
Когда организации переходят в облако, их системы тоже начинают стремиться к распределённым архитектурам. Один из самых распространённых примеров этого — использование микросервисов. Однако это также создаёт новые сложности с точки зрения наблюдаемости.
Необходимо подбирать подходящие инструменты для мониторинга, отслеживания и трассировки этих систем при помощи анализа выходных результатов посредством метрик, логов и трассировок. Это позволяет командам разработчиков быстро выявлять первопричины проблем, устранять их и оптимизировать производительность приложений, ускоряя выпуск кода.
В этой статье мы рассмотрим возможности, ограничения и важные особенности одиннадцати популярных инструментов наблюдаемости, что позволит вам выбрать наиболее подходящий для вашего проекта.
Helios
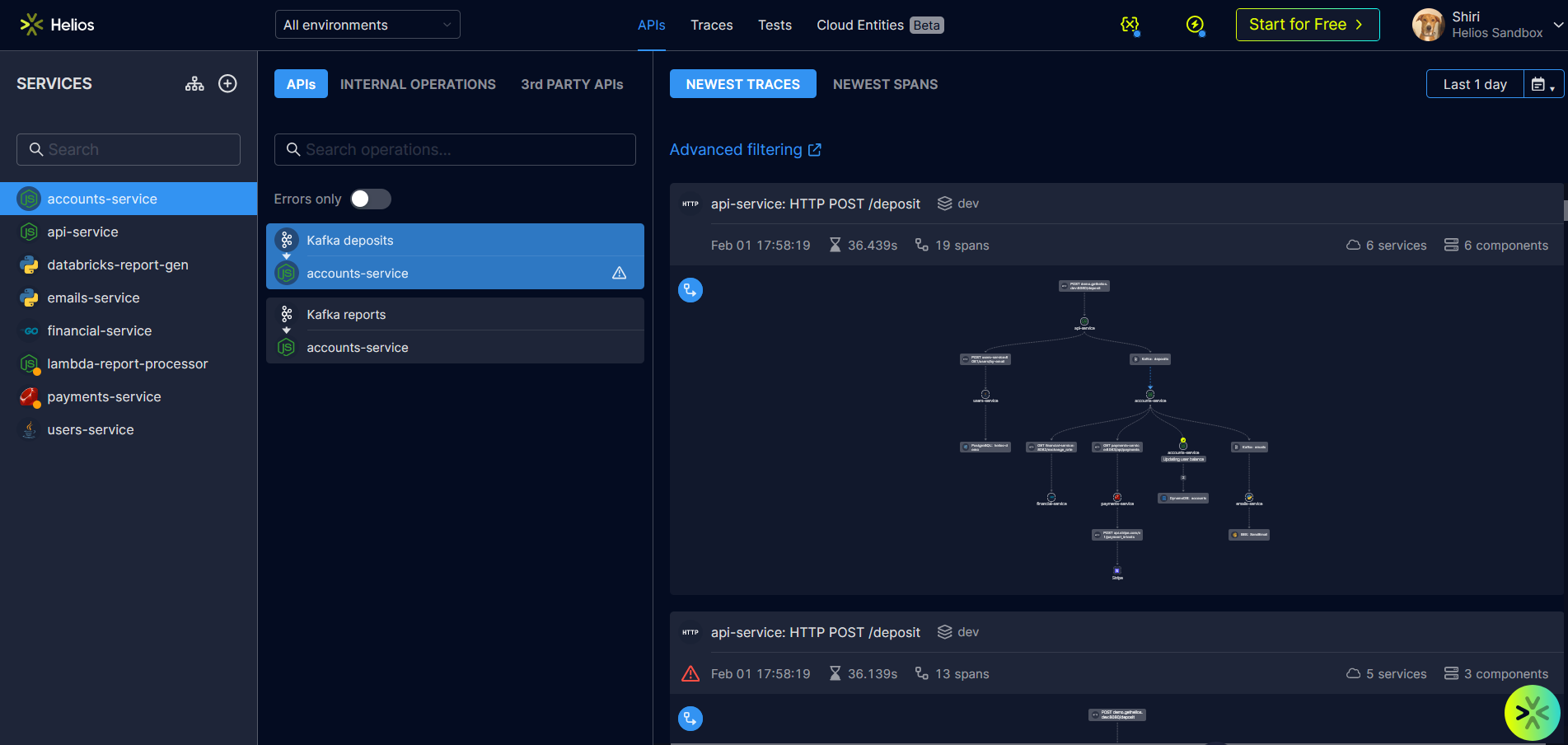
Helios — это решение по обеспечению наблюдаемости для разработчиков, предоставляющее информацию по всему потоку приложений. Оно включает в себя фреймворк распространения контекста OpenTelemetry и обеспечивает наблюдение за микросервисами, serverless-функциями, базами данных и сторонними API. Можно протестировать песочницу продукта или использовать его бесплатно, зарегистрировавшись здесь.
