
???? Привет! Возможно, вы что-то знаете о Python, если вы здесь. Особенно о веб-фреймворках Python. Например, есть одна вещь, которая меня очень раздражает при использовании Django: наложение слоя структуры проекта.
Вы можете спросить, почему это проблема, верно? Потому что вы просто следуете официальной документации, а затем у вас просто есть код, который понимает каждый, кто читает эту документацию.
Но как только вы начнете писать «лучшие» приложения, вы освоите другие шаблоны проектирования мирового класса, такие как DDD и его многоуровневая архитектура, и через некоторое время вы еще больше усложните свою систему с помощью CQRS. Лично мне стало труднее поддерживать базу кода, следуя всем этим принципам, когда фреймворк является ЦЕНТРАЛЬНОЙ частью всего приложения. Из него даже выйти невозможно, если через какое-то время решишь сменить фреймворк…
✅В этой статье я постараюсь поднять вопрос, а затем решить его.
???? Отказ от ответственности: давайте ограничим проект серверного API интернет-рынком.
???? Проблемы
Файлы конфигурации кода и проекта не разделены.
В некоторых проектах ( особенно в Django ) вы можете увидеть, что «приложение» или, скажем, основные компоненты размещаются прямо в корне проекта.
└─ backend/
├─ .gitignore
├─ .env.default
├─ .env
├─ .alembic.ini
├─ Pipfile
├─ Pipfile.lock
├─ pyproject.toml
├─ README.md
├─ config/
├─ users/
├─ authentication/
├─ products/
├─ shipping/
├─ http/
├─ mock/
├─ seed/
└─ static/Ну и ладно, так как внутри backend/ не 100 папок, но тут проблема в читабельности. Код читается разработчиками больше, чем пишется, поэтому лучше иметь части отдельно друг от друга. Давайте преобразуем приведенный выше пример:
└─ backend/
├─ .gitignore
├─ .env.default
├─ .env
├─ .alembic.ini
├─ Pipfile
├─ Pipfile.lock
├─ pyproject.toml
├─ README.md
├─ http/
├─ mock/
├─ seed/
├─ static/
└─ src/
├─ config/
├─ users/
├─ authentication/
├─ products/
└─ shipping/???? Гораздо лучше! Теперь разработчик может понять, что исходный код контейнера src/ folder. Таким образом, структура сгруппирована лучше.
???? Логическая составляющая
Что находится внутри каждой папки в папке src/ ? Обычно у нас есть что-то типа: модели данных, сервисы, константы…
Но вот проблема с этим подходом. Папка аутентификации / не имеет модели данных пользователя и зависит от пользователей/ папки. Папка Shipping / действует точно так же, это зависит от продуктов/ .
Затем вы можете создать дерево зависимостей компонентов, чтобы разработчики понимали, какой компонент от чего зависит.
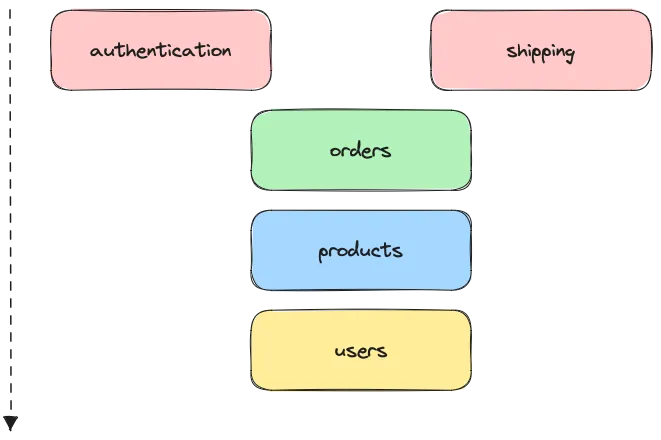
Основная сложность здесь — это поддержка этой кодовой базы ????. Каждый должен заботиться об этой диаграмме и обновлять ее с каждым новым компонентом. Еще один — каждый компонент имеет разную структуру, что делает файловую систему проекта несовместимой. Аутентификация не имеет таблицы базы данных, если это аутентификация на основе JWT, и она зависит от компонента пользователей , который представляет модель данных и взаимодействие с базой данных.
