть плоская, отрендеренная стейт репа, в которую автоматически коммитится выхлоп `kustomize buld` стейт репозитория. На эту репу смотрит ArgoCD, опять же не на ветку, а на тег.
Соответственно процесс выкатки выглядит так: Инженер коммитит новую версию аддона, ставит тег, меняет тег в стейт репе, новый тег синкается в арго. Если надо откатить, тег в арго меняется на предыдущий.seasadm Автор
00.00.0000 00:00А вот это вот действие - поменять тег в стейт репе, оно ручное?
past
00.00.0000 00:00Да, это коммит в репу. Во кусок kustomization:
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization resources: - git::https://gitlab.mydomain/k8s/certmanager.git/bases/?ref=v1.1.1Инженер сначала ставит тег v1.1.2 на репозитории Сертменеджера, потом коммитит в стейтрепу
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization resources: - git::https://gitlab.mydomain/k8s/certmanager.git/bases/?ref=v1.1.2seasadm Автор
00.00.0000 00:00Выглядит кривовато КМК. Надеюсь такую схему вы сделали по каким-то реальным практическим соображениям, а не просто потому что захотелось гитопс.
seasadm Автор
00.00.0000 00:00Ну во-первых вижу здесь отсутствие автоматизации. Toil automation - one of five SRE pillars так сказать.
Во-вторых человеческий фактор. У инженера может "соскочить пальчик" и это может привести к непредсказуемым последствиям.
Дублирование работы опять же. Постановка тега на целевой репозиторий плюс прописывание его в инфраструктурном.
Тайные знания. Не ознакомленный со схемой инженер может не сообразить что нужно пойти в репу и поправить там файл.
В принципе, если у вас медленные процессы и вы редко релизитесь, это наверное допустимо.
past
00.00.0000 00:00Деплоимся несколько раз в день, все изменения происходят через гит с ревью коллег и через этапы тестирования. Это как раз исключает человеческую ошибку полностью. Коммит в 2 репы как раз защищает от просачивания непротестированного кода в кластера. Это все хорошо задокументировано в README и на вики. За вновь присоединившимися инженерами устанавливаются менторство и особый контроль.
seasadm Автор
00.00.0000 00:00Всё верно. Выглядит как хрестоматийный пример muda 2-го порядка. Если вы понимаете о чем я.
seasadm Автор
00.00.0000 00:00Это термин из "бережливого производства". Собственно та база, которая помогает делать работу осмысленно, сделать качественный целенаправленный скачок от Ops к DevOps, не собирая известные грабли самостоятельно. Рекомендую ознакомиться с google sre book и project fenix. Там про это хорошо описано.



amkartashov
00.00.0000 00:00Допустим, мы выкатили изменения в develop-окружение, протестировали всё и хотим выкатиться в stage. Каким образом мы можем это сделать? У нас — GitOps, поэтому мы, очевидно, хотим по максимуму использовать git-подход, то есть выполнить merge кода из dev в stage.
В GitOps не делают merge описания одного окружения в описание другого окружения потому что в этом нет смысла.
Пытаться мержить код описания dev окружения в код описания stage окружения - это как пытаться смержить код apache и код nginx.
А вот в пределах одного окружения - там да, можно использовать стандартный подход с ветками, допустим в дев окружении появляется новое приложение, сделали под новую конфигурацию ветку, PR, ревью, тесты, merge.
seasadm Автор
00.00.0000 00:00Не очень понимаю, почему мы не можем относиться к инфраструктурному коду так же как к программному. Можете пояснить свою мысль?
amkartashov
00.00.0000 00:00-1Ты можешь применять подход с merge к инфраструктурному/программному коду в том случае если инфраструктурный/программный код относится к одной инфраструктуре/программе. Я вроде тебе аналогию простую привёл " мержить код описания dev окружения в код описания stage окружения - это как пытаться смержить код apache и код nginx "
seasadm Автор
00.00.0000 00:00Именно эта аналогия мне и не понятна:
У нас нет разницы apache - nginx. У нас flux в обоих окружениях. А также некоторый набор наших приложений и инфраструктурных сервисов, который очень похож (если не тождественен) от окружения к окружению.
amkartashov
00.00.0000 00:00-1Похож, но не одинаков. Он и не должен быть одинаков, потому что это разные окружения, они используют разную конфигурацию, и хранение этой конфигурации в гит - это и есть гитопс.
А когда у тебя в голове всякие мержи dev в production и гитфлоу - это про код одного приложения, и код в ветке разработки в момент сливания полностью и без изменений переносится в код основной ветки.То что у тебя и там и там гит используется, не значит, что у тебя должны быть одинаковые процессы.
seasadm Автор
00.00.0000 00:00Всё-таки я не понимаю разницу. Может сможете объяснить это на конкретном примере? Как правильно доставлять изменения в случае multistage environments в рамках gitops. Или дадите ссылку на документацию, где описана принципиальная разница в процессах, на которую вы намекаете?
amkartashov
00.00.0000 00:00Может сможете объяснить это на конкретном примере?
Нельзя мёржить такой текст
ingress: hosts: - stage.example.comс таким
ingress: hosts: - example.comКак правильно доставлять изменения в случае multistage environments в рамках gitops.
Постановка вопроса некорректна. Нет "правильного", "лучшего" ответа. Есть решения, у этих решений есть плюсы и минусы. Вариантов "доставлять изменения" много, и, как уже было сказано, это не в рамках подхода GitOps. GitOps только говорит, что нужно описывать конфигурацию декларативно и хранить в гите, а как ты будешь изменения конфигурации добавлять в гит - это другой вопрос.
Или дадите ссылку на документацию, где описана принципиальная разница в процессах, на которую вы намекаете?
Я не знаю где достать "документацию по GitOps".
seasadm Автор
00.00.0000 00:00+1Ровно то же самое я описал в своей статье в главе Проблема нескольких окружений .
Только объяснения разницы я делал на основе разницы в инстансах баз данных, а не ингрессах, дал ссылки на источники на gitops.tech и таки дал рецепты решения этой проблемы.Может вам стоит перечитать эту главу и обсудим её предметно?

artazar
00.00.0000 00:00Я бы сказал в общем, что с точки зрения GitOps не будет хорошей практикой держать разные среды в разных ветках и делать мержи между ними. Для GitOps среды принципиально различаются. Это не код приложения, который через ветки стабилизируется. Если проводить аналогию, тогда ветки с точки зрения GitOps могут означать разные кластера, то есть в одном кластере мы тестируем какие-то изменения, потом мержим в основную ветку и все раскатывается в продакшн кластер. И то это очень и очень с натяжкой, и даже так делать - это разложить себе грабли на будущее. Правильнее конфигурацию разных кластеров держать в разделенных директориях или репозиториях.
seasadm Автор
00.00.0000 00:00Если говорить строго, GitOps принципиально отказывается решать вопрос переноса версий ПО между окружениями. Я писал об этом в статье. Данный вопрос важный и этот тред прекрасно иллюстрирует мою мысль - когда какой-то вопрос не описан, каждый решает его сам при помощи собственных костылей и велосипедов.
