
Балансировщики падают, контроллеры зависают, а дата-центры атакуют экскаваторы. Это нормальная история. Мы живём в мире, где нет ничего надёжного на 100 %, а любой бит в планке оперативной памяти может внезапно перещёлкнуться из-за пролетевшей космической частицы.
Другое дело, что даже в условиях постоянных рисков отказа отдельных элементов нам нужно обеспечить работоспособность инфраструктуры в целом. Клиент не должен заметить, что где-то отказал контейнер с php-fpm или одна из серверных стоек выпала из сети.
По роду деятельности мне постоянно приходится сталкиваться с проблемами отказоустойчивости, так как я руководитель разработки в отделе Газпромбанка, обеспечивающем эксплуатацию ML и Big Data-решений. Поэтому сегодня я хочу рассказать о нескольких паттернах отказоустойчивости и типовых решениях при эксплуатации приложения в кластере Kubernetes. Разберём основные паттерны, ну и, конечно, рассмотрим варианты, при которых неправильные настройки прострелят вначале одну ногу, а потом — другую, потому что она слишком медленно стала шагать.
Давайте для начала определимся с ключевой терминологией и определим, что же такое отказоустойчивость в контексте наших приложений и инфраструктуры.
Таким образом, отказоустойчивая архитектура — это способ построения отказоустойчивых систем, которые сохраняют работоспособность. Возможно эффективность системы при этом будет падать, но лучше плохо работать, чем хорошо лежать.
Отказоустойчивость на первом, аппаратном уровне(память с контролем четности, RAID), — это база: мы вводим избыточность в инфраструктуру и обкладываем её некоторым количеством алгоритмов, позволяющих выявить и обойти сбои. Но сегодня я хочу подняться немного выше.
Первый важный элемент, про который я буду сегодня говорить, — это Watchdog и Health check. Заранее прошу прощения, если вам покажется, что я смешиваю эти понятия в один логический блок, но в нашей сегодняшней теме это оправданно.
Итак, у нас есть пара равнозначных серверов, на которых крутятся сервисы. Клиент может подключиться к любому из них. В силу особенностей архитектуры Service #2 связан с Service #1 и служит для обеспечения его работы. Клиенту доступен только Service #1. Это достаточно распространённый вариант реализации.
Вдруг в процессе работы на одном из серверов сервису стало плохо. Мы получили ситуацию, когда примерно 50 % всех клиентских запросов завершается с ошибкой из-за неработоспособности одного из серверов.
Чтобы исправить проблемы, мы вводим в нашу инфраструктуру дополнительную сущность, которая называется Watchdog. Watchdog периодически опрашивает сервисы, убеждаясь в их работоспособности. Если он регистрирует какие-то проблемы, то делает управляющее воздействие на сервер (например, перезапускает сервис) и восстанавливает работоспособность узла.
Следующий паттерн — Health check. В нашу инфраструктуру добавляется «умный» Load Balancer. Он самостоятельно проверяет наши сервисы и, когда всё нормально, маршрутизирует на них запросы клиента. Когда случаются проблемы, Load Balancer это регистрирует и исключает из балансировки этот сервер.

Вы, наверное, уже догадались, о чём я говорю. Я говорю про Kubernetes probes. Таким образом, эта наша схема из примера превращается в следующее:

В архитектуре Kubernetes вышеназванные паттерны будут реализованы с помощью Kubernetes probes:
Чтобы правильно настроить probes, нужно обратить внимание на важную вещь, про которую многие забывают: probes работают независимо друг от друга. При неправильной настройке они могут ещё сильнее усугубить проблему вместо того, чтобы её решить.
Многие люди думают, что вначале последовательно происходит Liveness probe, потом проходит Readiness probe, далее pod становится Ready, и на него идёт трафик. На самом деле это неверно и приводит к неправильному выставлению параметров проверки. Каждый элемент проверки работает и принимает решения независимо от других.
Например, случаются такие ситуации, когда Readiness probe у нас прошла, и трафик пошёл на pod. Потом Liveness probe решила, что что-то не в порядке, и принудительно перезапустила контейнер. В итоге мы потеряли некоторое количество запросов, которые уже начали выполняться.

Сейчас эта ошибка встречается реже, так как появилась Startup probe, которая служит для проверки приложений, которые долго инициализируются. Она действительно откладывает выполнение Liveness и Readiness probe.

Для чего нужна Startup probe? Например, в контейнере у вас — Java с включённой JIT-компиляцией, при которой виртуальная машина Java получает программный код на вход и перемалывает его мелко в бинарный код, попутно оптимизируя. В итоге наш код начинает работать быстрее, чем без JIT-компиляции, но этот процесс часто занимает много времени. К тому же джависты любят включать в процедуру инициализации приложения применение Liquibase migrations (которые также могут долго применяться). Для эксплуатации приложений в Kubernetes это очень плохая, но, к сожалению, очень частая практика.
Liveness и Startup probe перезапускают контейнеры внутри пода, и с этим нужно быть как можно более осторожными. Допустим, на ваше приложение пришла высокая нагрузка, и их работа сильно замедлилась. Liveness-проба в этом случае может не получить корректного ответа и перезапустить приложение в тот момент, когда это особенно неуместно. Прибегайте к перезапуску контейнеров, только если действительно уверены в том, что делаете.
Readiness probe управляет трафиком, изменяет DNS-записи и endpoint для Kubernetes-сервисов. Она должна быть настроена всегда, когда есть такая возможность.
Для настройки проб у нас есть некоторое количество возможностей.
Прежде всего это exec-проверка — возможность запустить какую-то команду в контейнере. Например, прогнать SQL-запросы с командной строки, чтобы понять, что база данных, которая находится в SQL-контейнере, работает хорошо. С этим нужно быть осторожнее, потому что exec-проба часто порождает зомби-процессы. Если вы используете exec-пробу, то настройте мониторинг зомби.
Кроме этого, у нас есть grpc-, http-, tcp-пробы на любой вкус и цвет для того, чтобы покрыть все возможные случаи для вашего приложения.
Хорошая probe должна в первую очередь учитывать бизнес-функционал вашего приложения. Вместо построения сложных синтетических метрик нужно стараться максимально близко имитировать поведение реального пользователя и проверять работоспособность именно тех механизмов, которые принимают участие в обработке пользовательских запросов. В противном случае могут возникать ситуации, когда формальные проверки внутренних механизмов проходят, но функциональность приложения для пользователя оказывается сломана.
Например, если ваше приложение реализует API и панель администратора, то вам нужно проверять именно API-часть. При этом нужно быть осторожнее с внешними зависимостями, потому что, если внешний сервис откажет, вы можете получить каскадный сбой.
К тому же хорошие пробы должны учитывать особенности приложений, на которые они направлены. Допустим, в наших pod’ах работает классическая связка из Nginx+php-fpm.

Чтобы построить хорошую readiness-пробу, необязательно проверять оба этих контейнера по отдельности. Вместо этого лучше тестировать nginx location, который проксирует запросы в php-fpm. Таким образом, одной сквозной проверкой можно проверить оба контейнера и оптимизировать Readiness-пробу.
Для создания хорошей Liveness probe для php-fpm нужно учесть следующую особенность: в php-fpm мы настраиваем так называемые pool — группы процессов для обработки запросов. В настройках этих pool есть, в частности, опция максимального количества процессов для обработки запросов. Один процесс может обрабатывать один запрос в единицу времени.
Если все процессы внутри пула будут заняты высокой нагрузкой, то они могут не успеть ответить вовремя на запрос Liveness probe. Система сделает ровно то, что от неё ожидается: перезапустит pod. И это именно то, чего вы меньше всего хотели бы в ситуации перегруженных запросами узлов. В худшем случае мы получим положительную обратную связь, которая вызовет каскадную проблему: Liveness probe не вовремя перезагружает узел → нагрузка на оставшиеся узлы ещё сильнее возрастает → они не успевают вовремя ответить на запрос probe → их тоже принудительно перезагружают. Чтобы этого избежать, специально для проверки работоспособности php-fpm стоит выделить отдельный пул с ограниченными ресурсами, который и будет опрашивать наша Liveness probe.
Ещё раз — про ключевые моменты, о которых надо помнить:
Следующий механизм, который мы можем настроить для повышения отказоустойчивости, — это Retry и Timeouts. В реализации протокола grpc разработчики Google назвали их Deadlines. С тех пор эти названия часто встречаются вперемешку. Опять же прошу прощения, что их смешиваю, но в практической реализации они часто встречаются вместе. Давайте их разберём.
Допустим, один из контейнеров в процессе работы испытывает сложности. Клиент делает запрос и, к сожалению, попадает на pod с этим контейнером. В итоге обработка его запроса завершается с ошибкой. Какого рода могут быть проблемы?

