
Helm — один из самых популярных пакетных менеджеров для Kubernetes. Познакомиться с ним полезно любому DevOps-инженеру и всем, кто сталкивается с задачами деплоя приложений. Эту мини-серию из двух статей можно рассматривать как краткое, но достаточно полное введение в Helm. В первой части поговорим об архитектуре Helm и некоторых типичных задачах, которые он позволяет решать. В частности, кастомизации приложения и переиспользвании кода.
Фрагменты кода в статье специально даны в виде картинок — это позволило выделить важные для нас строки. Но для вашего удобства я на всякий случай собрал все примеры в этом репозитории.
Назначение Helm
Современное приложение — сложный продукт с множеством внутренних компонентов и внешних связей.

При этом чаще всего у нас есть несколько рабочих окружений, которые могут достаточно сильно отличаться друг от друга и по количеству компонентов и связей, и по их качеству.
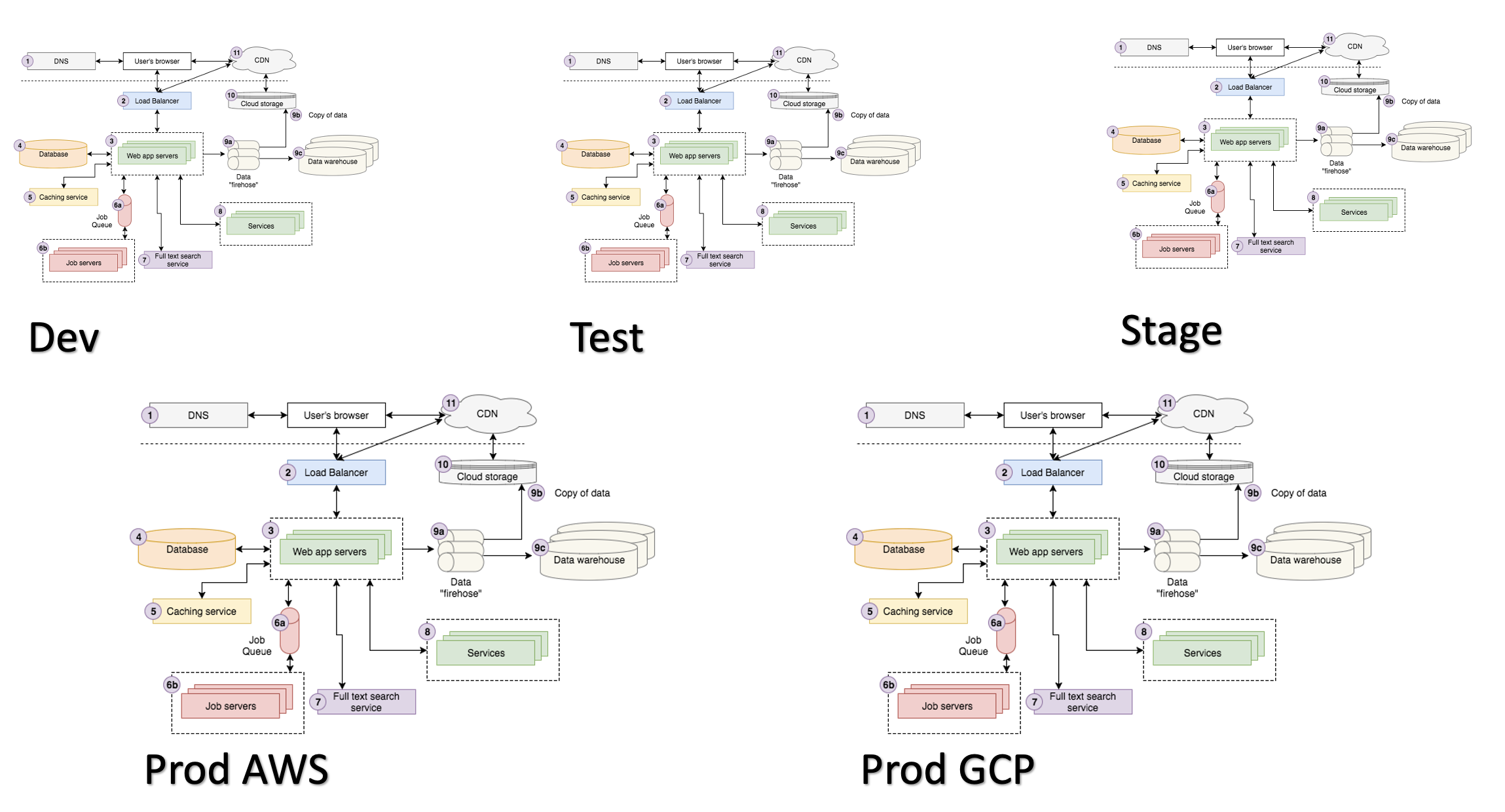
Кроме того, в современном мире микросервисов и распиленных монолитов у нас может быть гораздо больше одного проекта.

