
Техническая сторона стартапов иногда может быть очень изменчивой и содержать много неизвестного. Какой технологический стек использовать? Какие компоненты могут быть излишние на данный момент, но стоит ли следить за этим в будущем? Как сбалансировать темпы разработки бизнес-функций, сохраняя при этом планку качества на достаточно высоком уровне, чтобы иметь поддерживаемую кодовую базу?
Здесь я хочу поделиться нашим опытом создания https://cleanbee.syzygy-ai.com/ с нуля — как мы формировали наши процессы в зависимости от потребностей и как наши процессы развивались по мере расширения нашего технологического стека новыми компонентами.
Бизнес хочет завоевать рынок, а инженеры — попробовать крутые штуки и размять мозги. Тем временем индустрия производит новые языки, фреймворки и библиотеки в таких количествах, что вы не сможете их все проверить. И обычно, если вы поцарапаете блестящую поверхность «Следующей большой вещи», вы обнаружите старую добрую концепцию. Хорошо, если повезет.
Одна из самых интересных тем для споров — это процессы — полагаетесь ли вы на транковую разработку , предпочитаете более чудовищный поток GitHub , являетесь поклонником моббинга или считаете более эффективным тратить время на ревью кода на основе PR .
У меня есть опыт работы в среде, где артефакты выбрасывались пользователями без какого-либо стандартизированного процесса. В случае возникновения проблем разработчики с удовольствием (нет!) пытались выяснить, какая версия компонентов была на самом деле развернута.
С другой стороны, бесконечная очередь в CI. После того, как вы создадите PR, вам придется в ближайшие 30 минут развлекаться, ставя на то, найдет ли CI-кластер ресурс для запуска тестов ваших изменений. Иногда команда платформы представляет новые, интересные и полезные функции, которые могут нарушить совместимость с существующим шаблоном CI. Это может привести к тому, что все ваши проверки не пройдут в последнюю минуту, после часа ожидания.
Я твердо убежден, что, как обычно, все зависит от зрелости команды, типа программного обеспечения, которое вы создаете, и различных бизнес-ограничений, например, наличия бюджета ошибок и важности времени выхода на рынок по сравнению с SLX .
Я думаю, что важно иметь какие-то согласованные процессы, о которых все знают и которым следуют. Также важно иметь смелость бросить вызов и изменить ситуацию, если есть доказательства лучшей альтернативы.
Начните формировать процесс
Что мы имеем на старте:
менее десятка разработчиков — собственная команда и временные подрядчики, которые хотят и могут работать асинхронно
полностью новый проект — еще не написано ни одной строчки кода. Требования расплывчаты, но они уже начали во что-то формироваться
с технической точки зрения — очевидная потребность в серверной части, которая должна взаимодействовать с мобильными клиентами.
простой веб-интерфейс — статических страниц должно быть достаточно! (неа)
Мы начали с простого — код на GitHub и процесс, основанный на PR, с единственным требованием — разделить билеты и доставить их в течение 1–3 дней. Это потребовало некоторой практики в разрезании истории , и кажется, что ощущение видимого быстрого прогресса проявляется в возможности перемещать билеты в Done. Это может стать отличным мотивационным фактором для реализации этой идеи командой.
Линтеры и статические анализаторы позволяют пропустить интересные дискуссии, например, о том, сколько аргументов у каждого метода слишком много (6!). Постепенно будем добавлять автотесты. Мы также пробуем codesense . У них есть очень многообещающий подход к выделению важных частей кода (те биты, которые часто меняются и которые определенно должны иметь более высокую планку удобства сопровождения!) и определению сложности , глядя на уровень вложенности кода. Вероятно, на начальном этапе это немного дороговато для стартапов, но 100% дает инженерам достойные подсказки.
Что касается архитектуры, то возник соблазн погрузиться глубоко в страну чудес микросервисов. Но глядя на ужасающие диаграммы связей между ними со стороны крупных игроков, необходимость отслеживать запросы между ними, это действительно кажется самоубийственным подходом для команд на ранней стадии, которые хотят двигаться быстро.
