

Дебаты по поводу выбора между Playwright и Puppeteer — это большая дискуссия, поскольку они обе являются фантастическими библиотеками Node.js для автоматизации браузера. Хотя эти библиотеки делают практически одно и то же, между Puppeteer и Playwright есть несколько заметных различий.
Давайте проведем краткий экскурс в историю:
Puppeteer был создан командой разработчиков Chrome в 2017 году, чтобы компенсировать ненадежность Selenium для автоматизации браузеров. Playwright был позже запущен Microsoft и, как и Puppeteer, способен эффективно выполнять сложные тесты автоматизации в браузере. Но на этот раз они представили больше инструментов для тестирования. Так какой же из них лучше?
Давайте рассмотрим различия между Puppeteer и Playwright, чтобы понять, в чем уникальность обеих библиотек.
Playwright по сравнению с Puppeteer: в чем основные различия?
Puppeteer и Playwright — это headless‑браузеры, изначально предназначенные для сквозного автоматизированного тестирования веб‑приложений. Они использовались и для других целей, например, для веб‑скрейпинга. Несмотря на то, что у обоих инструментов автоматизации имеются схожие юзкейсы, существуют некоторые ключевые различия:
Playwright поддерживает Python, Golang, Java, JavaScript и C#, в то время как Puppeteer поддерживает только JavaScript, хотя существует неофициальный порт для Python.
Playwright поддерживает три браузера: Chromium, Firefox или WebKit. А Puppeteer, в свою очередь, поддерживает только Chromium.
Playwright
Playwright — это библиотека для сквозного веб‑тестирования и автоматизации. Хотя основная роль фреймворка заключается в тестировании веб‑приложений, его можно использовать для веб‑скрейпинга.
В чем преимущества Playwright?
Благодаря единому API библиотека позволяет вам использовать Chromium, Firefox или WebKit для тестирования. Кроме того, кроссплатформенный фреймворк быстро запускается в Windows, Linux и MacOS.
Playwright поддерживает Python, Golang, Java, JavaScript и C#.
Playwright работает быстрее, чем большинство фреймворков для тестирования, таких как Cypress.
Каковы недостатки Playwright?
В Playwright отсутствует поддержка Ruby и Java.
Вместо реальных устройств Playwright использует десктопные браузеры для эмуляции мобильных устройств.
Playwright параметры браузера
Параметры браузера и страничные методы управляют тестовой средой.
Headless: определяет, будет ли вам виден браузер во время тестирования. В качестве дефолтного значения установлено false. Вы можете изменить его на true, чтобы видеть браузер во время тестирования.
SlowMo: замедленное движение уменьшает скорость переключения между действиями на странице. Например, значение 500 означает задержку на 500 миллисекунд.
DevTools: Открывает Chrome Dev Tools при запуске целевой страницы. Обратите внимание, что эта опция работает только для Chromium.
await playwright.chromium.launch({ devtools: true })Playwright методы объекта страницы
Здесь представлены некоторые методы для управления страницей запуска.
Методы объекта |
Значение |
|
Посетите страницу в первый раз |
|
Этот метод обновляет страницу |
|
Этот метод предоставляет вам мини API для захвата элемента и манипулирования им с помощью JavaScript для DOM в среде Node.js. В качестве альтернативы вы можете использовать |
|
Чтобы сделать скриншот страницы. |
|
Он позволяет headless-браузеру ожидать действия в течение определенного времени, прежде чем выдать ошибку. |
|
Этот метод позволяет указать клавишу, которую нужно нажать. |
|
Он указывает странице отложить действие до тех пор, пока не будет загружен определенный селектор. |
|
Класс локатора захватывает элементы, используя несколько комбинаций селекторов. |
|
Этот метод позволяет вам указать тег, селектор которого вы хотите кликнуть. |
Веб-скрейпинг с помощью Playwright
В качестве небольшого учебного пособия, призванного помочь в обсуждении Playwright и Puppeteer, давайте воспользуемся Playwright чтобы соскрейпить названия товаров, цены и URL‑адреса изображений с Vue Storefront и сохраним результаты в CSV‑файл.
Начните с импорта модуля Playwright, а также модуля файловой системы (fs) для сохранения данных, которые вы соскрейпили в CSV‑файл.
import playwright from 'playwright' // web scraping
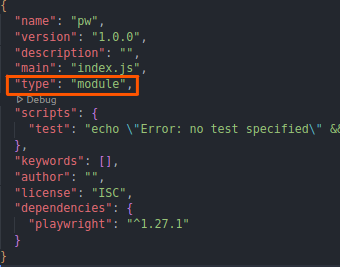
import fs from 'fs' // saving data to CSVНе забудьте указать тип модуля в файле package.json, иначе синтаксис import не будет работать.