Управлять этим сложным хозяйством хочется максимально простым, универсальным и наименее затратным способом. Поэтому отношение к выбору подходящего инструмента для деплоя и построение технической дисциплины на его основе варируется от хорошей практики до необходимого условия выживания.
Таким тулингом для многих стал Helm Package Manager.

Возможности Helm
Список основных возможностей включают в себя:
Простую текстовую шаблонизацию (Go templates + Sprig framework).
Управление релизами (установка, апгрейд, откат, удаление).
Tracking выката релиза с возможностью отката в случае неудачи.
3-way merge.
Hooks & plugins.
Развитое сообщество.
Множество готовых чартов для всего.
Для публикации последних создатели Helm даже запустили специальный сайт artifacthub.io. Там уже собрана и постоянно пополняется сообществом огромная коллекция чартов (в апреле 2021-го их было 3402, в сентябре — уже 5568).

Правда, как это бывает с опенсорс-наработками, их качество совершенно разное (я бы не рекомендовал использовать чарты с artifactshub без изменений). Более или менее сориентироваться в содержимом позволяют звезды, которые присваивают наработкам пользователи. Разумеется, вы также можете внести вклад в оценку.
В любом случае, даже если не найдете ничего подходящего, всегда можно взять готовый вариант за основу собственного проекта. Просто чтобы не начинать с нуля.
Альтернативы Helm
Конечно же, Helm — не единственное решение для деплоя в Kubernetes. У нас есть и другие:
Kustomize от авторов Kubernetes. Этакий «kubectl на стероидах», который, однако, слабо подходит для больших и сложных проектов.
Паттерн Kubernetes Operators, который в последнее время активно продвигает компания Red Hat. Она спонсируют опенсорсный Operators Framework и сайт operatorshub.io для публикации наработок. Более того, даже встроила в свою платформу OpenShift возможность установки операторов с этого сайта по клику. Но нужно понимать, что Kubernetes Operator — вещь в себе. Порой очень трудно разобраться, как он все-таки работает, а уж тем более внести в него изменения.
Ansible. Его используют многие, хотя, на мой взгляд, когда дело касается деплоя в Kubernetes, Ansible в сочетании с Jinja — прекрасный способ все запутать.
Terraform. С его помощью также можно строить деплой, используя какие-нибудь специализированные провайдеры, только вот красивых решений на его основе лично я до сих пор не видел.
-
Jsonnet — язык шаблонизации от Google, на котором построены некоторые инструменты. Например:
· Tanka (by Grafana);
· Qbeq (by Splunk);
· Ksonnet.
При выборе инструмента, безусловно, стоит учесть и его слабые стороны. Например, именно недостатки Helm и попытались преодолеть ребята из Grafana, создавая собственный продукт Tanka с использованием jsonnet.

Итак, основные недостатки Helm:
Только строковая шаблонизация. Мы строим деплой, ничего не зная о конечных примитивах, основываясь на хрупком YAML-синтаксисе.
Сложное расширение. Если вам чего-то не хватает в готовом чарте, скорее всего, придется его форкнуть и доработать самостоятельно.
Низкий уровень абстракции. Мы не можем описать объект, порождающий deployment, service и ingress, унаследоваться от него и переопределить deployment в StatefulSet.
Потенциальная запутанность. Конечные результаты генерации релиза могут очень сильно различаться в зависимости от значений, которые мы подали на вход.
Но несмотря на все недостатки Helm, я не знаю людей, сменивших его на что-то другое. А вот с обратными примерами сталкивался неоднократно. Например, мои знакомые сперва деплоили при помощи Terraform и Jsonnet provider, потом перешли на Ansible, но в итоге и его переписывают на Helm. Они объяснили это тем, что начали привлекать для описания деплоя в Kubernetes разработчиков, а Helm, покрывая большинство их потребностей, обеспечивает еще и низкий уровень входа.
Кстати, та же Tanka не так давно официально и с гордостью объявила о поддержке Helm charts.

Архитектура и основные понятия Helm
Сейчас актуальны версии Helm 2 и Helm 3, причем последняя, в отличии от предыдущей, не имеет серверного компонента (Tiller). Фактически это просто Go-бинарник, причем Helm 3 гораздо более легковесный и дружественный к разделению прав.
Архитектура Helm 3 представлена на схеме:

Работает же Helm 3 следующим образом:
Получает на вход Chart (локально или из репозитория, при этом чарты могут использовать друг друга) и генерирует манифест релиза.
Получает текст предыдущего релиза.
Получает текущее стостояние примитивов из namespace-релиза.
Сравнивает эти три вещи, делает patch и передает его в KubeAPI.
Дожидается выката релиза (опциональный шаг).
Эта схема называется 3-way merge. Таким образом Helm приведет конфигурацию приложения к состоянию, которое описано в git, но не тронет другие изменения. Т. е., если у вас в кластере есть какая-то сущность, которая трансформирует ваши примитивы (например, Service Mesh), то Helm отнесется к ним бережно.
Теперь пройдемся по основным понятиям Helm.
1. Helm chart
Фактически, папка определенной структуры с текстовыми файлами внутри. По команде helm create [chartname] будет создана заготовка, которую вы сможете развить нужным вам образом.