Анализ требований позволяет выделить три группы должностей:
основной API с обычными CRUD-подобными действиями
поиск и рекомендации
временная нагрузка, которая делает что-то полезное по расписанию (почти одновременно со случайными задержками — это нормально)

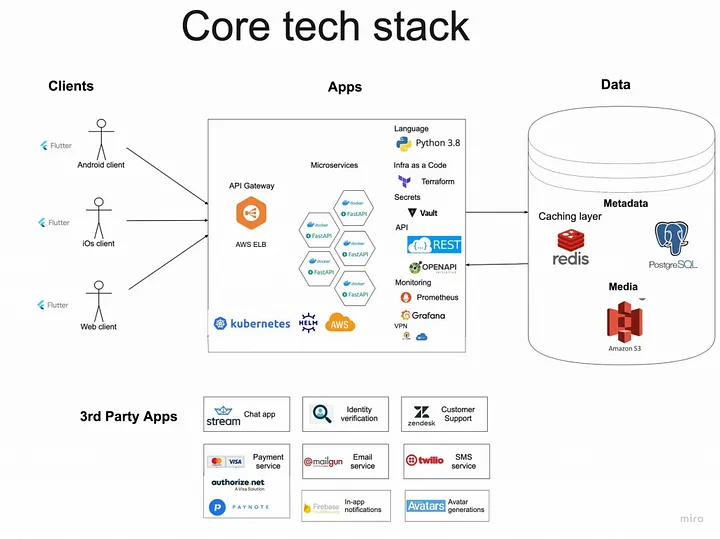
Выбор технологического стека: ситуации, когда время немного ограничено, а ожидания высоки. Используйте то, что знаете и освоите (да, возможно для кого-то это скучная технология ). Следовательно, Fastapi, REST, Stateless, Python, Redis и Postgres — наши лучшие друзья (да, нам нравятся Go и Rust, но нам нужно платить немного больше!).
С мобильными клиентами ситуация была немного иная. Мы предусмотрели множество экранов с состояниями и взаимодействием с удаленными службами, но не слишком много пользовательских настроек, специфичных для платформы. Следовательно, идея иметь единую кодовую базу для iOS и Android была очень привлекательной.
Сейчас выбор фреймворков действительно широк , но опять же, ввиду некоторого опыта работы с Flutter, мы решили попробовать. В рамках мобильной разработки одним из важных аспектов, над которым следует лучше принять решение, является управление состоянием. Здесь у вас будет множество аббревиатур из разных языков и фреймворков, которые помогут вам разобраться. Некоторые из них включают MVC , MVVM , VIPER , TCA , RIB , BLOC и т. д .
Наш девиз начинается с самых простых (*) решений, достаточных для поддержки необходимого функционала. (*) Простой. Ну, скажем так, мы думаем, что понимаем это.
Однако мы определенно допустили ошибку после создания MVP, потому что решили развивать его, а не выбрасывать . Поэтому в один чудесный (нет!) солнечный день я усомнился в своем здравом уме: после того, как я закомментировал код, очистил все возможные кеши, и все еще не увидел своих изменений на новом экране. Да, мертвый код следует удалить!
Начни строить!
После того как эти первоначальные формальности были улажены, следующим необходимым было иметь возможность проверять взаимодействие клиент-сервер.
Контракт API — отличная вещь, но будет гораздо очевиднее, что что-то не так, когда реальный сервер выдаст вам «ошибку проверки схемы» или с треском выйдет из строя с кодом ошибки HTTP 500.
Серверные сервисы изначально были разделены на две группы — монолит API и поиск и рекомендации. Первый содержит более или менее простую логику для взаимодействия с БД, а второй содержит вычисления с интенсивным использованием ЦП, которые могут потребовать определенной конфигурации оборудования. Каждый сервис имеет свою группу масштабируемости.
Поскольку мы все еще думали о стратегии развертывания (и спорили, какой домен купить), решение было простым: свести к минимуму трудности мобильных инженеров при работе с серверной частью, то есть с чужеродным стеком. Давайте упакуем все в докер.