▍ Основные возможности
- Обеспечение полного контроля: Helios предоставляет информацию о распределённой трассировке в полном контексте, показывает, как передаются данные через всё приложение в любом окружении.
- Визуализация: позволяет пользователям собирать и визуализировать данные трассировок из множественных источников данных, чтобы исследовать и устранять потенциальные проблемы.
- Многоязыковая поддержка: поддерживает множество языков и фреймворков, в том числе Python, JavaScript, Node.js, Java, Ruby, .NET, Go, C++ и Collector.
- Обмен и многократное использование: вы с лёгкостью можете сотрудничать с участниками команды, обмениваясь через Helios трассировками, тестами и триггерами. Кроме того, Helios позволяет многократно использовать запросы и полезные нагрузки между участниками команды.
- Автоматическая генерация тестов: автоматически генерирует тесты на основании данных трассировок.
- Простота интеграций: интегрируется в существующую экосистему, включая логи, тесты, мониторинг ошибок и многое другое.
- Воссоздание процессов: Helios всего за несколько кликов позволяет в точности воссоздавать рабочие процессы, в том числе HTTP-запросы, сообщения Kafka и RabbitMQ, а также вызовы Lambda.
▍ Популярные способы использования
- Распределённая трассировка
- Интеграция трассировок в многоязыковое приложение
- Наблюдаемость serverless-приложения
- Устранение неполадок в тестах
- Информация о вызовах API
- Анализ и выявление узких мест
Prometheus

Prometheus — это опенсорсный инструмент, широко используемый для обеспечения наблюдаемости в нативных облачных окружениях. Он может собирать и хранить данные временных последовательностей и предоставляет инструменты визуализации для анализа собранных данных.
▍ Основные возможности
- Сбор данных: он может скрейпить метрики из различных источников, в том числе из приложений, сервисов и систем. Также он «из коробки» поддерживает множество форматов данных, в том числе логи, трассировки и метрики.
- Хранилище данных: он сохраняет собранные данные в базе данных временных последовательностей, позволяя эффективно запрашивать и агрегировать данные с течением времени.
- Система алертов: инструмент включает в себя встроенную систему алертов, которая может запускать алерты на основании запросов.
- Исследование сервисов: он может автоматически распознавать и скрейпить метрики сервисов, работающих в различных окружениях, например, Kubernetes и в других системах управления контейнерами.
- Интеграция с Grafana: инструмент имеет гибкую интеграцию с Grafana, позволяющей создавать дэшборды для отображения и анализа метрик Prometheus.
▍ Ограничения
- Ограниченные возможности анализа первопричин: инструмент в первую очередь предназначен для мониторинга и алертов. Поэтому он не предоставляет встроенных возможностей аналитики первопричин проблем.
- Масштабирование: хотя инструмент может обрабатывать множество метрик, это может привести к большой трате ресурсов, поскольку Prometheus хранит все данные в памяти.
- Моделирование данных: содержит модель данных на основе пар «ключ-значение» и не поддерживает вложенных полей и join.