Поскольку Playwright выполняется в асинхронной среде, а синтаксис async-await работает только в асинхронной функции, вы можете создать асинхронную функцию main и прописать в ней скрейпер.
const main = async () => {
// write some code
}
main()Следующим шагом будет запуск браузера и создание новой страницы — давайте запустим Chromium в режиме headed.
const browser = await playwright.chromium.launch({ headless: false })Вы открыли браузер, поздравляем, теперь мы уже на полпути к цели. Создайте объект страницы с помощью метода newPage() API браузера.
const page = await browser.newPage()Чтобы получить подробную информацию о товаре из Vue Storefront, давайте посетим страницу категории "Кухня" (kitchen) и отсортируем элементы по "Самым новым" (Newest).
await page.goto('https://demo.vuestorefront.io/c/kitchen?sort=NEWEST')В качестве альтернативы вы можете автоматизировать работу скрейпера, чтобы он определял расположение и кликал по элементам каждый раз, пока не попадет на целевую страницу.

Давайте создадим CSV-файл и напишем его заголовки, чтобы соскрейпить название, цену и URL-адреса изображений.
fs.writeFileSync('products.csv', 'title,price,imageUrl\n')Вы можете найти элемент div, содержащий товары, с помощью селектора классов CSS и сохранить полученный массив элементов в переменной products (товары).
const products = await page.$$('.products__grid > .sf-product-card.products__product-card')Используя цикл for-of, извлеките заголовок, цену и URL изображения из каждого дочернего элемента (продукта), как показано ниже:
for (const product of products) {
let title, price, imageUrl
// extracting the target portions into title, price and image urls, respectively
title = await page.evaluate(e => e.querySelector('.sf-product-card__title').textContent.trim(), product)
price = await page.evaluate(e => e.querySelector('.sf-price__regular').textContent.trim(), product)
imageUrl = await page.evaluate(e => e.querySelector('.sf-image.sf-image-loaded').src, product)
// for every loop, append the extracted data into the CSV file
fs.appendFile('products.csv', `${title},${price},${imageUrl}\n`, e => { if (e) console.log(e) })
}Закройте браузер и выполните файл скрипта.
await browser.close()И вот! Получилась идеально соскрейпенная с помощью Playwright веб-страница.

На случай, если вы запутаетесь, вот как выглядит полный код:
// in index.js
// Import the modules: playwright (web scraping) and fs (saving data to CSV)
import playwright from 'playwright'
import fs from 'fs'
// create asynchronous main function
const main = async () => {
// launch a visible chromium browser
const browser = await playwright.chromium.launch({ headless: false })
// create a new page object
const page = await browser.newPage()
// visit the target page
await page.goto('https://demo.vuestorefront.io/c/kitchen?sort=NEWEST')
// create a CSV file, in readiness to save the data we are about to scrape
fs.writeFileSync('products.csv', 'title,price,imageUrl\n')
// download an array of divs containing the target data
const products = await page.$$('.products__grid > .sf-product-card.products__product-card')
// loop through the array,
for (const product of products) {
let title, price, imageUrl
// dissecting the target portions into title, price and image urls, respectively
title = await page.evaluate(e => e.querySelector('.sf-product-card__title').textContent.trim(), product)
price = await page.evaluate(e => e.querySelector('.sf-price__regular').textContent.trim(), product)
imageUrl = await page.evaluate(e => e.querySelector('.sf-image.sf-image-loaded').src, product)
// for every loop, append the dissected data into the already created CSV file
fs.appendFile('products.csv', `${title},${price},${imageUrl}\n`, e => { if (e) console.log(e) })
}
// Close the (running headless) browser when the mission is accomplished
await browser.close()
}
// don't forget to run the main() function
main()Puppeteer
Puppeteer — это библиотека автоматизации для JavaScript (Node.js), и, в отличие от Playwright, Puppeteer загружает и использует Chromium по умолчанию. Она больше ориентирована на Chrome DevTools, что делает ее одной из лучших библиотек для веб‑скрейпинга.
В чем преимущества Puppeteer?
Puppeteer упрощает начало работы по автоматизации браузера. Она управляет Chrome с помощью нестандартного протокола DevTools.
Каковы недостатки Puppeteer?
Puppeteer поддерживает только JavaScript (Node.js).
