
Спойлер
Всем привет, как и обещали, публикуем продолжение. Первая часть, напомню, здесь (если не читали, то лучше начать с нее, чтобы картина была цельной).
Небольшое введение
За этот период в целом, у нас мало что поменялось - очень много работы, очень много фич, работаем над облачной версией, таймшитами, гибкими полями, шаблонами проектов и типов задач, бизнес-процессами, миграциями - интенсивность такая, что иногда дым от клавиатуры идет. Но все же - вернемся к анонсированному в "предыдущем выпуске".
Гибкие поля
Гибкие поля - очень важная функциональность, поэтому они заслуживают отдельного раздела. Часто требуется, чтобы атрибутный состав (набор полей) сущностей (а значит и таблиц) был не фиксирован, а позволял донастроить себя в момент использования приложения. Для таск-трекера это требование особенно важно, самый простой пример - разный состав и типы полей у разных типов задач (задача, дефект, история). Причем разные поля могут быть у разных проектов. Разумеется, в Jira все это есть. Значит и у нас будет.
Как это обычно делают:
Делаем широкую таблицу, в которой учитываем все-все-все, потом показываем только то, что будет нужно показывать. Самый плохой путь. В никуда;
-
Добавляем поля прямо в базу данных, напрямую в таблицы. Вроде бы БД отвечает за структуры данных - почему бы ей это и не поручить? Почему это плохо и не получится:
Структура БД зависит от текущих настроек приложения и не закреплена;
Средства разработки (парадигма моделей объектов, ORM) не умеют так работать (или умеют?);
Установка доработок, эволюция приложения - также максимально затруднена ввиду неясной структуры БД (имеется ввиду на разных инстансах);
Короче говоря если такой дорогой и идти, то надо прорабатывать это с самого начала и выбирать соответствующий (и специфический) инструментарий;
-
Делаем дополнительный “словарь данных” (БД внутри БД), т.е. таблицу “перечень дополнительных полей” в привязке к сущностям и типам, а также таблицу “значения дополнительных полей” в привязке к экземпляру сущности, полю. Вот это частый сценарий, который реализуют через несколько вариаций:
Либо хранят все значения в текстовых полях, преобразовывая "в оба конца" при чтении / записи;
Либо заводят для каждого из значений несколько типизированных колонок (Int, String, Date, Float) и заполняют только одну из них, оставляя другие пустыми - в зависимости от типа значения;
Ну и тут в целом большой простор для творчества, часто заводят типы “списки”, “списки с мультивыбором” и то, что нужно в каждом конкретном случае.

В целом подход старый, себя зарекомендовал, так часто делают. Разве что немного устарел. Из минусов - если нужно разместить много дополнительных полей “в строчку” (т.е. в одной строке данных, в одном запросе) - то для каждого такого поля нужно будет писать JOIN (с этой дополнительной структурой), что, конечно, при больших объемах будет тормозить при нарастающем числе джойнов.
select o.id, o.[common_fields],
av1.field_value as custom_field1,
av2.field_value as custom_field2,
...
from main_object o
left join add_values av1 on av1.value_name = 'custom_field1' and av1.obj_id = o.id
left join add_values av2 on av2.value_name = 'custom_field2' and av2.obj_id = o.idРаз текст главы еще не кончился, то можно предположить, что мы и здесь пошли другим путем. В итоге:
Мы оставили описание “словаря данных”, примерно как в пункте 3;
-
