
Привет! Меня зовут Андрей Шмиг, я разработчик платформы DataHub, платформа для совместной работы над данными - своего рода GitHub для данных. В этой статье покажу, каким образом можно организовать доступ для внешних пользователей к репозиториям данных через Predefined Queries.

Предыдущие статьи
Полный список связанных статей:
DataHub: как делиться структурированными данными и получать за них донаты?
DataHub: репозитории данных коммерческого типа. Как зарабатывать на доступе к данным?
Демо-репозиторий
Из прошлых статей у нас сохранился демо-репозиторий с данными списка стран доступный по этой ссылке - база стран всего мира (демо).
В этом демо-репозитории создана одна единственная таблица countries:

Содержащая три записи:

На основе этих данных я и продемонстрирую, каким образом использовать Predefined Queries для предоставления доступов к данным стороннему пользователю.
Predefined Queries
Predefined Queries - это заранее подготовленные запросы владельцем репозитория к хранилищам данных. Запросы могут быть как на чтение, так и на запись. Могут быть приватными, а могут быть публичными. Основная задача predefined queries предоставить контролируемый и гибкий доступ к данным всем заинтересованным сторонам.
Predefined Queries в PRIVATE режиме могут быть использованы разработчиками ботов, мобильных приложений или игр для реализации MVP продуктов.
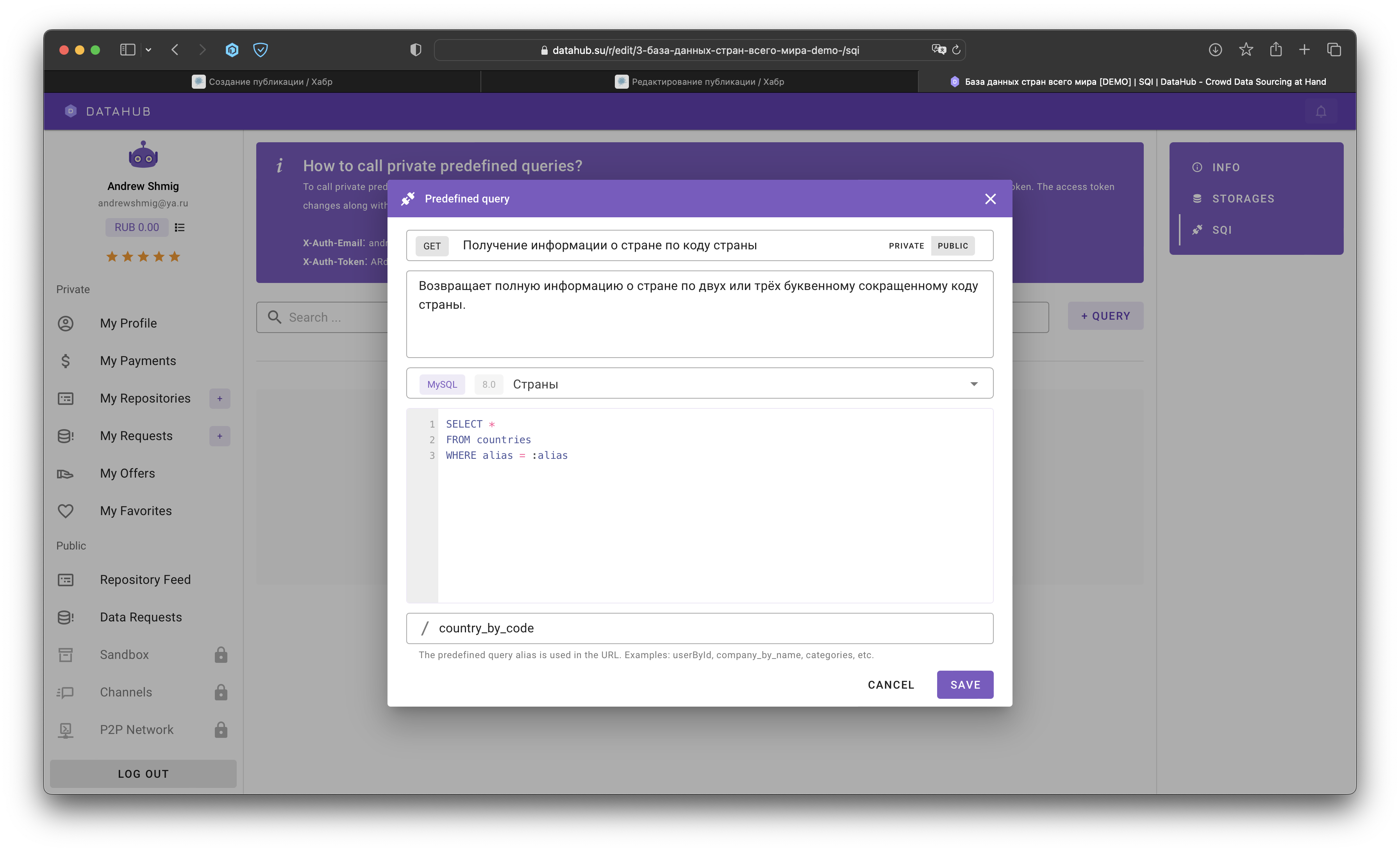
Для создания первого predefined-запроса переходим в режим редактирования репозитория данных и переключаемся на вкладку SQI (Storage Query Interface):

