

Как создать свою собственную нейронную сеть с нуля на Python
Мотивация: в рамках моего личного пути к лучшему пониманию глубокого обучения я решил создать нейронную сеть с нуля без библиотеки глубокого обучения, такой как TensorFlow. Я считаю, что понимание внутренней работы нейронной сети важно для любого начинающего специалиста по данным. Эта статья содержит то, что я узнал, и, надеюсь, она будет полезна и вам!
Что такое нейронная сеть?
В большинстве вводных текстов по нейронным сетям при их описании используются аналогии с мозгом. Не углубляясь в аналогии с мозгом, я считаю, что проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат.
Нейронные сети состоят из следующих компонентов:
Входной слой, x
Произвольное количество скрытых слоев
Выходной слой, y
Набор весов и смещений между каждым слоем, W и b
Выбор функции активации для каждого скрытого слоя, σ. В этом уроке мы будем использовать функцию активации
На приведенной ниже диаграмме показана архитектура двухуровневой нейронной сети (обратите внимание, что входной слой обычно исключается при подсчете количества слоев в нейронной сети).

Создать класс нейронной сети в Python очень просто.
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(y.shape)Обучение нейронной сети.
Выход y простой двухслойной нейронной сети:

Вы могли заметить, что в приведенном выше уравнении веса W и смещения b являются единственными переменными, влияющими на выход y.
Естественно, правильные значения весов и смещений определяют силу прогнозов. Процесс точной настройки весов и смещений на основе входных данных известен как обучение нейронной сети.
Каждая итерация процесса обучения состоит из следующих шагов:
Расчет прогнозируемого выхода y, известный как прямая связь.
Обновление весов и смещений, известное как обратное распространение.
Последовательный график ниже иллюстрирует процесс.

Прямая связь
Как мы видели на последовательном графике выше, упреждающая связь — это просто простое исчисление, и для базовой двухслойной нейронной сети выходные данные нейронной сети таковы:

Давайте добавим функцию прямой связи в наш код Python, чтобы сделать именно это. Обратите внимание, что для простоты мы приняли смещения равными 0.
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))Однако нам по-прежнему нужен способ оценить «хорошесть» наших прогнозов (т. е. насколько далеки наши прогнозы)? Функция потерь позволяет нам сделать именно это.
Функция потери
Есть много доступных функций потерь, и природа нашей проблемы должна диктовать наш выбор функции потерь. В этом уроке мы будем использовать простую ошибку суммы квадратов в качестве функции потерь.