Когда мы готовим все для локального развертывания — мобильные инженеры могут запускать команды docker-compose и все уже готово (после нескольких мучительных попыток, выявляющих недостатки в документации, но реальная ценность таких упражнений — реагировать на каждое «WTF!» и Улучши это).
«Все» хорошо, но какой смысл в API, работающем поверх пустой БД? Ручной ввод необходимых данных в короткие сроки приводит к депрессии (и риску увеличения продолжительности циклов разработки). Таким образом, мы подготовили тщательно подобранный набор данных, который был вставлен в локальную базу данных, чтобы с ним можно было поиграть. Мы также начали использовать его для автотестов. Беспроигрышный вариант! Аутентификация становится менее проблематичной при определении сценариев тестирования, когда у вас есть десятки фиктивных пользователей с похожими паролями!
Пробуйте что-то новое или выбирайте сторонних поставщиков
Иметь дело с новыми технологиями всегда немного опасно. Вы и ваша команда не можете знать всего (а иногда вещи, которые, как вам кажется, вы знаете, могут вас наполнить, но это уже другая история). И все же зачастую требуется оценить и исследовать то, к чему никто не прикасался.
Платежи, электронная почта, чат, СМС, уведомления, аналитика и т. д. Каждое современное приложение обычно представляет собой склеенную с несколькими сторонними провайдерами бизнес-логику.
Наш подход к выбору тех, с кем мы работаем — ограниченные по времени действия, направленные на то, чтобы попробовать наиболее перспективный вариант, выбранный по функциям, поддерживаемым языкам и, в случае поставщиков, ценам.
Как мы попали в Терраформ?
Серверная часть, являющаяся частью БД, также должна иметь некоторое хранилище объектов/файлов. Рано или поздно у нас тоже должен появиться DNS, чтобы наши сервисы были готовы к игре с большим жестоким миром.
Выбор поставщика облачных услуг был основан исключительно на имеющемся опыте внутри команды. Мы уже используем AWS для других проектов, поэтому решили придерживаться его. Конечно, в консоли AWS можно все сделать, но со временем все превращается в классический большой ком грязи, к которому все боятся прикоснуться, и никто не помнит, зачем вообще этот кусочек существует.
Хорошо, похоже, здесь может пригодиться парадигма инфраструктуры как кода .
С точки зрения инструментов выбор не такой уж и большой — в зависимости от поставщика (AWS Cloud form , Google Cloud ( Deployment Manager , Azure Automation ), terraform и его конкуренты .
Судя по опыту работы с терраформом… вы уже имеете представление о том, как мы выбираем вещи?
Да, первоначальная настройка займет некоторое время (и без контроля может легко превратиться в такой же большой ком грязи и в TF), но, по крайней мере, у него будет некоторая документация по инфраструктуре и наглядность того, ПОЧЕМУ она здесь. Еще одно важное преимущество: все, чем вы управляете через TF, будет обновляться автоматически (ну, когда вы или CI/CD запускаете соответствующие команды).
Управление секретами
Что касается самой AWS, поскольку мы запускаем все внутри AWS, мы можем полагаться на IAM и предполагаемые роли , прикрепляя необходимые политики к нашим виртуальным машинам. Но нам нужна интеграция со сторонними сервисами и какой-то способ передавать в наши приложения некоторые секреты, например, пароли к БД. Нам нужно какое-то решение для управления секретами. У AWS есть KMS , у действий GitHub есть свои секреты , а кроме него есть еще куча других провайдеров. Итак, реальный вопрос: что вам нужно от секретного управления:
аудит
доступ на основе пути
интеграция с Кубернетесом
возможность выдачи временных удостоверений
Веб-интерфейс
Бесплатно
секреты версий
KMS был очень удобен, и нам удалось добавить его в действия GitHub, но пользовательский интерфейс хранилища и возможность использовать его бесплатно (если вы запускаете его самостоятельно) были своего рода препятствием в этом вопросе.