А сами данные дополнительных (для себя мы назвали их "гибкими" или flex-полями) полей мы храним в одном поле типа json (jsonb) у каждого экземпляра сущности:

Хранение гибких полей в виде json
Сначала было немного страшновато, но потом привыкли и поняли насколько это удобно. Современная реализация json’а в БД PostgreSQL позволяет делать запросы и “внутрь” него, извлекая определенные значения, индексировать внутренние поля и так далее. Запросы правда получаются страшноватые:
select id, task_id, flex_value, jsonb_array_length(flex_value)
from jgproj.task_flex_value
where flex_value @? format('$[*] ? (@."fieldId" == %s && @."value"[*] == %s)', 4519, 8760)::jsonpath
and flex_value @? format('$[*] ? (@."fieldId" == %s && @."value"[*] >= %s && @."value"[*] <= %s)', 4498, 0, 2)::jsonpathВалидация значений
Еще одна архитектурная тема “на подумать и не забыть”. Порассуждаем, где у нас производится валидация значений. Собственно никого не удивлю, если скажу, что везде (фронт, бэк, БД), опишу подробнее:
-
Фронт. Есть такая парадигма, которая утверждает, что данные должны проверяться там, где они в систему попадают. В целом, это разумно, но есть технические нюансы. Каких проверок мы ожидаем на фронте? Наверное, самых очевидных:
Что в окно ввода для числа введено число, а не текст;
Что формат введенного емейла соответствует (а вы знали какое “самое корректное” регулярное выражение (regexp) для емейла? Я тоже не знал:
https://stackoverflow.com/questions/201323/how-can-i-validate-an-email-address-using-a-regular-expression
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
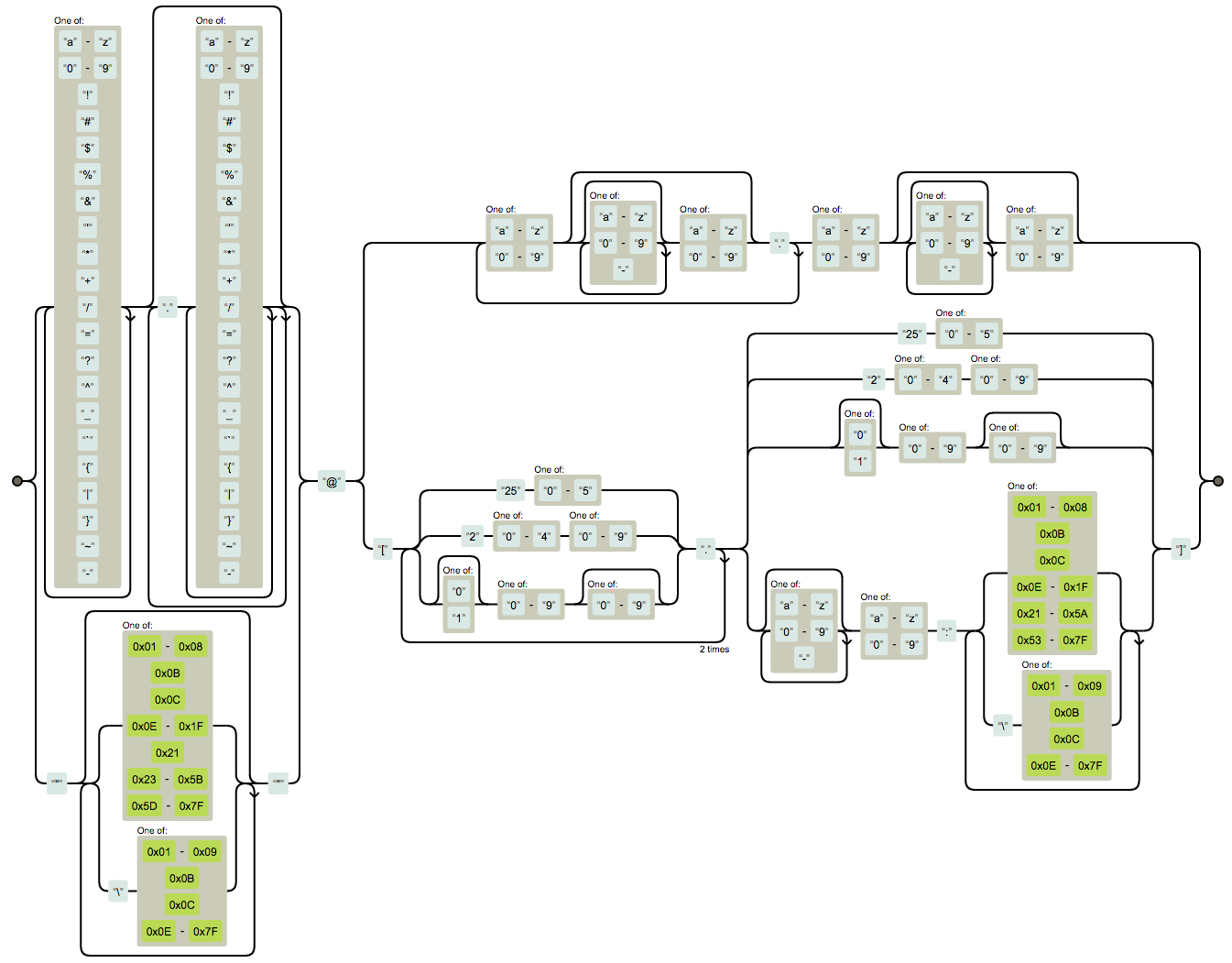
Некоторые несложные проверки на диапазоны (процент от 1 до 100), на язык (введите фамилию латиницей);
Может быть что либо еще.
-
Бэкенд. Бэкенд не должен доверять фронту и делать проверки повторно. Почему? Потому что фронт - это браузер и исправить в нем можно все что угодно (нажав F12), а также - фронтов может быть несколько (браузер, мобильное приложение). Кроме этого бэкэнд добавляет проверки:
Сложные расчетные проверки (например, что снимаемая сумма денег не больше баланса на карте + комиссия);
Может быть что либо еще.
-
БД. База данных - штука специфическая, транзакционная, она прекрасно решает следующие проверки:
Уникальность данных по ключевым полям. Да, именно на базе, так как бэкэнд по природе своей многопоточный, один поток может не видеть изменений другого (отчасти это решается, конечно). В БД такой трюк не пройдет;
Ссылочная целостность (через foreign key). Тоже годами стабильно работающий механизм.
Возникает вопрос - как будем решать? Не хочется дублировать код, не хочется его размазывать.
Изначально на ум приходит стандартный подход - использование аннотаций @Min, @Max и подобный на моделях “слоя” бэкенда. Однако фактически при таком подходе мы описываем проверки данных как бы дважды - один раз на уровне типов полей БД, второй раз на уровне моделей и эти описания лежат в разных местах.
Мы придумали иной подход, он заключается в следующем:
Каждая сущность бэкенда, она же таблица БД описана в БД (стандартным способом). А значит есть возможность вытащить типы данных, длины и размерности;
Также создаем дополнительную таблицу правил валидации для более сложных случаев (как раз минимумы, максимумы, проверки по regexp);
-
Пишем модуль валидатора на бэкенде, который умеет проверять (валидировать) “сущность” (перед выполнением entity.save()):
Проверять типы данных;
Делать более сложные проверки (диапазоны, regexp).
