
Это моя вторая статья(первая тут) о Velociraptor, программе для выполнения задач Threat Hanting’а и DFIR’a ????.
Как вы, наверное, уже знаете, Velociraptor неплохой инструмент сбора информации с конечных устройств. Ключевым элементом этой программы является собственный язык запросов, который называется Velociraptor Query Language или VQL. “Еще один специфический язык запросов?” - спросите вы. Да, но на это есть причины, такой подход позволяет добиться необходимой гибкости при разработке и адаптации меняющихся требований пользователей, то есть нас с вами.
В этой статье я познакомлю вас с базовыми понятиями и структурой VQL. Буду стараться подкрепить теоретическую часть примерами. А полученных знаний будет достаточно, чтобы чувствовать себя комфортно при изменении существующих или создании собственных запросов.
Где используется VQL?
Эта часть статьи будет самой короткой, потому что быстрый ответ - везде. Как я уже писал, это центральный элемент программы. Наверное, всё взаимодействие исполняемых файлов Velociraptor с внешним миром происходит в формате VQL запрос → ответ. Приведу несколько примеров:
клиенты получают инструкции к выполнению(артефакты) в формате VQL;
web GUI использует VQL для взаимодействия с сервером;
для получение данных по API вам также необходимо использовать VQL;
Offline коллектор использует артефакты для работы, а следовательно использует VQL.
Получается, хотите вы этого или нет, а для успешной работы с Velociraptor вам нужно познакомится с его языком запросов
Среда выполнения запросов
Прежде чем начать изучение теоретической части, давайте разберемся каким образом вообще возможно выполнять VQL запросы. Помиио того, что это выполнение происходит при использовании артефактов, существуют следующие пути:
Выполнение непосредственно в командной строке. Для примера, вы можете запустить следующую команду
velociraptor.exe query "select * from info()"она выведет общую информацию по вашему хосту.Выполнение через API. Например, вы можете использовать Jupyter Notebook вместе с библиотекой pyvelociraptor для комфортного написания запросов и сохранения результатов их работы.
Использование Notebooks встроенных в Velociraptor. Этот механизм будет основным для вас в рамках этой статьи, поэтому мы остановимся на нем подробнее.
Раздел Notebooks в Velociraptor в основном создан для проведение анализа уже собранных данных. В таких Notebook’ах удобно хранить запросы которые могут помочь при проведении расследований или поиске подозрительных активностей. Вы также можете дать доступ к своему Notebook’у всем пользователям Velociraptor, что помогает при совместной работе над инцидентом.
Notebooks состоят из ячеек(cells). Есть два типа таких ячеек - Markdown и VQL. Назначение каждого типа понятно из названия, Markdown для описания, а VQL для выполнения запросов. Все VQL запросы, определенные в Notebooks, выполняются на Velociraptor сервере(в статье это будет ваша рабочая станция) без какой либо фильтрации и ограничений, это делает Notebook’и хорошим инструментом для изучения и разработки VQL запросов.
Давайте создадим Notebook и выполним в нём первый VQL запрос. Для этого запустите Velociraptor velociraptor.exe gui --datastore temp, перейдите в web gui и в левой части окна перейдите в раздел Notebooks. Нажмите кнопку +, чтобы создать новый Notebook. В появившемся окне укажите название и нажмите кнопку Submit. Notebook создан, перейдите в панель нового Notebook'a и добавьте ячейку VQL с помощью кнопки +. Начните редактировать эту ячейку, нажав на иконку карандаша.

Вы готовы создать свой первый запрос. Напишите в ячейке select * from info() и сохраните этот запрос(иконка дискетки). При сохранении запрос выполнится и вы увидите строку с информацией о вашем хосте. Теперь вы можете переходить к теории написания запросов.
VQL
Основы
Синтаксис язык запросов VQL создавался с идеей быть максимально простым и понятным. Собственно говоря, все запросы осуществляются следующим образом:

Ключевое слово SELECT стоит первым, после него идет секция выбора столбцов. Далее идет слово FROM, которое указывает на плагин или другой источник из которого будут получены данные. И закрывает запрос слово WHERE после которого идут условия фильтрации полученных из источника данных.