Мерж кода - один из способов решения этого вопроса.
Другие способы связаны с активным скриптописанием. Тоесть stop scripting and start shipping не получается.
Можете рассказать как с вашей точки зрения этот вопрос решить правильно?
amkartashov
00.00.0000 00:00-1«А давайте у вас будет всего одно окружение, и вы не будете маяться дурью»
А давайте не будем перевирать то, что написано по ссылке? GitOps не ограничен одним окружением.
Это всё равно что сказать: "этот MySQL предлагает иметь только одно окружение, потому что я не могу использовать одну и ту же базу данных в проде и в деве, вот отстой".
seasadm Автор
00.00.0000 00:00+1Текст по ссылке, вольный перевод которого я привёл в статье:
GitOps doesn’t provide a solution to propagating changes from one stage to the next one. We recommend using only a single environment and avoid stage propagation altogether.
Можете предложить свой вариант перевода, если считаете, что мой не корректен?amkartashov
00.00.0000 00:00-1Контекст разный. У тебя в тексте это звучит так, будто при использовании GitOps тебе в нельзя иметь других окружений вообще. Это несерьёзно, как может методика деплоя тебя ограничивать в количестве окружений? У них контекст про применимость подхода, и эта фраза там значит что лучше не надо смешивать в одном декларативном описании несколько окружений.
seasadm Автор
00.00.0000 00:00+1Пожалуйста, не вырывайте мои фразы из контекста. Вот полный текст:
А что у нас GitOps говорит по поводу управления окружениями? А GitOps говорит: «А давайте у вас будет всего одно окружение, и вы не будете маяться дурью». Я, например, не уверен, у многих ли команд только одно окружение. GitOps-идеологи, похоже, тоже в этом не уверены. Поэтому они говорят: «Ну если вам очень нужен multistage, то сделайте это где-нибудь outside of the GitOps scope. В рамках вашей CI/CD-системы например».
На мой взгляд это достаточно близкий по смыслу перевод документации(с авторскими комментариями).
И здесь была мысль про то, что концепция GitOps игнорирует multistage, хотя это является важной частью эксплуатации приложений.
amkartashov
00.00.0000 00:00-1Я как раз тебе на контекст и указал. У тебя контекст про окружения для команды, в том тексте, который ты переводишь, контекст управления окружением. Если разжевать, то в рамках одного репозитория советуется описывать одно окружение.
seasadm Автор
00.00.0000 00:00+1Не нашел в пункте
https://www.gitops.tech/#how-does-gitops-handle-dev-to-prod-propagation
упоминания про правило "один репозиторий = одно окружение". Не нашел там вообще упоминаний про репозитории. Только про окружения.
Я не туда смотрю?
artazar
00.00.0000 00:00Ну, речь здесь о том, что GitOps сам по себе не предоставляет способ как перекатывать версию приложения между дев-стейдж-прод средами. И это правда, потому что GitOps - это про статическое декларирование состояния, а не про динамику.
Но никто не мешает использовать GitOps для того, чтобы делать коммит сначала для дев среды, потом для стейдж, потом для прод с указанием нужных версий, это и будет решением multi-stage. Это можно и в CI систему уже завернуть.
amkartashov
00.00.0000 00:00-2А GitOps нам говорит: «Никогда не храните ваши пароли открытым текстом в Git-репозитории». Что можно сказать? Спасибо, кэп!
Ну кому кэп, а кому нет. Скажи ещё, ты ни разу не видел паролей в гите.
Дальнейшее словоблудие к GitOps имеет отношение постольку-поскольку. Secrets management сложен независимо от того, используешь ты GitOps или нет. Вот тот же алгоритм со сменой паролей - а что, если б ты GitOps не использовал, тебе пароли не надо менять было? Нет? У тебя наверное ротация паролей тогда настроена? А чем же тебе GitOps мешает настроить ротацию паролей? Или IAM использовать для авторизации? Или инструменты типа Vault?
seasadm Автор
00.00.0000 00:00+1Я встречал множество паролей, токенов и сертификатов в гите. И, как правило, люди их туда положившие прекрасно знали, что этого делать нельзя. Просто ленились сделать по-другому.
Что до использования vault-подобного тулинга в GitOps — я изложил свои соображения в статье. Можем рассмотреть их по существу.
amkartashov
00.00.0000 00:00git ещё более неединственным источником истины и тем самым идёт вразрез с GitOps-подходом
Этот аргумент ещё в первой статье меня возмутил. Да кто ж тебе сказал, что в GitOps один git репозиторий это единственный источник истины ВСЕГО? Ты доводишь идею до абсурда, а потом возражаешь уже тому абсурду, который сам же и выдумал.
Есть артефакты сборки, для них "источником истины" будет код приложения и настройка системы сборки. А потом репозиторий артефактов, например Container Registry. В GitOps у нас только тег образа и адрес реестра, а не весь образ.
Есть Helm чарты, для них может быть свой репозиторий и код. В описании окружения у нас есть указание где брать хелм чарт, какую версию, и какую конфигурацию применить.
В тех статья, на которые ты ссылаешься, про это точно пишут, например "There are at least two repositories: the application repository and the environment configuration repository."
seasadm Автор
00.00.0000 00:00Я ориентируюсь на описание GitOps от авторов концепции: https://www.weave.works/technologies/gitops/
Цитаты:
GitOps leverages Git as the single source of truth to define every part of a cloud-native system.With the declaration of your system stored in a version-controlled system, and serving as your canonical source of truth, you have an ultimate repository from which everything is derived and driven.
At the center of our pull pipeline pattern is a single source of truth for manifests (or a config repo).
By applying GitOps best practices, there is a pre-defined, ultimate source of truth for both your infrastructure and application code that lets your development teams increase velocity and improve system reliability.
Как вы можете заметить, в этих цитатах употребляются словообороты single source of truth, ultimate source of truth.
Не main source of truth или common source of truth.Отсюда можно сделать вывод, что авторы концепции предполагают, что мы должны иметь возможность разрешить ЛЮБОЙ вопрос, связанный с конфигурацией нашего приложения просто посмотрев в гит.
Если вам кажется, что мой перевод не верен, или я что-то важное упустил в документации, прошу это аргументированно изложить.amkartashov
00.00.0000 00:00-2Да хоть запереводись, если ты не понимаешь текст. Источник правды чего? Там в тексте написано, если что. Там где-то указано, что это источник правды ВСЕГО? В частности, где там написано, что git дожен быть источником правды для секретов, ведь ты этому удивляешься
использование внешних хранилищ секретов делает git ещё более неединственным источником истины
seasadm Автор
00.00.0000 00:00Выше я привёл цитаты из официального источника и мой вывод, который я сделал на основе их интерпретации.