Каждый объект Repository перед сохранением сущности делает проверку через валидатор;
Передача правил проверки на фронт также достаточно тривиальна;
В коде это выглядит примерно так.
Реализация валидатора
// Интерфейс валидатора
@Repository
interface ValidateRuleRepository: JpaRepository<ValidateRule, Long> {
@Query(value = """
select column_name,
is_notnull,
is_required,
data_type,
character_maximum_length,
numeric_precision,
numeric_precision_radix,
udt_name,
table_description,
column_description,
rule_name,
rule_desc,
rule_type,
rule_regexp
from jgutil.f_get_validations(p_schema => :schema, p_object_name => :objectName)
""", nativeQuery = true
)
@Cacheable("validate_rules")
fun getValidateRules(schema: String, objectName: String): List<ValidateRule>
}
.....
// Все репозитории в коде реализуют интерфейс валидатора:
@Repository
interface ProjectRepository : JpaRepository<Project, Long>, ValidatableRepository, CodeSearchable {
.....
// соответствие типов JVM и БД:
companion object {
// Соответсвтие типов БД и JVM
val typesConformity: HashMap<String, List<String>> = HashMap()
}
init {
typesConformity["varchar"] = listOf("String")
typesConformity["int8"] = listOf("BigInteger", "Long", "long")
typesConformity["int4"] = listOf("Integer", "int")
typesConformity["int2"] = listOf("Short", "short")
typesConformity["timestamp"] = listOf("OffsetDateTime")
typesConformity["text"] = listOf("String")
typesConformity["bool"] = listOf("boolean", "bool", "Boolean")
typesConformity["date"] = listOf("OffsetDateTime")
typesConformity["timestamp"] = listOf("OffsetDateTime")
typesConformity["_text"] = listOf("[String]")
typesConformity["_int2"] = listOf("[Short]", "[short]")
typesConformity["_int4"] = listOf("[Integer]", "[int]")
typesConformity["_int8"] = listOf("[Long]", "[long]", "[BigInteger]")
// Продолжить
}
.....
// Валидация каждого объекта
fun validateObj(obj: Any, schema: String, objectName: String, extended: Boolean): List<ValidateResult> {
val res = ArrayList<ValidateResult>()
val rules = validateRuleRepository.getValidateRules(schema, objectName)
val сlazz = Class.forName(obj.javaClass.name)
for (field in сlazz.declaredFields) {
var fieldFound = false
for (rule in rules) {
var dbFieldName = field.getAnnotation(Column::class.java)?.name
if (dbFieldName.isNullOrEmpty()) dbFieldName = field.name.camelCaseToUnderscore()
if (rule.columnName == dbFieldName) {
val dbType = rule.udtName
val jvmType = parseArray(field.type.name) ?: field.type.name.substringAfterLast(".", field.type.name)
val confType = typesConformity[dbType]
if (confType == null) {
res.add(
ValidateResult(
field.name, dbFieldName, rule,
ValidateResult.Reason.TypeNotFound, rule.columnDescription,
"dbType: $dbType"
)
)
fieldFound = true
break
} else {
if (!confType.contains(jvmType)) {
res.add(
ValidateResult(
field.name, dbFieldName, rule,
ValidateResult.Reason.TypeMismatch, rule.columnDescription,
"dbType: $dbType != $confType"
)
)
fieldFound = true
break
} else {
println("testing rule ${rule.columnName}")
validateField(obj, field, dbFieldName, rule, res)
fieldFound = true
break
}
}
}
}
if ((!fieldFound) && (extended)) {
res.add(
ValidateResult(
field.name, null, null,
ValidateResult.Reason.RuleNotDefined, null
)
)
}
}
return res
}
.....
//Валидация поля (атрибута объекта)
fun validateField(obj: Any, field: Field, dbFieldName: String, rule: ValidateRule, res: MutableList<ValidateResult>) {
field.isAccessible = true
var ruleImplemented = false
val value = field.get(obj)
// Общие проверки
rule.isNotnull?.let {
if ((it) && (value == null)) {
res.add(
ValidateResult(
field.name, dbFieldName, rule,
ValidateResult.Reason.NotNull, rule.columnDescription, "dbType: ${rule.udtName}"
)
)
}
}
// Проверки по типам
if (rule.udtName == "varchar") {
ruleImplemented = true
val valueAsString = value as String?
rule.characterMaximumLength?.let {
if (valueAsString.NN().length > it)
res.add(
ValidateResult(
field.name, dbFieldName, rule,
ValidateResult.Reason.MaxLength, rule.columnDescription, "dbType: ${rule.udtName}"
)
)
}
rule.isRequired?.let {
if ((it) && (valueAsString.isNullOrBlank()))
res.add(
ValidateResult(
field.name, dbFieldName, rule,
ValidateResult.Reason.Required, rule.columnDescription, "dbType: ${rule.udtName}"
)
)
}
val rrexp = rule.ruleRegexp
if (!rrexp.isNullOrBlank()) {
val rx = rrexp.toRegex()
if (valueAsString!=null && !valueAsString.matches(rx))
res.add(
ValidateResult(
field.name, dbFieldName, rule,
ValidateResult.Reason.Regexp, rule.columnDescription, "dbType: ${rule.udtName}"
)
)
}
}
if (!ruleImplemented) {
//TODO not implemented yet
}
}
Профит от этого подхода мы начали получать сразу - если по невнимательности (это реальный кейс) мы завели разные типы данных в БД и на бэкенде, то валидатор тут как тут и не пропустит неверные значения.