Если вы знакомы с SELECT запросами в SQL, то и здесь не должно возникнуть сложностей. Первое отличие, которое вы могли заметить это то, что после слова FROM вместо названия таблицы идет название плагина. На этом этапе, думаю, надо остановиться подробнее. В Velociraptor существует два вида сущностей, которые выполняют ту или иную функцию при исполнении запроса, это:
Plugin - выступают в роли источников данных вместо таблиц, вызов плагина возвращает последовательность строк. После ключевого слова
FROMзачастую идет название плагина, вы не можете использовать плагин где-то еще в запросе. Часто плагины могут принимать входящие параметры, такие параметры могут быть обязательными или нет. Например для получения списка процессов вы можете использовать плагинpslist(), он также может принимать параметрpidдля получения информации по конкретному процессу, в этом случае форма записи будет следующейSELECT * FROM pslist(pid=4). Обратите внимание, что значения передаваемых параметров типизированы. То есть, если вы передадите параметру значение “string” напримерSELECT * FROM pslist(pid="4"), то такой запрос выполнен не будет.Function - производит преобразование данных или реализует дополнительную логику. Функция всегда возвращает единственное значение, даже если это значение список строк, он будет отражен в одной ячейки таблицы. Функции могут использоваться везде, где необходимо произвести операцию с данными, например в для преобразования параметров плагина. Следующий запрос будет выполнен успешно
SELECT * FROM pslist(pid=atoi(string="4"))
Информацию по существующим функциям и плагинам вы можете найти в официальной документации. Кроме того, при работе в Notebook вы можете использовать знак вопроса, чтобы вывести информацию о доступных функциях, плагинах и их параметрах.
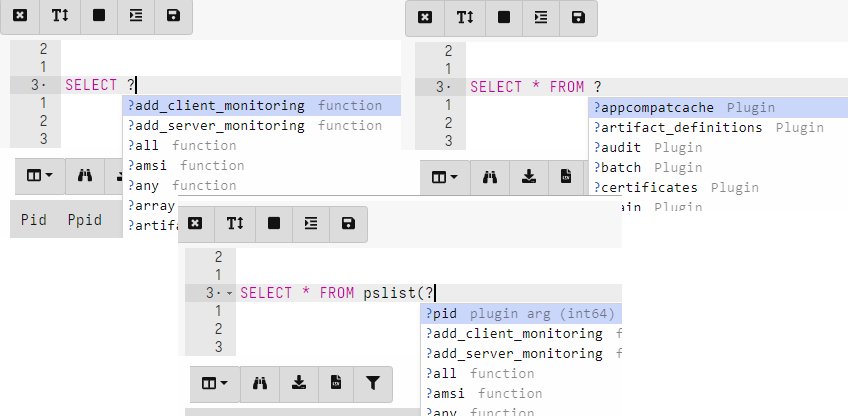
Вложенные запросы
VQL запросы могут быть вложенными в другие запросы или являться параметрами плагинов. Давайте разберемся на примере. Запрос SELECT * FROM pslist(pid=getpid()) использует плагин pslist, а в качестве параметра pid принимает функцию getpid, которая возвращает process id процесса Velociraptor. Выполнение этого запроса вернет таблицу с одной строкой и набором столбцов.

Давайте оставим интересные нам столбцы SELECT Pid, Ppid, Name FROM pslist(pid=getpid()). Плагин pslist не возвращает информацию об имени родительского процесса, а только parent pid(Ppid), чтобы получить имя необходимо сделать еще один запрос. Таким образом, запрос который отобразит имя дочернего и родительского процесса будет выглядить так:
SELECT Pid,
Ppid,
Name,
-- вложенный запрос
{
SELECT Name
FROM pslist(pid=Ppid)
} AS Pname
FROM pslist(pid=getpid())Вложенный запрос находится внутри фигурных скобок { } , в секции выбора столбцов. Результатом будет таблица с одной строкой

Количество и степень вложенности таких запросов неограничены, но черезмерное их использование делает запрос трудным для понимания.
