
На самом деле, большая доля этих правил не влияет на среду исполнения кода, который вы пишете. Подобные правила невозможно оценить объективно, да это и необязательно, ведь на этом этапе они достаточно произвольны. Однако есть правила «чистого» кода, на которые делают особый упор — это правила, которые можно измерить объективно, поскольку они влияют на поведение кода в среде исполнения.
Если посмотреть на список правил «чистого» кода и вытащить из него правила, которые действительно влияют на структуру кода, то мы получим следующее:
- Отдавайте предпочтение полиморфизму, а не «if/else» и «switch»
- Код не должен знать о внутреннем устройстве объектов, с которыми он работает
- Функции должны быть маленькими
- Каждая функция должна выполнять одну задачу
- Принцип «DRY» — Don’t Repeat Yourself («не повторяйся»)
Эти правила достаточно чётко формулируют то, как должен создаваться конкретный фрагмент кода, чтобы быть «чистым». Но я задам такой вопрос: если мы создадим фрагмент кода, соответствующий этим правилам, какова будет его производительность?
Чтобы создать наиболее предпочтительный пример для реализации чего-то на «чистом» коде, я воспользовался готовыми примерами кода, содержащимися в литературе о «чистом» коде. Таким образом, мне не придётся ничего придумывать, я просто оценю правила защитников «чистого» кода при помощи тех примеров кода, которыми они иллюстрируют эти правила.
В примерах «чистого кода» часто встречаются такие:
<code>/* ========================================================================
LISTING 22
======================================================================== */
class shape_base
{
public:
shape_base() {}
virtual f32 Area() = 0;
};
class square : public shape_base
{
public:
square(f32 SideInit) : Side(SideInit) {}
virtual f32 Area() {return Side*Side;}
private:
f32 Side;
};
class rectangle : public shape_base
{
public:
rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {}
virtual f32 Area() {return Width*Height;}
private:
f32 Width, Height;
};
class triangle : public shape_base
{
public:
triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
virtual f32 Area() {return 0.5f*Base*Height;}
private:
f32 Base, Height;
};
class circle : public shape_base
{
public:
circle(f32 RadiusInit) : Radius(RadiusInit) {}
virtual f32 Area() {return Pi32*Radius*Radius;}
private:
f32 Radius;
};Это базовый класс для фигур, из которого порождается несколько конкретных фигур: круг, треугольник, прямоугольник, квадрат. Далее идёт виртуальная функция, вычисляющая площадь.
Как и требуют правила, мы отдаём предпочтение полиморфизму. Каждая наша функция выполняет только одну задачу. Они компактны. Всё это отлично. Итак, мы получили «чистую» иерархию классов, каждый порождённый класс знает, как вычислять свою площадь и хранит данные, требуемые для вычисления этой площади.
Если мы представим, что используем эту иерархию для выполнения какой-то задачи, допустим, для нахождения общей площади передаваемой серии фигур, то ожидаем увидеть что-то подобное:
/* ========================================================================
LISTING 23
======================================================================== */
f32 TotalAreaVTBL(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += Shapes[ShapeIndex]->Area();
}
return Accum;
}Я не использовал здесь итератор, потому что в правилах не говорится ничего о том, что нам нужно использовать итераторы. Поэтому я решил, что не буду давать «чистому» коду кредит доверия и не стану добавлять никакого абстрагированного итератора, который может сбить с толку компилятор и привести к снижению производительности.
Вы также можете заметить, что это цикл по массиву указателей. Это прямое последствие использования иерархии классов: мы понятия не имеем, какой размер в памяти может занимать каждая из этих фигур. Так что если мы не собираемся добавлять вызов ещё одной виртуальной функции для получения размера данных каждой фигуры и использовать для их обхода какую-то процедуру пропуска переменных, нам понадобятся указатели, чтобы выяснять, где начинается каждая фигура.
Поскольку это накопление, существует циклически порождаемая зависимость, способная замедлить цикл. Так как порядок накопления может произвольно меняться, я для безопасности также написал разворачиваемую вручную версию:
/* ========================================================================
LISTING 24
======================================================================== */
f32 TotalAreaVTBL4(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount/4;
while(Count--)
{
Accum0 += Shapes[0]->Area();
Accum1 += Shapes[1]->Area();
Accum2 += Shapes[2]->Area();
Accum3 += Shapes[3]->Area();
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Если запустить эти две процедуры в простой тестовой обвязке, то можно приблизительно замерить общее количество тактов на фигуру, требуемое для выполнения этой операции:
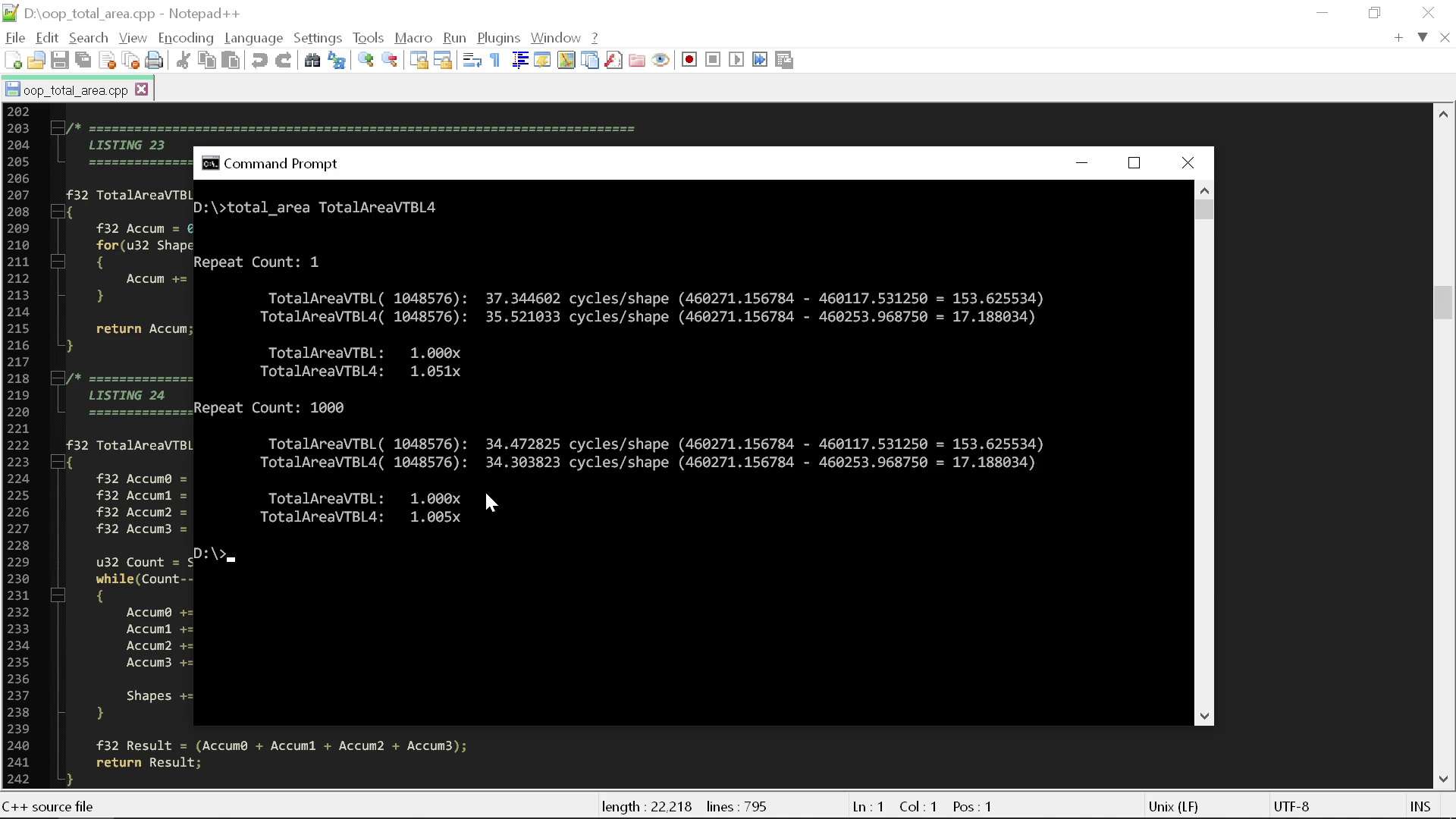
Обвязка хронометрирует код двумя способами. Первый — запустить код только один раз, чтобы показать, что происходит в произвольном «холодном» состоянии — данные должны быть в L3, однако L2 и L1 сброшены, а алгоритм предсказания ветвления ещё не «практиковался» на этом цикле.
Второй способ — многократное выполнение кода, чтобы посмотреть. что происходит, когда кэш и алгоритм предсказания ветвления работают наиболее удобным для цикла образом. Стоит заметить, что оба способа не являются хардкорными измерениями, поскольку, как вы видите, различия настолько велики, что нам не нужно применять какие-то серьёзные инструменты анализа.
Из результата мы видим, что между двумя процедурами нет особой разницы. Для выполнения вычисления площади «чистым» кодом требуется примерно 35 тактов. Если сильно повезёт, это количество иногда снижается до 34.
Итак, 35 тактов — это то значение, которое стоит ожидать получить при следовании всем правилам. Но что же произойдёт, если мы нарушим лишь первое правило? Что, если вместо применения здесь полиморфизма мы просто используем оператор switch? [Лично я не думаю, что оператор switch обязательно менее полиморфический, чем vtable. Это просто две разные реализации одного принципа. Однако правила «чистого» кода приказывают отдавать предпочтение полиморфизму вместо операторов switch, поэтому я использую здесь их терминологию, означающую, что они чётко считают, что оператор switch не полиморфический.]
Ниже я записал точно такой же код, однако вместо использования иерархии классов (а следовательно, vtable в среде исполнения) я написал его при помощи перечисления и типа фигуры, который упрощает всё до одной структуры:
/* ========================================================================
LISTING 25
======================================================================== */
enum shape_type : u32
{
Shape_Square,
Shape_Rectangle,
Shape_Triangle,
Shape_Circle,
Shape_Count,
};
struct shape_union
{
shape_type Type;
f32 Width;
f32 Height;
};
f32 GetAreaSwitch(shape_union Shape)
{
f32 Result = 0.0f;
switch(Shape.Type)
{
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;
case Shape_Count: {} break;
}
return Result;
}Это «олдскульный» способ, которым решались бы подобные задачи до появления «чистого» кода.
Обратите внимание, что поскольку у нас больше нет специальных типов данных для каждого варианта фигуры, то если тип не имеет одного из значений (например, «height»), он просто его не использует.
Теперь вместо получения площади от вызова виртуальной функции пользователь этой структуры получает её от функции с оператором switch: именно этого правила «чистого» кода никогда не рекомендуют делать. Несмотря на это, вы заметите, что код, несмотря на гораздо большую краткость, по сути, остался тем же. Каждый case оператора switch — это просто тот же код, что и в соответствующей виртуальной функции в иерархии классов.
Что касается самих циклов суммирования, то можно увидеть, что они практически идентичны «чистой» версии:
/* ========================================================================
LISTING 26
======================================================================== */
f32 TotalAreaSwitch(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += GetAreaSwitch(Shapes[ShapeIndex]);
}
return Accum;
}
f32 TotalAreaSwitch4(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
ShapeCount /= 4;
while(ShapeCount--)
{
Accum0 += GetAreaSwitch(Shapes[0]);
Accum1 += GetAreaSwitch(Shapes[1]);
Accum2 += GetAreaSwitch(Shapes[2]);
Accum3 += GetAreaSwitch(Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Единственное отличие заключается в том, что вместо вызова функции-члена для получения площади мы вызываем обычную функцию, вот и всё.
Однако вы сразу можете увидеть немедленную выгоду от использования упрощённой структуры по сравнению с применением иерархии классов: фигуры могут просто находиться в массиве, без необходимости указателей. Косвенных действий нет, потому что мы сделали все фигуры одного размера.
Плюс мы получаем выигрыш ещё и в том, что теперь компилятор может точно видеть, что происходит в цикле, потому что он может просто смотреть на функцию GetAreaSwitch и видеть весь путь выполнения кода. Ему не нужно предполагать, что нечто может произойти в какой-то виртуализированной функции вычисления площади, известной только в среде исполнения.
Что же может компилятор сделать для нас благодаря всем этим преимуществам? Если я запущу теперь все четыре фрагмента, то получу такие результаты:

При изучении результатов мы можем заметить кое-что довольно примечательное: всего одно изменение — старомодный стиль кодинга вместо стиля «чистого» кода — дало нам мгновенное увеличение производительности в полтора раза. Это полуторакратное улучшение мы получаем без затрат, нам ничего не пришлось делать, кроме как удалить излишний код, необходимый для применения полиморфизма C++.
То есть нарушив первое правило чистого кода, являющееся одним из его основным столпов, мы способны снизить затраты с 35 до 24 тактов на фигуру, и это подразумевает, что следующий этому правилу код в полтора раза медленнее того, который ему не следует. Если сравнивать на уровне «железа», то требования к производительности снижаются с iPhone 14 Pro Max до iPhone 11 Pro Max. Три-четыре года эволюции оборудования уничтожены, потому что кто-то сказал использовать полиморфизм вместо операторов switch.
Но мы только начали.
Что, если мы нарушим и другие правила? Что, если мы нарушим второе правило — «запрет на знания о внутреннем устройстве»? Что, если наши функции могут использовать знание того, с чем они работают, чтобы повысить свою эффективность?
Если снова взглянуть на оператор switch получения площади, то можно заметить, что все вычисления площадей схожи:
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;Во всех них или ширина умножается на высоту, или ширина на ширину, иногда с коэффициентом наподобие пи, после чего они делятся пополам в случае треугольника или умножаются на пи в случае круга, и так далее.
Это одна из причин, по которым я считаю операторы switch очень удобными (в отличие от защитников «чистого» кода)! Они позволяют очень легко разглядеть паттерн. Если код упорядочен по операции, а не по типу, очень легко изучать его и выявлять общие паттерны. И наоборот: если вы взглянете на версию с классами, то, вероятно, никогда не заметите подобный паттерн, не только потому, что вам помешает большое количество бойлерплейта, но и потому, что защитники «чистого» кода рекомендуют помещать каждый класс в отдельный файл, ещё больше снижая вероятность того, что вы заметите что-то подобное.
Поэтому архитектурно я в общем случае не согласен с иерархиями классов, но дело не только в этом. Единственное, что я хочу сейчас подчеркнуть — мы можем сильно упростить оператор switch, заметив паттерн.
И помните: я не специально выбирал такой пример! Этот пример используют для наглядности сами защитники чистого кода. Поэтому я не выбрал намеренно пример, в котором можно выявить паттерн — просто очень вероятно, что вы сможете это сделать, потому что большинство вещей схожего типа имеют схожую алгоритмическую структуру, поэтому, как и ожидалось, это здесь произошло.
Чтобы использовать этот паттерн, мы можем создать простую таблицу, сообщающую нам, какой коэффициент нужно использовать для каждого типа. Если для типов с одним параметром, например, для круга и квадрата, мы дублируем ширину в высоту, то можно написать существенно более простую функцию для площади:
/* ========================================================================
LISTING 27
======================================================================== */
f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};
f32 GetAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}Два цикла суммирования в этой версии полностью одинаковы, их не нужно изменять, они просто вызывают GetAreaUnion вместо GetAreaSwitch, а в остальном идентичны.
Посмотрим, что произойдёт при запуске этой новой версии и сравнении с предыдущими циклами:
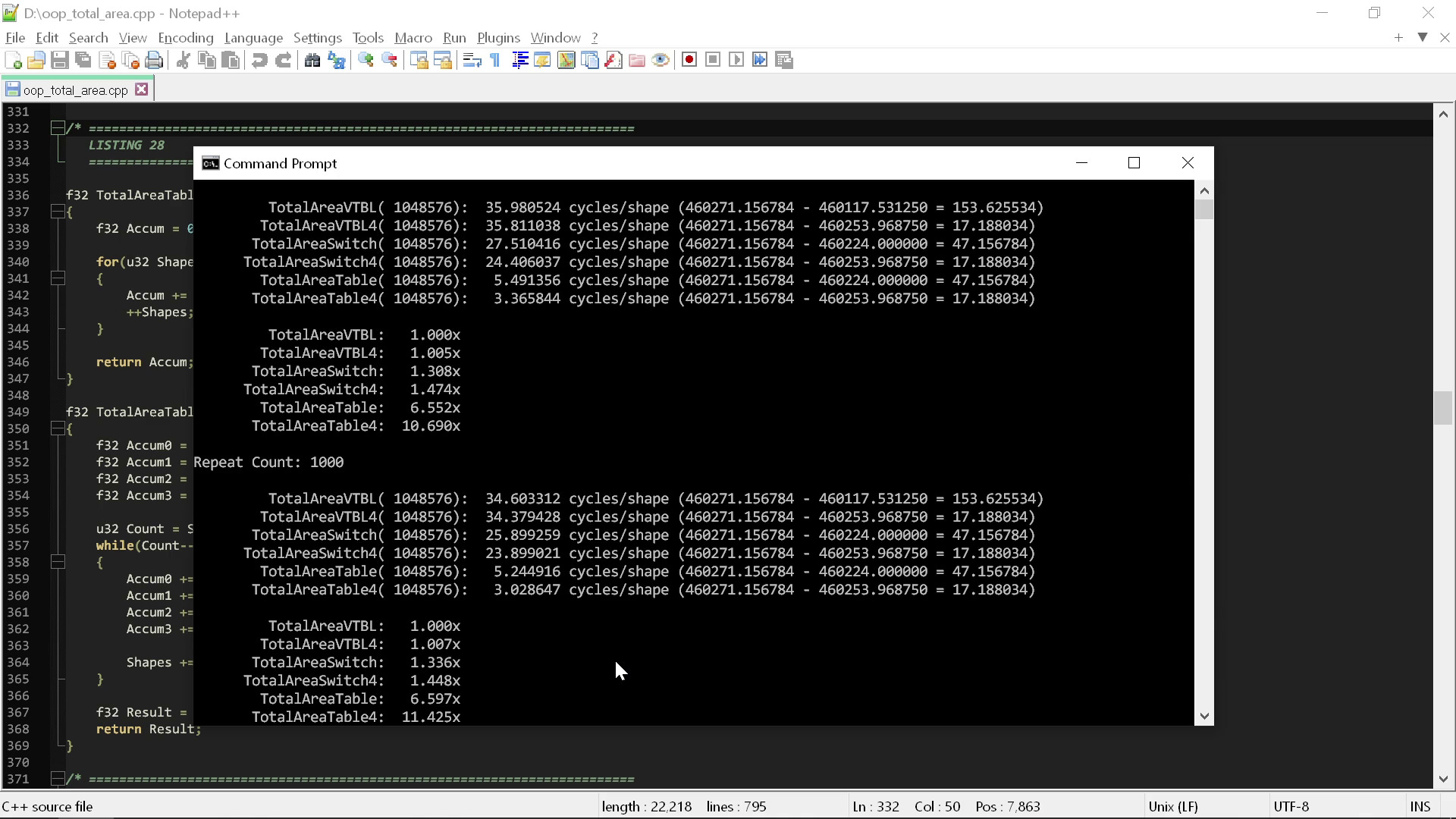
Здесь мы воспользовались тем, что знаем о самих типах, с которыми работаем, по сути, переключившись с мышления на основе типов на мышление на основе функции, получив огромный рост скорости. Мы сделали переход от оператора switch, ускорявшего работу всего в полтора раза, на версию с таблицей, которая в десять или более раз быстрее при решении точно такой же задачи.
И чтобы добиться этого, нам не понадобилось ничего, кроме как одна операция поиска в таблице и одна строка кода! Это не только намного быстрее, но и гораздо проще семантически. Меньше токенов, меньше операций, меньше строк кода.
То есть вместо того, чтобы требовать обязательной неосведомлённости операции о внутреннем устройстве данных и связав модель данных с нужной нам операцией, мы снизили затраты до 3,0-3,5 тактов на серию фигур. Мы получили десятикратное повышение скорости по сравнению с «чистой» версией кода, следующей первым двум правилам.
Десятикратное повышение производительности настолько существенно, что его невозможно даже сравнить на аналогии с iPhone, потому что в бенчмарках iPhone такой разницы уже нет. Если мы опустимся до iPhone 6 (самого старого телефона, встречающегося в современных бенчмарках), то он всего в три раза медленнее iPhone 14 Pro Max. То есть чтобы описать разницу, мы даже не можем больше использовать телефоны.
Если взглянуть на производительность однопоточного десктопного компьютера, то десятикратное повышение скорости — это переход от среднего современного CPU mark до среднего CPU mark аж 2010 года! Первые два правила концепции «чистого кода» уничтожают 12 лет эволюции оборудования.
Но как бы это ни шокировало, мы протестировали это лишь на одной простой операции. Мы практически не пользовались правилами «функции должны быть маленькими» и «функции должны выполнять только одну операцию», потому что работаем с очень простой задачей. А что, если мы добавим ещё один аспект к нашей задаче, чтобы более можно было более непосредственно следовать этим правилам?
Ниже я написал точно такую же иерархию, что и раньше, но на этот раз добавил ещё одну виртуальную функцию, сообщающую, сколько углов у каждой из фигур:
/* ========================================================================
LISTING 32
======================================================================== */
class shape_base
{
public:
shape_base() {}
virtual f32 Area() = 0;
virtual u32 CornerCount() = 0;
};
class square : public shape_base
{
public:
square(f32 SideInit) : Side(SideInit) {}
virtual f32 Area() {return Side*Side;}
virtual u32 CornerCount() {return 4;}
private:
f32 Side;
};
class rectangle : public shape_base
{
public:
rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {}
virtual f32 Area() {return Width*Height;}
virtual u32 CornerCount() {return 4;}
private:
f32 Width, Height;
};
class triangle : public shape_base
{
public:
triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
virtual f32 Area() {return 0.5f*Base*Height;}
virtual u32 CornerCount() {return 3;}
private:
f32 Base, Height;
};
class circle : public shape_base
{
public:
circle(f32 RadiusInit) : Radius(RadiusInit) {}
virtual f32 Area() {return Pi32*Radius*Radius;}
virtual u32 CornerCount() {return 0;}
private:
f32 Radius;
};У прямоугольника четыре угла, у треугольника — три, у круга их нет, и так далее. Я изменю определение задачи: вместо вычисления суммы площадей серии фигур мы будем вычислять сумму взвешенных по углам площадей, которую я определю как единицу, поделённую на единицу плюс количество углов.
Как и в случае с суммированием площадей, для этого нет никаких причин, я просто пытаюсь работать в рамках примера. Я добавил простейшее, что смог придумать, а затем добавил к этому очень простую математику.
Чтобы изменить «чистый» цикл суммирования, мы добавляем необходимую математику и дополнительный вызов виртуальной функции:
f32 CornerAreaVTBL(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += (1.0f / (1.0f + (f32)Shapes[ShapeIndex]->CornerCount())) * Shapes[ShapeIndex]->Area();
}
return Accum;
}
f32 CornerAreaVTBL4(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount/4;
while(Count--)
{
Accum0 += (1.0f / (1.0f + (f32)Shapes[0]->CornerCount())) * Shapes[0]->Area();
Accum1 += (1.0f / (1.0f + (f32)Shapes[1]->CornerCount())) * Shapes[1]->Area();
Accum2 += (1.0f / (1.0f + (f32)Shapes[2]->CornerCount())) * Shapes[2]->Area();
Accum3 += (1.0f / (1.0f + (f32)Shapes[3]->CornerCount())) * Shapes[3]->Area();
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Я мог бы сказать, что это нужно засунуть в ещё одну функцию, добавив ещё один слой косвенных действий. Но опять таки, чтобы не давать «чистому» коду кредит доверия, я оставлю это в явном виде.
Чтобы изменить версию с оператором switch, нужно, по сути, внести те же изменения. Сначала мы добавим ещё один оператор switch для количества углов с case, в точности отражающими версию с иерархией:
/* ========================================================================
LISTING 34
======================================================================== */
u32 GetCornerCountSwitch(shape_type Type)
{
u32 Result = 0;
switch(Type)
{
case Shape_Square: {Result = 4;} break;
case Shape_Rectangle: {Result = 4;} break;
case Shape_Triangle: {Result = 3;} break;
case Shape_Circle: {Result = 0;} break;
case Shape_Count: {} break;
}
return Result;
}Затем мы вычисляем точно так же, как в версии с иерархией:
/* ========================================================================
LISTING 35
======================================================================== */
f32 CornerAreaSwitch(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[ShapeIndex].Type))) * GetAreaSwitch(Shapes[ShapeIndex]);
}
return Accum;
}
f32 CornerAreaSwitch4(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
ShapeCount /= 4;
while(ShapeCount--)
{
Accum0 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[0].Type))) * GetAreaSwitch(Shapes[0]);
Accum1 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[1].Type))) * GetAreaSwitch(Shapes[1]);
Accum2 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[2].Type))) * GetAreaSwitch(Shapes[2]);
Accum3 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[3].Type))) * GetAreaSwitch(Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Как и в версии с общей суммой площадей, код в реализации с иерархией классов и реализации со switch выглядит почти идентично. Единственная разница заключается в вызове виртуальной функции или в выполнении оператора switch.
Перейдя к версии с таблицей, мы сможем увидеть, как здорово смешивать операции и данные! В отличие от предыдущих версий, единственное, что здесь нужно изменить — это значения в таблице! Нам необязательно получать вспомогательную информацию о фигуре — можно объединить количество углов и коэффициент площади непосредственно в таблицу, а код во всём остальном остаётся совершенно таким же:
/* ========================================================================
LISTING 36
======================================================================== */
f32 const CTable[Shape_Count] = {1.0f / (1.0f + 4.0f), 1.0f / (1.0f + 4.0f), 0.5f / (1.0f + 3.0f), Pi32};
f32 GetCornerAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}Если мы запустим эти функции «площадей с углами», то сможем понять, как на их производительность повлияло добавление второго свойства фигур:

Как видите, эти результаты ещё хуже для «чистого» кода. Версия с оператором switch, которая раньше была всего лишь в полтора раза быстрее, теперь быстрее почти в два раза, а версия с таблицей поиска почти в пятнадцать раз быстрее.
Это демонстрирует ещё более глубокую «чистого» кода: чем больше усложняется задача, тем больше эти идеи вредят производительности. При попытке масштабировать «чистые» техники на реальные объекты со множеством свойств подобные вездесущие проблемы падения производительности будут встречаться в коде повсюду.
Чем больше вы используете методологию «чистого» кода, тем меньше компилятор способен понять, что вы делаете. Всё разделено на отдельные программные единицы, спрятано за вызовы виртуальных функций и так далее. Каким бы умным ни был компилятор, он практически ничего не может сделать с подобным кодом.
Хуже того, с таким кодом мало что можете сделать и вы! Как я показывал выше, простые действия наподобие извлечения значений из таблицы и устранение операторов switch реализовать просто, если архитектура вашей кодовой базы основана на её функциях. Если она основана на типах, это сделать гораздо сложнее, а может, даже невозможно без переписывания большого объёма кода.
Итак, мы перескочили с десятикратной разницы в скорости на пятнадцатикратную, просто добавив фигурам ещё одно свойство. Это аналогично возврату «железа» 2023 года в 2008 год! Вместо уничтожения 12 лет мы уничтожаем 14 лет, просто добавив один новый параметр в определение задачи.
Это ужасно само по себе. Но можно заметить, что я ещё не упомянул оптимизацию! Кроме того, чтобы гарантировать, что это не циклически порождаемая зависимость, ради тестирования я ничего не оптимизировал!
Теперь давайте посмотрим, что будет, если пропустить эти процедуру через слегка оптимизированную AVX-версию тех же вычислений:
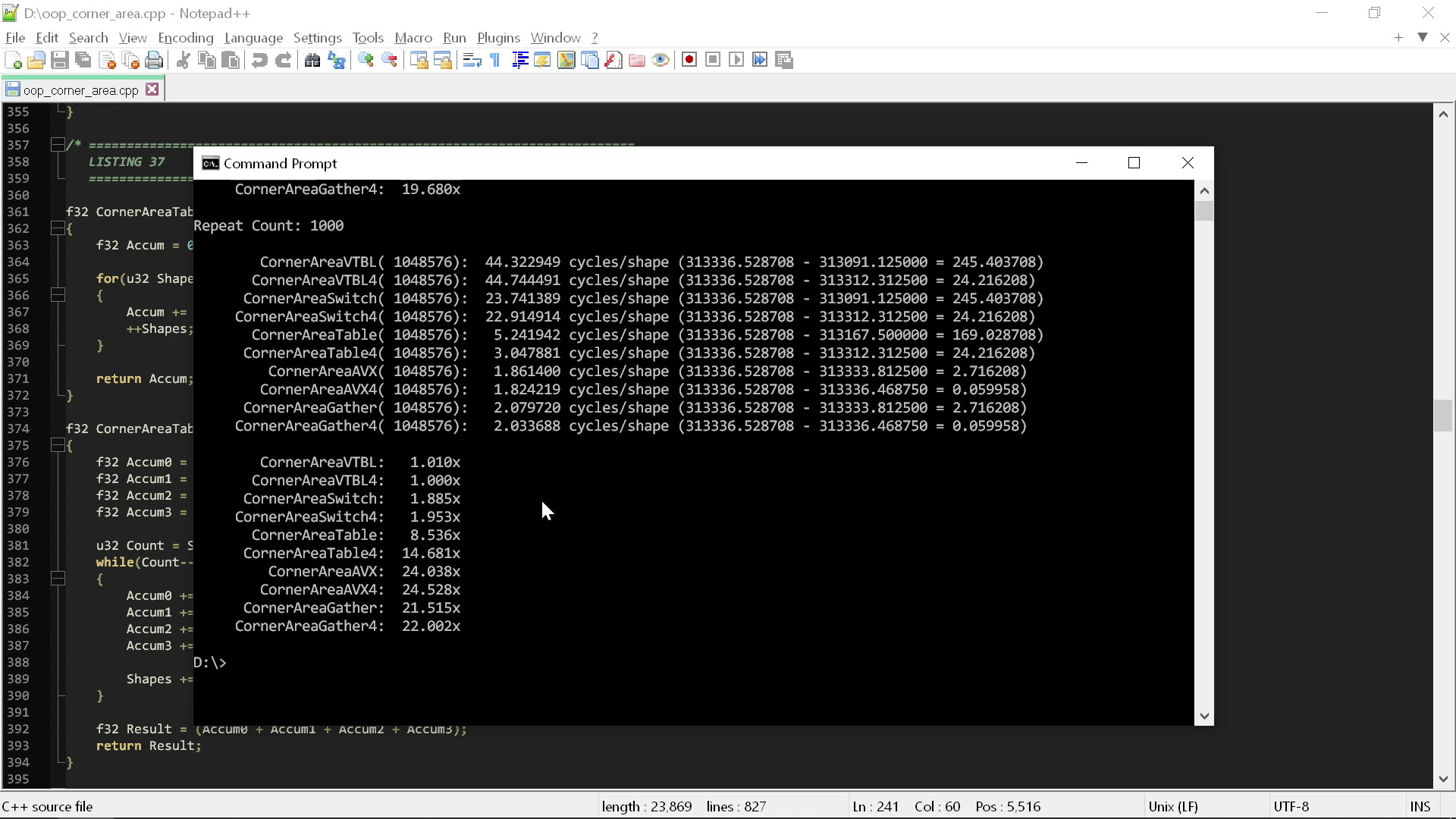
Разница в скорости составляет порядка 20-25 раз, и, разумеется, ни в какой части оптимизированного AVX кода не используется ничего даже отдалённо напоминающего принципы «чистого» кода.
То есть мы выбрасываем четыре правила. А как насчёт пятого?
Откровенно говоря, принцип «не повторяйся» вполне приемлем. Как видно из кода, мы не особо повторялись. Возможно, повторялись, если считать четыре развёрнутые версии сложения, но это нужно было лишь для демонстрации. На самом деле, если вы не проводите подобные измерения, то вам и не понадобятся обе такие процедуры.
Если «DRY» означает нечто более строгое, например, «не создавай две отдельные таблицы, в которых кодируются версии одинаковых коэффициентов», то иногда я не согласился бы с этим, потому что для достаточной производительности нам может понадобиться пойти на это. Но если в общем случае «DRY» просто означает «не пиши один и тот же код дважды», то это кажется разумным советом.
И самое важное то, что нам не нужно нарушать это правило, чтобы писать код с достаточной производительностью.
То есть я утверждаю, что из пяти принципов чистого кода, влияющих на структуру кода, учитывать нужно один, а четыре совершенно точно не нужно. Почему? Потому что, как вы могли заметить, ПО сегодня чрезвычайно медленное. Оно работает крайне плохо по сравнению с тем, как могло бы быстрое современное оборудование выполнять наше ПО.
Если вы спросите, почему программное обеспечение медленное, ответов может быть множество. И то, какой из них самый важный, зависит от конкретной среды разработки и методологии кодинга.
Но для большого сегмента компьютерной индустрии ответ на вопрос «почему ПО медленное» будет таким: «из-за „чистого“ кода». Почти все идеи, лежащие в основе методологии «чистого» кода, ужасно влияют на производительность, и их нельзя использовать.
Правила «чистого» кода были разработаны, потому что кто-то подумал, что они позволят создавать более удобные в поддержке кодовые базы. Даже если бы это так, вы должны задаться вопросом: «А какой ценой?»
Нельзя просто отказаться от десятка или больше лет эволюции производительности оборудования, только чтобы немного упростить жизнь программистов. Наша работа заключается в написании программ, хорошо работающих на оборудовании, которое у нас есть. Если из-за этих правил производительность ПО такая плохая, то они просто неприемлемы.
Мы всё равно можем попытаться выработать эмпирические правила, помогающие в упорядочивании, поддержке и читаемости кода. Это хорошие цели! Но подобные правила для этого не подходят. Их надо перестать повторять, или дополнять большой звёздочкой и сноской «и ваш код будет работать в пятнадцать или более раз хуже».
Комментарии (317)

panzerfaust
13.04.2023 11:35+156В примерах «чистого кода» часто встречаются такие
Я надеюсь, вы понимаете, что занимаетесь софистикой. Если брать какой-то удобный для себя синтетический кусочек кода и потом прожаривать его, то можно доказать вообще любой тезис. И что чистый код вреден, и что чистый код полезен. Да хоть, что кодить китайскими иероглифами быстрее и понятнее, чем латиницей.
Реальный разговор пойдет, когда вы отрефакторите реальный сервис на 100 килострок из своего прода в соответствии с вашим мировоззрением, а потом предъявите не только метрики скорости, но и такие "незначительные" метрики как динамику багов, время на исследование одного бага, время от todo до ready и т.д.

VladimirFarshatov
13.04.2023 11:35+3Был опыт, рефакторил. Товарный агрегатор на Zend 1.8:
было: 32 мегабайта на запрос, 8-10 секунд отклик. БД товаров около 1млн записей в основной товарной таблице. Просто это было "давно"..
стало: 2.5 мегабайта на запрос, 127 запросов в секунду. Железо то же самое, БД стала побольше за время рефакторинга. Плюсом попутно сайт дополнялся новыми фишками.
panzerfaust
13.04.2023 11:35+26Чего именно опыт-то? Превращения структурированного кода в неструктурированный и именно за счет этого драматической прибавки перфоманса? Я тоже однажды джуновский селект с 16 джойнами превратил в селект с 3 джойнами и соответствующим кратным бустом отклика. Только при чем здесь чистый код?
VladimirFarshatov
13.04.2023 11:35+7Опыт превращения кровавого энтерпрайза в "чистый код", с удалением разного рода Фабрик, провайдеров, хелперов провадеров и прочих прокладок. О скоростях выборки из БД речи не было, там все было почти чисто..

Druj
13.04.2023 11:35+42Дайте угадаю, когда пришло время добавлять новый функционал, проект дропнули со словами: "Мы не хотим разбираться в этом неподдерживаемом говне"
VladimirFarshatov
13.04.2023 11:35+1Насколько помню, там закрылась контора, не пережив крах печатных СМИ ..
panzerfaust
13.04.2023 11:35+17Опять же: софистика. Все страшные слова типа "фабрик" и "провайдеров" это признаки ООП в первую очередь, а не чистого кода. Иногда крайне херового ООП с щепоткой карго-культа и "надо потому что надо". Чистый код тут не при чем, и более того, он не привязан к какой-то конкретной парадигме. Возможно,о нем думали, возможно нет - сейчас уже не установишь. Вы сами придумали этот тезис и сами побороли.

javalin
13.04.2023 11:35+2Фабрики, хелперы и провайдеры замедляли на 4 порядка запрос? Что-то с трудом верится, честно говоря.. Больше похоже на то, что была удалена часть функционала, который перестал использоваться, или же был добавлен "на всякий случай"..
VladimirFarshatov
13.04.2023 11:35Легко. Откажитесь от Active Record при выборке из 50+ таблиц сущностей, создаваемых через фабрику, которая принимает сервис получения данных в БД через хелпер отбраковки записи, который на каждой итерации цикла сортирует весь rowset заново и будет вам щастье. Обработка по сути тех же запросов, объем таскаемых данных из сервера БД может даже и вырасти.

Fen1kz
13.04.2023 11:35+10Ну вот так всегда. Приходит такой весь в белом пальто, говорит "щас я от всех провайдеров и фабрик избавлюсь", а по факту избавляется от AR на сложных запросах. (-_- )
Ну самому не стыдно так кликбейтить?VladimirFarshatov
13.04.2023 11:35Избавлялся много от чего. Перечитайте, в т.ч. и от пересортировки набора, полученного из БД. Сколько времени занимает выборка 1000 строк и ее пересортировка на каждой операции перебора в цикле?
Стыдно должно быть Вам, уцепиться на AR и далее не читать. AR была далеко не единственной и может не самой главной проблемой.
panzerfaust
13.04.2023 11:35+2Так при чем тут чистый код, напомните пожалуйста? Кто из адвокатов чистого кода дает советы макаронить паттернами? Или там в авторах коммита лично Мартин с Фаулером?

WASD1
13.04.2023 11:35+6Я рефакторил библиотеку DSL-языка на 10 КLoC (это включая заголовки) на С \ CPP.
Заменил полиморфизм свичами (defaul проверял экзостив в рантайм), списки массивами (для этого надо иметь нерасширяемый тип в заголовке библиотеке).
Ускорение в типовом случае в 5-7 раз (после сборки с -lto).
Значимых багов (после вылавливания изначальных с помощью тестового генератора) найдено не было. И уж точно не помню багов как-либо связанных с переписыванием.
Понятность кода после разворота динамических вызовов в свичи повысилась.
klvov
13.04.2023 11:35+24Понятность кода после разворота динамических вызовов в свичи повысилась.
Хехе, я как-то пошутил, что, мол, полиморфизм - это такой архитектурный подход к построению программ, который нужен для того, чтобы чтения исходного кода было недостаточно для понимания, как ведет себя программа, и, чтобы это понять, надо ее обязательно запустить. Сейчас мне кажется, что в этой шутке оказалась занимающая непропорционально большое место доля правды.

PsyHaSTe
13.04.2023 11:35+2А "Чистый код" и "ООП" связаны положительно? Выпиливание динамического диспатча не делает код менее чистым, зачастую даже наоборот. Поэтому ваш пример никак не доказывает/опровергает упомянутые тезисы.
В современных языках можно иметь статический диспатч для открытого множества типов который часто будет даже лучше свитча, если бранчинг известен на топлевеле (ну или хотя бы на 1 левел выше текущего). А что может быть лучше бранча? Его отсутствие.

