
Всем привет. В данной статье коснусь темы запросов к базе данных и как небольшие изменения в коде позволят значительно увеличить скорость работы нашего приложения, за счет увеличения производительности работы базы данных.
Данная статья будет исключительно практической.
И так поехали.
Допустим у нас есть такое задание: имеется какая-то база данных с аккаунтами, в каждом аккауте есть электронная почта. К нам приходят с отдела маркетинга и говорят "Вот вам список почтовых адресов, необходимо пройтись по базе данных с аккаутами, проверить есть ли такие адреса, и если есть - отправить на эту почту письмо".
Вроде задание не сложное, но если в базе данных аккаутов не сотни, а тысячи или десятки тысяч, то неправильно написанный код может понизить скорость работы нашего метода по отправке сообщений.
Приступим к созданию нашего приложения.
Зайдем на https://start.spring.io/ и создадим проект.
Откроем его в среде разработки и немного переработаем pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>spring-data-jpa-multiple-single-queries</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-data-jpa-multiple-single-queries</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<!--JPA-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--WEB-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--DATABASE-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<!--LIQUIBASE-->
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
</dependency>
<!--LOMBOK-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--TESTING-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--OTHERS-->
<dependency>
<groupId>com.github.javafaker</groupId>
<artifactId>javafaker</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
Базу данных буду использовать postgresql, для накатывания таблицы в ней - liquibase.
Базу данных поднимем с помощью docker-а, также в докере поднимем контейнер с pgadmin - для просмотра данных в базе.
Ссылку на код с проектом будет в конце статьи.
В корне нашего проекта напишем docker-compose.yml со следующим содержанием:
services:
service-db:
image: postgres:14.7-alpine
environment:
POSTGRES_USER: username
POSTGRES_PASSWORD: password
ports:
- "15432:5432"
volumes:
- ./infrastructure/db/create_db.sql:/docker-entrypoint-initdb.d/create_db.sql
- db-data:/var/lib/postgresql/data
restart: unless-stopped
pgadmin:
container_name: pgadmin4_container
image: dpage/pgadmin4:7
restart: always
environment:
PGADMIN_DEFAULT_EMAIL: admin@admin.com
PGADMIN_DEFAULT_PASSWORD: root
ports:
- "5050:80"
volumes:
- pgadmin-data:/var/lib/pgadmin
volumes:
db-data:
pgadmin-data:Базу данных accounts_database создадим с помощью скрипта, расположенного в папке infrastructure/db
create database accounts_database;Он выполнится при создании контейнера в docker-е. Также данные мы будем хранить вне контейнера с нашей базой данных, чтобы при перезапуске контейнера они не потерялись.
Создадим нашу сущность, то есть аккаунт.
@Data
@Builder
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Table(name = "accounts")
public class Account {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name="username",
nullable = false)
private String username;
@Column(name="email",
nullable = false)
private String email;
@Column(name="created_at",
nullable = false)
private LocalDate createdAt;
public Account(String username, String email, LocalDate createdAt) {
this.username = username;
this.email = email;
this.createdAt = createdAt;
}
}Также создадим структуру папок и напишем файлы для накатывания базы данных.
2023-06-06-1-create-table-accounts.xml
<?xml version="1.0" encoding="UTF-8" ?>
<databaseChangeLog
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<changeSet logicalFilePath="2023-06-06-1-create-table-accounts"
id="2023-06-06-1-create-table-accounts" author="s.m">
<createTable tableName="accounts">
<column name="id" type="serial">
<constraints nullable="false" primaryKey="true"/>
</column>
<column name="username" type="varchar(255)">
<constraints nullable="false"/>
</column>
<column name="email" type="varchar(255)">
<constraints nullable="false"/>
</column>
<column name="created_at" type="date">
<constraints nullable="false"/>
</column>
</createTable>
</changeSet>
</databaseChangeLog>cumulative.xml
<?xml version="1.0" encoding="UTF-8" ?>
<databaseChangeLog
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<include file="2023-06-06-1-create-table-accounts.xml" relativeToChangelogFile="true" />
</databaseChangeLog>db.changelog-master.xml
<?xml version="1.0" encoding="UTF-8" ?>
<databaseChangeLog
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<include file="v.1.0.0/cumulative.xml" relativeToChangelogFile="true" />
</databaseChangeLog>Далее создадим интерфейс AccountRepository для выполнения действий с нашей сущностью в базе данных.