Локальные переменные и функции
VQL поддерживает создание локальных переменных и даже функций. Они называются локальными, потому что существуют только во время выполнения запроса. Для создания такой переменной используется ключевое слово LET, вот несколько примеров
-- вы можете создать переменные содержащие простые значения
LET i = 4
LET s = "World!"
-- содержащие запросы
LET q = SELECT Pid, Name FROM pslist(pid=getpid())
-- и даже функции
LET to_str(integer) = format(format="%v is a string. Hello ", args=integer)
-- все это можно использовать при выполнении запроса
SELECT to_str(integer=i) + s AS Greeting, Name, Pid FROM q
SELECT запросы, сохраненные в переменной(6-ая строка), не выполняются до момента их вызова. Такой подход позволяет создавать сложные запросы, но при этом оставлять их доступными для чтения и понимания.
Давайте модифицируем один из запросов, который мы уже выполняли, чтобы увидеть как использовать сохраненные запросы. Рассмотрите следующий пример
LET Pname = SELECT Name FROM pslist(pid=Ppid)
SELECT Pid,
Ppid,
Name,
-- используем сохраненный запрос
Pname[0].Name AS Pname -- необходимо указать индекс 0, т.к. плагин всегда возвращает список строк, даже если в списке один элемент.
FROM pslist(pid=getpid())
Такая запись удобнее, особенно если количество вложенных запросов будет больше.
Сохраненные запросы используют пространство имен основного запроса, который производит их вызов. Поэтому запись FROM pslist(pid=Ppid) является коррктной, несмотря на то, что значение Ppid несуществует на момент создания переменной.
Важно различать обычные и "материализованные" переменные. Первые создаются как показано выше LET = , вторые LET <= . Синтаксическая разница в операторе (= - простые, <= - материализованные), а смысловая в том, что "материализованные" производят выполнение запроса в момент объявления переменной. В следующем примере мы будем использовать функцию log которая выводит сообщение в лог запроса при ее выполнении.
-- сохраненный запрос, выполнен не будет
LET one = SELECT *, log(message="Run from =") FROM info()
-- материализованный запрос, будет выполнен при создании переменной
LET two <= SELECT *, log(message="Run from <=") FROM info()Выполнение второго запроса произойдет даже при отсутствии основного SELECT запроса, который должен вывести информацию на экран.
Scope()
В некоторых случаях вам может понадобится выполнить функцию без необходимости получения каких либо данных из какого-либо плагина. Например вы не сможете выполнить такой запрос SELECT 4 + 4 вам необходимо следовать синтаксису и добавить FROM, а в качестве плагина указать scope() - SELECT 4 + 4 FROM scope(). Плагин scope() не выполняет операций.
Но само понятие scope немного больше в Velociraptor чем “псевдо” плагин при отсутствии операций. Scope это набор тех переменных и столбцов, к которым вы можете обращаться в запросе. Другими словами это пространство имен с помощью которых VQL понимает как преобразовать то, что вы описали в запросе в реальные значения. Для примера вы можете выполнить следующий запрос:
LET local_var1 = true
SELECT Platform, OS, local_var1, Foo FROM info()
В результате выполнения запроса вы получите ошибку, что столбца с именем Foo не существует. В тексте ошибки видна информация о всех текущих пространствах имен или scope. Поиск в пространстве имен происходит следующим образом
Запрос
SELECTсоздает набор значений, получаемых из плагинаinfo().VQL производит поиск столбцов в этом наборе. Если информация не найдена, VQL переходит на уровень выше и ищет в наборе, относящемся ко всему запросу. На скрине видно, что локальные переменные отделены от значений из плагина.
Если и там значения не найдено, то VQL переходит еще выше. Например, мы можем использовать переменную
Artifact, чтобы обратиться к сохраненному артефакту в системе. значения. Таким образом VQL перебирает информацию во всем пространстве имен.
