
Data science, машинное обучение и искусственный интеллект — не просто громкие слова: многие организации стремятся их освоить. Но прежде чем создавать интеллектуальные продукты, необходимо собрать и подготовить данные, которые станут топливом для ИИ. Фундамент для аналитических проектов закладывает специальная дисциплина — data engineering. Связанные с ней задачи занимают первые три слоя иерархии потребностей data science, предложенной Моникой Рогати.
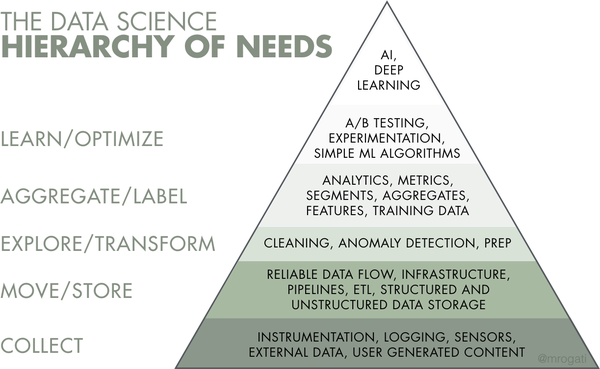
Слои data science для реализации ИИ.
В этой статье мы рассмотрим процесс data engineering, расскажем о его базовых компонентах и инструментах, опишем роль дата-инженера.
Data engineering — это набор операций, позволяющий сделать данные доступными и применимыми для дата-саентистов, аналитиков данных, разработчиков business intelligence (BI) и других специалистов организации. Для проектирования и создания систем крупномасштабного сбора и хранения данных, а также их для подготовки к дальнейшему анализу требуются специалисты.
В большой организации обычно есть множество разных типов ПО управления операциями (например, ERP, CRM, продакшен-системы и так далее), и все они содержат базы данных с различной информацией. Кроме того, данные могут храниться как отдельные файлы или в реальном времени подтягиваться из внешних источников (например, IoT-устройств). Из-за того, что данные хранятся во множестве разных форматов, организация не может получить чёткую картину состояния бизнеса и текущей аналитики.
Data engineering пошагово решает эту проблему.
Процесс data engineering заключается в выполнении последовательности задач, превращающих большой объём сырых данных в практичный продукт, отвечающий потребностям аналитиков, дата-саентистов, инженеров машинного обучения и других специалистов. Обычно весь процесс состоит из следующих этапов.

Упрощённая структура процесса data engineering.
При потреблении данных (Data ingestion) они перемещаются из множества разных источников — баз данных SQL и NoSQL, IoT-устройств, веб-сайтов, потоковых сервисов и так далее — в целевую систему с целью преобразования для дальнейшего анализа. Данные поступают в различных видах и могут быть как структурированными, так и неструктурированными.
При преобразовании данных (Data transformation) разобщённые данные подстраиваются под потребности конечных пользователей. Этот этап включает в себя устранение ошибок и дублированных данных, их нормализацию и преобразование в нужный формат.
Передача данных (Data serving) доставляет преобразованные данные конечным пользователям — платформе BI, в дэшборд или команде data science.
Оркестрация потоков данных (Data flow orchestration) обеспечивает наблюдаемость (visibility) процесса data engineering, гарантируя успешное выполнение всех задач. Оно координирует и непрерывно отслеживает процессы обработки данных для выявления и устранения проблем с качеством данных и точностью.
Механизм, автоматизирующий этапы потребления, преобразования и передачи процесса data engineering, называется конвейером данных (data pipeline).
Конвейер данных сочетает в себе инструменты и операции, перемещающие данные из одной системы в другую для хранения и дальнейшей обработки. Создание и поддержка конвейеров данных является основной задачей дата-инженеров. Среди прочего, они пишут скрипты для автоматизации повторяющихся задач — job.
Обычно конвейеры используются для:
Подробности можно узнать из нашего поста Data Pipeline: Components, Types, and Use Cases. Ниже мы вкратце расскажем о распространённых типах конвейеров данных.
Конвейер ETL (Extract, Transform, Load) — это самая распространённая архитектура, которая используется уже десятки лет. Часто она реализуется специалистом — разработчиком ETL.
Как понятно из названия, конвейер ETL автоматизирует следующие процессы.

Операции ETL.
После преобразования и загрузки данных в централизованный репозиторий их можно использовать для дальнейшего анализа и операций business intelligence, например, для генерации отчётов, создания визуализаций и так далее. Конвейеры ETL реализует специалист в этой сфере.
Конвейер ELT выполняет те же этапы, но в другом порядке — Extract, Load, Transform. Вместо преобразования всех собранных данных они помещаются в хранилище данных, озеро данных или в data lakehouse. Позже их можно частично или полностью обработать и отформатировать, один или множество раз.

Операции ELT.
Конвейеры ELT предпочтительны, когда нужно потребить как можно больше данных, а преобразовывать их позже, в зависимости от возникающих потребностей. В отличие от ETL, архитектура ELT не требует заранее выбирать типы и форматы данных. В крупномасштабных проектах эти два типа конвейеров данных часто комбинируются, чтобы обеспечить возможность как традиционной аналитики, так и аналитики в реальном времени. Кроме того, эти две архитектуры можно использовать для поддержки аналитики Big Data.
Подробнее эта тема раскрыта в данной статье.
Создание безопасного и надёжного потока данных — сложная задача. При передаче данных многое может пойти не так: данные могут повреждаться, создавать узкие места, приводя к задержкам, могут возникать конфликты источников данных, генерация дублирующихся или некорректных данных. Передача данных в одно хранилище требует тщательного планирования и тестирования для фильтрации мусорных данных, устранения дубликатов и несовместимых типов данных, чтобы обфусцировать уязвимые данные без утери критически важных данных.
