

Поговорим сегодня про выбор, перед которым встают разработчики всех распределённых систем. Обеспечивать ли консистентность данных? Или доступность системы при различных внешних условиях — поломках, плановых отключениях узлов, — а также во время штатной эксплуатации? Теория нам даёт простые, но не всегда применимые на практике ответы: можно выбрать либо консистентность, либо доступность (теорема CAP), а когда проблем с сетью нет — то либо консистентность, либо низкие задержки (PACELC). За скобками остаётся вопрос о том, как делать этот выбор. Система как будто всегда должна быть CP или AP, а что происходит, если вдруг работающая CP-система должна начать вести себя как AP, или, наоборот, перейти обратно из AP в CP?
Я Сергей Петренко, программист Tarantool, занимаюсь разработкой алгоритма синхронной репликации и выборов лидера. В статье расскажу о нюансах CAP-теории и организации разных систем, особенностях Raft в Tarantool, возможных проблемах и методах их решения на примере Tarantool.
Статья написана по моему выступлению на HighLoad++ 2022. Вы можете посмотреть его здесь.
CAP-теорема
Впервые про такой выбор заговорил Эрик Брюэр, сформулировав CAP-теорему:
При наличии проблем с сетью (Partition) система может гарантировать либо консистентность (Consistency), либо доступность (Availability), но не то и другое вместе.
Здесь под доступностью и консистентностью понимаются конкретные определения:
Консистентность: запрос на чтение возвращает все записи, подтверждённые до этого запроса.
Доступность: запрос к любому из работающих узлов возвращает ответ за конечное время.
Итак, в терминах CAP-теоремы система может быть CP или AP.
Давайте посмотрим, почему она не может быть одновременно CP и AP: предположим, что наша распределённая система состоит из трёх узлов, и 1 и 2 потеряли связь с 3. С одной стороны, чтобы обеспечивать доступность, мы должны обслуживать любые записи на узлах 1 и 2, не дожидаясь репликации записи на узел 3, а с другой стороны — узел 3 в ответ на чтение либо возвращает устаревшие данные за конечное время (обеспечивая доступность и нарушая консистентность), либо неограниченно долго ждёт восстановления соединения с остальными, чтобы получить актуальные данные (тем самым обеспечивая консистентность, но нарушая доступность).
Есть, конечно, ещё одна возможность: забыть про разделение сети и вместо этого обеспечивать консистентность и доступность вместе. В этом нет ничего принципиально сложного. Например, CP-системы само собой обеспечивают и доступность в отсутствие проблем с сетью. Правда, за обеспечение консистентности в таком случае приходится платить повышенными задержками записи и чтения, но об этом позже. В любом случае, забывать про проблемы с сетью нельзя. Как бы ни была установлена распределённая система, в какой-то момент связность сети нарушится. Такое может происходить даже в пределах одного ЦОДа. Не говоря уже о том, что, как правило, системы устанавливаются в нескольких ЦОДах. Про то, насколько часты проблемы с сетью очень хорошо рассказано здесь. А вот более свежий пример, подтверждающий, что за прошедшие годы проблемы с сетью никуда не ушли.
Итак, поскольку рано или поздно проблемы с сетью начнутся в любой системе, реально выбор стоит между обеспечением AP или CP.
AP — любая eventually consistent система. Отличительные черты: асинхронная репликация, чтение локальных данных (без проверки на актуальность). Соответственно, запросы и на чтение, и на запись без проблем обрабатываются любым работающим узлом. Отсюда очевидно, что может нарушиться консистентность, но не доступность.
CP — это, как правило, системы с кворумом на запись и на чтение. Прежде чем запись будет подтверждена, сервер рассылает её кворуму реплик. Перед ответом на запрос на чтение сервер общается с кворумом и выясняет, не отстал ли он.
Кворумы
Для того, чтобы гарантированно читать последнюю подтверждённую запись, нужно, чтобы кворумы на чтение и запись пересекались. Обозначим общее количество узлов в кластере как N, кворум на чтение — R, а кворум на запись — W. Нам нужно, чтобы выполнялось условие R + W > N.