То есть ошибка суммы квадратов представляет собой просто сумму разницы между каждым предсказанным значением и фактическим значением. Разница возводится в квадрат, так что мы измеряем абсолютное значение разницы.
Наша цель в обучении — найти наилучший набор весов и смещений, который минимизирует функцию потерь.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространить ошибку обратно и обновить наши веса и смещения.
Чтобы узнать подходящую величину для корректировки весов и смещений, нам нужно знать производную функции потерь по отношению к весам и смещениям.
Вспомним из исчисления, что производная функции — это просто наклон функции.
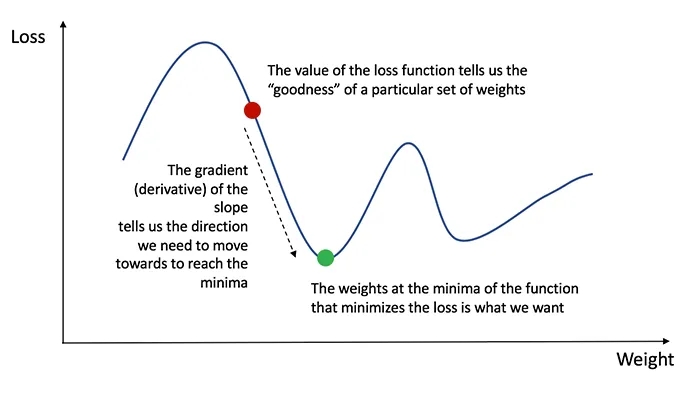
Если у нас есть производная, мы можем просто обновить веса и смещения, увеличивая/уменьшая ее (см. диаграмму выше).
Это известно как градиентный спуск. Однако мы не можем напрямую вычислить производную функции потерь по весам и смещениям, потому что уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно цепное правило, чтобы помочь нам вычислить его.
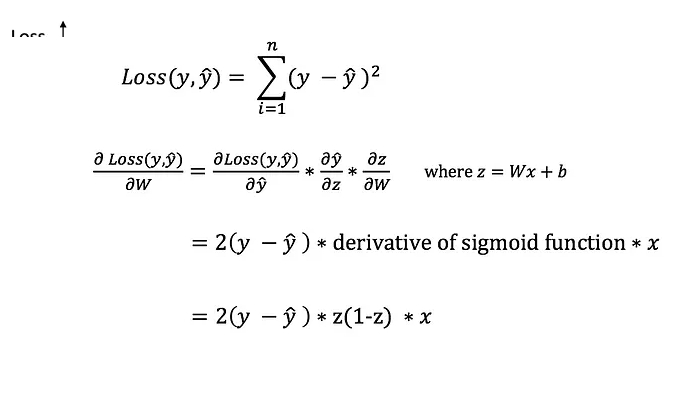
Фу! Это было некрасиво, но позволяет нам получить то, что нам нужно — производную (наклон) функции потерь по весам, чтобы мы могли соответствующим образом скорректировать веса. Теперь, когда у нас это есть, давайте добавим функцию обратного распространения в наш код Python.
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
def backprop(self):
# application of the chain rule to find derivative of the loss function with respect to weights2 and weights1
d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) * sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1)))
# update the weights with the derivative (slope) of the loss function
self.weights1 += d_weights1
self.weights2 += d_weights2Собираем все вместе
Теперь, когда у нас есть полный код Python для прямого и обратного распространения, давайте применим нашу нейронную сеть на примере и посмотрим, насколько хорошо она работает.
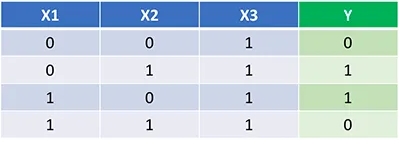
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции. Обратите внимание, что для нас не совсем тривиально определить веса только путем проверки.
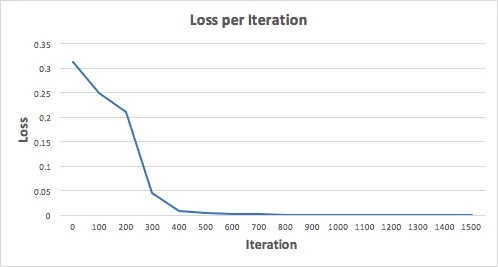
Давайте обучим нейронную сеть на 1500 итераций и посмотрим, что получится. Глядя на приведенный ниже график потерь на итерацию, мы ясно видим, что потери монотонно уменьшаются к минимуму. Это согласуется с алгоритмом градиентного спуска, который мы обсуждали ранее.
Давайте посмотрим на окончательный прогноз (выход) нейронной сети после 1500 итераций.
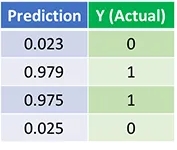
Мы сделали это! Наш алгоритм прямого и обратного распространения успешно обучил нейронную сеть, и прогнозы сошлись на истинных значениях.
Обратите внимание, что есть небольшая разница между прогнозами и фактическими значениями. Это желательно, поскольку предотвращает переоснащение и позволяет нейронной сети лучше обобщать невидимые данные.
Что дальше?
К счастью для нас, наше путешествие не закончено. Нам еще многое предстоит узнать о нейронных сетях и глубоком обучении.
Например:
Какую еще функцию активации мы можем использовать, кроме сигмовидной?
Использование скорости обучения при обучении нейронной сети.
Использование сверток для задач классификации изображений.
Последние мысли
Я определенно многому научился, написав свою собственную нейронную сеть с нуля.
Хотя библиотеки глубокого обучения, такие как TensorFlow и Keras, упрощают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я считаю, что начинающим специалистам по данным полезно получить более глубокое понимание нейронных сетей. Это упражнение было отличным вложением моего времени, и я надеюсь, что оно будет полезным и для вас!
Комментарии (16)

tenzink
00.00.0000 00:00+1Немного странно использовать квадратичную функцию потерь в связке с sigmoid активацией на выходном слое. Тут уж либо мы решаем задачу классификации, либо регрессии
задача классификации: sigmoid activation + cross-entropy loss
или задача регрессии: linear (no) activation + quadratic loss

ShashkovS
00.00.0000 00:00+13У меня вот есть такая интерактивная иллюстрация работы ма-а-а-аленькой сеточки, которая играет в змейку: https://shashkovs.ru/ai/

ReLU + чем толще линия — тем больше слагаемое 
user18383
00.00.0000 00:00Очень интересно что такое казалось бы сложное задание, нейросеть может выполнить на таком маленьком количестве нейронов.