@Repository
public interface AccountRepository extends JpaRepository<Account, Long> {
}Следующим шагом напишем файл application.yml
server:
port: 8081
spring:
datasource:
url: jdbc:postgresql://${DB_HOST:localhost}:${DB_PORT:15432}/accounts_database
username: username
password: password
liquibase:
enabled: true
drop-first: false
change-log: classpath:db/changelog/db.changelog-master.xml
default-schema: public
jpa:
show-sql: true
properties:
hibernate:
format_sql: trueЗдесь мы настраиваем подключение к нашей базе данных, настраиваем liquibase и задаем настройки, чтобы в консоль выводились sql запросы к базе данных.
Далее напишем немного кода для автоматического заполнения базы данных какими-то значениями, чтобы с ними работать.
Допусти в нашей базе данных будет 10 000 аккаунтов, а список для проверки есть ли такие email-ы будет содержать 5 000 адресов электронной почты.
Создадим класс ConstantData в папке config.
public class ConstantData {
public final static int NUMBER_ACCOUNTS = 10_000;
public final static int NUMBER_OF_EMAILS_TO_SEND = (NUMBER_ACCOUNTS / 2) + 1;
public final static List<String> LIST_OF_EMAILS_TO_SEND = createListOfEmails();
static List<String> createListOfEmails() {
Faker faker = new Faker();
List<String> emailsToSend = new ArrayList<>();
for (int i = 0; i < NUMBER_OF_EMAILS_TO_SEND; i++) {
emailsToSend.add(faker.internet().emailAddress());
}
return emailsToSend;
}
}В методе createListOfEmails() мы с помощью библиотеки javafaker генерируем 5000 адресов электронной почты.
Далее создаем еще один класс DataLoader.
@Component
public class DataLoader {
@Bean
public CommandLineRunner loadDataAccount(AccountRepository accountRepository) {
return (args) -> {
Faker faker = new Faker();
for (int i = 1; i <= ConstantData.NUMBER_ACCOUNTS; i++) {
String username = faker.name().username();
String email = "";
if (i % 2 == 0) {
email = ConstantData.LIST_OF_EMAILS_TO_SEND.get(i / 2);
} else {
email = faker.internet().emailAddress();
}
Account account = Account.builder()
.username(username)
.email(email)
.createdAt(LocalDate.of(2022, Month.JANUARY, 1).plusDays(faker.number().numberBetween(1, 365)))
.build();
accountRepository.save(account);
}
};
}
}
Данный метод loadDataAccount будет создавать 10 000 аккаунтов и заполнять их данными, половина адресов в данных аккаунтов будет взята из ранее сгенерированного списка с электронными адресами.
При каждом запуске приложения будет выполняться данный метод, поэтому при перезапуске приложения нужно будет удалять все из базы данных.
Напишем интерфейс AccountService с методом getEmailExistsInDBMultipleQueries(List targetEmailList).
public interface AccountService {
List<String> getEmailExistsInDBMultipleQueries(List<String> targetEmailList);
}Так как мы будем проверять существует ли адрес электронной почты в аккаунте, то в интерфейсе AccountRepository напишем метод boolean existsByEmail(String email), который с помощью Spring Data JPA , создаст для нас очень просто "волшебный" метод, который пойдет в базу данных и проверит есть ли у какого-то аккаунта такой адрес и если есть - вернет true.
boolean existsByEmail(String email);А также класс AccountServiceImpl, который будет имплементить класс AccountService.