????♂️ С другой стороны — компонент доставки сам собирает всю эту логику. Это зависит от информации о заказе, которая зависит от продукта и информации о пользователе. Сопровождение этого кода через некоторое время может оказаться немного сложным.
Почему? Потому что, допустим, теперь клиент хочет, чтобы мы добавили новую функцию, связанную с 2 и более компонентами. Допустим, теперь нам нужно создать страницу для администраторов, которая будет предоставлять им аналитику по каждому продукту. Первый — по идентификатору товара мы должны вернуть количество текущих заказов, а второй — количество «в работе» поставок. Где нам следует разместить эти контроллеры и бизнес-логику? В заказах, доставке или продуктах?
Что ж, было бы лучше создать отдельный модуль, работающий со всеми ними вместе, и обновить схему выше. Это связано с тем, что у этого компонента нет собственных моделей данных. Он просто работает с другими компонентами системы.
└─ backend/
├─ .gitignore
├─ ...
└─ src/
├─ config/
├─ orders/
├─ products/
├─ shipping/
└─ analytics/ # new component
???? Тогда нашими контроллерами будут:
1. HTTP GET /analytics/products/<id>/orders
1. HTTP GET /analytics/products/<id>/shipping?status=inProgress
✅И вообще, это решает все наши проблемы. Только одно здесь — непрозрачная структура архитектуры. Нас должна интересовать схема, которая сообщает нам о зависимостях.
????️ Поэтому использование многоуровневой архитектуры Эрика Эванса (DDD) было бы отличной идеей. Он говорит нам разделить логические компоненты на несколько слоев:
Уровень «презентации», соответствующий шлюзу API приложения.
Уровень «приложение/операция» представляет собой основную сложную единицу бизнес-логики. Он делегирует сложность между более мелкими компонентами.
Уровень «домен» соответствует единице бизнес-логики.
«Инфраструктура» инкапсулирует код, который используется для создания всех вышеуказанных компонентов. ( все установленные библиотеки являются частью уровня инфраструктуры )

Например, пользователи, продукты и заказы представляют собственные модели данных и автономные сервисы, а также реализуют взаимодействие с базой данных. Эти источники рекомендуется размещать в слое «домен».
????♂️ С другой стороны, заказ — это пользовательская операция (которая зависит от продукта и пользователя), которую следует поместить на уровень «приложение».
????️ Таблицы базы данных обычно используются всеми компонентами системы, и мы не можем гарантировать, что поддомен пользователя не получит доступ к таблице заказов когда-нибудь в будущем. Это означает, что таблицы базы данных должны быть размещены на уровне инфраструктуры.
Тогда у нас есть что-то вроде этого:
└─ backend/
├─ .gitignore
├─ .env.default
├─ .env
├─ .alembic.ini
├─ Pipfile
├─ Pipfile.lock
├─ pyproject.toml
├─ README.md
├─ http/
├─ mock/
├─ seed/
├─ static/
└─ src/
├─ main.py # application entrypoint
├─ config/ # application configuration
├─ presentation/
├─ rest/
├─ orders
├─ shipping/
└─ analytics/
└─ graphql/
├─ application/
├─ authentication/
├─ orders/
└─ analytics/
├─ domain/
├─ authentication/
├─ users/
├─ orders/
├─ shipping/
└─ products/
├─ infrastructure/
├─ database/
└─ migrations/
├─ errors/
└─ application/
└─ factory.pyПо сути, идея следующая: интерфейс API представлен на уровне представления. Затем он вызывает уровень приложения, если логика сложна, или непосредственно уровень предметной области, если нет. Далее уровень инфраструктуры включает в себя фабрику для создания приложения.
???? Эта структура соответствует большинству потребностей и очень легко масштабируется.
Фреймворки заставляют писать ????
У всех фреймворков есть документация, описывающая предоставляемые ими функции, и для упрощения они также используют примеры PoC, не так ли? Для лучшего объяснения: функция платформы становится центральной идеей кода, описывающего эту функцию.
Так как же мы можем получить фреймворк и использовать его в качестве инфраструктуры для написания приложения вместо того, чтобы делать его центральным мозгом всего приложения?
???? Реальный пример
???? Весь код доступен на ???? GitHub
Отказ от ответственности: я не собираюсь создавать MVP, который имеет какой-либо смысл. Некоторые сложные компоненты, такие как доставка, пропускаются.