Файлы имеют разную структуру и назначение. Например, в Chart.yaml описаны основные параметры чарта. Перед вами официальный Chart.yaml minio:
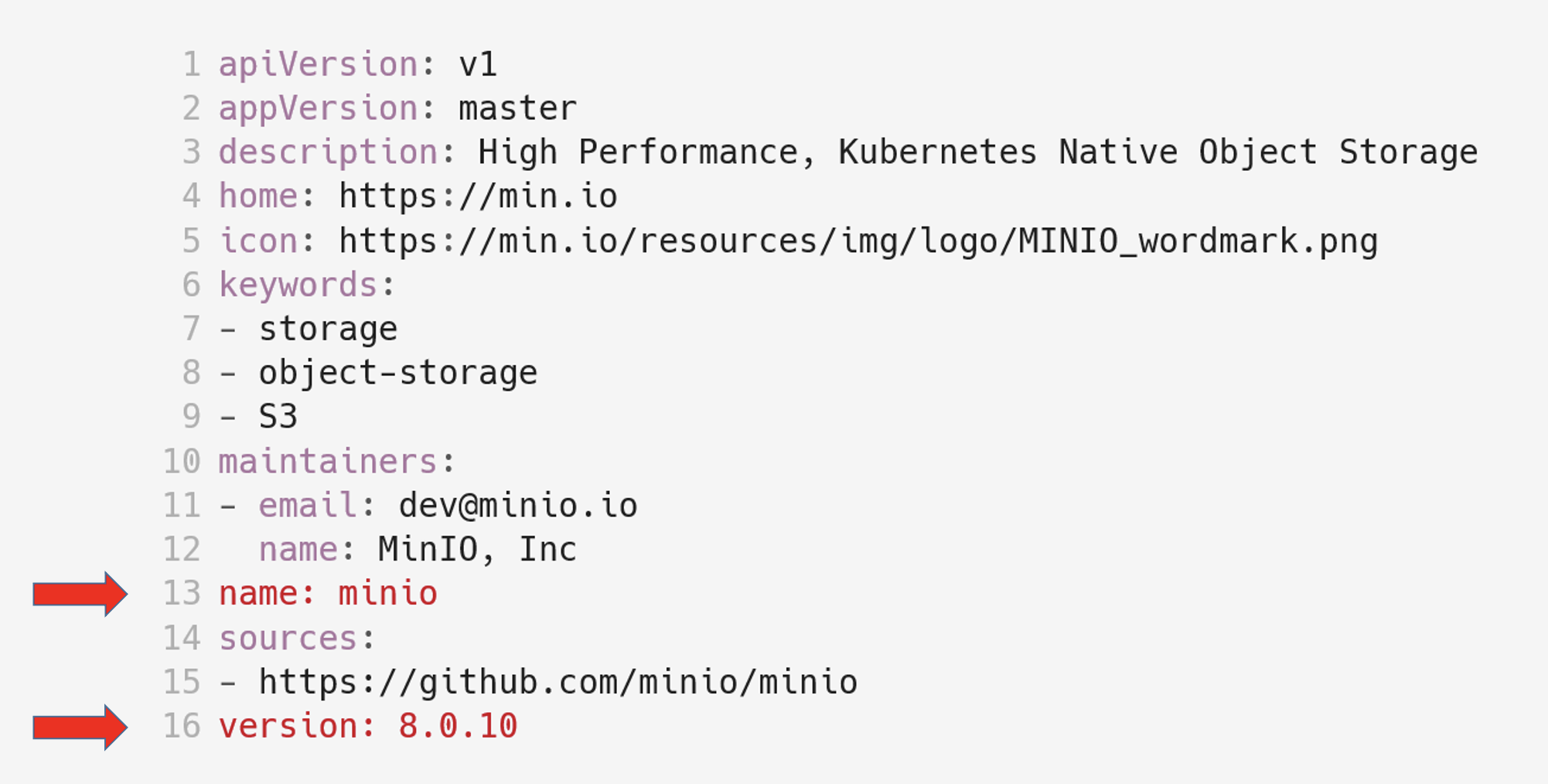
В нем много произвольных описательных полей, однако необходимое и достаточное условие — указать только name и version. Если хотите копнуть глубже, вам сюда.
2. Репозиторий чартов
Достаточно простая сущность, фактически веб-сервер, в корне которого лежит index.yaml с описанием чартов и сами запакованные .tgz-чарты.
В принципе, управлять репозиторием можно вручную, используя команды Helm. Хотя существует и ПО, обеспечиващее быстрый старт и визуальные интерфейсы для облегчения работы. Например:
Chart museum;
Jfrog Artifactory;
Harbour.
Копнуть глубже можно здесь.
3. Helm Release, Helm Values
Helm Release генерируется из чарта (Chart) с использованием входных значений (Values):
Chart + Values = Release
При помощи команды helm list мы можем просмотреть релизы, установленные в конкретном Kubernetes Namespace.
Пример:

С релизами связано понятие Release backend — места, в котором Helm хранит и версионирует переданные на деплой релизы.
Это может быть configmap/secret/SQL. По умолчанию это secret — Helm создает объект этого типа (в котором хранится JSON, завернутый в gzip + Base64) на каждый релиз в Namespace, куда его и устанавливает. Хотя он может сделать это и, например, в SQL-базе.