Например, пишем во всех, читаем с одного (W = N, R = 1). Понятно, что это обеспечивает консистентность: на какой бы узел ни пришёл запрос на чтение, этот узел гарантированно знает обо всех подтверждённых записях: перед подтверждением они должны попасть на каждый узел.
Или пишем в одного, читаем со всех (W = 1, R = N). Тоже консистентно. Любой запрос на чтение опрашивает все узлы, каждый из которых самостоятельно подтверждает попавшие на него записи. Чтение увидит все записи, которые были подтверждены на этот момент.
Такие крайности, конечно, не практичны. При кворумах W = N, R = 1 или W = 1, R = N отказ всего одного узла приведёт к недоступности всей системы на запись или чтение соответственно. Чтобы пережить отказ одного узла, можно без вреда для консистентности выставить кворум W = N - 1, R = 2. То есть подтверждаем запись после её попадания на произвольные N - 1 узлов, а при чтении узел, на который пришёл запрос, обращается к своему собственному состоянию и состоянию другого случайно выбранного узла.
Рассуждая так и дальше, придём к тому, что наилучшая с точки зрения доступности пара кворумов — W = N / 2 + 1, R = N / 2 + 1 — позволяет пережить отказ (N - 1) / 2 узлов без нарушения консистентности. То есть система переживает потерю одного из трёх или четырёх, двух из пяти или шести и т. д. узлов. Можно заметить, что нет смысла выбирать чётное количество узлов в такой системе. Платим за размещение лишнего узла (например, четвёртого вдобавок к трём), ничего не получая в плане количества переживаемых отказов. Даже наоборот, вероятность того, что откажут сразу два или более узла из четырёх, выше, чем вероятность того, что откажут сразу два или более узла из трёх. Значит доступность системы понизилась с добавлением четвёртого, шестого, … узла. То же самое касается кластера из двух узлов: кворум W = R = 2, и отказ любого из них приводит к недоступности системы и на запись, и на чтение.
Алгоритм Raft
Широко известный пример CP-системы — Raft, алгоритм распределённого консенсуса. Он нужен, чтобы несколько участников могли совместно решить, произошло ли событие или нет и что за чем следовало. Для обеспечения консенсуса в Raft сначала выбирают лидера, который управляет распределённым журналом. Лидер принимает запросы от клиентов и реплицирует их на остальные серверы в кластере. Подтверждение транзакции происходит после её попадания на W = N / 2 + 1 узлов. В случае выхода лидера из строя в кластере будет выбран новый лидер. Чтобы стать лидером, кандидат должен набрать R = N / 2 + 1 голосов. Можно провести аналогию между кворумом на чтение, про который мы говорили выше, и кворумом голосов для избрания лидером. Фактически лидером может стать только тот узел, который видел все подтверждённые до сих пор записи. Это нужно для того, чтобы распределённый журнал на всех узлах содержал одни и те же записи в одном и том же порядке, и чтобы уже подтверждённые записи не терялись при смене лидера.
У нас в Tarantool есть своя реализация алгоритма Raft вместе с необходимыми для его стабильной работы расширениями, PreVote и CheckQuorum. Про реализацию Raft и синхронную репликацию можно прочитать в предыдущих наших статьях (1, 2). Про PreVote, CheckQuorum и некоторые другие расширения Raft, которые мы применили, можно почитать тут.
Как бы замечателен ни был Raft в теории, на практике всё упирается в выбор между консистентностью и доступностью. А доступностью нельзя просто так пожертвовать. Дело в том, что Raft хорошо работает только в том случае, когда в кластере есть три или больше точек отказа. Если кластер (пусть и с тремя или больше узлами) расположен в двух точках отказа, то выход из строя любой из них приведёт к недоступности всего кластера.
Две точки отказа — очень частый сценарий. У большинства заказчиков кластер располагается в двух ЦОДах, и невозможно распределить узлы по ним так, чтобы кластер продолжил работать при отключении одного из ЦОДов: если мы расположили узлы поровну, например, два и два, то отключение любого ЦОДа приведёт к потере кворума: останется два узла при кворуме три. Если же мы расположим узлы неравномерно, например один и два, то отключение ЦОДа с одним узлом не навредит кластеру; но вот уже отключение ЦОДа с двумя узлами опять приведёт к недоступности. В такой ситуации для восстановления системы нужно или ждать, когда будет устранен сбой ЦОДа, или вручную снижать кворум, что нарушает Raft.