Обработка ошибок
Ещё один момент, про который нужно хорошо подумать. Ошибки, они же исключительные ситуации бывают также на трех слоях, при этом транслируются в конечном итоге на фронт (БД-бэкенд-фронт, бэкенд-фронт). Если ничего здесь не предпринять, то от БД приходит куча текста, в котором где-то нужно разглядеть ошибку БД (для бэка же это просто "ошибка запроса в БД"), на фронт ошибки бэка (свои или БДшные) приходят в виде 500 кода и кучи технической информации.
Пример, как выглядела ошибка БД
В логе приложения:
org.postgresql.util.PSQLException: ERROR: ~~DB-LG004. БД - Класс LG - Нарушение логической целостности данных. Запись с таким набором идентификаторов не существует или уже закрыта. Hint: Проверьте правильность набора идентификаторов модифицируемой записи . system_state: P0001 . errm: DB-LG004. -->p_id 6919. detail: .context: PL/pgSQL function jgproj_api.f_del_task_type_ref(bigint) line 16 at RAISE .Constraint:
Где: PL/pgSQL function jgutil.f_return_error_description(text,text,text,text,text) line 80 at RAISE
SQL statement "SELECT jgutil.f_return_error_description(l_con, l_state, l_errm, l_detail, l_context)"
PL/pgSQL function jgproj_api.f_del_task_type_ref(bigint) line 27 at PERFORM
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2674)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2364)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:354)
at org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:484)
.......При этом в ответе Spring-контроллера ошибка показывалась примерно так:
{
"timestamp": "2023-04-07T15:10:41.478+00:00",
"status": 500,
"error": "Internal Server Error",
"exception": "org.springframework.orm.jpa.JpaSystemException",
"message": "could not extract ResultSet; nested exception is org.hibernate.exception.GenericJDBCException: could not extract ResultSet",
"path": "/project/99160/taskType/6919",
"datetime_iso": "2023-04-07T18:10:41.47997+03:00",
"version": "0.0.1"
}
Неинтересно. Давайте подумаем, что хотим:
Чтобы до фронта доходил текст ошибки в том виде, в котором его сразу можно показывать;
Чтобы была связка по информации об ошибке БД-бэк, для понимания полной картины мира;
Чтобы в максимуме ситуаций мы показывали истинную (бизнесовую) причину ошибки, например не "ошибка первичного ключа в таблице 'проекты' ", а "невозможно создать проект, так как проект с таким наименованием уже существует";
А также нам надо договориться какие коды ошибок в каких ситуациях мы передаем на фронтэнд - когда 400, а когда 500. А может быть лучше всегда 200, а информацию об ошибке передавать в специальном объекте “ошибка”? А может 418 «I’m a teapot»?
Так родился модуль "ошибатор".
Что мы сделали:
Завели глобальный перечень ошибок, с категориями и нумерацией (прямо как, например, знаменитое ORA-XXXX);
На базе - создали некоторые примитивы, которые позволяют вычислить поля ключей, которые должны быть уникальны (а не просто техническое имя ключа), разыменовывания полей по внешним ключам;
На базе - сделали обертку запуска функций, которая, в случае возникновения ошибки не отдает Exception, а формирует информативный json, который пробрасывает бэку;
На бэке - разработали специальные аннотации, которые берут на себя рутинную работу по обработке ошибок.
Теперь ошибки БД выглядят вот так
В логе приложения (обратите внимание на класс исключения):
com.rit.crossdev.jaga.exceptions.DBException: Запись с таким набором идентификаторов не существует или уже закрыта
at com.rit.crossdev.jaga.service.ErrorHandler.withDBErrorHandling(ErrorHandler.kt:363)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
В ответе контроллера:
{
"timestamp": "2023-04-07T15:37:35.727+00:00",
"status": 500,
"error": "Internal Server Error",
"exception": {
"code": "BK-00001",
"level": "SEVERE",
"cause": {
"code": "DB-LG004",
"level": "WARNING",
"hint": "Проверьте правильность набора идентификаторов модифицируемой записи",
"additionalInfo": "",
"text": "Запись с таким набором идентификаторов не существует или уже закрыта",
"group": "БД - Класс LG - Нарушение логической целостности данных"
},
"text": "Необработанная ошибка BACKEND",
"group": "BACKEND"
},
"message": "Необработанная ошибка BACKEND",
"path": "/project/99160/taskType/6919",
"datetime_iso": "2023-04-07T18:37:35.7275917+03:00",
"version": "0.0.1"
}
Реализация и использование аннотаций
//Собственно сама обертка аннотация
@Target(AnnotationTarget.FUNCTION)
@Retention(AnnotationRetention.RUNTIME)
annotation class DBErrorProcessable {
}
......