Типовые задачи «YAML-девелопера»
Перейдем к задачам, которые наиболее часто возникают в процессе деплоя приложений в Kubernetes, и их реализции с помощью Helm. У меня получился вот такой короткий список:
Кастомизация приложения в разрезе окружений.
Переиспользвание кода.
Управление блоками кода по условию.
Модульная разработка.
Трекинг выката.
Установка очередности запуска подов.
Отладка.
Релизный цикл.
Расширение функциональности Helm.
Как видите, в список вошли и базовые, я бы даже сказал, экзистенциальные, задачи вроде переиспользования кода, и вполне практические, вроде отладки
1. Кастомизация приложения в разрезе окружений
У нас может быть достаточно много окружений, похожих в целом, но, в то же время, имеющих несколько важных отличий.
Среди последних можно выделить два типа:
Отличия, связанные с параметрами работы приложений (например, данные внешних систем, имена баз, очередей и т. п.).
Отличия в инфраструктуре (адреса ингрессов, количество реплик, включение или отключение инфраструктурных компонентов).
Согласно лучшим практикам, мы должны уметь передавать рабочие параметры в приложение как можно ближе к деплою. Если вы до сих пор устанавливаете их при сборке имиджа или запекаете в образ, не делайте так — этот подход чреват многими проблемами. Хороший способ управления рабочими параметрами — передавать их через переменные окружения или configmap, которые монтируются в под.
Управление инфраструктурными изменениями концептуально сходно с управлением рабочими параметрами приложения: в рамках Helm это изменение текстовых файлов в зависимости от набора входных значений.

Чтобы управлять входными значениями, в Helm есть механизм Values, расположенный в файле values.yaml:

Мы можем использовать values в templates.

Values.yaml представляет собой иерархическую древовидную структуру «ключ — значение».

С ее помощью мы можем создавать нужную группировку и мнемонику для наших входных величин.