Для решения этой проблемы обычно применяют подход с «кворумным» ЦОДом. Понятно, что устанавливать полноценные узлы ещё и в третьем ЦОДе дорого. Поэтому нужно придумать какие-нибудь легковесные узлы, которые бы участвовали в кворуме, но при этом сами не писали данные и никогда не становились лидерами. В идеале пусть вообще один такой узел имеет возможность следить за состоянием множества кластеров, участвует в голосовании и кворуме на запись в каждом из кластеров, но не хранит у себя никакие данные.
Реализация такого узла достаточно сложна: нужно хранить на диске некоторый объём системной информации сразу для нескольких кластеров, участвовать одновременно во множестве выборов. Мы пока не поддерживаем такие узлы, поэтому для нас остро стоит проблема доступности при размещении кластера в двух ЦОДах. Дальше поговорим, как мы с этим справляемся.
Доступность после потери кворума
Как правило, консистентность интересует всех только до тех пор, пока она не влияет на доступность. Другими словами, потери от длительного простоя обычно оказываются намного выше, чем потери от возможной потери консистентности. Поэтому в отсутствие лучших альтернатив (кворумный ЦОД) мы позволяем пользователю вручную понижать кворум для выборов лидера и коммита синхронных транзакций. Это помогает проводить выборы и обрабатывать пользовательские запросы даже если отказал один из основных ЦОДов.
Но, как известно, там, где может вмешаться человек, возможны ошибки. Например, можно одновременно понизить кворум в двух разделённых частях кластера, устроив split brain. Или же понизить кворум только в одной части кластера, но забыть повысить его до корректного значения после восстановления связности.

В любом случае можно прийти к ситуации, когда два лидера будут функционировать одновременно и писать конфликтующие версии данных. Главное, что мы делаем для защиты от внутренних конфликтов между нодами в этом случае — не даём им соединиться после независимой работы. Такой подход выбран потому, что оба узла в процессе независимой работы могут записывать и подтверждать транзакции, и обе версии данных становятся актуальными — заменить или отозвать любую из них без риска непредсказуемых последствий нельзя. Кроме того, на уровне системы неизвестно, какая из версий данных важнее пользователю, то есть вариант с автоматическим разрешением конфликтов тоже не подходит.
Основная идея состоит в том, что появление таких конфликтующих историй можно заметить сразу в момент восстановления связности. И заметив расхождение, мы не пытаемся соединить конфликтующие истории, а просто сохраняем обе версии для разрешения конфликтов человеком. Про то, как именно мы этого добиваемся, я уже рассказывал в прошлой статье.
Консистентость уровня Linearizable
Что же такое эта консистентность, которую мы так стараемся сберечь? На самом деле существует целый ворох уровней консистентности (https://jepsen.io/consistency). Среди них есть уровень linearizable. Определяется он так:
Любая операция (и на запись, и на чтение) выполняется атомарно в какой-то момент времени между получением системой запроса и отправкой ответа клиенту.
Любое чтение возвращает результат всех выполненных на момент его прихода записей. Если чтение вернуло какой-то результат, то все последующие чтения возвращают либо такой же результат, либо результат более свежей записи.
Это ровно то, что подразумевается под термином Consistency в терминах CAP теоремы. Очень сильное требование: для его выполнения и читать, и писать нужно по кворуму.
Linearizable read — составная часть Raft, и мы достигаем его следующим образом: поскольку любые решения в кластере Raft принимаются большинством, то если мы спросим большинство узлов об их актуальном состоянии, мы не пропустим ни одного принятого решения (выполняется условие, что кворум на запись и на чтение должны пересекаться). После такого опроса, который занимает достаточно продолжительное время, мы дожидаемся, пока актуальная версия данных попадёт к нам по каналу репликации, и уже после этого выполняем чтение.
На практике это реализовано так. В кластере из N узлов с кворумом N / 2 + 1 узел, выполняющий линеаризуемую транзакцию, опрашивает всех об их актуальном состоянии (vclock) и дожидается ответа от кворума (N / 2 + 1). После этого, найдя максимальный vclock из присланных, узел ждёт, пока его vclock сравняется с найденным максимумом, а затем ждёт ещё, до тех пор, пока все пришедшие на него за это время записи не будут подтверждены.