Если вы считаете, что моё понимание неверное, можете изложить своё понимание, подкрепив его источниками?
amkartashov
00.00.0000 00:00-1Цитирую твоё цитирование.
single source of truth for manifests (or a config repo)
Где ты там увидел "single source of truth for everything" или "single source of truth for secrets"?
seasadm Автор
00.00.0000 00:00Там чуть ниже цитата. Вот эта:
By applying GitOps best practices, there is a pre-defined, ultimate source of truth for both your infrastructure and application code that lets your development teams increase velocity and improve system reliability.
amkartashov
00.00.0000 00:00-1Ну значит текст в твоём прочтении сам себе противоречит, ок.
seasadm Автор
00.00.0000 00:00+1Можете пояснить в чем противоречие? Для меня это не очевидно.
amkartashov
00.00.0000 00:00-1Ты понял что у тебя гит это источник правды для всего, при этом там же на той же странице прямо говорится что это источник правды для манифестов.
seasadm Автор
00.00.0000 00:00Вообще-то в предыдущем ответе я привёл цитату
By applying GitOps best practices, there is a pre-defined, ultimate source of truth for both your infrastructure and application code that lets your development teams increase velocity and improve system reliability.
Фраза
ultimate source of truth for both your infrastructure and application code
переводится как
окончательный источник правды как для вашей инфраструктуры, так и для кода приложения.
Контекст этой фразы можете найти здесь https://www.weave.works/technologies/gitops/ .
НО!!! 3-й фактор из 12-factor app говорит нам: сохраняйте конфигурацию в среде выполнения. Поскольку среда выполнения управляется как раз "манифестами" (кукбуками/плейбуками) системы управления конфигурацией, методология 12 factor app явно говорит нам, что секреты являются частью манифестов.artazar
00.00.0000 00:00Хранилище и манифесты - это разные вещи.
Образ контейнера хранится в реестре - это хранилище.
В манифесте указывается версия - это source of truth для деплоя приложения. Инструментарий внутри кластера отвечает за доставку образа с данной версией.
Также и секретами. Vault - это хранилище, зашифрованный пароль в репозитории - тоже хранилище. Манифест говорит о том, где секрет лежит. Контроллер в кластере достает секрет и предоставляет его приложению.
Конфигурация = манифесты, она хранится в репозитории и является этим самым источником правды.
Хранилище это другое.
seasadm Автор
00.00.0000 00:00В этом подходе источник истины распространяется на хранилище и его содержимое в том числе. Содержимое хранилищ может быть изменено, эти изменения могут быть не зарегистрированы (и не отображены в гит) но напрямую повлиять на функционал приложения. Это нужно по крайней мере учитывать.
Я бы назвал git в данном случае не single а main source of truth.
amkartashov
00.00.0000 00:00+1Давайте подумаем. GitOps покрывает только stage деплоя. Но, поскольку git не может являться единственным источником истины, про откат мы должны думать на стадии сборки наших артефактов
Давайте подумаем, да. Если у тебя нет предыдущих артефактов сборки и предыдущего кода, то никакой SuperMegaOps тебе не даст сделать откат, если у него нет машины времени под капотом. Почему ты записываешь это в минусы именно подходу GitOps?
seasadm Автор
00.00.0000 00:00Потому что гитопс прямо обещает простой и быстрый откат: https://www.gitops.tech/#easy-and-fast-error-recovery
Я просто обозначил что откат возможен только если ты позаботишься о нём в том числе outside of gitops scope. Считаете по-другому?
amkartashov
00.00.0000 00:00-1да, там ещё не написано, что этот подход будет работать, только если
ты после git revert сделал git push
при этом в нужный репозиторий
и у тебя есть на это права
и компьютер у тебя при этом включен
и интернет есть
и AWS при этом сам не лежит
и ты живой и можешь нажимать на кнопки.
Да. Уж обманули так обманули, на самом деле всё сложно и ещё кучу условий надо соблюсти.
amkartashov
00.00.0000 00:00Откатывали продакшн, откатили стейджинг внезапно.
Если у тебя не гранулярные коммиты, которые затрагивают сразу несколько окружений, то ты ССЗБ. Это можно и в пуш модели сделать через жопу, когда у тебя пайплайн обновляет версии сразу на всех окружениях, и там нельзя отдельно обновить/откатить одно.
seasadm Автор
00.00.0000 00:00+1Это иллюстрация того, что откаты в GitOps нужно хорошо проектировать. И рекомендации от авторов flux часто достаточно плохие.
Вы считаете по-другому?
amkartashov
00.00.0000 00:00-1Ты критикуешь весь подход, а не авторов flux. У тебя заголовок статьи "GitOps бесполезен" а не "Советы авторов flux отстой"
seasadm Автор
00.00.0000 00:00Я рассматриваю подход, на базе тулинга, который сделали его авторы. Вы считаете такой способ не достаточно хорошим?
amkartashov
00.00.0000 00:00Подход может и хороший, но статья получилась так себе.
amkartashov
00.00.0000 00:00-1Gitlab может быть единственным источником истины
То есть в случае гитлаба вот эти аргументы из предыдущей статьи не работают чтоли? А что поменялось?
в данном конкретном случае не может быть единственным источником правды. У нас есть по крайней мере два ресурса — два артефакта вне git, от которых этот Helm-релиз зависит
seasadm Автор
00.00.0000 00:00Какие именно аргументы не работают для gitlab?
amkartashov
00.00.0000 00:00-2Это я у тебя спросил, "эти аргументы из предыдущей статьи не работают чтоли?" Я нигде не утверждал что какие-то аргументы не работают для гитлаб, почему ты меня об этом спрашиваешь? Логика вышла из чата?
amkartashov
00.00.0000 00:00-1И это работает прекрасно, пока не случается каких-то ручных операций. Например, ваш Ops guy уволился.
GitOps нигде не декларирует что есть защита от бас фактора или что оно будет нормально работать с ручными операциями.
Допустим, где-то есть кластер Kubernetes, в котором он поставил Flux и дал ему вручную в обход flux-fleet доступ в ваши инфраструктурные репозитории.
Допустим, он где-то поднял ещё один гитлаб, добавил ключи доступа для синка реп и периодически деплоит в левый кластер.
seasadm Автор
00.00.0000 00:00GitOps нигде не декларирует что есть защита от бас фактора или что оно будет нормально работать с ручными операциями.
Гитопс декларирует
https://www.gitops.tech/#self-documenting-deployments
https://www.gitops.tech/#shared-knowledge-in-teamsЭто заявка если не на снятие, то на уменьшение bus factor.