Опытный практик в сфере обработки данных Хуан де Диос Сантос выделяет две основных опасности при создании конвейеров данных:
«Важность надёжной и релевантной системы метрик заключается в том, что она информирует нас о состоянии и характеристиках каждого этапа конвейера; под недооценкой уровня нагрузки данных я подразумеваю то, что необходимо создавать систему таким образом, чтобы она не испытывала перегрузок в случае, если продукт сталкивается с неожиданным всплеском количества пользователей», — объясняет Хуан.
Наряду с конвейером необходимо создать хранилище данных, поддерживающее и упрощающее операции data science. Давайте рассмотрим, как оно работает.
Хранилище данных (data warehouse, DW) — это центральный репозиторий, хранящий данные в форматах, которые можно запрашивать. С технической точки зрения, хранилище данных — это реляционная база данных, оптимизированная под чтение, агрегирование и запросы больших объёмов данных. Традиционно DW содержали только структурированные данные или данные, которые можно упорядочить в таблицы. Однако современные DW также могут поддерживать неструктурированные данные (например, изображения, файлы PDF и аудиоформаты).
Без DW дата-саентистам пришлось бы получать данные напрямую из базы данных в продакшене, что могло бы приводить к различающимся ответам на один вопрос, задержкам или даже аварийным ситуациям. Хранилище данных, используемое в качестве единственного источника истины в компании, упрощает отчётность и анализ, принятие решений и прогнозирование метрик.
Как ни странно, DW не является обычной базой данных. Как же это возможно?
Во-первых, они различаются с точки зрения структуры данных. Типичная база данных нормализует данные, исключая любую избыточность данных и выделяя связанные данные в таблицы. Это требует больших вычислительных ресурсов, потому что один запрос комбинирует данные из множества таблиц. DW наоборот использует простые запросы с ограниченным количеством таблиц для повышения производительности и улучшения аналитики.
Во-вторых, стандартные транзакционные базы данных, нацеленные на повседневные транзакции, обычно не хранят исторические данные, а для хранилищ данных это является основной задачей, потому что они собирают данные из разных периодов. DW упрощает работу аналитика данных, что позволяет управлять данными из единого интерфейса, получая аналитику, визуализации и статистику.
Обычно хранилище данных, в отличие от базы данных, не поддерживает большое количество одновременных пользователей, потому что предназначено для маленькой группы аналитиков и руководителей.

Архитектура данных в хранилище данных
Для создания хранилища данных комбинируются четыре неотъемлемых компонента.
Накопитель хранилища данных. Фундамент архитектуры хранилища данных — это база данных, хранящая все корпоративные данные и позволяющая бизнес-пользователям получать доступ к ней и делать важные выводы.
Архитекторы данных обычно выбирают между хранилищем данных на мощностях компании или в облаке с учётом того, какие преимущества бизнес получит от того или иного решения. Хотя облачная среда более экономически эффективна, проста в масштабировании и ограничена заданной ей структурой, она может проигрывать решениям, созданным на внутренних мощностях компании, с точки зрения скорости обработки запросов и безопасности. Ниже мы перечислим самые популярные инструменты.
Архитектор данных также может спроектировать коллективный накопитель для хранилища данных — множество параллельно работающих баз данных. Это повысит масштабируемость хранилища.
Метаданные. Добавляющие данным бизнес-контекста метаданные помогают преобразовывать их в всеобъемлющие знания. Метаданные определяют способы изменения и обработки данных. Они содержат информацию о всех преобразованиях или операциях, применяемых к исходным данным при их загрузке в хранилище данных.
Инструменты доступа к хранилищу данных. Функциональность этих инструментов может быть разной. Например, инструменты запросов и отчётности используются для генерации отчётов бизнес-анализа. А инструменты дата-майнинга автоматизируют поиск паттернов и корреляций в огромных объёмах данных на основании сложных методик статистического моделирования.
Инструменты управления хранилищем данных. Хранилище данных используется всей компанией и имеет дело со множеством операций управления и администрирования. Для выполнения таких операций используются специализированные инструменты управления хранилищем данных.
Более подробную информацию можно узнать из нашего поста.
Хранилища данных стали большим шагом для улучшения архитектуры данных. Однако если у вас есть сотни пользователей из разных отделов, управление DW может быть слишком медленным и неудобным. В таком случае можно создать витрины данных (data mart), повышающие скорость и эффективность.
Витрина данных — это хранилище данных меньшего размера (обычно они занимают не больше 100 ГБ). Они становятся необходимы с ростом компании и объёмов данных, когда поиск в корпоративной DW оказывается слишком долгим и неэффективным. Витрины данных создаются, чтобы позволить различным отделам (например, продаж или маркетинга) быстро и просто получать релевантную информацию.

Место витрин данных в инфраструктуре данных.
Существует три основных типа витрин данных.
Зависимые витрины данных (dependent data mart) создаются из корпоративной DW и используются как первичный источник информации (это называется «методикой сверху вниз»).
Независимые витрины данных (independent data mart) это автономные системы, работающие без DW и извлекающие информацию из различных внешних и внутренних источников (это называется «методикой снизу вверх»).
Гибридные витрины данных комбинируют информацию и из DW, и из других рабочих систем.
Основное различие между хранилищем и витриной данных заключается в том, что DW — это большой репозиторий. хранящий в себе все данные компании, извлечённые из множества источников; это усложняет обработку запросов и управление ими. Витрина данных — это репозиторий меньшего размера, содержащий ограниченный объём данных для конкретной бизнес-группы или отдела.
Хотя витрины данных позволяют бизнес-пользователям быстро получать доступ к запрашиваемым данным, часто простого получения информации недостаточно. Она должна быть эффективно обработана и проанализирована, чтобы сделать из неё выводы, на которые опираются для принятия решений. Посмотреть на данные с разных точек зрения можно с помощью OLAP-кубов. Давайте разберёмся, что это такое.