Это могут быть ошибки протокола, например, 500 Internal Server Error и им подобные из группы 5**. Также это могут быть проблемы сетевого соединения или просто долгий ответ, когда pod подвис и не отвечает. Поскольку наше приложение, скорее всего, cloud native, написано с учётом методологии 12 factor app и имеет несколько работающих экземпляров, было бы неплохо, если бы клиент распознал ошибку, не стал ждать неразумное время в случае долгого ответа и повторил бы запрос. В этом случае велика вероятность, что он обработается успешно.

В этом заключаются паттерны Retry и Timeouts. В экосистеме Kubernetes мы можем реализовать это при помощи Ingress и Service mesh.
В случае с Ingress в нашу инфраструктуру добавляется так называемый ingress-контроллер.
Фактически это proxy, интегрированный с Kubernetes API, который становится на границе нашего кластера и принимает трафик от клиента. Существуют различные варианты Ingress от различных разработчиков, но мы поговорим об одном из наиболее популярных — Ingress Nginx.
Для настроек Retry/Timeouts в Ingress Nginx существуют следующие опции:
Retry
Timeout/Deadline
Для задания этих настроек в Ingress Nginx есть несколько возможностей:
Прежде всего нужно помнить, что nginx по умолчанию делает retry только идемпотентных запросов.
Согласно существующим соглашениям ваша реализация глаголов GET, HEAD, OPTIONS, TRACE, PUT, DELETE должна быть идемпотентной. То есть их реализация должна предусматривать возможность выполнить эти запросы на вашей инфраструктуре любое количество раз с одинаковыми результатами.
Глаголы POST, LOCK, PATCH считаются неидемпотентными, и, чтобы включить для них retry, нужно выставить параметр retry-non-idempotent в глобальный configmap контроллера.
Что такое неидемпотентный запрос? Допустим, у нас интернет-магазин, и мы создаём заказ через POST-запрос. Мы послали запрос в первый экземпляр приложения, но тот был слишком занят, и соединение отвалилось по тайм-ауту. Послали запрос во второй, но там — та же история. Третий запрос прошёл, и мы получили корректный ответ с подтверждением обработки запроса. Через какое-то время в БД мы находим три одинаковых заказа, так как на самом деле все три инстанса получили запрос и завели его в базу, но первые два просто не успели уложиться с ответом в Timeout. Это ещё добрый сценарий, который не грозит компании непосредственными финансовыми убытками. Куда хуже, если трижды пройдёт оплата на одну и ту же сумму или израсходуется какой-то ресурс.
Для преодоления этой проблемы существуют так называемые ключи идемпотентности, когда в каждый конкретный запрос встраивается уникальный хеш-идентификатор. То есть мы не говорим: «Заведи, пожалуйста, заказ». Мы говорим: «Заведи, пожалуйста, заказ с ID a5754d44adfv». Таким образом, мы можем выполнить его любое количество раз на нашей инфраструктуре с одинаковым результатом — созданием определённого заказа. К сожалению, эту логику можно реализовать только на стороне приложения. Поэтому, прежде чем разрешать Retry неидемпотентных запросов, сходите к разработчикам и уточните, что их реализация идемпотентна. И про реализацию обработки запросов с идемпотентными глаголами я бы тоже спросил: кто знает, кто какую реализацию мог сделать? Чуть подробнее — вот тут.
Следующий момент, который нужно учитывать, состоит в том, что Retry и Timeouts повышают нагрузку на вашу инфраструктуру. Поэтому нам нужно позаботиться о настройке разумных значений для этих параметров.
Proxy-next-upstream-timeout — это общее время, в течение которого мы можем делать Retry. Если, допустим, клиенты вашего сервиса не готовы ждать больше двух секунд на обработку своего запроса, то очевидно, что это значение не стоит выставлять больше.
Proxy-next-upstream-tries — это общее количество Retry. Допустим, у вас пять экземпляров вашего приложения. Соответственно общее число Retry не имеет смысла ставить больше, так как если уж никто не ответил, то не стоит ещё сильнее усугублять ситуацию.
При настройке тайм-аутов вам пригодится статистика. Хорошей практикой при настройке тайм-аутов считается выставление его значения в 99-й перцентиль соответствующей метрики. То есть нужно поднять статистику мониторинга за репрезентативный период, найти значение, которое попадает в 99 % показателей для соответствующих действий на вашем приложении, и выставить его в настройках. Оставшийся 1 % — это и будет тот порог, которым мы отсекаем случаи, когда что-то пошло не так. Здесь стоит помнить, что приложения находятся в постоянном развитии, и значения метрик, которые мы берём за основу расчёта тайм-аутов, также могут меняться.
Объяснения этого вопроса будут производиться на примере Istio — одного из самых популярных Service mesh. Часто наши клиенты находятся внутри кластера (допустим, у нас микросервисная архитектура), и у нас совершенно нет желания ставить Ingress и каким-то образом их через него публиковать. Для решения задач подобного рода служит Service mesh.

Мы можем поставить в кластер Service mesh, который делает примерно следующее. В Service mesh есть control plane, который собирает информацию со всего кластера о состоянии подов, сервисов и неймспейсов. Также он получает некоторое количество дополнительных настроек, специализированных для Service mesh.
Далее control plane агрегирует эти настройки и рассылает по так называемым Sidecar proxy-контейнерам, которые находятся в каждом pod'е. «Sidecar» в переводе означает коляску мотоцикла, что хорошо отражает вспомогательную функцию этой сущности. Sidecar proxy-контейнеры, как правило, попадают туда автоматически через Mutation webhook при создании pod`а.
Итак, Service mesh разложила config по нашим Sidecar proxy-контейнерам. Клиентское приложение хочет сделать запрос к сервису, но его по дороге перехватывает Sidecar proxy в его поде.

Далее Sidecar сам попытается доставить (проксировать) запрос сервиса.

Неудачная попытка доставки
Удачная попытка доставки
Retry и Timeout в Istio мы можем настроить в custom resource, который называется Virtual Service.
Пример конфигурации
Для начала обратите внимание, что Istio по умолчанию выполняет Retry для всех запросов. То есть если вы не хотите выполнять Retry для неидемпотентных запросов, то вам нужно написать для этого дополнительный фильтр.
Далее мы конфигурируем сами Retry:
attempts — максимальное количество попыток;
perTryTimeout — тайм-аут на попытку (в отличие от Ingress мы настраиваем Timeout именно на одну попытку-Retry, а не на общее время, в течение которого можно делать повторы);
retryOn — список ошибок, в случае которых запрос будет повторён (аналогично Ingress Nginx).
Кроме того, в Istio есть отдельные настройки Timeout. Их стоит использовать, когда Retry не настроены, потому что опция retryOn их переопределяет.
Circuit breaker-паттерн проектирования пришёл к нам из инженерии и работает аналогично аварийному автоматическому выключателю в вашем электрическом щитке. В процессе работы экземпляр приложения может испытывать проблемы, которые влияют на обработку запросов от клиентов. Это могут быть внутренние проблемы приложения, проблемы с внешними зависимостями, проблемы с сетью, просто высокая нагрузка или тяжёлый запрос. В этом случае разумно не добивать его новыми запросами или повторами запросов, но убрать с него нагрузку и дать время на восстановление. Возможно, за время без трафика приложение сможет справиться с пришедшей нагрузкой, инфраструктура восстановится или к инстансу придёт Watchdog и приведёт его в чувство.
Circuit breaker мы можем настроить в Istio при помощи custom resource DestinationRule:
Пример конфигурации
Здесь мы можем настроить:
Consecutive5xxErrors — общее количество ошибок, после которого исключаем pod из маршрутизации трафика, причём здесь считаются как ошибки протокола, так и тайм-ауты. Это могут быть тайм-ауты, настроенные как в VirtualService (как в примере выше), так и настроенные здесь же, в секции connectionPool;
interval — период, за который мы считаем ошибки. В данном конкретном случае после семи ошибок за последние 10 секунд pod исключается из маршрутизации трафика;
baseEjectionTime — время, на которое мы исключаем pod из маршрутизации;
maxEjectionPercent — это максимальное количество подов нашего сервиса, которые мы можем отключить от трафика;
minHealthPercent — это минимальное число здоровых ready pod, после которых Circuit breaker начинает работать.
При настройке Circuit breaker на Istio стоит помнить, что:

Как мы помним из определения, в отказоустойчивой инфраструктуре ухудшение качества сервиса для нас в некоторых случаях приемлемее, чем простой.
Как правило, если всё нормально, то мы рассчитываем производительность нашей инфраструктуры заранее, так как приблизительно представляем себе средние нагрузки. Исходя из этих расчётов закладываются серверные мощности, каналы связи и другие параметры. Тем не менее рано или поздно к вам постучится риск падения сервиса из-за перегрузки. Это могут быть внезапный habr-эффект, ошибка в реализации клиента, приведшая к флуду API-запросов, или просто несколько миллионов запросов от неизвестных ботов, которые решили поинтересоваться вашими уязвимостями.
Согласно паттерну Rate limit мы пропускаем к приложению ровно то количество запросов, которые система может обработать, а остальные отбрасываем. Это ведёт к ухудшению качества сервиса, но в данном случае оно оправданно.
В экосистеме Kubernetes есть несколько возможностей настройки Rate limits. Прежде всего мы можем их настроить на Ingress. Ingress-контроллер — это единая точка входа для клиентского трафика, и на нём это делать логичнее и проще всего. Но для обеспечения отказоустойчивости количество экземпляров Ingress у нас обычно больше одного.