Что до (в том числе) отсутствия толерантности к ручным операциям, я изложил своё мнение в этих абзацах:
Одним из ключевых принципов DevOps является постулат о том, что нет плохих исполнителей, есть плохие процессы. Отсюда вытекает blameless culture и понимание того, что нужно организовать процессы так, чтобы проблема стала невозможна.
Но из-за ограниченности концепции GitOps она имеет слишком много пробелов и потенциальных проблем, слишком много вещей, которые нужно делать «out of GitOps scope». Всё это приводит к непониманию, как правильно организовать процессы, и, соответственно, к костылям и велосипедам со всеми вытекающими.
amkartashov
00.00.0000 00:00-1Погоди погоди. GitOps декларирует какие-то вещи, которые будут происходить, если ты будешь следовать подходу GitOps. В каком месте у тебя
пока не случается каких-то ручных операций
это следование подходу GitOps?
seasadm Автор
00.00.0000 00:00Это про "сделать такой подход, чтобы проблема стала невозможна".
На самом деле ручные операции и configuration drift - давняя проблема подхода IaC.
Chef и Puppet это в какой-то степени решали за счет reconciliation loop, но там были фундаментальные проблемы с выделенными железными персистентными серверами.
Сейчас же у нас immutable infrastructure, и stateless. И за счет более строгих подходов можно нивелировать проблему. Но на мой взгляд, GitOps этого не делает даже близко.
amkartashov
00.00.0000 00:00-1Ещё раз, вопрос был достаточно простой, в твоём понимании ручные операции - это GitOps? Если да, то ок, я с тобой согласен, твой GitOps - плохой. Если нет, то я не понимаю, почему ты обвиняешь GitOps в проблемах, которые вызваны ручными операциями.
seasadm Автор
00.00.0000 00:00Приведу аналогию: амортизаторы это часть автомобиля? Значит ли что автомобиль без амортизаторов плохой?
amkartashov
00.00.0000 00:00-1Ты увиливаешь от ответа. Если это игра в "за кем последнее слово тот и прав", то я сдаюсь. На следующий коммент, в котором не будет ответа на простой вопрос, является ли ручная правка следованием GitOps, я промолчу.
seasadm Автор
00.00.0000 00:00Я уже ответил на этот вопрос.
Ручные правки являются фундаментальной проблемой. Ты с ней сталкиваешься в том числе когда делаешь GitOps.
Являются ли ручные правки частью GitOps? - НЕТ
Должен ли GitOps с ними бороться? - ДА
Борется ли GitOps с ручными правками? - ПЫТАЕТСЯ
Как у него это получается? - ПОСРЕДСТВЕННО
Так понятнее?
amkartashov
00.00.0000 00:00-1Наконец-то.
Ты путаешь методологию (GitOps) и инструмент (fluxcd). GitOps это подход при котором у тебя конфигурация хранится в git, и любой инструмент который используется для "доставки" конфигурации должен использовать git как источник. Всё. Поэтому
Должен ли GitOps с ними бороться?
НЕТ.
Борьба с ручными правками - это уже детали реализации. Если инструмент тебе такое обещает и не делает - позор ему, такому инструменту, но GitOps тут не при чём. Поэтому правильнее было бы в следующих вопросах наверное (сомневаюсь потому что не работал с Flux) поменять:
Должен ли FluxCD с ними бороться? - ...
Борется ли FluxCD с ручными правками? - ...
Как у него это получается? - ...
А сам GitOps, как методология, тут не при чём, ещё раз повторяю. Ты можешь реализовать его как push так и pull моделью, можешь в качестве инструмента использовать FluxCD/ArgoCD, а можешь Crossplane/Ansible/Terraform или вообще bash скрипты с kubectl/helm/kustomize. Можешь защищаться от ручных правок, строить процесс с review и тестами, а можешь плюнуть и без проверки делать apply. И всё это будет GitOps в каком-то приближении - до тех пор пока ты манифесты у тебя кладутся в git и только оттуда применяются к кластеру каким либо автоматизированным способом.
seasadm Автор
00.00.0000 00:00Ты путаешь методологию (GitOps) и инструмент (fluxcd). GitOps это подход при котором у тебя конфигурация хранится в git, и любой инструмент который используется для "доставки" конфигурации должен использовать git как источник.
Всё.Нет. Это как раз только начало. Моя статья - сборник кейсов, в которых можно применить GitOps и сборник проблем, которые при этом могут случиться. Я отдельно указал это в дисклеймере к статьям.
Вы считаете что делая GitOps вы не столкнётесь с ручными изменениями на инфраструктуре? Или что ими можно пренебречь?amkartashov
00.00.0000 00:00-1Твоя статья утверждает что GitOps бесполезен. В доказательство ты приводишь ручные правки или что в манифесте HelmRelease можно указать неточную версию (latest ещё укажи и жалуйся, ага?), или что артефакты из репы могут пропасть, или ещё какой-то бред.
ПДД бесполезен, потому что светофоры могут не работать а водители превышать скорость.
Сборник кулинарных рецептов бесполезен, потому я их не читаю и жарю яичницу.
ВУЗы бесполезны потому что я там протирал штаны и пропускал лекции.
CIOPS (это не опечатка, не гитопс, а ciops за который ты топишь, как я понимаю, и я не вижу, почему этот аргумент не должен работать против ciops) бесполезен, потому что после каждого релиза автоматически выкатываемого через пайплайны в гитлабе админ идёт и правит манифесты руками, скотина такая.
seasadm Автор
00.00.0000 00:00Судя по содержанию коментариев, вы не прочитали мои статьи. Взять хотябы это замечение что инфраструктурные репозитории мержить нельзя.
Меж тем в них я пытался дать системную картинку. Описать предпосылки -> обещания -> практическую реализацию -> анализ обещаний через практическую реализацию -> выводы. Причем снабдил это множеством ссылок на теорию и документацию потому что практика без теории слепа.
Вы же прошли статью по диагонали, выбрали несколько моментов, которые не понравились и пытаетесь их обсуждать вне контекста. Как в той притче когда человек нашел хвост слона и утверждал что слон это верёвка.
amkartashov
00.00.0000 00:00-1Ты уводишь диалог в сторону. Читал я статью или нет, правильно ты перевёл с английского или не правильно, это всё демагогия и увёртки. По сути ты ничего внятного не пишешь. И не надо на это отвечать, это метаспор, я не буду тебе доказывать, что читал твою статью.
Ты утверждаешь что GitOps бесполезен, используя аргументы, в которых описываемая ситуация не является следствием применения GitOps, а является следствием некомпетентного использования инструментов. То есть у тебя нет логической связи от GitOps к твоим аргументам. Я тебе привёл несколько неувязок в статье, ни на одну ты не смог ответить нормально.
seasadm Автор
00.00.0000 00:00Жаль, что вы фокусируетесь на моментах, которые вам кажутся спорными и отказываетесь видеть общую картину. Я сталкивался с многими странными решениями в своей практике, и к любой вещи подхожу на основе закона Мерфи: если что-то может быть сделано не так, это будет сделано не так. Это принцип, с позиции которого я писал и эту статью. Для меня неожиданно что этот подход вызвал у вас столько недоумения, потому что я считаю, что любой специалист с достаточным опытом рано или поздно приходит к этой позиции.