Нажимаем на кнопку "+ Query":

Настраиваемые значения:
HTTP Method: по-умолчанию на текущий момент всегда GET. HTTP метод для выполнения запроса доступа к данным по сгенерированному endpoint (URL).
Название: публичное название метода (например: Получение информации о пользователе по уникальному идентификатору).
Тип запроса: PRIVATE (приватный) или PUBLIC (публичный).
Storage: хранилище данных к которому относится создаваемый запрос.
Predefined Query: текст запроса (язык запроса зависит от типа выбранного хранилища - MySQL, MongoDB, прочие).
HTTP Query Alias: имя (url alias) для predefined query. Сокращенное название метода (endpoint), например, user_by_id или total_users.
Пишем наш первый predefined запрос - получение информации о стране по коду (двух-трёх буквенному коду):
Приведенный в примере запрос является простейшим и служит лишь для демонстрации работы predefined queries. Фактические запросы могут быть любой сложности - хранилище данных MySQL поддерживает практически все возможности одноименной базы данных (триггеры, процедуры, функции, события, индексы и пр).
Обратите внимание, что в запрос мы подставляем переменную :alias, которая будет извлекаться из GET запроса query-строки.
Формат подставляемых переменных :[name], например:
:id:user_name:nick10
Сохраняем наш запрос:

У репозитория стал доступен SQI метод country_by_code по ссылке (без параметров данный метод будет возвращать сообщение об ошибке)
https://datahub.su/api/v1/r/3/sqi/country_by_codeЧтобы выполнить этот запрос необходимо передать параметр alias в GET запросе:
https://datahub.su/api/v1/r/3/sqi/country_by_code?alias=ruРезультаты выполнения запроса:

{
"status": true,
"price": 0,
"payload": [
{
"id": 1,
"name": "Russia",
"alias": "ru",
"phone_code": "+7"
}
]
}Параметры ответа:
status: true или false, был ли выполнен запрос удачно.
price: стоимость запроса (при типе репозитория данных FREE и SPONSORED значение будет равно нулю, при типе COMMERCIAL - стоимости выборки данных);
payload: результат выполнения запроса.
Поддерживаемые форматы ответа на текущий момент:
application/json;
Надеюсь, что возможности DataHub позволят вам делиться, монетизировать и работать с данными эффективно!
В следующих статьях рассмотрим возможности веб-редактора хранилища MySQL - редактора, который перенимает лучший опыт взаимодействия и работы с данными у MySQL Workbench.
Если вам понравилась статья — ставьте лайк и оставляйте комментарий. Подписывайтесь на мой блог про DataHub на Хабре, а так же на Телеграм канал поддержки сервиса.
Мой публичный профиль на DataHub — @aashmig.
Буду рад ответить на ваши вопросы и дополнить статью.
AcckiyGerman
Привет, "зацепился" глазом за название DataHub и прочитал ваши статьи с обзором интерфейса этого самого Датахаба.
Позвольте задать несколько вопросов.
Интерфейс
Первое, что непонятно - нафига
козе баянтабличным данным "облачное" хранилище с web-интерфейсом?Давным давно существует вылизанный поколениями учёных и разработчиков SQL (который вы под капотом и используете). Мощный, гибкий, выразительный.
Для пользователей табличных данных, не умеющих в SQL, есть Excel.
Для пользователей SQL, не умеющих / желающих его учить - есть десятки программ c мощным графическим интерфейсом, начиная от нативных клиентов типа Microsoft Access (или там Microsoft SQL Server Management Studio - суть та же) и кончая веб клиентами от PhpMyAdmin до всяких Amazon RDS и SQL Azure. Их десятки, если не сотни.
Из этих соображений простой вывод: интерфейс вашего Datahub не сможет переплюнуть уже существующие решения в общем случае, ресурсов для разработки не хватит.
Скорость
Та же картина, как и с удобностью интерфейса.
Вы не сможете обрабатывать данные быстрее, чем MySQL под капотом.
А еще же надо индексы в таблицы проставить, исходя из запросов ваших пользователей (а запросы у всех разные, ага).
Так что не забудьте добавить в интерфейс возможность назначать индексы на колонки!
Нажал на кнопочку и положил сервак перестройкой индекса - красота!
Объём
А если пользователь попробует загрузить "большие данные" ? Которые не влезут на вашу VPS (признайтесь честно, у вас же всё на VPS крутится, да)?
Допустим у вас не VPS а большие сервера, облачные СХД, автоматическое скалирование.
Придётся городить инфраструктуру, шардирование, реплицирование
И всё равно ограничивать пользователей в объёмах.
А то любой хацкер положит всё одной
/dev/random > datahub uploadКлиентская программа
Вы уже думали кстати про программу клиента для вашего datahub?
Ну чтобы данные загружать/выгружать.
А может и показывать сразу.
А то веб-интерфейсы ненадёжны, в браузерах таймауты, в сессиях обрывы.
Однозначно нужен клиент. Ну типа как
gitу GitHub.Я вам и название подскажу.
Aккуратно отрезаем от названия проекта суффикс Hub и остаётся самая суть -
data.data upload,data fetchи т.д.Коротко и понятно, не запутаться.
"John, use data to upload data on Datahub?" или "Upload data using data! Where? - To Data (Hub)!"
Хотя лучше всего было бы использовать клиент mysql. Ну который
apt install mysql-clientА на сервере, вы знаете, открыть порт 3306, назначить логин/пароль.
Хахаха, это было бы конечно слишком просто.
Вам нужен модный современный консольный клиент на Node.js
Не не, Node вышел из моды - на Go!
Клиент чтобы XML понимал и Excel и JSON и все остальные форматы, какие у поставщиков данных бывают.
А потом на основе этого клиента сделаете Electron приложение (срочно переписываем назад на Node.js, для консистентности кода) мегабайт этак на 100 размером.
Меньше наверное не получится, а делать нативный клиент под каждую платформу, так это ж програмистов десяток нужен будет.
Предварительный итог
В общем можно долго обсуждать возникающие перед вами технические проблемы.
Перед вами стоит ряд сложных задач (давно и многократно решённых в других продуктах)
Но вы собираетесь хорошенько побится об них лбом.
И всем читателям уже очевидно, что DataHub затеяли не ради удобного интерфейса, скорости, надёжности. А зачем?
Ясно же зачем! Данные продавать!
Откуда деньги?
Как же продать данные и/или сервис по продаже данных?
