
Всем привет.
В данной статье будет описано, как создать простой kafka producer и kafka consumer, а затем протестировать их.
Данная статья будет полезна начинающим разработчикам, которые еще не работали с технологией Apache Kafka.
Немного теории.
Вначале надо разобраться, что такое Apache Kafka и для чего она используется. И тут сразу могут возникнуть первые вопросы, так как первое, что приходит в голову, если идет речь о kafka, то это - распределенная система обмена сообщениями между серверными приложениями в режиме реального времени. Но если "копнуть глубже" и посмотреть на определение kafka на официальном сайте https://kafka.apache.org/ мы увидим.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Исходя из этого определения Apache Kafka — это больше, чем просто система обмена сообщениями, это распределенная платформа потоковой передачи событий, а также потоковой аналитики и интеграции данных.
То есть kafka может использоваться и как база данных, и как распределенное хранилище логов, и как очередь, и как платформа для потоковой обработки данных и т.д.
В данной статье будет рассмотрен пример, как с помощью kafka организовать обмен сообщениями между двумя микросервисами.
Kafka, как и почти все сервисы обработки очередей, условно состоит из трех основных частей:
1) сервер или еще его называют брокер;
2) producer - отправляют сообщения брокеру;
3) consumer - считывают сообщения с брокера, использую модель pull, то есть консьюмеры сами отправляют запросы к брокеру для получения новых сообщений.
Главной отличительной чертой kafka от других систем обработки очередей (например RabbitMQ), является то, что сообщения в kafka могут храниться на брокере днями, неделями или даже годами. Благодаря этому одно и тоже сообщение может быть обработано разными консьюмерами по-разному.
Рассмотрим какая структура сообщения в kafka. Оно состоит из ключа (key), значения (value), таймстампа (timestamp) и набора метаданных (headers).
Сообщения хранятся в топиках (topics). Топики состоят из партиций (partitions). Партиции или их еще называют разделы - это копии очередей наших сообщений. Чтобы повысить надежность и доступность данных в кластере-Kafka, разделы могут иметь копии, число которых задается коэффициентом репликации (replication factor), который показывает, на сколько брокеров-последователей (follower) будут скопированы данные с ведущего-лидера (leader). Таким образом, гарантируется наличие нескольких копий сообщения на разных брокерах. Партиции, в свою очередь, распределены между брокерами внутри одного кластера. Такая сложная, на первый взгляд, система хранения сообщений необходима для отказоустойчивости, масштабирования и повышения производительности работы, так как она позволяет продюсерам писать в несколько брокеров одновременно, а консьюмерам - читать, также из нескольких брокеров.
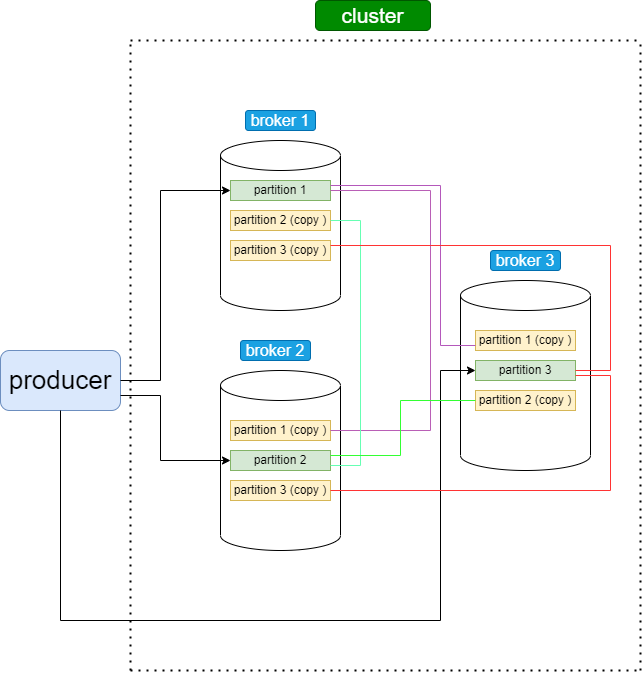
У каждой партиции есть свой "лидер" (leader) - это тот брокер, который работает с продюсером и на него приходит сообщение, а также у каждой партиции имеются несколько "фолловеров" (followers) - это брокеры, которые хранят копии партиций. Перед отправкой сообщения консьюмер обращается к брокеру и запрашивает данные, кто является лидером партиции.
Таким образом, общая схема сохранения сообщения в kafka выглядит следующим образом. Имеется какой-то топик, в который записываются сообщения, и есть несколько партиций (копий очередей наших сообщений), распределенных по брокерам в кластере. Продюсер вначале обращается к брокеру с вопросом, кто является лидером партиции в данном брокере, и после получения данной информации отправляет туда свое сообщение, на втором этапе, фолловеры данной партиции копируют себе отправленное сообщение на свой брокер. Так происходит с каждой партицией.
Время хранения сообщения в kafka регулируется с помощью специальных настроек.
Рассмотрим сейчас как выглядит работа консьюмера в kafka.