Самое интересное, что этой процедуры не может избежать даже мастер. Дело в том, что он никогда не может быть уверен, что его ещё не сместили. Поэтому ему нужно получить от большинства подтверждение, что он — всё ещё лидер, а они — всё ещё его последователи.
PACELC. Выбирать приходится и в отсутствие разделения сети
На самом деле даже если забыть про проблемы с сетью, мы всё равно стоим перед выбором, и здесь уже CAP-теорема нам ничего сказать не может. В отсутствие P — разделения сети — можно обеспечить и консистентность, и доступность. Но за консистентность по-прежнему приходится платить. Для её обеспечения нам по-прежнему нужно читать и писать по кворуму, а каждая такая операция требует похода по сети к каждому узлу кворума, что неизбежно приводит к повышению задержек для таких операций. Фактически задержка записи (и чтения) увеличивается на время похода по сети до самого медленного узла из кворума и выполнения операции на нём.
Итак, об этом говорит теорема PACELC — расширение CAP теоремы: в случае разделения сети (Partitioning) выбираем между доступностью (Availability) и консистентностью (Consistency), иначе (Else) — между задержкой (Latency) и консистентностью (Consistency).
Кроме того, если уж выбирать консистентность, то нет смысла в репликации «мастер-мастер». Предположим, что у нас два узла могут писать независимо и одновременно. Каждый из них выполняет операции над своей версией данных. Чтобы эти операции приводили к консистентной картине, они должны выполняться над самой свежей версией данных. Фактически, чтобы «мастер-мастер» система писала консистентно, нам нужно заставить каждого из мастеров дожидаться изменений, сделанных остальными, прежде чем он сможет сделать своё изменение. Это сводит на нет все преимущества от использования «мастер-мастер», поэтому CP-системы и не пытаются обеспечивать эту схему.
Место Tarantool в PACELC
В Tarantool реализован алгоритм Raft вместе с синхронной репликацией; с недавнего времени у нас есть и linearizable read. Таким образом, если пользоваться только синхронной репликацией и никогда не снижать кворум вручную, мы будем относиться к PC/EC в PACELC. Ручное понижение кворума в случае разделения сети превращает нас в PA/EC.
Полный отказ от Raft и синхронной репликации, включение «мастер-мастер» превращает нас в PA/EL.
Для полноты не хватает только PC/EL: что, если очень хочется достичь низкой задержки, но при этом не жертвовать консистентностью? Можно использовать Raft и при этом выбрать для некоторых таблиц асинхронную репликацию. На первый взгляд кажется, что такой режим — это PC/EL, но всё не так просто. Можно сказать, что у нас получается достичь PC/EL с некоторыми оговорками.
Проблема асинхронных транзакций
До сих пор мы обсуждали синхронную репликацию, классический Raft работает только с ней. Конечно, напортачить и нарушить консистентность можно и с синхронной репликацией — при условии, что кворум понижен вручную. Однако есть ещё и асинхронная репликация, и с ней дело приобретает ещё более интересный оборот. Посмотрим, что, например, может произойти.
Например, есть кластер с Raft, в котором выбран лидер I. В какой-то момент его связь с остальными рвётся, но он продолжает принимать асинхронные транзакции и отвечает клиентам. В том числе записывает, что “foo” равно 2. Одновременно с этим большинство связанных узлов выбирает нового лидера II, который тоже начинает принимать запросы и отвечать на них. В том числе записывает, что “foo” равно 3. Таким образом система работает с двумя лидерами, но не нарушает гарантии Raft.
Гарантии не нарушены, потому что Raft лишь гарантирует, что в каждом Term будет не более одного лидера. Про наличие нескольких лидеров одновременно в разных Term ничего не сказано. Оригинальный Raft может себе это позволить, потому что использует синхронную репликацию. Соответственно, лидер, оставшийся в старом Term, не сможет подтвердить ни одну запись после потери связи. Если же мы разрешаем использовать асинхронную репликацию, то получаем вот такие сюрпризы.