"Чтобы чтото продать, надо вначале чтото купить, а у нас
денегданных нет!"Итак, пользователь видит ваш проект для хранения данных.
С ограниченным интерфейсом.
С ограниченной скоростью.
С ограничениями по объёмам.
С дурацким клиентом (в идеальном будущем, а пока только браузер), который никогда не догонит обычный MySQL клиент.
Любому продвинутому пользователю очевидно - для хранения данных ваш сервис не подходит.
Для настройки репликации, например, ему нужно звонить в техподдержку и платить денежку.
Проще и дешевле свой сервер использовать. Ну или SQL Azure.
Хотя может у вас есть интересующие пользователя данные?
Хммм, а интересных данных еще никто не загрузил.
Срочно ищём Junior Data Scientist в команду!!!
Чтобы искать и загружать данные, пустой сайт не продать!
Ну вот уже загружено чтото интересное - статистика по ковиду там.
Или история цен акций. Биржевых ботов тренировать.
А что? Нельзя что-ли данные дублировать?
Мы не зря диски крутим, мы сохранили и приумножили!
Любому исследователю данных очевидно, что данных вы сами не генерируете.
А любые интересные данные вы загрузили из открытых источников.
Он их и сам бесплатно загрузит.
Итак, в качестве вашей цели остаются только обладатели интересных данных, желающие их продать.
Ну и искатели труднодоступных данных, желающие их купить.
Хакеры?
Ненене, хакеры свои данные в даркнете продают через биткоины. А то чревато.
Да вы и сами не захотите таких данных на сервере.
(Не будем шутить про швабры, бутылки и другие методы из арсенала имперской полиции).
Учёные?
Но учёные данные принадлежат правительству или корпорации, которое исследования оплатило.
Здесь тоже облом.
Кому же блин продать этот, такой классный на первый взгляд стартап?
Или кто будет на него свои данные загружать и хранить?
Государство!
Ему родному продать!
В рамках импортозамещения!
Чтобы данные надёжно хранились! На родине!
Правда продукт пока слабоват.
Данные по закону Яровой - не поместятся.
Данные призывников разве что.
Придётся интерфейсов прикрутить, для взаимодействия с другими госорганами, но это дело наживное.
Конец!
А хотя нет, не конец.
Есть еще конкурент буржуйский! - https://datahub.io/
Они уже далеко по этой дорожке продвинулись.
[x] идея по аналогии с GitHub - есть
[x] веб интерфейс,
скоростьтормоза, ограничения по объёмам[x] раздутая консольная программа и ГУИ на электроне - есть, а то как же ? (называется - труляля! -
data!!!!!)[x] свои библиотеки и протоколы, свои форматы хранения данных - а как же! под 300 репозиториев. Не так-то просто догнать mysql по возможностям обработки данных, но они очень стараются.
[ ] пользовательская база - небольшая (я так думаю что в основном через личные и профессиональные контакты основателя)
[ ] доход от пользователей - наверное есть, но на зарплаты программистам не всегда хватает
[x] Зато есть научные гранты!!! Чиновники европейские не абы что спонсируют, а целую новую экосистему хранения данных!
[x] Увольнения работников, когда грантов нет, и возобновление работы, когда есть. Присутствует.
Уважаемый Андрей.
Судя по вашим статьям, вы программист, который вначале изучал экосистему iOS, потом нейросети, а вот теперь вас занесло на эту кривую дорожку.
Вы ли сами такой проект придумали или наткнулись на datahub.io (который очень хочет казаться успешным) и решили повторить успех.
Или вас нанял основатель компании, который сам идею придумал (что вряд ли) или скопировал.
В любом случае - ввиду обозначенных технических, концептуальных и бизнес проблем,
стартап ваш не имеет перспектив кроме продажи государству или тупым инвесторам!
Пожалуйста, не вредите инвесторам.
Не вредите государству (в случае если оно решит эту херню купить).
Не вредите самому себе (потраченное лично вами на этот безполезный проект время).
Бросайте и увольняйтесь.
И вашему начальнику (директору, инвестору) покажите.
Я работал в Datahub.io , видел все их проблемы изнутри .
Я осветил эти проблемы вам.
Умные буржуи (PhD там работают) за 6 лет не могут признать, что они в тупике.
Всё множат технические решения, и всё никак не догонят обычный Mysql.
Все мечутся и ищут покупателей.
И каждый потенциальный покупатель выдаёт свои требования, которые прогаммисты по полгода внедряют, но их потом всё равно отказываются покупать.
Не идите туда. Положитесь на чужой опыт.
AndrewShmig Автор
Комментарий за статью. Благодарю за обратную связь, подумаю над некоторыми моментами.