0xd34df00d
13.04.2023 11:35+12Подавляющее большинство людей понимает под чистым кодом абстрактные фабрики декораторов и прочий GoF. Одноименная книга, собственно, тоже про какую-то ООпорнографию на джаве. Поэтому, да, похоже, что положительно.
panzerfaust
13.04.2023 11:35+7А еще подавляющее большинство людей понимает под квантовой физикой смешные шутки про полудохлого кота.
А "одноименная книга", конечно, написана с примерами на джаве. Но про ООП там процентов 5 текста. А во всем остальном язык меняется хоть на си, хоть на ерланг без потери смысла.
0xd34df00d
13.04.2023 11:35+1А еще подавляющее большинство людей понимает под квантовой физикой смешные шутки про полудохлого кота.
Разница в том, что это подавляющее большинство по факту никак не влияет на развитие квантовой физики и не вносит в неё никакой вклад, а вот эти вот с GoF — вносят своё понимание чистого кода в кодовые базы.
А во всем остальном язык меняется хоть на си, хоть на ерланг без потери смысла.
Ну ерланг я не знаю, чтобы так утверждать, но те сколь угодно нетривиальные вещи, про которые Мартин говорит (не уровня «называйте переменные понятно» — это вообще для кого?), они в основном ориентированы на ООП.

Ndochp
13.04.2023 11:35Переносил на 1С. Без ООП отваливается процентов 50. Ну или эмулируется такими хаками, что чистым это не назвать.

gatoazul
13.04.2023 11:35+6Если в языке есть анонимные функции с замыканиями, половина этих самых паттернов становится вообще не нужны.
Поэтому ее правильное название "Костыли для Джавы и других языков с сомнительным ООП"*.
*Сомнительным, потому что для Смоллтолка все это тоже вряд ли нужно.
panzerfaust
13.04.2023 11:35половина этих самых паттернов становится вообще не нужны.
Если бы вы читали "Чистый код", то знали бы, что там не про паттерны.
Если в языке есть анонимные функции с замыканиями
То там ничуть не меньше возможностей наговнокодить, накостылить и невелосипедить чем в джаве. Говнокодит не язык и не парадигма, а человек.
0xd34df00d
13.04.2023 11:35+2То там ничуть не меньше возможностей наговнокодить, накостылить и невелосипедить чем в джаве. Говнокодит не язык и не парадигма, а человек.
Я как-то эмпирически заметил, что чем больше в языке возможностей для контроля эффектов, тем сложнее в нём говнокодить и тем проще писать нормально.
gatoazul
13.04.2023 11:35+1Мой комментарии относился к книге банды четырех.
Писать плохо можно, разумеется, на любом языке, включая Go *
*Язык, проектировавшийся по принципу деревянных колодок, дабы максимально ограничить программиста.

ermouth
13.04.2023 11:35Насчёт Эрланга я бы не горячился, там же вся фишка в паттерн-матчинге, и он что из case-оф, что из function clause-оф (это когда функция с одним и тем же именем несколько раз определена для разных масок аргументов) порождает практически идентичный байт-код для beam-машины.
То-есть по-любому будет небыстро )

neyronon
13.04.2023 11:35Разве "Чистый код" получил популярность не после книги дяди Боба? В этой его книге про GoF почти ничего нет, на сколько я помню. Паттерны в другой его книге по архитектурам рассматриваются.
PsyHaSTe
13.04.2023 11:35+1Ну я ровно потому и говорю. В таком случае написание чистого кода на всяких там хачкелях или растах получается невозможно — там же нет "ООП как джава". Что выглядит довольно "ООП-центристским" взглядом как ООП как уберпарадигму со снисходительным взглядом на остальных
WASD1
13.04.2023 11:35Вы наверное хотели адресовать это к человеку выше?
Потому, что там был хитрый вопрос "вот выпилите ООП в кодовой базе на 100KLoC тогда поговорим" - и ответ "вот выпилил на проде в базе 10KLoС, доволен".
И да я так не считаю (часто Хаскель за счёт отделения кода от данных чудо как хорош, часто Rust за счёт управления ошибками (близко к аппаратуре) великолепен).
Но часто ООП очень полезен (иначе dyn в Rust не завозили бы).Upd.
В современных языках можно иметь статический диспатч для открытого множества типов который часто будет даже лучше свитча
Сдаётся мне мы как-то сильно по разному это понимаем, ну или вы забыли (*) и подпись мелким шрифтом.
PsyHaSTe
13.04.2023 11:35+27Да меня с одного заголовка вынесло. Что разбиение на функции что-то там автору замедляет. То что атрибут inline изобрели ещё 50 лет назад он видимо не слышал.
Пишу радостно маленькие функции, почти все приложение склеивается в один большой main (и нет, я не идиот который развесил кучу инлайнов, компилятор просто думает что так выгоднее).
Все эти срачи "чистый код зло" каждый раз умиляют. Чистый код может и зло, но с ним есть время на то чтобы побенчить профайлером и потюнить узкие места. А фанат "пили быстро" мало что пилить неподдерживаемую фигню, так ещё и фигарит 2 недели суперфункцию по эффективному парсингу структурки из файла, только чтобы потом на отвали написать запрос в базу (который надо было делать ещё вчера, но он слишком замотался оффсеты считать и отлаживать, и времени думать тут нет), которая будет в мульон раз больше жрать на каждый запрос чем суммарная выгода от его реализации парсинга за всю свою жизнь. Которую причем придется выкинуть когда изменятся требования.
Популистская статья с фальшивым сбрасыванием покровов.

isadora-6th
13.04.2023 11:35+1Because the meaning of the keyword inline for functions came to mean "multiple definitions are permitted" rather than "inlining is preferred"
https://en.cppreference.com/w/cpp/language/inline (since C++17). Т.е. во всех современных проектах, (кроме тех, где решили не переезжать)
Да, я сам недавно узнал, что у inline ныне другое значение. Так что inline в 99% случаев автоматический и если он не сам, то он уже никак (я практически не встречал компилятор-specific
__force_inline).Ну и маленькие функции (не виртуальные) прекрасно автоматически инлайнятся, индирекция за счет виртуальных коллов иногда убивает потенциал инлайнинга.
https://stackoverflow.com/questions/2130226/inline-virtual-function
Я не копал, насколько модерновые компиляторы "clever", но мне все еще кажется, что если у вас цепочка вызовов раскидана по TU, то LTO не осилит поинлайнить сложные случаи на компиляторах в 2023. Тут могу быть неправ.
Без -O1 не инлайнит вообще ничего, а значит дебаг сборки медленнее от количества строк, что может в целом привести к неверным выводам. Поэтому лучше бы автор мерял на -O1. Разница из-за виртуализации в 10 раз это немного перебор.
В любом случае "чистокодовый подход" у меня ассоциируется с ООП-абстрактными-фабриками, которые несколько спорные например: FizzBuzzEnterpriseEdition.
Я кстати недавно почитал "Чистый Код", их абсолютно понятные примеры на Java с листингом на 7 страниц и примечанием, что автор реализовал этот же функционал на pyhon в 5 раз короче. Я бы поспорил про то, что более длинное но "чистокодовое" решение лучше [читаемее, поддерживаемее, понимаемее] более короткого.
Ну и люди любят делать отвратительные OOP-стайл решения там, где достаточно просто функции. Вообще я считаю, что проникновение в культуру C++ программистов Java подхода немного нехорошо.
PsyHaSTe
13.04.2023 11:35+3Да, я сам недавно узнал, что у inline ныне другое значение. Так что inline в 99% случаев автоматический и если он не сам, то он уже никак (я практически не встречал компилятор-specific __force_inline).
Это от языка зависит. Например:
Inline attributes do not guarantee that a function is inlined or not inlined, but in practice, #[inline(always)] will cause inlining in all but the most exceptional cases.
Я на своей практике в эти "мост эксепшонал кейзес" ни разу не упирался, даже километровые функции в стни строк с кучей логики спокойно инлайнились.
Ну и маленькие функции (не виртуальные) прекрасно автоматически инлайнятся, индирекция за счет виртуальных коллов иногда убивает потенциал инлайнинга.
Динамический дисптч — зло, всегда функции должны быть статические.
В любом случае "чистокодовый подход" у меня ассоциируется с ООП-абстрактными-фабриками, которые несколько спорные например: FizzBuzzEnterpriseEdition.
Это общепринятый биас, тем не менее считаю что с ним нужно бороться)
Я кстати недавно почитал "Чистый Код", их абсолютно понятные примеры на Java с листингом на 7 страниц и примечанием, что автор реализовал этот же функционал на pyhon в 5 раз короче. Я бы поспорил про то, что более длинное но "чистокодовое" решение лучше [читаемее, поддерживаемее, понимаемее] более короткого.
Чистокод это книга для джунов, в которой довольно бескомпромиссно высказыаются многие спорные тезисы. Но суть именно в том что она для джунов которые не умеют взвешивать за и против, поэтому лучше их научить всегда делать одно и то же, и когда подрастут смогут более критически относиться к многим советам. В универе мне книга казалась откровением, например пункт "если вы пишете комментарий значит вы не смогли нормально обозвать переменные и функции" был прям разрывом шаблона, особенно на фоне лекций про важность комментариев от нашей профессуры.
0xd34df00d
13.04.2023 11:35Но суть именно в том что она для джунов которые не умеют взвешивать за и против, поэтому лучше их научить всегда делать одно и то же, и когда подрастут смогут более критически относиться к многим советам.
Может, это моя мизантропия, но люди как-то в среднем паршиво прокачивают критическое отношение с возрастом (что паспортным, что джуново-синьорным).
В универе мне книга казалась откровением, например пункт "если вы пишете комментарий значит вы не смогли нормально обозвать переменные и функции" был прям разрывом шаблона, особенно на фоне лекций про важность комментариев от нашей профессуры.
Одна апелляция к авторитету выбила другую. А прикинь, если б обеих не было?
PsyHaSTe
13.04.2023 11:35+1Одна апелляция к авторитету выбила другую. А прикинь, если б обеих не было?
Почему-то все системы обучения построены по этому принципу. Например в младших классах меня били линейкой по руке за запись "2 — 5" ведь "из меньшего нельзя вычитать большее!!". Это был закон. Потом через пару лет оказалось, что на самом деле можно, но вот корень из отрицательных чисел снова оказалось брать нельзя. Ну и так далее.
Почему-то во всех образовательных системах что я знаю предполагается что человеку сначала надо дать простой и понятный императив, а потом про нюансы излагать.


Knightt
13.04.2023 11:35+66чистый код - это не про производительность.. это про процесс(!) разработки, где есть несколько команд разработки, несколько лет поддержки сложного с точки зрения бизнес-логики кода, увольнения, найм новых сотрудников на допил кода без документации...
п.с. надеюсь вы по городу ездите со скоростью 200 км/ч. Ведь нафиг эти ПДД - можно же быстрее /s

Ru6aKa
13.04.2023 11:35+4Если на чистый код смотреть только как на процесс, то микросервисная архитектура будет "идеальным" чистым кодом, а это не так.
VladimirFarshatov
13.04.2023 11:35+13Это типичная отговорка авторов "кровавых энтерпрайзов".. Как правило они тупо не умеют в "хайлоад", да и вообще уже несколько раз слышал "программист не должен смотреть на эффективность кода".
Не бывает "сложного" с т.з. "бизнеса" кода, т.к. бизнес практически везде один и тот же. Просто поверьте моим 40+ лет в разработке. ;)
п.с. Не уместное сравнение. Правила ПДД - это техника безопасности, которая написана кровью людей. Бизнес и энтерпрайз с "правилами" - это о другом.
Впрочем .. сами по себе правила чистого кода - ни есть ни добро ни зло. Это всё те же рекомендации (Карл!) всё того же модульного программирования, начиная с книжек Дейкстры и Вирта. А вот то, как их сейчас навязывают (Карл!) новичкам, то зовется иначе:
Заставь дурака Богу молиться, он и пол пробьет и лоб расшибет. Статья как раз про это.
WASD1
13.04.2023 11:35Не бывает "сложного" с т.з. "бизнеса" кода,
Ну вот я не согласен с вами. Как писал выше - переписывал библиотеку DSL-языка с полиморфизма на струкруты + switch.
Но это очень "алгоритмический" код. А вот бизнес-логику я бы так переписывать не стал - я не могу прямо определить что есть "бизнес-логика" что есть "алгоритмы". Но когда работаешь с кодом прям чувствуется.
nronnie
13.04.2023 11:35+1У меня есть подозрение, что если объекты для полиморфного вызова брать из заранее созданной таблицы синглтонов, то такой полиморфный вызов вполне может оказаться даже быстрее switch.
isadora-6th
13.04.2023 11:35У вас остаётся индирекция за счет того, что размер объекта "динамический" и его нельзя "просто сложить в вектор".
Ну и индирекция за счет девиртуализации вызова. Поэтому время создания объекта не очень "роляет".
Даже если удалить этот оверхед, и как-то сохранять указатели на конечные реализации функций, то у вас все равно будет switch на поиск нужного указателя по RTTI [или решения на if* / std::unordered_map<>].
Быстрей не будет, возможно сопоставимо.
Предположения сделаны из того, что инлайнинг не возможен т.к. типы в контейнере определяются на рантайме и оптимизации девиртуализации на комайл-тайме не происходит.
nronnie
13.04.2023 11:35+2Вызов виртуального метода не требует RTTI. Отличие от вызова невиртуального только в том, что для невиртуального адрес вызова сразу прописывается в скомпилированном коде, а для виртуального берется из таблицы VTBL (по заранее известному смещению). Вот и получаем, например, что у нас всё что нужно это взять из готовой таблицы/словаря по индексу или ключу указатель на объект, а потом взять адрес метода из его VTBL. А switch наоборот развернется в цепочку if/else по которой шагать придется пока нужное условие не найдем.

ksbes
13.04.2023 11:35+1А switch наоборот развернется в цепочку if/else по которой шагать придется пока нужное условие не найдем.
Не всегда. С енумами и другими интами — будет сразу переход по смещению. Именно поэтому в статье всё ускоряется.
WASD1
13.04.2023 11:35Я не очень понимаю как это может быть устроено у вас с "синглтоном".
Есть "статический полиморфизм" (это по сути шаблоны / трэйты + мономорфизация)
Есть D2S фаза компиляции (у бинарных трансляторов и JIT-компиляторов), но она никак не привязана к "синглтону" - она просто собирает статистику по dynamic call destination и если это 1-2-3 варианта - просто вставляет статические джампы + ветка "не смогла".
А что у вас написано (в частности при чём тут синглтон) - я не понимаю.
ПС
При dynamic call сразу несколько сложностей:
1. Прочитать адрес вызова из VMT (в java к стати у объекта может быть целый вектор VMT а не одна) - из-за этого у java он скрыт за отдельной индирекцией.
2. предсказателю переходов намного сложнее работать с динамической информацией.
Она же скрыта за машинерией получения VMT, а не лежит по конкретному смещению +field_offset у объекта.

BugM
13.04.2023 11:35+5Это типичная отговорка авторов "кровавых энтерпрайзов".. Как правило они тупо не умеют в "хайлоад",
Шутите? Энтерпрайз умел в хайлоад еще задолго до нас.
Скорее кроме него никто не умеет. Так чтобы и хайлоад и надежно и поддерживаемо десятилетиями.
да и вообще уже несколько раз слышал "программист не должен смотреть на эффективность кода".
В среднем да. Ну вот есть серверный продакшен код который работает 10мс на запрос, на продакшен нагрузке потребляет в сумме 10 ядер, еще 10 ядер в запасе под него держим. Есть способ так его переписать чтобы он работал в 10 раз быстрее. Нужно это делать? Нет.
VladimirFarshatov
13.04.2023 11:35Шутите? Энтерпрайз умел в хайлоад еще задолго до нас.
До Вас - поверю легко. В ИТ с 1979года. И Хайлоад в виде дравйвера EGA для 286 компа с отрисовкой 12-16 кадров в секеунду - моя работа. Врядли у Вас получится быстрее. Для справки: вышедшая чуть раньше Windows 3.1 ещё долго рисовала 2 кадра в секунду. Впрочем .. http://www.planetaquarium.com/library/innokentii1246.html
Писалось нами по тем событиям.. ;)
BugM
13.04.2023 11:35+14Этот ваш код к хайлоаду не имеет никого отношения. Да и вообще хайлоад со скоростью работы бизнес логики почти не связан.
Хайлоад это балансировка и шардирование. Ну и выбор разумных архитектурных решений. Код при этом может быть почти любым. Квадратов нет и хорошо.
Исключения конечно же есть. Но это как обычно процентов 10 кодовой базы максимум. Типичная бизнес логика стоящая под тысячами РПС может быть написана с точки зрения производительности на чем угодно и как угодно. И точно без обращения внимания на микрооптимизации.

sumanai
13.04.2023 11:35+8Хайлоад это балансировка и шардирование.
Ощущение, что эту позицию продвигают облачные провайдеры, которым это выгодно. В итоге проекты, которые могли бы крутиться буквально на одной виртуалке, раскатывают на десятки инстансов с соответствующей оплатой.
BugM
13.04.2023 11:35+8Я к облачным провайдерам не имею никакого отношения. Верю что бывает всякое.
При этом есть гигиенический минимум:
На одной виртуалке крутиться не может ничего. Два инстанса, желательно географически разнесенных, это абсолютный минимум. Для вообще всего в проде.
Перед ними должен стоять какой-то балансировщик. Естественно тоже два инстанса минимум. По тем же причинам. Балансировщик может быть один на несколько ваших приложений. Но тут уже зависит от конкретики.
За ними должна стоять какая-то БД. С аналогичными правилами. С учетом особенностей многих БД вероятно минимум будет три хоста. А баз бывает больше одной, вы же наверно хотите какой-нибудь Редис кеш в дополнение к основной SQL БД?
Где-то рядом должен быть мониторинг всего этого. Опять два хоста минимум. Отдельных хоста, чтобы любые проблемы прода на него никак не влияли. Лететь без приборов в случае проблем с продом совсем ужасно.
Вылет любого одного (если вы хосты начинаете считать сотнями, то более чем одного. опять зависит от конкретики) хоста не должен сказываться на пользователях никак. Увеличение времени ответа процентов на 20 это должно быть максимальным влиянием на пользователей. Без любых ручных действий. Нагрузку считаем соответственно.
Вот так и набирается.... Если вы конечно серьезный хайлоад, отказоустойчивый сервис делаете.
sumanai
13.04.2023 11:35Я к облачным провайдерам не имею никакого отношения.
А я и не конкретно про вас, я про общие настроения в индустрии.
Вот так и набирается....
А потом падает из-за строчки в конфиге.
А серьёзный хайлоад в 99% случаев просто не нужен.BugM
13.04.2023 11:35+4А потом падает из-за строчки в конфиге
Бывает. Неплохо помогает постепенная выкатка чего угодно. Сначала один инстанс, минут через 15 второй. 15 минут сидим смотрим мониторинги и держим палец над кнопкой немедленного отката. Инфраструктура позволяющая так откатывать тоже нужна. Забыл совсем.
А серьёзный хайлоад в 99% случаев просто не нужен.
Посмотрите начало ветки. Там первое сообщение и мой ответ про хайлоад. Кому не надо, тем не надо.
sumanai
13.04.2023 11:35-1Инфраструктура позволяющая так откатывать тоже нужна. Забыл совсем.
И ломается она той же строчкой, ибо всё красиво и централизованно.
Посмотрите начало ветки. Там первое сообщение и мой ответ про хайлоад.
Да, вижу. Кстати, надо бы код оптимизировать, чтобы держать про запас 1 ядро и 1 работало )
BugM
13.04.2023 11:35И ломается она той же строчкой, ибо всё красиво и централизованно.
Она так же задублирована и так аккуратно обновляется. Ну и про любые обновления инфраструктуры принято всех предупреждать, чтобы люди свои выкатки по возможности перенесли.
Да, вижу. Кстати, надо бы код оптимизировать, чтобы держать про запас 1 ядро и 1 работало )
Пусть будет два работать и два стоять. Или даже десять работать и десять стоять. Это даже по ценам Амазона долларов 400-500 в месяц. При желании можно найти в разы дешевле.
Вот когда речь о сотнях можно подумать на тему: А не стоит ли что-нибудь оптимизировать? Десятки процентов оптимизации уже становятся видны в бюджете.
sumanai
13.04.2023 11:35Пусть будет два работать и два стоять. Или даже десять работать и десять стоять.
А потом программы тормозят и требуют нового железа ((
BugM
13.04.2023 11:35Это так не работает. Я про серверный софт. Там свои критерии производительности и свои расчеты железа.
Десктопный софт это совсем другой мир, про который я почти ничего не знаю. И не готов его обсуждать.
nronnie
13.04.2023 11:35+1А потом программы тормозят и требуют нового железа
Железо постоянно дешевеет, а разработчики наоборот дорожают.