OLAP, или Online Analytical Processing — это методика обработки информации, позволяющая пользователям анализировать многомерные данные. Она отличается от OLTP, или Online Transactional Processing — упрощённой методики взаимодействия с базами данных, не предназначенной для анализа огромных объёмов данных с разных точек зрения.
Традиционные базы данных напоминают электронные таблицы, они используют двухмерную структуру из строк и столбцов. В отличие от них, в OLAP датасеты представлены в многомерных структурах — OLAP-кубах. Такие структуры обеспечивают эффективную обработку и сложный анализ огромных объёмов разнообразных данных. Например, отчёт для отдела продаж может включать в себя такие размерности, как товар, регион, торгового представителя, объём продаж, месяц и так далее.
Информация из DW агрегируется и загружается в OLAP-куб, где происходит её предварительная обработка, и она становится доступной для пользовательских запросов.

Анализ данных при помощи OLAP-кубов.
Внутри OLAP данные могут анализироваться с разных точек зрения. Например, их можно опускать/поднимать, если необходимо изменить уровень иерархии представления данных и получить более или менее подробную картину. Также можно нарезать информацию для сегментирования датасета как отдельной электронной таблицы или преобразовать его для создания другого куба. Эти и другие методики позволяют находить паттерны в разнообразных данных и создавать всевозможные отчёты.
Важно отметить, что OLAP-кубы необходимо специально создавать под каждый отчёт или аналитический запрос. Однако их применение оправдано, потому что, как мы сказали, они упрощают процесс сложного многомерного анализа.
Более подробное объяснение можно прочитать в нашей статье What is OLAP: A Complete Guide to Online Analytical Processing.
Говоря о data engineering, мы не можем не упомянуть Big Data, отличительными особенностями которых являются объём, скорость поступления, разнообразие и достоверность; обычно они используются в крупных технологических компаниях наподобие YouTube, Amazon или Instagram. Big Data engineering — это процесс создания огромных резервуаров и распределённых систем с высокой масштабируемостью и устойчивостью к сбоям.
Архитектура работы с Big data отличается от традиционной обработки данных, потому что в этом случае мы говорим о таких огромных объёмах стремительно изменяющихся информационных потоков, которые не могут уместить в себе хранилища данных. И здесь нам на помощь приходит озеро данных.
Озеро данных (data lake) — это огромный резервуар для хранения данных в их исходном, необработанном виде. Озеро выделяется своей высокой гибкостью, так как не ограничено фиксированной конфигурацией хранилища данных.

Архитектура Big data с озером данных
В озере данных используется методика ELT, а данные начинают загружаться сразу после извлечения с обработкой сырых и часто неструктурированных данных.
Озеро данных стоит создавать в таких проектах, которые будут масштабироваться и потребуют более сложной архитектуры. Кроме того, оно очень удобно, когда предназначение данных пока не определено. В таком случае можно сохранять данные быстро, хранить их и изменять по необходимости.
Кроме того, озёра данных — это мощный инструмент дата-саентистов и инженеров машинного обучения, использующих сырые данные для их подготовки к предсказательной аналитике и машинному обучению. Подробнее о подготовке данных можно прочитать в нашей статье.
Озёра создаются в крупных распределённых кластерах, способных хранить и обрабатывать большие объёмы данных. Известный пример такой платформы озёр данных — это Hadoop.
Hadoop — это крупномасштабный фреймворк обработки данных на основе Java, способный анализировать огромные датасеты. Эта платформа упрощает распределение задач анализа данных по разным серверам и их параллельное выполнение. Она состоит из трёх компонентов:
Также для Hadoop существует огромная экосистема опенсорсных инструментов, расширяющих его возможности и позволяющих решать различные задачи, связанные с Big Data.

Эволюция экосистемы Hadoop.
Вот некоторые из самых популярных инструментов из экосистемы Hadoop:
О преимуществах и недостатках Hadoop можно прочитать в нашей статье The Good and the Bad of Hadoop Big Data Framework.
Инструменты для потоковой аналитики образуют важную группу в экосистеме Hadoop. Она включает в себя следующее:
Все эти технологии используются для создания конвейеров Big Data реального времени. Подробнее о них можно узнать из наших статей Hadoop vs Spark: Main Big Data Tools Explained и The Good and the Bad of Apache Kafka Streaming Platform.
Если конвейером big data управляют неправильно, то озёра данных быстро превращаются в болота данных — набор разнообразных данных, которыми нельзя ни управлять, ни пользоваться. Для решения этой проблемы была создана новая методика интеграции данных.
Корпоративные концентраторы данных (Enterprise data hub, EDH) — это новое поколение архитектуры данных, нацеленное на обмен управляемыми данными между системами. Они соединяют множество источников информации, в том числе DW и озёра данных. В отличие от DW, концентратор данных поддерживает все типы данных и с лёгкостью интегрирует системы. Кроме того, его можно развернуть за недели или даже дни, в то время как развёртывание DW может длиться месяцы или даже годы.
Кроме того, концентраторы данных имеют дополнительные возможности управления данными, их гармонизации, исследования и анализа, чего недостаёт озёрам данных. Они проектируются под потребности конкретного бизнеса и его наиболее актуальные нужды.
Подведём итог:
EDH можно интегрировать с DW и/или озером данных, чтобы упростить обработку данных и решать повседневные проблемы этих архитектур. Подробнее об этом можно прочитать в нашей статье What is Data Hub: Purpose, Architecture Patterns, and Existing Solutions Overview.
Теперь, когда мы знаем, чем занимается data engineering, давайте исследуем профессию, которая специализируется в создании программных решений, связанных с big data – дата-инженер.