Путь к Кубернетесу
И как только мы закрепили приложение, мы начали рассматривать Kubernetes, поскольку он предлагает несколько полезных функций «из коробки». Самый важный из них — иметь возможность развернуть необходимое количество модулей для удовлетворения требований к производительности и возможность декларативно определять все ваши потребности. Итак, при достаточном уровне автоматизации ни один человек не должен бегать kubectl apply. Для начала у AWS есть EKS, которым можно управлять через terraform.
С другой стороны, крутая кривая обучения (чтобы понять идею о том, что точно определено, что должно быть запущено и запущено) и немного специфических инструментов, с которыми можно было поиграть, были вескими причинами подумать об этом дважды.
Шлемовые диаграммы
Если мы говорим о Kubernetes и уже выпускаем докер-приложения при каждом слиянии с основным, то диаграммы управления станут следующим шагом в адаптации современного стека инфраструктуры. Мы подключили AWS ECR, чтобы отслеживать каждый новый выпуск и публиковать управляющие диаграммы в специальных корзинах S3, которые становятся нашим внутренним реестром управляющих диаграмм.
Соединить все это оказалось не так просто, как ожидалось. Узлы Kubernetes изначально не могли подключиться к ECR и получить необходимые образы докеров, модули terraform ( aws-ssm-operator), предназначенные для работы с секретами в AWS KMS, устарели и не поддерживали последние API Kubernetes, секреты и карты конфигурации были не в настроении быть помещены в капсулы.
Первое внедрение сервисов приносит радость мобильным пользователям — не нужно беспокоиться об инструкциях по локальной настройке! Первую неделю или около того все было не очень стабильно, но потом одной заботой стало меньше.
Вам нужно все это? Не обязательно.
Надо признать, эта смесь — Kubernetes с vault через terraform и helm — наверняка не для всех, и на начальном этапе она вам, скорее всего, не понадобится. Простое нажатие докера в ECR при слиянии с основным и выполнение ssh в ec2 && docker pull && docker-composestop-start во время выпуска из CICD может работать хорошо (по крайней мере, для счастливого пути). Это будет понятно каждому с первого взгляда. Именно так мы сейчас перераспределяем наши статические веб-сайты . Мы можем сосредоточиться на новой версии сборки ci и скопировать ее в соответствующую корзину s3.
Развитие инфраструктуры
AWS достаточно хороша, чтобы предлагать кредиты тем, кто достаточно смел, чтобы исследовать тенистые пути мира стартапов. Можем ли мы использовать его, чтобы сэкономить несколько долларов на GitHub-минутах и раскрыть меньше секретов и инфраструктуры для виртуальных машин GitHub?
А как насчет самостоятельных бегунов, т. е. когда вы открываете PR, не виртуальные машины GitHub, а ваши собственные Kubernetes выделяют модуль для запуска ваших проверок CI? Конечно, сложно все подготовить к релизам iOS (подробнее об этом ниже), но Android и бэкенд наверняка должны работать на старом добром Linux?!
Мы построили его с помощью выделенных модулей k8s , но есть также возможность запускать проверки на локальных экземплярах EC2 .
Наблюдаемость и Ко
Вокруг таких терминов, как мониторинг и оповещение, ходит много маркетинговой болтовни.
В некоторых компаниях такие вещи внедряются просто для того, чтобы похвастаться: «У нас для этого есть X!». Однако инженеры по-прежнему слепы к тому, что происходит с их производством, когда возникают реальные проблемы или каналы оповещений приходится отключать, поскольку они содержат шум, не требующий принятия мер.
И я должен сказать, что нам еще предстоит пройти долгий путь.
Первое, что вы обнаружите, как только начнете искать такое решение, — это стек ELK и кучу платных провайдеров. Измерив время и усилия по поддержанию нашей собственной установки, я начал думать, что платное решение может того стоить. Если и только если вы действительно сможете делегировать бремя передачи самой важной информации о ваших приложениях и состоянии инфраструктуры существующим решениям. Все зависит от того, есть ли у них предустановленные метрики, анализаторы журналов и сопоставление индексов, которые вы можете легко адаптировать к своему проекту.