santjagocorkez
13.04.2023 11:35+2Ну и про любые обновления инфраструктуры принято всех предупреждать, чтобы люди свои выкатки по возможности перенесли
Какая архаика, аж олдскулы свело. Пацанское решение будет такое:
Scheduled mutually exclusive deployments
Каждый артифакт имеет просчитанное с запасом время на деплой
При планировании выкатки деплоя другие деплои не могут встать в план, если время выкатки будет хоть частично перекрываться
При внеочередной выкатке инфраструктуры могут быть варианты, когда уже запланированные деплои отменяются, ответственные оповещаются
Наоборот тоже работает: инфраструктура не может вкорячиться в план, если заденет по времени хоть один артифакт
Само собой, даже внеочередной деплой "срочно, прямо сейчас же" не может начаться тогда, когда уже идёт хотя бы один конфликтующий деплой
В общем, примерно, как в календаре встреч, а хотя бы даже в том же аутлуке. Только там любой конфликтует с любым обычно.
BugM
13.04.2023 11:35+1А вы не пробовали добавить немного хаоса? Ну хочет разработчик катнуть релиз какой-то внутренней обработки чего-то сейчас. Все положенные приседания с ревью тестами и оками он сделал. Пользователей не задевает. Как работало, так и будет работать. Ну и пусть катит.
Мне нравятся системы со специально заложенной в них долей хаоса. Так жить приятнее и свободнее. И люди растут в таких системах лучше, а увольняются реже.
При этом надежность остается на достаточном уровне. Большое красное предупреждение что мы тут инфру сейчас обновляем, аккуратнее может пойти не так все что угодно с явной кнопкой "Ок, я понимаю что делаю". Люди просто так такие предупреждения игнорируют редко. И если что у них можно спросить: Зачем ты это сделал? О чем ты думал? Это точно срочно катить надо было несмотря на предупреждение?
Долю хаоса всегда можно регулировать. Разработчики начали ерунду творить потому что можно? Гайки закручиваем. Никто не проявляет никакой инициативы и пишет строго то что сказали без всяких идей и предложений? Гайки откручиваем.
0xd34df00d
13.04.2023 11:3515 минут? В одной компании, славящейся околонулевым даунтаймом, где я работал, ключевые сервисы выкатывают на следующую группу через неделю, и разных групп инстансов по очередности штуки четыре.
BugM
13.04.2023 11:35Не надо сразу людей пугать. Даже 15 минут это в бесконечность раз лучше чем катить сразу на все. Начинать надо с малого.

vkni
13.04.2023 11:35+1Между прочим, неделя — это не просто так. Это потому, что дни недели существенно разные. Кстати, вот буквально пару недель назад объяснял популярно, почему надо писать прототипы. И почему прототип на Хаскеле, написанный за 2 недели, сэкономил пару-тройку месяцев.
nronnie
13.04.2023 11:35+1Балансировка и шардирование это не только про производительность, а еще и про надежность. А иначе так-то было бы дешевле вместо двух одинаковых нод развернуть одну в два раза более мощную.
VladimirFarshatov
13.04.2023 11:35-2Хайлоад - это всё то, что работает на таком железе, которое не тянет задачу "по определению" по своим возможностям. Редактор Emacs, который в свое вмеря обрабатывал мегабайтные документы, в 64 килобайтах памяти и даже без "жестких дисков" которых ещё не было, да тот же Лексикон как ни странно, Тор.., внезапно тот же Хайлоад. Doom1, Doom2 в которых движок на 486 процах лочил свой драйвер в кеше проца, идея от Дейва Тейлора, насколько помню из переписки.. это всё Хайлоад. Этот драйвер тоже писался для игровой индустрии..
А вот шардирование и балансировка - это ни разу НЕ хайлоад, а распараллеливание отклика с неизбежным ростом латенси. Это high popularity - рост посещений.

Didimus
13.04.2023 11:35Хайлоад это когда у вас тормозит. Для кнопочного телефона тетрис может быть хайлоадом
VladimirFarshatov
13.04.2023 11:35+1Верно. High Load == "высокая нагрузка (на железо)". Когда сложность задачи превышает возможности железа. High Popularity -- высокая посещаемость. Количество запросов (обращение) превышает возможности железа их обслуживать.
Как вариант решения - обработка параллельными потоками, в т.ч. и даже(!) на одном железе с виртуализацией или без таковой. Как самый примитивный пример: популярная связка Appache + Nginx. Оставьте один поток-обработчик, сколько пользователей обслужит такой сервер? А 5, а 10? Мало и не справляемся, но загрузка ядер невелика? Шардируем ноду в виртуалках. Железо одно, а "машин" стало больше. Все равно мало? Ставим отдельное железо.
попутно(!) решаем вопрос надежности...
Только тут, вопрос статьи тоже интересен. При каких параметрах популярности ресурса придется "шардировать"? Из выше следует:
Yii2, core2duo = 190 запросов в секунду на двух ядрах с 5-ю потоками (кажется, не помню). 191-й запрос уже требует шардирования.. 190rps это 684_000(!!!) запросов часовой "пиковой" нагрузки. Ну ок, поделим на "сберовские" 300 обращений к серверу на страничку == 2280 активных пользователей в час или около миллиона посещений в месяц.. Много таких ресурсов в Сети?
ussr.monster == 2500 запросов в секунду. Далее продолжать? Впрочем, можете провести оценочную прикидку самостоятельно. Методика выше. ;)
Особенно последнее время, очень часто слышу "У нас жуткий хайлоад и шардирование" .. смотришь на сайт, а там .. "три пленных немца" в статистике: директор, бухгалтер, пара менеджеров, сисадмин и программист по 5 раз в сутки. Сайт с посещаемостью .. до 100 пользователей (ботов много больше)..
sumanai
13.04.2023 11:35Мало и не справляемся, но загрузка ядер невелика? Шардируем ноду в виртуалках.
Выглядит весьма бессмысленно. Чем добавление лишнего слоя в виде виртуалки может быть лучше, чем простое увеличение числа потоков?
Didimus
13.04.2023 11:35+1Гарантированное выделение ресурсов? Не всегда ведь потоки можно ограничить в потреблении ресурсов

PuerteMuerte
13.04.2023 11:35+2И Хайлоад в виде дравйвера EGA для 286 компа с отрисовкой 12-16 кадров в секеунду — моя работа. Врядли у Вас получится быстрее
Справедливости ради, это не ваша заслуга, а заслуга видеокарты. В драйвере EGA ещё надо специально постараться сделать что-то, чтобы ограничителем скорости работы был ваш код, а не скорость записи в видеопамять. "В среднем" видяхи EGA умели в 500кб/с, шустрые и в мегабайт умели. Режим высокого разрешения там 640х350х16 цветов, это 112 килобайт на кадр. Вот вам и естественное ограничение.
VladimirFarshatov
13.04.2023 11:35+1Драйвер работал с видео картой на 5 мегабайтах в секунду. Карта так не умела. Это реально надо было постараться..
P.S. А вот деталей уже не помню.. что-то там юзалось из текстовых режимой Еги..

WinPooh73
13.04.2023 11:35Спасибо за ссылку! Помню, что читал отдельные строфы в виде эпиграфов в книге Иртегова про операционные системы, лет двадцать назад. Поиск по тогдашнему интернету ничего не дал. Не знал, что где-то выложен полный вариант.
Kohelet
13.04.2023 11:35+2А поддержка этого "чистого" кода проще? Искал я как-то баг — видим в форме неправильное значение. Это значение получаем из какой-то функции. А в эту функцию оно приходит из другой функции. А в ту из третьей… И где-то там, на 10 уровне вложенности "маленьких функций, выполняющих одну задачу" — баг. И просмотром исходников его не найти. Только в отладчике по шагам. И если заходить отладчиком в каждую функцию, до конца не добраться. А если перешагивать через вызовы, то в какой-то момент приходится матерясь перезапускать все это, записывая на бумажке, в какую функцию надо заходить, а в какую нет. Потому что шагнуть в отладчике назад и зайти туда уже нельзя. А перезапуск этого хозяйства не быстрый.
Хорошие имена функций? Да где же их взять то. Нет 100500 хороших имен. Документация? Да, по паре слов про возвращаемое значение и каждый из параметров. Юнит тесты? Есть, но оказывается, покрывают не всё.VladimirFarshatov
13.04.2023 11:35+2Само слово "чистый" подразумевает "отсутствие грязи" - ошибочного кода, неиспользуемого, избыточно добавленного. В примере выше как раз чистым является переделка на switch и табличное хранение констант, т.к. исключает всё лишнее.
Чистый код отлаживать и сопровождать всегда легче "по определению". Другой вопрос, что сделать так как в примере можно далеко не всегда. Существуют задачи с динамикой, в т.ч. и в классах. Как пример другой крайности - PHP код (интерпретатор), который пишет сам себе же PHP файлик и затем его исполняет - крайняя степень динамики. Ну и какие тут свичи и предвычисления константных таблиц? :)
Как пример применения: выгрузка документов ЭДО, кодом, который создается генератором по XSD описаниям от налоговой. Генератор выкачивает описания, сличает их с имеющимися, в случае обновления законодательной базы парсит нововведения и получает новый PHP файлик выдачи документов. Бухам даже не надо напрягаться, что там поменялось у налоговой.. достаточно только указать ссыль на новые xsd..
WASD1
13.04.2023 11:35Генератор выкачивает описания, сличает их с имеющимися, в случае
обновления законодательной базы парсит нововведения и получает новый PHP
файлик выдачи документов.Э... подождите в вашем примере парсится текст закона (и подзаконных актов). И по тексту закона, даже без промежуточного ТЗ, генерируется нужный нам код.
Это как?VladimirFarshatov
13.04.2023 11:35парсится xsd созданный по тексту закона. Формат документов ЕДО описан в соответствующих ссылях на сайте налоговой. Нужно просто указать новую ссылку, что не сложно.
P.S. и да, это уже не "у меня" больше трех лет.. работает штатно, насколько понимаю..
WASD1
13.04.2023 11:35было: в случае обновления законодательной базы парсит нововведения и получает новый PHP файлик выдачи документов.
-
стало: ну мы умеем форматировать данные по xsd.
Понятно.
> P.S. и да, это уже не "у меня" больше трех лет.. работает штатно, насколько понимаю..
Было "в вашем примере", стало "у меня". Смысл кавычем - в точности цитаты.Впрочем я уже по предыдущему ответу всё понял, удачи вам.
VladimirFarshatov
13.04.2023 11:35-1Ничкего не понял, что Вы там поняли, но написано кмк достаточно внятно, что выше, что ниже:
Изменения законодательства, отражаются в изменениях форматов и полей ЭДО документов. Эти изменения фиксируются на сайте налоговой в виде обновлений xsd описаний.
Xsd описание скачивается парсером, сличается с уже имеющимся и, в случае расхождения, генерируется новый PHP-файл, который далее и исполняется при создании самого ЭДО документа.
Надеюсь так понятнее?

Andrey_Solomatin
13.04.2023 11:35Есть, но оказывается, покрывают не всё.
Если убрать маленькие функции, то и юниттестов не будет.
А если юниты можно заменить более высокооуровневыми тестами, то из можно написать и с тукущим кодом и найти проблему через тесты, а не через дебаг.
0xd34df00d
13.04.2023 11:35Хорошие имена функций? Да где же их взять то. Нет 100500 хороших имен. Документация? Да, по паре слов про возвращаемое значение и каждый из параметров. Юнит тесты? Есть, но оказывается, покрывают не всё.
Эх, если бы только документацию можно было записывать как-то, ну, прямо в определении функции… И чтобы компилятор её проверял…
Да не, фантастика, лучше написать ещё юнит-тестов.

mayorovp
13.04.2023 11:35+1Хорошие имена функций? Да где же их взять то.
Вообще-то это хороший критерий необходимости функции — можно ли придумать ей имя.
Ndochp
13.04.2023 11:35Часто зависит от структуры проекта и настройки неймспейсов. А то вот в одном файле есть десяток функций на 2к+ строк, вы начинаете рефакторинг. Если бы каждая функция была в своем неймспейсе, то легко можно выделить законченные куски типа "проверка входящих параметров" "получение и подговка данных из БД" и наконец алгоритм по названию практически совпадающий с именем исходной 2к функции.
Беда в том, что функции не зря в одном модуле, они примерно про одну область. И тебе приходится или городить монстра ИмяОсновнойФункции_ПроверкаВходящихПараметров или придумывать десяток синонимов, стараясь не совпасть с соседней функцией.mayorovp
13.04.2023 11:35Вооот, критерий-то работает! Проверка входящих параметров должна быть в той функции, чьи параметры проверяются. Это абсурд, когда функция проверяет чужие параметры.
Да, 2к+ строк просятся чтобы их разбили, но делить их механически нельзя.
Ndochp
13.04.2023 11:35-1Никому она ничего не должна.
Беру функцию на 2к, последовательно на человеческом языке записываю в комментах план того, что она делает из 10 — 15 строк, каждую строку меняю на вызов новой функции, плюс обвязка. Получаю нормальную функцию на полэкрана. Для тех вызовов, что получились внутри больше комфортного — повторяю алгоритм.
nronnie
13.04.2023 11:35Поддерживаю. А еще, если к куску кода хочется написать комментарий, даже если этот кусок кода нигде больше не используется. Знал когда-то одного чудака, который на ревью упорно объединял структурированный методами код в один метод, обосновывая это: "Оно же нигде больше не вызывается". Слава Ктулху он очень скоро свалил куда-то в другую контору свои фантазии воплощать.



aborouhin
13.04.2023 11:35+27Ну да, если на том железе, на котором софт обычно работает, он нагружает все ядра CPU на десятки процентов - наверное, пора переходить к оптимизации в ущерб сопровождаемости и простоте. А если 95% задержек, как обычно и бывает, - это disk и network IO или БД... Ну, в общем, про premature optimization уже столько всего написано, что нет смысла повторяться.
VladimirFarshatov
13.04.2023 11:35+3Как правило, хорошо написанный код, и чист и быстр и жрет мало и сопровождается "на раз" .. просто такое редко, т.к. часто на вопрос сроков слышим ответ: "вчера!" :)
vkni
13.04.2023 11:35+1Ну да, обычно работают не продукты, а прототипы. Естественно, "переписыванием с Питона на Rust" (сейчас это модно, но переписывать можно обратно на Питон), достигают нормального продукта и, следовательно, нормальной производительности.

Cheater
13.04.2023 11:35+39Если она основана на типах, это сделать гораздо сложнее, а может, даже невозможно без переписывания большого объёма кода.
Сказал человек, которому при изменении иерархии классов придётся руками искать и дополнять все эти гениальные switch statements в каждом подобном методе))
VladimirFarshatov
13.04.2023 11:35-5Необязательно "в каждом". принцип DRY требует выделения такого switch в функцию, как только у него больше одного места применения. Но! Она перестает быть виртуальной, и соответственно "экономит" 2 уровня косвенности, что и есть "главный тормоз" в примере статьи.

Daemonis
13.04.2023 11:35+10Необязательно "в каждом". принцип DRY требует выделения такого switch в функцию, как только у него больше одного места применения.
Как выделение в функции спасает от ползанья по всему коду, ведь свичи там могуть быть?
Ну и интересно посмотреть, во что превратится этот чудесный код, когда добавится пятиугольник, которому будет недостаточно ширины и высоты :)
VladimirFarshatov
13.04.2023 11:35Зачем ползать по коду, если dry предлагает выделить в функцию уже для второго места?
Попробуйте, всё не так страшно.

koreychenko
13.04.2023 11:35+2А в этот момент у вас же будет определение параметров в рантайме и компилятор не сможет это оптимизировать.
Т.е. у вас будет какой-то новый общий резолвер, который на вход получает тип фигуры, а на выходе возвращает чего-то.
(я не сишник, так что не бейте, если глупость написал)VladimirFarshatov
13.04.2023 11:35В целом верно. Тут с++ надо рассматривать исключительно как демонстратор кода. Написанное верно для любого языка в целом.
Да, такая инкапсуляция switch создаёт функцию-резолвер, которая возвращает нужный вариант.
Но, это и есть принцип "чистой" архитектуры YAGNY -- делать только то и только тогда, когда оно с ановится востребованным! А не городить заранее "кровавый Энтерпрайз".

grossws
13.04.2023 11:35И где-то в этот момент функция превращается в ручной диспетчер виртуальных вызовов. Называется, см. рис. 1.
VladimirFarshatov
13.04.2023 11:35+1Вот на этом этапе, чистым станет код с виртуальными методами .. всё относительно. :)
Статья, да и нашумевшая книжка, как раз о том, что не надо лепить везде многоуровневый энтерпрайз. Каждый класс, каждая виртуализация, обратная зависимость .. всё это обязано быть обосновано соответствующим пунктом ТЗ. Больше чем уверен, что фразу типа "ну такую простую программу мы напишем в лоб" мало кто найден в нашумевшей книжке. А она там есть. ;)