Хуан де Диос Сантос, сам работающий дата-инженером, формулирует эту профессию следующим образом: «В многодисциплинарной команде, включающей в себя дата-саентистов, инженеров BI и дата-инженеров, задача дата-инженера по большей мере заключается в обеспечении качества и доступности данных». Также он утверждает, что дата-инженер может взаимодействовать с другими специалистами при реализации или проектировании связанной с данными функции (или продукта), например, A/B-теста, развёртывания модели машинного обучения и совершенствовании имеющегося источника данных.
Data engineering расположен на пересечении проектирования ПО и data science, что приводит к необходимости пересечения навыков.

Пересечение навыков разработчика ПО, дата-инженера и дата-саентиста.
Опыт разработки ПО. Дата-инженеры при помощи языков программирования обеспечивают надёжный и удобный доступ к данным и базам данных. По словам Хуана де Диос Сантоса, они должны уметь работать с полным циклом разработки ПО, в том числе формировать идеи, проектировать архитектуру, прототипировать, тестировать, развёртывать, заниматься DevOps, задавать метрики и выполнять мониторинг систем. Дата-инженеры — опытные разработчики как минимум на на Python или Scala/Java.
Навыки, связанные с данными. «Дата-инженер должен обладать знаниями множества разновидностей баз данных (SQL и NoSQL), платформ данных, концепций наподобие MapReduce, пакетной и потоковой обработки и даже части самой фундаментальной теории данных, то есть типов данных и описательной статистики», — подчёркивает Хуан.
Навыки создания систем. У дата-инженеров должен быть опыт работы с различными технологиями и фреймворками хранения данных, которые они могут комбинировать для создания конвейеров данных.
Дата-инженер должен обладать глубоким пониманием множества технологий работы с данными, чтобы иметь возможность подбирать подходящие для конкретной работы.
Airflow. Эта система управления рабочими процессами на основе Python разработана Airbnb для изменения архитектуры её конвейеров данных. Мигрировав на Airflow, компания снизила время работы своего experimentation reporting framework (ERF) с более чем 24 часов до 45 минут. Среди плюсов Airflow Хуан отмечает его операторы: «Они позволяют нам исполнять команды bash, выполнять SQL-запросы и даже отправлять электронные письма». Также Хуан подчёркивает возможность Airflow отправлять уведомления в Slack, его завершённый и богатый UI и совершенство проекта в целом. С другой стороны, Хуану не нравится, что Airflow позволяет писать задачи только на Python.
Чтобы узнать подробности, прочитайте нашу статью The Good and the Bad of Apache Airflow Pipeline Orchestration.
Cloud Dataflow. Облачный сервис обработки данных Dataflow нацелен на потребление больших объёмов данных и обработку с низкими задержками благодаря быстрому параллельному исполнению конвейеров аналитики. Dataflow имеет преимущество перед Airflow, поскольку поддерживает несколько языков, в том числе Java, Python, SQL и движки наподобие Flink и Spark. Также его хорошо поддерживает Google Cloud. Однако де Диос Сантос предупреждает, что недостатком Dataflow могут быть высокие затраты.
Среди прочих популярных инструментов можно упомянуть платформу Stitch для быстрого перемещения данных и Blendo — инструмент для синхронизации различных источников данных с хранилищем данных.
Решения для создания хранилищ. Для хранилищ данных, создаваемых внутри компаний, широко применяются Teradata Data Warehouse, SAP Data Warehouse, IBM db2 и Oracle Exadata. Самые популярные облачные решения для хранилищ данных — это Amazon Redshift и Google BigQuery.
Инструменты Big data. Дата-инженер должен освоить следующие технологии (или хотя бы знать о них): Hadoop и его экосистема, Elastic Stack для сквозной аналитики big data, озёра данных.
Дата-инженеров часто путают с дата-саентистами. Мы попросили дата-саентиста с более чем десятилетним опытом Александра Кондуфорова рассказать о разнице между этими профессиями.
«И дата-саентисты, и дата-инженеры работают с данными, но решают достаточно разные задачи, имеют разные навыки и используют разные инструменты», — объясняет Александр. «Дата-инженеры создают и поддерживают крупные хранилища данных, применяют свои навыки проектирования: языки программирования, методики ETL, знания различных хранилищ данных и языков баз данных. Дата-саентисты очищают и анализируют эти данные, делают из них важные выводы, внедряют модели для прогнозирования и предиктивной аналитики, и по большей мере применяют свои математические и алгоритмические навыки, алгоритмы и инструменты машинного обучения».
Александр подчёркивает, что доступ к данным может по множеству причин стать для дата-саентистов сложной задачей.
Как мы видим, при работе с созданными и поддерживаемыми дата-инженерами системами хранения дата-саентисты становятся их «внутренними клиентами». Здесь и происходит их совместная работа.
Слои data science для реализации ИИ.
В этой статье мы рассмотрим процесс data engineering, расскажем о его базовых компонентах и инструментах, опишем роль дата-инженера.
Что такое data engineering?
Data engineering — это набор операций, позволяющий сделать данные доступными и применимыми для дата-саентистов, аналитиков данных, разработчиков business intelligence (BI) и других специалистов организации. Для проектирования и создания систем крупномасштабного сбора и хранения данных, а также их для подготовки к дальнейшему анализу требуются специалисты.
В большой организации обычно есть множество разных типов ПО управления операциями (например, ERP, CRM, продакшен-системы и так далее), и все они содержат базы данных с различной информацией. Кроме того, данные могут храниться как отдельные файлы или в реальном времени подтягиваться из внешних источников (например, IoT-устройств). Из-за того, что данные хранятся во множестве разных форматов, организация не может получить чёткую картину состояния бизнеса и текущей аналитики.
Data engineering пошагово решает эту проблему.