Развивайте системное мышление, повышайте уровень технической грамотности, будьте позитивным и уважительным и вас определённо ждёт успех в будущем.
Спасибо!
amkartashov
00.00.0000 00:00-2Все просто, нехер делать кликбейтные заголовки для статей. И никто не будет макать в несоответствие между заголовком и содержимым.
seasadm Автор
00.00.0000 00:00Отличный заголовок. Ну а как назвать статью о штуке которая не приносит ничего нового, не решает большинство существующих проблем, добавляет новых, увеличивает сложность системы и трудозатраты? Просто ещё один способ деплоя.
seasadm Автор
00.00.0000 00:00Вы правы. Более пятидесяти плюсов в сумме за обе статьи прекрасно это подчеркивает.
amkartashov
00.00.0000 00:00+1Мне неинтересно развивать дискуссию в этом направлении. Я (аргументированно) утверждаю что твоя статья плохая, и мне этого достаточно.
artazar
00.00.0000 00:00Многие проблемы именно связаны с Helm и с тем фактом, что Helm управляет манифестами, а FluxCD управляет Helm чартами/релизами. Тут действительно может быть неприятно. Но они решают эту проблему и скоро предоставят свои первые результаты:
amkartashov
00.00.0000 00:00Итого
Вторая спорная статья с буллщит аргументами.
seasadm Автор
00.00.0000 00:00+1Как говорят мудрецы, в споре рождаются истина. Всегда готов пояснить моменты, показавшиеся спорными.
artazar
00.00.0000 00:00+1Спасибо за статью! Использую GitOps + FluxCD уже несколько лет благополучно. Начинал только с инфраструктурной части, а последний год и деплой приложения переключил с CI Ops на Git Ops и не жалею. Попробую обозначить главные пункты, с которыми не согласен, отдельными тредами под своим комментарием :)
artazar
00.00.0000 00:00Потому что в данном конкретном случае конфигурация вашего приложения будет зависеть уже от четырёх репозиториев (репозиторий приложения c чартом, репозиторий «единой точки конфигурации платформы», инфраструктурный репозиторий flux, репозиторий с файлами terraform) и двух систем деплоя (flux и terraform).
здесь не нашел какой-то громкой большой проблемы, если процессы настроены, устаканены, задокументированы - то есть когда ops команда хорошо делает свое дело, а не "тяп ляп - и так сойдет"
1 - terraform репозиторий по умолчанию является "провижинингом инфраструктуры", и это просто должен быть общий стандарт, все знают, что именно там создается кластер и его уникальные специфические значения - никакой проблемы
2 - репозитории с чартом и «единой точки конфигурации платформы» можно смело смержить, не знаю зачем разделять; или же чарт может лежать рядом с кодом приложения; оба способа понятны
3 - инфра репозиторий может существовать, а может и нет, здесь каждый под себя строит процесс; я думаю его нужно отделять только если инфрой занимается совсем отдельная команда; но тогда и процессы внутри компании должны быть четко разделены; но уж точно 100% изменения в приложении не должны никак быть связаны с инфра репозиторием
в общем, я не понимаю совсем аргумент "много репозиториев - это плохо"
для меня это "хорошая структура"
seasadm Автор
00.00.0000 00:00Я правильно понимаю, что этот комментарий скорее в поддержку моей мысли?
это очевидно
речь идёт о случае когда у нас много микросервисов и values для них хранятся в едином месте
существование инфра репозитория - фундаментальное требование гитопс
Есть такой принцип программирования - KISS (keep it simple, stupud).
Много репозиториев это не плохо при условии что это хорошо спроектировано. Согласно моему опыту, в отдельные репозитории нужно выносить только явно используемые совместно вещи. Если вы просто вынесете в отдельный репозиторий настройки всех приложений, то возникнет просто разрыв между приложением и его конфигурацией, который будет не очевиден и который потребуется покрыть документацией. Если вы добавите к этому репозиторий глобальных настроек приложенй, то просто будете просто теряться между репозиториями - в какой из них положить тот или иной конфигурационный параметр.
В качестве резюме - если создание отдельного репозитория сможет сократить сложность вашей системы и/или ваши трудозатраты, - во всех остальных случаях лучше этого избегать.
artazar
00.00.0000 00:00Первый — valuesFiles
Следующий вариант — valuesFrom
Есть еще один очень удобный вариант. Использовать механизм патчей от kustomize. Если совсем не любите/не используете kustomize, то можно остаться на хелм чартах, но использовать патчи. И это будет выглядеть как-то так:
patches: - patch: |- apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease metadata: name: myapp spec: values: clusterCustomVar: newValue target: kind: HelmRelease name: myappseasadm Автор
00.00.0000 00:00Это опять же не позволит сделать stage propagation через merge.
Почему я настаиваю на мерже изменений для доставки изменений по окружениям? Если у нас окружения описаны отдельными репозиториями или папками в гите, и конфигурацию там мы изменяем вручную, либо при помощи каких-то скриптов, то это потенциально приводит нас к ситуации когда накапливается environment drift.
artazar
00.00.0000 00:00я не выстраивал такую структуру с мержем изменений
если ее действительно можно выстроить работоспособной, то значение внутри кластера в виде секретов - это действительно выход
artazar
00.00.0000 00:00Проблема секретов
Это вообще широкая тема за рамками GitOps, я бы совсем не стал сюда добавлять это. GitOps предлагает и поддерживает разные подходы для этого, но ничего не прописывает стандартом. Каждый для себя выбирает сам.
seasadm Автор
00.00.0000 00:00Тема широкая, согласен, но она фундаментальная. Это та вещь, которая must have. И обойти её было бы по крайней мере не правильно.
В гитопс есть понятие Git as the single source of truth. Мне было интересно как сделать управление секретами, чтобы следовать этой идее.