Использовать values мы можем в файлах templates при помощи конструкций вида:
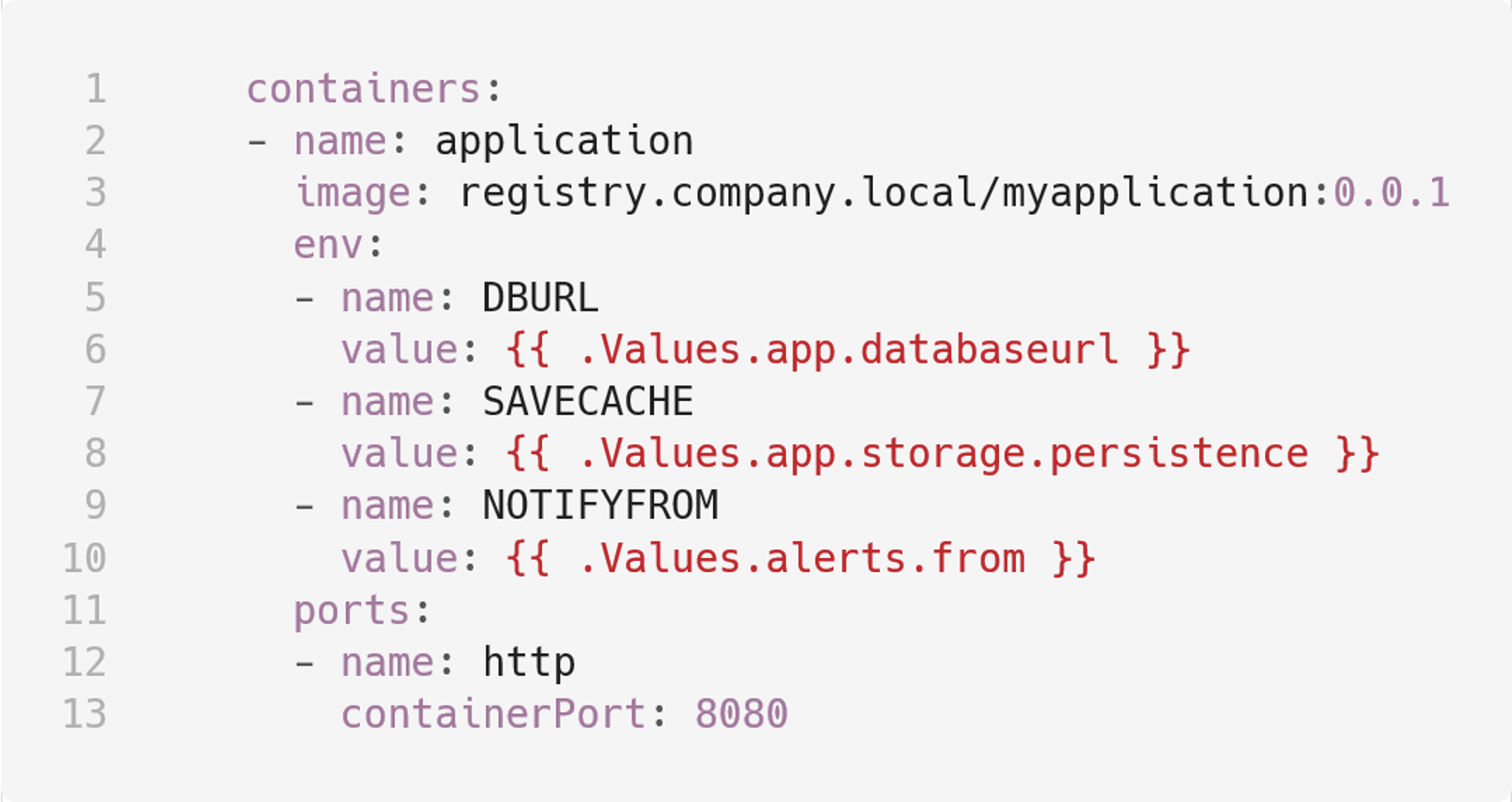
Здесь “.” означает текущую область значений (current scope), далее идет зарезервированное слово Values и путь до ключа. При рендере релиза сюда подставится значение, которое было определено по этому пути.
Но values.yaml — статический способ задания величин. Очевидно, что нам нужно менять некоторые values при деплое в конкретное окружение. В Helm для этого предусмотрено несколько способов:
Передача через директиву --set. Мы можем передавать одну:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--set global.env=developили несколько директив set:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--set global.env=develop \
--set app.databaseurl=$POSTGRESQL_PASSWORD_DEVПередавать несколько значений через запятую в одной директиве set:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--set global.env=develop \
--set app.databaseurl=$POSTGRESQL_PASSWORD_DEV \
--set app.cloud=aws,app.storage.storageclass.aws=gp3Передавать списки:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--set global.env=develop \
--set app.databaseurl=$POSTGRESQL_PASSWORD_DEV \
--set app.cloud=aws,app.storage.storageclass.aws=gp3 \
--set alerts.receivers={“dev@company.local”,”dev@subcompany.com”}Передавать значения в списки:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--set global.env=develop \
--set app.databaseurl=$POSTGRESQL_PASSWORD_DEV \
--set app.cloud=aws,app.storage.storageclass.aws=gp3 \
--set alerts.receivers={“dev@company.local”,”dev@subcompany.com”} \
--set alerts.receivers[0].host="smtpdev.subcompany.com"Но это уже, пожалуй, слишком неудобно. Поэтому мы можем передавать заполненные файлы values через директивы -f или --values (также один или несколько).
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--set global.env=develop \
--set app.databaseurl=$POSTGRESQL_PASSWORD_DEV \
--set app.cloud=aws,app.storage.storageclass.aws=gp3 \
--set alerts.receivers={“dev@company.local”,”dev@subcompany.com”} \
--set alerts.receivers[0].host="smtpdev.subcompany.com" \
--values=./path/to/app.dev.yaml \
--values=./path/to/alerts.dev.yamlПри этом значения, переданные через --set или --values, будут переопределять те, которые описаны в values.yaml чарта. Также можно передавать значения по ключам, которые не описаны в values.yaml — они также будут доступны. Но если в шаблоне используется значение, которого нет в values.yaml чарта, его нужно передать при деплое (или сделать заглушку, например, функцией default go templates), иначе рендер релиза сломается.
1.1. Работа со списками
В примере values.yaml выше были описаны списки storageClass и persistentVolumeSize в секции app.storage. Они описывают параметры persistentVolume в зависимости от облака, куда мы производим деплой (aws или gcp). Такие списки очень удобны и встречаются достаточно часто. Есть несколько вариантов использования таких списков. При деплое нам прежде всего нужно определить value, характеризующее конкретный вариант. В примере выше это
--set app.cloud=awsПлохой способ использования списка — описать при помощи конструкции if все имеющиеся варианты:

Более правильный способ — использовать функции Go templates:

Здесь мы при помощи функции pluck по значению .Values.app.cloud выбираем ключ из нужного из списка, приводим его к строке при помощи функции first и оборачиваем в кавычки результат, передавая его в функцию quote.
Функции Go templates, расширенные Sprig framework, позволяют делать код гораздо более красивым, функциональным и компактным. Если вы что-то делаете и чувствуете, что получается не очень-то хорошо, подумайте насчет использования Go templates.
Вот пара полезных ссылок на этот случай:
Говоря о values, нужно упомянуть стандартные значения Helm, которые формируются автоматически при каждом рендере релиза.
Например, имя/версия чарта: {{ .Chart.Name }}-{{ .Chart.Version }}, или нэймспэйс, в который производится деплой: {{ .Release.Namespace }}.
Они подробно описаны в документации по этой ссылке.
Если вы используете эти значения в своем коде