Процесс data engineering
Процесс data engineering заключается в выполнении последовательности задач, превращающих большой объём сырых данных в практичный продукт, отвечающий потребностям аналитиков, дата-саентистов, инженеров машинного обучения и других специалистов. Обычно весь процесс состоит из следующих этапов.
Упрощённая структура процесса data engineering.
При потреблении данных (Data ingestion) они перемещаются из множества разных источников — баз данных SQL и NoSQL, IoT-устройств, веб-сайтов, потоковых сервисов и так далее — в целевую систему с целью преобразования для дальнейшего анализа. Данные поступают в различных видах и могут быть как структурированными, так и неструктурированными.
При преобразовании данных (Data transformation) разобщённые данные подстраиваются под потребности конечных пользователей. Этот этап включает в себя устранение ошибок и дублированных данных, их нормализацию и преобразование в нужный формат.
Передача данных (Data serving) доставляет преобразованные данные конечным пользователям — платформе BI, в дэшборд или команде data science.
Оркестрация потоков данных (Data flow orchestration) обеспечивает наблюдаемость (visibility) процесса data engineering, гарантируя успешное выполнение всех задач. Оно координирует и непрерывно отслеживает процессы обработки данных для выявления и устранения проблем с качеством данных и точностью.
Механизм, автоматизирующий этапы потребления, преобразования и передачи процесса data engineering, называется конвейером данных (data pipeline).
Конвейер data engineering
Конвейер данных сочетает в себе инструменты и операции, перемещающие данные из одной системы в другую для хранения и дальнейшей обработки. Создание и поддержка конвейеров данных является основной задачей дата-инженеров. Среди прочего, они пишут скрипты для автоматизации повторяющихся задач — job.
Обычно конвейеры используются для:
- миграции данных между системами или средами (из внутренних систем компании в облачные базы данных);
- обработки данных или преобразования сырых данных в формат, применимый в аналитике, BI и проектов машинного обучения;
- интеграции данных из различных систем и IoT-устройств
- копирования таблиц из одной базы данных в другие.
Подробности можно узнать из нашего поста Data Pipeline: Components, Types, and Use Cases. Ниже мы вкратце расскажем о распространённых типах конвейеров данных.
Конвейер ETL
Конвейер ETL (Extract, Transform, Load) — это самая распространённая архитектура, которая используется уже десятки лет. Часто она реализуется специалистом — разработчиком ETL.
Как понятно из названия, конвейер ETL автоматизирует следующие процессы.
- Extract — извлечение данных. В начале конвейера мы имеем дело с сырыми данными из множества источников — баз данных, API, файлов и так далее.
- Transform — стандартизация данных. После извлечения данных скрипты преобразуют их для соответствия требованиям к формату. Преобразование данных существенно повышает удобство изучения данных и их использования.
- Load — сохранение данных в новое место. После преобразования данных в применимый формат инженеры могут загрузить их в целевое хранилище; обычно это система управления базами данных (СУБД) или хранилище данных (data warehouse).
Операции ETL.
После преобразования и загрузки данных в централизованный репозиторий их можно использовать для дальнейшего анализа и операций business intelligence, например, для генерации отчётов, создания визуализаций и так далее. Конвейеры ETL реализует специалист в этой сфере.
Конвейер ELT
Конвейер ELT выполняет те же этапы, но в другом порядке — Extract, Load, Transform. Вместо преобразования всех собранных данных они помещаются в хранилище данных, озеро данных или в data lakehouse. Позже их можно частично или полностью обработать и отформатировать, один или множество раз.
Операции ELT.
Конвейеры ELT предпочтительны, когда нужно потребить как можно больше данных, а преобразовывать их позже, в зависимости от возникающих потребностей. В отличие от ETL, архитектура ELT не требует заранее выбирать типы и форматы данных. В крупномасштабных проектах эти два типа конвейеров данных часто комбинируются, чтобы обеспечить возможность как традиционной аналитики, так и аналитики в реальном времени. Кроме того, эти две архитектуры можно использовать для поддержки аналитики Big Data.
Подробнее эта тема раскрыта в данной статье.
Сложности работы с конвейерами данных
Создание безопасного и надёжного потока данных — сложная задача. При передаче данных многое может пойти не так: данные могут повреждаться, создавать узкие места, приводя к задержкам, могут возникать конфликты источников данных, генерация дублирующихся или некорректных данных. Передача данных в одно хранилище требует тщательного планирования и тестирования для фильтрации мусорных данных, устранения дубликатов и несовместимых типов данных, чтобы обфусцировать уязвимые данные без утери критически важных данных.
Опытный практик в сфере обработки данных Хуан де Диос Сантос выделяет две основных опасности при создании конвейеров данных:
- отсутствие релевантных метрик
- недооценка уровня нагрузки данных
«Важность надёжной и релевантной системы метрик заключается в том, что она информирует нас о состоянии и характеристиках каждого этапа конвейера; под недооценкой уровня нагрузки данных я подразумеваю то, что необходимо создавать систему таким образом, чтобы она не испытывала перегрузок в случае, если продукт сталкивается с неожиданным всплеском количества пользователей», — объясняет Хуан.
Наряду с конвейером необходимо создать хранилище данных, поддерживающее и упрощающее операции data science. Давайте рассмотрим, как оно работает.
Хранилище данных
Хранилище данных (data warehouse, DW) — это центральный репозиторий, хранящий данные в форматах, которые можно запрашивать. С технической точки зрения, хранилище данных — это реляционная база данных, оптимизированная под чтение, агрегирование и запросы больших объёмов данных. Традиционно DW содержали только структурированные данные или данные, которые можно упорядочить в таблицы. Однако современные DW также могут поддерживать неструктурированные данные (например, изображения, файлы PDF и аудиоформаты).