//И ее реализация
@Around("@annotation(com.rit.crossdev.jaga.service.DBErrorProcessable)")
fun withDBErrorHandling(jointPoint: ProceedingJoinPoint): Any? {
logger.info("withDBErrorHandling ${jointPoint.signature.name}")
return try {
jointPoint.proceed()
} catch (ex: JpaSystemException) {
val code = ex.findPsqlErrorCode()
val error = findAndPrintErrorStr(code, ex)
throw DBException(
code = error.code,
level = error.level,
group = error.group,
text = error.text,
additionalInfo = error.additionalInfo,
hint = error.hint
)
} catch (ex: Exception) {
val error = findAndPrintError(DEFAULT_DB_ERROR_CODE, ex)
throw DBException(
code = error.code,
level = error.level,
group = error.group,
text = error.text,
additionalInfo = error.additionalInfo,
hint = error.hint
)
}
}
......
//Получаем error code и пытаемся найти ошибку в кэше ошибок по коду если не получилось то возвращаем необработанную ошибку БД по умолчанию
//Для бэкенда аналогичный обработчик
@Around("@annotation(com.rit.crossdev.jaga.service.ErrorProcessable)")
fun withErrorHandling(jointPoint: ProceedingJoinPoint): Any? {
logger.info("withErrorHandling ${jointPoint.signature.name}")
return try {
jointPoint.proceed()
} catch (ex: AttributeNameAlreadyExistException) {
val error = findAndPrintError(ATTRIBUTE_WHITH_SAME_NAME_ALREADY_EXIST_ERROR_CODE, ex)
throw BadRequestException(
code = error.code,
level = error.level,
group = error.group,
text = error.text,
additionalInfo = error.additionalInfo,
hint = error.hint,
cause = ex
)
}
catch (ex: DBException) {
val error = findAndPrintError(DEFAULT_BK_ERROR_CODE, ex)
throw BEException(
code = error.code,
level = error.level,
group = error.group,
text = error.text,
additionalInfo = error.additionalInfo,
hint = error.hint,
cause = ex
)
}
......
//Таким образом вызов оборачивается
@ErrorProcessable
fun foo(){
bar()
}
@DBErrorProcessable
Fun bar(){
}
дополнительно - как по FK извлечь перечень полей с их описаниями
SELECT
tc.table_schema,
ccu.constraint_schema,
tc.constraint_name,
obj_description(format('%s.%s', isc.table_schema, isc.table_name)::regclass::oid, 'pg_class') AS table_description,
tc.table_name,
kcu.column_name,
pg_catalog.col_description(format('%s.%s', isc.table_schema, isc.table_name)::regclass::oid, isc.ordinal_position) AS column_description,
ccu.table_schema AS foreign_table_schema,
ccu.table_name AS foreign_table_name,
obj_description(format('%s.%s', ccu.table_schema, ccu.table_name)::regclass::oid, 'pg_class') AS foreign_table_description,
ccu.column_name AS foreign_column_name,
pg_catalog.col_description(format('%s.%s', ccu.table_schema, ccu.table_name)::regclass::oid, isc.ordinal_position) AS foreign_column_description
FROM
information_schema.table_constraints AS tc
JOIN information_schema.key_column_usage AS kcu ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
JOIN information_schema.constraint_column_usage AS ccu ON ccu.constraint_name = tc.constraint_name
AND ccu.table_schema = tc.table_schema
JOIN information_schema.columns isc ON isc.table_schema = tc.table_schema
AND isc.table_name = tc.table_name
AND isc.column_name = kcu.column_name
WHERE
tc.constraint_type = 'FOREIGN KEY'
AND tc.table_name = 'task_assignee'
AND tc.constraint_name = 'assignee_fk'Executor, протоколирование вызовов БД, обработка ошибок
Модуль “Экзекутор” (рабочее название, которое прижилось пока без нормального русского
аналога). У него интересная судьба, так как вызов, который он был призван решать возник достаточно внезапно, а именно в момент, когда мы хотели сдать первую версию в эксплуатацию - от них (эксплуатационных служб) пришло дополнительное требование, которое было сформулировано примерно так: “для качественной поддержки пользователей необходимо видеть (протоколировать) их действия в системе”. Первая мысль, как всегда была “классической” - взять ELK-стек, парсить логи приложений с его помощью. Опять таки, сделать нужно было быстро и “с гарантированным результатом”. И мы как всегда пошли своей дорогой ;) У нас же есть API в БД, так? Т.е. мы можем зафиксировать все действия с данными, которые производит пользователь (а по ним уже понятно, что он делает в интерфейсе приложения). Так родился его величество, модуль Экзекутор. Что он из себя представляет и что делает:
Это функция, которая написана в БД. На вход она принимает имя (api) функции, которую она будет запускать, а также набор параметров в виде json;
Также это “обвязка” в коде бэкенда, позволяющая вызвать эту функцию и правильно передать параметры;
Она парсит json с параметрами, самостоятельно находит наиболее подходящую функцию, если их несколько (например похожих или перегруженных) по набору параметров, запускает ее;
Передает дополнительные параметры, например идентификатор пользователя;
Протоколирует запуск, переданные параметры;
Протоколирует результат, т.е. исходящие параметры;
Реализует централизованную обработку ошибок, возникающую при работе “вызываемых” (api) функций, возвращая информативный json (таким образом удалось убрать много однотипных кусков кода обработки ошибок из api-функций);
[В планах] Пробрасывает протоколирования из RAISE NOTICE / WARNING в логи бэкенд приложений;
[В планах] Сделать универсальное версионирование объектов, примерно как умеет Hibernate Envers;
[В планах] Доработать протоколирование, чтобы сделать удобное профилирование запросов;
[Под вопросом] А может быть уже и от JPA отказаться...