Каждый консьюмер должен быть частью какой-нибудь консьюмер группы. Данная группа должна иметь уникальное название и должна быть зарегистрирована в кластере. Как правило, если у нас есть несколько консьюмеров, в одной группе, то они получают сообщения из разных партиций. Желательно, чтобы количество консьюмеров было равно количеству партиций, и каждый консьюмер читал сообщения из своей партиции, таким образом, распределяется нагрузка и повышается производительность работы.
Есть еще один важный вопрос. Если мы захотим добавить консьюмера к топику не сразу, а позже или, например, произойдет сбой консьюмера, а позже он восстановится и вопрос, откуда он будет знать с какого сообщения продолжить работу? Для этого имеется специальный механизм консьюмер-офсетов (offset). Перед началом работы консьюмер делает специальный запрос к брокеру с указанием группы, топика, партиции и офсета, который должен быть помечен как обработанный. Брокер сохраняет эту информацию у себя. При сбое в работе, консьюмер запрашивает у брокера последний закомиченный офсет и продолжает читать с данной позиции сообщения.
Это упрощенное описание работы kafka-продюсера и kafka-консьюмера.
Также при описании kafka нельзя не вспомнить про один важный компонент - zookeeper.
ZooKeeper - это хранилище метаданных kafka, именно он знает в каком состоянии находятся брокеры, какая партиция играет роль лидера, сколько партиций и где они находятся, сколько у каждой партиции реплик и так далее.
Разобравшись немного с теорией приступим к нашему примеру.
Весь код примера будет доступен по ссылке.
Пример будет очень простой. Допустим у нас будет три микросервиса. Один - это продюсер - он будет производить и отправлять сообщения в kafka, в нашем случае это будет Заказ.
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order {
private String productName;
private String barCode;
private int quantity;
private BigDecimal price;
}Второй микросервис - консьюмер, который будет читать наше сообщение и записывать его в базу данных.
И третий микросервис - также будет читать наше сообщение и просто выводить его в консоль.
Таким образом, я хочу показать, что можно настроить несколько консьюмеров, которые будут подписаны на один топик и будут получать из него сообщения, но поступать с ними по-разному.
Весь код приводить не буду, буду останавливаться только на главных моментах.
Kafka, zookeeper, kafka-ui (для просмотра сообщений в kafka), database (postgres) и pgadmin (для просмотра данных в базе) поднимем с помощью docker.
Для этого напишем следующий docker-compose.yml файл.
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.4
healthcheck:
test: [ "CMD", "nc", "-vz", "localhost", "2181" ]
interval: 10s
timeout: 3s
retries: 3
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181
kafka:
image: confluentinc/cp-kafka:6.2.4
depends_on:
zookeeper:
condition: service_healthy
ports:
- 29092:29092
healthcheck:
test: [ "CMD", "nc", "-vz", "localhost", "9092" ]
interval: 10s
timeout: 3s
retries: 3
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENERS: OUTSIDE://:29092,INTERNAL://:9092
KAFKA_ADVERTISED_LISTENERS: OUTSIDE://localhost:29092,INTERNAL://kafka:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8080:8080"
restart: always
depends_on:
kafka:
condition: service_healthy
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
service-db:
image: postgres:14.7-alpine
environment:
POSTGRES_USER: username
POSTGRES_PASSWORD: password
healthcheck:
test: ["CMD-SHELL", "pg_isready", "-d", "clients_database"]
interval: 10s
timeout: 3s
retries: 3
ports:
- "15432:5432"
volumes:
- ./infrastructure/db/create_db.sql:/docker-entrypoint-initdb.d/create_db.sql
restart: unless-stopped
pgadmin:
container_name: pgadmin4_container
image: dpage/pgadmin4:7
restart: always
environment:
PGADMIN_DEFAULT_EMAIL: admin@admin.com
PGADMIN_DEFAULT_PASSWORD: root
ports:
- "5050:80"
kafka-topics-generator:
image: confluentinc/cp-kafka:6.2.4
depends_on:
kafka:
condition: service_healthy
entrypoint: [ '/bin/sh', '-c' ]
command: |
"
# blocks until kafka is reachable
kafka-topics --bootstrap-server kafka:9092 --list
echo -e 'Creating kafka topics'
kafka-topics --bootstrap-server kafka:9092 --create --if-not-exists --topic send-order-event --replication-factor 1 --partitions 2
