
В статье приведён анализ производительности недавно ставшей популярной [1] реализации сортировки Intel AVX-512.
Intel опубликовала невероятно быструю библиотеку сортировки для AVX-512, Numpy переходит на неё, чтобы ускорить сортировку в 10-17 раз
В этом анализе мы рассмотрим производительность x86-simd-sort компании Intel и сравним её с другими обобщёнными реализациями сортировки, например, с std::sort из стандартной библиотеки C++ и vqsort — ещё одной высокопроизводительной реализацией сортировки с ручной векторизацией. Сведение сложных характеристик производительности к единому числу может быть сложной задачей, а получаемые прогнозы могут быть неточными. В своём анализе я хочу шире взглянуть на это значение «10-17 раз» и понять, как оно соотносится с другими высокопроизводительными реализациями.
TL;DR: бенчмаркинг — это сложно. Если вы пользуетесь x86-simd-sort, то можете повысить общую производительность и избежать катастрофического масштабирования при определённых паттернах входных данных с помощью vqsort + Clang. Кроме того, в анализе показано, что аппаратно-зависимая ручная векторизация с широкими AVX-512 SIMD — не единственный способ писать эффективное ПО. Несмотря на свою обобщённость, ipnsort демонстрирует сравнимую с x86-simd-sort производительность, оптимизированную не только под пиковую производительность, и при этом используя команды только до уровня SSE2.
Предупреждение о предвзятости: автор этого анализа — разработчик ipnsort.
Термины «реализация сортировки» и «алгоритм сортировки» не взаимозаменяемы. На практике все высокопроизводительные реализации — это гибриды, использующие множество алгоритмов сортировки. Поэтому термин «алгоритм сортировки» будет использоваться только при обсуждении алгоритмической природы конкретных «строительных блоков» реализаций.
Графики с логарифмическими осями маркированы так, что в первую очередь полезны для исследования изменений свойств, а не абсолютных значений.
Бенчмарки
Подготовка бенчмарков
Бенчмарки печально известны своей сложностью реализации, и в особенности могут быть нерепрезентативны синтетические бенчмарки. Вот неполный список влияющих на результаты факторов:
Объём входных данных
Тип входных данных (затраты на перемещение и затраты на сравнение)
Паттерн входных данных (уже отсортированные, случайные, кардинальность, периодичность, смешанные данные и так далее)
Аппаратное прогнозирование и влияние кэшей
Аппаратное прогнозирование и влияние кэшей в «холодных» бенчмарках, циклически выполняющихся только с входными данными фиксированного размера, типа и сочетания паттернов, могут снижать прогностическую силу бенчмарков для реального применения. Особенно при малых объёмах входных данных. В последнем разделе «Горячие бенчмарки» рассматриваются «горячие» результаты и подробнее объясняется, почему они могут быть не очень полезны в данном контексте.
Тестовая машина с Windows
Windows 10.0.19044
rustc 1.69.0-nightly (0416b1a6f 2023-02-14)
clang version 15.0.1
Microsoft (R) C/C++ Optimizing Compiler Version 19.31.31104 for x86
18-ядерный процессор Intel Core i9-10980XE (микроархитектура Skylake)
Включен CPU boost.Тестовая машина с Linux
Linux 5.19
rustc 1.69.0-nightly (7aa413d59 2023-02-19)
clang version 14.0.6
18-ядерный процессор Intel Xeon Gold 6154 (микроархитектура Skylake)
Отключен CPU boost.Некоторые реализации сортировок адаптивны, они пытаются использовать паттерны в данных, чтобы выполнять меньше работы. Вот примеры паттернов бенчмаркинга:
ascending— по возрастанию, числа в интервале0..sizerandom— случайные числа, сгенерированные randStdRng::gen[2]random_d20— равномерно распределённые случайные числа в интервале0..=20random_p5, 95% — нули и 5% случайных данных, неравномерныхrandom_z1— распределение Zipfian с характеризующей экспонентой s == 1.0 [3]saws_long—(size as f64).log2().round()чисел в случайно выбранных возрастающих и убывающих сериях значенийsaws_short— случайно выбранные возрастающие и убывающие серии значений в интервале20..70
Репрезентативность этих паттернов зависит от вашей конкретной полезной нагрузки. Всё это — фундаментально синтетические бенчмарки для изолированного изучения производительности сортировок.
Претенденты
Выборка высокопроизводительных реализаций сортировок без потребности в дополнительном пространстве (in-place).
Основанные на обобщённом сравнении
- rust_std_unstable | `slice::sort_unstable` https://github.com/rust-lang/rust (1)
- rust_ipnsort_unstable | https://github.com/Voultapher/sort-research-rs/blob/main/src/unstable/rust_ipnsort.rs (2) (3)
- cpp_std_msvc_unstable | MSVC `std::sort` (4)
- cpp_std_gnu_unstable | libstdc++ `std::sort` (8)
- cpp_std_libcxx_unstable | libc++ `std::sort` (9)
- cpp_pdqsort_unstable | https://github.com/orlp/pdqsort (4)
- c_crumsort_unstable | https://github.com/scandum/crumsort (5) (6)
С ручной векторизацией
- cpp_vqsort | https://github.com/google/highway/tree/master/hwy/contrib/sort (7) (10)
- cpp_intel_avx512 | https://github.com/intel/x86-simd-sort (7)
Примечания:
Разработана примерно в середине 2022 года.
По-прежнему находится в разработке, и результаты только предварительные.
Раньше эта сортировка называлась ipn_unstable, ранее представленная ipn_stable уже не развивается, а работа над стабильной реализацией сортировки продолжается под другим названием.
Собрана с помощью msvc.
Скомпилирована с
#define cmp(a, b) (*(a) > *(b)). Это необходимо для конкурентоспособности: обычный способ обеспечения функции сравнения проблематичен из-за ограничений языка C. По сути, это значит, что результаты применимы только к примитивным типам, а всё, что использует собственную функцию сравнения для пользовательских типов, будет иметь серьёзное снижение производительности.crumsort производит первоначальный анализ и переключается с сортировки слиянием (merge sort) на quadsort, которая занимает до N памяти, из-за чего сортировка перестаёт быть in-place. В случае сбоя распределения он может вернуться обратно к in-place сортировке слиянием. Тесты выполнялись с условием возможности распределения.
Сборка выполнена с clang и
-march=native. Скомпилировано со статической диспетчеризацией, код не будет портируемым. CPU без поддержки AVX-512 не сможет запустить двоичный файл. Неизвестно, как снизит производительность динамическая диспетчеризация.Сборка выполнена с gcc.
Сборка выполнена с clang.
Распределяет буфер памяти фиксированного размера, независящий от размера входных данных. Это размывает границы in-place.
Результаты u64
Хороший бенчмарк, позволяющий пролить свет на способность сортировки использовать параллелизм на уровне команд (instruction-level parallelism, ILP) — это hot-u64-10000. В качестве входных данных в нём используются 10 тысяч значений u64, которые на использованных тестовых машинах помещаются в приватный кэш данных L2 ядра. Для такого датасета верхняя граница должна быть порядка 4-5 команд на такт. 10 тысяч элементов достаточно, чтобы точно использовать паттерны входных данных. Это можно воспроизвести, выполнив cargo bench hot-u64-<pattern>-10000

