

Веб-потоки (web streams) предоставляют основанный на веб-стандартах способ асинхронной потоковой передачи данных по сети. Они позволяют разработчикам обрабатывать большие наборы данных по чанкам (chunks — части, куски), контролировать перегрузку сети (обратное давление — backpressure) и создавать высокоэффективные и отзывчивые приложения.
Использование веб-потоков может повысить производительность и отзывчивость приложения. Обработка данных по мере их поступления позволяет применять обновления и реагировать на взаимодействия пользователя в реальном времени, обеспечивая бесшовный пользовательский опыт за счет быстрой загрузки данных, предоставления актуальной информации и плавного, более интерактивного интерфейса.
Web Streams API постепенно становится краеугольным камнем основных веб-платформ, включая браузеры, Node.js и Deno. В этой статье мы рассмотрим, что такое веб-потоки, как они работают, их преимущества, а также инструменты, созданные на их основе.

Двумя основными преимуществами веб-потоков являются:
- Мгновенная обработка данных: данные могут обрабатываться по мере поступления, нет необходимости ждать всю полезную нагрузку (payload). Это может существенно повысить скорость загрузки больших данных, особенно в условиях медленного соединения.
- Полный контроль данных: веб-потоки позволяют разработчикам читать и обрабатывать данные в соответствии с потребностями приложения и сценариями его использования.
Веб-потоки могут быть разделены на 3 основных типа: WritableStream, ReadableStream и TransformStream. У каждого из них своя роль:
-
WritableStream: пишет данные (но не читает) в любое место с помощью "писателя" (writer); -
ReadableStream: асинхронно читает данные (но не пишет) с помощью "читателя" (reader); -
TransformStream: манипулирует данными или преобразует их в процессе передачи с помощью "преобразователя" (transformer).
Веб-потоки могут объединяться в цепочки (chain) — последовательность шагов по обработке данных, что повышает читаемость и "поддерживаемость" кода, а также облегчает создание сложных конвейеров (pipeline) обработки данных.

Чанки
Чанки — это фундаментальные единицы данных в веб-потоках, часто представленные в виде строк (текстовые потоки) или Uint8Array (бинарные потоки). Чанки могут иметь разные формы и размеры, что зависит от таких факторов, как:
- Источник данных. Если мы читаем данные из файла, файловая система может читать его по блокам определенного размера, что будет влиять на размер чанков.
- Реализация потока. Данные могут помещаться в буфер и отправляться, объединяясь в большие чанки, или же данные могут отправляться малыми чанками.
- Среда локальной разработки. При локальной разработке на размер чанков не влияют сетевые условия.
- Сеть. Размер чанков может ограничиваться максимальной единицей передачи (maximum transmission unit, MTU). Физическое расстояние между клиентом и сервером может приводить к фрагментации чанков.
Наш код должен быть готов к обработке чанков любого размера, поскольку его сложно предсказать, и мы его часто не контролируем.
Рассмотрим пример.
const decoder = new TextDecoder();
const encoder = new TextEncoder();
const readableStream = new ReadableStream({
start(controller) {
const text = "Stream me!";
controller.enqueue(encoder.encode(text));
controller.close();
},
});
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = decoder.decode(chunk);
controller.enqueue(encoder.encode(text.toUpperCase()));
},
});
const writableStream = new WritableStream({
write(chunk) {
console.log(decoder.decode(chunk));
},
});
readableStream
.pipeThrough(transformStream)
.pipeTo(writableStream); // STREAM ME!Сначала мы кодируем (encode) строку "Stream me!" и помещаем ее в очередь (enqueue) в ReadableStream. Этот ReadableStream становится источником данных, который могут потреблять (consume) другие потоки.
Для передачи данных от ReadableStream другому потоку используется метод pipeThrough. Данные передаются TransformStream, который получает чанки данных, декодирует (decode) их в строки текста, приводит строку к верхнему регистру, кодирует ее и помещает преобразованный чанк для потребления следующим потоком.
Данные передаются WritableStream с помощью метода pipeTo. По сути, WritableStream — это конечная точка (endpoint), позволяющая потребить данные кастомизированным способом. В данном случае мы декодируем чанк данных и выводим его в консоль.
Одним из основных способов взаимодействия с веб-потоками является метод getReader, предоставляемый Fetch API. Данный метод позволяет последовательно читать чанки данных из тела запроса по мере их прибытия, что позволяет эффективно обрабатывать большое количество данных.
const decoder = new TextDecoder();
const response = await fetch('/api/stream');
const reader = response.body.getReader();
let done = false;
while (!done) {
const { value, done: doneReading } = await reader.read();
done = doneReading;
const data = JSON.parse(decoder.decode(value));
// Работаем с данными
}Обратное давление
Одной из самых мощных возможностей, предоставляемых веб-потоками, является встроенная обработка обратного давления, которое происходит, когда данные генерируются быстрее, чем потребляются, например, когда высокоскоростной сервер посылает данные клиенту с медленным соединением.
При несовпадении скорости генерации и обработки данных, лишние элементы помещаются в очередь и ждут обработки потребителем. Если это продолжается долгое время, очередь продолжает расти, что может привести к заполнению памяти со всеми вытекающими последствиями.