▍ Популярные способы применения
- Сбор и хранение метрик
- Система алертов
- Исследование сервисов
Grafana
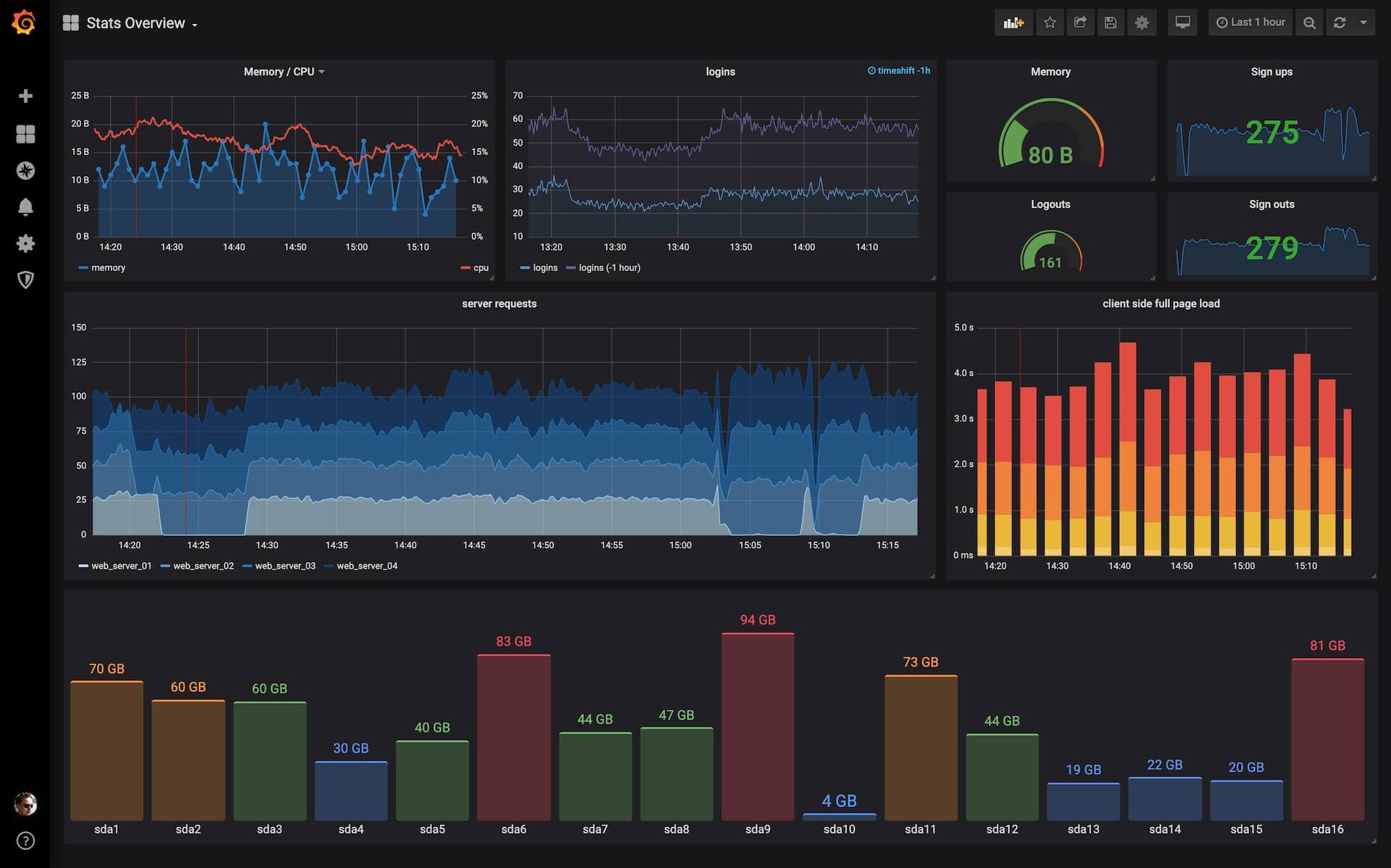
Grafana — это опенсорсный инструмент, в первую очередь используемый для визуализации и мониторинга данных. Он позволяет с лёгкостью создавать интерактивные дэшборды для визуализации и анализа данных из различных источников.
▍ Основные возможности
- Визуализация данных: создаёт настраиваемые и интерактивные дэшборды для визуализации метрик и логов из различных источников данных.
- Система алертов: позволяет настраивать алерты на основании состония метрик для информирования о потенциальных проблемах.
- Выявление аномалий: позволяет настроить выявление аномалий для автоматического определения и отправки алертов в случае аномального поведения в метриках.
- Анализ первопричин: позволяет углубиться в метрики для анализа первопричин, предоставляя подробную информацию с историческим контекстом.
▍ Ограничения
- Хранение данных: архитектура инструмента не поддерживает долговременное хранение и для сохранения метрик и логов требует дополнительных инструментов наподобие Prometheus или Elasticsearch.
- Моделирование данных: Grafana не предоставляет расширенных возможностей моделирования данных. То есть она не позволяет моделировать конкретные типы данных и выполнять сложные запросы.
- Агрегирование данных: Grafana не содержит встроенных функций агрегирования.