Но если бы мы использовали эти данные, чтобы составить заголовок типа
Rust std sort в 15 раз быстрее сортировки C++ std sort
то это не было бы честно. И по-прежнему под вопросом, можно ли ужать такой объём информации в единственное число, сохранив при этом репрезентативность. Изучая этот единственный размер входных данных на одной конкретной микроархитектуре с использованием конкретного набора компиляторов и тестируя эти синтетические паттерны, мы получаем такие результаты:
При таком размере входных данных intel_avx512 в общем случае быстрее, чем vqsort.
Две вручную векторизируемые реализации сортировки (intel_avx512 и vqsort) плохо справляются с использованием паттернов во входных данных.
intel_avx512 испытывает трудности, если во входных данных есть одно очень часто встречающееся значение (random_p5).
cpp_std_msvc в общем случае становится самой медленной реализацией сортировок, исходя из сравнений.
rust_std, основанная на pdqsort, имеет схожую с ней производительность, за исключением входных данных, полностью идущих по возрастанию.
идущие по возрастанию входные данные демонстрируют наибольший разброс: самая быстрая сортировка примерно в 31 раза медленнее самой медленной.
Более естественные случайные распределения наподобие random_z1 уменьшают разрыв между вручную векторизированным кодом и структурами на основе pdqsort, rust_std, ipnsort и crumsort.
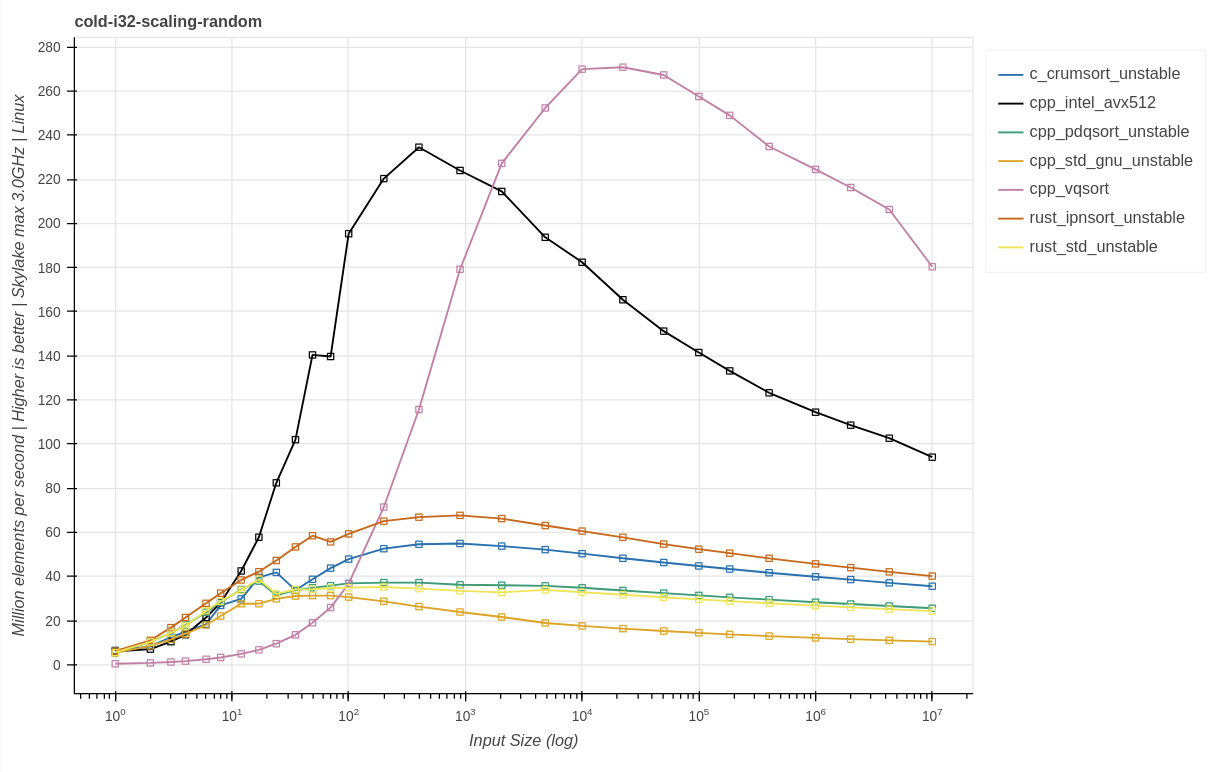
Измерение производительности на случайных паттернах для разных размеров данных:

Выводы:
Сортировка для случайных входных данных классически ограничена сложностью O(N * log(N)), поэтому можно ожидать, что наибольшая производительность будет наблюдаться на наименьших объёмах входных данных. Однако в реальности на крошечных размерах входных данных производительность снижается из-за лишней траты ресурсов на вызов функций, холодного кода и промахов прогнозирования кэша и ветвлений. А при очень больших размерах основным ограничением обычно становятся пропускная способность основной памяти и увеличение объёма работы на один элемент. Пиковая производительность большинства высокопроизводительных реализаций, уравновешивающая все вышеупомянутые факторы, достигается на входных данных размером примерно 1 тысячу.
При тестировании vqsort показала себя как чрезвычайно медленная с малыми объёмами входных данных. Подробнее об этом говорится ниже.
Начиная с примерно 50 тысяч элементов входных данных vqsort становится самой быстрой.
ipnsort догоняет intel_avx512 примерно при 1 миллионе, несмотря на то, что использует только команды SSE2 и не применяет аппаратно-зависимого кода; при этом она стремится к снижению размера двоичного файла и времени компиляции, иногда ценой производительности.
Сравнение Linux и Windows
В обычном случае я бы не ожидал никаких существенных отличий между Linux и Windows для кода, который, за исключением распределений и структуры стека, не содержит специфичной для операционных систем логики. Более того, в двух тестовых машинах используется одинаковая микроархитектура Skylake. Изучая тот же бенчмарк cold-u64-random, мы получаем:
Windows:

Linux:
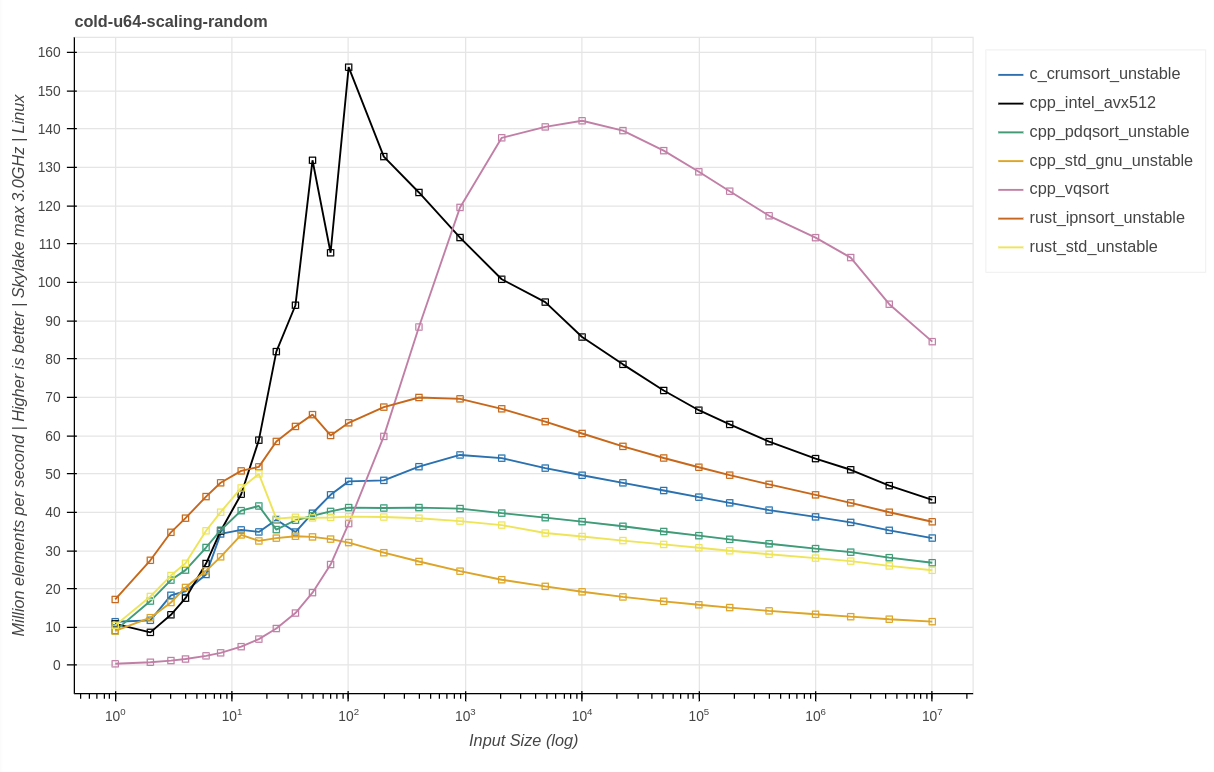
Выводы:
intel_avx512, pdqsort, rust_std и ipnsort теряют производительность
Похоже, libstdc++
std::sortв этом тесте проявляется лучше, чемmsvc-версия. Она демонстрирует существенно меньшую регрессию, чем можно было бы ожидать вследствие разницы частот CPU.Относительное снижение производительности по сравнению с ipnsort на машине с Windows больше, чем у intel_avx512. Вероятно, это вызвано отключенным CPU boost и общим консервативным ограничением частоты в 3 ГГц. Машина с Linux более показательна для серверной среды. По контрасту на машине с Windows ipnsort может разгоняться быстрее, чем intel_avx512.
При больших входных данных intel_avx512 демонстрирует в Windows лучшую производительность при замеренной поддерживаемой частоте примерно в 3,8 ГГц. Например, при размере входных данных в 1 миллион на машине с Windows производительность составила примерно 67 миллионов элементов/с, а в Linux — примерно 54 миллиона элементов/с. Это вполне соответствует разнице в частотах.
Однако vqsort в Linux гораздо быстрее. Она обгоняет остальные сортировки как с точки зрения пиковой производительности, так и при минимальном размере входных данных. Такой результат оказался неожиданным, и для анализа первопричин этого были приложены существенные усилия. В тестовой vqsort использовались те же компилятор и флаги, что и для intel_avx512. Другой набор бенчмарков дал те же результаты, другая предварительно собранная версия Clang тоже дала те же результаты. На машине Zen3 с dual boot vqsort в режиме AVX2 при переходе с Linux на Windows демонстрирует ту же регрессию примерно в 2 раза при размере входных данных в 10 тысяч. При всём этом остальные реализации сортировок остаются преимущественно с такими же результатами. Первопричину этого удалось выявить совместно с авторами vqsort [4]. Протестированная версия vqsort приобрела случайность от операционной системы для каждого вызова vqsort в попытке устранить потенциальный отказ в обслуживании (denial-of-service, DOS) производительности. Эта идея схожа с использованием SipHash в качестве стандартного хэшера для стандартной библиотеки Rust. Это объясняет существенно различающиеся в Windows и Linux результаты. См. подробности в объяснении по ссылке выше.
Ещё одним неожиданным результатом стало то, что пиковая производительность intel_avx512 в Linux ниже, несмотря на повышенные частоты. И пиковые значения в Linux достигаются раньше.
Измерения более естественного zipfian-распределения random_z1 при разных размерах входных данных:


Выводы:
В общем случае поведение схоже с масштабированием производительности при случайных паттернах.
intel_avx512 демонстрирует менее равномерное масштабирование, а в целом ухудшившаяся производительность схожа с производительностью при случайных паттернах.
Реализации на основе pdqsort и vqsort по сравнению со случайными паттернами демонстрируют рост производительности благодаря возможности эффективной фильтрации часто встречающихся значений.
Измерения для случайного распределения, в котором большинство значений (95%) одинаково:


Выводы:
Реализации на основе pdqsort и rust_std_msvc в Windows, а также vqsort в Linux демонстрируют превосходную производительность, в несколько раз выше, чем при случайных паттернах.
Производительность intel_avx512 хуже, чем при случайных паттернах, что даёт в этом сценарии ухудшенную производительность.
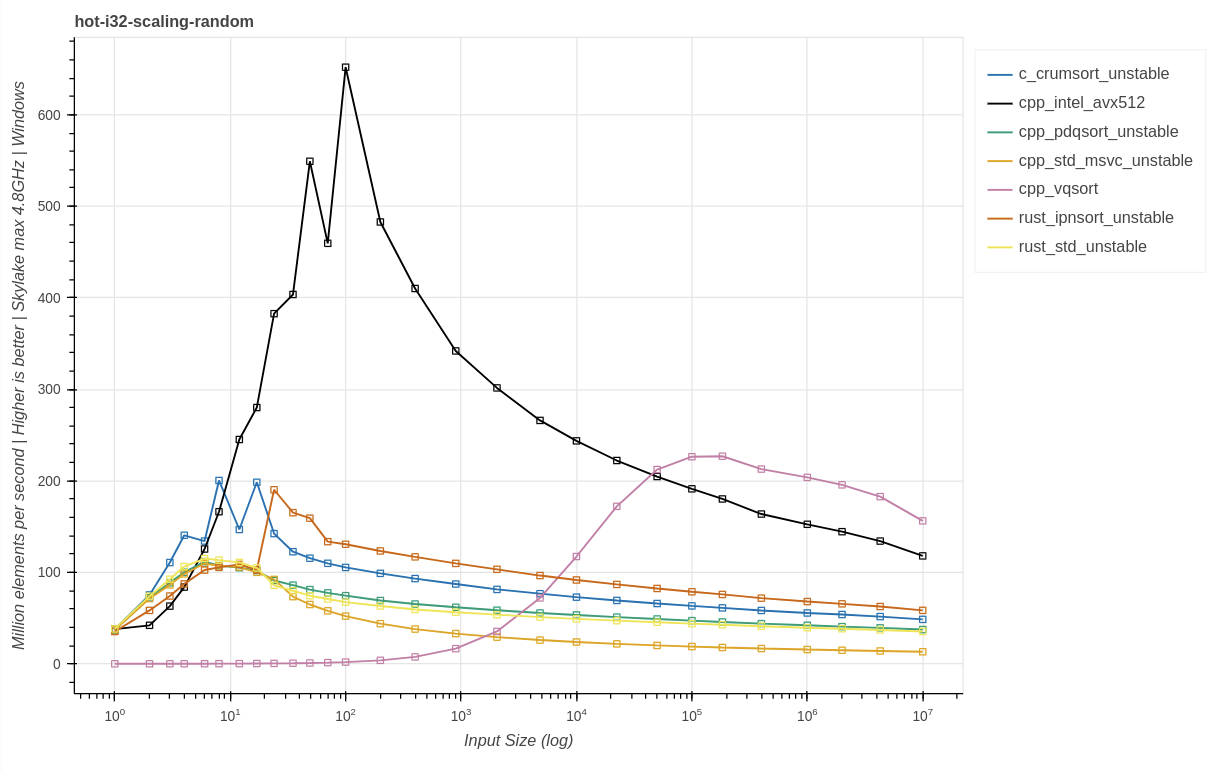
Результаты i32
i32-10k
Основная разница между i32 и u64 заключается в том, что i32 составляет всего 4 байта, а u64 — 8 байтов. На практике все высокопроизводительные реализации сортировок чувствительны к пропускной способности подсистем памяти CPU. Теоретически это позволяет обеспечить повышенную пропускную способность кэшей, оптимизированное использование кэшей и повышенную производительность векторного АЛУ.
Windows:
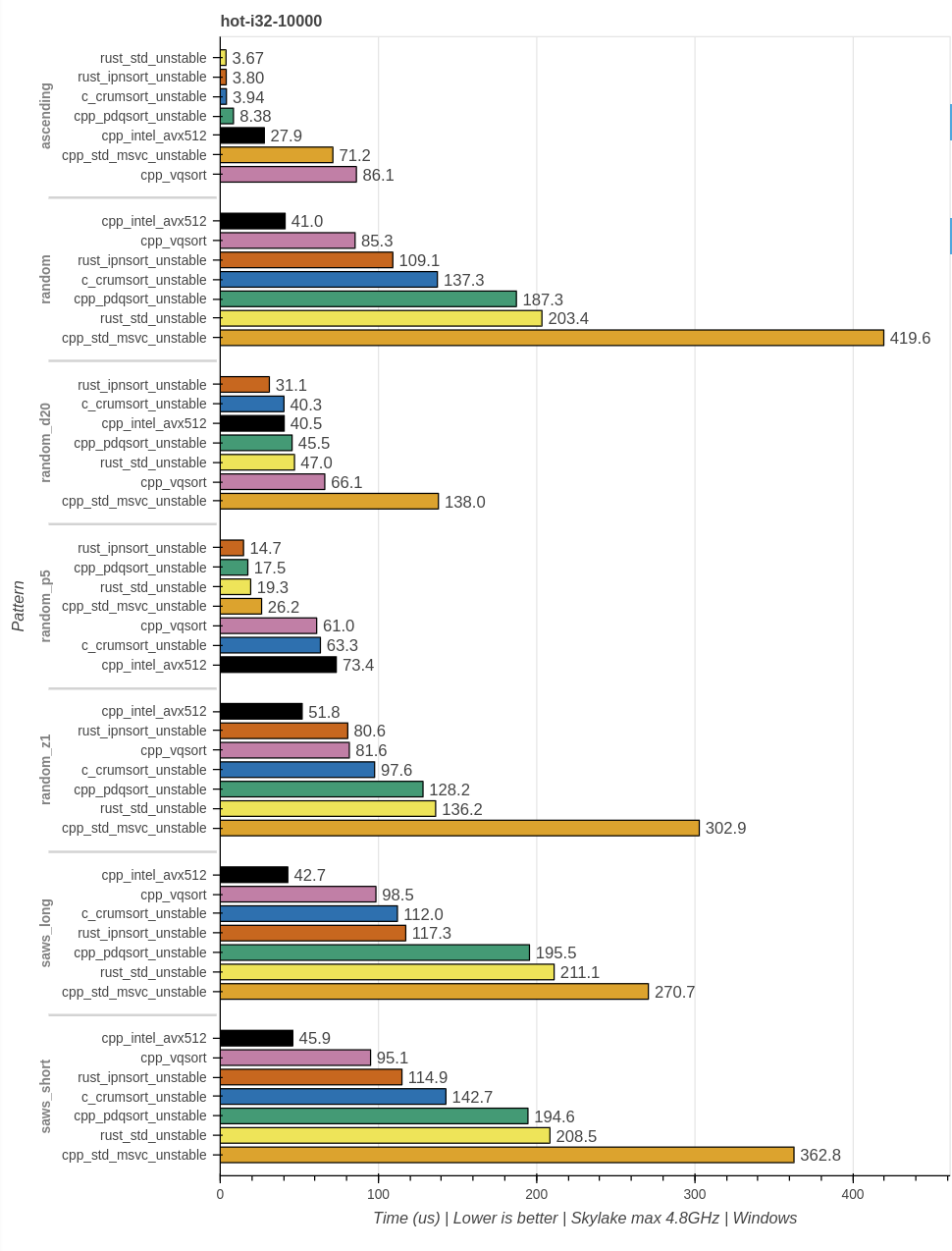
Linux:

Выводы:
Обе вручную векторизируемые реализации почти удвоили свою производительность. Для этого размера входных данных vqsort демонстрирует это только в Linux. В Windows она показывает меньший рост.
Все реализации сортировок на основе сравнений демонстрируют по сравнению с
u64лишь небольшой рост производительности.
i32-scaling
Windows:

Linux:
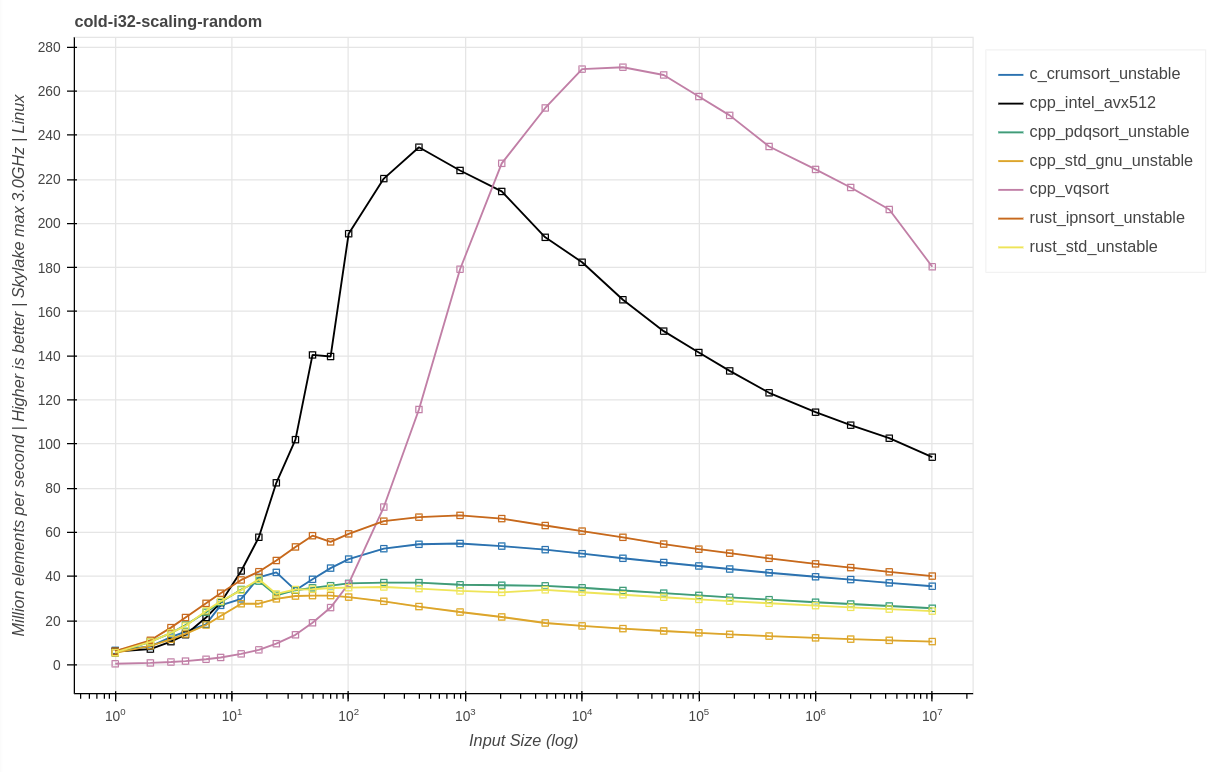
Выводы:
Вручную векторизируемые реализации гораздо лучше используют повышенную потенциальную производительность, чем реализации на обобщённого основе сравнения.
Масштабирование очень схоже с ситуацией с
u64для реализаций без ручной векторизации.
Прямое сравнение
Исчерпывающую картину производительности для одного типа можно получить сравнением двух реализаций и составлением графика, где на оси Y откладываются их симметричные относительные ускорения и замедления, а на оси X — объём тестовых данных. Каждый график представляет собой паттерн. Например в a-vs-b, 1.7x означает, что a в 1,7 раза быстрее b, а -1.7x означает, что b в 1,7 раза быстрее a. Первое название в заголовке — это сортировка a, а второе название — сортировка b. Графики фиксированы по оси Y в интервале от -3x до 3x, чтобы обеспечить возможность сравнения графиков.
Сравнение двух реализаций u64 с ручной векторизацией:


Выводы:
Есть огромная разница между Linux и Windows. Все линии движутся влево, то есть vqsort обгоняет intel_avx512 при меньших размерах входных данных. А при опускании графиков в интервале размеров от 100 тысяч до 10 миллионов vqsort примерно в 2 раза быстрее в Linux, но только примерно в 1,4 раза быстрее в Windows для случайных входных данных.
В Windows ниже 10 тысяч и 200 в Linux intel_avx512 быстрее vqsort в каждом из паттернов.
Паттерн random_5p вызывает создание плохих разделений в intel_avx512, у которой нет от них защиты, из-за чего vqsort становится примерно в 14 раз быстрее, чем intel_avx512 при
len == 10mв Windows и примерно в 26 раз быстрее в Linux. Похоже, это демонстрирует, что intel_avx512 имеет масштабирование наихудших случаев хуже, чемO(N * log(N)); вероятно, это вызвано плохим выбором опорных точек и отсутствием стратегий борьбы с такими проблемами.
Сравнение двух реализаций i32 с ручной векторизацией:


Выводы:
i32показывает себя очень схоже сu64за исключением random_z1 в Linux, демонстрирующего более серьёзное преимущество vqsort.
Сравнение с самой быстрой реализацией ipnsort на основе обобщённого сравнения:


Выводы:
Между размерами входных данных 36 и 1 тысяча intel_avx512 в Linux быстрее почти в каждом паттерне. Между 1 тысячей и 100 тысячами intel_avx512 быстрее с полностью случайными и пилообразными паттернами.
ipnsort быстрее при паттернах с низкой кардинальностью и zipfian, в которых она может использовать позаимствованную у pdqsort способность фильтрации часто встречающихся значений.
В Linux и с максимальной частотой 3 ГГц intel_avx512 быстрее при полностью случайных и пилообразных паттернах.
Как говорилось выше, intel_avx512 демонстрирует при random_p5 масштабирование хуже, чем
O(N * log(N)), поэтому ipnsort примерно в 15 раз быстрее в Windows и примерно в 19 раз быстрее в Linux при 10 миллионах входных данных.Ни intel_avx512, ни vqsort не способны пользоваться уже отсортированными входными данными. Однако производные от pdqsort реализации способны обрабатывать такие случаи за
O(N). При 100 тысячах входных данных ipnsort примерно в 20 раз быстрее в Windows и примерно в 15 раз быстрее в Linux. А при 10 миллионах входных данных примерно в 10 раз быстрее в Windows и примерно в 16 быстрее в Linux. В случае с 10 миллионами данных производительность по большей мере ограничена пропускной способностью основной памяти, которой у серверной реализации Skylake больше.
Результаты в системах без AVX-512
Подавляющее большинство потребительских устройств не поддерживает AVX-512. intel_avx512 поддерживает только устройства AVX-512, однако vqsort написана поверх highway [5] — SIMD-абстракции, поддерживающей различные платформы и аппаратные возможности. Например, её можно использовать на машинах, поддерживающих только AVX2, а также в чипах Arm с поддержкой Neon.
Тестовая машина AVX2
Linux 6.2
rustc 1.70.0-nightly (17c116721 2023-03-29)
clang version 15.0.7
12-ядерный процессор AMD Ryzen 9 5900X (микроархитектура Zen3)
Включен CPU boost.
Выводы:
vqsort демонстрирует ту же чрезвычайно низкую производительность при малом размере данных.
Все реализации на основе обобщённого сравнения демонстрируют большой рост производительности по сравнению со Skylake.
При больших объёмах входных данных ipnsort гораздо ближе к vqsort по сравнению с Linux-машиной на Skylake.
crumsort демонстрирует меньший рост по сравнению с pdqsort и rust_std, чем на машинах со Skylake.
vqsort добирается до пиковой производительности раньше, чем на Linux-машине со Skylake.
Тестовая машина с Neon
Darwin Kernel Version 22.1.0
rustc rustc 1.70.0-nightly (f15f0ea73 2023-03-04)
Apple clang version 14.0.0
8-ядерный процессор M1 Pro (микроархитектура Firestorm P-core)
Включен CPU boost.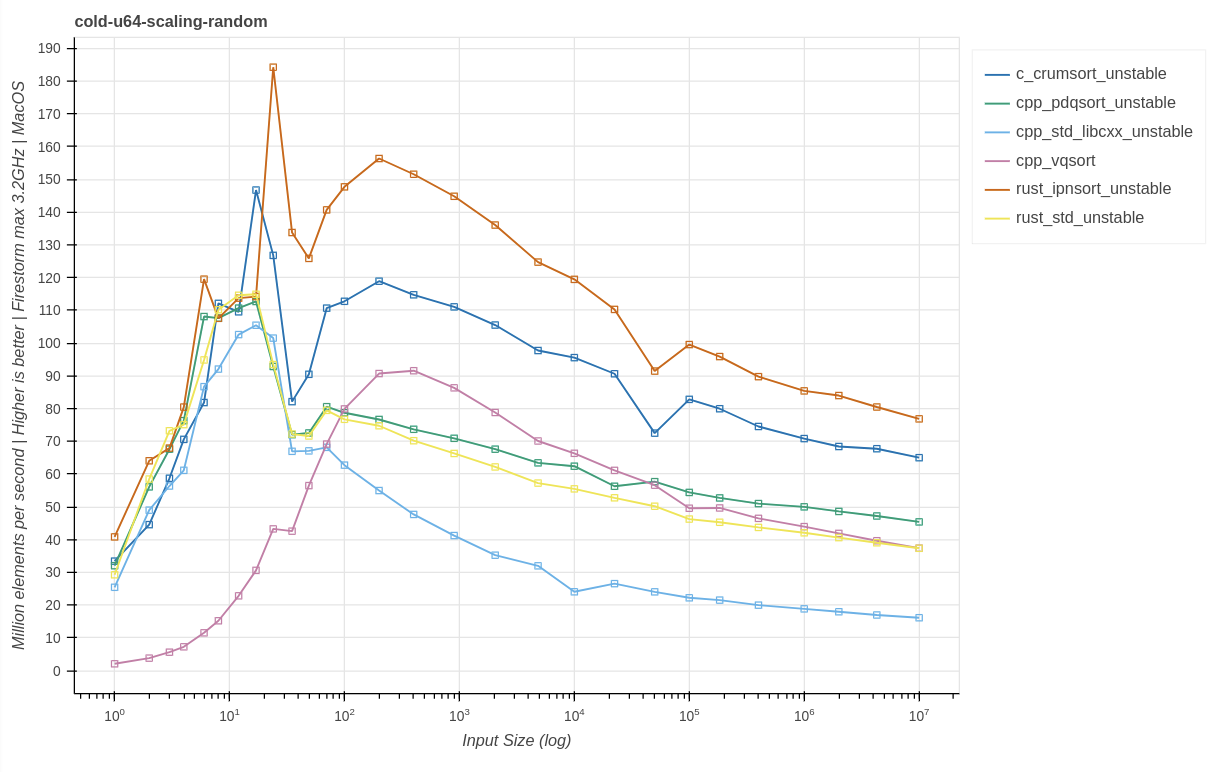
Выводы:
vqsort демонстрирует ту же чрезвычайно низкую производительность при малом размере данных.
У большинства реализаций сортировок производительность практически удвоилась по сравнению с результатами на чипе Skylake со схожими тактовыми частотами. Это демонстрирует возможности микроархитектуры Firestorm, использующей широкую структуру внеочередного исполнения (out-of-order, OoO).
По сравнению с результатами на Skylake и Zen3, Firestorm раньше добирается до пиковой производительности. Это демонстрирует превосходную реализацию прогнозирования ветвлений с меньшим уроном от промахов, быстрое обучение и превосходную структуру кэша в целом.
В общем случае cpp_std_libcxx показывает себя наихудшим образом.
vqsort демонстрирует производительность, схожую с pdqsort, ограниченную набором команд Neon и 128-битной шириной векторов.
Две реализации, активно использующие ILP (crumsort и ipnsort) демонстрируют больший прирост производительности по сравнению с pdqsort; ipnsort показывает рост производительности в 1,9 по сравнению с 1,6 раза на Skylake.
При 50 тысячах входных данных возникает стабильно воспроизводимое плато производительности; похоже, ему подвержены и crumsort, и ipnsort.
Измерения мощности показывают, что ipnsort потребляет примерно в 1,4 раз меньше мощности, при этом она почти вдвое быстрее. Это подразумевает примерно в 2,7 раза бОльшую энергоэффективность. Значит, в некоторых ситуациях код, делающий упор на использование ILP, может быть более энергоэффективным, чем векторизированный код. К тому же у него есть преимущество отсутствия зависимости от оборудования.
Интерфейс сортировки C
crumsort отзеркаливает интерфейс qsort стандартной библиотеки C, который запрашивает функцию сравнения int (*comp)(const void *, const void *). И хотя в большинстве кода это реализуется при помощи return a - b;, такой код при некоторых integer приводит к UB и не является обобщённым. Простая реализация с веб-сайта cppreference имеет следующий вид:
int compare_ints(const void* a, const void* b)
{
int arg1 = *(const int*)a;
int arg2 = *(const int*)b;
if (arg1 < arg2) return -1;
if (arg1 > arg2) return 1;
return 0;
// return (arg1 > arg2) - (arg1 < arg2); // possible shortcut
// return arg1 - arg2; // erroneous shortcut (fails if INT_MIN is present)
}Однако на некоторых компьютерах он будет генерировать ветвления. А это, в свою очередь, вызывает промахи прогнозирования ветвлений, что нежелательно, особенно для кода, который должен использовать ILP. Другая альтернатива заключается в том, чтобы записать это способом, генерирующим хороший код без ветвления, особенно с Clang:
int compare_ints(const void* a_ptr, const void* b_ptr)
{
const int a = *(const int*)a_ptr;
const int b = *(const int*)b_ptr;
const bool is_less = a < b;
const bool is_more = a > b;
return (is_less * -1) + (is_more * 1);
}Этой проблемы можно избежать прогнозированием промахов ветвления, однако сохраняется ещё одна проблема. C выполняет абстрагирование поверх пользовательской логики при помощи указателей функций. По контрасту с замыканиями в C++ и Rust их нельзя встроить (inline) без profile-guided optimization (PGO). До недавнего времени crumsort требовал собственного define, глобально отключающего собственные сравнения при помощи #define cmp(a, b) ((a) > (b)) до парсинга реализации только в заголовке. Это требуется для наилучшей производительности и используется во всех бенчмарках. Однако с точки зрения поддерживаемых типов это делает crumsort более похожей на реализации с ручной векторизацией. Пользовательские типы, не помещающиеся в long long, потребуют модификаций на уровне исходников. А для наилучшей производительности с таким интерфейсом для каждого типа нужно компилировать уникальную версию crumsort при помощи системы сборки. По сути, это проблема C и проблема только для crumsort, потому что эта сортировка реализована на C и отзеркаливает интерфейс qsort.
Сравнение результатов crumsort и crumsort, использующей функцию сравнения без ветвления (c_crumsort_generic) на Linux-машине со Skylake:


Выводы:
При использовании обобщённой версии crumsort производительность существенно хуже, примерно в 2,4 при больших размерах данных и для большинства случайных паттернов.
c_crumsort_generic демонстрирует производительность, близкую к cpp_std_gnu.
На паттерны наподобие ascending и random_d20, в которых выполняется меньше сравнений, это влияет сильнее.
Горячие бенчмарки
Выполнение реализации сортировки в цикле несколько миллионов раз, стандартно применяемое в инструментах наподобие бенчмарка google и criterion с новыми уникальными входными данными одинакового размера и паттерна, нерепрезентативно для реальной производительности. Для имитации программы, которая время от времени вызывает сортировку с различными размерами данных и с холодным состоянием прогнозирования CPU, бенчмарки также выполняются в режиме, в котором между каждыми вызовами сортировки состояния прогнозирования CPU сбрасывается [6]. Эти бенчмарки маркируются как cold-. И они стали основой для представленных выше графиков масштабирования. Бенчмарки, использующие только стандартную логику горячих циклов, помечены как hot-. Результаты горячих бенчмарков следует интерпретировать как производительность в наилучшем случае и в лабораторных условиях.
Масштабирование u64
Измерение производительности случайных паттернов с разными размерами входных данных:

Выводы:
Даже в горячем цикле vqsort чрезвычайно медленная при малых размерах входных данных.
При бенчмаркинге в горячем цикле intel_avx512 быстр при всех размерах входных данных.
intel_avx512 и crumsort выделяются на фоне других реализаций тем, что не используют для таких входных данных сортировку вставками.
Начиная с примерно 50 тысяч самой быстрой становится vqsort .
ipnsort догоняет intel_avx512 примерно при 1 миллионе, несмотря на то, что использует только команды SSE2 и не применяет аппаратно-зависимого кода.
Начиная с 10 тысяч входных данных холодные и горячие результаты по большей мере примерно одинаковы.
При использовании стандартной библиотеки Rust и сборке специализированной версии rustc, записывающей логи размеров входных данных и времени, проведённого в slice::sort [7] (устойчивой сортировке стандартной библиотеки Rust), дало следующие результаты чистой компиляции 60 крейтов:
Из примерно 500 тысяч вызовов slice::sort 71,6% имели len == 0, 22,8% имели len == 1, и суммарно 99+% имели len <= 20 , все вместе они составляют примерно 50% времени, проведённого в slice::sort.
Взглянем на важный интервал len <= 20:

Выводы:
В отличие от ситуации с горячими результатами, ipnsort побеждает в графике.
Пиковая производительность для
len <= 20по сравнению с горячими результатами падает в пять раз.
Стоит также упомянуть масштабирование частот. За исключением последних поколений микроархитектур Intel и AMD, Golden Cove и Zen4, предыдущие реализации Intel AVX-512 при исполнении некоторых команд AVX-512 [8] уменьшали частоту CPU boost. Это может влиять на реальное использование и производительность. Ещё один аспект, на который потенциально может повлиять холодный код — это запуск AVX-512; это явление ограничено плохой реализацией Skylake AVX-512.
Судя по холодным и горячим бенчмаркам, они моделируют два предельных случая самого вероятного интервала возможных результатов.
Другие горячие результаты