echo -e 'Successfully created the following topics:'
kafka-topics --bootstrap-server kafka:9092 --list
"Базу данных orders_database, создадим на этапе поднятия контейнера с postgres.
Топик (send-order-event) создадим с помощью команды в отдельном контейнере, здесь же создадим две партиции, так как у нас будет два консьюмера и желательно, чтобы каждый консьюмер читал из своей патриции.
Топики можно также создавать и с помощью кода.
Пройдемся по этапам создания продюсера.
Вначале необходимо сделать некоторые настройки продюсера. Это можно делать с помощью кода или прописывать в application файле. Мы это сделаем с помощью application.yml файла.
server:
port: 8081
spring:
kafka:
bootstrap-servers: localhost:29092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
acks: 1
spring:
json:
add:
type:
headers: false
topic:
send-order: send-order-eventЗдесь указываем порт, на котором будет работать kafka (должен совпадать с внешним портом, который мы открыли в docker для kafka), также необходимо указать как мы будем сериализовать ключ и значение (значение - это и будет наш заказ, поэтому здесь надо указать JsonSerializer). Также прописываем название нашего топика send-order-event, название должно совпадать с тем, что мы указали при создании топика в docker. Данное название мы потом с помощью аннотации @Value будем сетать в переменную.
Далее создадим сам сервис по отправке сообщений.
@Service
@RequiredArgsConstructor
public class KafkaMessagingService {
@Value("${topic.send-order}")
private String sendClientTopic;
private final KafkaTemplate<String , Object> kafkaTemplate;
public void sendOrder(OrderSendEvent orderSendEvent) {
kafkaTemplate.send(sendClientTopic, orderSendEvent.getBarCode(), orderSendEvent);
}
}Внедряем бин private final KafkaTemplate<String , Object> kafkaTemplate в данный класс с помощью аннотации @RequiredArgsConstructor. Также как было сказано раньше сетаем в переменную sendClientTopic название нашего топика с application.yml файла. Далее пишем сам метод по отправке сообщения, который на вход будет принимать OrderSendEvent - то есть наш заказ. Вызываем у kafkaTemplate метод send куда передаем название топика, ключ (в качестве ключа будет выступать код продукта). Ключ нужен для того чтобы сообщения с одинаковыми ключами всегда записываются в одну и ту же партицию. Последним передаем сам заказ.
@Data
@AllArgsConstructor
@NoArgsConstructor
public class OrderSendEvent {
private String productName;
private String barCode;
private int quantity;
private BigDecimal price;
}Создадим еще класс Producer.
@Slf4j
@Component
@RequiredArgsConstructor
public class Producer {
private final KafkaMessagingService kafkaMessagingService;
private final ModelMapper modelMapper;
public Order sendOrderEvent(Order order) {
kafkaMessagingService.sendOrder(modelMapper.map(order, OrderSendEvent.class));
log.info("Send order from producer {}", order);
return order;
}
}Он нужен просто для того чтобы отделить логику отправки от маппинга сущностей.
Отправку сообщения будем производить с помощью postman, поэтому создадим еще контроллер OrderController.
@Slf4j
@Validated
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/v1/orders")
public class OrderController {
private final Producer producer;
@PostMapping
@ResponseStatus(HttpStatus.OK)
public Order sendOrder(@RequestBody Order order) {
log.info("Send order to kafka");
producer.sendOrderEvent(order);
return order;
}
}Рассмотрим теперь первый консьюмер.
Вначале также создадим application.yml файл, в котором настроим наш консьюмер.
server:
port: 8082
spring:
kafka:
bootstrap-servers: localhost:29092
consumer:
group-id: "order-1"
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
trusted:
packages: '*'
datasource:
url: jdbc:postgresql://${DB_HOST:localhost}:${DB_PORT:15432}/orders_database
username: username
password: password
liquibase:
enabled: true
drop-first: false
change-log: classpath:db/changelog/db.changelog-master.xml
default-schema: public
jpa:
show-sql: false
open-in-view: false
hibernate:
ddl-auto: none
properties:
hibernate:
dialect: org.hibernate.dialect.PostgreSQLDialect
