
Нейронные сети в частности и машинное обучение в целом демонстрируют потрясающие результаты в тех областях науки и техники, в которых от них никто не ожидал этого еще лет 10 назад. Уже на текущий момент модели машинного обучения превзошли человека в задачах классификации, распознавания, предсказания, и даже в некоторых играх человек не способен конкурировать c ними…
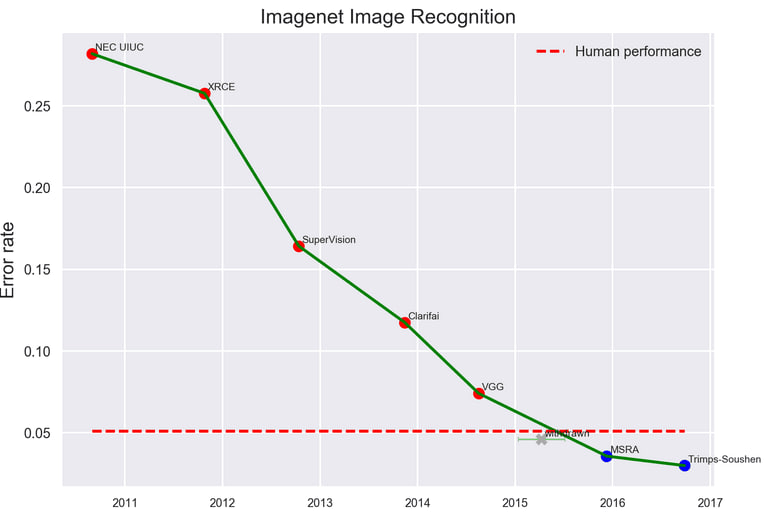
Задача классификации изображений на датасете ImageNet — ярчайший пример того, как нейросети догнали и перегнали людей (внимание: еще в 2016 году).
Удивительно, но все еще нас окружает большое количество документов, в которых есть рукописный текст. До сих пор часто от руки пишут врачи, в некоторых организациях все еще принят рукописный оборот, есть сервисы, в которых требуется писать от руки, обеспечивая дополнительную биометрическую проверку. С другой стороны, активно внедряется автоматизация… Внедрение автоматического распознавания рукописного текста позволило бы значительно ускорить процесс обработки документов.
Архитектура

Одной из архитектур, с помощью которой можно реализовать распознавание текста, является так называемая CRNN (сверточно-рекуррентная нейронная сеть) . Модель представляет из себя комбинацию сверточной нейронной сети (CNN) для извлечения локальных признаков из изображения и рекуррентной нейронной сети (RNN), представленной двумя слоями двунаправленных LSTM, которая занимается обработкой последовательности.
Сверточная часть сети устроена таким образом, что исходное изображение разбивается на k (гиперпараметр) вертикальных сегментов вдоль горизонтальной оси, каждому из которых на выходе из свертки соответствует вектор признаков размерности (1, n). За счет уменьшения одного из измерений до единицы, мы можем без потери информации понизить размерность карты признаков ((k, 1, n) -> (k, n)). Таким образом, на выходе получена двухмерная матрица признаков размерности (k, n), которую можно передать на вход в рекуррентную часть сети (RNN) (n-также гиперпараметр, размерность вектора признаков для каждого из окон, по сути, число карт признаков, получаемых из последней свертки).

С помощью двух Bidirectional LSTM слоев RNN блок трансформирует последовательность, многоклассовую классификацию элементов которой выполняет полносвязный слой (число классов = длина алфавита + 1 (служебный символ, к которому еще вернемся)).
Пример классификации для примера выше (для алфавита «0 123 456 789» + служебный символ):
[10, 6, 7, 7, 10, 1, 10, 2, 2, 10, 2, 10, 3, 3, 10, 7, 10, 10, 2, 10, 4, 4, 10, 9, 10]
Применив классическую для задачи многоклассовой классификации функцию argmax, мы можем декодировать выходную матрицу softmax-векторов в последовательность индексов элементов алфавита (и для наглядности подставить элементы алфавита по индексам):
“-677-1-22-2-33-7--2-44-9-”
Помня механизм деления исходного изображения на окна, учитываем, что некоторые символы могли попасть сразу в несколько окон, соответственно, в декодированной последовательности они могут дублироваться. Здесь нам помогает служебный символ-разделитель: с его помощью можем
убрать «ложные» дубли – ситуации, когда один символ исходного изображения попал в несколько окон,
сохранить «настоящие» дубли – ситуации, когда в исходной последовательности подряд идут одинаковые символы (как у нас в примере с двойками - 6712237249)).
С помощью Connectionist Temporal Classification (CTC) выравниваем последовательность и в результате работы функции нам удастся объединить раздвоившиеся символы (при этом сохранив "настоящие" дубли) и убрать знаки-разделители. Выход будет выглядеть так:
[6, 7, 1, 2, 2, 3, 7, 2, 4, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
Последовательность выровнена, а вектор дозаполнился заведомо ложными символами до размера соответствующему выходу сети. Нам останется только убрать все элементы со значением -1 и подставить индексы в алфавит.
Наш результат:
“6712237249”
Обучение CRNN распознаванию рукописного текста
Для решения задач рукописного распознавания я применю модификацию данной архитектуры на двух датасетах, с латиницей и с кириллицей.
Первый датасет - IAM. В нем содержатся бланки A4 с рукописным текстом на английском языке, для удобства была взята его версия, заранее разбитая на строки. Всего 13 353 записей.