@Slf4j
@Service
@RequiredArgsConstructor
@Transactional(readOnly = true)
public class AccountServiceImpl implements AccountService{
private final AccountRepository accountRepository;
@Override
public List<String> getEmailExistsInDBMultipleQueries(List<String> targetEmailList) {
return targetEmailList.stream()
.filter(accountRepository::existsByEmail)
.toList();
}
}В данном методе мы проходимся по переданному списку электронных адресов и по каждому адресу проверяем существует ли такой аккаунт с таким электронным адресом в базе данных, если есть - то добавляем этот адрес с список.
Далее напишем еще один сервис NotificationService, где будем вызывать метод getEmailExistsInDBMultipleQueries и замерять время его выполнения и выводить на экран размер списка с электронными адресами.
@Slf4j
@Service
@RequiredArgsConstructor
@Transactional(readOnly = true)
public class NotificationService {
private final AccountService accountService;
public void sendEmailMultipleQueries(){
List<String> targetEmailList = ConstantData.LIST_OF_EMAILS_TO_SEND;
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<String> listEmailToSend = accountService.getEmailExistsInDBMultipleQueries(targetEmailList);
//email send code
stopWatch.stop();
System.out.println("Time has passed with to check if an account with this email exists with multiple queries, ms: " + stopWatch.getTime());
System.out.println("Size of emails list: " + listEmailToSend.size());
}
}Последний класс, который мы напишем - это AccountController, где мы будем вызывать наш метод и его тестировать.
@Slf4j
@Validated
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/v1/accounts")
public class AccountController {
private final NotificationService notificationService;
@GetMapping("/emailSendMultipleQueries")
@ResponseStatus(HttpStatus.OK)
public void emailSendMultipleQueries() {
log.info("Send emails with multiple queries");
notificationService.sendEmailMultipleQueries();
}
}Приступим к тестированию нашего кода.
Вначале выполним команду docker-compose up -d в командной строке, где находится наш docker-compose.yml файл.
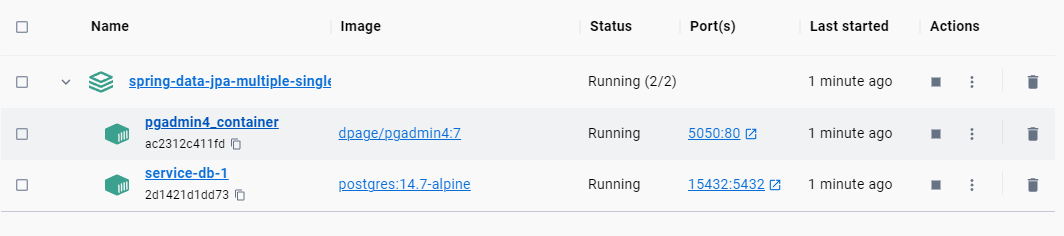
Контейнеры должны подняться и работать.
Запуск приложения займет некоторое время, так как будет заполняться база данных.
Далее идем на http://localhost:5050/ и входим в pgadmin используя данные для входа указанные в docker-compose.yml
Добавляем новый сервер.
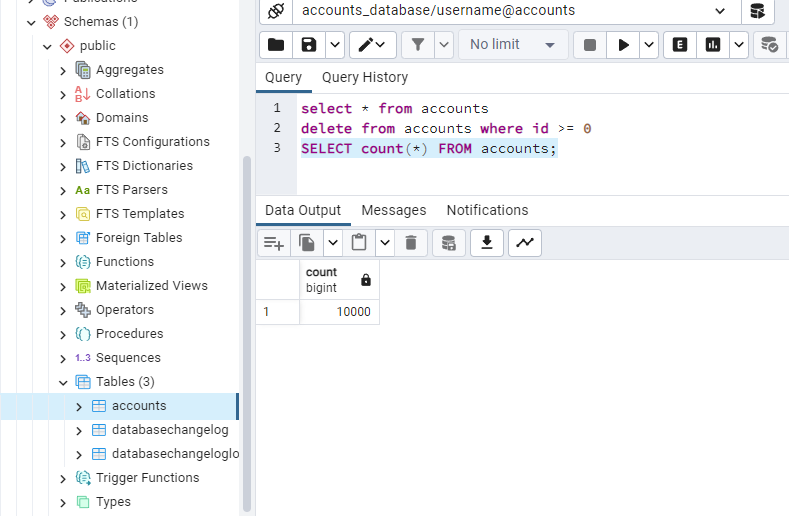
Выполнив запрос SELECT count(*) FROM accounts; можно убедиться, что записей в базе данных 10000.