topic:
send-order: send-order-eventЗдесь как и в продюсере указываем порт, на котором работает kafka.
Прописываем group-id: "order-1" - так как консьюмеры должны быть объединены в группы.
Указываем настройку auto-offset-reset: earliest - она нужна для того, если мы добавим новую партицию, когда в топик пишут сообщения продюсеры, без данной настройки, мы можем потерять или не обработать кусок данных, записавшихся в новую партицию до того, как консьюмеры обновили метаданные по топику и начали читать данные из этой партиции.
Как и в продюсере указываем как мы будем уже только десериализовать наши ключ и значение. Также прописываем настройку для того чтобы JsonDeserializer доверял десериализовать только классы в доверенном пакете. То есть тут можно указать конкретный пакет или с помощью "*" - указать, что нужно доверять всем классам во всех пакетах.
Также прописываем название нашего топика send-order-event.
В данном файле также прописываем настройки по подключению к базе данных, накатыванию таблиц с помощью liquibase и чтобы выводились sql запросы к базе данных.
Далее создадим класс OrderEvent. По структуре он должен совпадать с тем классом (OrderSendEvent), который мы отправляем через продюсер.
@Data
@AllArgsConstructor
@NoArgsConstructor
public class OrderEvent {
private String productName;
private String barCode;
private int quantity;
private BigDecimal price;
}И сам сервис по приемке сообщения.
@Slf4j
@Service
@AllArgsConstructor
public class KafkaMessagingService {
private static final String topicCreateOrder = "${topic.send-order}";
private static final String kafkaConsumerGroupId = "${spring.kafka.consumer.group-id}";
private final OrderService orderService;
private final ModelMapper modelMapper;
@Transactional
@KafkaListener(topics = topicCreateOrder, groupId = kafkaConsumerGroupId, properties = {"spring.json.value.default.type=com.example.consumer.service.messaging.event.OrderEvent"})
public OrderEvent createOrder(OrderEvent orderEvent) {
log.info("Message consumed {}", orderEvent);
orderService.save(modelMapper.map(orderEvent, OrderDto.class));
return orderEvent;
}
}Здесь сетаем переменным topicCreateOrder и kafkaConsumerGroupId с application.yml файла значения названия топика и группы.
Создаем сам метод по обработке сообщений. Вешаем на него аннотацию @KafkaListener куда передаем название топика, который надо слушать, название группы, а также передаем еще настройку по дефолтному типу данных, который мы принимаем. Данную настройку, можно прописать и в application.yml файле, но я хотел показать как можно передавать настройки каждому слушателю, или, например, у вас в группе есть слушатель, который принимает другую сущность.
Далее с полученным сообщением, то есть OrderEvent, можно выполнять различную логику, зависящую от бизнес-требований. В нашем случае мы будем сохранять наш заказ в базу данных.
Рассмотрим еще один консьюмер, он создан в другом микросервисе и его настройки идентичны первому, поэтому только покажу сам метод по приемке сообщений - он будет выводить наш заказ в консоль. Здесь я хочу показать, что на один топик могут быть подписаны несколько консьюмеров и по разному трактовать, что делать с тем сообщением, которое будет появляться в топике.
@Slf4j
@Service
@AllArgsConstructor
public class KafkaMessagingService {
private static final String topicCreateOrder = "${topic.send-order}";
private static final String kafkaConsumerGroupId = "${spring.kafka.consumer.group-id}";
@Transactional
@KafkaListener(topics = topicCreateOrder, groupId = kafkaConsumerGroupId, properties = {"spring.json.value.default.type=com.example.service.OrderEvent"})
public OrderEvent printOrder(OrderEvent orderEvent) {
log.info("The product: {} was ordered in quantity: {} and at a price: {}", orderEvent.getProductName(), orderEvent.getQuantity(), orderEvent.getPrice());
log.info("To pay: {}", new BigDecimal(orderEvent.getQuantity()).multiply(orderEvent.getPrice()));
return orderEvent;
}
}Давайте сейчас посмотрим как все это работает.
Вначале запустим наш docker-compose.yml командой docker-compose up -d в консоли.