то при переносе его между чартами, код подхватит нужные значения и бесшовно, без изменений встроится в новый чарт.
2. Переиспользование кода
Допустим, у нас есть некоторое количество значений:
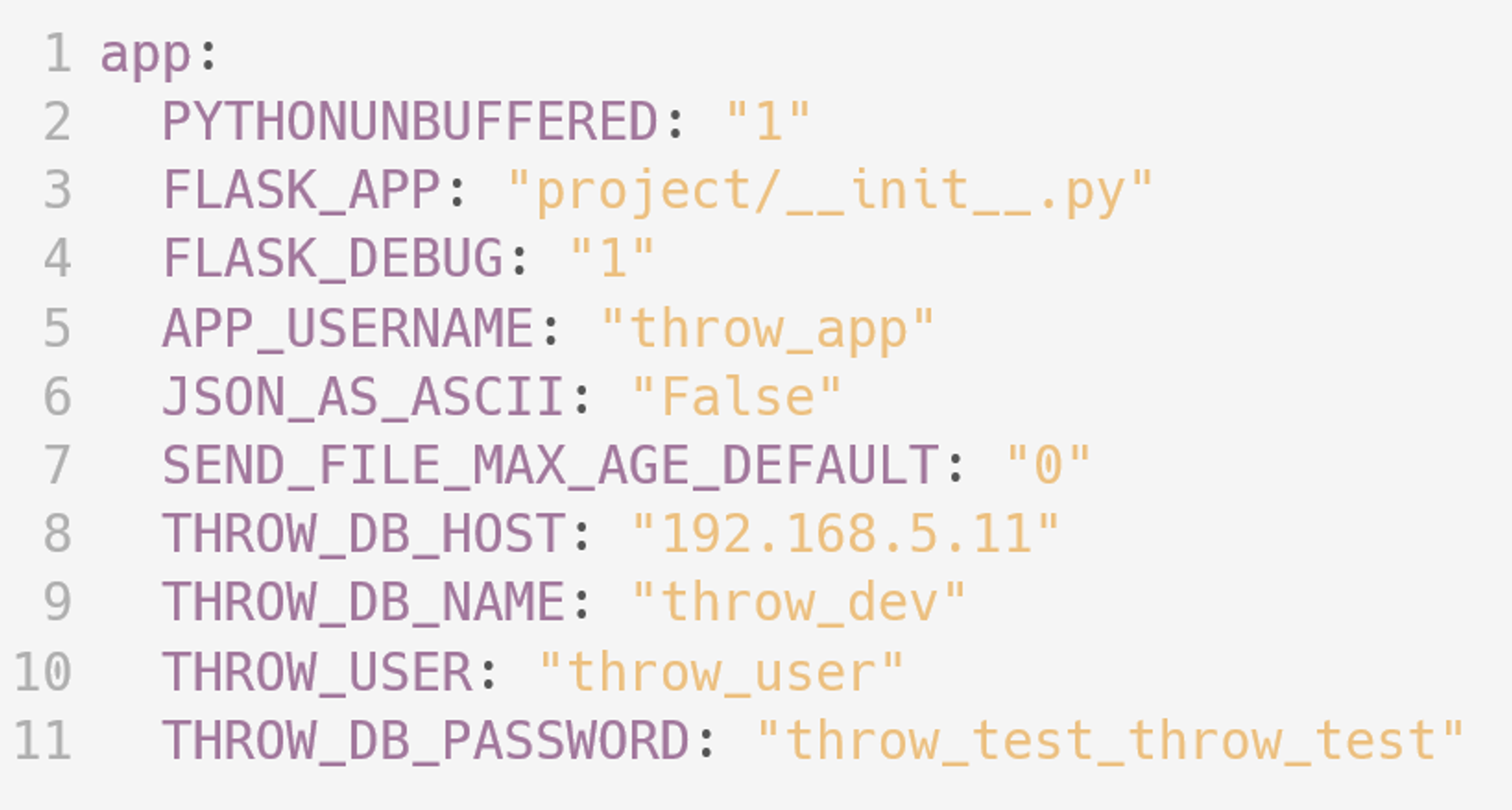
И эти значения нужны нескольким приложениям в нашем чарте:
- Backend;
- Websockets;
- Workers;
- Cronjobs.
Вполне очевидно, что дублировать секцию env: в описании каждого приложения совершенно некрасиво.
Для решения этой проблемы в Helm есть механизм “Named templates”.
Согласно соглашениям, named templates могут быть описаны в файлах с расширениями .tpl или .yaml, имя которых начинается с нижего подчеркивания:
_*.tpl
_.yaml