Кстати как вы относитесь к идее Git as the single source of truth? Считаете ли вы её важной для гитопс?
artazar
00.00.0000 00:00Да, конечно, это идея фундаментальна. Но кажется мы ее слегка по-разному понимаем. Я понимаю так, что Git хранит описание желаемого состояния. GitOps инструменты помогают приводить целевую инфраструктуру к этому желаемому состоянию и следить за тем, чтобы не происходило отклонения от этого состояния.
seasadm Автор
00.00.0000 00:00Хорошо. А что в этом подходе специфично для GitOps?
artazar
00.00.0000 00:00GitOps специфика для меня = никаких ручных действий с инфраструктурой, любое изменение - это git commit. И если инфраструктуру стереть в пепел, ее можно полностью восстановить исходя из состояния, которое зафиксировано на репозитории.
seasadm Автор
00.00.0000 00:00Ну давайте по порядку
никаких ручных действий с инфраструктурой, любое изменение - это git commit
Эта проблема известна ещё с эпохи "синхронизации конфигурации". Я описывал это в первой статье в разделе про configuration drift и сервера-снежинки. И в процессе развития темы статьи дал понять что GitOps не толерантен к ручным изменениям (по крайней мере не более толерантен чем обычная SCM с pull-подходом и reconcilliation loop). Он не ставит во главу угла борьбу с ручными изменениями. А ручные изменения обязательно будут, просто потому что они могут быть.
И если инфраструктуру стереть в пепел, ее можно полностью восстановить исходя из состояния, которое зафиксировано на репозитории.
Принципы infrastructure-as-code:
#1 Systems can be Easily Reproduced
#2 Systems are Disposable
#3 Systems are Consistent
#4 Processes are Repeatable
#5 Design is Always Changing
Вы только что описали первый и четвёртый. Вот только эти принципы были сформулированы за добрый десяток лет до гитопс.
Чего здесь нет, так это про обязательное хранение кода IaC в гите. Но хранение кода в гите известна как хорошая практика уже более десятка лет. Посмотрите 6-й пункт теста Лимончелли.
Так что такое GitOps? Что мы сейчас с вами обсуждаем? Это просто требование хранить манифесты IaC в гите?
artazar
00.00.0000 00:00IaC безусловно входит в GitOps.
Для меня вообще грань эта едва уловима, эти понятия схожи. Разве что IaC просто говорит нам хранить все в виде кода, а GitOps добавляет поверх этого еще автоматический процесс синхронизации с целевой средой.
Что мы сейчас с вами обсуждаем?
Ну я тоже потерялся. Тред начинался с секретов.
seasadm Автор
00.00.0000 00:00GitOps добавляет поверх этого еще автоматический процесс синхронизации с целевой средой.
Парадигма "синхронизации конфигурации" стара как мир. Впервые идея декларативного описания инфраструктуры и автоматическая синхронизация конфигурации с ним была реализована в cfengine (первая версия 1993 год).
Если говорить о развитии парадигм, то сейчас главенствует immutable infrastructure. Полностью автоматизированные пайплайны доставки её необходимый аттрибут. Я описывал это в первой части статьи.
Возможно вы имеете в виду разницу между pull и push подходом? Pull-подход был основным в SCM второго поколения - puppet и chef. SCM-системы третьего поколения (ansible, salt,terraform) от него отошли. Как думаете почему? (ответ - pull подход очень ресурсозатратен и не может до конца предотвратить configuration drift)
Кроме того гитопс всего лишь рекомендует использовать pull. С push-подходом он тоже ок.
Для меня вообще грань эта едва уловима, эти понятия схожи.
Ну так можете объяснить эту грань? Мы ведь говорим про IT. Строгая теоретическая база её фундаментальное свойство. Вот вы явно адепт или апологет гитопс. Чувствуется что вы любите эту концепцию. Что мне нужно чтобы делать гитопс?
Покачто вы описываете идеи, самая свежая из которых появилась не менее деясти лет назад. Самое оригинальное из того что вы сказали это превращение давно и хорошо известной хорошей практики держать IaC в гите в обязательное требование. Этого достаточно?
Вот у меня например дженкинс и пайплайны как код. У меня дженкинсфайл, который билдит имидж, sed'ит его в шаблон ямлика и аплаит ямлик в куб. Всё это лежит в гите и триггерится по пушу в гит. У меня гитопс?
Ну я тоже потерялся. Тред начинался с секретов.
Не совсем. Тред начинался с обсуждения секретов в рамках одной вполне определённой идеи.
artazar
00.00.0000 00:00И какая из них безопаснее при условии, что они обе имеют админские права? Это риторический вопрос. Потому что админские права есть админские права.
Хороший риторический вопрос. Но при сравнении CI системы против GitOps, здесь речь скорее про то, что не нужно в CI систему класть пользователя с доступом в кластер. В этом и находится ключевое различие.
seasadm Автор
00.00.0000 00:00Почему в CI систему нельзя класть пользователя с доступом в кластер?
Во-первых хранилище секретов это один из важнейших функционалов CI систем. Мы можем достаточно гибко заводить секреты, раздавать на них права и защищать от кражи.
Во-вторых есть множество способов интеграции CI систем с kubernetes. От авторотирующихся токенов в специальных модулях до установки раннера в кластер и использования сервисаккаунтов (схема очень близкая к контроллерам flux).
Но моя основная мысль здесь - к безопасности нужно подходить осмысленно. Гитопс утвержданием что он безопасен по умолчанию вводит в заблуждение.
artazar
00.00.0000 00:00Почему в CI систему нельзя класть пользователя с доступом в кластер?
Не утверждаю, что нельзя. Я имею в виду, что в случае GitOps мы этого не делаем, и следственно не добавляем точку хранения доступа в инфраструктуру. А в случае CI Ops делаем. И это обычно и является тем пунктом, которые ставится GitOps подходу в плюсы.
seasadm Автор
00.00.0000 00:00Сомнительный/неоднозначный плюс.
Во-первых мы точно также можем не делать это в CIOps.
Во-вторых замена непосредственного доступа на апосредованный на мой взгляд не сильно поднимает безопасность.
artazar
00.00.0000 00:00А как не делать это в CIOps? Что имеется в виду?
seasadm Автор
00.00.0000 00:00А как не делать это в CIOps? Что имеется в виду?
Я же привёл пример - поднять раннер ci системы в целевом кластере и использовать сервисаккаунт для доступа к нему. Эта схема повторяет модель безопасности контроллеров флюкс например.
artazar
00.00.0000 00:00не сильно поднимает безопасность.
не сильно, согласен, но немного поднимает
они еще добавляют один пункт, который я не упомянул
For that, your environment only needs access to your repository and image registry. That’s it. You don’t have to give your developers direct access to the environment.
но тут на самом деле разного рода разработчики бывают, не всем будет приятно совсем не видеть напрямую, что происходит с контейнерами
seasadm Автор
00.00.0000 00:00+1По ходу тут явное передёргивание. Действие "положить ключ доступа к кластеру kubernetes в CI систему" трактуется как "дать ключ разработчику". Это севершенно не верно. В CI системе мы можем при желании запретить доступ разработчика к этому ключу.
Единственный наверное кейс, в котором безопасность с GitOps увеличивается, это когда CI-систему и кубовые кластера эксплуатируют разные команды, и команде CI-щиков не хочется выдавать ключи доступа к кластерам. И то этот случай можно решить установкой раннера в кластере и использование сервисакаунта.