Это нужно помнить при настройке лимитов.
Например, в Ingress Nginx есть два типа Rate limits: это локальные Rate limits и глобальные Rate limits.
Локальные Rate limits действуют в пределах одного экземпляра Ingress. Для того чтобы их выставить, мы можем через аннотации сделать специальные настройки.
Пример конфигурации
Прежде всего мы можем настроить сами лимиты:
nginx.ingress.kubernetes.io/limit-connections — лимит на соединение;
nginx.ingress.kubernetes.io/limit-rps — лимит на количество запросов в секунду;
nginx.ingress.kubernetes.io/limit-rpm — лимит на количество запросов в минуту.
Причём они срабатывают именно в таком порядке: connections → rpm → rps.
Часто наши Ingress-контроллеры, в свою очередь, находятся за load balancer. Это могут быть облачный IP load balancer (например, Amazon Elastic load balancer или haproxy в OpenStack) или HTTP-based load balancer.
Для того чтобы мы могли применять лимиты к клиентам, мы должны знать их адрес. Для этого в случае IP load balancer мы должны включить поддержку proxy protocol, то есть указать use-proxy-protocol: «true» в глобальной ConfigMap Ingress-контроллера. В случае с HTTP-based load balancer мы должны согласовать хедеры, в которых будем передавать адрес клиента. По умолчанию это X-Forwarded-For, но мы можем его переопределить при помощи настройки use-forwarded-headers.
Дополнительно мы можем настроить так называемые Burst-лимиты. Очень часто нагрузка от клиента неравномерная, например, большую часть времени он медленно тащит какой-то контент, и его это совершенно не задевает, к примеру, во время фоновой синхронизации данных приложения, пока телефон лежит в кармане. Но когда телефон оказался в руке и вам прилетает резкий всплеск запросов, клиент ожидает, что они будут обработаны немедленно и без задержек. Если мы просто отбросим запросы, выбивающиеся за лимит, то можем, во-первых, огорчить клиента, а во-вторых, недогрузить инфраструктуру.

Чтобы сгладить такие всплески, и служит Burst limit. В рамках Burst limit мы принимаем некоторое дополнительное разумное количество запросов в очередь и пытаемся их исполнить в пределах существующих Rate limit.
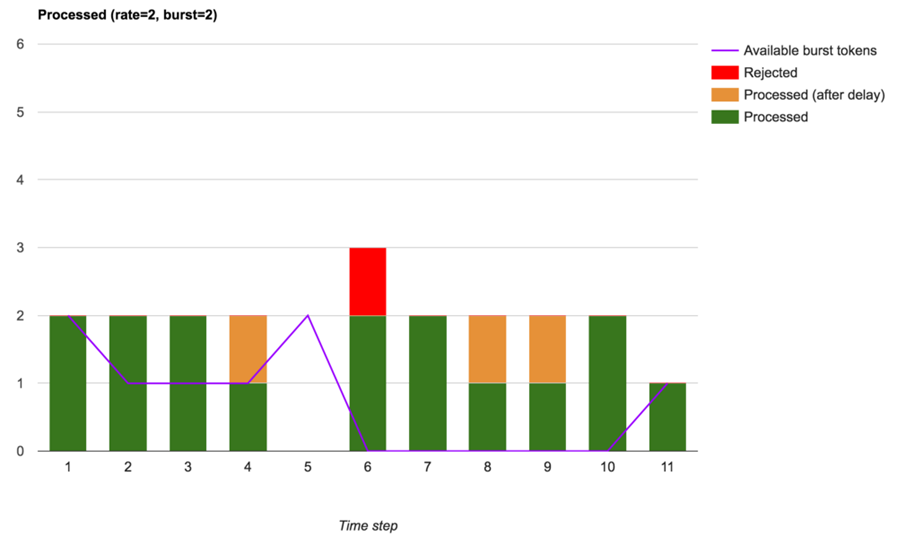
Да, такие запросы будут обрабатываться медленнее, но подобное ухудшение качества сервиса часто устраивает нас больше, чем просто отбрасывание запросов.
Limit burst в Ingress-Nginx можно настроить при помощи аннотации:
nginx.ingress.kubernetes.io/limit-burst-multiplier.
Также мы можем настроить ширину полосы пропускания для каждого отдельного соединения при помощи аннотаций:
nginx.ingress.kubernetes.io/limit-rate — количество килобайт в секунду, разрешённое для отправки в это соединение;
nginx.ingress.kubernetes.io/limit-rate-after — начальное количество килобайт, после которого дальнейшая передача ответа на данное соединение будет ограничена по скорости, но limit-rate и limit-rate-after работают, только если у нас включены и настроены proxy-буфера;
nginx.ingress.kubernetes.io/proxy-buffering: «on».
Кроме того, мы можем задать Whitelist, то есть лист IP-адресов, к которым никогда не будем применять Rate limit при помощи аннотации nginx.ingress.kubernetes.io/limit-whitelist.
И последний момент: при отказе в отработке запроса при истечении лимитов Nginx по умолчанию отдаёт ошибку 503 Service Unavailable. Это не совсем корректно. В спецификации HTTP протокола есть более подходящий код ответа: HTTP 429 Too Many Requests. Изменить код ответа можно при помощи настройки limit-req-status-code в глобальной configmap.
Настраивая локальные Rate limits, мы должны помнить, что с изменением количества экземпляров Ingress, через которые идёт трафик, мы меняем не только полосу пропускания, но изменяем и лимиты. Для того чтобы это преодолеть, у нас существуют Global Rate limits.
В Ingress Nginx они реализованы при помощи библиотеки lua-resty-global-throttle и сервиса memcached. Для того чтобы начать с ними работать, мы должны настроить memcached: указать его параметры в глобальном ConfigMap Ingress-контроллера и настроить аннотациями параметры глобальных лимитов.
Пример конфигурации
В этих параметрах мы можем настроить:
nginx.ingress.kubernetes.io/global-rate-limit — количество запросов;
nginx.ingress.kubernetes.io/global-rate-limit-window — временной период, за который готовы их принять.
Кроме того, мы можем настроить Whitelist при помощи nginx.ingress. kubernetes.io/global-rate-limit-ignored-cidrs.
Настраивая Rate limits на Service mesh, мы должны помнить, что proxy, которая принимает решение о наложении Rate limits, может находиться в любом pod`е: на сервере, на клиенте, везде, в любой щели.