Для ведения журналов в настоящее время мы полагаемся на ELK . Да, его более или менее просто настроить, и, скорее всего, некоторые люди находят язык запросов elastic очень удобным для ежедневного использования.
Здесь мы все еще изучаем варианты, так как кажется, что старые добрые времена kubectl logsпозволяют grepполучать информацию по таким вопросам, как «Какова последняя ошибка в app1модулях» гораздо более своевременно, не теряясь среди бесконечных элементов управления пользовательского интерфейса. Но, скорее всего, пользовательский интерфейс Kibana по-прежнему скрывает рычаги, которые мы должны использовать, чтобы добавить правильный конвейер приема и выбрать соответствующее сопоставление для эластичного индекса для filebeat.
Для оповещения настраиваем prometheus и интегрируем его в Slack. Опять же, главным образом потому, что мы уже сталкивались с этим раньше.
Итак, зачем нам Azure?!
Как обычно бывает, когда продукты развиваются, новые требования создают новые вещи:
теперь, чтобы сделать что-то общедоступным, нам нужны некоторые ресурсы, доступные только для команды
для управления флагами функций, доступа к пользовательскому интерфейсу хранилища или борьбы с эластиком, чтобы выяснить последнюю ошибку API.
Конечно, для этого есть платные решения , или вы можете объединить их Identityв качестве поставщика услуг (активный каталог Azure) для аутентификации ваших товарищей по команде с любыми поставщиками VPN. Мы выбрали OpenVPN из-за их уровней бесплатного пользования и предоставляем необходимые услуги только внутренней сети тем, кто должен войти в систему, используя свои учетные данные. У него есть одно явное преимущество по сравнению с использованием стека AWS — он бесплатен (для ограниченного количества подключений).
Хорошо, зачем нам Google Cloud?
До сих пор мы в основном обсуждали серверную часть. Но есть и другие. Первое, что вы видите — мобильные приложения! Flutter или что-то еще также необходимо собрать, проверить и протестировать. И каким-то образом опубликовано где-то, чтобы заинтересованные стороны могли сразу же восхищаться новыми функциями (и находить новые ошибки).
Для запуска в производство вам придется пройти множество формальностей (скриншоты, журнал изменений = что нового, обзор), которые будут мешать вашей аудитории наслаждаться этими произведениями искусства.
Надо сказать, что API магазинов не очень-то дружелюбно для частого выпуска. Когда вы создаете и подписываете приложение, публикация может занять более 15 минут. Как и любой другой API, API магазинов приложений рано или поздно может выйти из строя. Да, и подписание может оказаться кошмаром, поскольку оно различается на разных платформах. И было бы здорово, если бы инженеры не тратили время на подготовку релизов для своих ноутбуков.
Первое (и, вероятно, единственное?), на что вам следует обратить внимание, — это полоса быстрого доступа — изначально у меня были некоторые предубеждения по поводу всех этих новых терминов, таких как драгоценные камни (хотя это имя!) и Bundle , но это работает. Чтобы запустить их из CI, потребуются некоторые усилия, чтобы разобраться с секретами jks для Android или соответствием для iOS.
К «темной» стороне
Далее вы начнете думать о распространении приложений: testflight — удобный инструмент для мира iOS, а как насчет Android? В итоге мы использовали App Distribution — решение от Firebase — главным образом потому, что оно помогло нам с первой попытки. Но есть и другие варианты (которые утверждают, что работают на обеих платформах).
Важно то, что на быстрой полосе вы можете делать все! Даже когда ваше приложение развивается и вы начинаете добавлять различные дополнения — аналитику, чаты, карты, гео — многие из них были созданы Google непосредственно из Firebase. Поскольку Firebase предлагает множество полезных функций, было естественно собирать аналитические события, и после нескольких изменений в их политике IAM мы настроили экспорт необработанных событий в gs-корзины, чтобы можно было поиграть с BigQuery.