▍ Популярные способы применения
- Визуализация метрик
- Система алертов
- Выявление аномалий
Elasticsearch, Logstash и Kibana (ELK)
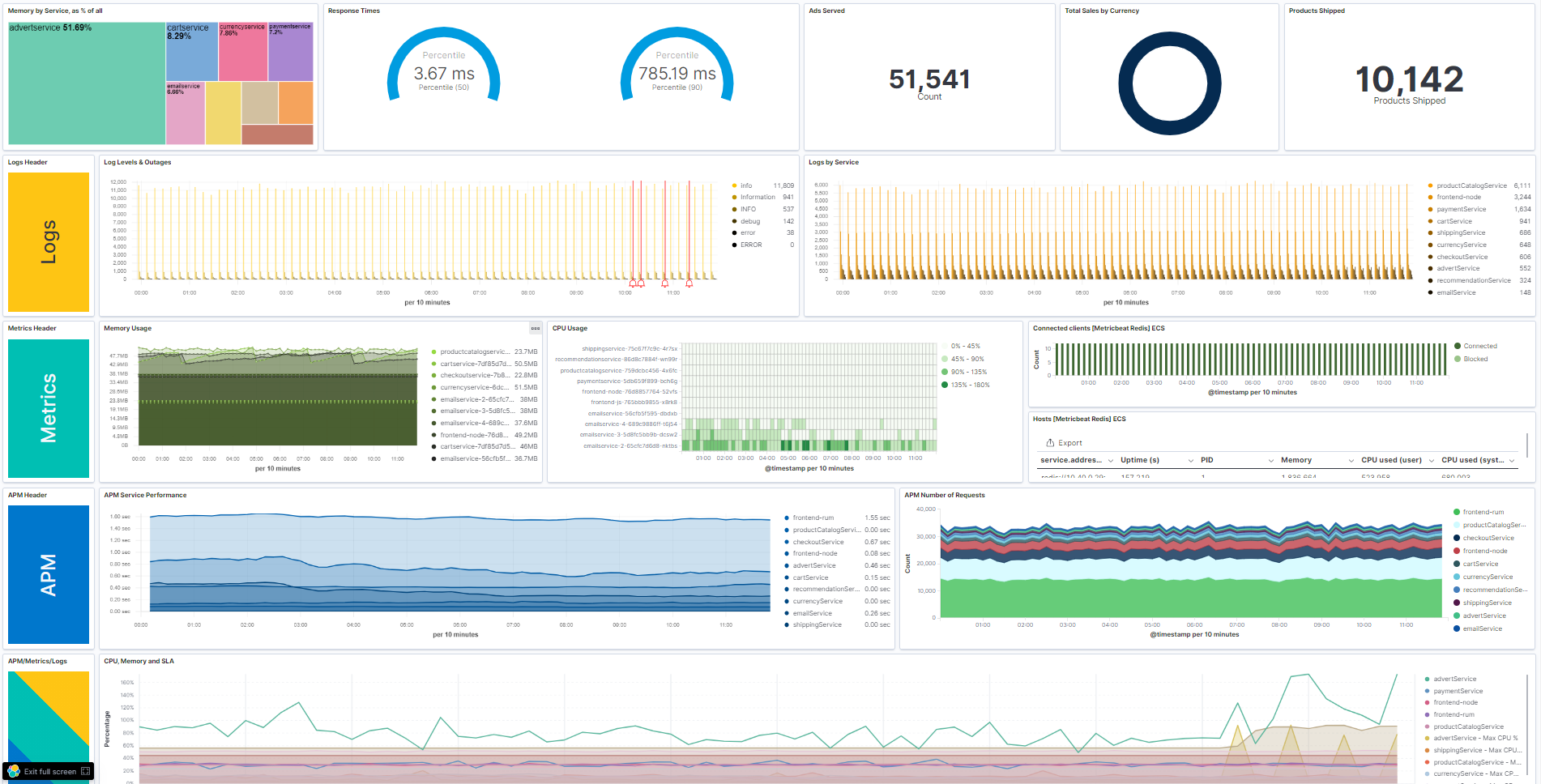
Стек ELK — это популярное опенсорсное решение, помогающее управлять логами и анализировать данные. Оно состоит из трёх компонентов: Elasticsearch, Logstash и Kibana.
Elasticsearch — это движок распределённого поиска и аналитики, способный обрабатывать большие объёмы структурированных и неструктурированных данных; он позволяет хранить и индексировать большие массивы данных, а также выполнять поиск по ним.
Logstash — это конвейер сбора и обработки данных, позволяющий собирать, обрабатывать и обогащать данные из множества источников, например, файлов логов.
Kibana — это инструмент визуализации и исследования данных, позволяющий создавать интерактивные дэшборды и визуализации на основе данных, находящихся в Elasticsearch.