Далее необходимо подождать, пока docker стянет необходимые образы с docker hub и на их основе запустит контейнеры.
Идем в docker desktop и мы должны увидеть следующее.

Kafka, zookeeper, kafka-ui, postgres и pgadmin должны быть запущены и работать. Зайдем в kafka-topics-generator и убедимся, что топик создался.

Далее запускаем все наши три микросервиса.
Идем в postman и отправляем json с заказом на адрес http://localhost:8081/api/v1/orders, так как мы запустили наш продюсер на порту 8081.

В логах продюсера мы должны увидеть, что сообщение отправилось.

Теперь зайдем на http://localhost:8080/ здесь мы должны увидеть в Topics наш топик.

Также в Messages мы должны увидеть наше отправленное сообщение.


И в Consumers мы можем увидеть, что у нас есть два консьюмера.

Также проверим сохранился ли наш заказ, это должен был сделать наш первый консьюмер.

В логах мы видим, что сообщение обработано.
Идем на http://localhost:5050 заходим используя креды указанные в docker-compose.yml.
Далее настраиваем подключение.


Делаем select * from orders и должны увидеть сохраненный заказ.

Теперь еще проверим как сработал наш второй консьюмер. Смотрим логи и видим, что наш второй консьюмер также отработал и вывел в консоль наш заказ.

Еще посмотрим как можно протестировать продюсер и консьюмер.
Вначале обратимся к продюсеру. Его мы протестируем с помощью EmbeddedKafka, он будет работать быстрее, чем использовать KafkaContainer, но для тестов консьюмера мы попробуем использовать KafkaContainer.
@SpringBootTest
@DirtiesContext
@EmbeddedKafka(partitions = 1, brokerProperties = { "listeners=PLAINTEXT://localhost:9092", "port=9092" })
public class KafkaMessageProducerServiceIT {
public static final String TOPIC_NAME_SEND_CLIENT = "send-order-event";
@Autowired
private KafkaMessagingService kafkaMessagingService;
@Test
public void it_should_send_order_event() {
OrderSendEvent order = FakeOrder.getOrderSendEvent();
kafkaMessagingService.sendOrder(order);
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
properties.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group-java-test");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(JsonDeserializer.VALUE_DEFAULT_TYPE, OrderSendEvent.class);
KafkaConsumer<String, OrderSendEvent> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC_NAME_SEND_CLIENT));
ConsumerRecords<String, OrderSendEvent> records = consumer.poll(Duration.ofMillis(10000L));
consumer.close();
//then
assertEquals(1, records.count());
assertEquals(order.getProductName(), records.iterator().next().value().getProductName());
assertEquals(order.getBarCode(), records.iterator().next().value().getBarCode());
assertEquals(order.getQuantity(), records.iterator().next().value().getQuantity());
assertEquals(order.getPrice(), records.iterator().next().value().getPrice());
}
}Суть данного теста проста, мы внедряем наш реальный сервис по отправке сообщений KafkaMessagingService и вызываем метод sendOrder(), куда передаем тестовое сообщение. После создаем консьюмера, подключаемся к нашему топику, читаем оттуда сообщение и проверяем совпадает ли оно с отправленным.