Вывод и мнение автора
intel_avx512 — очень быстрая реализация сортировки, особенно для случайных входных данных, демонстрирующая хорошее масштабирование при различных размерах входных данных. Однако в простых паттернах она демонстрирует масштабирование хуже O(N * log(N)) и страдает от плохого выбора опорных точек без возможности перехода в другой режим. При типах меньше 8 байтов, например, u8 или i32, обе реализации с ручной векторизацией демонстрируют гораздо большую производительность, чем реализации на основе обобщённого сравнения. В этом анализе мы не рассматривали затраты на динамическую диспетчеризацию, которая потребуется для использования этого в коде, не скомпилированного уникально для конкретной платформы. Рассмотрим несколько сценариев:
Специализированная сортировка в библиотеке
intel_avx512 может быть отличным выбором, если входные данные в основном случайны, состоят из обычных integer или float различного размера, не очень малы, имеют не очень низкую кардинальность и имеется соответствующее оборудование с поддержкой AVX-512. В то же время её может быть проблематично использовать в качестве единственной замены для вызовов сортировки из-за холодной производительности, производительности в наихудшем случае и потенциальных проблем с масштабированием частот.
Специализированный код для HPC
Если вам нужна наилучшая производительность и известно, что будут присутствовать только большие объёмы данных поддерживаемых типов, то vqsort — это более быстрая альтернатива. Для наилучшей производительности vqsort требуются Linux и clang. Другие компиляторы использовать не стоит, они создают код, который во много раз медленнее.
Стандартная библиотека языка
В большинстве ситуаций вполне подойдёт реализация из стандартной библиотеки, однако в некоторых ситуациях возможна низкая производительность. В таком случае у применения intel_avx512 есть множество очевидных проблем. Она поддерживает только небольшую долю устройств и увеличивает размер двоичных файлов для всех целевых систем x86. Она не очень хорошо использует готовые паттерны во входных данных. Она не может поддерживать пользовательские сравнения, и потенциально это может означать существенные различия в производительности между v.sort_unstable() и v.sort_unstable_by(|a, b| a.cmp(b)). Она не может поддерживать пользовательские типы без дополнительного пользовательского кода, например, #[derive(Copy, Clone)]struct X(i32) может иметь существенную разницу в производительности с i32. Кроме того, есть проблемы с холодной производительностью и масштабированием частот.
Все результаты — это снэпшоты соответствующих реализаций. После выполнения этих измерений могли возникнуть изменения в crumsort и ipnsort, а разработчики vqsort изучают вопрос производительности при малых размерах данных. Я специально решил не выполнять повторно бенчмарки с новыми версиями, чтобы избежать перекосов, вызванных исправлением некоторых аспектов, например низкой производительности saws_long в ipnsort, не дав всем реализациям шанс внести подобные улучшения.
Благодарности
Я благодарю Яна Вассенберга за подробные отзывы, огромную помощь в проведении бенчмарков и в понимании некоторых выводов. Благодарю Роланда Бока за подробные отзывы и помощь в повышении удобочитаемости статьи.
Дополнение
Результаты обновлённой vqsort
Новая версия vqsort fe85fdf. Те же графики, что и раньше, с добавленной cpp_vqsort_new. Здесь повторно тестировалась только vqsort.
Skylake (AVX-512):
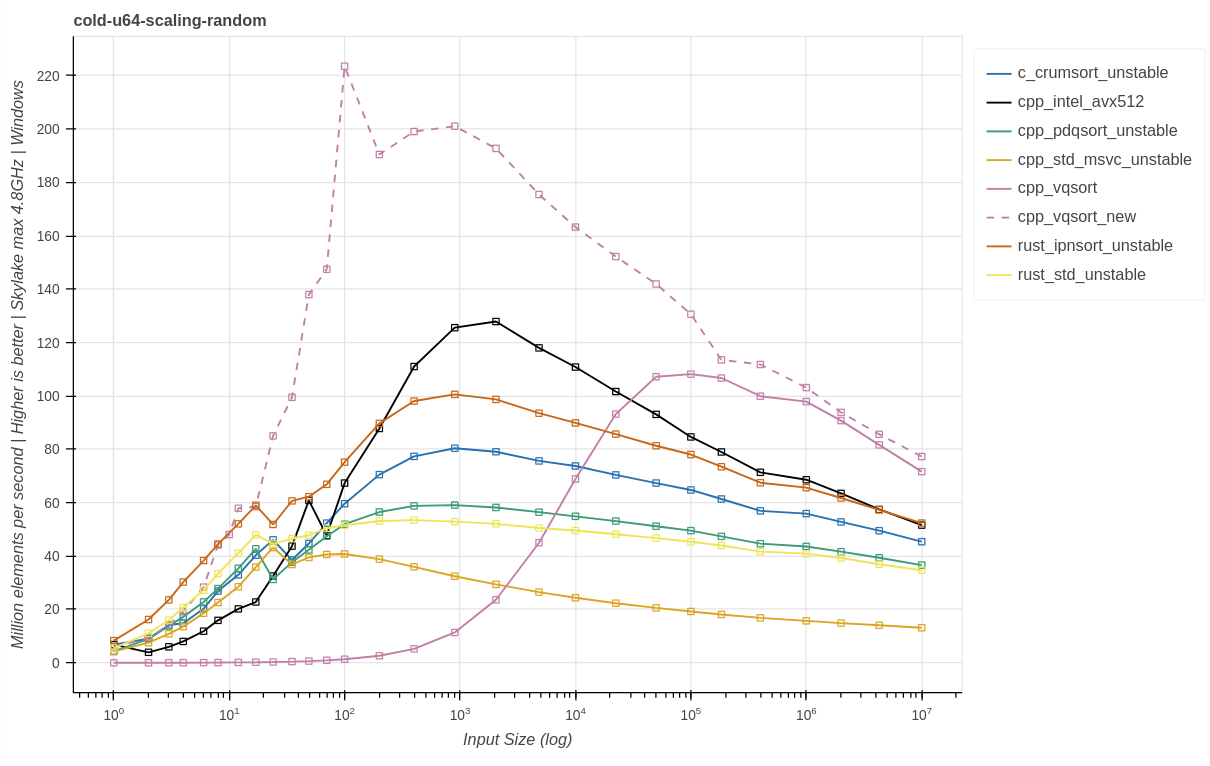
Zen3 (AVX2):

Выводы:
Новая версия vqsort решила основную проблему очень низкой производительности при малых объёмах входных данных и даже смогла улучшить общую производительность при больших размерах входных данных. Теперь это, без сомнения, самая быстрая реализация сортировки из протестированных, когда для случайных паттернов возможно использование AVX2 или AVX-512.
Комментарии (7)

Sabirman
13.06.2023 11:50Интересно, как они ускорили - за раз по несколько чисел что ли сравнивают ?
Если оно работает только для простых массивов int или float, то в этом случае можно задействовать алгоритмы сортировок с линейным временем - они, в конце концов, дадут лучший результат.


Str5Uts
13.06.2023 11:50PatientZero про сортировку — не видел перевода новости от deepmind — может возьмётесь?


Panzerschrek
13.06.2023 11:50Мне несколько непонятно, зачем автор свою сортировку на Си написал. На C++ бы не было головной боли с передачей компаратора.
Lex20
Ну это прям культ - avx везде пихать. А потом доказывать что быстрее стало.
6p45c
А вы предпочли бы без доказательств? Всему верите на слово?