

На этой диаграмме хорошо видно, почему облачная инфраструктура позволяет гарантировать доступность вашего проекта
Есть хорошая фраза: «Нет никаких облаков, есть просто чужие вычислительные мощности».
Эту мысль стоит всегда держать где-то на заднем плане, когда планируешь развитие своей инфраструктуры. Облако — это не волшебная коробочка, которая гарантирует 100-процентную неубиваемость сервисов и их доступность. Это скорее история про быстрое получение почти произвольного объёма ресурсов ровно на тот период, когда они вам нужны. Где-то в бэкенде всё равно крутятся те же самые сервисы, выходят из строя и заменяются жёсткие диски. Просто теперь большинство этих задач — не ваша головная боль.
Привет, меня зовут Олег Вознесенский, и я руководитель разработки отдела развития инфраструктуры для анализа данных в Газпромбанке. Сегодня я попробую рассказать про то, какие основные выгоды можно получить от облаков, какими они бывают и как правильно строить свою инфраструктуру, чтобы потом не было мучительно больно. Поговорим о классической дилемме питомцев и домашнего скота и о том, как правильно всё это запекать.
Если в ядре вашей инфраструктуры до сих пор есть сервера, которые тщательно настраиваются вручную уже шестым поколением бородатых людей в свитерах, то пост может быть вам полезен.
Что такое облако
На мой взгляд, это понятие отличается от обычного хостинга несколькими ключевыми моментами:
- Делегирование ответственности за инфраструктурный слой, а часто — и за другие элементы архитектуры.
- Быстрый автоматизированный доступ к нужному объёму вычислительных мощностей.
- Перенос эксплуатационной сложности с вас на провайдера облачных услуг.
То же самое можно обеспечить на своих железных серверах, но нужно будет расширить штат редкими недешёвыми специалистами и следить сервером за всем зоопарком самостоятельно.
По сути, это уровень абстракции над человеческими и железными ресурсами с хорошо развитым API.
Не облако в современном понимании: надо написать десяток заявок и переругаться со всей техподдержкой, чтобы вам выделили виртуальную машину и пробросили сети.
Облако: вы, использовав визуальный/программный интерфейс, в течение нескольких минут получили работающую инфраструктуру со всеми сетевыми экранами, балансировкой, нужным числом виртуальных машин и подключённых томов.
Текущий рынок облачных провайдеров

Со стандартами всё как обычно
Ещё в 2013 году был разработан Cloud Infrastructure Management Interface (CIMI) — открытая подробная спецификация API. Можете подробнее посмотреть тут.
Идея более максимально эффективного использования железа за счёт их разделения между пользователями давно витала в воздухе начиная от совместного доступа к мейнфреймам вычислительной эпохи, появившейся позднее виртуализации, и текущим состоянием рынка, где нарезается ломтиками абсолютно всё — от vCPU до последнего мегабита сетевого интерфейса.
Основным законодателем мод на рынке стал, конечно, Amazon с его AWS. Он вышел на рынок в далёком 2006 году с тремя сервисами: Elastic Compute Cloud (EC2), объектного хранилища S3 и Amazon SQS и до сих пор определяет «пейзаж» этой отрасли спустя десятилетия. Сейчас большинство облачных провайдеров развивает набор сервисов, близкий к экосистеме AWS, что позволяет плюс-минус получать сходный набор возможностей.
Каждая из этих компаний очень старается стать очередным «убийцей AWS», но в итоге занимает своё особое место под солнцем. В РФ сейчас сложилась весьма специфическая ситуация, когда крупнейшая тройка из AWS, Google Cloud и Microsoft Azure стала недоступна, а потребность рынка в подобных решениях никуда не делась. Всё это дополнительно усугубляется необходимостью соответствовать 152-ФЗ «О персональных данных» и другим регуляторным директивам.
В итоге в России облачную нишу с переменным успехом пытается заместить несколько крупных игроков. Вот только некоторые из них:
- Yandex Cloud.
- Selectel.
- T1 Cloud.
- Megafon Cloud.
- КРОК Облачные сервисы.
- Timeweb Cloud.
Большинство из них — полный набор услуг в виде S3-хранилищ, database-as-a-service (DBaaS), Kubernetes, облачные балансировщики и все остальные атрибуты современного сервиса. У большинства также есть услуга виртуального рабочего места как сервиса (VDI), хотя не совсем понятны перспективы этого сегмента после ухода Citrix и Microsoft. В плане API те же КРОК и Yandex Cloud предоставляют AWS-подобный вариант, хотя и с неполным соответствием: масштабы всё-таки разные.