Ну плюс на раннере можно выполнить произвольный скрипт, а на контроллере флюкс только создание объекта в кубе, но это не особо существенное различие.
artazar
00.00.0000 00:00Процедура отката
Общий комментарий на всю секцию. Вы, кажется, просто перечислили несколько способов как делать не надо.
На самом деле процедура отката = git revert коммита, который привел к обновлению приложения. То есть либо версии образа, либо версии хелм чарта. И система откатывается. На этом все.
С точки зрения инфраструктуры может быть чуть сложнее, в том плане, что в коммите может быть и много структурных изменений. И вопрос перетекает в git-гигену - правильный набор изменений внутри коммита сделает откат возможным через revert. И это в разы, в разы удобнее, чем ходить по кластерам руками править конфигурации. Мне кажется, тут бессмысленно спорить)
Единственный существенный минус `git revert`, который я вижу, это когда происходит предварительная мутация структур баз данных и нужно сначала предусмотреть откат на этом уровне перед откатом приложения. Но это тоже не в рамках GitOps, это про искусство сохранения обратной совместимости и т.п.
seasadm Автор
00.00.0000 00:00+1Основная мысль здесь была в том, что откат нужно хорошо спроектировать. Следование пути гитопс не гарантирует возможность откатиться. Возможно я это чуточку многословно изложил, с избыточным количеством примеров, но мысль именно такая.
artazar
00.00.0000 00:00Хорошая мысль, поддерживаю на 100%.
Но опять же, откат нужно спроектировать в любой системе. Поэтому это не минус/плюс GitOps подхода. GitOps подход просто дает возможность делать это через `git revert`, и это приятно.
seasadm Автор
00.00.0000 00:00+1Здесь я стриггерился на этот пункт
https://www.gitops.tech/#easy-and-fast-error-recovery
Он выглядит так будто "git revert всё что вам нужно". Это явная брехня.
artazar
00.00.0000 00:00А что у нас насчёт CI Ops? В рамках CI Ops на Gitlab нам не нужно делать кучу дополнительных телодвижений для обеспечения функционирования GitOps. Нам нужно:
Сделать CI-скрипт сборкой и публикаций докер-образа.
Добавить в скрипт деплой Helm-релиза через Helm apply.
Создать аккаунт для доступа CI-системы в Kubernetes.
Я бы в целом сказал, что вы замыкаете обсуждения на уровне "деплоя приложения", хотя есть еще большой аспект управления Kubernetes инфраструктурой и ее наполнением, для чего GitOps инструменты очень хорошо подходят, и здесь CI система совсем не подходит.
Но даже если говорить только про деплой приложения, то я бы добавил еще ряд пунктов:
разработать удобную и масштабируемую CI шаблонизацию
проработать удобные нотификации от CI систем
позаботиться о том, чтобы из енва и приложения можно было бы определить из какого билда оно прилетело (тут благо почти все CI системы это уже умеют в аннотации проставлять, но мало ли)
при каких-то изменениях CI скриптов проходиться по n репозиториев приложений (мое любимое, даже с максимальной шаблонизацией CI шаблонов и автоматизацией массовых git апдейтов это всегда весело)
продумать и решить вопрос привязки енва к вашему git flow
решать вопрос падающих helm upgrade на этапе деплоя (retries, timeouts, etc)
Это все просто с ходу пришло в голову по опыту связки CI + helm. Очень рад был уйти от этого и переключиться на FluxCD + kustomize. Не могу сказать, что сразу решены все проблемы, но по общему ощущению всё сильно стабильнее.
seasadm Автор
00.00.0000 00:00Обсуждение я замыкаю на уровне деплоя приложения потому что гитопс замыкается на уровне деплоя приложения. Тоесть это не continuous delivery (определение понятий есть в первjй части статьи), а просто способ организации деплоя.
разработать удобную и масштабируемую CI шаблонизацию
Разработать удобную и масштабируемую CI шаблонизацию придётся в любом случае. В случае гитопс вам придётся написать скрипт апдейта инфраструктурного репозитория. И потенциально его написать не проще чем скрипт деплоя через тот же хелм.
проработать удобные нотификации от CI систем
Нотификации как правило встроены в CI систему. И их возможности больше и шире чем у того же Flux Notification controller. Их настройка проще.
позаботиться о том, чтобы из енва и приложения можно было бы определить из какого билда оно прилетело (тут благо почти все CI системы это уже умеют в аннотации проставлять, но мало ли)
Да. Причем за счет стандартных переменных пайплайна CI это сделать проще чем в gitops(который этот вопрос тоже никак по умолчанию не решает - я писал об этом в статье). Я кстати говорю про это в этом докладе https://youtu.be/1uhfChFSktQ
при каких-то изменениях CI скриптов проходиться по n репозиториев приложений (мое любимое, даже с максимальной шаблонизацией CI шаблонов и автоматизацией массовых git апдейтов это всегда весело)
Во-первых в случае GitOps стоит ровно такая же проблема, потому что вам точно также нужно писать CI-скрипты для обвязки.
Во-вторых CI системы умеют нативно в централизованный CI. Посмотрите инклюд Gitlab CI из централизованного GIT репозитория или build configuration template в teamcity.
продумать и решить вопрос привязки енва к вашему git flow
Этот пункт, как я понимаю, обратен второму пункту? Посмотрите пожалуйста место про трекинг окружений в гитлаб в моей статье.
решать вопрос падающих helm upgrade на этапе деплоя (retries, timeouts, etc)
helm upgrade --atomic --timeout 600 ?
artazar
00.00.0000 00:00При всем уважении, этот ответ - это "подгон под ответ".
Ну то есть, при том, что я считаю, что GitOps проще, а вы - что CI Ops проще, мы тут можем сколь угодно долго спорить, но останемся при своем мнении.
Я находился на стороне CI Ops продолжительное время, была очень продуманная шаблонизация с инклюдами, были выверенные временем деплойменты через helm, прошел через все возможные грабли.
Но когда перешел на GitOps + FluxCD, я просто почувствовал насколько это проще.
Пожалуй, это моя главная мысль в этой ветке.
seasadm Автор
00.00.0000 00:00+1А можете пояснить почему стало проще? Я описал свои претензии к гитопс в статье. В кратце это
Количество скриптов CI не уменьшается, добавяются новые инфрастуктурные сервисы и доступы, увеличивается сложность инфрыструктуры и пайплайна.
Я отразил это в чеклистах.
artazar
00.00.0000 00:00Сразу скажу, буду субъективен, и части задач, которые вы решаете, у меня на данный момент просто нет.