arteast
13.04.2023 11:35+9Для того, чтобы избежать shotgun surgery, в c++ (про который речь) есть паттерн "статический полиморфизм". К примеру, вместо базового класса с виртуальными методами - std::variant с набором классов, имеющие одинаковый набор методов, а вместо вызова виртуальной функции - std::visit с аргументом-шаблоном, который под капотом вызывает какой-либо метод у своего аргумента. std::visit при компиляции превращается в тот самый switch; в то же время, специфичный код остается чисто разделенным по своим классам, а сам набор классов - собран в едином месте в определении типа std::variant.
Главное, чтобы компилятор всю эту бижутерию соптимизировал нормально :)
arteast
13.04.2023 11:35+6Отвечу сам себе :) Народ в ответ на статью-оригинал сделал тот же самый комментарий, что и я здесь, но заморочился на предмет потестировать: https://blog.codef00.com/2023/04/13/casey-muratori-is-wrong-about-clean-code
Результаты интересные.
Но на самом деле, если мы тут заморачиваемся с производительностью, то правильнее было бы попытаться разделить коллекции предметов по их типу - тогда каждый тип можно обрабатывать простым циклом, и тем самым вообще убрать накладные расходы на полиморфизм (и притом более-менее остаться с чистым кодом). Дальше осталось бы только играться с чем-нибудь типа SoA, чтобы SIMD задействовать по полной и тому подобными извращениями.
VladimirFarshatov
13.04.2023 11:35Бизнес часто не знает состав коллекций.
0xd34df00d
13.04.2023 11:35Бизнесу не нужно их знать. Бизнесу достаточно быть нечувствительным к точному порядку обработки.
vkni
13.04.2023 11:35А вот для этого нужно немного работать над сбором требований. Вернее, работать в рамках спиральной модели, когда мы в цикле
«собираем/уточняем требования»
«планируем архитектуру»
«реализуем прототипы» (необязательно)0xd34df00d
13.04.2023 11:35+1Я тут по рекомендациям читаю книгу Domain Modeling Made Functional — с технической точки зрения там ни для тебя, ни для меня ничего нового (кроме синтаксиса F#, но он очевидный), но вот с точки зрения «а как тут взаимодействовать с бизнесом» вполне годно.
vkni
13.04.2023 11:35+2Я переехал в группу производства средств производства: что хорошо — что заказчик/пользователь — это кто-то вроде меня же. Ну и некоторым образом использую вышеописанную методику, хоть и немного партизанскими методами. Но, что радует — не давят пока, впрочем и промежуточные результаты какие-то есть.
По сбору требований — есть Volere Requirements Template 2007 года (сайт универа в Чикаго). Он простой и понятный. Тупо скачиваешь и проходишь, отмечая то, что тебе нужно.
Я посмотрел главу Understanding The Domain — они там дают ложное впечатление, что требования нужно один раз собирать. Нет, нет, и нет. Где-то пробегала статья, что ограничения легко композиционируются => требования легко можно изменять => их нужно периодически переуточнять по планируемой архитектуре.
Просто список должен сходиться + ложиться на архитектуру.0xd34df00d
13.04.2023 11:35+1Я переехал в группу производства средств производства: что хорошо — что заказчик/пользователь — это кто-то вроде меня же.
Ровно поэтому я люблю заниматься всякими там компиляторами и прочей инфрой, а этой вашей бизнес-логикой — нет.
Я посмотрел главу Understanding The Domain — они там дают ложное впечатление, что требования нужно один раз собирать.
Нет, чувак про итеративность там где-то чуть позже явно говорит. Но, возможно, ему стоило бы говорить про это чаще.
PsyHaSTe
13.04.2023 11:35И? Зато при необходимости добавить ещё одну функцию (скажем посчитать периметр) можно написать 1 функцию, а в варианте с иерархией добавлять функцию в интерфейс/базовый класс и потом менять всех наследников.
С чего вы вызяли что добавление ещё одного наследника более важная задача чем добавление функционала в существующую иерархию? Это может быть верным, а может быть и нет, в зависимости от задачи. В общем-то известная проблема.
Не стоит так снисходительно посмеиваться, не будучи на 100% правым в своем поинте, некрасиво выглядит.
mayorovp
13.04.2023 11:35Тут ещё надо помнить про подсказки от компилятора.
Скажем, в большинстве ООП языков компилятор подскажет вам если вы забыли реализовать абстрактный метод в одном из наследников. А вот про забытый кейс в switch вам подскажет только компилятор Rust и никто кроме него...
Хотя эти подсказки от компилятора зачастую мешают обратной совместимости и от них, наоборот, пытаются избавиться.
grossws
13.04.2023 11:35И то, если нет обработки
default/_варианта. Но вообще clang умел в предупреждение если не все тэги обработаны, javac -- аналогично (а при использовании нового синтаксиса выдаёт ошибку).Аналогично обнаружение fallthrough в языках с си-подобным switch.
0xd34df00d
13.04.2023 11:35А вот про забытый кейс в switch вам подскажет только компилятор Rust и никто кроме него...
Языки из ML-семейства вышли из чата.
PsyHaSTe
13.04.2023 11:35
mayorovp
13.04.2023 11:35Не подскажете, каким очередным тайным ключом эта проверка включается в том же Хаскеле? По умолчанию там проверка тотальности только в рантайме...
0xd34df00d
13.04.2023 11:35-Wallили что-то в этом духе — у меня ghc на неполные паттерны всегда жалуется.Другое дело, что наличие pattern guard'ов и некоторых других особенностей синтаксиса (pattern synonyms, например) делает проверку неразрешимой, но когда в раст завезут guard'ы или синонимы, тогда это можно будет обсудить снова.
PsyHaSTe
13.04.2023 11:35Какие именно гварды? обычные match x if x>5 имеются, речь про какие-то другие?
0xd34df00d
13.04.2023 11:35match x if f xдля произвольной Тьюринг-полнойf : a → Bool, да.PsyHaSTe
13.04.2023 11:35ну он есть, но компилятор не использует закон исключенного третьего для него. Поэтому после матчей
match x if P(x) => ..., x if !P(x) => ...нужно матчитьmatch x if P(X) && !P(X) => ...Так-то оно нсть с версии раста 1.0, не очень понятно утверждение "когда завезут гварды".
0xd34df00d
13.04.2023 11:35А, ну тем более, значит, аналогичная проблема с false positives есть и у раста (хотя в соседнем треде подсказывают, что теперь мне надо говорить RS).
WASD1
13.04.2023 11:35+1придётся руками искать и дополнять все эти гениальные switch statements
Ну если мы сравниваем C++ -classes мы C++ -templates то наверное да.
А вот если мы возьмём Rust - то там из коробки свичи (они там pattern-matching и называются match) exhaustive. Поэтому компилятор их за вас все сам найдёт и скажет: допиши ещё ону альтернативу пожалуйста.


Emulyator
13.04.2023 11:35+4В первом примере с оптимизацией получается, что мы для круга и квадрата резервируем место для неиспользуемого значения высоты. Не совсем честная альтернатива или я не прав?

WannaCode
13.04.2023 11:35-13Очень даже честная. В варианте без оптимизации каждая фигура является классом, соответственно, при создании одной фигуры для нее отдельно выделяется память, а количество выделяемой памяти обозначается в страницах, то есть одна фигура занимает как минимум одну страницу, а это аж 4 кб. А в случае оптимизации все фигуры аккуратно размещаются в одном массиве впритык друг к другу и занимают каждая всего по 12 байт. Минусов нет, есть только выигрыш как в скорости, так и в потреблении памяти.

nin-jin
13.04.2023 11:35+30Это ОС выделяет память страницами. Внутри процесса память под объекты выделяется с любой необходимой гранулярностью, в зависимости от используемого аллокатора.

MiraclePtr
13.04.2023 11:35+19для нее отдельно выделяется память, а количество выделяемой памяти обозначается в страницах, то есть одна фигура занимает как минимум одну страницу, а это аж 4 кб.
Вы сначала разберитесь, как на самом деле работает аллокация памяти для процессов в ОС и аллокация памяти в используемом вами языке/рантайме и не порите больше такую чушь, ей больно.

prefrontalCortex
13.04.2023 11:35+3Тут скорее нужно рассуждать не о размере страницы, а о размере кэш-линии, который в наши дни - 64 байта.
Daemonis
13.04.2023 11:35+7Почему ж неиспользуемая? Какой-нибудь последователь автора может решить, что для круга нужно использовать высоту, а не ширину, и напишет свои свичи для своих операций :)
grossws
13.04.2023 11:35Да не, туда высоту цилиндра самое то запихнуть. А для прямоугольных параллелепипедов с квадратным основанием width будет размером грани основания, а height -- высотой цилиндра. Но для треугольника оно будет значить совсем другое и часть его параметров будет храниться в отдельном массиве с командой адресацией по индексам. По крайней мере это будет интерпретироваться так в части функций.
Другие смогут использовать те же поля чуть-чуть иначе и сэкономят и память, и стоимость виртуального вызова.
Где-то я это видел и очень хочу развидеть
nronnie
13.04.2023 11:35Так-то по ОО и у круга и у квадрата есть и высота и ширина. Просто в отличие от эллипса или прямоугольника у них есть еще инвариант одинаковости высоты и ширины. Поэтому круг и квадрат это частные случаи (подклассы) эллипса и прямоугольника, а не наоборот.
0xd34df00d
13.04.2023 11:35+3Имею ли я право написать тест
void stupidTest(Rectangle& rect) { const auto oldHeight = rect.height(); rect.setWidth(rect.width() * 2); assert(oldHeight == rect.height()); }?
PsyHaSTe
13.04.2023 11:35В ооп один из основных столпов это SOLID, к каждой букве которого можно придумать контрпример. в результате которого принцип оказывается, ну, принципом. А не законом.

0xd34df00d
13.04.2023 11:35Неявно подразумеваемый тут LSP вроде как претендует на то, чтобы быть именно законом. Лисков там с кем-то ещё целый научный папир в 80-х написали по этому поводу, ЕМНИП.
PsyHaSTe
13.04.2023 11:35Не претендует, потому что нам нужно определиться с тем что такое "поведение", чтобы проверить, изменяется оно или нет. Это в некоторой степени сходно с "чистотой" — что считать сайд эффектом а что нет. Является ли дополнительные аллокации сайдэффектом? А лишние ЦПУ циклы? А принт в лог? Вопросы, вопросы...
Так и тут: количество инвариантов базового типа бесконечно и нигде не описано.
0xd34df00d
13.04.2023 11:35Так и тут: количество инвариантов базового типа бесконечно и нигде не описано.
Ну так LSP говорит, что если S <: T, то ∀P: T → Prop. (∀ t: T. P t) ⇒ (∀s: S. P s).
PsyHaSTe
13.04.2023 11:35Так вопрос что такое "любое Пэ". Как очертить множество этих самых "пэ" которые должны выполняться? Возьмем иерархию:
class DoubleAddList<T> extends List<T> { public override Add(T item) { base.Add(item); base.Add(item); } }Этот наш класс нарушает принцип лискова или нет?
0xd34df00d
13.04.2023 11:35Ура, правильные вопросы!
Вот к принципу математической индукции, и что там подразумевается под любым пэ, у тебя вопросов нет?
PsyHaSTe
13.04.2023 11:35Я такой себе математик, но кажется что "пэ" это "свойства выполняемые для данного Т". К индукции у меня вопросов нет. Вопрос именно откуда брать список требований к типам. Я ниже раписал
0xd34df00d
13.04.2023 11:35кажется что "пэ" это "свойства выполняемые для данного Т"
Верно, предпосылка (∀ t: T. P t) за это отвечает. Но это ничего не меняет.
nronnie
13.04.2023 11:35+1LSP он про контракты. Неусиление предусловий, неослабление постусловий и сохранение инвариантов. Поэтому тут все зависит от того как описан контракт базового класса. Если в нем, например, есть постусловие "Число элементов класса List после вызова Add должно быть на единицу больше чем до вызова" то тут нарушение LSP, если ничего такого нет, то нет и нарушения.
PsyHaSTe
13.04.2023 11:35+1Поэтому тут все зависит от того как описан контракт базового класса.
И как? Ну вот возьмем List.Add из стандартой библиотеки C#. Описание
Adds an object to the end of the
List<T>.Можете перечислить предусловия/постусловия? Единственное которое я могу придумать "должно выполняться
list.Add(obj); Assert.Equals(list[list.length-1], obj);", но является ли это исчерпывающим списком. Есть ли тут другие пред/пост условия? Как узнать? Скажем я могу написать такую реализацию, которая под это условие подходит:class WeirdList<T> extends List<T> { public override Add(T item) { base.Clear(); base.Add(item); } }Соблюдает ли такая реализация LSP?
0xd34df00d
13.04.2023 11:35-1Тут твой
List.Addничем не отличим от условногоOptional.Setс точностью до синтаксиса. Слишком слабый набор требований.
PsyHaSTe
13.04.2023 11:35Ну это не комне вопрос) Мой тейк собственно в том что эти требования нигде никогда не описываются и приходится полагаться на "здравый смысл", "ну понятно же что имелось в виду" и прочие формальные критерии. Но господа выше утверждают что где-то это описано, и я хотел бы вот на примере стд одного из крупнейших языков узнать о чем они. Потому как продакшн код любого проекта который я видел куда меньше документирован, соответственно хочется получить оценку сверху на максимальное количество требований, которые можно почерпнуть из описание типа/документации/...
nronnie
13.04.2023 11:35Имею ли я право написать тест
И да и нет. Если в АПИ задан инвариант типа: "Изменение ширины любого прямоугольника не меняет его высоту", то тест правильный, но тогда квадрат не должен наследовать прямоугольника, потому что тогда он нарушит ЛСП.
0xd34df00d
13.04.2023 11:35+1Если в API этот инвариант не задан, то код
Rectangle rect; rect.setWidth(800); rect.setHeight(600); window.resize(rect);я написать не могу, потому что после третьей строчки с
setHeightя не знаю, осталась ли у него та же ширина. Не знаю, кому и зачем такие прямоугольники нужны.
VladimirFarshatov
13.04.2023 11:35-1не совсем. Точнее, конкретно тут экономим, т.к. можем упихать весь набор фигур в банальный массив. Для классов, память будет выделяться в куче, что есть доп. затраты как на CPU, так и на место в ОЗУ.. тут - "чистая экономия". Такой пример просто..

tenzink
13.04.2023 11:35+11Раз у нас такой highload, то давайте уже держать отдельно массив прямоугольников, кругов, треугольников, ... Будет счастье: и cache-locality, и экономия памяти, и девиртуализация (хотя и классы можно будет сделать plain structs). Потом прикрутим SSE/GPU/..., всё что угодно.
Сейчас у вас один вызов new перекроет всю экономию на спичках на несколько лет вперёд.
nronnie
13.04.2023 11:35На платформах со сборкой мусора и уплотнением кучи (.NET/Java) выделение памяти в куче и в стеке одинаковы по скорости. Возвращается текущий указатель на вершину кучи, потом он увеличивается на величину размера объекта.

onyxmaster
13.04.2023 11:35Зато освобождение потом не бесплатное, плюс работа с тем что выделено в куче может быть медленнее из-за особенностей кэша, особенно в многопоточном приложении, да и лишняя косвенная адресация скорости не добавляет (впрочем это годится только для того, что реально можно разместить на стеке целиком без ссылок, а это очень небольшой спектр структур данных).

Deosis
13.04.2023 11:35В варианте с классами в массиве хранятся не сами данные, а указатель на них. Далее для вызова виртуального метода в С++ обычно используется указатель на таблицу виртуальных методов.
Таким образом при переходе на структуры, мы сэкономили по два указателя на каждую фигуру и добавили одно поле для определения типа и для части фигур одно неиспользуемое поле.
prefrontalCortex
13.04.2023 11:35+10Непопулярное мнение, завуалированное в виде интернет-мема

Уточнение
По крайней мере в том виде, в котором его понимают в потомках Алгола вроде C++, Java, C# и проч.

Medeyko
13.04.2023 11:35+3Меня, наверное, распнут за прозелитизм, но отмечу, что мне очень импонирует в Rust'е, что в нём не стали делать полномасштабное ООП как в Плюсах и Джаве, а только некоторые его части, и в несколько отличном виде... Вообще, когда говорят про Rust, обычно вспоминают только про управление памятью, а ведь там гораздо больше интеиесных архитектурных решений, по-моему.
Andrey_Solomatin
13.04.2023 11:35Это неплохой инструмент, который решает конкретные проблемы.
Две основных проблемы это то, что его пытаются использовать везде, и то что им называют всё что угодно, особенно гибриды ООП и императивного программирования.
Плохой код можно писать в любой парадигме.

Fedorkov
13.04.2023 11:35+43«Преждевременная оптимизация — корень всех зол.» — Дональд Кнут
Всё перечисленное надо делать только после того, как профайлер указал на проблемное место в коде. Либо если вы по своему опыту можете указать на те 2% кода, которые в будущем дадут 80% тормозов.
VladimirFarshatov
13.04.2023 11:35-6Когда Кнут это говорил, не было ни ООП ни "чистой архитектуры".. он говорил совсем о другом. Но .. "Цитатам в интернете народ верит легко" (с) В.И. Ульянов (Ленин). :)
VladimirFarshatov
13.04.2023 11:35Забавно, сколько минусов .. а то, что это ни разу не цитата Кнута, то никто и не заметил.. Кстати, моя любимая фраза: "Кнута на вас нет!" .. многие понимают "буквально", ибо не читали, мой любимый настольный трехтомник (по смерти Кнута было выпущено ещё из недописанного и дополненного иными, но это уже детали)..
Fedorkov
13.04.2023 11:35+1Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
— Structured Programming with go to Statements, Donald E. Knuth
VladimirFarshatov
13.04.2023 11:35Ещё раз: Кнут говорил О ДРУГОМ, не было тогда ни ООП (в зачатке ещё) ни "чистой архитектуры". Это цитата, вырванная из контекста, что уже обсуждалось на Хабре, не вижу смысла повторяться. Кнута надо читать, чтобы так не спорить и минусовать по не знанию:
https://habr.com/ru/articles/550926/
В применении к ООП и энтерпрайз архитектурам и паттернам это вообще не его цитата..

Ogra
13.04.2023 11:35+5Почему же? Если в задаче, приведенной в посте, нужно посчитать площадь десяти фигур, которые выбираются из БД, то попытка считать такты на полиморфный вызов - это как раз таки "worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered."
VladimirFarshatov
13.04.2023 11:35+1Потому что, в данной статье автор применил сравнение двух реализаций алгоритма расчета, а не времени работы с БД, по получению данных.
Треш и угар, который часто наблюдаем в скульных запросах требует отдельного описания и своей статьи. Вы пытаетесь подменить обсуждение энтерпрайз решений обсуждением способов хранения данных (и это не только БД!) методами их выборки и оптимизации работы БД-хранилищ.. они тоже разные: SQl, No-Sql типа "монго", in-memory типа Redis, Cache, который mumps..
Ogra
13.04.2023 11:35+1Сравнение двух реализаций алгоритма расчета - вполне может быть "worrying about noncritical parts". Потому что может быть такое, что форм мало, может быть такое, что данные мы получаем с большой latency, и т.д.

demimurych
13.04.2023 11:35+1Дональд Кнут в єтой статье говорил о том, что код должен писаться образом, который бы позволил компилятору произвести все необходимые оптимизации.
Дональд Кнут не говорил ничего о чистом коде, или коде понятном человеку. Он, на примере разбора применения условных и безусловных переходов рассуждал о том, что наиболее выигрышной стратегией является не стратегия когда тратятся чвловеко-часы для тонких оптимизаций, но настаивал на том, что код должен быть написан в форме, упрощающей работу компилятора, который уже и произведет все необходимые оптимизации. Чему как раз очень вредят переходы.
То есть Дональд Кнутт не выдавал программистам индульгенцию на написания кода так как им захотелось: удобно или читабильно, но напротив настаивал как раз на том, чтобы люди создавли код подчиненный требованиям компилятора.

ainoneko
13.04.2023 11:35+1по смерти Кнута было выпущено ещё из недописанного и дополненного иными, но это уже детали
А разве он уже умер?! (Или это про другого?)
Medeyko
13.04.2023 11:35+6Что Вы несёте, уважаемый? :)
Какая-такая "смерть Кнута"? Дональд Кнут жил, Дональд Кнут жив, Дональд Кнут будет жить, и вроде как пока помирать не собирается.
И про какой трёхтомник Вы говорите? Том 4B Искусства программирования был дописан Дональдом Кнутом и выпущен в 2022-м году.
Или это такая-то очень тонкая непонятная мне шутка?

V1RuS
13.04.2023 11:35+3То, о чем пишет автор — не оптимизация, а стиль кода, который не привносит лишние тормоза. То есть не "вначале написать медленный код, а потом искать узкие места профайлером", а сразу делать нормально. Об этом он рассказывает вот здесь https://www.youtube.com/watch?v=pgoetgxecw8 (да, видео, текстовую версию не нашел).