Сначала давайте создадим минимальную настройку проекта со следующими технологиями:
Язык программирования:
Python
Инструменты для запуска:
Gunicorn: WSGI server
Uvicorn: ASGI server
Дополнительные инструменты:
FastAPI: web framework
Pydantic: data models and validation
SQLAlchemy: ORM
Alembic: database migration tools
Loguru: logging engine
Инструменты качества кода:
pytest, hypothesis, coverage
ruff, mypy
black, isort
После завершения создания файлов конфигурации давайте начнем с интеграции точки входа приложения. Обычно мы называем этот файл main.py или run.py , тогда я бы предпочел остаться с main.py.
from fastapi import FastAPI
from loguru import logger
from src.config import settings
from src.infrastructure import application
from src.presentation import rest
# Adjust the logging
# -------------------------------
logger.add(
"".join(
[
str(settings.root_dir),
"/logs/",
settings.logging.file.lower(),
".log",
]
),
format=settings.logging.format,
rotation=settings.logging.rotation,
compression=settings.logging.compression,
level="INFO",
)
# Adjust the application
# -------------------------------
app: FastAPI = application.create(
debug=settings.debug,
rest_routers=(rest.products.router, rest.orders.router),
startup_tasks=[],
shutdown_tasks=[],
)Как видите, мы просто импортируем основные пользовательские компоненты в файл точки входа для сборки приложения. Я помогаю сделать это прозрачным для разработчика, который обслуживает программное обеспечение.
Вы можете видеть, что в первую очередь мы настраиваем логирование, а затем собираем приложение с использованием фабрики.
Давайте углубимся в фабрику приложений:
import asyncio
from functools import partial
from typing import Callable, Coroutine, Iterable
from fastapi import APIRouter, FastAPI
from fastapi.exceptions import RequestValidationError
from pydantic import ValidationError
from src.infrastructure.errors import (
BaseError,
custom_base_errors_handler,
pydantic_validation_errors_handler,
python_base_error_handler,
)
__all__ = ("create",)
def create(
*_,
rest_routers: Iterable[APIRouter],
startup_tasks: Iterable[Callable[[], Coroutine]] | None = None,
shutdown_tasks: Iterable[Callable[[], Coroutine]] | None = None,
**kwargs,
) -> FastAPI:
"""The application factory using FastAPI framework.
???? Only passing routes is mandatory to start.
"""
# Initialize the base FastAPI application
app = FastAPI(**kwargs)
# Include REST API routers
for router in rest_routers:
app.include_router(router)
# Extend FastAPI default error handlers
app.exception_handler(RequestValidationError)(
pydantic_validation_errors_handler
)
app.exception_handler(BaseError)(custom_base_errors_handler)
app.exception_handler(ValidationError)(pydantic_validation_errors_handler)
app.exception_handler(Exception)(python_base_error_handler)
# Define startup tasks that are running asynchronous using FastAPI hook
if startup_tasks:
for task in startup_tasks:
coro = partial(asyncio.create_task, task())
app.on_event("startup")(coro)
# Define shutdown tasks using FastAPI hook
if shutdown_tasks:
for task in shutdown_tasks:
app.on_event("shutdown")(task)
return app????️ Обсуждение:
Использование подобной фабрики помогает разработчикам не совершать ошибок. Вы просто видите несколько свойств, которые вам нужно заполнить: маршрутизаторы, задачи запуска и завершения работы, и это облегчает понимание всей базы кода. Вы переводите этот код так: « Хорошо, я создаю приложение и передаю аргумент с маршрутизаторами и задачами. Я предполагаю, что если я удалю отсюда один маршрут или задачу, они больше не будут использоваться… ' и вы правы! Помните, что код читается чаще, чем пишется .
????️ Шаблон репозитория
Обычно шаблон репозитория реализуется ORM, который используется в проекте ( в настоящее время SQLAlchemy ). Он реализует преобразователь данных для доступа к базе данных.
Но когда вы начинаете использовать класс, который представляет преобразователь данных во всем приложении, становится намного сложнее перейти на другой ORM в будущем или, скажем, заменить ORM своим собственным преобразователем данных.