Второй датасет - казахско-русская база слов и словосочетаний (HKR). Поскольку для нашей задачи не было необходимо распознавание казахских символов, мы пропустили поля, содержащие их. Также была проведена фильтрация некоторых символов: заменили схожие символы ground truth (“ё” -> “е”, “…” -> “...”, “—”,“–”-> “-” и т. д.) и удалили записи содержащие ненужные знаки препинания. Всего получилось 64 222 записи. Далее данные были приведены к схожему виду, что и у датасета IAM, а именно мы объединили по три записи в одну строку.
Пример изображения:

Далее, каждый из наборов данных был разбит на тренировочную (60%), валидирующую (20%) и тестовую (20%) выборки.
Ввиду схожести имеющихся данных все последующие операции применимы как к датасету IAM, так и к датасету HKR.
Записей в датасетах представлено с избытком, поэтому синтетическая аугментация для данных не потребовалась.
Препроцессинг включил в себя два простых шага:
Приведение изображений к виду соответствующему входу модели (изображения были приведены к размеру 800 на 64 и повернуты на 90 градусов по часовой стрелке);
Преобразование изображений в черно-белые (бинаризация).
Пример изображения (без поворота), подающегося в качестве входа в модель:

Результаты обучения
Метрики, по которым проводилась оценка:
Character Error Rate (CER) — метрика, характеризующая частоту ошибок в символах.
Character Accuracy Rate (CAR) — метрика, описывающая долю совпадения конкретного символа с местом этого символа в ground truth.
По итогам обучения модели на датасете IAM, CER на тестовой выборке составил 9.10%. Также была посчитана метрика CAR для каждого типа символов, чтобы наглядно увидеть какие символы модель хорошо классифицирует, а с какими возникают трудности. Среднее значение CAR для датасета IAM составило 76.54%.
Ниже приведены графики значений функции потерь и метрики CER в процессе обучения.

Метрика CAR по каждому символу для IAM:

Взглянув на конкретные примеры, можно убедиться в том, что модель справляется даже с трудночитаемыми вариантами почерка:



Применение подхода на датасете HKR тоже показало высокие результаты. Метрика CER составила 4.75%, а CAR оказался на уровне 93.24%. Точность распознавания на датасете HKR ощутимо выше ввиду того, что датасет изначально имеет более читаемый текст, также имела место предобработка датасета.

Метрика CAR по каждому символу для HKR:

Пример распознавания сегментов строк из общедоступной части датасета HKR.

На обоих датасетах модель достигла хороших результатов - 9.10% и 4.75% CER для IAM и HKR датасетов соответственно. Полученных результатов достаточно для использования моделей в проектах, не требующих абсолютной точности. Также, стоит помнить о том, что к строкам, получаемым из нейронной сети, можно применить техники пост-обработки, способные повысить точность еще на пару процентов (в основном работа со словарями т. к. множество слов более или менее известно и на выходе последовательности букв редко являются случайными). По ссылке ниже можно ознакомиться с кодом и лично обучить модель на датасете IAM.
Заключение
На обоих датасетах модель достигла хороших результатов - 9.10% и 4.75% CER для IAM и HKR датасетов соответственно. Полученных результатов достаточно для использования моделей в проектах, не требующих абсолютной точности. Также, стоит помнить о том, что к строкам, получаемым из нейронной сети, можно применить техники пост-обработки, способные повысить точность еще на пару процентов (в основном работа со словарями т. к. множество слов более или менее известно и на выходе последовательности букв редко являются случайными). По ссылке ниже можно ознакомиться с кодом и лично обучить модель на датасете IAM.
https://github.com/CyberLympha/Examples/blob/main/CV/CRNN_for_IAM.ipynb
Полезные ссылки
Репозиторий с используемой нами архитектурой
Датасеты:


kovserg
Круто. А с таким справится?

GeorgeAivazov
На фармацевта идёшь?
dmt_ovs
С таким и не каждый человек справится...