Gradiens
13.04.2023 11:35+15Вот именно это и вызывает восхищение и содрагание от ужаса.
То, что автор умеет писать в оптимальном стиле.
Респект автору, я так не умею.
В современных распухших многофункциональных приложениях выполнение порядка 98% кода занимает 2% времени.Если сразу сделать "нормально", нам надо тратить время очень высококвалифицированного спеца, и мы получим 100% слабоподдерживаемого процедурного кода.
Если сделать "медленно" а потом переписать "нормально" узкое горлышко, у нас будет всего лишь 2% слабоподдерживаемого кода. И нам надо будет 2% времени профи, который умеет в оптимизацию.
А итоговый результат почти одинаков.
Да, в идеальном мире мы сразу знаем, где эти 2%. Но в реальности попытка их выделить заранее заканчивается обычно провалом .
Лично я только в 1/10 случаев угадывал bottlebeck заранее. Хотя опыт рефакторинга кровавого энкрпрайза, чтобы ускорить критические сценарии использования на порядок, у меня имеется.V1RuS
13.04.2023 11:35мы получим 100% слабоподдерживаемого процедурного кода.
Почему вы так считаете?
Автор приводит аргументы в пользу того, что его быстрый код поддерживается ничуть не хуже, а то и лучше. В частности за счет того, что сам код короче и понятнее.
И нам надо будет 2% времени профи, который умеет в оптимизацию.
А итоговый результат почти одинаков.Нет, не будет. Потому что проблема не в тех 2%, которые придется оптимизировать, а в остальных 98%. Бюджета — как денег, так и времени, и желания — на их оптимизацию не будет, потому что тормозят они не критично. Однако это "не критично" часто все же заметно и портит жизнь юзерам.
PsyHaSTe
13.04.2023 11:35+3Если сразу сделать "нормально", нам надо тратить время очень высококвалифицированного спеца, и мы получим 100% слабоподдерживаемого процедурного кода.
Это скажем так неправда. Писать хороший код и плохой код почти всегда примерно одинаково по времени, нужно только знать как писать хороший.
Вторая ошибка — процедурный код значит быстрый — это тоже неверно. ООП в стиле "как в джава" — медленный, никто не спорит, только проблема не в отсутствие процедур, а в динамическом диспатче. Пишите любое ООП без динамического диспатча (хотя бы как пример стд:: вариант выше) и будет все белым, пушистым и бенчмарки будут биться.
И итоговый код как можно посмотреть ничуть не сложнее ни медленного "чистого" кода, ни процедурной портянки.
VladimirFarshatov
13.04.2023 11:35-2Чтобы писать быстрый и легко поддерживаемый код есть несколько неплохих книжек. Одна из них: "Оптимизационные преобразования программ" Касьянова. Когда эта книжка сидит "в пальцах", плохой код писать сложнее... Для начинающих, всегда рекомендую ДРАКОН Паронджанова, там несколько книжек для детей. Усваиваются легко, проверено на собственном сыне, в т.ч. сайт drakon.su в помощь, не сочтите за рекламу...

shasoftX
13.04.2023 11:35+14Тут бы ещё посчитать время выкатывания новой фичи в таком коде. И цену ошибки. И тут, внезапно, окажется что лучше писать чище даже если это работает медленнее.
nin-jin
13.04.2023 11:35+7Кому лучше? Как пользователь, я предпочту хорошо работающее приложение с редкими, но меткими обновлениями, чем редизайны каждый месяц с бесполезными наспех слепленными фичами, которые адски тормозят.
Я тут недавно поставил Twitch Studio для стриминга. Ёе запукаешь, ещё не включил стриминг, а она уже неслабо грузит систему. Надо ли говорить куда эта "быстрая" поделка отправилась после такого?

KanuTaH
13.04.2023 11:35+7Вы еще по основной массе комментариев не поняли, что на пользователей тут всем плевать? :) Вот "время от todo до ready" - эт да. А пользователь проглотит, ну или в крайнем случае разорится на девайс помощнее, продвинет мировой ВВП.
nin-jin
13.04.2023 11:35+6В данном случае пользователь ушёл к конкуренту, так как FPS никогда не лишние, даже если у тебя и так мощный девайс.
shasoftX
13.04.2023 11:35+7Но ведь как пользователь вы предпочтете чтобы ошибки исправлялись в течении 1-2 дней, а не месяцев. И тут чистота кода имеет значение.
nin-jin
13.04.2023 11:35+2Как пользователь, я предпочитаю, чтобы ошибки до меня вообще не доезжали, а не латались на скорую руку, создавая новые ошибки.

Nalivai
13.04.2023 11:35+7В таком случае вы предпочтете чтобы люди писали не write-only простыни свитчей, а чистый код по практикам, в которых ошибки допускать сложнее а находить и исправлять проще.
VladimirFarshatov
13.04.2023 11:35-1Это не так. В динамическом ООП, да ещё и разнесенном по папкам в соответствии с правилами "кровавого энтерпрайз" (ну не могу я ЭТО называть "чистым кодом"!) количество багом как правило кратно сложности и уровневости (вложенности) энтерпрайза, а искать их кратно дольше, банально только за счет листания папо при розыске. ИДЕ в этом сильно помогают, но скорость подрастает линейно, а падает квадратично от размера проекта.
0xd34df00d
13.04.2023 11:35+4Можете считать, что эффективное приложение просто еще не успели написать.
VladimirFarshatov
13.04.2023 11:35+2Тут иной прикол.. то, что приведено в статье и есть тот самый "чистый код" как его описал дядюшка Боб. а вот то из чего он сделан, ни разу не "чистый код", а "кровавый энтерпрайз" двоешников. Всё ровно наоборот, что автор статьи и показывает: и шустрее работает и доработать .. ПРОЩЕ. Читай "сопровождать".
Попробуйте доработать пример с полиморфизмом ООП, при условии, что класс каждой фигуры находится в своей папке проекта.. засеките время на доработку.

fireSparrow
13.04.2023 11:35+14Ну ок, вы взяли небольшие куски кода, и сравнили производительность по ним.
Но можно ли масштабировать эти выводы на картину в целом?Если код написан ясно, то при необходимости изменить его, разработчик с большей вероятностью увидит более изящный и оптимальный способ сделать это.
Если же код написан запутанно, то с большей вероятностью разработчик будет править фрагмент кода без понимания того, как он взаимодействует с остальным кодом. И в итоге код будет представлять из себя лоскутное одеяло, где каждый лоскуток может работать очень быстро, но в итоге программа "почему-то" будет тормозной и забагованной.Основная причина медленной работы ПО — халатность и рукожопие, а вовсе не следование каким-либо практикам.
V1RuS
13.04.2023 11:35Ответ автора на это возражение (и прочие другие): https://www.computerenhance.com/p/response-to-a-reporter-regarding
Если кратко: пример в статье — не исследование, на базе которого делаются выводы, а просто демонстрация.

Pastoral
13.04.2023 11:35+22И при чём тут "чистый код"? Вы меряете дополнительные затраты на полиморфизм в С++. Это другое ©. И при этом, видимо, понимаете "чистый код" как доведение до абсурда. Кстати, если уж говорить "чистый код" в наглую, то неплохо бы рассмотреть и другие варианты реализации, например в Rust и Dart. С последним Вам будет вообще счастье, там сборщик мусора есть.
Примеры "чистого кода" - это примеры для изучения, а не темплеты для вычисления площади. Наклкдные расходы конечно есть, но если бы вместо площади Вы делали бы что-то содержательное, Вы их не заметили бы.
Если до сих пор не понятно, домашнее задание. Если Python такой медленный, почему результаты на нём получаются так быстро?
nin-jin
13.04.2023 11:35+2Как быстро? Запустил нейронку - она одну картинку сгенерила нормально, а на второй упала с нехваткой памяти. Запарился уже после каждой картинки перезапускать сервер. Доходит до маразма - люди перезапускают сервер каждые 10 минут, ибо зависает. На каждую из этих проблем я потратил несколько дней, но так и не нашёл стабильного решения. Спасибо за такие "быстрые" результаты.

PanDubls
13.04.2023 11:35-1Это, получается, как в анекдоте про японскую бензопилу и сибирских лесорубов?

lgorSL
13.04.2023 11:35Я при похожей проблеме делал os.fork() в питоне, выполнял задачу в дочернем процессе и после его завершения утёкшая память освобождалась.
mayorovp
13.04.2023 11:35+1Звучит как дичайшая утечка памяти. И я уверен, что проблема тут вовсе не в питоне.
nin-jin
13.04.2023 11:35Она не дичайшая. Просто питон аллоцирует памяти больше, чем есть свободной, вместо того, чтобы эффективно использовать уже аллоцированную. И дело скорее всего именно в питоне, а точнее в его GC.

DirectoriX
13.04.2023 11:35+2Overcommit — вообще нормальное явление в Linux, и вроде всё работает (чаще всего).
Кстати, попробуйте запустить Python с другим системным аллокатором (например, черезLD_PRELOADподсуньте), может сильно помочь...sumanai
13.04.2023 11:35+1Overcommit — вообще нормальное явление в Linux
Это не единственная ОС на Земле.
DirectoriX
13.04.2023 11:35Разумеется, есть и Windows, которая скорее (в смысле "раньше") пристрелит видеосистему, чем даст выделить память "под крышечку" (бывало несколько раз, да). Linux — это лишь пример, показывающий, что
аллоцирует памяти больше, чем есть свободной
не является проблемой само по себе.

Kiel
13.04.2023 11:35+8Чистый код и вправду зачастую приводит к понижение производительности. Это правда и грустная правда. Даже за примерами ходить не надо, в .net есть EF, который значительнее медленнее просто sql, и уж тем более вызова хранимки. Но! Чистый код пинает к выстраиванию здоровой архитектуры, что приводит к невероятным вещам, и, внезапно, к росту производительности в целом.
Например, EF можно покрыть юнит тестами с in-memory db, а вот хранимку только интеграционными тестами! Такая вот безнаказанность, когда есть оправдание "а оно не покрывается юнит тестами", ведёт к написанию кода в хранимках тяп-ляп, а отлавливать такие баги ;) Наслаждение! Иногда такие хранимки достигают до 20 тысяч строк кода (хотя я видел максимум 6 тысяч). Что делает приложение неподдерживаемым и приводит к состоянию "либо бизнес смирится с багами, либо меня уволят", вместо того, чтобы вы придумывали как сделать бизнес еще рентабельнее
nin-jin
13.04.2023 11:35Странно, что для хранимок ещё не запилили какого-то тестового фреймворка.
Kiel
13.04.2023 11:35А они хранятся в db, то есть буквально "в другом приложении". И может какие то тесты у db, но я таковых не знаю не видел и не видел чтобы их кто то использовал
VladimirFarshatov
13.04.2023 11:35+2Помнится, было модно пихать бизнес-логику в хранимки БД.. там реально ещё тот треш и 6 тысяч строк - вполне реальный объем хранимки в таком разе.. как это тестировать?


gybson_63
13.04.2023 11:35+6А можно было просто написать "final" и не морочить людям голову.
Использование современного С++ для повышения производительности / СоХабр (sohabr.net)
Или вы рассчитываете наследовать от этих объектов и далее? Мне кажется нет, все возможности по любому развитию кода Вы закрыли, он в принципе сразу мертвый - не способный к адаптации, росту.

lamerok
13.04.2023 11:35Ну почему же, можем применить шаблон визитер и можно расширить эти классы, если надо.
А так да запрещает наследников и компилятор сделает девиртуализацию.
isadora-6th
13.04.2023 11:35Как сделать девиртуализацию если тип объекта понимается на рантайме?
Shape* GenerateShape(){ if (rand() % 2) { new Circle(10); } else { new Square(10); } } //Different TU void ProcessArea(Shape* s){ s->Area(); }Circle и Square могут быть чем угодно final не файнал, без знания о всех возможных типах наинлайнить
s->Area();ну как-то сложно (ну кроме кейсов, где у нас можно весь вызов свернуть вreturn rand() % 2 ? X : Y;).finalне делает ничего с оптимизациями как иconst.lamerok
13.04.2023 11:35Final лишь облегчает задачу Компилятор у, но он конечно не панацея. Девиртуализацию можно сделать не всегда. А только если :
Компилятор знает значение, которое записывается в виртуальный указатель в конструкторе.
Адрес конкретного метода. обычно он хранится в самой виртуальной таблице и известен на этапе компиляции.
Компилятор должен быть уверен, что с момента инициализации виртуального указателя (записи значения) в конструкторе и до момента вызова конкретного виртуального метода т.е. чтения виртуального указателя, его значение не переписывается (no clobbering).
В вашем примере непонятно, когда вызывается ProcessArea поэтому и сказать по вашему примеру ничего нельзя. Если например вызвать метод сразу после создания Circle, то почему бы и нет, все условия соблюдены.
isadora-6th
13.04.2023 11:35Давайте намажем везде
inlinefinal! Если очередное волшебное слово приносит перф, оно должно ставится автоматически компилятором. noexcept в ту же копилку волшебных слов, только оно пока работает.Статья 16 года, за 7 лет компиляторы довольно неплохо научились девиртуализировать де факто статически известную виртуальную функцию. (O1 godbolt)
MiraclePtr
13.04.2023 11:35Давайте намажем везде
inlinefinal! Если очередное волшебное слово приносит перф, оно должно ставится автоматически компиляторомЭто как? Компилятор - не телепат, он не может угадать намерения программиста. Тут у вас сейчас вроде последний уровень наследования, а потом вы этот хедер заинклудите еще куда-то и там навернете еще один уровень снизу, например, в динамически линкуемой библиотеке - и ой.
isadora-6th
13.04.2023 11:35+1Тогда скорее уж LTO, компиляторы и за пределами одного TU могут делать inline, думается, что и раскидать final на этапе линковки осилят. Да и не понятно, чем final наследник отличается от не final наследника в вопросах подстановки, когда типы известны на этапе компиляции, на O1 прекрасно вся динамика удаляется.
Просто для рантайм динамики final визуально ничего не делает. Ну не умеет С++ на рантайме магически делать сворачивание динамических коллов в статику (или я чего-то не знаю).
А навешивать контракты на торчащие наружу типы из соображений оптимизаций компилятором... вредно для нервной системы.
Когда-то встречал статью (перевод на Хабре) где удаление всех const из кодовой базы не привело к понижению performance после оптимизаций. Так что все работает вообще не так, как ожидают люди.

vassabi
13.04.2023 11:35-1дело не в чистом коде, дело в реализациях ООП
вот тут кстати можете почитать на примере JS: https://twitter.com/mhevery/status/1622499229813047296
https://mrale.ph/blog/2015/01/11/whats-up-with-monomorphism.html

LordDarklight
13.04.2023 11:35+13Уж извините, сложилось впечатление, что автор "Casey Muratori" попросту не понимает идеологии чистого кода! Суть, в большей степени, которого - это не про производительность (хотя этом там тоже уделяется внимание, но куда в меньшей степени), а про сопровождение (в т.ч. в процессе разработки) программного кода. И да, безусловно, на небольших примерах зачастую не сложно подогнать какую-либо "не чистую" реализацию с оптимизацией, решающую эти пример куда быстрее, чем в рамках идеологии чистого кода. Вот только будь примеры посерьёзнее, а сами задачи требующие более высокой изначальной абстракции - и этот оптимизированный код начнёт обрастать такими костылями.... или окончательно уйдёт в степь тотальной оптимизации под текущую задачу, когда шаг влево, шаг в право - готовься к высокой вероятности переписать (ну или точечно внести изменения) почти половину кода. И повезёт если это будет делать тот, кто это написал ранее и держит в голове все нюансы реализации.
Чистый код - это не про время исполнения, а про время разработки (хотя, опять же, на небольших проектах чистый код будет требовать даже больше времени - но плох тот программист, который взращивает свои навыки исключительно для небольших проектов).
Указанные автором оптимизации в цифрах безусловно впечатляют - но лишь в цифрах.... по сути вся эта разница в тактах для подобных задач будет в реальности ничтожна. И автор сам об этом косвенно пишет говоря про отсутствие разницы в бенчмарках на современном железе - ему пришлось лезть в железо 12 летней давности, чтобы показать эту разницу в синтетических тестах. Я понимаю, что железо 12 летней давности ещё достаточно популярно (у самого такое в эксплуатации есть) - но даже на нём - даже чистый код даст достаточную производительности для абсолютного большинства случаев реального применения! Ну а с ростом сложности задачи - будет и расти сложность вот такой оптимизации и дальнейшего видоизменения.
Безусловно - есть потребность в решении задач, которые априори требуют экстремальной оптимизации - обычно это достаточно узкоспециализированные и статические задачи - которым навряд ли понадобится вскоре доработка - а если и понадобится - то на уровне "переписать всё"! Вот тут не нужно рьяно придерживаться идеологии чистого кода - тут уже другие требования! Но даже в этих случаях зачастую лучше сначала разработать алгоритм в идеологии чистого кода - добиться его безотказной работы, разобравшись до конца в самой задачи - а уже потом заниматься его опиливания с элементами экстремальной оптимизации до нужного результата по скорости выполнения - и тут должны быть уже заданы и целевые показатели и платформы для них. Не должно быть экстремальной оптимизации ради оптимизации - только в рамках достижения заданных показателей, которые не должны браться "с потолка", а должны быть продиктованы реальной "пользовательской" потребностью! И, так как оптимизировать небольшие задачи проще, тут потребуется декомпозиция исходных больших задач - и ели они уже будут решены в рамках идеологии чистого кода - то эта декомпозиция пройдёт куда легче!
Сейчас ЯП C/C++ активно вытесняются в область решения задач, в которых возникает потребность в экстремальной оптимизации - вот пусть тут и останется идеология античистого кода - в угоду производительности! А при разработке на ЯП более высоко-прикладного уровня скорее лучше сосредоточится на качестве кода, чем на его производительной эффективности - чай не в эру дискетных ЭВМ живём и программируем. И задумываться сейчас больше стоит о том, как оптимизировать решение задачи распараллеливанием на много ядер (и даже много компьютеров) и как наиболее оптимально наполнять кеш данных и кеш команд этих ядер, минимизируя переключения и ветвления задач в рамках одного ядра.
И тут, в заключении, я скажу так - по сути вся эта проблема с разницей производительности разных вариантов написания алгоритма в современном мире - это скорее проблема компиляторов, чем программистов - это блок оптимизации компилятора не смог грамотно с оптимизировать код вариации "чистый код" - да там виртуальные функции - но по сути - вся их логика на ладони (в данных примерах) и продвинутый компилятор мог их развернуть хотя бы до свитчей - а то и до таблиц данных. И задача современного развития ЯП как раз и заключается в разработки системы компиляции, способной оптимизировать именно "чистый код" в более эффективные реализации с глубоким разбором логики.
Я не говорю, что такое возможно для C++ - слишком сложный ЯП.
Но если целенаправленно, скажем, разработать новый ЯП - цель которого писать как можно понятнее, проще и абстрактное - а цель компилятора такого ЯП понять логику постановки и решения и оптимизировать выходные инструкции так - чтобы они были наиболее эффективными (в т.ч. опираясь на базы знаний различных решений и статистику исполнения на той или иной платформе) - то такой подход мог бы в близком к 100% случаев (со временем, с развитием) давать программу, которая не уступала бы (с заданной погрешностью) вручную экстремально оптимизированным алгоритмам на, написанным на С++ на реальных проектах (а не искусственных небольших примерах). В т.ч. тут на помощь придёт и JIT-компиляция, в т.ч. динамическая перекомпиляция - с учётом набранной реальной статистки рантайм выполнения алгоритма.
А уж время разработки тут бы уже отличалось на порядки, на много порядков! Не говоря уже о времени на последующее сопровождение и доработки!
Именно идеология чистого кода позволила бы такому ЯП быть глубоко разбираемым компилятором и глубоко оптимизируемым! Ведь разбираться в логике программного кода автоматам пока сложнее, чем людям! А чистый код упрощает этот разбор.
Но в защиту автора (и переводчика) всё же скажу - что статья интересная и всё-таки полезная - знать о том, что чистота кода - это далеко не всегда производительность очень полезно - и это надо иметь всегда в виду! Ну а как часто прибегать к античистому коду - тут уж пусть каждый для себя решает сам - в угоду своим профессиональным навыкам и опыту! Я свои соображения на эту тему высказал

victor_1212
13.04.2023 11:35+1> Чистый код - это не про время исполнения, а про время разработки (хотя, опять же, на небольших проектах чистый код будет требовать даже больше времени - но плох тот программист, который взращивает свои навыки исключительно для небольших проектов).
правильно мыслите, сделаем еще один шаг - для больших и сложных систем (особенно real time) наиболее трудоемкий этап это интеграция, отладка и сопровождение, любые технологии которые облегчают отладку и делают систему более надежной имеют высокий приоритет, без разницы - это структурное программирование, проектирование сверху-вниз, чистый код или иначе, важен результат, т.е. понятный и надежный код за минимальное возможное время,
но заметим все имеет свою цену, поэтому для проектов другого уровня сложности приоритеты могут отличаться, что и наблюдается по жизни

nomhoi
13.04.2023 11:35только-только собирался вернуться в C++ с познаниями в "чистой архитектуре" полученными в разработке на Python
Andrey_Solomatin
13.04.2023 11:35-1Прочитайте статью со стороны Питона :) Автор пытается там считать какие-то такты.
Питоновский "print(hello world)" сождёт больше тактов, чем все его примеры выполненные тысячи раз.
Я после Питона и Джавы пробовал немного С++. Посмотрел на трейсбэки при ошибках и решил, что с меня хватит.

shornikov
13.04.2023 11:35Удобно поддерживать <==================================> Быстро работает.