Недавно к нам присоединился новый разработчик и когда он это увидел, его реакцией было "офигеть, спринг в БД написали".
Примеры вызовов функций БД API из Kotlin
Без Экзекутора:
@Query(
"""SELECT * FROM jgproj_api.v_task_assignee WHERE task_id = :task_id ORDER BY Id DESC LIMIT 1""",
nativeQuery = true
)
@DBErrorProcessable
fun findLastRecordByTaskId(
@Param("task_id") taskId: Long
): TaskAssigneeС экзекутором:
val user = executor.executeDbApi(
"jguser_api.f_upd_intern_user_profile_by_user",
userProfileByUser.toDbRequest(isOfficeLocationEdited),
UserProfile::class.java
).value?.convertToDto() ?: throw RuntimeException("can't update userProfile")Результат работы экзекутора - запись в таблице протокола вызовов:

Также есть решение, когда вызываемая функция возвращает набор значений (Resultset), а не “скалярную” величину - он преобразовывается в json и в таком виде передается на бэкенд:
получение результата функции в виде массива json
CREATE OR REPLACE FUNCTION jgcore_api.f_execute_table_func(p_sql text, p_is_json boolean)
RETURNS json
LANGUAGE plpgsql
AS $function$
declare
l_rec record; -- Очередная запись, полученная из прикладной функции
l_result jsonb; -- Результат выполнения прикладной функции
begin
l_result := '[]'::jsonb;
if not p_is_json then
for l_rec in execute 'select row_to_json(res)::jsonb as val from ' || p_sql || ' res' loop
l_result := l_result || l_rec.val;
end loop;
else
for l_rec in execute 'select res from ' || p_sql || ' res' loop
l_result := l_result || l_rec.res::jsonb;
end loop;
end if;
return l_result::json;
end;
$function$
;
COMMENT ON FUNCTION jgcore_api.f_execute_table_func(text, bool) IS 'Выполнение прикладной функции, возвращающей setof и оборачивание результата в JSON';
Поддержка нескольких языков
Мы целимся в историю с поддержкой нескольких языков, хотя, признаемся, пока не было времени этим полноценно заняться. Проблематика здесь простая и понятная - в каждой среде разработки на каждом слое (фронт, бэк, БД) строки локализации хранятся по своему и “локально”. За примерами далеко ходить не надо - это файлы strings.xml в андроиде, файлы-bundle *.properties для локализаций например, в Eclipse и так далее.
Чем плохо, когда все "так как есть".
Все строковые ресурсы разнесены по разным репозиториям;
И еще и в разных форматах (тех языков, фреймворков и т.д. - strings.xml, bundle.properties) и т.д.
Это достаточно негибко, если поручать это переводчикам - нужно и работать обучить (и с IDE и с git) и доступы дать и чтобы ничего не сломалось.
Поэтому стали думать.
Изначально хотели поместить все строки локализации в БД, снабдив их мнемоническим ключом (имеется ввиду некая уникальная строка, типа "project.status.new". При этом то, что требует перевода (например, значения справочников) мы пишем “двумя полями”, а именно “значение на базовом языке” плюс “мнемоника”. Далее для каждой мнемоники заводим нужное количество значений на разных языках.
А на каждом слое (фронт, бэк, БД) уже хотели интерактивно извлекать нужные значения на нужных языках.
Однако этой дорогой не пошли, так как не удалось договориться с фронтами - они убедили нас, что это будет медленно и неудобно.
Эту идею можно оставить, но немного доработать - генерировать соответствующие файлы ресурсов, основываясь на данные, внесенные в БД непосредственно перед компиляцией и деплоем, а потом использовать их уже для компиляции приложений фронтенда и бэкенда "без захода в БД". Засматриваемся для этого на библиотеки, типа KotlinPoet и подобные.
Есть еще очень интересные решения, которые можно рассмотреть - localazy, localise и подобные.
В чем суть: вы работаете с переводами в облаке и получаете достаточно роскошные возможности:
Ведение строк переводов (ну, как обычно - ключ+значение)
Скачивание в разных форматах (все популярные, как правило, есть)
Возможность получение переводов из онлайн словарей "на лету"
Возможность получения переводов из предложений коммьюнити (и самому предложить можно)
Загрузка скриншотов интерфейсов и последующий процесс OCR
и наверное много чего еще
Вообщем интересно. Но опять же и минусы очевидны - это облако, причем явно не российское. Не до конца ясно как это встраивать в процессы CI/CD, тем более в корпоративной среде. Вообщем, ладно, когда нибудь напишем свое решение, тем более с API онлайновых словарей работали очень много.
Мигратор
В этой главе речь пойдет о ведении кода БД в системе контроля версий (Git) и установке миграций.
К сожалению, я вас обманываю, но - по уважительной причине. Все дело в том, что мы разработали свой "мигратор" БД PostgreSQL (и он очень активно развивается), о чем хотим написать отдельную статью, а также опубликовать сам мигратор в виде набора утилит - условно будем считать ее третьей частью (хотя, мигратор используется не только на этом проекте), поэтому, ограничусь только спойлером (если вы были на pgConf2023, то, возможно, вы нас там видели, а если вы работаете у нас, то скоро запишем "крекер").