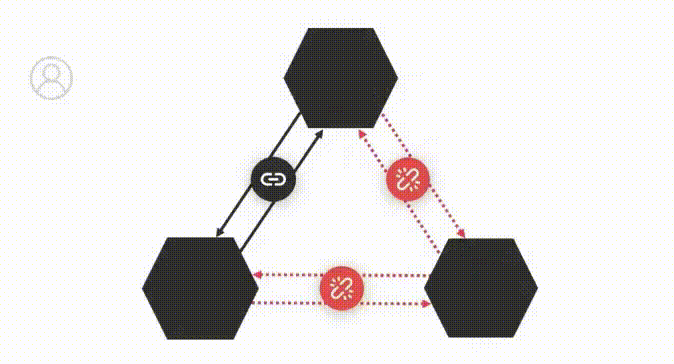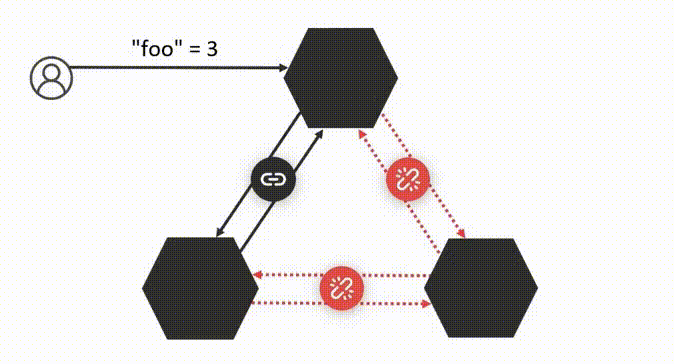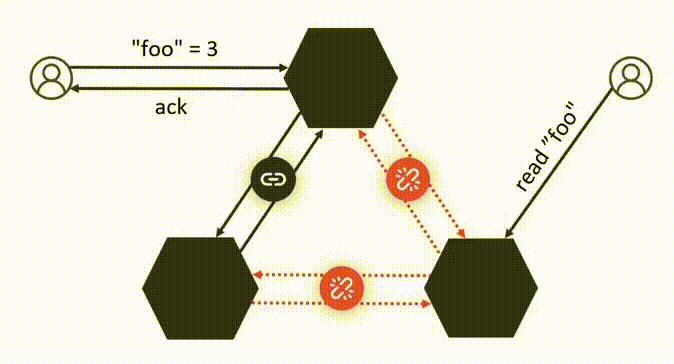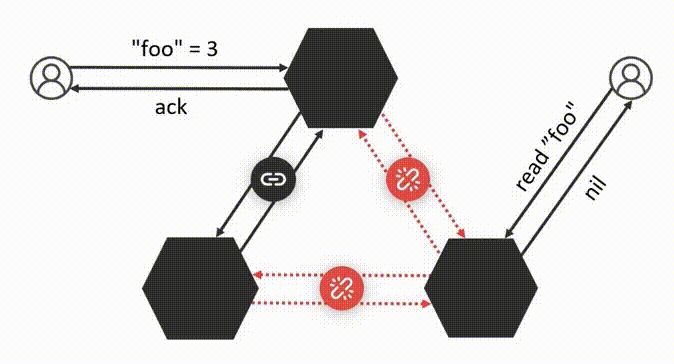
Как только сеть снова объединяется, старый лидер I складывает полномочия и лидеры начинают синхронизировать подтвержденные транзакции. При синхронизации оказывается, что данные на серверах противоречат друг другу: на одном “foo” равно 3, а на другом — 2. Но отменить подтвержденные транзакции нельзя.
Мы столкнулись с подобным инцидентом: серверы работали независимо всего 1,5 минуты, но на устранение последствий и восстановление консистентности данных понадобилось 9 часов работы специалиста. В результате мы сделали вывод, что такие ситуации лучше предупреждать. Но поскольку при асинхронной репликации мы не можем запретить серверам работать после обрыва связи, нужно просто не дать им воссоединиться после независимой работы.
В нашей ситуации оказался бы бессилен даже CheckQuorum — надстройка Raft, которая заставляет лидера сложить полномочия, как только он видит, что потерял большинство. Причина в том, что у CheckQuorum есть небольшой таймаут на проверку соединения, во время которого всё равно существует два лидера, которые независимо получают транзакции. То есть даже с CheckQuorum при восстановлении связи пришлось бы вручную приводить данные в консистентное состояние.