General_Failure
13.04.2023 11:35+8Эти два параметра вообще никак не связаны.
Например, мне сейчас достался проект, который поддерживать очень трудно (там похоже соблюдены все антипаттерны), но работает не очень быстро.
Единственная косвенная связь, про которую уже сказали выше - в чистом коде легче найти узкие места, и там оптимизировать.
0xd34df00d
13.04.2023 11:35+2Пишу на хаскеле. Удобно поддерживать и быстро работает.
shornikov
13.04.2023 11:35+1На hh haskell упоминается в 20 вакансиях, си++ в более чем 2000. Мне кажется, это говорит о том, что хаскелиста фиг найдешь, если понадобится. А когда работать некому - это тоже - "неудобно поддерживать"
0xd34df00d
13.04.2023 11:35У знакомых мне хедж-фондов есть проблемы с наймом плюсистов на даже 500 килобаксов в год. У хаскелистов я таких зарплат не видел — хватает и меньших, и вакансии все равно закрываются быстро.
vkni
13.04.2023 11:35Народ вроде разучился в ручное управление памятью. В смысле, люди младше 30 не умеют.
С другой стороны, меня вот спрашивали про то, какое копирование в C++ — deep copy или shallow copy. Я был несколько ошарашен этим вопросом (и, кстати, выбрал не тот ответ в их опроснике).0xd34df00d
13.04.2023 11:35+3Народ вроде разучился в ручное управление памятью. В смысле, люди младше 30 не умеют.
Да там не только за управление памятью платят, но и за весь этот пердолинг в темплейты констекспр sfinae концепты фолдинг экспрешонс я её рука if consteval.
То ли дело GHC.Generics!
С другой стороны, меня вот спрашивали про то, какое копирование в C++ — deep copy или shallow copy. Я был несколько ошарашен этим вопросом (и, кстати, выбрал не тот ответ в их опроснике).
Я такое воспринимаю как знак, что там клоунада, и туда идти не надо.
vkni
13.04.2023 11:35Да там не только за управление памятью платят, но и за весь этот пердолинг в темплейты констекспр sfinae концепты фолдинг экспрешонс я её рука if consteval.
Что характерно, этот пердолинг делается, в общем-то на языке, смутно напоминающем Хаскель (вернее Myranda). Я на эту тему всё хочу статью написать, даже пару страниц А4 от руки набросал, но отвлекаюсь.
Я такое воспринимаю как знак, что там клоунада, и туда идти не надо.
Это так. Причём у них в опроснике было написано, что shallow. Я вот только что проверил на
#include <iostream> struct A { char z[10]; int u; }; int main() { A a; strcpy(a.z, "Hello!"); a.u = 8; A b = a; std::cout << "'" << b.z << "'\n"; std::cout << "'" << b.u << "'\n"; std::cout << (size_t)a.z << " -- " << (size_t)b.z << "\n"; return 0; }Вывод
'Hello!' '8' 140701788539400 -- 140701788539384Ну, если это не deep copy, то меня тоже можно записать в клоуны. Хотя, конечно, сам вопрос дебильный.
0xd34df00d
13.04.2023 11:35+1Ну, если это не deep copy, то меня тоже можно записать в клоуны. Хотя, конечно, сам вопрос дебильный.
Технически там копируется указатель на саму строку (что можно проверить через печатание
(void*)b.z). Но сам вопрос конечно дебильный, потому что как напишешь, так и будет, а наличие value semantics делает любые такие разделения бессмысленными.Это хороший вопрос для обсуждения на интервью словами, где можно это всё обсудить, но для опросника это отвратительный вопрос.
vkni
13.04.2023 11:35Нет, как раз массив — это часть структуры, он копируется целиком:
140702007872008 -- 140702007871992 sizeof(A) = 16Это вывод указателей (a.z и b.z по методу (size_t)((void*) a.z)) и размера структуры. На int выдаётся 4 байта и 2 байта — выравнивание.
0xd34df00d
13.04.2023 11:35А, я вечером слепой был, да, конечно, ты прав.
Но стоит только сделать
char *zкак указатель (хоть на динамическую память, хоть на другой массив, хоть на что угодно), как всё станет неглубоким копированием.vkni
13.04.2023 11:35Ну, если мы говорим не на клоунском, то в семантике С, поскольку указатель — это first class value, то полем объекта является не тот объект, на который ссылается указатель, а сам указатель.
Единственное исключение из этого — вот встроенный массив, который копируется методом deep copy, как я и продемонстрировал. Все поля объекты копируются методом deep copy.Поэтому это всё вопрос терминологии, достаточно тонкий, т.к. семантика указателей С рассматривается с точки зрения языков с редуцированными указателями. Соответственно, приходится доопределять сущности.
Если доопределять сущности серьёзно, «по гамбургскому счёту», то объект, на который указывает указатель не может быть полем текущего объекта. Это может быть какая-нибудь DMA область, например.Поэтому вопрос, как часть опросника — клоунский. Но я не уверен, что мужик на той стороне это понял. Как тема для беседы — очень занятно.

WebConn
13.04.2023 11:35Но ведь у вас
A.z- это массив фиксированной длины внутри структуры, а не указатель. Он и будет вместе со структурой побайтово копироваться.vkni
13.04.2023 11:35+2Вопрос дебильный. Потому, что он в конечном итоге сводится к тому, «что принадлежит объекту, а что — нет?». Соответственно есть два ответа:
Если я утверждаю, что указатели — это просто поля, а вот то, на что они ссылаются — это нечто левое (там может быть хоть число 42 записано — хотите продемонстрирую?), то в С++ абсолютное deep copy: любое поле структуры конструктором по-умолчанию копируется целиком.Если мы считаем, что все указатели в структуре объекта указывают на объекты, принадлежащие данному, то у нас частичная shallow copy.
Поскольку профи. знают, что С++ идёт из С с его POD семантикой, то и ни о какой shallow/deep, которые идут от указателей, а в конечном итоге из LISP, нет.
KanuTaH
13.04.2023 11:35У знакомых мне хедж-фондов есть проблемы с наймом плюсистов на даже 500 килобаксов в год. У хаскелистов я таких зарплат не видел — хватает и меньших, и вакансии все равно закрываются быстро.
Потому что 3.5 хаскелиста закрывают все 20 вакансий - ведь багов же нет, сиди, плюй в потолок на удаленке в трусах поверх костюма и получай сразу 6 зарплат. А плюсовик на каждой из этих 2000+ вакансий все равно не справится, поэтому все эти вакансии остаются вакантными даже после найма очередного плюсовика.
0xd34df00d
13.04.2023 11:35Сразу шесть не выходит, невозможно столько раз анаморфизмом за день заниматься.


CrashLogger
13.04.2023 11:35-2Проблемы с производительностью в современном софте не из-за чистого кода, а из-за того, что подключают тонну сторонних библиотек на каждый чих. Вместо того, чтобы подумать полчаса и написать алгоритм, решающий твою конкретную задачу быстро и эффективно.

kelegorm
13.04.2023 11:35+3Я думал, это влияет только на объем общего кода, а не на скорость. Разве что на скорость сборки влияет.
MiraclePtr
13.04.2023 11:35+4чтобы подумать полчаса и написать алгоритм, решающий твою конкретную задачу быстро и эффективно.
А особенно весело бывает, когда такой Васян-велосипедостроитель, страдающий Даннингом-Крюгером в острой форме (который всегда считает что уж он-то напишет свою реализацию какого-нибудь алгоритма или функции гораздо лучше и эффективнее, чем в выверенных и массово используемых библиотеках разрабатываемых сообществом) добирается до чего-нибудь типа шифрования и делает так как привык... Тогда это уже начинает быть не только весело, но и очень больно и очень дорого.
CrashLogger
13.04.2023 11:35+2Массовость вообще ничего не гарантирует - вспомним heartbleed в OpenSSL. Но тут соглашусь - в шифрование лучше не лезть без соответствующей подготовки.
kelegorm
13.04.2023 11:35+8Программный код — это не только программа сама по себе, но и средство общения программистов. Даже небольшие проекты часто пишутся несколькими программистами. И важно иметь хороший язык, чтобы код читался легко и понятно.
Чистый код преследует именно понятность кода, призван облегчить это общение.
И я не помню рекомендаций в "чистом коде", где бы советовали каждый чих превращать в миллион классов, тем более использовать наследование.
И в третьих, у любого совета или инструмента есть область применения, условия, когда его хорошо использовать, а когда — нет. Использование инструмента не к месту не делает инструмент плохим.

wslc
13.04.2023 11:35+3Интересно посмотреть на то, какие коэффициенты нужно добавить в CTable и как будет выглядеть GetAreaUnion, если:
нужно рассчитать площадь фигуры, заданной точками (контур или внутренность)
другой случай: сами точки получаются, как значения функции
третий случай: пространство искривлено, а коэффициент искривления определяется внешней настройкой
Потому что когда методы виртуальные - это скучно и просто

alex-khv
13.04.2023 11:35+8Автору оригинальный статьи предлагали написать unreal engine 5 на структурах на стеке, без ооп, и принципов чистого кода ?
Как он там будет обмазываться свитчами для нанитов представили ?

z0rlog
13.04.2023 11:35+2Автор таки и пишет, не Unreal 5 конечно, но тоже годный движок. Ещё и объясняет что как работает: https://www.youtube.com/c/MollyRocket
Я сначала тоже к Кейси со скепсисом относился (аж трясло!), но потом "уверовал". Как только "уверовал" — появилось отвращение ко всей этой "энтерпрайз разработке на чистых кодах".
lamerok
13.04.2023 11:35+2Интересно, если такой оптимизтрованный код надо будет поменять или добавить новую сущность, но только проект будет из 100500 файлов, искать switch везде и анализировать все связи?
Что, если вместо применения здесь полиморфизма мы просто используем оператор switch?
А что если применить статический полимофирмз? И раскрутить цикл во время компиляции? Передайте ссылки через variadic template и все.
А ещё можно воспользоваться оптимизацией и девертуализацей, запретив наследникам интерфейса от себя наследоватся добавив final.

I_Love_Misato
13.04.2023 11:35+4Так это не для кого и не секрет. Чистый код в большинстве случаев будет не самым эффективным решением с точки зрения использования ресурсов. Но он и нужен вовсе не для этого. Автор (авторка?) предлагает заниматься ранней оптимизацией каждого куска кода)) Спасибо, не надо))) Нетленка МакКоннелла "Совершенный код" ему в помощь, про производительность там тоже есть. А на месте компании, ведущей блог, я бы постыдился переводить и постить подобные статьи)
victor_1212
13.04.2023 11:35+1> на месте компании, ведущей блог, я бы постыдился
автор оригинала Casey Muratori, конечно опыт у него своеобразный, но так он ничего пишет, типа не хуже других, если в своем контексте, см. другие статьи и обсуждение (этого хватает)
https://caseymuratori.com/contents

Daddy_Cool
13.04.2023 11:35Извините, не соглашусь. В примерах автора нет ранней оптимизации. Это естественная оптимизация. Возможно, что примеры автора слишком простые, усложнить задачу - и всё стало бы хуже, но не уверен.
Еще в 90-х видел в журнале статью про С++, и там показывалось какой ценой достаются эти ООП-плюш-плюшки.


SadOcean
13.04.2023 11:35+6То, что описал автор, конечно правда, но не вся.
Давно понятно, что мы платим скоростью за удобство организации и удобство разработки.
Как мне кажется, опасность "Чистого кода" (кстати очень крутая книжка по архитектуре, советую), как и многих других паттернов и рекомендаций по организации кода в другом.
За все нужно платить. И речь не про производительность, а про когнитивную и организационную сложность.
Каждый слой архитектуры, каждая абстракция - больше кода, каждый архитектурный шов - больше бойлерплейта, каждое использование интерфейса - сложнее понять.
- Если вы придерживаетесь адового MVP + MVVM, а у вас 12 окошек и их делают НЕ 3 разных человека (верстальщик, прикладной программист и серверник или программист бизнес логики) - вы платите зря.
- Если вы пытаетесь покрыть все тестами, абстрагируя и мокая технические детали - вы платите зря.
- Если вы сделали полностью асинхронный доступ к ресурсам, а ваш проект не серверный - вы платите зря.
- Если вы поддерживаете слой абстракций к БД, но спокойно живете на 1-й БД - вы платите зря.
- Если вы платите за реализацию паттерна, а он не оправдан - ну, вы поняли.MiraclePtr
13.04.2023 11:35+1...вы платите зря сегодня, но очень крупно сэкономите потом. При условии, что это "потом" вообще наступит :)
SadOcean
13.04.2023 11:35Ну если наступит - да.
Но гораздо чаще оно не наступает, или наступает не там, где платили.
Или оказалось, что платили не в той валюте, и ваш выстраданный слой абстракций не решает задачи абстрагирования от бд и нужно переписывать.
Но я не говорю что занятие бесполезное)
SadOcean
13.04.2023 11:35+2В дополнение к этому я бы ещё сказал, что автор все же не верно определил причину ухудшения качества программ.
Мне кажется, что они связаны с практиками быстрой и эффективной (более простой) разработки.
Размер и производительность по прежнему важны, но их значимость уменьшилась на порядки из-за развития оборудования, в то время как простота использования библиотек и инструментов оборачивается непропорциональным ростом размера кода и сложности (в смысле производительности)
VladimirFarshatov
13.04.2023 11:35Так автор статьи, кмк, поэтому и делает сравнение в виде кратности отката в развитии оборудования. Это же основной аргумент всех энтерпрайзов: "оборудование стало настолько мощным, что не важно" .. отчего при этом реакция сайтов (даже у Сбера и прочих) отлетает на пару и больше секунд, а то и минут(!) в зависимости от скорости наличного интернета? Как так .. (сарказм).
SadOcean
13.04.2023 11:35Да, но этот аргумент разобьет первый же попавшийся поклонник хардкор архитектуры.
Ведь есть "предварительная оптимизация" и оптимизацию в целом нужно начинать с профайлера.
И это правильная рекомендация - даже в хорошем коде вычислительной мощности может не хватать, а оптимизировать нужно сначала горячие зоны, которые дадут макс результат.
VladimirFarshatov
13.04.2023 11:35+1И там где работаю, и там где консультировал последнее время .. НИ РАЗУ мне не удалось донести эти мысли до кого-либо. Спасибо, попробую так.

Aniro
13.04.2023 11:35+5Надо пойти дальше и переписать все на ассемблере. Потому что компилятор неэффективно разместит значения в стэке, хотя можно использовать регистры, да и еще и использует call вместо инлайна. </sarcasm off>
На самом деле в данном примере любой нормальный инженер напишет switch и это все еще будет чистый код. Но скорее всего в реальной жизни вам классы фигур нужны не для того чтобы считать их площадь. Представьте что вы пишите геометрическую библиотеку и там определение точек пересечения фигуры и других геометрических примитивов, определение принадлежности точки фигуре, булевы операции над примитивами и прочее, прочее... вы все еще можете написать эту библиотеку с использованием enum и switch, но когда ее попытается доработать другой человек (или вы сами через год) разобраться в этом адище будет непросто. При этом выигрыш в производительности все еще будет, но он будет копеечным на фоне общей вычислительной сложности используемых алгоритмов.

dyadyaSerezha
13.04.2023 11:35+3Автор некорректно делает сравнение и абсолютно не понимает принципа полиморфизма и его преимуществ.
Например, в первом же сравнении в случае switch автор заодно убрал поинтеры на объекты, а значит сравнение уже некорректное, причём существенно некорректное. И так далее, и так далее.
[Лично я не думаю, что оператор switch обязательно менее полиморфический, чем vtable. Это просто две разные реализации одного принципа.
Уаы, автор не понимает самых основ, самых базовых азов. Приводить десятки более сложных примеров просто не имеет смысла.

nivorbud
13.04.2023 11:35+3"Чистый код" это уже стало нечто типа хайпа. Особенно в руках неофитов. И всё же (имхо) надо бы разумно и осторожно к этой "чистоте" относиться, без фанатизма.
Недавно пришлось работать с одним проектом, в котором программист фанатично следовал всем этим принципам чистоты. Функции/методы малюсенькие - до 5 строк (зачастую 1-2 строки). В огромном количестве. Раскинуты по множеству файлов. Простые вещи делаются через множественные цепочки вызовов этих функций. Поймал себя на мысли, что работать с таким кодом очень тяжело даже в редакторе, который отслеживает все связи и позволяет быстро переходить к нужной функции. Постоянные метания между сотнями функций и файлов замучили. В общем всё же меру надо знать.Daddy_Cool
13.04.2023 11:35"в редакторе, который отслеживает все связи и позволяет быстро переходить к нужной функции".
А чем именно вы пользуетесь?
isadora-6th
13.04.2023 11:35Думаю вы рассказываете о чём то таком)
Вообще неофиты на то и неофиты, что-бы делать СТРАШНОЕ

Rolk
13.04.2023 11:35А почему нельзя взять что-то лучшее от первого и второго и использовать их вместе? Зачем придерживаться одного направления и тупо следовать ему? Тебя обвинят в предательстве? С первым правилом чистого кода указанным в статье я не согласен, да, лучше использовать switch или if/else и понимание от этого не испортится. А остальные правила очень даже полезные. Очень важным правилом я бы отметил - Код не должен знать о внутреннем устройстве объектов, с которыми он работает. А каждый класс в отдельный файл - это уже маразм.

iburanguloff
13.04.2023 11:35+2Мне кажется чистый код пишется не для производительности, а для поддержания правильной архитектуры - тот же полиморфизм позволяет не городить тысячи switch-case. Хороший программист найдет грань между тем, где нужно писать грязный но быстрый код, а где - медленный, но разделенные на сущности и правильно направленные зависимости и абстракции. Можно писать насколько угодно быстрый код, но если он не будет легко изменяться или масштабироваться - его место в старом никому не нужном репозитории

Vladimirsencov
13.04.2023 11:35+1Примеры не очень релевантные. Обычно функция содержит больше логики. И тогда не так уж и важны потери на вызов виртуальной функции. Насчёт того, чтобы писать большие функции и методы я хочу сказать, что и при статической и при JIT компиляции эти вызовы обычно хорошо оптимизируются. Причем часто работать за компилятор вредно для производительности. Так что не стоит отказ от полиморфизма надо делать сознательно, как впрочем и его использование.

MaxakCh
13.04.2023 11:35+21) В компанию пришел новый программист и ему поставили задачу добавить к существующим фигурам еще одну. При этом программист вообще не знает как считать площадь и углы у существующих фигур. Так сложилось, что вычисление этих вещей является сложными узкоспециализированными бизнес задачами. В какой реализации займет меньше времени и породит меньше багов добавление новой фигуры?
2) Или приходит тот же новый программист и его просят добавить новый тип взвешивания площадей с использованием квадрата углов? В какой реализации этой будет быстрее и надежнее сделать?
3) Сколько времени от расчета всей программы занимает суммирование этих площадей? В конце концов может уже нужно запрограммировать это на ASIC устройстве, если это настолько критично?