Первая возможность для настройки Rate limits в Istio — это секция connection pool для DestinationRule.
Пример конфигурации
Разработчики Istio считают это частью Circuit breaker, но я думаю, что это не совсем корректно. В рамках лимитов на connection pool мы можем настроить лимиты на количество активных TCP-соединений, максимальное количество HTTP-запросов в обработке и максимальное количество запросов в ожидании — такой специфический аналог Burst limit. Это правило применяется на клиенте, и оно локальное внутри конкретного Sidecar proxy. То есть, настроив лимит в 100 соединений при двух клиентах, мы соответственно получаем 200 запросов на сервисе.
В Istio мы также можем настроить так называемые Envoy Rate limits. Они тоже бывают локальными и глобальными, и для их настройки используется custom resource EnvoyFilter. На мой взгляд, это функционал, который очень похож на Configuration Snippets в Ingress-контроллере. То есть разработчики Istio не стали заморачиваться с созданием каких-то абстракций для Rate limits, а отдали нам конфиг Envoy и сказали: «Вот, пожалуйста». Документацию по этим Rate limits, наверное, лучше искать в документации Envoy.
При настройке локальных Rate limits в Istio мы должны помнить, что лимиты мы можем применять к TCP и HTTP, на источнике и на назначении трафика, для входящего и исходящего трафиков. Например:
Пример конфигурации
Здесь мы видим, что custom resource EnvoyFilter состоит из двух частей. Первая описывает, куда применяется патч конфигурации envoy, вторая — сам патч. В первой части примера мы видим, что патч применяется к HTTP-протоколу (applyTo: HTTP_FILTER) к входящим (context: SIDECAR_INBOUND) для подов приложения, имеющим метку, описанную в workloadSelector.
В патче мы видим непосредственно описание Rate limits. Они сделаны по принципу token bucket. То есть у нас есть bucket, у которого есть заданная ёмкость токенов (max_tokens — это могут быть http-запросы в обработке либо tcp-соединения) и правила его заполнения: tokens_per_fill — количество новых токенов; fill_interval — временной промежуток, в который мы можем принять описанное количество токенов. Но если bucket у нас заполнен, то мы не можем принять ничего.
Для того чтобы начать с ними работать, мы должны установить специальный сервис для работы с Rate limits, куда Envoy будут ходить по gRPC. Чаще всего это должен быть Redis, который хранит информацию по соединениям.
Здесь мы можем настроить domain, к которому будем применять лимиты, и сами лимиты: временной промежуток unit и requests_per_unit — количество запросов, которые мы готовы в него принять (что-то достаточно близкое к глобальным лимитам Ingress Nginx).
Применяются глобальные лимиты также при помощи custom resource EnvoyFilter:
Здесь в секции patch мы можем видеть описание domain, для которого мы хотим ввести лимиты и описание grpc service, в котором они хранятся.
При настройке глобальных Rate limits стоит понимать, что это распределённые Rate limits, и они небесплатные с точки зрения нагрузки. Запрос в Redis занимает время и увеличивает время на обработку трафика нашими прокси. Это тяжёлый механизм, поэтому разработчики, что Ingress, что Istio, рекомендуют использовать локальные и глобальные Rate limits вместе, чтобы оптимизировать использование ресурсов.
Тема отказоустойчивости обширна до бесконечности. Описанные выше паттерны универсальны и могут быть реализованы на нескольких уровнях – от аппаратного обеспечения до кода приложений.
Мы рассказали про применение в этих целях платформы Kubernetes и ее экосистемы. Это удобный инструмент, а нужен он или нет — каждый должен решить для себя сам. Всё зависит от индивидуальных требований к отказоустойчивости и уровня качества сервиса.
Ключевыми элементами при формировании нужных лимитов и тайм-аутов должны быть понятно описанная схема вашей конкретной инфраструктуры и накопленная статистика мониторинга. Только в этом случае вы сможете подобрать параметры, оптимальные именно для вашей ситуации.
Другое дело, что даже в условиях постоянных рисков отказа отдельных элементов нам нужно обеспечить работоспособность инфраструктуры в целом. Клиент не должен заметить, что где-то отказал контейнер с php-fpm или одна из серверных стоек выпала из сети.
По роду деятельности мне постоянно приходится сталкиваться с проблемами отказоустойчивости, так как я руководитель разработки в отделе Газпромбанка, обеспечивающем эксплуатацию ML и Big Data-решений. Поэтому сегодня я хочу рассказать о нескольких паттернах отказоустойчивости и типовых решениях при эксплуатации приложения в кластере Kubernetes. Разберём основные паттерны, ну и, конечно, рассмотрим варианты, при которых неправильные настройки прострелят вначале одну ногу, а потом — другую, потому что она слишком медленно стала шагать.
Что такое отказоустойчивость
Давайте для начала определимся с ключевой терминологией и определим, что же такое отказоустойчивость в контексте наших приложений и инфраструктуры.
- Отказоустойчивость — способность системы сохранять свою работоспособность после отказа одной или нескольких её составных частей.
- Отказоустойчивая архитектура — способ построения отказоустойчивых систем, которые сохраняют работоспособность (возможно, с понижением эффективности) при отказах элементов.
Таким образом, отказоустойчивая архитектура — это способ построения отказоустойчивых систем, которые сохраняют работоспособность. Возможно эффективность системы при этом будет падать, но лучше плохо работать, чем хорошо лежать.
Watchdog и Health check
Архитектура
Отказоустойчивость на первом, аппаратном уровне(память с контролем четности, RAID), — это база: мы вводим избыточность в инфраструктуру и обкладываем её некоторым количеством алгоритмов, позволяющих выявить и обойти сбои. Но сегодня я хочу подняться немного выше.
Первый важный элемент, про который я буду сегодня говорить, — это Watchdog и Health check. Заранее прошу прощения, если вам покажется, что я смешиваю эти понятия в один логический блок, но в нашей сегодняшней теме это оправданно.
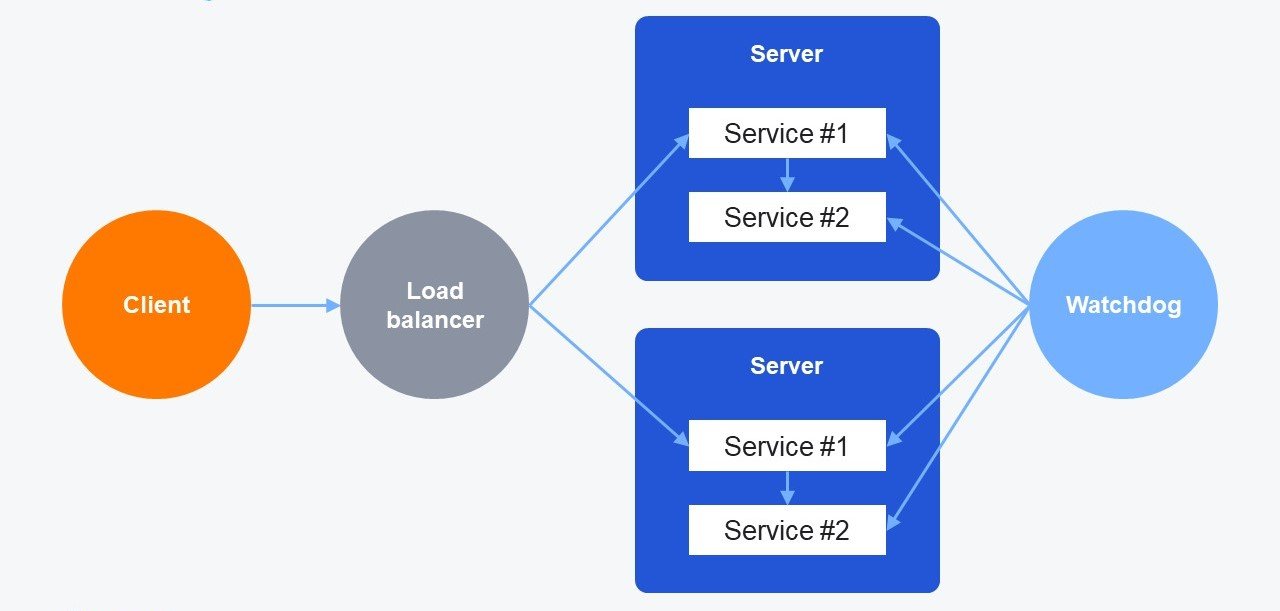
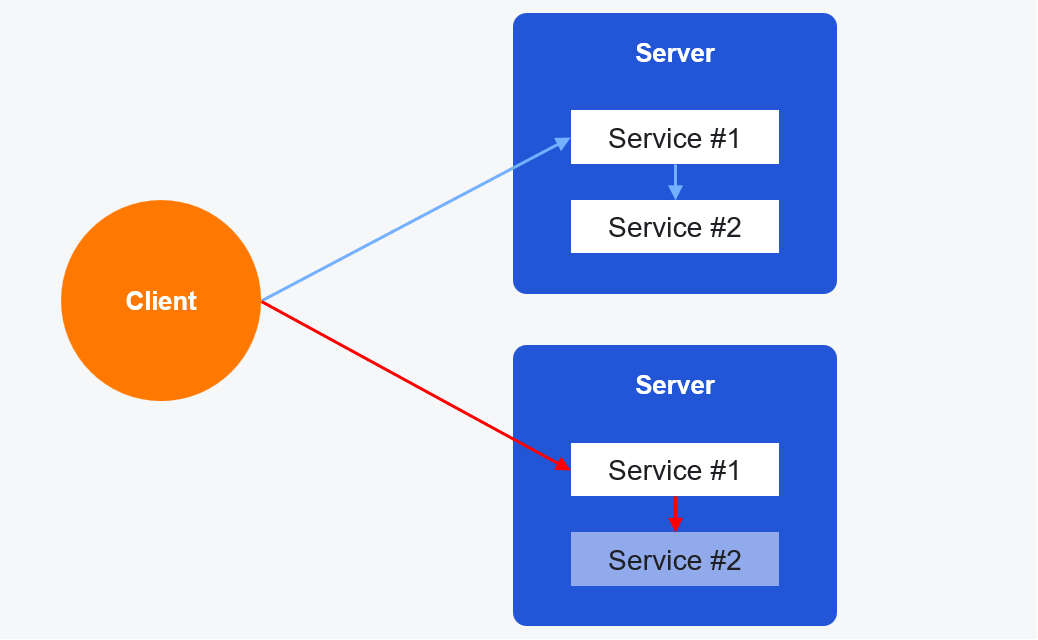
Итак, у нас есть пара равнозначных серверов, на которых крутятся сервисы. Клиент может подключиться к любому из них. В силу особенностей архитектуры Service #2 связан с Service #1 и служит для обеспечения его работы. Клиенту доступен только Service #1. Это достаточно распространённый вариант реализации.
Вдруг в процессе работы на одном из серверов сервису стало плохо. Мы получили ситуацию, когда примерно 50 % всех клиентских запросов завершается с ошибкой из-за неработоспособности одного из серверов.
Чтобы исправить проблемы, мы вводим в нашу инфраструктуру дополнительную сущность, которая называется Watchdog. Watchdog периодически опрашивает сервисы, убеждаясь в их работоспособности. Если он регистрирует какие-то проблемы, то делает управляющее воздействие на сервер (например, перезапускает сервис) и восстанавливает работоспособность узла.
Следующий паттерн — Health check. В нашу инфраструктуру добавляется «умный» Load Balancer. Он самостоятельно проверяет наши сервисы и, когда всё нормально, маршрутизирует на них запросы клиента. Когда случаются проблемы, Load Balancer это регистрирует и исключает из балансировки этот сервер.
Вы, наверное, уже догадались, о чём я говорю. Я говорю про Kubernetes probes. Таким образом, эта наша схема из примера превращается в следующее:
В архитектуре Kubernetes вышеназванные паттерны будут реализованы с помощью Kubernetes probes:
- Watchdog — это Liveness probe.
- Health check — это Readiness probe.
- Сервер — это pod.
- Сервис — это контейнер с приложением, запущенный в этом pod`е.
Нюансы конфигурации Kubernetes probes
Чтобы правильно настроить probes, нужно обратить внимание на важную вещь, про которую многие забывают: probes работают независимо друг от друга. При неправильной настройке они могут ещё сильнее усугубить проблему вместо того, чтобы её решить.