▍ Основные возможности
- Управление логами: ELK позволяет собирать, обрабатывать, хранить и анализировать данные логов и метрики из множества источников, предоставляя централизованную консоль для поиска по логам.
- Поиск и анализ: позволяет выполнять поиск и анализ релевантных данных логов, что критически важно для выявления и устранения первопричин проблем.
- Визуализация данных: Kibana позволяет создавать настраиваемые дэшборды, которые способны визуализировать данные логов и метрики из множества источников данных.
- Выявление аномалий: Kibana позволяет создавать алерты для аномальной активности в данных логов.
- Анализ первопричин: стек ELK позволяет глубоко изучать данные логов, чтобы лучше понять первопричины, предоставляя подробные логи и исторический контекст.
▍ Ограничения
- Трассировка: ELK нативно не поддерживает распределённую трассировку. Поэтому может понадобиться применение дополнительных инструментов наподобие Jaeger.
- Мониторинг в реальном времени: архитектура ELK позволяет ему качественно выполнять задачи платформы управления логами и анализа данных. Однако в отчётности логов присутствует незначительная задержка, и пользователям приходится ждать.
- Сложная настройка и поддержка: для платформы требуется сложный процесс настройки и поддержки. Кроме того, для управления большими объёмами данных и множественными источниками данных требуются специфические знания.
▍ Популярные способы применения
- Управление логами
- Визуализация данных
- Комплаенс и безопасность
InfluxDB и Telegraf
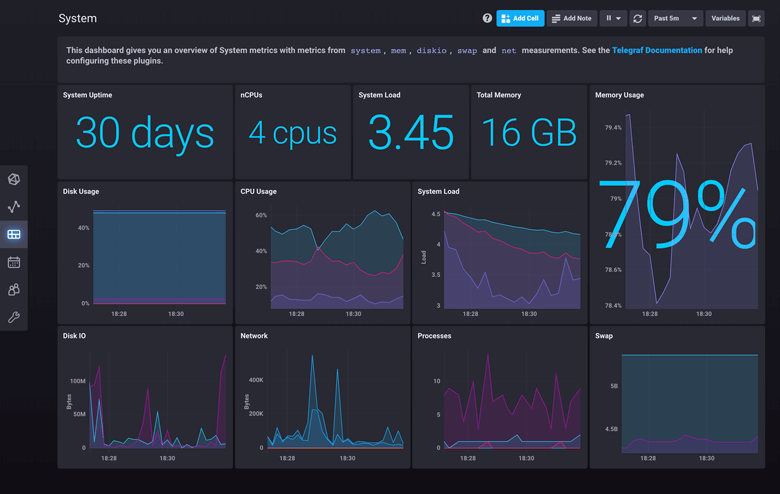
InfluxDB и Telegraf — это опенсорсные инструменты, популярные благодаря своим возможностям по хранению и мониторингу данных временных последовательностей.
InfluxDB — это база данных временных последовательностей, хранящая большие объёмы данных временных последовательностей и выполняющая запросы к ним при помощи своего языка запросов, напоминающего SQL.
Telegraf — это хорошо известный агент сбора данных, способный собирать и отправлять метрики широкому выбору получателей, например, InfluxDB. Также он поддерживает многие источники данных.
▍ Основные возможности
Комбинация из InfluxDB и Telegraf предоставляет множество возможностей, повышающих наблюдаемость приложений.
- Сбор и хранение метрик: Telegraf позволяет собирать метрики из множества источников и отправлять их в InfluxDB для хранения и анализа.
- Визуализация данных: InfluxDB можно интегрировать со сторонними инструментами визуализации наподобие Grafana для создания интерактивных дэшбордов.
- Масштабируемость: архитектура InfluxDB позволяет обрабатывать большие объёмы данных временных последовательностей и выполнять горизонтальное масштабирование.
- Поддержка множества источников данных: Telegraf поддерживает более двухсот плагинов ввода для сбора метрик.
▍ Ограничения
- Ограниченные возможности алертинга: в обоих инструментах отсутствуют возможности алертинга и для его подключения необходима интеграция сторонних сервисов.
- Ограниченный анализ первопроичин: в этих инструментах отсутствуют нативные возможности анализа первопричин и необходима интеграция сторонних сервисов.