Обработка обратного давления может быть сложной из-за необходимости соблюдения баланса между скоростью генерации и потребления данных. Бесконтрольная генерация данных может привести к проблемам с памятью из-за буферизации данных. С другой стороны приостановка генерации данных может привести к простою их генератора при наличии доступных возможностей по обработке данных.
Обработка обратного давления с помощью веб-потоков
Веб-потоки обрабатывают обратное давление через управление потоком данных (flow control). Когда поток находится в состоянии readable, данные свободно передаются между генератором и потребителем. Если входящие данные начинают превышать возможности потребителя, поток переходит в состояние backpressure. Это состояние является сигналом для генератора о необходимости приостановки производства данных.
Когда потребитель освобождается, поток снова переходит в состояние readable, и генерация данных продолжается. Этот автоматический механизм защищает потребителя от переполнения данными, а генератора — от простоя.
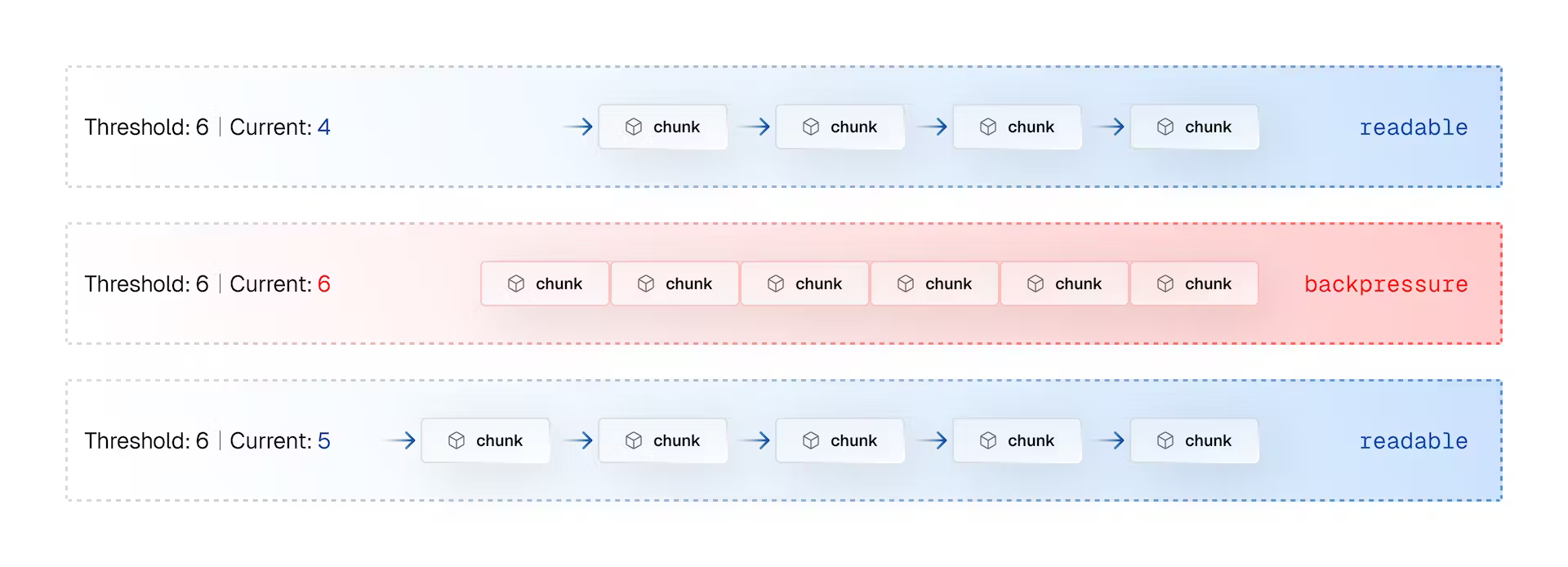
В ReadableStream обратное давление применяется косвенно через читателя. Когда читатель извлекает (pull) чанки из потока, это сигнализирует о его готовности к обработке новых данных. Если читатель перестал извлекать данные (метод read перестал вызываться), поток делает вывод о том, что читатель занят обработкой имеющихся данных, и генерация новых данных должна быть приостановлена.
В WritableStream обратное давления применяется напрямую к писателю. Метод write возвращает промис, который разрешается (resolve) только когда поток готов к новым данным. Таким образом, неразрешенный промис служит индикатором обратного давления.
const stream = new WritableStream(...)
async function writeData(data) {
const writer = stream.getWriter();
for (const chunk of data) {
// Ждем разрешения промиса для записи следующего чанка
await writer.ready;
writer.write(chunk);
}
writer.close();
}Использование ключевого слова await приводит к приостановке выполнения кода до разрешения промиса. Это гарантирует, что мы не пишем данные быстрее, чем поток для записи может их обработать.
Server-Sent Events
Server-sent events (SSE), что условно можно перевести как "события, отправляемые сервером", являются популярным способом доставки обновлений от сервера к клиенту в реальном времени. В то время как веб-потоки используются, в основном, для обработки данных, SSE поддерживает открытое соединение с сервером, позволяя передавать данные по мере их появления.