Многие люди думают, что вначале последовательно происходит Liveness probe, потом проходит Readiness probe, далее pod становится Ready, и на него идёт трафик. На самом деле это неверно и приводит к неправильному выставлению параметров проверки. Каждый элемент проверки работает и принимает решения независимо от других.
Например, случаются такие ситуации, когда Readiness probe у нас прошла, и трафик пошёл на pod. Потом Liveness probe решила, что что-то не в порядке, и принудительно перезапустила контейнер. В итоге мы потеряли некоторое количество запросов, которые уже начали выполняться.
Сейчас эта ошибка встречается реже, так как появилась Startup probe, которая служит для проверки приложений, которые долго инициализируются. Она действительно откладывает выполнение Liveness и Readiness probe.
Для чего нужна Startup probe? Например, в контейнере у вас — Java с включённой JIT-компиляцией, при которой виртуальная машина Java получает программный код на вход и перемалывает его мелко в бинарный код, попутно оптимизируя. В итоге наш код начинает работать быстрее, чем без JIT-компиляции, но этот процесс часто занимает много времени. К тому же джависты любят включать в процедуру инициализации приложения применение Liquibase migrations (которые также могут долго применяться). Для эксплуатации приложений в Kubernetes это очень плохая, но, к сожалению, очень частая практика.
Liveness и Startup probe перезапускают контейнеры внутри пода, и с этим нужно быть как можно более осторожными. Допустим, на ваше приложение пришла высокая нагрузка, и их работа сильно замедлилась. Liveness-проба в этом случае может не получить корректного ответа и перезапустить приложение в тот момент, когда это особенно неуместно. Прибегайте к перезапуску контейнеров, только если действительно уверены в том, что делаете.
Readiness probe управляет трафиком, изменяет DNS-записи и endpoint для Kubernetes-сервисов. Она должна быть настроена всегда, когда есть такая возможность.
Для настройки проб у нас есть некоторое количество возможностей.
Прежде всего это exec-проверка — возможность запустить какую-то команду в контейнере. Например, прогнать SQL-запросы с командной строки, чтобы понять, что база данных, которая находится в SQL-контейнере, работает хорошо. С этим нужно быть осторожнее, потому что exec-проба часто порождает зомби-процессы. Если вы используете exec-пробу, то настройте мониторинг зомби.
Кроме этого, у нас есть grpc-, http-, tcp-пробы на любой вкус и цвет для того, чтобы покрыть все возможные случаи для вашего приложения.
Хорошая probe должна в первую очередь учитывать бизнес-функционал вашего приложения. Вместо построения сложных синтетических метрик нужно стараться максимально близко имитировать поведение реального пользователя и проверять работоспособность именно тех механизмов, которые принимают участие в обработке пользовательских запросов. В противном случае могут возникать ситуации, когда формальные проверки внутренних механизмов проходят, но функциональность приложения для пользователя оказывается сломана.
Например, если ваше приложение реализует API и панель администратора, то вам нужно проверять именно API-часть. При этом нужно быть осторожнее с внешними зависимостями, потому что, если внешний сервис откажет, вы можете получить каскадный сбой.
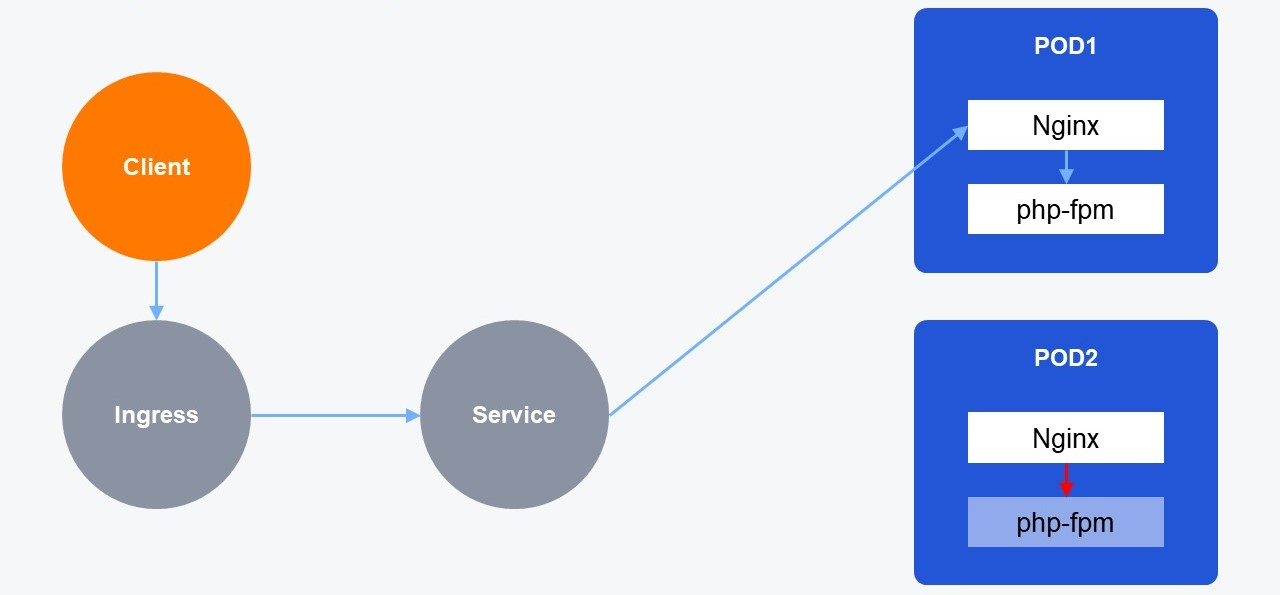
К тому же хорошие пробы должны учитывать особенности приложений, на которые они направлены. Допустим, в наших pod’ах работает классическая связка из Nginx+php-fpm.
Чтобы построить хорошую readiness-пробу, необязательно проверять оба этих контейнера по отдельности. Вместо этого лучше тестировать nginx location, который проксирует запросы в php-fpm. Таким образом, одной сквозной проверкой можно проверить оба контейнера и оптимизировать Readiness-пробу.
Для создания хорошей Liveness probe для php-fpm нужно учесть следующую особенность: в php-fpm мы настраиваем так называемые pool — группы процессов для обработки запросов. В настройках этих pool есть, в частности, опция максимального количества процессов для обработки запросов. Один процесс может обрабатывать один запрос в единицу времени.
[site]
user = www
group = www
listen = 127.0.0.1:9001
pm = dynamic
pm.max_children = 20
pm.start_servers = 10
pm.min_spare_servers = 5
pm.max_spare_servers = 10
pm.process_idle_timeout = 10s
[healthcheck]
user = www
group = www
listen = 127.0.0.1:9002
pm = static
pm.max_children = 1Если все процессы внутри пула будут заняты высокой нагрузкой, то они могут не успеть ответить вовремя на запрос Liveness probe. Система сделает ровно то, что от неё ожидается: перезапустит pod. И это именно то, чего вы меньше всего хотели бы в ситуации перегруженных запросами узлов. В худшем случае мы получим положительную обратную связь, которая вызовет каскадную проблему: Liveness probe не вовремя перезагружает узел → нагрузка на оставшиеся узлы ещё сильнее возрастает → они не успевают вовремя ответить на запрос probe → их тоже принудительно перезагружают. Чтобы этого избежать, специально для проверки работоспособности php-fpm стоит выделить отдельный пул с ограниченными ресурсами, который и будет опрашивать наша Liveness probe.
Ещё раз — про ключевые моменты, о которых надо помнить:
- Startup probe — перезагружает контейнер.
- Liveness probe — перезагружает контейнер.
- Readiness probe — управляет service.
- Все probe работают независимо и могут приводить к деградации сервиса.
Retry / Timeouts
Следующий механизм, который мы можем настроить для повышения отказоустойчивости, — это Retry и Timeouts. В реализации протокола grpc разработчики Google назвали их Deadlines. С тех пор эти названия часто встречаются вперемешку. Опять же прошу прощения, что их смешиваю, но в практической реализации они часто встречаются вместе. Давайте их разберём.
Допустим, один из контейнеров в процессе работы испытывает сложности. Клиент делает запрос и, к сожалению, попадает на pod с этим контейнером. В итоге обработка его запроса завершается с ошибкой. Какого рода могут быть проблемы?
Это могут быть ошибки протокола, например, 500 Internal Server Error и им подобные из группы 5**. Также это могут быть проблемы сетевого соединения или просто долгий ответ, когда pod подвис и не отвечает. Поскольку наше приложение, скорее всего, cloud native, написано с учётом методологии 12 factor app и имеет несколько работающих экземпляров, было бы неплохо, если бы клиент распознал ошибку, не стал ждать неразумное время в случае долгого ответа и повторил бы запрос. В этом случае велика вероятность, что он обработается успешно.
В этом заключаются паттерны Retry и Timeouts. В экосистеме Kubernetes мы можем реализовать это при помощи Ingress и Service mesh.
Retry/timeouts на Ingress
В случае с Ingress в нашу инфраструктуру добавляется так называемый ingress-контроллер.
Фактически это proxy, интегрированный с Kubernetes API, который становится на границе нашего кластера и принимает трафик от клиента. Существуют различные варианты Ingress от различных разработчиков, но мы поговорим об одном из наиболее популярных — Ingress Nginx.
Для настроек Retry/Timeouts в Ingress Nginx существуют следующие опции:
Retry
- proxy-next-upstream — список ошибок, в случае которых запрос будет повторён (error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | non_idempotent | off...;);
- proxy-next-upstream-timeout — общее время, в течение которого мы можем делать повторы запроса;
- proxy-next-upstream-tries — число Retry, которое мы можем сделать.
Timeout/Deadline
- proxy-connect-timeout — максимальное время ожидания коннекта;
- proxy-read-timeout — максимальное время ожидания чтения;
- proxy-send-timeout — максимальное время ожидания записи.
Для задания этих настроек в Ingress Nginx есть несколько возможностей:
- Глобальный configmap контроллера.