Хотя ведется разработка поддержки Firefox, в настоящее время Puppeteer поддерживает только Chromium.
Опции браузера в Puppeteer
Большинство опций браузера из Playwright, такие как headless, slowMo и devtools, работают и в Puppeteer.
await puppeteer.launch({ headless: false, slowMo: 500, devtools: true })Методы объекта страницы в Puppeteer
Большинство методов объекта страницы Playwright работают и в Puppeteer. Вот некоторые из них.
Методы объекта |
Значение |
|
Посетите страницу в первый раз |
|
Перейти вперед |
|
Вернуться на предыдущую страницу |
|
Этот метод обновляет страницу |
|
Этот метод предоставляет вам мини API для захвата элемента и манипулирования им с помощью JavaScript для DOM в среде Node.js. В качестве альтернативы можно использовать |
|
Чтобы сделать скриншот страницы. |
|
Позволяет headless-браузеру ожидать действия в течение заданного времени, прежде чем выдать ошибку. |
|
Этот метод позволяет указать клавишу для нажатия. |
|
Указывает странице отложить действие до тех пор, пока не будет загружен определенный селектор. |
|
Для задержки последующих действий. |
|
Класс локатора захватывает элементы, используя несколько комбинаций селекторов. |
|
Этот метод позволяет вам указать тег, селектор которого вы хотите кликнуть. |
|
Для выбора опции в элементе select. |
Веб-скрейпинг с помощью Puppeteer
Чтобы соскрейпить веб‑страницу с помощью Puppeteer, импортируйте модуль Puppeteer для веб‑скрейпинга и модуль fs для сохранения соскрейпенных данных в CSV‑файл.
import puppeteer from 'puppeteer' // web scraping
import fs from 'fs' // saving scraped data Создайте асинхронную функцию для запуска headless-браузера.
const main = async () => {
// write some code
}
main()Теперь запустите headless-браузер и создайте новую страницу.
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()Используя метод goto(), посетите целевую страницу, прежде чем начать скрейпинг данных.
await page.goto('https://demo.vuestorefront.io/c/kitchen?sort=NEWEST')Затем создайте CSV-файл для хранения соскрейпенных данных.
fs.writeFileSync('products.csv', 'title,price,imageUrl\n')Найдите и просмотрите данные с веб-страницы
const products = await page.$$('.products__grid > .sf-product-card.products__product-card')Используя цикл for-of, извлеките название, цену и URL изображения товаров перед добавлением данных в CSV-файл.
for (const product of products) {
let title, price, imageUrl
// extracting the target portions into title, price and image urls, respectively
title = await page.evaluate( e => e.querySelector('.sf-product-card__title').textContent.trim(), product)
price = await page.evaluate( e => e.querySelector('.sf-price__regular').textContent.trim(), product)
imageUrl = await page.evaluate( e => e.querySelector('.sf-image.sf-image-loaded').src, product)
// for every loop, append the extracted data into the CSV file
fs.appendFile('products.csv', `${title},${price},${imageUrl}\n`, e => { if (e) console.log(e) })
}Наконец, закройте браузер и запустите скрипт.
await browser.close()Поздравляем, вы только что соскрейпили веб-страницу с помощью Puppeteer. ????.

Вот как выглядит полная версия кода:
// Import the modules: puppeteer (web scraping) and fs (saving data to CSV)
import puppeteer from 'puppeteer'
import fs from 'fs'
// create asynchronous main function
const main = async () => {
// launch a headed chromium browser
const browser = await puppeteer.launch({ headless: false })
// create a new page object
const page = await browser.newPage()
// visit the target page
await page.goto('https://demo.vuestorefront.io/c/kitchen?sort=NEWEST')
// create a CSV file, in readiness to save the data we are about to scrape
fs.writeFileSync('products.csv', 'title,price,imageUrl\n')
// download an array of divs containing the target data
const products = await page.$$('.products__grid > .sf-product-card.products__product-card')
// loop through the array,
for (const product of products) {
let title, price, imageUrl
// dissecting the target portions into title, price and image urls, respectively
title = await page.evaluate( e => e.querySelector('.sf-product-card__title').textContent.trim(), product)
price = await page.evaluate( e => e.querySelector('.sf-price__regular').textContent.trim(), product)
imageUrl = await page.evaluate( e => e.querySelector('.sf-image.sf-image-loaded').src, product)
// for every loop, append the dissected data into the already created CSV file
fs.appendFile('products.csv', `${title},${price},${imageUrl}\n`, e => { if (e) console.log(e) })
}
// Close the (running headless) browser when the mission is accomplished
await browser.close()
}
// don't forget to run the main() function
main()Playwright или Puppeteer: что быстрее?