IvanPetrof
00.00.0000 00:00Помнится как-то давно уже, как раз, во времена подобных игр, когда все спорили - полезны комп-игры или нет, защитники игр говорили, что они (игры) развивают мозг..

Hvorovk
00.00.0000 00:00Ну игры даже сегодняшние развивают мозг, различные механики к которым нужно найти подход, различные логические задачи в играх все так же встреачаются опять же. Да условный cookie clicker мало что разовьет, как и змейка, но все же это уже лучше чем смотреть в стену)
ShashkovS
00.00.0000 00:00Там есть вариант, когда оно играет в змейку вообще без промежуточного слоя: 4 входных и 3 выходных, то есть всё управление — это 15 весов.
IvanPetrof
00.00.0000 00:00А что за информация на входе "яблоко". То, что это угол в радианах, я понял, но от чего он отсчитывается? Просто если змейка приближается к яблоку строго справа, то он равен 3,14, а если с любой другой стороны, то ноль.
ShashkovS
00.00.0000 00:00Для змейки всегда есть положение «вперёд». Во входе «яблоко» угол от положения «вперёд» в радианах.
ShashkovS
00.00.0000 00:00А, ну и конкретно про 3.14. Для вычисления угла используется atan2, а для приближения справа
Math.atan2(0, -1) = 3.1415...IvanPetrof
00.00.0000 00:00Т.е. Если змейка приближается к яблоку, находясь с ним на одной линии, то угол должен быть 0, а если удаляется, то 3.14?
Это было бы логично, но у вас угол равен 0, если змейка приближается сверху, слева, Снизу. И почему-то равен 3,14, когда змейка приближается справа. Во всех случаях - она приближается точно по линии яблока
Змейка ползёт справа налево

Ползёт слева направо

видимо из-за этого змейка весьма однобоко ест яблоки.
На нижней картинке она ползла вниз и поровнявшись с яблоком повернула налево (чтобы ползти вправо по картинке). Но дальше она не поползёт и на следующем шаге повернёт направо (максимум у выхода "направо"), обползёт яблоко по стенке и съест его зайдя на него с правой стороны картинки.
P.s.
Возможно, такая ассиметрия углов сделана намеренно, чтобы заставлять змейку ползать по максимальному кругу, дабы не напарываться на свой хвост. Ведь хвоста-то она не видит и не может по месту сообразить с какой стороны лучше себя обползать.
ShashkovS
00.00.0000 00:00Не, асимметрия ненамеренная. Угол вычисляется через atan2, которая так работает... Но вообще действительно есть гипотеза, что это портит обучаемость. Нужно бы как-то это поправить и попробовать переобучить заново.



gybson_63
00.00.0000 00:00+1Порекомендую вот эту статью
Let’s code a Neural Network in plain NumPy | by Piotr Skalski | Towards Data Science

Glomberg
00.00.0000 00:00+2Покажите как используется ваш класс в итоге и что является результатом работы. Покажите код, который делает это "Давайте обучим нейронную сеть на 1500 итерации". Спасибо.

matthew_shtyasek
00.00.0000 00:00А почему именно сигмоид? Почему не relu, например?
Просто насколько мне известно, от сигмоида отказываются из-за того, что при обучении он любит уходить намертво в 1 или 0. Ну а если не уходит, то по сути мы получаем ± градиент как при relu
Revertis
А есть то же самое, но для Раста?
Keirichs
Я вообще проходимец, но как заметил это реализация формулы автора тупо на питоне,
чтобы реализовать такое на расте, полагаю, надо уметь пользоваться математическими функциями в этом языке.