Без DW дата-саентистам пришлось бы получать данные напрямую из базы данных в продакшене, что могло бы приводить к различающимся ответам на один вопрос, задержкам или даже аварийным ситуациям. Хранилище данных, используемое в качестве единственного источника истины в компании, упрощает отчётность и анализ, принятие решений и прогнозирование метрик.
Как ни странно, DW не является обычной базой данных. Как же это возможно?
Во-первых, они различаются с точки зрения структуры данных. Типичная база данных нормализует данные, исключая любую избыточность данных и выделяя связанные данные в таблицы. Это требует больших вычислительных ресурсов, потому что один запрос комбинирует данные из множества таблиц. DW наоборот использует простые запросы с ограниченным количеством таблиц для повышения производительности и улучшения аналитики.
Во-вторых, стандартные транзакционные базы данных, нацеленные на повседневные транзакции, обычно не хранят исторические данные, а для хранилищ данных это является основной задачей, потому что они собирают данные из разных периодов. DW упрощает работу аналитика данных, что позволяет управлять данными из единого интерфейса, получая аналитику, визуализации и статистику.
Обычно хранилище данных, в отличие от базы данных, не поддерживает большое количество одновременных пользователей, потому что предназначено для маленькой группы аналитиков и руководителей.
Архитектура данных в хранилище данных
Для создания хранилища данных комбинируются четыре неотъемлемых компонента.
Накопитель хранилища данных. Фундамент архитектуры хранилища данных — это база данных, хранящая все корпоративные данные и позволяющая бизнес-пользователям получать доступ к ней и делать важные выводы.
Архитекторы данных обычно выбирают между хранилищем данных на мощностях компании или в облаке с учётом того, какие преимущества бизнес получит от того или иного решения. Хотя облачная среда более экономически эффективна, проста в масштабировании и ограничена заданной ей структурой, она может проигрывать решениям, созданным на внутренних мощностях компании, с точки зрения скорости обработки запросов и безопасности. Ниже мы перечислим самые популярные инструменты.
Архитектор данных также может спроектировать коллективный накопитель для хранилища данных — множество параллельно работающих баз данных. Это повысит масштабируемость хранилища.
Метаданные. Добавляющие данным бизнес-контекста метаданные помогают преобразовывать их в всеобъемлющие знания. Метаданные определяют способы изменения и обработки данных. Они содержат информацию о всех преобразованиях или операциях, применяемых к исходным данным при их загрузке в хранилище данных.
Инструменты доступа к хранилищу данных. Функциональность этих инструментов может быть разной. Например, инструменты запросов и отчётности используются для генерации отчётов бизнес-анализа. А инструменты дата-майнинга автоматизируют поиск паттернов и корреляций в огромных объёмах данных на основании сложных методик статистического моделирования.
Инструменты управления хранилищем данных. Хранилище данных используется всей компанией и имеет дело со множеством операций управления и администрирования. Для выполнения таких операций используются специализированные инструменты управления хранилищем данных.
Более подробную информацию можно узнать из нашего поста.
Хранилища данных стали большим шагом для улучшения архитектуры данных. Однако если у вас есть сотни пользователей из разных отделов, управление DW может быть слишком медленным и неудобным. В таком случае можно создать витрины данных (data mart), повышающие скорость и эффективность.
Витрины данных
Витрина данных — это хранилище данных меньшего размера (обычно они занимают не больше 100 ГБ). Они становятся необходимы с ростом компании и объёмов данных, когда поиск в корпоративной DW оказывается слишком долгим и неэффективным. Витрины данных создаются, чтобы позволить различным отделам (например, продаж или маркетинга) быстро и просто получать релевантную информацию.
Место витрин данных в инфраструктуре данных.
Существует три основных типа витрин данных.
Зависимые витрины данных (dependent data mart) создаются из корпоративной DW и используются как первичный источник информации (это называется «методикой сверху вниз»).
Независимые витрины данных (independent data mart) это автономные системы, работающие без DW и извлекающие информацию из различных внешних и внутренних источников (это называется «методикой снизу вверх»).
Гибридные витрины данных комбинируют информацию и из DW, и из других рабочих систем.
Основное различие между хранилищем и витриной данных заключается в том, что DW — это большой репозиторий. хранящий в себе все данные компании, извлечённые из множества источников; это усложняет обработку запросов и управление ими. Витрина данных — это репозиторий меньшего размера, содержащий ограниченный объём данных для конкретной бизнес-группы или отдела.
Хотя витрины данных позволяют бизнес-пользователям быстро получать доступ к запрашиваемым данным, часто простого получения информации недостаточно. Она должна быть эффективно обработана и проанализирована, чтобы сделать из неё выводы, на которые опираются для принятия решений. Посмотреть на данные с разных точек зрения можно с помощью OLAP-кубов. Давайте разберёмся, что это такое.
OLAP и OLAP-кубы
OLAP, или Online Analytical Processing — это методика обработки информации, позволяющая пользователям анализировать многомерные данные. Она отличается от OLTP, или Online Transactional Processing — упрощённой методики взаимодействия с базами данных, не предназначенной для анализа огромных объёмов данных с разных точек зрения.
Традиционные базы данных напоминают электронные таблицы, они используют двухмерную структуру из строк и столбцов. В отличие от них, в OLAP датасеты представлены в многомерных структурах — OLAP-кубах. Такие структуры обеспечивают эффективную обработку и сложный анализ огромных объёмов разнообразных данных. Например, отчёт для отдела продаж может включать в себя такие размерности, как товар, регион, торгового представителя, объём продаж, месяц и так далее.
Информация из DW агрегируется и загружается в OLAP-куб, где происходит её предварительная обработка, и она становится доступной для пользовательских запросов.
Анализ данных при помощи OLAP-кубов.