Леность VQL
Иногда операции которые необходимо выполнить VQL могут требовать значительных ресурсов, например вычисление хэша при поиске файла. Что бы избежать ненужных вычислений в VQL применят ленивый подход обработки запроса. Выполнение функций в секции выбора столбцов происходит только если это необходимо. Давайте рассмотрим следующие запросы
-- Возвращает одну строку и логирует сообщение I run
SELECT OS, log(message="I run") AS Log FROM info()
-- не возвращает данные, не логирует сообщение
SELECT OS, log(message="I run") AS Log FROM info() WHERE OS = "Unknown"
-- не возвращает данные, но логирует сообщение
SELECT OS, log(message="I run") AS Log FROM info() WHERE Log AND OS = "Unknown"На этом примере вы можете видеть, что выполнение функции log произошло только в случае где это необходимо. Во втором запросе функция log не была выполнена потому, что условие WHERE OS = "Unknown" не вернуло строк. Тоже самое должно было случится и в третьем запросе, но мы явно указали необходимость проверки Log WHERE Log AND OS = "Unknown" и для этой проверки VQL выполнил функцию log.
Давайте рассмотрите следующие два запроса
LET path = "c:\Users\**"
SELECT Name,
FullPath,
Size,
hash(path=FullPath).SHA1 AS SHA1
FROM glob(globs=path)
WHERE SHA1 =~ "^1ee"
AND Name =~ "\.exe$"
LIMIT 1
SELECT Name,
FullPath,
Size,
hash(path=FullPath).SHA1 AS SHA1
FROM glob(globs=path)
WHERE Name =~ "\.exe$"
AND SHA1 =~ "^1ee"
LIMIT 1 Первый запрос займет минуты на выполнение, когда второй будет выполнен моментально. При одинаковом результате, объем работы первого запроса несоизмеримо больше второго. Как вы видите в первом запросе вначале происходит вычисление хэша, а потом проверка расширения файла. Во втором запросе порядок действий обратный. В обоих запросах, если первое условие не соблюдается проверка второго не происходит. Получается, первый запрос вычисляет хеш для всех файлов, когда как второй только для файлов соответствующих выражению ".exe$". Такой принцип “ленивого” выполнения запросов позволяет использовать меньше ресурсов и получать результаты быстрее.
foreach()
Один из самых полезных плагинов в VQL это foreach(). С его помощью вы можете комбинировать и обогащать данные из разных запросов. В большинстве случаев foreach() плагин принимает два параметра:
row- "итерируемый" объект, это может быть вложенный/сохраненный запрос или список строк.query- запрос, который будет выполнен для каждой строки изrow.
Таким образом мы можем комбинировать информацию из обоих запросов и использовать информацию из row для обогащения информации из query . Рассмотрите следующий пример:
-- сохраненный запрос, получает информацию о процессах на хосте
LET ps_list = SELECT *
FROM pslist()
WHERE Exe
LIMIT 5
SELECT *
FROM foreach(
-- каждая строка из ps_list применяется при выполнении query
row=ps_list,
query={
SELECT *, Pid,
Ppid,
Exe
FROM stat(filename=Exe)
})Scope который мы можем использовать в основном запросе формируется параметром query. Чтобы отобразить информацию из row её необходимо явно указать в query, как это сделано с Pid, Ppid, Exe, в противном случае эти столбцы будут недоступны основному запросу.
Use Case - Scheduled Tasks
В качестве практической работы, в которой вы можете увидеть на практике как составлять запросы, давайте рассмотрим следующий сценарий:
Получение списка задач из планировщика задач -> вычисление хэша исполняемого файла -> проверка хэша на Virustotal -> отображение информации вместе с результатами проверки.
Нам известно, что задачи планировщика это файлы формата xml, которые хранятся в C:/Windows/System32/Tasks/ . На первом этапе нам необходимо получить список этих файлов.
-- сохраняем путь к файлам в переменную. ** - рекурсивное чтение каталогов
-- (смотрите документацию плагина glob)
LET folder_path = "C:/Windows/System32/Tasks/**"
-- создаем запрос для формирования списка файлов (запрос не будет выполнен
-- до момента его вызова)
LET files = SELECT FullPath FROM glob(globs=folder_path) WHERE NOT IsDirДалее необходимо произвести чтение, преобразование и парсинг xml
-- создадим функцию, чтобы отфильтровать строку объявления XML. В противном случае
-- парсер выведет ошибку.