Продюсирование против постановки — великий раскол!
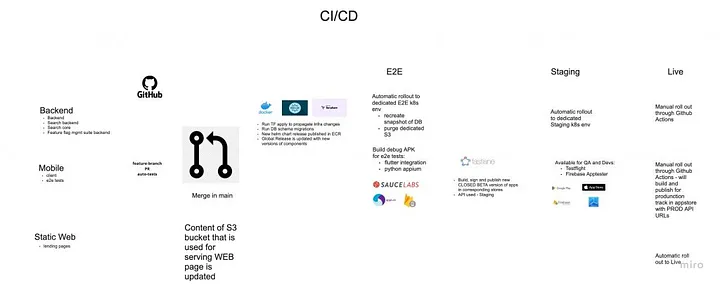
Что касается бэкэнда, у нас с самого начала есть автотесты. Различные методы, такие как двойной тест, оказываются весьма эффективными для предотвращения регрессий даже в сложной бизнес-логике с интеграцией сторонних сервисов. Что касается мобильных устройств, мы были немного ограничены из-за сосуществования кода MVP, а автотесты были не очень полезны для сложных бизнес-сценариев, например, когда кто-то хочет воспользоваться нашими услугами, но мы не можем снять средства с его банковской карты.
Ручное тестирование было очень трудоемким и подвержено ошибкам, особенно когда бизнес-логика динамически развивалась и состояние данных в базе данных после недавних обновлений становилось невозможным с точки зрения правил предметной области.
Да, поэтому было бы неплохо запустить тесты e2e, щелкнув приложение с данными, которые мы поддерживаем (и убедившись, что они действительны). Было бы хорошо, если бы эти тесты не загрязняли реальную базу данных, корзины S3 и сторонних поставщиков.
Мы начали с одной основной ветки и одной среды (rds, redis, пространство имен k8s и s3), которые использовали первые тестировщики и разработчики. Мы не были представлены публике, но по мере того, как мы приближались к релизу, становилось ясно, что необходимо какое-то различие между местами, где мы можем что-то ломать и иметь стабильную среду.
В мобильных приложениях изменение URL-адреса API во время сборки было проблемой. На серверной стороне необходимо выполнить несколько аспектов для поддержки конфигураций, специфичных для развертывания: с точки зрения инфраструктуры, путем создания выделенных политик и ресурсов и параметризации нескольких битов кода, где ожидались определенные URL-адреса. Помимо него, существует несколько репозиториев, некоторые из них независимы, а некоторые зависимы — как в случае с общим функционалом.
Знаете ли вы, что произойдет, если вы обновите общие функциональные возможности без немедленного повторного развертывания и тестирования всех зависимых приложений? Через несколько дней, когда вы совсем об этом забудете, вы вносите какие-то невинные — чисто косметические изменения где-то еще в зависимом репо, которые приведут к передислокации и извлечению последней зависимости.
Наверняка во время важной демки или сразу после нее вы увидите какие-нибудь глупые ошибки, связанные с несовместимостью по одному-единственному условию, которые вы забудете перепроверить.
Итак, первое важное соображение при разделении среды — автоматизировать общее развертывание всех зависимых приложений, если какой-то базовый репозиторий был обновлен. Вы можете попросить команду сделать это, и все согласятся, но забудут запустить пул.
Второй аспект — что нам нужно развернуть? Нужно ли нам поддерживать все приложения в каждой среде, включая временные рабочие места, отвечающие за отправку электронных писем или уведомлений? Кажется, некоторые флаги для включения или исключения заданий из развертывания могут оказаться полезными.
E2E и более поздние версии, возможно, не требуют Staging, должны быть доступны каждому в Интернете.
Продвижение новых выпусков на e2e и их размещение должны быть автоматизированы.
Продвижение новых релизов в прод, по крайней мере сейчас, лучше контролировать и вручную
В настоящее время у нас есть три конца, которые выполняют все вышеперечисленное:
E2E — среда, в которой интеграционные тесты будут выполняться на тщательно отобранных данных, чтобы гарантировать сохранение базовой функциональности.