В отсутствие Raft и синхронной репликации такое поведение асинхронных транзакций никого не удивляет. В конце концов, отличие Raft от обычной асинхронной репликации именно в том, что Raft обеспечивает идентичность журналов на разных узлах (включая порядок операций). Для асинхронных транзакций такую идентичность обеспечить невозможно. Более того, мы не можем молча откатывать асинхронные транзакции старого лидера: они подтверждаются без кворума, а значит, старый лидер уже подтвердил клиенту их применение.
Итак, мы стоим перед выбором, что же делать с асинхронными транзакциями от старого лидера в присутствии синхронных:
Применять их, как ни в чём не бывало.
Откатывать их так, как будто это неподтверждённые синхронные транзакции.
Не применять их, а соответственно и всё, что придёт от старого лидера после них.
Первый вариант, естественно, хорош для асинхронной репликации без каких-либо алгоритмов, обеспечивающих консистентность, но совершенно не подходит для Raft. Как я уже сказал, главное обещание Raft — совпадение порядка операций в журналах на всех узлах. Его очень легко нарушить, применив асинхронную транзакцию со старого лидера. Последствия при этом могут быть самые разные, начиная от конфликта и остановки репликации из-за дублирующегося insert до расхождения данных на двух узлах, если они, например, выполнят отличающиеся replace по одному и тому же ключу.
При асинхронной репликации «мастер-мастер» (вообще говоря, и при single master тоже) пользователь хорошо осведомлён о таких проблемах и может их решать с помощью триггеров на автоматическое разрешение конфликтов. Цель всегда одна: добиться консистентной картины мира на всех узлах.
Однако когда в дело вступает Raft, такое поведение асинхронных транзакций портит гарантии и для синхронных: например, пользователь может опираться на результат чтения асинхронной таблицы в синхронной транзакции, и его ожидания насчёт содержимого асинхронной таблицы будут нарушены после синхронизации со старым лидером.
Другой вариант — откатывать асинхронные транзакции старого лидера — тоже плох. Хотя в этом случае мы и приведём журналы на всех узлах к общему состоянию, старый лидер уже сообщил пользователю, что применил транзакцию, и мы не имеем права молча её выкинуть.
Остаётся лишь не допускать перемешивания транзакций из двух параллельных ветвей истории и ждать пользовательского вмешательства. Мы используем для этого тот же механизм, который применили для обнаружения split brain при понижении кворума.
Главное из нашего опыта
Хотя выбор между консистентностью и доступностью, который предоставляет CAP-теорема, предельно прост, на практике он нас не устраивает. Хочется, насколько это возможно, ухватить лучшее от обоих миров. Однако теория не обманывает: выбрать и то, и другое нельзя. Короткий вывод: чудес не бывает, и теорема CAP (а также PACELC) не врёт. Тем не менее, с помощью различных настроек можно превратить Tarantool в PC/EC-, PA/EC- или PA/EL-систему. Каждый из режимов хорош по-своему, но нужно хорошо понимать, где те ограничения, которые система не может преодолеть:
При наличии асинхронных транзакций даже Raft не защищает от перехода в «мастер-мастер» — полноценно обеспечить консистентность не получится.
Ошибки при конфигурировании могут привести к переходу в «мастер-мастер» даже при синхронной репликации. Например, при неправильном снижении кворума могут появиться два лидера и конфликтующие транзакции.
Данные нужно защищать от последствий независимого изменения несколькими узлами. Мы используем превентивные методы: не даём соединиться узлам, которые какое-то время работали независимо.
Разрешать конфликты автоматически неправильно. Если обе ноды записали данные и подтвердили это, то система не имеет права выбрать лучшую из двух расходящихся версий данных.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
Комментарии (6)

nin-jin
13.06.2023 20:46+2Перед ответом на запрос на чтение сервер общается с кворумом и выясняет, не отстал ли он.
Но процесс опроса не мгновенный, так что к моменту отсылки (и тем более приёма) ответа, данные могут быть уже не актуальны. Так что кворум на чтение принципиально не гарантирует актуальности.