Создание простого слоя абстракции может вам очень помочь. Давайте посмотрим на src/infrastructure/database/repository.py.
from typing import Any, AsyncGenerator, Generic, Type
from sqlalchemy import Result, asc, delete, desc, func, select, update
from src.infrastructure.database.session import Session
from src.infrastructure.database.tables import ConcreteTable
from src.infrastructure.errors import (
DatabaseError,
NotFoundError,
UnprocessableError,
)
__all__ = ("BaseRepository",)
# Mypy error: https://github.com/python/mypy/issues/13755
class BaseRepository(Session, Generic[ConcreteTable]): # type: ignore
"""This class implements the base interface for working with database
and makes it easier to work with type annotations.
"""
schema_class: Type[ConcreteTable]
def __init__(self) -> None:
super().__init__()
if not self.schema_class:
raise UnprocessableError(
message=(
"Can not initiate the class without schema_class attribute"
)
)
async def _get(self, key: str, value: Any) -> ConcreteTable:
"""Return only one result by filters"""
query = select(self.schema_class).where(
getattr(self.schema_class, key) == value
)
result: Result = await self.execute(query)
if not (_result := result.scalars().one_or_none()):
raise NotFoundError
return _result
async def count(self) -> int:
result: Result = await self.execute(func.count(self.schema_class.id))
value = result.scalar()
if not isinstance(value, int):
raise UnprocessableError(
message=(
"For some reason count function returned not an integer."
f"Value: {value}"
),
)
return value
async def _save(self, payload: dict[str, Any]) -> ConcreteTable:
try:
schema = self.schema_class(**payload)
self._session.add(schema)
await self._session.flush()
await self._session.refresh(schema)
return schema
except self._ERRORS:
raise DatabaseError
async def _all(self) -> AsyncGenerator[ConcreteTable, None]:
result: Result = await self.execute(select(self.schema_class))
schemas = result.scalars().all()
for schema in schemas:
yield schemaЭто зависит от src/infrastructure/database/session.py
class Session:
# All sqlalchemy errors that can be raised
_ERRORS = (IntegrityError, PendingRollbackError)
def __init__(self) -> None:
self._session: AsyncSession = CTX_SESSION.get()
async def execute(self, query) -> Result:
try:
result = await self._session.execute(query)
return result
except self._ERRORS:
raise DatabaseError????️ Обсуждение
Прежде всего, BaseRepository можно назвать BaseCRUD ( создание/чтение/обновление/удаление ) или BaseDAL ( уровень доступа к данным ). Это не имеет большого значения.
1. Он реализует интерфейс для создания конкретных классов, которые представляют доступ к уровню базы данных для конкретной таблицы.
2. Этот класс обеспечивает довольно хорошее манипулирование универсальными типами в проекте.
Небольшой пример файла src/domain/products/repository.py.
class ProductRepository(BaseRepository[ProductsTable]):
schema_class = ProductsTable
async def all(self) -> AsyncGenerator[Product, None]:
async for instance in self._all():
yield Product.from_orm(instance)
async def get(self, id_: int) -> Product:
instance = await self._get(key="id", value=id_)
return Product.from_orm(instance)
async def create(self, schema: ProductUncommited) -> Product:
instance: ProductsTable = await self._save(schema.dict())
return Product.from_orm(instance)Обратите внимание, что Schema_class используется для теневых операций в классе BaseRepository , поскольку нельзя использовать этот класс непосредственно из GenericType .
3. Операция async for позволяет нам не создавать промежуточные структуры ( списки, кортежи и т. д. ), которые требуют много оперативной памяти для запросов выборки.
4. Все общие методы имеют подчеркивание в начале для обеспечения гибкости. Общая цель такова: ` get()` заказа может отличаться от операции базы данных ` get()` продукта . Лучше держать их отдельно. С другой стороны, метод count, возвращающий примитив, может быть общим для всех таблиц базы данных.
⚠️ Если необходимо получить информацию, которую невозможно представить в одной таблице, вы можете легко создать экземпляр Session() , который обеспечивает самый простой интерфейс доступа к базе данных.
✨ План действий по функции «Создать заказ»
Давайте посмотрим на конвейер действий « создать заказ » и его зависимости.