Уровни абстракции облачных услуг
Допустим, вы решили переходить в облака. Давайте поближе посмотрим на то, какой объём задач мы можем делегировать облачным сервисам в разных моделях обслуживания.
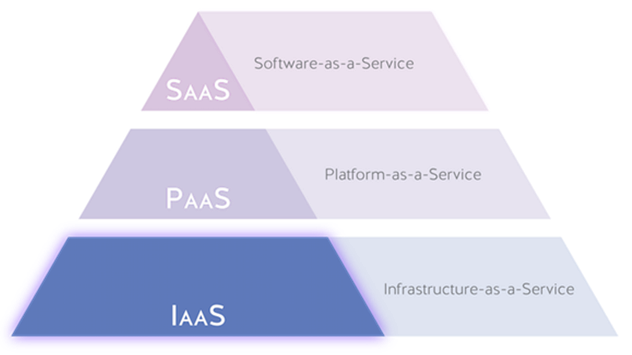
Иерархия «*aaS»-терминов очень хорошо описывается данной пирамидой. В основе лежат сервисы, наиболее близкие к «железу и физике», на вершине — абстракции, которые просто работают.
IaaS
Infrastructure-as-a-service.
В этой модели предполагается, что вы получаете по запросу доступ к ресурсам в виде классических виртуальных машин, СХД, сетевых ресурсов и каких-то инфраструктурных элементов, облегчающих их эксплуатацию (например, фаерволов и балансировщиков сетевой нагрузки). Это очень похоже на классический низкоуровневый вариант администрирования, только серверная теперь у вас виртуальная. Если вылетит диск, отключится питание или особо опасный бульдозерист-рецидивист перекопает оптоволокно, то этим будет заниматься ваш провайдер в соответствии с SLA.
Вам самостоятельно придётся рассчитывать риски недоступности региона, задержки от вашего сервиса до потребителя и самостоятельно управлять ОС.
Классический пример — Amazon EC2.
PaaS
Platform-as-a-service.
Это возможность получить какое-то базовое программное обеспечение, запущенное и управляемое облаком, например, базы данных или kubernetes control plane.
В общем случае вы не заботитесь об инфраструктуре, на которой развёрнуты эти сервисы, не заботитесь о тонком тюнинге, настройках репликации, отказоустойчивости, резервном копировании и прочем — вы просто управляете сервисом через какие-то абстрактные укрупнённые параметры (вроде размера диска и количества реплик), реализованные в облаке.
Как там реплицируется база данных и как обеспечивается заявленный уровень отказоустойчивости очереди, вам неважно.
Классический пример — Amazon S3.
SaaS
Software-as-a-service.
Вы делегируете практически всё, кроме голой бизнес-логики. В этой модели поставщик предоставляет вам API или веб-интерфейс/ПО для доступа к приложению, которое он полностью поддерживает. Простейший пример — gitlab, который работает не в on-premise-варианте на ваших мощностях, а на стороне провайдера услуги. Вам не нужно следить за обновлениями, заниматься резервированием и тому подобным. У вас просто есть репозитории и CI-система, интегрированная в ваши бизнес-процессы.
Первым SaaS считается Amazon SQS.
Часто наиболее востребованные типовые варианты сервисов SaaS/PaaS получают собственные названия вроде БД как сервис (DbaaS) или managed Kubernetes (KaaS). Концепция здесь примерно схожая: вы занимаетесь своей частью работы, а магия внутри облака быстро и удобно обеспечивает вам API для масштабирования ваших бизнес-задач.
Разновидности облаков
По типам облака обычно разделяют на несколько видов.
Публичное облако. Вычислительные ресурсы принадлежат внешнему провайдеру, им же и управляются. Например, Amazon, Yandex или Microsoft предоставляют полный набор услуг на этом рынке. От клиентов нужны только деньги и интеграция с облачной инфраструктурой.
Частное облако. Эта история актуальна для очень крупных компаний. Например, тот же Мегафон использует OpenStack для внутренних целей. Всё то же самое, но заказчиком становятся уже внутренние клиенты. Если вы думаете, что скорость и удобство в масштабировании важны только для внешних потребителей, то вы просто никогда не пробовали согласовывать в течение нескольких недель заявку на выделение ресурсов в кровавом энтерпрайзе. Понятный и простой API с интегрированным биллингом позволяет своим командам получать и отпускать нужное количество ресурсов в рамках выделенных бюджетов. Сейчас МФ стал предлагать Megafon Cloud как продукт, в том числе и для внешних заказчиков.