Внутри OLAP данные могут анализироваться с разных точек зрения. Например, их можно опускать/поднимать, если необходимо изменить уровень иерархии представления данных и получить более или менее подробную картину. Также можно нарезать информацию для сегментирования датасета как отдельной электронной таблицы или преобразовать его для создания другого куба. Эти и другие методики позволяют находить паттерны в разнообразных данных и создавать всевозможные отчёты.
Важно отметить, что OLAP-кубы необходимо специально создавать под каждый отчёт или аналитический запрос. Однако их применение оправдано, потому что, как мы сказали, они упрощают процесс сложного многомерного анализа.
Более подробное объяснение можно прочитать в нашей статье What is OLAP: A Complete Guide to Online Analytical Processing.
Big Data engineering
Говоря о data engineering, мы не можем не упомянуть Big Data, отличительными особенностями которых являются объём, скорость поступления, разнообразие и достоверность; обычно они используются в крупных технологических компаниях наподобие YouTube, Amazon или Instagram. Big Data engineering — это процесс создания огромных резервуаров и распределённых систем с высокой масштабируемостью и устойчивостью к сбоям.
Архитектура работы с Big data отличается от традиционной обработки данных, потому что в этом случае мы говорим о таких огромных объёмах стремительно изменяющихся информационных потоков, которые не могут уместить в себе хранилища данных. И здесь нам на помощь приходит озеро данных.
Озеро данных
Озеро данных (data lake) — это огромный резервуар для хранения данных в их исходном, необработанном виде. Озеро выделяется своей высокой гибкостью, так как не ограничено фиксированной конфигурацией хранилища данных.
Архитектура Big data с озером данных
В озере данных используется методика ELT, а данные начинают загружаться сразу после извлечения с обработкой сырых и часто неструктурированных данных.
Озеро данных стоит создавать в таких проектах, которые будут масштабироваться и потребуют более сложной архитектуры. Кроме того, оно очень удобно, когда предназначение данных пока не определено. В таком случае можно сохранять данные быстро, хранить их и изменять по необходимости.
Кроме того, озёра данных — это мощный инструмент дата-саентистов и инженеров машинного обучения, использующих сырые данные для их подготовки к предсказательной аналитике и машинному обучению. Подробнее о подготовке данных можно прочитать в нашей статье.
Озёра создаются в крупных распределённых кластерах, способных хранить и обрабатывать большие объёмы данных. Известный пример такой платформы озёр данных — это Hadoop.
Hadoop и его экосистема
Hadoop — это крупномасштабный фреймворк обработки данных на основе Java, способный анализировать огромные датасеты. Эта платформа упрощает распределение задач анализа данных по разным серверам и их параллельное выполнение. Она состоит из трёх компонентов:
- Hadoop Distributed File System (HDFS), способная хранить Big Data,
- движок обработки MapReduce и
- менеджер ресурсов YARN для управления рабочими нагрузками и их мониторинга.
Также для Hadoop существует огромная экосистема опенсорсных инструментов, расширяющих его возможности и позволяющих решать различные задачи, связанные с Big Data.
Эволюция экосистемы Hadoop.
Вот некоторые из самых популярных инструментов из экосистемы Hadoop:
- HBase — построенная на основе HDFS база данных NoSQL, предоставляющая доступ в реальном времени для чтения или записи данных;
- Apache Pig, Apache Hive, Apache Drill и Apache Phoenix для упрощения исследования и анализа Big Data при работе с HBase, HDFS и MapReduce;
- Apache Zookeeper и Apache Oozie для координации операций и планирования задач в кластере Hadoop.
О преимуществах и недостатках Hadoop можно прочитать в нашей статье The Good and the Bad of Hadoop Big Data Framework.
Инструменты потоковой аналитики
Инструменты для потоковой аналитики образуют важную группу в экосистеме Hadoop. Она включает в себя следующее:
- Apache Spark — вычислительный движок для крупных датасетов с возможностями обработки практически в реальном времени;
- Apache Storm — вычислительная система реального времени для неограниченных потоков данных (они имеют начало, но не имеют определённого конца и должны обрабатываться постоянно);
- Apache Flink обрабатывает как неограниченные, так и ограниченные потоки данных (с конкретным началом и концом);
- Apache Kafka — потоковая платформа для передачи сообщений, хранения, обработки и интеграции больших объёмов данных.
Все эти технологии используются для создания конвейеров Big Data реального времени. Подробнее о них можно узнать из наших статей Hadoop vs Spark: Main Big Data Tools Explained и The Good and the Bad of Apache Kafka Streaming Platform.
Корпоративный концентратор данных
Если конвейером big data управляют неправильно, то озёра данных быстро превращаются в болота данных — набор разнообразных данных, которыми нельзя ни управлять, ни пользоваться. Для решения этой проблемы была создана новая методика интеграции данных.
Корпоративные концентраторы данных (Enterprise data hub, EDH) — это новое поколение архитектуры данных, нацеленное на обмен управляемыми данными между системами. Они соединяют множество источников информации, в том числе DW и озёра данных. В отличие от DW, концентратор данных поддерживает все типы данных и с лёгкостью интегрирует системы. Кроме того, его можно развернуть за недели или даже дни, в то время как развёртывание DW может длиться месяцы или даже годы.
Кроме того, концентраторы данных имеют дополнительные возможности управления данными, их гармонизации, исследования и анализа, чего недостаёт озёрам данных. Они проектируются под потребности конкретного бизнеса и его наиболее актуальные нужды.
Подведём итог:
- хранилище данных создаётся в основном для работы со структурированными данными с целью самообслуживающейся аналитики и BI;
- озеро данных создают для работы с масштабируемыми скоплениями структурированных и неструктурированных данных как способ поддержки глубокого обучения, машинного обучения и ИИ в целом;
- концентратор данных создаётся для портируемости многоструктурных данных, упрощения обмена ими и эффективной обработки.