Мигратор
Мигратор разрабатывался БДшниками и для БДшников, но его задача - обеспечить миграции БД в рамках "общей парадигмы" процессов CI/CD. Что было самым сложным? На самом деле не было, а есть и остается. Когда мы начинаем говорить про мигратор с девопсами или теми, кто его не знает (новые члены команды), обычно разговор начинается так "а почему не взяли Liquibase? Может быть не умеете, давайте мы вам покажем и научим?". Ну и дальше идет длинная беседа, а что это вообще и зачем. Вот про это и поговорим.
Как нам нужно вести объекты в git? В виде жестко заданной структуры папок в виде "схема/тип_объекта/наименование_объекта". В целом, разумное же требование? Примерно как структура проекта на любом языке программирования. Мы хотим видеть историю изменений каждого объекта;
Как мы хотим "проливать" изменения на базу данных? По возможности автоматически, раз уж мы внесли изменения в объекты, то инструмент должен уметь эти изменения "собрать". Это кстати основной блок работ и самая существенная разница с разработкой "просто кода". Если для процедур и функций все более менее просто - нужно взять свежую версию и скомпилировать в БД, то для таблиц уже нужно генерировать alter table add column. Для более сложных манипуляций - нужно учитывать ситуации с зависимостями объектов, тем более в PostgreSQL с этим не очень просто (попробуйте, например, заменить представление, которое используется в куче мест, вставив ему в середину новое поле).
Мы не хотим писать вручную файл-патч (чейнджсет) с изменениями объектов, мы уже написали эти изменения в сами объекты, смотри пункт 2.
И мы точно не хотим описывать изменения структур в виде xml, хотя знаем, что у Liquibase есть такой режим. Я вообще не видел ни один проект, на котором его используют.
Ролевая модель
Это очень сложная, если углубляться, тема. И, начиная, мы даже не понимали во что ввязались - мы тогда даже не знали о существовании модных аббревиатур, таких как RBAC и ABAC (статья, статья, статья). Но для начала рассмотрим примеры попроще, например гипотетическую системы отчётности. Как можно разграничить доступ?
Горизонтально - по ролям, например менеджер видит 10 отчетов, специалист отдела продаж - 5.
Территориально - сотрудники филиалов видят в (одних и тех же) отчетах данные только по своему филиалу.
А теперь пойдем в тасктрекер. Кто имеет доступ к проекту? Участник, автор? Кто может редактировать задачи? Все или только "свои"? Что значит "свои"? Там где я автор или исполнитель? Кто может настраивать атрибутный состав? Создавать типы задач? Настраивать бизнес-процессы? Роли, группы, пользователи, полномочия…
Осознав все многообразие ситуаций мы поняли, что это примерно ABAC и пошли думать над реализацией.
В первую очередь выделим "субъект". Это пользователь или, в частном случае, система (если она сама инициирует какие либо операции). Также заведем понятие "полномочие". Это возможность что либо сделать в системе, их фиксированный (хоть растущий по мере разработки) список и их достаточно много. Чтобы было удобно, сделаем группы пользователей - любое число пользователей может входить в любое число групп.
Также введем роли, как группирующий элемент для полномочий, со схожим поведением (любое число полномочий входит в любое число ролей). Ну и собственно позволим связывать (выдавать роли) пользователям или группам. Окей, это же RBAC, скажете вы. Да, но не совсем. Введем понятие "аттрибутивные" роли - это динамические роли, которые появляются у пользователя в случае срабатывания некоторых условий (значений атрибутов). Таким образом, например, в случае, если пользователь является исполнителем задачи, то у него (в отношении задачи) появляется дополнительная роль "исполнитель задачи". Полномочия же для этой роли настроены заранее, на этапе настройки ролевой модели. Вот такой вот ABAC в RBAC, нам это показалось удобным. За скобками здесь - сам способ вычисления атрибутивных ролей, но это уже у нас будет задача Scripting Engine (активно разрабытывается).
Подсвечу еще достаточно непростые вопросы - на подумать.
Иерархичность объектов. Допустим, есть полномочие "редактирование задачи". Выданное в отношении задачи X оно действует напрямую на взаимоотношения с ней, а что если (и разрешим ли мы так делать) мы выдадим его на весь проект? Будет действовать разрешение на редактирование всех задач, входящих в проект?
Иерархичность полномочий. Если мы выдали разрешение на просмотр задачи, но не выдали - на просмотр проекта в который она входит, будет ли (должен ли) пользователь видеть задачу? Нет, потому что на проект доступа нет? Так не бывает, так как в интерфейс вход идёт все равно через проект? А если через поиск? А если дали прямую ссылку?
Эта глава подошла к концу, хоть и много вопросов остались без ответов - на самом деле мы ещё только проектируем все эти нюансы, попутно решая вопросы.
Инструментарий
Вот мы и добрались до инструментария. Вряд ли кого то можно удивить, сказав, что мы используем Intellij Idea (в варианте Ultimate). Особо сказать тут нечего, инструмент на самом деле лучший среди подобных.
Для доступа к БД мы взяли DBeaver. Выбор скорее сложился исторически, но теперь мы с ним, наверное, навсегда. Да, конечно, можно ходить в БД и из Idea, но если разработчик "чисто БДшый", то idea ему и не нужна (тем более платная), а "бобра" хватает вполне (и даже community edition).