apiVersion: v1 kind: ConfigMap metadata: name: ingress-nginx-controller namespace: ingress-nginx data: proxy-next-upstream: "error timeout http_500" proxy-next-upstream-timeout: "10" proxy-next-upstream-tries: "5" proxy-connect-timeout: "1" proxy-read-timeout: "5" proxy-send-timeout: "2" - Аннотациями на конкретном ingress-ресурсе.
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: nginx-configuration-snippet annotations: nginx.ingress.kubernetes.io/proxy-next-upstream: "error timeout http_500" nginx.ingress.kubernetes.io/proxy-next-upstream-timeout: "10" nginx.ingress.kubernetes.io/proxy-next-upstream-tries: "5" nginx.ingress.kubernetes.io/proxy-connect-timeout: "1" nginx.ingress.kubernetes.io/proxy-send-timeout: "5" nginx.ingress.kubernetes.io/proxy-read-timeout: "2" spec: ingressClassName: nginx rules: - host: custom.configuration.com http: paths: - path: / pathType: Prefix backend: service: name: http-svc port: 8080 - Поскольку эти параметры — абстракция над конфигурацией nginx, который контроллер использует в качестве ядра, мы можем добавить соответствующие параметры непосредственно в конфиг nginx посредством функционала configuration snippet, но это достаточно низкоуровневая возможность, и я бы не советовал ею злоупотреблять для сохранения стабильности контроллера.
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: nginx-configuration-snippet annotations: nginx.ingress.kubernetes.io/configuration-snippet: | proxy_next_upstream: "error timeout http_500" proxy_next_upstream_timeout: "10" proxy_next_upstream_tries: "5" proxy_connect_timeout: "1" proxy_read_timeout: "5" proxy_send_timeout: "2" spec: ingressClassName: nginx rules: - host: custom.configuration.com http: paths: - path: / pathType: Prefix backend: service: name: http-svc port: 8080
Нюансы настройки Retry/Timeouts на Ingress-Nginx
Прежде всего нужно помнить, что nginx по умолчанию делает retry только идемпотентных запросов.
Согласно существующим соглашениям ваша реализация глаголов GET, HEAD, OPTIONS, TRACE, PUT, DELETE должна быть идемпотентной. То есть их реализация должна предусматривать возможность выполнить эти запросы на вашей инфраструктуре любое количество раз с одинаковыми результатами.
Глаголы POST, LOCK, PATCH считаются неидемпотентными, и, чтобы включить для них retry, нужно выставить параметр retry-non-idempotent в глобальный configmap контроллера.
Что такое неидемпотентный запрос? Допустим, у нас интернет-магазин, и мы создаём заказ через POST-запрос. Мы послали запрос в первый экземпляр приложения, но тот был слишком занят, и соединение отвалилось по тайм-ауту. Послали запрос во второй, но там — та же история. Третий запрос прошёл, и мы получили корректный ответ с подтверждением обработки запроса. Через какое-то время в БД мы находим три одинаковых заказа, так как на самом деле все три инстанса получили запрос и завели его в базу, но первые два просто не успели уложиться с ответом в Timeout. Это ещё добрый сценарий, который не грозит компании непосредственными финансовыми убытками. Куда хуже, если трижды пройдёт оплата на одну и ту же сумму или израсходуется какой-то ресурс.
Для преодоления этой проблемы существуют так называемые ключи идемпотентности, когда в каждый конкретный запрос встраивается уникальный хеш-идентификатор. То есть мы не говорим: «Заведи, пожалуйста, заказ». Мы говорим: «Заведи, пожалуйста, заказ с ID a5754d44adfv». Таким образом, мы можем выполнить его любое количество раз на нашей инфраструктуре с одинаковым результатом — созданием определённого заказа. К сожалению, эту логику можно реализовать только на стороне приложения. Поэтому, прежде чем разрешать Retry неидемпотентных запросов, сходите к разработчикам и уточните, что их реализация идемпотентна. И про реализацию обработки запросов с идемпотентными глаголами я бы тоже спросил: кто знает, кто какую реализацию мог сделать? Чуть подробнее — вот тут.
Следующий момент, который нужно учитывать, состоит в том, что Retry и Timeouts повышают нагрузку на вашу инфраструктуру. Поэтому нам нужно позаботиться о настройке разумных значений для этих параметров.
Proxy-next-upstream-timeout — это общее время, в течение которого мы можем делать Retry. Если, допустим, клиенты вашего сервиса не готовы ждать больше двух секунд на обработку своего запроса, то очевидно, что это значение не стоит выставлять больше.
Proxy-next-upstream-tries — это общее количество Retry. Допустим, у вас пять экземпляров вашего приложения. Соответственно общее число Retry не имеет смысла ставить больше, так как если уж никто не ответил, то не стоит ещё сильнее усугублять ситуацию.
При настройке тайм-аутов вам пригодится статистика. Хорошей практикой при настройке тайм-аутов считается выставление его значения в 99-й перцентиль соответствующей метрики. То есть нужно поднять статистику мониторинга за репрезентативный период, найти значение, которое попадает в 99 % показателей для соответствующих действий на вашем приложении, и выставить его в настройках. Оставшийся 1 % — это и будет тот порог, которым мы отсекаем случаи, когда что-то пошло не так. Здесь стоит помнить, что приложения находятся в постоянном развитии, и значения метрик, которые мы берём за основу расчёта тайм-аутов, также могут меняться.
Retry/Timeouts на Service mesh
Объяснения этого вопроса будут производиться на примере Istio — одного из самых популярных Service mesh. Часто наши клиенты находятся внутри кластера (допустим, у нас микросервисная архитектура), и у нас совершенно нет желания ставить Ingress и каким-то образом их через него публиковать. Для решения задач подобного рода служит Service mesh.
Мы можем поставить в кластер Service mesh, который делает примерно следующее. В Service mesh есть control plane, который собирает информацию со всего кластера о состоянии подов, сервисов и неймспейсов. Также он получает некоторое количество дополнительных настроек, специализированных для Service mesh.
Далее control plane агрегирует эти настройки и рассылает по так называемым Sidecar proxy-контейнерам, которые находятся в каждом pod'е. «Sidecar» в переводе означает коляску мотоцикла, что хорошо отражает вспомогательную функцию этой сущности. Sidecar proxy-контейнеры, как правило, попадают туда автоматически через Mutation webhook при создании pod`а.
Итак, Service mesh разложила config по нашим Sidecar proxy-контейнерам. Клиентское приложение хочет сделать запрос к сервису, но его по дороге перехватывает Sidecar proxy в его поде.
Далее Sidecar сам попытается доставить (проксировать) запрос сервиса.
Неудачная попытка доставки
Удачная попытка доставки
Нюансы конфигурации Retry/Timeouts в Istio
Retry и Timeout в Istio мы можем настроить в custom resource, который называется Virtual Service.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: microservice-route
spec:
hosts:
- "*"
http:
- match:
- method:
regex: "GET|HEAD|TRACE"
route:
- destination:
host: microservice.prod.svc.cluster.local
retries:
attempts: 3
perTryTimeout: 2s
retryOn: connect-failure,refused-stream,gateway-error,503
timeout: 5sПример конфигурации
Для начала обратите внимание, что Istio по умолчанию выполняет Retry для всех запросов. То есть если вы не хотите выполнять Retry для неидемпотентных запросов, то вам нужно написать для этого дополнительный фильтр.
Далее мы конфигурируем сами Retry:
attempts — максимальное количество попыток;
perTryTimeout — тайм-аут на попытку (в отличие от Ingress мы настраиваем Timeout именно на одну попытку-Retry, а не на общее время, в течение которого можно делать повторы);
retryOn — список ошибок, в случае которых запрос будет повторён (аналогично Ingress Nginx).
Кроме того, в Istio есть отдельные настройки Timeout. Их стоит использовать, когда Retry не настроены, потому что опция retryOn их переопределяет.
Circuit breaker