Как видим тест прошел успешно.
Протестируем наш консьюмер, который сохраняет заказ в базу данных.
@Testcontainers
@SpringBootTest
class KafkaMessagingServiceIT {
public static final Long ORDER_ID = 1L;
public static final String TOPIC_NAME_SEND_ORDER= "send-order-event";
@Container
static PostgreSQLContainer<?> postgreSQLContainer = new PostgreSQLContainer<>("postgres:12")
.withUsername("username")
.withPassword("password")
.withExposedPorts(5432)
.withReuse(true);
@Container
static final KafkaContainer kafkaContainer =
new KafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:6.2.4"))
.withEmbeddedZookeeper()
.withEnv("KAFKA_LISTENERS", "PLAINTEXT://0.0.0.0:9093 ,BROKER://0.0.0.0:9092")
.withEnv("KAFKA_LISTENER_SECURITY_PROTOCOL_MAP", "BROKER:PLAINTEXT,PLAINTEXT:PLAINTEXT")
.withEnv("KAFKA_INTER_BROKER_LISTENER_NAME", "BROKER")
.withEnv("KAFKA_BROKER_ID", "1")
.withEnv("KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR", "1")
.withEnv("KAFKA_OFFSETS_TOPIC_NUM_PARTITIONS", "1")
.withEnv("KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR", "1")
.withEnv("KAFKA_TRANSACTION_STATE_LOG_MIN_ISR", "1")
.withEnv("KAFKA_LOG_FLUSH_INTERVAL_MESSAGES", Long.MAX_VALUE + "")
.withEnv("KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS", "0");
static {
Startables.deepStart(Stream.of(postgreSQLContainer, kafkaContainer)).join();
}
@DynamicPropertySource
static void overrideProperties(DynamicPropertyRegistry registry) {
registry.add("spring.kafka.bootstrap-servers", kafkaContainer::getBootstrapServers);
registry.add("spring.datasource.url", postgreSQLContainer::getJdbcUrl);
registry.add("spring.datasource.username", postgreSQLContainer::getUsername);
registry.add("spring.datasource.password", postgreSQLContainer::getPassword);
registry.add("spring.datasource.driver-class-name", postgreSQLContainer::getDriverClassName);
}
@Autowired
private OrdersRepository ordersRepository;
@Test
void save_order() throws InterruptedException {
//given
String bootstrapServers = kafkaContainer.getBootstrapServers();
OrderEvent orderEvent = FakeOrder.getOrderEvent();
Order order = FakeOrder.getOrder();
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
ProducerFactory<String, OrderEvent> producerFactory = new DefaultKafkaProducerFactory<>(configProps);
KafkaTemplate<String, OrderEvent> kafkaTemplate = new KafkaTemplate<>(producerFactory);
//when
SECONDS.sleep(5);
kafkaTemplate.send(TOPIC_NAME_SEND_ORDER, orderEvent.getBarCode(), orderEvent);
SECONDS.sleep(5);
//then
Order orderFromDB = ordersRepository.findById(ORDER_ID).get();
assertEquals(orderFromDB.getId(), ORDER_ID);
assertEquals(orderFromDB.getProductName(), order.getProductName());
assertEquals(orderFromDB.getBarCode(), order.getBarCode());
assertEquals(orderFromDB.getQuantity(), order.getQuantity());
assertEquals(orderFromDB.getPrice(), order.getPrice().setScale(2, RoundingMode.HALF_DOWN));
assertEquals(orderFromDB.getAmount(), order.getAmount().setScale(2));
assertEquals(orderFromDB.getOrderDate().getYear(), order.getOrderDate().getYear());
assertEquals(orderFromDB.getStatus(), order.getStatus());
}
}Так как это интеграционный тест, то мы будем использовать KafkaContainer и PostgreSQLContainer, и проверим, что наше сообщение прочиталось и сохранилось в базу данных.
То есть вначале настраиваем контейнеры с kafka и postgreSQL.
Далее внедряем OrdersRepository, чтобы потом получить оттуда данные.
И сам тест тоже довольно прост. Вначале мы создаем продюсера и отправляем в наш топик сообщение с заказом. Далее с помощью ordersRepository обращаемся к базе данных, оттуда получаем наш сохраненный заказ, который должен был сам сохраниться и проверяем правильный ли он.
Данный тест будет выполняться довольно долго, так как надо еще поднять контейнеры с kafka и postgreSQL.


Как видим наш тест прошел успешно.
На этом все.
Спасибо. Всем кто дочитал до конца.
Всем пока.
Комментарии (7)

Ingvar_HrabroV
20.06.2023 14:28Пройдемся по этапах создания продюсера
Добрый день, нашел опечатку. Спасибо за статью

gl-ko
20.06.2023 14:28Партиции - это копии очередей наших сообщений. Количество партиций задается replication factor.
Простите, немного выпал на этом моменте. Почему вы приравниваете partition count и replication factor? Это немного разные вещи. Replication factor показывает, сколько копий одной партиции будет храниться на разных брокерах.

MiSta1984 Автор
20.06.2023 14:28Спасибо за комментарий. Да, согласен. Replication factor - показывает на сколько брокеров-последователей (follower) будут скопированы данные с ведущего лидера (leader), а partition count - количество патриций (разделов).

drew_dru
Статья не будет полной без упоминания обновления Kafka KIP-500 (“Replace ZooKeeper with a Metadata Quorum,”), что в релизе с апреля 2021. Где рекомендуется использовать Kafka Raft Mode вместо ZooKeeper.
MiSta1984 Автор
Спасибо за комментарий.