наилучшая с точки зрения доступности пара кворумов — W = N / 2 + 1, R = N / 2 + 1 — позволяет пережить отказ (N - 1) / 2 узлов без нарушения консистентности
Но эта схема при этом максимизирует нагрузку на сеть. Например, для 11 узлов, на каждый запрос от клиента (что на запись, что на чтение) происходит пересылка минимум 20 сообщений между узлами. В то время как чтение без кворума может ограничиться лишь 2 сообщениями, чтобы проверить свою актуальность у лидера. То есть разница на порядок.
Чтобы эти операции приводили к консистентной картине, они должны выполняться над самой свежей версией данных.
Либо надо использовать конвергентные структуры, операции над которыми можно переставлять местами.

sergepetrenko Автор
13.06.2023 20:46+2Но процесс опроса не мгновенный, так что к моменту отсылки (и тем более приёма) ответа, данные могут быть уже не актуальны. Так что кворум на чтение принципиально не гарантирует актуальности.
Да, кворум на чтение гарантирует только то, что ответ будет актуален на момент получения запроса, но не на момент отправки ответа.
bak
В ассинхронных транзакциях нужно возвращать клиенту ID транзакции и в последствии сообщать об успешности или не успешности данной транзакции. Клиент не имеет права полагаться на то что асинхронная транзакция завершилась успешно.
Ну и в целом "ручное понижение" и попытки сделать консистентность из 2-х нод выглядят как костыли пораждающие кучу проблем.
PS. Ну и выводы ИМХО не верные, рафт обрабатывает все эти случаи абсолютно корректно, вы пытаетесь сделать из него то чем он не является и ловите проблемы.
sergepetrenko Автор
Наверное, мы с вами разное понимаем под "асинхронной транзакцией". Мы возвращаем клиенту ответ только после того, как транзакция записана в журнал мастера. В этот момент она уже применилась, и клиент вполне может на это полагаться. Никакого подтверждения лучше он не получит. Только то, что транзакция есть в журнале одного узла. А "асинхронная" она потому что мы не дожидаемся её попадания в журналы реплик прежде чем ответить клиенту.
Это правда. При "ручном понижении", двух нодах или асинхронных транзакциях это уже не рафт. Но все эти компромиссы могут быть полезны в конкретных случаях. Другое дело, что гарантии при этом явно снижаются. Мы лишь пытаемся сделать так, чтобы пользователь получил какой-то повышенный уровень консистентности по сравнению с полным отказом от рафта. Ну и, конечно, от пользователя зависит, пользоваться этими трюками, или нет. Если не пользоваться, то получите полноценный рафт со всеми его гарантиями.
bak
В журнал мастер пишет транзакции сразу по получению. Это не значит что она уже "применилась". "Применять" транзакцию нужно только после того как получено подтверждение от >1/2 кластера что они тоже записали это в свои журналы (commit_index нужен именного для этого).
До этого - клиенту нельзя давать ответ об успешной записи, это не даёт вообще никаких гарантий. Кроме отката транзакций raft-ом ещё есть ситуации аварийного отключения сервера и если вы не делаете flush после каждой записи (что убивает производительность) - клиент так же успешно потеряет транзакцию.
И асинхронные интерфейсы обычно делают так что им можно предоставить колбек который потом асинхронно вернет результат. А не "ну потерялось подумаешь".
sergepetrenko Автор
Да, именно так работает рафт. Потому что в нём есть только "синхронные" транзакции.
В Тарантуле есть и "асихнронные" и "синхронные". И первые - это не просто асинхронный интерфейс для вторых. Это другой тип транзакций с другим поведением. Как я уже написал, асинхронные применяются сразу после попадания в журнал мастера. И в этот же момент отвечают клиенту.
У нас тип репликации для транзакции выбирает пользователь. Выбрал "синхронную" - получает рафт. Выбрал "асинхронную" - получает что-то среднее со своими проблемами, не такими, как в рафте. Я про эти проблемы и пишу в статье.
Да, и как правило пользователь знает об этом риске. Есть ведь системы, которые ни рафт, ни кворумную ("синхронную") запись не поддерживают. Про них нельзя сказать, что они не дают никаких гарантий. Зато они позволяют писать с низкой latency. Потому что не надо ждать, пока запись доедет до большей части узлов.