Сравнение производительности Puppeteer и Playwright может оказаться сложной задачей, но попробуем выяснить, какая библиотека окажется на первом месте.
Давайте создадим третий файл сценария под названием performance.js и запустим в нем Playwright и Puppeteer, засекая время, которое требуется каждой функции для скрейпинга данных Vue Storefront.
// in performance.js
const playwrightPerformance = async () => {
// START THE TIMER
console.time('Playwright')
// Playwright scraping code
// END THE TIMER
console.timeEnd('Playwright')
}
const puppeteerPerformance = async () => {
// START THE TIMER
console.time('Puppeteer')
// Puppeteer scraping code
// END THE TIMER
console.timeEnd('Puppeteer')
}
playwrightPerformance()
puppeteerPerformance()Мы вставим код скрейпинга Playwright и Puppeteer в соответствующие функции, настроим просмотр в режиме headless, а затем прогоним файл performance.js пять раз, чтобы определить среднее значение рантайма.
Вот средняя продолжительность работы для каждой библиотеки:
Playwright ➡️ (7,580 + 7,372 + 6,639 + 7,411 + 7,390) = (36,392 / 5) = 7,2784 с.
Puppeteer ➡️ (6.656 + 6.653 + 6.856 + 6.592 + 6.839) = (33.596 / 5) = 6.7192s
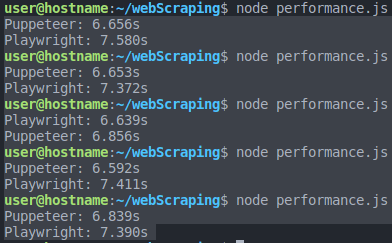
И по итогу Puppeteer побеждает в споре с Playwright по скорости работы!
Стоит отметить, что данные результаты основаны на нашем собственном тесте. Если вы хотите провести свой, воспользуйтесь мини-руководством, приведенным выше.
Лучше ли Playwright, чем Puppeteer?
Невозможно дать однозначный ответ на вопрос, что лучше: Puppeteer или Playwright, поскольку это зависит от множества факторов, таких как долгосрочная поддержка библиотек, поддержка кросс-браузерности и ваши конкретные потребности относительно автоматизации браузера.
Вот некоторые из наиболее значимых фич Playwright и Puppeteer:
Функциональность |
Playwright |
Puppeteer |
Поддерживаемые языки |
Python, Java, JavaScript и C# |
JavaScript |
Поддерживаемые браузеры |
Chromium, Firefox и WebKit |
Chromium |
Скорость |
быстрая |
быстрее |
Распространенная проблема, с которой сталкиваются при веб‑скрейпинге, заключается в том, что некоторые сайты могут детектировать ботов и блокируют ваш headless‑браузинг, особенно если вы часто кликаете на кнопки и отправляете множественный трафик за короткое время. Одним из решений является введение таймеров перед последующими действиями.
Например, вы можете запрограммировать Puppeteer на имитацию пользователя (человека), выжидая 0,1 с перед кликом на кнопку после ввода данных в форму для авторизации. Однако недостатком множественных таймеров является то, что они замедляют браузинг, и большинство веб‑сайтов даже могут их засечь (детектировать).
API ZenRows отлично решает эту проблему, он способен справиться со всеми анти‑ботами и обходом CAPTCHA вместо вас, и это лишь малая часть того, на что он способен. Воспользуйтесь бесплатной пробной версией, чтобы узнать, почему это святой Грааль для веб‑скрейпинга.
Перевод статьи подготовлен в преддверии старта специализации QA Automation Engineer. Хочу порекомендовать вам два бесплатных урока курса, на первом из которых поговорим о той документации, которую составляет тестировщик, а именно: дефекты, чек‑листы, тест‑кейсы. А на втором занятии обсудим различные виды тестирования. Научимся отличать черные коробки от белых, регрессионное тестирование от дымового. В результате вы научитесь структурировано подготавливать тест‑кейсы и составлять чек‑листы. Занятие будет интересно всем, кто хочет стать тестировщиком. Зарегистрироваться на каждый из уроков можно по ссылкам ниже.
Комментарии (2)

kozikoff
00.00.0000 00:00У вас в недостатках написано, что playwright не поддерживает джаву. А в преимуществах, что поддерживает. Подозрительно…
iBljad
Понятно, что перевод, но всё же (правильный ответ: поддерживает)