Там мы можем определить секцию “define”…

…которую потом сможем подключить к нашим yaml при помощи директивы include:
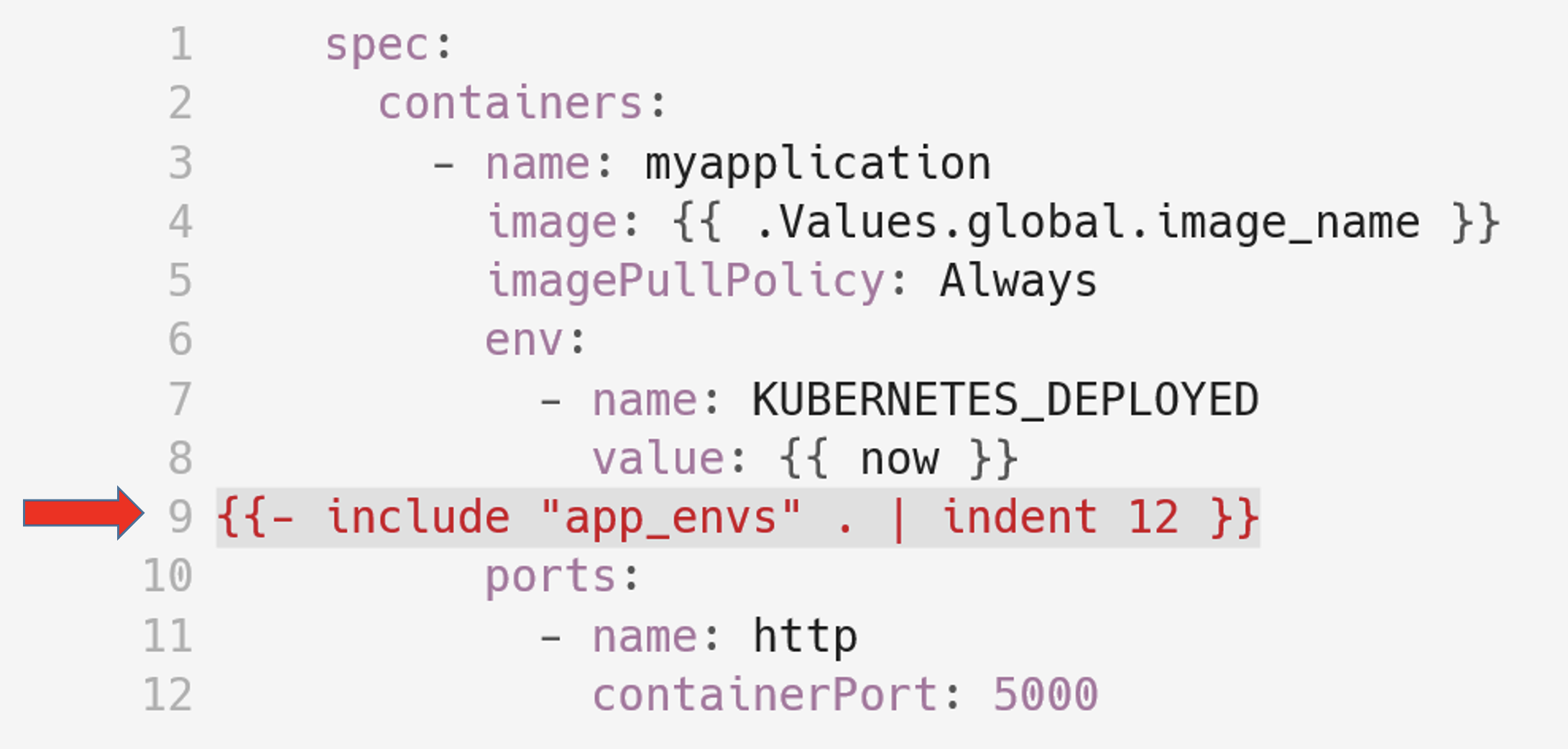
Здесь мы видим, что в функцию include передается имя define и текущий контекст, потом текст, описанный в define, при помощи pipe передается в функцию indent, которая сдвигает его на 12 пробелов.
Для чего это может быть использовано? Для любых повторяющихся участков кода.
Определение общих labels:


annotations:


nodeSelector / tolerations:


antiAffinity:


Используйте templates и следуйте базовому правилу программирования “DRY”: DON’T REPEAT YOURSELF!

2.1. Использование циклов (range)
Примеры values.yaml и define, который был сделан для подключения его в yaml приложения, выглядят совсем некрасиво. Приходится описывать значение в values, потом описывать его же в define. Это явное дублирование.
Избавиться от него в Helm можно при помощи range.
Пример 1: range по заданному списку.