▍ Популярные способы применения
- Сбор и хранение метрик
- Мониторинг
Datadog
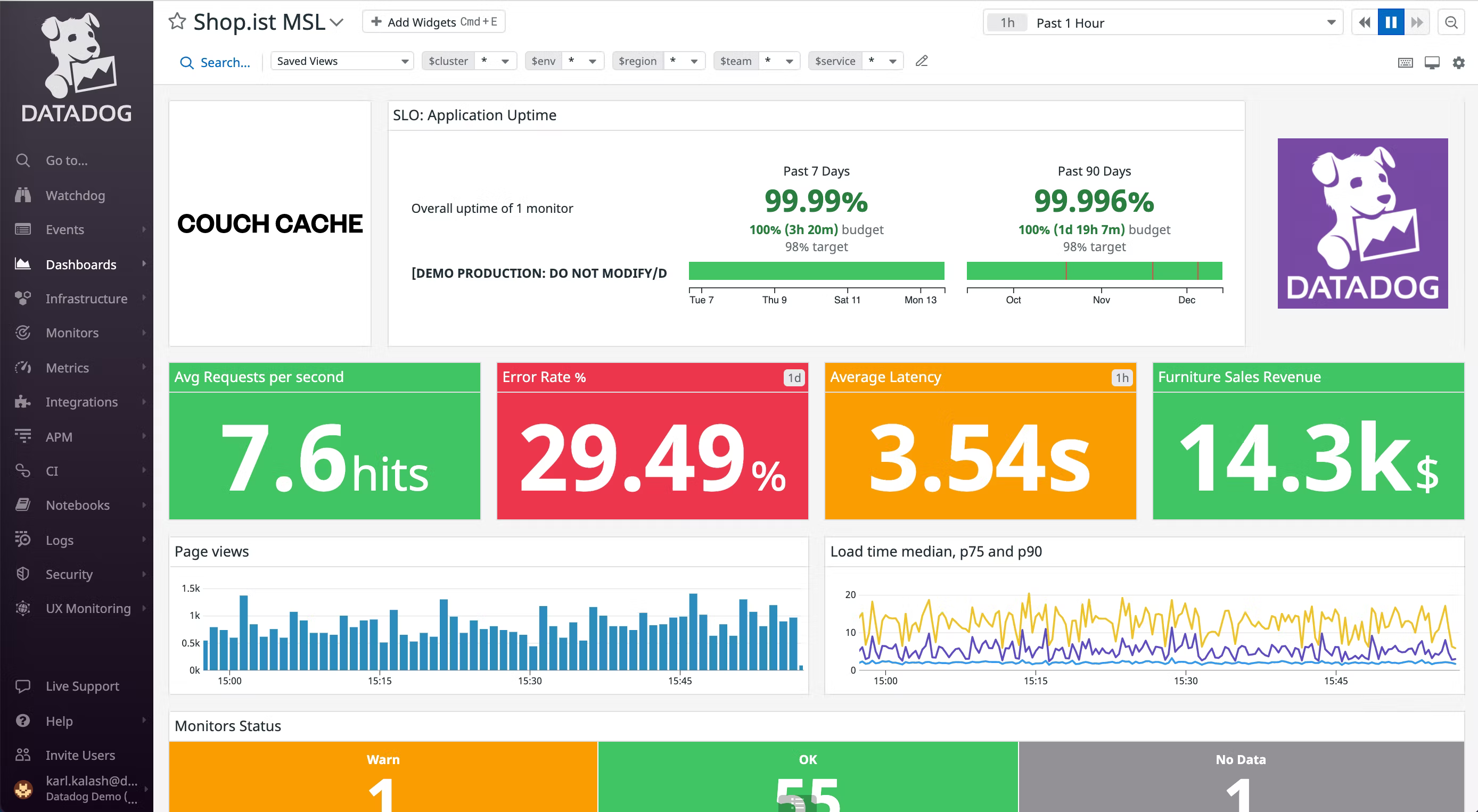
Datadog — это популярная облачная платформа для мониторинга и аналитики. Она широко используется для получения информации о здоровье и производительности распределённых систем с целью заблаговременного устранения проблем.
▍ Основные возможности
- Многооблачная поддержка: пользователи могут выполнять мониторинг приложений, работающих на облачных платформах нескольких поставщиков, например, AWS, Azure, GCP и так далее.
- Карты сервисов: позволяют выполнять визуализацию зависимостей сервисов, местоположений, сервисов и контейнеров.
- Аналитика трассировок: пользователи могут анализировать трассировки, предоставляя подробную информацию о производительности приложений.