Далее с помощью postman отправляем get запрос на http://localhost:8081/api/v1/accounts/emailSendMultipleQueries
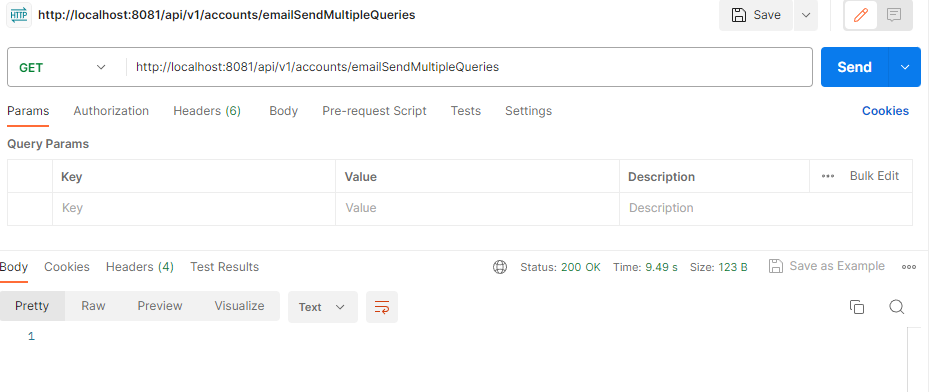
И в консоли получаем много sql запросов к базе данных и время выполнения нашего метода 9366 миллисекунд.
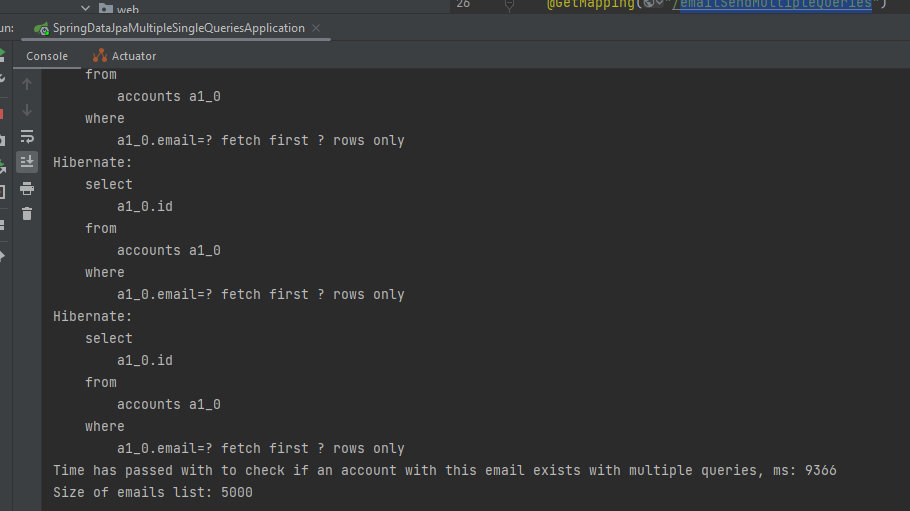
Повторим это еще 2 раза и выведем среднюю. Результаты такие (9366+8863+9165)/3=9131.
Сейчас давайте переделаем наше обращение к базе данных таким образом, чтобы был только один запрос к ней и посмотрим на сколько это уменьшит время работы нашего метода.