Стадия — где происходит основная разработка и где бета-тестеры могут попытаться сломать то, что мы создаем.
Прод — что рад приветствовать новых пользователей
Кластер Kubernetes по-прежнему один. Все было разделено на уровне пространства имен. Похожая ситуация произошла с RDS, где несколько баз данных работали вместе в одном экземпляре RDS.

В части автоматизации мобильного тестирования выбор не очень большой. Сначала вам нужно выбрать, будете ли вы использовать какого-либо поставщика устройств в облаке или проводить тесты самостоятельно.
Конечно, можно подключить смартфон к ноутбуку и запустить тесты, но было бы неплохо (и правильно!), если бы вместо этого этим занимался CI? Когда вы начнете рассматривать поставщиков, которые предоставляют эмуляторы и реальные устройства для игры, вы обнаружите, что выбор среды тестирования для мобильных устройств невелик, но вам придется сделать второй выбор (и выбор поставщика может вас здесь ограничить). Еще один важный момент: существуют ли особые требования к оборудованию, например, к использованию графического процессора или npu? Следовательно, нам было достаточно любого эмулятора.
Мы выделяем два основных варианта среды мобильного тестирования e2e — интеграционные тесты Flutter и pytests на основе Appium . Лаборатория тестирования Firebase поддерживала интеграционные тесты Flutter, хотя требовалась некоторая настройка, чтобы разрешить запросам из их диапазонов IP (VM с запущенными эмуляторами) достигать нашего E2E API.
Appium, часть Python API, была очень многообещающей, поскольку это было похоже на использование чего-то вроде тестового проекта (вы, ребята, молодцы!). Вы можете записывать все клики через приложение для каждого сценария. Следовательно, он не требует специальных знаний в области программирования, но позволяет изучать его постепенно). На данный момент Appium имеет гораздо более полную настройку в отношении покрытия сценариев.
У E2E-тестов есть одна маленькая (нет!) проблема — холодный старт приложения в эмуляторе происходит не очень быстро. Если мы добавим к этому время, необходимое для сборки приложения, и продолжительность копирования отладочной сборки провайдеру, это станет настоящим узким местом для быстрого продвижения.
До сих пор мы экспериментировали с их запуском дважды в день, но давайте посмотрим, как пойдет дело.
Что дальше?
В нашем списке дел еще много интересных задач:
Со стороны инфраструктуры — тестирование производительности, тестирование безопасности, тестирование Flutter для Интернета.
Со стороны разработки — обслуживание и обновление моделей машинного обучения для механизма рекомендаций, прогнозирование продолжительности очистки, создание кеша с вектором функций для рекомендаций, смешивание задач оптимизации в соответствии с механизмом, а также планирование заданий и теория игр.
И самое главное, ничто не может заменить реальное использование.
Много диких вещей вы увидите только тогда, когда начнете собирать реальные данные о поведении пользователей, поэтому мы с нетерпением ждем предстоящего запуска!
Комментарии (6)



klimkinMD
07.09.2023 06:06-1А Цукерберг с Сальваторе Санфилиппо были в курсе этих "откровений". И, что, Dmitry Kruglov уже сколотил хотя бы десяток миллионов на СВОИХ стартапах?
Да и кто-нибудь может назвать имя человека, который по книжкам Гейтса или Баффета стал миллиардером?
ivankudryavtsev
Привет. Много ошибок, очень много. Не заметил архитектуры «из говна и палок», что реально интересует стартапы в ранней стадии, типа будем делать все на Node/Mongo, не будет никаких стеков - вот она архитектура современного стартапа, а выше - это well-funded company.
craxti Автор
Прошу заметить, что это перевод статьи)
Я с вами согласен, но такой вариант тоже можно рассмотреть
ivankudryavtsev
Так я и пишу:
ошибок перевода много
есть сомнение в том, что заголовок статьи соответствует тому, что происходит в современном стартапе.