Гибридное облако. История для компаний поменьше, где есть свой условный Kubernetes в паре дата-центров, но недостающие ресурсы берутся у внешнего поставщика. Например, основная нагрузка может ложиться на свою инфраструктуру, а машинное обучение может происходить эпизодически в течение нескольких суток на инфраструктуре Yandex Cloud или AWS.
Чуть больше подробностей на примере AWS
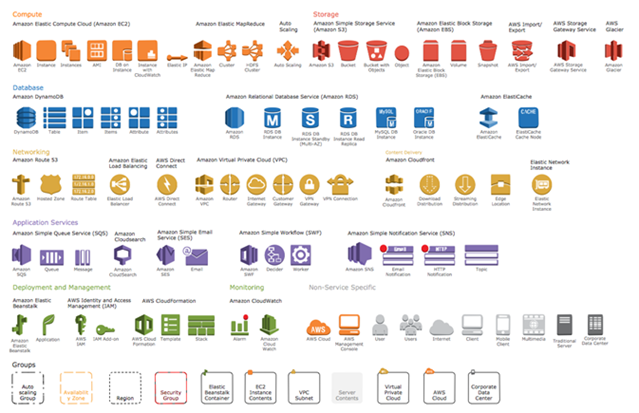
На текущий момент AWS — это уже несколько сотен различных сервисов в виде единой облачной экосистемы и с развитым API
На самом деле вместо Amazon можно взять любого более или менее крупного облачного провайдера. В основных ведущих облаках — примерно то же самое (возможно, с чуть меньшими масштабом и разнообразием). Взгляните для примера на возможности Yandex Cloud.
Допустим, что у нас есть некое приложение, которое запущено в AWS. Наш бэкенд состоит из нескольких типовых элементов. Пусть это будет некое приложение на Go, PostgreSQL, и ещё сбоку мы прикрутим Redis для кеширования. Нагрузка у нас пусть будет неравномерной, завязанной на пользовательскую активность в регионе GMT+3. Одно из главных правил облачной инфраструктуры — бери столько ресурсов, сколько тебе нужно в данный момент, и освобождай, как только они не нужны.
Autoscaling
Поэтому начнём с автоскейлинга. Наши EC2-инстансы объединены в auto scale-группу, которая автоматически масштабируется в зависимости от нагрузки, показателей мониторинга или вручную, если очень надо. В нашем варианте это может быть поднятие дополнительных узлов с worker’ами на Go, которые обрабатывают пользовательские запросы в бэкенде. Триггером для добавления узлов может быть метрика утилизации CPU или слишком большой размер очереди в redis — сигнал о том, что условные воркеры не успевают её разгребать. Тут важно тщательно рассчитать лимиты и алгоритм масштабирования, чтобы из-за бага внезапно не создать посреди ночи тысячи инстансов, поставив личный рекорд суммы в месячном счёте за услуги облака.
Load balancer
Следующий важный элемент — балансировщик нагрузки, load balancer. Это именно тот узел, который будет перераспределять нагрузку между нашими инстансами приложения в бэкенде. В принципе мы можем и не использовать отдельный сервис балансировки, а просто добавить ещё несколько виртуальных машин, сконфигурировать на них haproxy или nginx, настроить балансировку с отказоустойчивостью, прикрутить autodiscovery при создании новых узлов и всё прочее. Но гораздо проще будет использовать уже работающий облачный load balancer, который всё это умеет: перенаправляет нагрузку в зависимости от здоровья экземпляров вашего бэкенда плюс сам заказывает и следит за сертификатами HTTPS.
Application Firewall
Следующий слой — Application Firewall. AWS WAF — это продвинутый инструмент, который позволяет вам получить дополнительную защиту от широкого спектра атак и помогает отсеивать ботов от живых посетителей. Гибкий WAF позволит защитить ваше приложение и снизить риски атаки. Затрудняюсь назвать существующие opensource-решения, позволяющие справиться с подобным спектром задач.
CDN
Один из ключевых элементов вашей инфраструктуры. Очень часто значительную часть контента можно кешировать. У облачных провайдеров с развитой инфраструктурой есть дата-центры во всех ключевых локациях с высокой плотностью населения, где находятся ваши потребители. В Южной Америке или Центральной Африке с этим похуже, но тоже решаемо. С использованием этого инструмента вы решите сразу две ключевые проблемы:
- Минимизация задержки от вашего сервиса до клиента. Несмотря на 0-RTT и прочие техники, не очень круто ждать, пока ваш клиент из Японии завершит все хендшейки с узлом в Амстердаме.
- Снижение нагрузки на ваш бэкенд. Вместо того чтобы отдавать раз за разом одно и то же напрямую от бэкенда, вы можете переложить это на географически распределённый CDN.