И здесь мы немного увлеклись и начали делать свой форк (благо, исходники доступны) инструмента. В отличие от "обычного" мы изменили в нем:
Реализовали нужное нам форматирование кода объектов: таблиц, функций, процедур;
Форматирование кода

Также не забываем контрибьютить и в upsteam, на текущий момент приняты следующие патчи:
Возможность проверки кода фукций и процедур через расширение pgplsql_ckeck


Расширили набор генераторов SQL, добавив, в том числе, специфические для PostgreSQL

Улучшили фильтрацию объектов в дереве, дополнив синтаксис в виде "схема.объект", а также реализовали возможность поиска по описанию

Добавили возможность явного указания типов параметров функций (добавили CAST к параметрам);
Исправили ошибки фильтрации по ENUM;
Ожидают рассмотрения:
Обработали ситуацию, когда при сохранении функции на самом деле создается ее новая версия (при изменении состава параметров)
Реализовали копирование колонок с их типами, модификаторами not null / default для более быстрого использования в составлении скриптов
Улучшили автоматический расчет ширины колонок
Останавливаться пока не планируем
Будущее
Поговорим о том, до чего мы еще не добрались, но о чем, тем не менее, много думаем. Будем рады, если вы дадите в комментариях практические советы.
Скриптовый язык
Нам видится, что перспективным движком в JDK-мире является сейчас реализация от GraalVM. Да, он добавляет 100мб (я не шучу!) к jar файлу, но он, из коробки позволяет программировать на JavaScript, Ruby и Python. На одном проекте мы его уже опробовали, думали применить и здесь. Но пока мы остановились на более классическом подходе - groovy, который в JVM прочно прижился, а заодно имеет реализацию в OpenJDK, что открывает больше возможностей для выбора runtime платформы. Не последнюю роль играет и то, что он входит и в Axiom, имеющую российскую "прописку". Но скриптовый язык - это только половина дела, поэтому мы реализовали API для доступа к объектам Яги из скриптов. Конечно же мы включили так называемый контекст - это то, что позволяет понять кто, где и зачем вызвал скрипт (проект, задача, пользователь, время и что должно получиться после выполнения вызванного изменения) и реализовали доступ к большей части API, которым с нами взаимодействует фронтенд, когда изменяет объекты системы - таким образом в скриптах мы используем одни и те же сервисы и модели, которые используются и при "обычном" взаимодействии, а значит мы экономим, реализовывая логику только один раз - меняется только "транспорт".
Язык запросов
Мы “замахиваемся” на джиру и она не дает нам покоя - в ней есть JQL. Возможно это немного устаревшая концепция, но мы все таки в эту историю хотим “вписаться” и уже начали изучать ANTLR. Отговорите нас или посоветуйте, мы еще в начале пути.
Система плагинов
Джира не была бы джирой (и трелло треллом) без своих плагинов. В эту сторону пока даже не заглядывали, но понимаем необходимость. Где то через полгода-год. Есть, конечно, некоторый опыт написания плагинов, в основном для CRM / Интернет-магазинов (Ecwid, Bitrix24, AmoCRM), конечно же, большой опыт кастомизации Jira. Может быть вы подскажете еще интересные системы / материалы?
Мобильное приложение
Еще одна самая короткая глава ;)
Да, оно будет.
Нет, еще не начали.
Dart / Flutter? Kotlin Compose / Multiplatform? React Native?
Я лично за первые два, но жизнь и время - покажут.
Вместо заключения
Ну что ж, кажется пора заканчивать. Конечно, не все темы были раскрыты полноценно - что то забывается, что то - достаточно стандартно, т.е. "как у всех" и наверное нет большого смысла это описывать, коснусь вскользь:
SSO. Тщательно разобрались в Keycloak, научились вести в нем два типа пользователей - доменных и "локальных", научились делать регистрацию пользователей, отправку писем оповещений и т.д. А главное сделали действительно единое SSO для разных частей нашей "экосистемы" - здесь я имею ввиду то, что два (и более) разных фронтенд приложения используют единое SSO и не требуют двойного логина (это очень раздражает в текущей реализации Jira/Confluence, сделаем лучше);
Тонкие клоны БД. Это интересная функциональность на базе файловой системы ZFS. Решение разработал дружественный нам центр компетенций - ЦК Постгрес. Если коротко - у нас появилась возможность очень быстро (пере)создавать копию БД, которая почти не занимает места (чем меньше отличается от исходной, тем меньше занимает места). Сейчас мы можем каждому разработчику под каждую задачу выдать его собственную БД.
Код ревью, проверка кода. Здесь все достаточно серьезно, мы почти всегда проводим код ревью, при этом стараемся на каждый MR ставить по два аппрува;
Покрытие тестами. Пожалуй, тут все стандартно, но тем не менее - мы пишем тесты, стараемся уделять этому должное время. Сейчас обдумываем, как нам реализовать тесты еще и в БД - возможно через pgTAP;
CI/CD процессы. Они просто есть (сделаны на гитлабе), они постоянно эволюционируют, команда DevOps инженеров иногда не успевает за нашими идеями (шутка). Иными словами - стараемся все автоматизировать - и создание / удаление тонких клонов, и запуск несколько dev / test площадок для параллельного тестирования разных фич и много чего еще.
Спасибо за внимание, надеюсь, было интересно!