Этот блок кода генерирует три persistentVolume типа local storage на трех выделенных нодах. На вход мы подаем список из порядковых номеров нод. К его элементам мы обращаемся через конструкцию {{ . }} (строки 6 и 15), которая означает текущую область значений (current scope). При этом мы используем в наименовании имя чарта .Chart.Name, которое находится в верхней области значений, обратиться к нему мы можем, используя символ $.
Пример 2: range по values.yaml
Допустим, у нас есть некоторое количество cronJob, которые различаются фактически только расписанием и командой запуска. Описываем их как список в values.yaml:

И описываем range:

Здесь в Строке 1 в переменные $name и $range мы считываем секцию cronjobs.
Затем на основании $name, в которую попадают узлы первой иерархии из дерева секции, делаем имя cronJob (Строка 5).
На основании $params, куда попадает список значений узла, мы заполняем расписание (Cтрока 7) и параметры команды запуска (Строки 15 и 16), обращаясь к ключам, указанным в списке.
При этом мы делаем include переменных окружения из верхней области значений по аналогии с предыдущим примером (Строка 19).
Range — очень мощное средство шаблонизации, но оно требует повышенного внимания, не проявив его, можно запросто выстрелить себе в ногу.
Скажем, в Примере 2 допущена ошибка, которая приведет к тому, что из всего списка будет создан только последний cronJob. Дело в отсутствии yaml разделителя. Правильный вариант выглядит так (обратите внимание на Строку 2):

Каким же образом при помощи range мы можем улучшить эту конструкцию?

Итоговая конструкция получается гораздо проще и лаконичнее:

2.3. Хорошие практики values.yaml
Поскольку Helm chart часто описывает несколько окружений, многие делают разные файлы values и передают их через директиву --values при деплое. На мой взгляд, это плохая практика — такой подход приводит к потере наглядности.
Гораздо лучше описывать переменные списком в разрезе окружений. Т. о., базовое описание values…

…превращается в

Однако от окружения к окружению менять нужно не все величины, часть из них изначально описана как _default.
Код для разбора таких конструкций будет выглядеть так:

Здесь range по секции app (Строка 3). В name приходит название переменной окружения, в map — список значений, из которого выбирается значение на основании переменной global.env, переданной через директиву --set при запуске Helm, и в которой должно находиться имя целевого окружения.
Если значения, соответствующего окружению, не найдено, то при помощи функции default подставляется значение из ключа _default.
Этот способ описания очень любят разработчики, поскольку оно достаточно простое и наглядное.
2.4. Лучшие практики
Если говорить о лучших практиках, в документации Helm есть набор рекомендаций и хаков, которые могут пригодиться при его использовании: Chart best practices, Chart tips and tricks.
Например, из подборки лучших практик вы можете узнать, что создатели Helm топят за использование camelCase. А в tips and tricks я недавно нашел такую штуку:

Здесь же мы делаем аннотацию подов в template, которая рассчитывается на основании хеш-функции от содержимого configmap. Configmap изменился, хеш пересчитался, анотация поменялась, поды перекатились, конфигурация применилась. На мой взгляд, решение очень остроумное.
На этом пункте я решил сделать перерыв, поскольку материал получается очень большим. Впрочем, обещаю не затягивать с выкатом продолжения, в котором речь пойдет о прочих типичных задачах, возникающих в ходе деплоя в Kubernetes: трекинге выката, отладке, управлении релизным циклом и т. д.
Комментарии (13)

Ramiras
18.11.2021 08:32С большой радостью ушел с хельма на кастомайз. Не без недостатков, но терпеть эту убогую шаблонизацию и бесконечный поток обращений с ошибкой "Error. UPGRADE FAILED" не было сил.

seasadm Автор
18.11.2021 08:36Go templates очень мощный и гибкий инструмент если умеешь им пользоваться. Этому собственно и посвещена статья. В ошибках апгрейда хелм как правило не виноват. Там либо чарт кривой(иммутабельные поля правятся например), либо выкат (включен трекинг и выкат сфэйлился по таймауту). Про отладку чартов в следубщей части.

shurup
18.11.2021 09:44+1
Из CNCF Survey Report 2020 Хорошо, что есть разные инструменты. Но игнорировать Helm невозможно.


amarkevich
18.11.2021 15:17даже в простых примерах не стоит использовать пароли из values.yaml. В прод все равно пойдет
envFrom: - secretRef: name: {{ .Values.secretName }}seasadm Автор
18.11.2021 17:53Не обязательно. Всё зависит от того как в данном конкретном случае организована работа с секретами. Они могут передаваться из защищенного хранилища ci системы через директиву set или лежать в зашифрованном виде в values в репозитории.
amarkevich
22.11.2021 18:16... и будет светится открытым текстом в yaml Deployment'а
seasadm Автор
22.11.2021 19:32А в yaml чего он должен светиться?
amarkevich
04.12.2021 17:19Helm поместит значение в явном виде; имея доступ к просмотру yaml Deployment'ов - все пароли на виду.
seasadm Автор
06.12.2021 08:16Нужно отделять мух от котлет, а секьюрность от деплоя. Программист может не иметь доступа к cd системе и кластеру и не видеть ни её защищённое хранилище, ни нутрянку кластера, и при этом легко вытащить пароли, потомучто в контейнерах крутится его код и выложить содержимое переменных окружения на отдельный локейшен например - как два байта п. Совет "не используйте пароли из вэльюс" в общем случае очень наивный.
Shaman_RSHU
Лучше было бы оформлять код не в виде картнок, а то размер шрифта получился разный.
acheonline
Чистейшая вкусовщина
amarkevich
ломает копи-пасту
acheonline
С этой точки согласен. Просто автор комментария написал про размер шрифтов