Aquahawk
13.04.2023 11:35+2Да, да, да, и ещё раз да. Как человек плотно погружавшийся в недра компилятора и библиотек сворачивания белков, написавший графдвижок с нуля(не в стол, а работающий в продукте, окупившийся за считанные месяцы, и работающий уже третий год в продакшне без особых правок) я подтверждаю всё что здесь написано. Очень, очень часто "красота" и "чистота" кода прямо противоположны скорости и реальной понятности. Сложные вещи были и остаются сложными, нельзя взять сложный алгоритм и распилить его на миллион функций, в каждой не больше трёх if, и 10 строк кода. Нельзя распилить на бесконечное количество абстракций нижний уровень матмодели. Ну т.е. можно, но в итоге получится никому не нужный мусор.
VladimirFarshatov
13.04.2023 11:35+1Истинно так. Поддерживаю всеми своими 40+ лет разработки. Энтерпрайз обертка может только добавлять когнитивную сложность в проект, а заодно и повышать требования к железу.
Аргумент "за" только один, он выше:
В компанию пришел новый программист и ему поставили задачу добавить к
существующим фигурам еще одну. При этом программист вообще не знает как
считать площадь и углы у существующих фигур.т.е. берем то, что подешевле и пофиг что "оно не умеет, не знает". А то, что бизнес (и часто) со временем не тянет рост стоимости железа и закрывается, тому в Сети (да даже тут) есть примеров масса.
ksbes
13.04.2023 11:35+1А теперь добавьте к шейпам произвольный многогранник с самопересечениями. А затем — картинку в png.
Где это пройдёт проще и безболезненнее? Где меньше кода переписывать и багов плодить?
Хотя да, с десяток циклов может быть и сэкономим.

fishHook
13.04.2023 11:35+3Если те же самые примеры переписать на ассемблере, то мы наверняка обнаружим существенное увеличение производительности, правда? Автор статьи борется с какими-то мизерными проблемами. Подумаешь, заменил массив указателей на массив объектов, выиграл на разыменовании указателя. Подумаешь, избавился от виртуальных методов, выиграл на обращеннии к ТВМ. Если уж начали считать такты и байты, ну давайте посчитаем, а сколько тактов мы тратим на рантайм поддержку функций? Избавиться от них, конечно же, как от ненужных финтифлюшек навязанных кровавым ынтерпрайзом.
Разоблачая порочные практики "лишних" абстакций, автор ловко оставляет за скобками вопрос, а зачем это всё вообще напридумывали. Такое чувство, что "чистый код" - это такой масонский заговор, существующий чтобы нагадить из природной вредности. Очень это похоже на риторику разоблачителей "официальной" науки, когда демагог фокусируется на слабых сторонах теории, забывая о сильных, и выдавая эти слабые стороны за скрываемую от народа правду. Мне кажется, ни для кого не стало открытием, что не все абстракции бесплатны? Дайте оглянемся вокруг и убедимся, что подобный процесс удорожания не уникален для программирования. Давайте посчитаем, сколько бензина мы бы экономили выкинув из автомобиля системы безопасности и экологичекские примочки. А коробка-автомат? Это же 20% топлива впустую.
Автор молодец, что посчитал стоимость бест-практик в единицах и процентах, это интересно. Но вывод - если я его правильно понял - сделан совершенно бестолковый и вредный. Абстракции совершенно необходимы, это особенность нашего типа мышления - мы не можем оперировать большим количеством элементарных сущностей (вспомним закон Миллера). Что, собственно, подтверждается практикой, все эти методики чистого кода (если только автор не имеет в виду хамского тезиса, что многочисленные авторы соответствующих работ навыдумывали ерунды с потолка, и толко он знает, как надо) решают реально существующие проблемы, с коромыми поколения программистов сталкивались и продолжают сталкиваться ежедневно. Предложи соответсвующее бесплатное для ЦПУ решение и получишь почет, уважение и Нобелевскую премию. Думаю, что Ынтерпрайз(тм) был бы толко рад экономить ресурсы.ksbes
13.04.2023 11:35-1А коробка-автомат? Это же 20% топлива впустую.
Вот за то чтобы запретить коробку-автомат — я бы проголосовал бы. И даже не из-за топлива, а из-за опасного поведения машины (без водителя — сама едет).
Но вернёмся к главному:редложи соответсвующее бесплатное для ЦПУ решение и получишь почет, уважение и Нобелевскую премию. Думаю, что Ынтерпрайз(тм) был бы толко рад экономить ресурсы.
Ну так Раст вроде предлагает. Но многие сипипишники негодуют. Не всё так просто с абстракциями: платить за них всегда нужно: не тактами, так чем-то ещё.
Весь вопрос только — отбивают ли абстракции свою цену или нет? По практике могу сказать — что «чистый код» отбивает не всегда. Далеко не все системы должны иметь возможность динамически развиваться в макаронного монстра.
V1RuS
13.04.2023 11:35Если те же самые примеры переписать на ассемблере, то мы наверняка обнаружим существенное увеличение производительности, правда?
Нет, компиляторы достаточно хорошо оптимизируют машинный код, если им не мешать.
0xd34df00d
13.04.2023 11:35Что, собственно, подтверждается практикой, все эти методики чистого кода (если только автор не имеет в виду хамского тезиса, что многочисленные авторы соответствующих работ навыдумывали ерунды с потолка, и толко он знает, как надо) решают реально существующие проблемы, с коромыми поколения программистов сталкивались и продолжают сталкиваться ежедневно.
Проблемы реально существующие, а вот решения — так себе. Нет, не решают.

abar
13.04.2023 11:35+2Писал в блог ответ на статью автора, весь его пример разваливается как только мы попытаемся посчитать треугольник по трём сторонам, а не стороне и высоте.
Да, идея - "взять кусок проблемного кода и оптимизировать" - это, конечно, хорошо, но делать это надо уже на рабочей системе, когда понятно где завтыки и что проблема именно в них. Я бы предположил, что гораздо скорее мы уткнёмся в поблемы "как грузить фиугры и куда сохранять результаты", чем в то, что площадь фиугр считается слишком медленно.

arTk_ev
13.04.2023 11:35+2Автор некомпетентен.
Каждая CPU программа - это строго линейный список команд, - машина тьюринга.
Так как все алгоритмы пишутся под машину тьюринга и доказываются ими. Так же она нужна для конвеера команд в CPU. Чистый код - это всего лишь стандартный кибернетический подход к управлению сложными системами и так же это чистый системный анализ.
Держать в голове миллиарды строк команд, которые еще постоянно изменяются - невозможно.
С помощью декомпозиции можно легко получить стандартную пирамиду управления(аналогично пирамиде власти в армии). Теперь нужно держать в голове лишь несколько команд и список всех модулей. Способа идеальной декомпозиции пока не нашли.
С помощью инверсии зависимостей можно изменить направление зависимости модулей в нужных местах. Для уменьшения связности и большей модульности.
Функциональные принципы: отделение данный от логике, неизменяемость данных. Позволяет уменьшить энтропию кода.
Принципы ооп - применяют лишь в фасадах и плагинах, для структуры типов. Применяются ооп-функционал в качестве инструмента, сам принцип никто не использует.
Каждый if, каждое ветвление кода - это бифуркация, и является логикой. Каждый if увеличивает количество состояний по степенной функции. Десяток тысяч if увеличит количество состояния больше числа гугл.
if(true){}else{} даже в этом случае веротяность попадание в блок else равна 100% на продакшене. Значит каждого сочетания ветвления нужно продумывать и чтобы она всегда было корректное поведение. Каждый лишний if неминуемо приведет к багу.
По тому же принципу нужно учитывать и каждую связь, которых тоже больше гугла.
Поэтому программа в разработке - это всегда сложная система. Но с помощью кибернетики можно каждый баг превратить в уникальную фичу, и минимизировать негативные баги.
Вывод: чистый код по определению содержит меньшее инструкций, и меньше энтропии.
isadora-6th
13.04.2023 11:35"Чистый код" обычно подразумевает подход изложенный в одноимённой книге. Статью читали? Тут про разницу подходов между "чистым" и не "чистым".
0xd34df00d
13.04.2023 11:35+1if(true){}else{} даже в этом случае веротяность попадание в блок else равна 100% на продакшене.
Щито?

tmxx
13.04.2023 11:35+1На мой взгляд, статья - классическая ошибка проектирования.
Преждевременная оптимизация.

saboteur_kiev
13.04.2023 11:35+1Интересно, а автор меряет производительность методов сортировки всегда по самому плохому случаю? Или как?

GarryC
13.04.2023 11:35+2Я сначала подумал, что это статья от первого апреля, но нет - оказывается, это серьезно ...

0serg
13.04.2023 11:35+2Я пишу больше 10 лет высокопроизводительные системы работающие в реальном времени (3д сканеры) и по моему опыту то что описано в статье - это крайне плохой паттерн.
Во-первых как уже упомянули это premature optimization в чистом виде. В подавляющем большинстве случаев подобные улучшения будут незаметны в общей производительности приложения.
Во-вторых я не раз встречал код написанный в стиле продвигаемом автором и это ВСЕГДА была проблема которую было сложно поддерживать. Как вам например state machine вручную реализованная в виде гигантского switch на тысячи строк кода? А теперь давайте поищем в нем багу или попробуем написать юнит тест. Половина этого кода выбрасывалась при необходимости что-то более-менее серьезное в нем изменить или добавить, он одноразовый по сути
Я придерживаюсь простого правила: вначале пишем максимально читаемый код, затем запускаем профайлер и горячие точки оптимизируем. Для начала устраняя алгоритмические и архитектурные проблемы что дает наибольший эффект и на чистом коде делается гораздо проще. Затем оставшиеся хотспоты оптимизируются вручную. Обычно там требуется ускорить буквально пару функций и наибольший эффект достигается при их векторизации вручную на SIMD с помощью интринсиков. Буквально пара страниц квазиассемблера щедро разбавленного комментариями (иначе он не читается вообще) и покрытого тестами. И это отлично работает.
KamalMsc
13.04.2023 11:35Нельзя просто отказаться от десятка или больше лет эволюции производительности оборудования, только чтобы немного упростить жизнь программистов.
Да, только идея не в "немного упростить жизнь программистам", а писать так чтобы это можно было поддерживать. ООП, Clean и даже SOLID - мы привыкли говорить что это нужно чтобы упростить нашу жизнь, но это не значит "не хочу с этим возиться, хочу смузи в правой руке и печатать левой", это значит быть способными работать с ним дальше.
Что когда код разрастается или проект добавит принципиально новый функционал нам не придется нанимать еще 20 человек чтобы переписать 60% кодовой базы.
Во всем нужен баланс, если у вас команда душнит и на каждом шагу вас посылает на I, то это просто незрелые ребята.

SergeyTatevosyan
13.04.2023 11:35Ну так если включать голову то проблем не возникает, иногда если чистый код критически влияет на производительность- начинаешь писать в сторону производительности. Если производительно страдает не критически лучше написать красивый код, который выиграет в возможностях масштабирования, удобной поддержки и отказоустойчивости. Просто нужно найти тот самый баланс.
askolo4ek
13.04.2023 11:35Архитектурные решения и качество кода должно определяться от специфики задачи. Если мы ядро ОС, драйвера или ПО для ракет пишем, то очевидно на первое место встаёт скорость. Но бизнес в основном любит скорость разработки и выкатывание фич как можно быстрее, поэтому так и популярен DevOps, сокращающий Time to market и сопутствующие в основном питоновские фреймворки в которых есть всё из коробки. Но про скорость тут вообще тогда говорить бесмысленно))
Т.к. память и процессоры дешевеют, появились облачные технологии, контейнеризация, Kubernetes, то куда бизнесу куда проще масштабировать инфраструктуру вширь, кидая на это всё миллионы долларов
truevoice
13.04.2023 11:35Я думаю, тут стоило бы больше обращать внимания на абсолютные цифры, а не вычислять, образно говоря, во сколько раз 300 наносекунд больше 20.
romcky
13.04.2023 11:35ООП с продемонстрированным здесь полиморфизмом пришло на замену чисто процедурному программированию не потому, что оно быстрее, а потому, что в реальных проектах (когда речь идет о мегабайтах кода) проще в голове удерживать взаимосвязь всех этих абстракций между собой, проще вносить изменения, проще и быстрее вводить в курс дела новых разработчиков, ну и так далее

Gromilo
13.04.2023 11:35К сожалению код для машин и для людей требует разного и выглядит по разному. Это противоречие, нам приходится решать выбирая оптимальный вариант по ситуации. Иногда нам нужна поддерживаемость, иногда производительность.
В вопроса иерархия vs свич я обычно следую такому правилу: если набор операций не меняется, делаю иерархию, т.к. можно легко добавить новый тип, если часто дорабатывается набор операций - то свич, который часто выглядит как словарь ключ:операция.
У автора всё гладко получилось, но чтобы он делал, если бы потребовалось вычислять площадь произвольного многоугольника на точках или каких-нибудь параметрических кривых? Я бы хотел, чтобы такой жил в своём отдельном файле и не попадался разрабам на глаза без надобности.

t13s
13.04.2023 11:35Да ладно, полгигон. Пусть хотя бы расчет трапеции вкрутит... Было бы любопытно на это посмотреть
tenzink
13.04.2023 11:35Поступит так же как и с треугольником, а конретно подгонит под ответ. Хранить треугольник как высоту и сторону, это уже супер-странно. Однако автора это не останавливает. Так что трапецию он будет хранить как полусумму сторон и высоту :)
t13s
13.04.2023 11:35"Логично", черт побери! :) Но вот добавить операцию вычисления периметра - и отлаженный подход начнет давать сбои.

silverpopov
13.04.2023 11:35В тех редких случаях, когда производительность важнее поддерживаемости, можно сделать исключение из правил. КО.
tenzink
13.04.2023 11:35Проблема в том, что борьбу за производительность автор тоже провалил. Можно сделать заметно лучше. Автор добился микроскопическое улучшение в супер-синтетическом сценарии c перерасходом памяти, абсолютно нереалистичным представлением треугольника. У меня прям идея родилась, раз уж можно хранить всякую чушь (типа ширины и высота круга), то давайте считать площадь в конструкторе и хранить в
shape_base. Кто быстрее?silverpopov
13.04.2023 11:35Кстати, можно использовать union, как у автора чтобы все объекты были одного размера, но вместо switch использовать виртуальный метод. И будет быстрее.

Wan-Derer
13.04.2023 11:35Так, а я правильно понял что всякие интерпретаторы, как и Java- и др. виртуальные машины мы теперь должны переместить строго в топку? Ить они, подлые, тормозят как не в себя и память жрут, моё почтение! Только ж и успевай как поколения и-фонов отщёлкивать.....

noldowalker
13.04.2023 11:35Чистый код, который про читабельность, поддерживание и расширение щас бы критиковать за непроизводительность. Автор наяривает на цифорки, забыв что код надо писать, поддерживать, расширять, люди уходят и приходят, требования меняются. Чистый код писался в первую очередь для того, чтобы было легко понять что написано и какая логика заложена. На некоторых проектах, где требуется производительность да, можно пренебречь читабельностью, особенно в определенных местах. На некоторых такая мудреная и сложная бизнеслогика, что проще писать более медленный но понятный код. Ну выиграл ты 20% производительности, да хоть 100%, если сервис позволяет такую нагрузку и компания экономит на этом найм одного мидла, знаешь что тебе скажут? Нам наплевать.
Конкретное > абстрактного.
isadora-6th
13.04.2023 11:35Пример сферического чистого кода в вакууме
Очень абстрактно, очень поддерживаемо, очень понятно!

Gorthauer87
13.04.2023 11:35Ну по сути автор заменил динамическую диспетчеризацию на статическую и поручил более короткий быстрый и понятный код. И если это релевантно задаче, то круто, так и надо. Нечего заниматься преждевременным абстрагированием. Но вот когда нужна гибкость и гибкость в рантайме, то за неё придётся заплатить
gybson_63
13.04.2023 11:35+4Трагедия данной заметки укладывается в две строки
Убрали абстракцию.
Поддержка трапеций будет в другой версии проекта, написанной с нуля.
Занавес.
ProstoTyoma
Интересно, есть какие-то исследования или это личная идея автора оригинала.
VladimirFarshatov
Делал подобные исследования в свое время, но для PHP7.4. Цифирьки "на память":
полноценное оформление "сайта" с одной страничкой "Hello world" но вытаскиваемой из БД MariaDb 10.1 из таблички в три поля и 1000 записей. Core2duo 2ггц, 1Гб ОЗУ (живой по сию, памяти столько же).
Laravel -- около 70 запросов в секунду. Но тут возможно оплошал, т.к. это было мое единственное применение фреймворка для знакомства. После чего сказал "нунафиг" и забросил;
Yii 2 -- около 190 запросов в секунду;
ussr.monster -- делал под этот сайт (заброшен) микрофреймворк на 7.4 без ООП, как раз в стиле переведенной статьи. 2500 запросов в секунду при 3.5 кб памяти на запрос.
В целом, спасибо за перевод, очень наглядно.
AlexanderY
Справедливости ради, часто при таких замерах забывают про production-рекомендации для Laravel. И измеряют в debug-режиме, грубо говоря.
Я как раз не так давно сравнивал производительность одного и того же микросайта на своем ноуте. В debug-режиме (без opcache) было 14 rps на ядро, с opcahe 250 rps, а в production (с opcache) уже 407.
Это, правда, не сравнится с вашими 2500 на микрофреймворке. Даже интересно, там тоже бэк в БД ходил?
VladimirFarshatov
Конешно, своим же пакетом а-ля Yii_Db, да в этой части был ООП, но .. местами. ;). Код с т.з. функциональности один и тот же. Автозагрузка классов .. 5 или 6. Диспетчер - рекурсивный, позволял наращивать структуру "вверх" произвольно: ... - модуль - контроллер, в т.ч. после себя запускать те же фрейворки для продолжения роутинга.
Вот насчет production рекомендаций - уже не помню. Помню что ещё делал аналог на Зенде 1.11 кажется, но он делался отдельно и его цифирек уже не помню. Разница с Yii не принципиальная, порядок тот же.
opcahce включен в этих цифирьках.
vkni
Это, надо сказать, общее место у C++-ников, уже лет 25, что ООП сильно тормозит выполнение. Собственно, шаблоны C++ введены вот именно по этой причине — ускорить полиморфизм, перейдя от динамики к статике.
Поэтому статья ничего нового не несёт. Единственно, я не очень согласен с тем, что 10 раз отбрасывают в 2010 — поскольку у меня есть Thinkpad с Core2 Duo, ну не тормозит он в 10 раз по сравнению с новым Thinkpad'ом.
0xd34df00d
Только пользоваться этим невозможно, потому что тогда все должно быть в хедерах, и один TU собирается по 5-10 минут. Я не преувеличиваю, у меня были такие кодовые базы.
Я тут как раз вчера взамен своей старой машины с i7 3930k (HEDT из 2012-го) собрал новую на Ryzen 7950X3D (даже, наверное, не совсем HEDT). Первая компиляет, скажем, qtwebengine за 150-170 минут, вторая — за 20. Почти 10 раз.
maeris
Как-то 5-10 минут это ещё хорошо, это ещё код простой был. А так, конечно, нужно писать такой код на других языках.
0xd34df00d
На каких имеющихся языках такое писать, я так и не придумал, поэтому мы там начали дружно делать свой DSL, но, к сожалению,
курицы кончилисьфирма сдохла раньше.Lizdroz
На каких например?
nin-jin
https://dlang.org/articles/pretod.html
vkni
С++ — это язык, сделанный армейским способом...
Небось не одно ядро использовалось?
0xd34df00d
Нет, конечно. Но жрёт вся система при компиляции 200 ватт, а не 420, как предыдущая. Поэтому на что тут нормировать — вопрос открытый.
vkni
Я про однопоток — как ты можешь заметить, статья про однопоточную производительность. Однопоток с Core2Duo вырос раза в 2-3, но никак не в 10. Я же периодически пишу с ноута 2007 года, на нём ещё можно работать, хотя уеб, конечно, тормозит. А 10 раз — это запретительные тормоза.
Ну и смешно, когда про энергосбережение пишет чувак из Техаса (возможно на пикапе). :-)
0xd34df00d
Ну ещё бы, многопоток на C++ — это совсем больно.
На электропикапе, но неважно :]
Энергопотребление — это и то, сколько может вытянуть бесперебойник при отключении питания. Энергопотребление — это и то, сколько дополнительной энергии надо затратить на отвод тепла жарким летом. И в последнем случае разница получается уже не в пару сот ватт, а в среднем ватт в 600-700.
vkni
Водяное охлаждение + радиатор на улицу!!!! Ты видел, как устроены были старые техасские дома? Из двух половин, а между ними арка, где всегда есть ветерок. :-)
0xd34df00d
Я и всерьез-то воду не хочу — для 24/7, включая когда меня нет дома весь день, как-то стремно.
domix32
Учитывая как он "чистый код" пишет я крайне сомневаюсь, что он хоть сколько-то на этот чистый код смотрел. Не говоря уж про работу в чем-нибудь облачном.