Circuit breaker-паттерн проектирования пришёл к нам из инженерии и работает аналогично аварийному автоматическому выключателю в вашем электрическом щитке. В процессе работы экземпляр приложения может испытывать проблемы, которые влияют на обработку запросов от клиентов. Это могут быть внутренние проблемы приложения, проблемы с внешними зависимостями, проблемы с сетью, просто высокая нагрузка или тяжёлый запрос. В этом случае разумно не добивать его новыми запросами или повторами запросов, но убрать с него нагрузку и дать время на восстановление. Возможно, за время без трафика приложение сможет справиться с пришедшей нагрузкой, инфраструктура восстановится или к инстансу придёт Watchdog и приведёт его в чувство.
Circuit breaker мы можем настроить в Istio при помощи custom resource DestinationRule:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: microservice-destinationrule
spec:
host: microservice.prod.svc.cluster.local
trafficPolicy:
connectionPool:
tcp:
connectTimeout: 100ms
outlierDetection:
consecutive5xxErrors: 7
interval: 10s
baseEjectionTime: 3m
maxEjectionPercent: 100
minHealthPercent: 50Пример конфигурации
Здесь мы можем настроить:
Consecutive5xxErrors — общее количество ошибок, после которого исключаем pod из маршрутизации трафика, причём здесь считаются как ошибки протокола, так и тайм-ауты. Это могут быть тайм-ауты, настроенные как в VirtualService (как в примере выше), так и настроенные здесь же, в секции connectionPool;
interval — период, за который мы считаем ошибки. В данном конкретном случае после семи ошибок за последние 10 секунд pod исключается из маршрутизации трафика;
baseEjectionTime — время, на которое мы исключаем pod из маршрутизации;
maxEjectionPercent — это максимальное количество подов нашего сервиса, которые мы можем отключить от трафика;
minHealthPercent — это минимальное число здоровых ready pod, после которых Circuit breaker начинает работать.
При настройке Circuit breaker на Istio стоит помнить, что:
- Circuit breaker предполагает только пассивные проверки. То есть, чтобы убедиться, что pod рабочий, Istio опять пускает на него трафик и следит, не появятся ли ошибки.
- outlierDetection срабатывает на клиенте, и счётчик ошибок действует в пределе одного конкретного Sidecar proxy-контейнера. То есть если у вас несколько pod’ов клиентов, то Circuit breaker может для них включаться по-разному.
Rate limits
Как мы помним из определения, в отказоустойчивой инфраструктуре ухудшение качества сервиса для нас в некоторых случаях приемлемее, чем простой.
Как правило, если всё нормально, то мы рассчитываем производительность нашей инфраструктуры заранее, так как приблизительно представляем себе средние нагрузки. Исходя из этих расчётов закладываются серверные мощности, каналы связи и другие параметры. Тем не менее рано или поздно к вам постучится риск падения сервиса из-за перегрузки. Это могут быть внезапный habr-эффект, ошибка в реализации клиента, приведшая к флуду API-запросов, или просто несколько миллионов запросов от неизвестных ботов, которые решили поинтересоваться вашими уязвимостями.
Согласно паттерну Rate limit мы пропускаем к приложению ровно то количество запросов, которые система может обработать, а остальные отбрасываем. Это ведёт к ухудшению качества сервиса, но в данном случае оно оправданно.
Rate limits на Ingress
В экосистеме Kubernetes есть несколько возможностей настройки Rate limits. Прежде всего мы можем их настроить на Ingress. Ingress-контроллер — это единая точка входа для клиентского трафика, и на нём это делать логичнее и проще всего. Но для обеспечения отказоустойчивости количество экземпляров Ingress у нас обычно больше одного.
Это нужно помнить при настройке лимитов.
Например, в Ingress Nginx есть два типа Rate limits: это локальные Rate limits и глобальные Rate limits.
Локальные Rate limits
Локальные Rate limits действуют в пределах одного экземпляра Ingress. Для того чтобы их выставить, мы можем через аннотации сделать специальные настройки.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-configuration-example
annotations:
nginx.ingress.kubernetes.io/limit-connections: 100
nginx.ingress.kubernetes.io/limit-rpm: 200
nginx.ingress.kubernetes.io/limit-rps: 10
nginx.ingress.kubernetes.io/limit-burst-multiplier: 2
nginx.ingress.kubernetes.io/proxy-buffering: "on"
nginx.ingress.kubernetes.io/limit-whitelist: 8.8.8.8
spec:
ingressClassName: nginx
rules:
- host: custom.configuration.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: http-svc
port: 8080Пример конфигурации
Прежде всего мы можем настроить сами лимиты:
nginx.ingress.kubernetes.io/limit-connections — лимит на соединение;
nginx.ingress.kubernetes.io/limit-rps — лимит на количество запросов в секунду;
nginx.ingress.kubernetes.io/limit-rpm — лимит на количество запросов в минуту.
Причём они срабатывают именно в таком порядке: connections → rpm → rps.
Часто наши Ingress-контроллеры, в свою очередь, находятся за load balancer. Это могут быть облачный IP load balancer (например, Amazon Elastic load balancer или haproxy в OpenStack) или HTTP-based load balancer.
Для того чтобы мы могли применять лимиты к клиентам, мы должны знать их адрес. Для этого в случае IP load balancer мы должны включить поддержку proxy protocol, то есть указать use-proxy-protocol: «true» в глобальной ConfigMap Ingress-контроллера. В случае с HTTP-based load balancer мы должны согласовать хедеры, в которых будем передавать адрес клиента. По умолчанию это X-Forwarded-For, но мы можем его переопределить при помощи настройки use-forwarded-headers.
Дополнительно мы можем настроить так называемые Burst-лимиты. Очень часто нагрузка от клиента неравномерная, например, большую часть времени он медленно тащит какой-то контент, и его это совершенно не задевает, к примеру, во время фоновой синхронизации данных приложения, пока телефон лежит в кармане. Но когда телефон оказался в руке и вам прилетает резкий всплеск запросов, клиент ожидает, что они будут обработаны немедленно и без задержек. Если мы просто отбросим запросы, выбивающиеся за лимит, то можем, во-первых, огорчить клиента, а во-вторых, недогрузить инфраструктуру.
Чтобы сгладить такие всплески, и служит Burst limit. В рамках Burst limit мы принимаем некоторое дополнительное разумное количество запросов в очередь и пытаемся их исполнить в пределах существующих Rate limit.
Да, такие запросы будут обрабатываться медленнее, но подобное ухудшение качества сервиса часто устраивает нас больше, чем просто отбрасывание запросов.
Limit burst в Ingress-Nginx можно настроить при помощи аннотации:
nginx.ingress.kubernetes.io/limit-burst-multiplier.
Также мы можем настроить ширину полосы пропускания для каждого отдельного соединения при помощи аннотаций:
nginx.ingress.kubernetes.io/limit-rate — количество килобайт в секунду, разрешённое для отправки в это соединение;
nginx.ingress.kubernetes.io/limit-rate-after — начальное количество килобайт, после которого дальнейшая передача ответа на данное соединение будет ограничена по скорости, но limit-rate и limit-rate-after работают, только если у нас включены и настроены proxy-буфера;
nginx.ingress.kubernetes.io/proxy-buffering: «on».
Кроме того, мы можем задать Whitelist, то есть лист IP-адресов, к которым никогда не будем применять Rate limit при помощи аннотации nginx.ingress.kubernetes.io/limit-whitelist.
И последний момент: при отказе в отработке запроса при истечении лимитов Nginx по умолчанию отдаёт ошибку 503 Service Unavailable. Это не совсем корректно. В спецификации HTTP протокола есть более подходящий код ответа: HTTP 429 Too Many Requests. Изменить код ответа можно при помощи настройки limit-req-status-code в глобальной configmap.
Глобальные Rate limits
Настраивая локальные Rate limits, мы должны помнить, что с изменением количества экземпляров Ingress, через которые идёт трафик, мы меняем не только полосу пропускания, но изменяем и лимиты. Для того чтобы это преодолеть, у нас существуют Global Rate limits.