LET ms_xml_to_normal(data) = regex_replace(
source=utf16(string=Data),
re="<\\?.+>",
replace='')
-- запрос, который произведет чтение и парсинг xml файлов
LET get_xml = SELECT parse_xml(
-- используем локальную функцию
file=ms_xml_to_normal(data=Data),
accessor='data'
) AS XML,
FullPath
FROM read_file(filenames=FullPath)
-- нам интересны команды в которых присутствует путь к исполняемому файлу
WHERE XML.Task.Actions.Exec.Command =~ '^c:'
-- запрос с помощью которого мы соберем информацию из двух предыдущих
LET tasks = SELECT FullPath,
XML.Task.Actions.Exec.Command as Command,
-- вычисляем хэш
hash(path=XML.Task.Actions.Exec.Command, hashselect="SHA1").SHA1 AS SHA1,
XML.Task.Actions.Exec.Arguments as Arguments,
XML.Task.Actions.ComHandler.ClassId as ComHandler,
XML.Task.Principals.Principal.UserId as UserId
-- используем плагин foreach чтобы передать информацию о файлах в запрос, который
-- прочтет и распарсит xml
FROM foreach(
row=files,
query=get_xml)На следующем этапе производим проверку хэша на Virustotal и отображаем результат.
-- используем материализованный LET, чтобы указать VT API Key который необходим
-- для работы артефакта Artifact.Server.Enrichment.Virustotal
LET VTAPI_set <= server_set_metadata(
metadata=dict(
-- укажите ваш API ключ
VirustotalKey="4a903....c386"))
-- запрос произведет проверку хэша с помощью артефакта
-- Artifact.Server.Enrichment.Virustotal
LET VTCheck = SELECT FullPath,
Command,
Arguments,
SHA1,
VTRating,
FirstSeen,
FirstSubmitted
FROM Artifact.Server.Enrichment.Virustotal(Hash=SHA1)
-- основной запрос
SELECT FullPath,
Command,
Arguments,
SHA1,
VTRating
FROM foreach(
-- для каждой задачи row провести проверку запросом query
row=tasks,
query=VTCheck)
LIMIT 10Финальный запрос будет выглядить следующими образом.
Hidden text
LET folder_path = "C:/Windows/System32/Tasks/**"
LET files = SELECT FullPath
FROM glob(globs=folder_path)
WHERE NOT IsDir
LET ms_xml_to_normal(data) = regex_replace(source=utf16(string=Data),
re="<\\?.+>",
replace='')
LET get_xml = SELECT parse_xml(file=ms_xml_to_normal(data=Data),
accessor='data') AS XML,
FullPath
FROM read_file(filenames=FullPath)
WHERE XML.Task.Actions.Exec.Command =~ '^c:'
LET tasks = SELECT FullPath,
XML.Task.Actions.Exec.Command AS Command,
hash(path=XML.Task.Actions.Exec.Command, hashselect="SHA1").SHA1 AS SHA1,
XML.Task.Actions.Exec.Arguments AS Arguments,
XML.Task.Actions.ComHandler.ClassId AS ComHandler,
XML.Task.Principals.Principal.UserId AS UserId
FROM foreach(
row=files,
query=get_xml)
LIMIT 10
LET VTAPI_set <= server_set_metadata(
metadata=dict(
VirustotalKey="4a90....386"))
LET VTCheck = SELECT FullPath,
Command,
Arguments,
SHA1,
VTRating,
FirstSeen,
FirstSubmitted
FROM Artifact.Server.Enrichment.Virustotal(Hash=SHA1)
SELECT FullPath,
Command,
Arguments,
SHA1,
VTRating
FROM foreach(
row=tasks,
query=VTCheck)
LIMIT 10 Таким образом мы выполняем все требования этого задания. Надеюсь этот материал был вам полезен и возможно пригодиться при написании собственных VQL запросов.