- Анализ первопричин: позволяет глубоко изучать метрики и трассировки, чтобы понять первопричину проблем, предоставляя подробную информацию с историческим контекстом.
- Выявление аномалий: может настраивать систему выявления аномалий, которая автоматически выявляет аномальное поведение в метриках и создаёт алерты о нём.
▍ Ограничения
- Затраты: Datadog — это облачный платный сервис, стоимость которого увеличивается при развёртывании крупномасштабных систем.
- Ограниченная поддержка потребления, хранения и индексации логов: Datadog по умолчанию не предоставляет поддержку анализа логов. Необходимо отдельно приобретать поддержку потребления и индексации логов. Поэтому большинство организаций принимает решение хранить ограниченное количество логов, что может вызвать неудобства при устранении проблем, поскольку отсутствует доступ к полной истории проблемы.
- Нехватка контроля за хранением данных: Datadog хранит данные на собственных серверах и не позволяет пользователям хранить данные локально или в дата-центрах компании.
▍ Популярные способы применения
- Конвейеры наблюдаемости
- Распределённая трассировка
- Мониторинг контейнеров
New Relic

New Relic — это облачная платформа мониторинга и аналитики, позволяющая выполнять мониторинг приложений и систем в распределённом окружении. Она использует сервис «New Relic Edge» для распределённой трассировки и способна выполнять наблюдение за 100% трассировок приложения.
▍ Основные возможности
- Мониторинг производительности приложений: предоставляет комплексное решение APM для мониторинга производительности приложений и устранения проблем.
- Многооблачная поддержка: поддерживает мониторинг приложений на облачных платформах нескольких поставщиков, например, AWS, Azure, GCP и так далее.
- Аналитика трассировок: позволяет анализировать трассировки, предоставляя подробную информацию о производительности системы и приложений.
- Анализ первопричин: позволяет глубоко изучать матрики и трассировки для анализа первопричин проблем.
- Управление логами: собирает, обрабатывает и анализирует данные логов из различных источников, обеспечивая всеобъемлющую картину логов.
▍ Ограничения
- Ограниченная опенсорсная интеграция: New Relic — это платформа с закрытыми исходниками, поэтому её интеграция с опенсорсными инструментами может быть ограниченной.
- Затраты: New Relic может быть более дорогим по сравнению с другими решениями при работе с крупномасштабными системами.
▍ Популярные способы применения
- Мониторинг производительности приложений
- Многооблачный мониторинг
- Аналитика трассировок
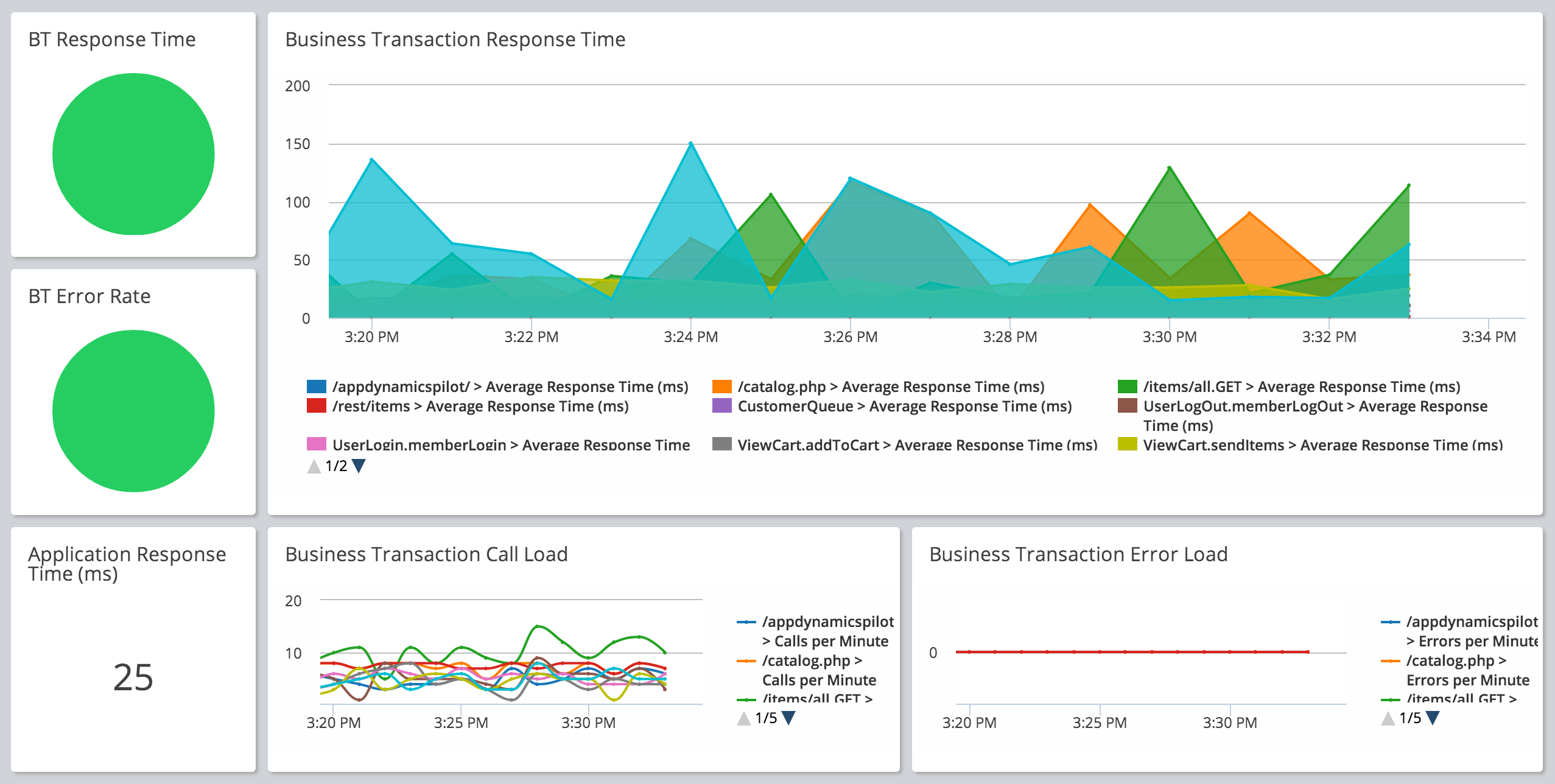
AppDynamics