С точки зрения кода:
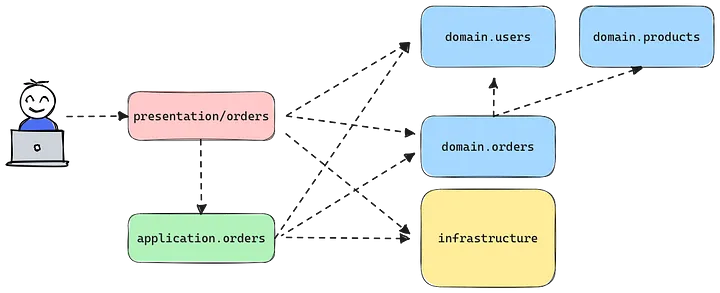
Файл presentation/orders.py :
from fastapi import APIRouter, Depends, Request, status
from src.application import orders
from src.application.authentication import get_current_user
from src.domain.orders import (
Order,
OrderCreateRequestBody,
OrderPublic,
)
from src.domain.users import User
from src.infrastructure.database.transaction import transaction
from src.infrastructure.models import Response
router = APIRouter(prefix="/orders", tags=["Orders"])
@router.post("", status_code=status.HTTP_201_CREATED)
async def order_create(
request: Request,
schema: OrderCreateRequestBody,
user: User = Depends(get_current_user),
) -> Response[OrderPublic]:
"""Create a new order."""
# Save product to the database
order: Order = await orders.create(payload=schema.dict(), user=user)
order_public = OrderPublic.from_orm(order)
return Response[OrderPublic](result=order_public)Файл application/orders.py
from src.domain.orders import Order, OrdersRepository, OrderUncommited
from src.domain.users import User
from src.infrastructure.database.transaction import transaction
@transaction
async def create(payload: dict, user: User) -> Order:
payload.update(user_id=user.id)
order = await OrdersRepository().create(OrderUncommited(**payload))
# Do som other stuff...
return orderИ реализация декоратора @transaction
from functools import wraps
from loguru import logger
from sqlalchemy.exc import IntegrityError, PendingRollbackError
from sqlalchemy.ext.asyncio import AsyncSession
from src.infrastructure.database.session import CTX_SESSION, get_session
from src.infrastructure.errors import DatabaseError
def transaction(coro):
"""This decorator should be used with all coroutines
that want's access the database for saving a new data.
"""
@wraps(coro)
async def inner(*args, **kwargs):
session: AsyncSession = get_session()
CTX_SESSION.set(session)
try:
result = await coro(*args, **kwargs)
await session.commit()
return result
except DatabaseError as error:
# NOTE: If any sort of issues are occurred in the code
# they are handled on the BaseCRUD level and raised
# as a DatabseError.
# If the DatabseError is handled within domain/application
# levels it is possible that `await session.commit()`
# would raise an error.
logger.error(f"Rolling back changes.\n{error}")
await session.rollback()
raise DatabaseError
except (IntegrityError, PendingRollbackError) as error:
# NOTE: Since there is a session commit on this level it should
# be handled because it can raise some errors also
logger.error(f"Rolling back changes.\n{error}")
await session.rollback()
finally:
await session.close()
return inner????️ Обсуждение
1. Транзакция с использованием ContextVar, которая отлично подходит для управления асинхронной задачей, выполняемой в данный момент. ???? Официальная документация Python
Комментарии (4)

Pavel1114
18.09.2023 10:46Пытаюсь вникнуть что и для чего вы делаете и, главное, стоит ли оно того. Но вот так сходу разобраться не получилось. Покопаюсь на досуге.
Но один вопрос уже есть - чем ваша реализация настроек логирования лучше, чем то что предлагает к примеру та же django - т.е использовать по сути стандартные инструменты модуля logging? Зачем эта надстройка? Почему нельзя так же с помощью словаря настраивать?
craxti Автор
18.09.2023 10:46Ну почему же нельзя, можно, можно вообще все
Но иногда удобнее настроить под себя

Stantin
18.09.2023 10:46Не совсем понятно, как Джанго был виноват в описываемых проблемах и почему fastapi вместе orm и кучей лютого бойлерплейта решают все проблемы.
Думаю, стоило больше букв потратить на донесение мысли, а код можно и на гитхабе посмотреть
EX_Amadeus
Классная статья! У меня тоже были трудности с организацией проектов в Python, особенно с Django. Ваш метод с разделением компонентов и использованием архитектуры DDD звучит очень разумно. Это не только улучшает читаемость кода, но и делает проект более гибким и управляемым в будущем.