1) CI часть упростилась, стадия с деплойментом свелась к `git push`
2) Нет дрифта конфигурации, любые изменения откатываются сами - это пожалуй один из самых больших жирных плюсов для меня
3) Удобнее использовать `git revert` как откат версии, это просто работает, не заходя в кластер
4) Мониторинг и отладка падений тоже нравится, объект HelmRelease всегда содержит логи и ошибки от вызова хелма, по логам контроллеров можно вообще всю историю событий установить для всех объектов
5) Не забываем про историю изменений через git history
Большинство из перечисленных вами пунктов - это единоразовая работа на старте. После этого об этом не беспокоишься. Такие вещи меня совсем не смущают, пока не надо что-либо повторять регулярно.
С CI Ops мне много приходилось делать руками в кластере, чтобы чинить состояние. С GitOps этого делать практически не приходится и всегда можно вернуться в заведомо работоспособную точку.
seasadm Автор
00.00.0000 00:001) А как вы генерите то что нужно запушить? Как решаете вопрос stage propagation? У вас всего одно окружение?
2) Вы не используете флюкс с хелмом?
3) Как вы определяете на какой комит откатиться? У вас репозиторий на каждое окружение каждого приложения? Как вы определяете что конфигурация в конкретном комите рабочая?
4) Вы не используете нотификации о прохождении пайплайнов? А если билд или пуш сфэйлится?
5) Вам хватает git history? Как вы определяете какая конфигурация выкатилась, а какая упала например?
С CI Ops мне много приходилось делать руками в кластере, чтобы чинить состояние.
А что помешало сделать это через перезапуск стейджей пайплайнов? У вас монолитные пайплайны?
artazar
00.00.0000 00:001) CI пайплайн просто пушит версию приложения сначала в dev, потом в stage, потом в prod - три разных kustomization.yaml файла. Версия генерится в момент сборки.
2) Для деплоя своих приложений хелм не используем. Для кластерной обвязки (мониторинг, логгинг, безопасность и тп), используем.
3) Вообще редки ситуации, когда нужно прямо в далекое прошлое откатываться, чаще всего это в виде "задеплоили, что-то пошло не так, откатили", и тут не надо много ума определить куда откатиться. У нас монорепа для флакса, там хранится состояние всех сред со списком версий всех текущих приложений.
4) Конечно используем. Любой упавший пайплайн о себе сообщает.
5) Хватает. Если честно, тут сложно ответить абстрактно, проще было бы на конкретном примере. Обычно есть какая-то проблема, она исследуется, дальше понимаем когда она возникла - в этой точке по времени будет какой-то коммит, который нужно откатить.
А что помешало сделать это через перезапуск стейджей пайплайнов? У вас монолитные пайплайны?
Перезапуск стейджей - это все равно ручное действие. Retries не сильно распространенная фича, насколько мне известно. На самом деле, я этот пункт немного не додумал, здесь не переход CI Ops на GitOps помог, а с helm на kustomize скорее, ибо с helm действительно часто приходилось сражаться.
seasadm Автор
00.00.0000 00:001) Выглядит так будто у вас очень маленький проект, для которого хватает кастомайза, либо ваши кастомайзы должны быть адом копипаста. Вы пересобираете имиджи для каждого окружения? Вы настолько уверены в повторяемости сборок? Мне интересно какой у вас стек и какое медианное количество собственных строк кода на проект. SBOM вы составляли?
2) Закономерно. Хелм экстремально популярен. Все основные проекты развивают свои хелм чарты. Даже если основа деплоя проекта - оператор, обвязку к нему тоже как правило заворачивают в чарт.
4) Тоесть внедрение гитопс заставило вас принести в инфру ещё одну систему алертинга?
5) Интересно сколько команд в вашей организации, сколько у них проектов и как часто они релизятся. По моим ощущениям, после двадцати проектов с недельным релизным циклом разбираться в инфраструктурных гитах становится уже достаточно сложно.
Перезапуск стейджей - это все равно ручное действие.
Вы не считаете git revert ручным действием? У вас он как-то автоматизирован?
YegorP
Почему очевидно? Мне в какой-то момент стало неочевидно. Тогда я предложил команде перестать притворяться, что develop достаточно стабилен, чтобы целиком раскатывать его на stage и затем на prod. Он почти никогда не стабилен: туда постоянно выкатывают что-нибудь свежее и там всегда висит что-нибудь недоделанное, а иной раз даже отложенное в долгий ящик. Кто-то предлагает обмазывать всё нестабильное feature-тогглами, но тогда код становится месивом из тогглов.
Короче, мы собираем stage из тех же самых веток, из которых собирается develop, но только после их адресного тестирования в develop. Уже потом тестируем stage в целом и раскатываем его на prod. А develop живёт практически как форк - он никуда не вмёрживается (кроме бранчей для разрешения конфликтов, но это другая история; в любом случае develop никогда не попадает в prod).
Естественно, это компромисс со своими минусами. Но он вполне покрывает условия с ограниченным числом сред, ручным тестированием (ибо пробелы в автотестах) и зависимыми командами (мобильщикам нужен свежий бэк). Сейчас хотим избавляться от этих статических сред (кроме прода, естественно) в пользу эфемерных. Типа создал PR - сразу получил в нём ссылку на отдельное окружение для тестирования. Дальше по желанию либо сразу в прод, либо накопить изменения в stage и уже потом в prod.
Короче, для меня теперь под большим вопросом очевидность проталкивания всей среды по этапам стабильности. И, возвращаясь к теме топика, такой подход исключает попадание develop-конфигурации в prod. Вполне можно рассмотреть. Не исключено также, что я несу чушь и заразил команду каким-то неортодоксальным пониманием develop/stage/prod, но в целом это сработало, и мы больше не ломаем голову относительно стабильности целых сред.
seasadm Автор
На самом деле, здесь речь идёт немного о другом — об инфраструктурном репозитории. Код, который в нём лежит, — это не код программы, а код, описывающий её деплой. Вы же говорите об артефакте, который собираете из программного кода и этот вопрос "outside of GitOps scope".
YegorP
Окей, сижу краснею насколько я не в теме был. Но даже так, что мешает и в инфраструктурном репозитории собирать каждую среду отдельными бранчами, а не промоутить целиком develop в stage и потом в prod? Тогда специфика одной среды не будет перетекать в другую.
seasadm Автор
Если говорить об общих принципах и распространённых "хороших практиках", то у нас есть методология 12-factor app, в которой первый фактор говорит, что должна быть одна кодовая база, отслеживаемая в системе контроля версий, — множество развёртываний (https://12factor.net/ru/codebase ). Когда у вас несколько веток, код в которых принципиально отличается друг от друга, то между ними накапливается drift, код разъезжается и вам приходится тратить дополнительные силы на поддержку этой разницы. В частности, за это ругают gitflow, в котором предполагается несколько отдельных долгоживущих веток под разные нужды.
Но вообще я давал ссылки в статье на стратегии организации инфраструктурных репозиториев от авторов flux. Там много примеров, где одна ветка и несколько папок на окружения. Это близко к стратегии ветка на окружение, и это, на мой взгляд плохая практика (исходя из вышеизложенных соображений).