Дополним интерфейс AccountRepository следующим методом:
@Query("select a.email from Account a where a.email IN(:emails)")
List<String> emailExists(@Param("emails") List<String> emails);Здесь мы использовали аннотацию @Query для обращения к базе данных, в которой мы сразу передаем весь список электронных адресов и делаем поиск адреса непосредственно на уровне базы данных.
Дополним интерфейс AccountService следующим методом:
List<String> getEmailExistsInDBSingleQueries(List<String> targetEmailList);В классе AccountServiceImpl реализуем этот метод:
@Override
public List<String> getEmailExistsInDBSingleQueries(List<String> targetEmailList) {
return accountRepository.emailExists(targetEmailList);
}И в классе NotificationService вызовем этот метод и посчитаем за сколько он выполнился.
public void sendEmailSingleQueries(){
List<String> targetEmailList = ConstantData.LIST_OF_EMAILS_TO_SEND;
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<String> listEmailToSend = accountService.getEmailExistsInDBSingleQueries(targetEmailList);
//email send code
stopWatch.stop();
System.out.println("Time has passed with to check if an account with this email exists with single queries, ms: " + stopWatch.getTime());
System.out.println("Size of emails list: " + listEmailToSend.size());
}Последнее - дополним класс AccountController get запросом по вызову этого метода.
@GetMapping("/emailSendSingleQueries")
@ResponseStatus(HttpStatus.OK)
public void emailSendSingleQueries() {
log.info("Send emails with single queries");
notificationService.sendEmailSingleQueries();
}Перед перезапуском приложения зайдем в базу данных и удалим в ней все записи.

После перезапуска приложения идем в postman и отправляем get запрос на http://localhost:8081/api/v1/accounts/emailSendSingleQueries

Сейчас метод сработал очень быстро, идем в консоль и видим, что был только один запрос к базе данных и скорость работы нашего метода составила 129 миллисекунд.

Повторим еще 2 раза и выведем среднюю. Результат составит (129+48+47)/3=75.
Итак, получается, что мы с помощью небольших изменений в коде улучшили производительность работы нашего метода по обращению к базе данных в 122 раза (9131/75).
На данном примере я хотел показать, что использование "волшебных" методов, которые дает нам Spring Data JPA не всегда оправдано, необходимо искать возможность замены многократных обращений к базе данных одним sql запросом, чтобы он выполнялся на уровне базы данных, а к нам приходил в программу уже готовый результат.
Спасибо всем, кто дочитал до конца.
Вот ссылка на проект.
Всем пока.
Комментарии (4)


enforcer_snk
07.06.2023 12:10Статья интересная, проблема актуальная, хотелось бы еще увидеть тест для запроса вида
List<Account> findByEmailIn(List<String> emails);за исключением попадания в выборку готовых объектов Account запрос будет идентичным, считаю, нужно использовать инструмент на максимум

SimSonic
07.06.2023 12:10О, господи, сколько всего собрано в одном месте! Я попробую самые крупные огрехи хотя бы указать:
Банальный вывод статьи. Делать много запросов дороже, чем один - это очень важное сообщение от КО.
Использовать System.out.println, когда уже есть логгер (
@Slf4jвисит над классом).Логирование 10к запросов в консоль, к слову, тоже влияет на результат ;)
Сразу же в application.yaml отключит OSiV.
На сущности висит Data, читать классическую статью https://thorben-janssen.com/lombok-hibernate-how-to-avoid-common-pitfalls/.
Можно побенчмаркать хотя бы JMeter-ом.
"Ребят, ревьюю ваш код, у вас тут поиск по email, а на нём индекса нет..."
Похвалить автора, конечно, тоже есть за что, например, что юзает StopWatch, а не сам мерит nanoTime., докер использует. В каждом ревью должно быть что-то позитивное =)
hello_my_name_is_dany
Только надо учитывать, что максимальный размер SQL-запроса в PostgreSQL - 1 гигабайт, и если предположить, что один e-mail адрес занимает 255 символов (255 байт), то ваш максимум примерно 4 млн с копейками