Мы можем, конечно, собрать его самостоятельно, арендовав сервера во всех регионах присутствия и настроив anycast, но в Amazon есть CloudWatch, и он просто работает.
S3
Контент мы можем хранить непосредственно в объектном хранилище S3 со всей гибкостью настройки бакетов, версионированием и прочим. Есть и открытые аналоги, которые можно поднять самостоятельно, но на Amazon оно отказоустойчивое и интегрируется с сервисами защиты информации.
База данных
Вы можете нанять хороших DBA, которые смогут настроить и поддерживать в дальнейшем отказоустойчивую распределённую БД. Либо можно воспользоваться Amazon RDS (Amazon Relational Database Service), где вы просто выберете нужный тип БД и быстро сконфигурируете отказоустойчивый кластер «из коробки». Облачный провайдер позаботится об этом за вас.
Физическая связность
Сейчас облака — это не просто дата-центры в регионах присутствия. Все дата-центры связаны друг с другом выделенной оптикой. Это огромная сеть трансокеанических и трансматериковых кабелей. В частности, в Amazon — 25 регионов с 80 зонами доступности и примерно 108 точек прямого подключения.
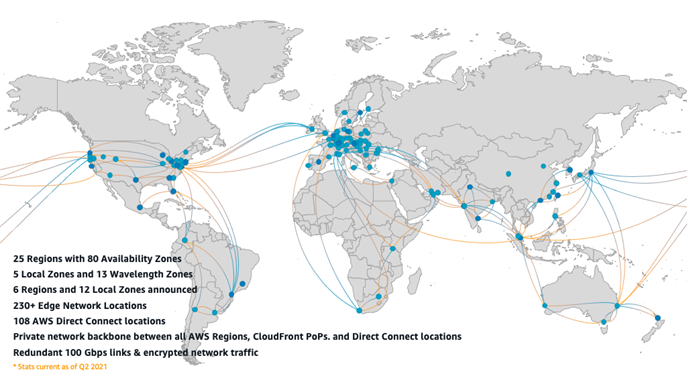
В результате мы можем сделать наше приложение по-настоящему геораспределённым. Причём внутренний трафик между узлами будет идти не по случайным ненадёжным публичным маршрутам, а по выделенным физическим линиям, предоставленным нам облаком.
В случае гибридной инфраструктуры мы можем подключить оптикой свою внутреннюю инфраструктуру в точке присутствия непосредственно к линиям облачного провайдера. В результате наши региональные узлы собственной инфраструктуры будут объединены с облачной частью теми же выделенными быстрыми линиями провайдера.
Что нужно знать, чтобы идти в облака
Итак, вы решили перейти в облако, чтобы получить все те блага с масштабируемостью, отказоустойчивостью и снижением эксплуатационной сложности. С чего стоит начать?
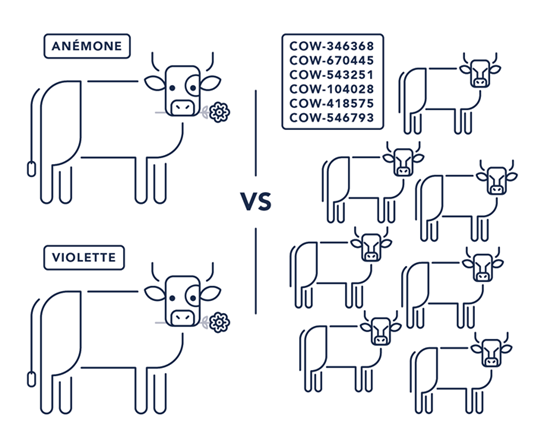
Начать стоит с изменения образа мышления. Появление облаков привело к ряду фундаментальных изменений в индустрии, которые нужно осознать. Самое заметное из них — переход от «серверов-питомцев» к «серверному стаду» (pets vs cattle). То есть если раньше мы имели конечное количество железных серверов, которым заботливо придумывали забавные названия, настраивали, обновляли, лечили от вирусов и восстанавливали после сбоев, то теперь можем заказать облачное «стадо», обработать входящую нагрузку, а потом просто удалить лишнее, чтобы сократить расходы. Но давайте обо всём по порядку.
В процессе своего развития индустрия прошла несколько этапов.
На заре индустрии это были ручная настройка узлов и документирование изменений.
Бородатые админы в свитерах подключались к серверам и что-то конфигурировали. Результат сохранялся во внутренней документации, которая стремительно устаревала и начинала противоречить реальному состоянию.