AppDynamics — это платформа мониторинга и аналитики, позволяющая отслеживать и визуализировать каждый компонент приложения, а также управлять ими. Кроме того, она позволяет выполнять анализ первопричин для выявления внутренних проблем, которые могут влиять на производительность приложения.
▍ Основные возможности
- Сбор данных: пользователи могут собирать метрики и трассировки из множества источников: хостов, контейнеров, облачных сервисов и приложений.
- Выявление аномалий: позволяет настраивать систему выявления аномалий, которая выявляет аномальное поведение и сообщает о нём при помощи алертов.
-
Аналитика трассировок: пользователи могут анализировать трассировки и получать подробную информацию о производительности.
Мониторинг производительности приложений: предоставляет комплексное решение APM, позволяющее выполнять мониторинг и устранение проблем производительности приложения. - Ограниченные возможности настройки: по сравнению с другими инструментами, опции настройки не очень гибки, потому что пользователи не могут настраивать решение самостоятельно.
▍ Популярные способы применения
- Мониторинг производительности приложений
- Многооблачный мониторинг
- Управление бизнес-транзакциями
Выбор лучшего инструмента наблюдаемости
Наблюдаемость — неотъемлемая часть разработки и эксплуатации современного ПО. Она помогает компаниям выполнять мониторинг здоровья и производительности систем и быстро решать проблемы ещё до того, как они станут критичными.
В этой статье мы рассказали об одиннадцати лучших инструментах наблюдаемости, о которых должны знать разработчики при работе с распределёнными системами. Как видите, каждый инструмент имеет свои сильные стороны и ограничения. Поэтому чтобы найти подходящий для вас инструмент, следует сравнить его с требованиями вашей системы. Выбор наилучшего инструмента наблюдаемости для вашей организации зависит от конкретных потребностей, таких, как окружение, технологический стек, опыт разработчиков, профили пользователей, требования к мониторингу и устранению проблем, а также рабочие процессы.
Надеюсь, эта статья была для вас полезной.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

Комментарии (4)


hardim
00.00.0000 00:00-1Хотел было написать "А как же Графана ?", а нннет, воткнули ее родимую :) Графана и всякие разные дллки на питоне дают безраничную власть в наблюдаемости :) сарказм :)
Забыли про NetBox. Система тегирования с хранением необходимых инвентарных данных позволяет выстроить какие угодно связи, будь то неймспесы, поды, кластера, сервера, бд,.. все что угодно + визулизвтор. Автор что скажешь ?

chemtech
А как же tempo, loki, victoriametrics?