Веб-потоки закрывают соединение после передачи всех данных. SSE используют долгоживущее (long-lived) соединение HTTP, которое может использоваться сервером для передачи новых данных. SSE может быть востребован в приложениях, где новые данные генерируются в реальном времени, включая провайдеров ИИ (искусственный интеллект — artificial intelligence, AI), таких как OpenAI.
Для обработки ответа SSE, содержащего обычный текст (plain text), можно применить библиотеку eventsource-parser для разбора фрагментированных чанков, передаваемых с помощью функции feed:
import { createParser } from "eventsource-parser"
export function OpenAITextStream(
res: Response,
): ReadableStream {
const encoder = new TextEncoder()
const decoder = new TextDecoder()
let counter = 0
const stream = new ReadableStream({
async start(controller): Promise<void> {
function onParse(event: ParsedEvent | ReconnectInterval): void {
if (event.type === 'event') {
const data = event.data
if (data === '[DONE]') {
controller.close()
return
}
try {
const json = JSON.parse(data)
const text =
json.choices[0]?.delta?.content ?? json.choices[0]?.text ?? ''
if (counter < 2 && (text.match(/\n/) || []).length) {
return
}
const queue = encoder.encode(`${JSON.stringify(text)}\n`)
controller.enqueue(queue)
counter++
} catch (e) {
controller.error(e)
}
}
}
const parser = createParser(onParse)
// [Асинхронно перебираем](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for-await...of) тело ответа
for await (const chunk of res.body as any) {
parser.feed(decoder.decode(chunk))
}
}
})
return stream
}Полный пример можно найти в этом репозитории.
Прим. пер.: далее речь идет об основанных на веб-потоках возможностях, предоставляемых Vercel. Если вы не планируете пользоваться этой платформой, можете закончить чтение статьи на этом месте.
Потоковая передача данных в Vercel
Vercel поддерживает веб-потоки как в граничной (edge), так и в бессерверной (serverless) средах выполнения, что позволяет эффективно обрабатывать данные в реальном времени. Это позволяет "стримить" данные в формате JSON клиенту или даже прогрессивно рендерить части UI (user interface — пользовательский интерфейс).
export const config = {
runtime: "edge",
};
const delay = (ms) => new Promise((res) => setTimeout(res, ms));
export default async function handler() {
const encoder = new TextEncoder();
const readable = new ReadableStream({
async start(controller) {
controller.enqueue(encoder.encode("<html><body>"));
await delay(500);
controller.enqueue(encoder.encode("<ul><li>List Item 1</li>"));
await delay(500);
controller.enqueue(encoder.encode("<li>List Item 2</li>"));
await delay(500);
controller.enqueue(encoder.encode("<li>List Item 3</li></ul>"));
await delay(500);
controller.enqueue(encoder.encode("</body></html>"));
controller.close();
},
});
return new Response(readable, {
headers: { "Content-Type": "text/html; charset=utf-8" },
});
}Прогрессивный рендеринг может быть использован для улучшения опыта пользователей с медленным соединением. Тот же принцип применим в отношении данных JSON, когда мы хотим отправлять части большого набора данных по мере их готовности.
Vercel AI SDK
Построение UI вокруг данных LLM (large language model — большая языковая модель) стало очень популярным на фоне роста популярности провайдеров ИИ. Стриминг ответов LLM привел к важным изменениям в подходах к разработке приложений.
Решение об использовании потоковой передачи данных зависит от таких факторов, как размер языковой модели, скорость и длина ответа. Большие модели могут генерировать сложные ответы, но медленно отвечать из-за сложных вычислений. Маленькие модели отвечают быстро, но их ответы гораздо проще, чего может быть недостаточно для удовлетворения потребностей приложения.
Vercel AI SDK помогает минимизировать количество шаблонного кода, необходимого для обработки потоковых ответов, облегчая получение и рендеринг таких ответов:
import { OpenAIStream, StreamingTextResponse } from 'ai'
export const runtime = 'edge'
export async function POST(req: Request) {
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
stream: true,
messages: [...]
})
// Преобразуем ответ в дружелюбный текстовый поток
const stream = OpenAIStream(response)
// Отвечает потоком
return new StreamingTextResponse(stream)
}Эти потоковые ответы могут потребляться хуками useChat и useCompletion:
'use client'
import { useChat } from 'ai'
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat()
return ...
}Заключение
Веб-потоки сильно меняют подход к обработке данных в веб-приложениях. Они предоставляют мощный, эффективный и стандартизированный способ асинхронной обработки большого количества данных.
Возможности автоматической обработки обратного давления и доставки данных по частям могут существенно повысить производительности приложения. Преобразование данных в процессе передачи открывает целый спектр возможностей по обработке и манипуляции данными.
MarineEngineer
Спасибо за статью. Наконец-то я узнал, как у меня мемесы на 9gag появляются в единой ленте.
И может я не внимательно читал статью, но как определяется минимальный/максимальный объем чанка?
Eugeny1987
описание есть под заголовком Чанки