apiVersion: v1
kind: ConfigMap
metadata:
name: ingress-nginx-controller
namespace: ingress-nginx
data:
global-rate-limit-memcached-host: memcached.nginx-ingress.svc.cluster.local
global-rate-limit-memcached-port: 11211
global-rate-limit-memcached-connect-timeout: 20msВ Ingress Nginx они реализованы при помощи библиотеки lua-resty-global-throttle и сервиса memcached. Для того чтобы начать с ними работать, мы должны настроить memcached: указать его параметры в глобальном ConfigMap Ingress-контроллера и настроить аннотациями параметры глобальных лимитов.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-configuration-example
annotations:
nginx.ingress.kubernetes.io/global-rate-limit: 100
nginx.ingress.kubernetes.io/global-rate-limit-window: 5s
nginx.ingress.kubernetes.io/global-rate-limit-key: "${remote_addr}-${http_x_api_client}"
nginx.ingress.kubernetes.io/global-rate-limit-ignored-cidrs: "8.8.8.8"
spec:
ingressClassName: nginx
rules:
- host: custom.configuration.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: http-svc
port: 8080Пример конфигурации
В этих параметрах мы можем настроить:
nginx.ingress.kubernetes.io/global-rate-limit — количество запросов;
nginx.ingress.kubernetes.io/global-rate-limit-window — временной период, за который готовы их принять.
Кроме того, мы можем настроить Whitelist при помощи nginx.ingress. kubernetes.io/global-rate-limit-ignored-cidrs.
Rate limits на Service mesh
Настраивая Rate limits на Service mesh, мы должны помнить, что proxy, которая принимает решение о наложении Rate limits, может находиться в любом pod`е: на сервере, на клиенте, везде, в любой щели.
Первая возможность для настройки Rate limits в Istio — это секция connection pool для DestinationRule.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: microservice-destinationrule
namespace: prod
spec:
host: microservice
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http2MaxRequests: 200
http1MaxPendingRequests: 5Пример конфигурации
Разработчики Istio считают это частью Circuit breaker, но я думаю, что это не совсем корректно. В рамках лимитов на connection pool мы можем настроить лимиты на количество активных TCP-соединений, максимальное количество HTTP-запросов в обработке и максимальное количество запросов в ожидании — такой специфический аналог Burst limit. Это правило применяется на клиенте, и оно локальное внутри конкретного Sidecar proxy. То есть, настроив лимит в 100 соединений при двух клиентах, мы соответственно получаем 200 запросов на сервисе.
Envoy Rate limits
В Istio мы также можем настроить так называемые Envoy Rate limits. Они тоже бывают локальными и глобальными, и для их настройки используется custom resource EnvoyFilter. На мой взгляд, это функционал, который очень похож на Configuration Snippets в Ingress-контроллере. То есть разработчики Istio не стали заморачиваться с созданием каких-то абстракций для Rate limits, а отдали нам конфиг Envoy и сказали: «Вот, пожалуйста». Документацию по этим Rate limits, наверное, лучше искать в документации Envoy.
Локальные Rate limits
При настройке локальных Rate limits в Istio мы должны помнить, что лимиты мы можем применять к TCP и HTTP, на источнике и на назначении трафика, для входящего и исходящего трафиков. Например:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: httpbin-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
app: httpbin
version: v1
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
response_headers_to_add:
- append_action: APPEND_IF_EXISTS_OR_ADD
header:
key: x-rate-limited
value: TOO_MANY_REQUESTS
status:
code: BadRequestПример конфигурации
Здесь мы видим, что custom resource EnvoyFilter состоит из двух частей. Первая описывает, куда применяется патч конфигурации envoy, вторая — сам патч. В первой части примера мы видим, что патч применяется к HTTP-протоколу (applyTo: HTTP_FILTER) к входящим (context: SIDECAR_INBOUND) для подов приложения, имеющим метку, описанную в workloadSelector.
В патче мы видим непосредственно описание Rate limits. Они сделаны по принципу token bucket. То есть у нас есть bucket, у которого есть заданная ёмкость токенов (max_tokens — это могут быть http-запросы в обработке либо tcp-соединения) и правила его заполнения: tokens_per_fill — количество новых токенов; fill_interval — временной промежуток, в который мы можем принять описанное количество токенов. Но если bucket у нас заполнен, то мы не можем принять ничего.
Глобальные Rate limits
Для того чтобы начать с ними работать, мы должны установить специальный сервис для работы с Rate limits, куда Envoy будут ходить по gRPC. Чаще всего это должен быть Redis, который хранит информацию по соединениям.
Здесь мы можем настроить domain, к которому будем применять лимиты, и сами лимиты: временной промежуток unit и requests_per_unit — количество запросов, которые мы готовы в него принять (что-то достаточно близкое к глобальным лимитам Ingress Nginx).
apiVersion: v1
kind: ConfigMap
metadata:
name: ratelimit-config
data:
config.yaml: |
domain: productpage-ratelimit
descriptors:
- key: PATH
value: "/productpage"
rate_limit:
unit: minute
requests_per_unit: 1
- key: PATH
rate_limit:
unit: minute
requests_per_unit: 100Применяются глобальные лимиты также при помощи custom resource EnvoyFilter:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: filter-ratelimit
namespace: istio-system
spec:
workloadSelector:
# select by label in the same namespace
labels:
istio: ingressgateway
configPatches:
# The Envoy config you want to modify
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
subFilter:
name: "envoy.filters.http.router"
patch:
operation: INSERT_BEFORE
# Adds the Envoy Rate Limit Filter in HTTP filter chain.
value:
name: envoy.filters.http.ratelimit
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ratelimit.v3.RateLimit
# domain can be anything! Match it to the ratelimter service config
domain: productpage-ratelimit
failure_mode_deny: true
timeout: 10s
rate_limit_service:
grpc_service:
envoy_grpc:
cluster_name: outbound|8081||ratelimit.default.svc.cluster.local
authority: ratelimit.default.svc.cluster.local
transport_api_version: V3Здесь в секции patch мы можем видеть описание domain, для которого мы хотим ввести лимиты и описание grpc service, в котором они хранятся.
При настройке глобальных Rate limits стоит понимать, что это распределённые Rate limits, и они небесплатные с точки зрения нагрузки. Запрос в Redis занимает время и увеличивает время на обработку трафика нашими прокси. Это тяжёлый механизм, поэтому разработчики, что Ingress, что Istio, рекомендуют использовать локальные и глобальные Rate limits вместе, чтобы оптимизировать использование ресурсов.
Короткие выводы
Тема отказоустойчивости обширна до бесконечности. Описанные выше паттерны универсальны и могут быть реализованы на нескольких уровнях – от аппаратного обеспечения до кода приложений.
Мы рассказали про применение в этих целях платформы Kubernetes и ее экосистемы. Это удобный инструмент, а нужен он или нет — каждый должен решить для себя сам. Всё зависит от индивидуальных требований к отказоустойчивости и уровня качества сервиса.
Ключевыми элементами при формировании нужных лимитов и тайм-аутов должны быть понятно описанная схема вашей конкретной инфраструктуры и накопленная статистика мониторинга. Только в этом случае вы сможете подобрать параметры, оптимальные именно для вашей ситуации.
Комментарии (2)

n_bogdanov
26.12.2022 15:59В статье устаревшие конфиги приведены как пример. С 8 версии php-fpm появилась директива
pm.status_listen, которая позволяет избавиться от уродливого костыля в виде пулаhealthcheck. Это так же позволит наконец-то сделать скейлинг исходя из загрузки worker- процессов.
seasadm Автор
Статья по итогам доклада на Highload++
https://youtu.be/y8diUsNPc6w