Императивный подход. Для настройки новых узлов начали использоваться скрипты, которые, будучи запущенными на новой машине, ставили там нужное ПО и обновляли конфигурацию. К сожалению, это не всегда хорошо работало. Например, в случае появления незапланированных изменений скрипт мог свалиться на каком-то промежуточном этапе, но это уже было достаточным прогрессом по сравнению с ручной работой.
Декларативный подход и парадигма синхронизации конфигурации. Постепенное развитие императивного подхода привело к появлению систем управления конфигурацией (SCM — software configuration management). В рамках этой парадигмы мы описывали желаемую конфигурацию наших серверов декларативно (хотим, чтобы было так), а система управления конфигурацией периодически ходила по нашим серверам и любыми знакомыми ей способами приводила состояние сервера к желаемому, синхронизировала его. К сожалению, этот подход имел ряд проблем. Прежде всего это configuration drift — когда не все изменения делались через SCM, а часть производилась в обход вручную. Это приводило к накоплению разницы между описанным и текущим состояниями системы. Эта разница порождала спираль страха автоматизации (automation fear spiral), когда мы боялись запускать систему SCM из страха, что она сломает какие-то неучтённые изменения. Всё это приводило к появлению серверов-снежинок — серверов, которые стали настолько неконсистентными, что уже никто не понимал, что внутри, и как это восстановить после сбоя или переставить.
Инфраструктура как код. Развитие систем управления конфигурации параллельно с развитием систем виртуализации дало нам возможность не просто применять конфигурацию к выделенным железным серверам, но заказывать и конфигурировать сами сервера. Применение конфигурации SCM к новому серверу могло занимать продолжительное время, и чтобы поднимать новые сервера быстрее, появилась концепция «базового имиджа» — образа операционной системы, в которой уже содержалось (было «запечено») некоторое количество нужных нам компонентов, а остальное «прожигалось» сверху системой управления конфигурацией при настройке на новой машине (см. дилемму baked vs fried).
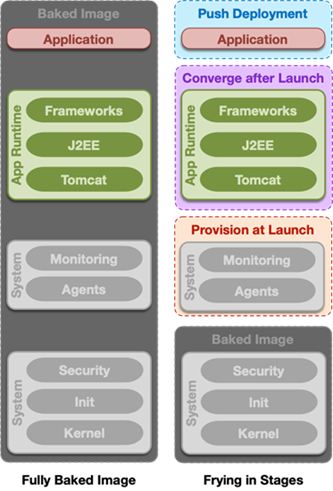
Соединив возможность быстрого пересоздания серверов на основе базовых имиджей с потребностью решения проблемы configuration drift, в индустрии была выработана концепция сервера Феникс (Phoenix server). Суть в том, чтобы пересоздавать сервер как можно чаще.
Допустим, мы регистрируем вход на сервер по ssh. В тот же день в технологическое окно сервер автоматически пересоздаётся с базового образа. Таким образом мы вынуждаем сотрудников эксплуатации делать все изменения в рамках SCM, а не вручную на серверах. Этот подход породил создание парадигмы Immutable infrastructure.
Immutable infratstructure
В рамках этой парадигмы мы делим инфраструктуру на две группы:
- Stateless. Инстансы этой части иммутабельны и идемпотентны. То есть они не накапливают состояния и не изменяют своей работы в зависимости от накопленного состояния. Они могут содержать в себе какие-то исполняемые файлы, скрипты, ассеты, статический контент, но требующую сохранения информацию (например, пользовательские сессии, пользовательский контент) они сохраняют в stateful-части.
- Stateful-часть мы можем реализовать по классической схеме с выделенными серверами либо можем использовать облачные сервисы (например, DBaaS), объектные или блочные хранилища.
Это позволяет обновлять наши приложения путём пересоздания stateless-инстансов с новых базовых имиджей и легко их масштабировать при помощи запуска новых экземпляров. Подробнее про правила разработки таких приложений вы можете прочитать в The twelve-factor app.
Резюме
Итак, что такое облако? Облако сейчас превратилось фактически в инфраструктурный фреймворк, в котором при помощи API мы можем получить инфраструктуру интегрированных сервисов, покрывающих потребности нашего бизнеса.
Как правильно использовать облака? Вы можете использовать их любым описанным выше способом: создавать и настраивать инстансы вручную, синхронизировать в них конфигурацию при помощи SCM, описывать инфраструктуру как код, но наибольшую эффективность, гибкость и масштабируемость вы получите, если будете разрабатывать приложения в парадигме immutable infrastructure, максимально используя существующие облачные сервисы.
romxx
Есть еще лучше фраза: "Даже свои собственные мощности не гарантируют доступности, если ты рукожоп".