EDH можно интегрировать с DW и/или озером данных, чтобы упростить обработку данных и решать повседневные проблемы этих архитектур. Подробнее об этом можно прочитать в нашей статье What is Data Hub: Purpose, Architecture Patterns, and Existing Solutions Overview.
Задача дата-инженера
Теперь, когда мы знаем, чем занимается data engineering, давайте исследуем профессию, которая специализируется в создании программных решений, связанных с big data – дата-инженер.
Хуан де Диос Сантос, сам работающий дата-инженером, формулирует эту профессию следующим образом: «В многодисциплинарной команде, включающей в себя дата-саентистов, инженеров BI и дата-инженеров, задача дата-инженера по большей мере заключается в обеспечении качества и доступности данных». Также он утверждает, что дата-инженер может взаимодействовать с другими специалистами при реализации или проектировании связанной с данными функции (или продукта), например, A/B-теста, развёртывания модели машинного обучения и совершенствовании имеющегося источника данных.
Навыки и квалификация
Data engineering расположен на пересечении проектирования ПО и data science, что приводит к необходимости пересечения навыков.
Пересечение навыков разработчика ПО, дата-инженера и дата-саентиста.
Опыт разработки ПО. Дата-инженеры при помощи языков программирования обеспечивают надёжный и удобный доступ к данным и базам данных. По словам Хуана де Диос Сантоса, они должны уметь работать с полным циклом разработки ПО, в том числе формировать идеи, проектировать архитектуру, прототипировать, тестировать, развёртывать, заниматься DevOps, задавать метрики и выполнять мониторинг систем. Дата-инженеры — опытные разработчики как минимум на на Python или Scala/Java.
Навыки, связанные с данными. «Дата-инженер должен обладать знаниями множества разновидностей баз данных (SQL и NoSQL), платформ данных, концепций наподобие MapReduce, пакетной и потоковой обработки и даже части самой фундаментальной теории данных, то есть типов данных и описательной статистики», — подчёркивает Хуан.
Навыки создания систем. У дата-инженеров должен быть опыт работы с различными технологиями и фреймворками хранения данных, которые они могут комбинировать для создания конвейеров данных.
Инструментарий
Дата-инженер должен обладать глубоким пониманием множества технологий работы с данными, чтобы иметь возможность подбирать подходящие для конкретной работы.
Airflow. Эта система управления рабочими процессами на основе Python разработана Airbnb для изменения архитектуры её конвейеров данных. Мигрировав на Airflow, компания снизила время работы своего experimentation reporting framework (ERF) с более чем 24 часов до 45 минут. Среди плюсов Airflow Хуан отмечает его операторы: «Они позволяют нам исполнять команды bash, выполнять SQL-запросы и даже отправлять электронные письма». Также Хуан подчёркивает возможность Airflow отправлять уведомления в Slack, его завершённый и богатый UI и совершенство проекта в целом. С другой стороны, Хуану не нравится, что Airflow позволяет писать задачи только на Python.
Чтобы узнать подробности, прочитайте нашу статью The Good and the Bad of Apache Airflow Pipeline Orchestration.
Cloud Dataflow. Облачный сервис обработки данных Dataflow нацелен на потребление больших объёмов данных и обработку с низкими задержками благодаря быстрому параллельному исполнению конвейеров аналитики. Dataflow имеет преимущество перед Airflow, поскольку поддерживает несколько языков, в том числе Java, Python, SQL и движки наподобие Flink и Spark. Также его хорошо поддерживает Google Cloud. Однако де Диос Сантос предупреждает, что недостатком Dataflow могут быть высокие затраты.
Среди прочих популярных инструментов можно упомянуть платформу Stitch для быстрого перемещения данных и Blendo — инструмент для синхронизации различных источников данных с хранилищем данных.
Решения для создания хранилищ. Для хранилищ данных, создаваемых внутри компаний, широко применяются Teradata Data Warehouse, SAP Data Warehouse, IBM db2 и Oracle Exadata. Самые популярные облачные решения для хранилищ данных — это Amazon Redshift и Google BigQuery.
Инструменты Big data. Дата-инженер должен освоить следующие технологии (или хотя бы знать о них): Hadoop и его экосистема, Elastic Stack для сквозной аналитики big data, озёра данных.
Разница между дата-инженером и дата-саентистом
Дата-инженеров часто путают с дата-саентистами. Мы попросили дата-саентиста с более чем десятилетним опытом Александра Кондуфорова рассказать о разнице между этими профессиями.
«И дата-саентисты, и дата-инженеры работают с данными, но решают достаточно разные задачи, имеют разные навыки и используют разные инструменты», — объясняет Александр. «Дата-инженеры создают и поддерживают крупные хранилища данных, применяют свои навыки проектирования: языки программирования, методики ETL, знания различных хранилищ данных и языков баз данных. Дата-саентисты очищают и анализируют эти данные, делают из них важные выводы, внедряют модели для прогнозирования и предиктивной аналитики, и по большей мере применяют свои математические и алгоритмические навыки, алгоритмы и инструменты машинного обучения».
Александр подчёркивает, что доступ к данным может по множеству причин стать для дата-саентистов сложной задачей.
- Огромность объёмов данных требует дополнительных усилий и специфических инженерных решений для доступа к данным и их обработки за разумное время.
- Данные обычно хранятся во множестве разных систем и форматов. Имеет смысл сначала выполнить этапы подготовки данных и переместить информацию в центральный репозиторий, например, в хранилище данных. Обычно этой задачей занимаются архитекторы данных и дата-инженеры.
- Для доступа к репозиториям данных используются разные API. Дата-саентистам требуется, чтобы дата-инженеры реализовали наиболее эффективный и надёжный конвейер получения данных.
Как мы видим, при работе с созданными и поддерживаемыми дата-инженерами системами хранения дата-саентисты становятся их «внутренними клиентами». Здесь и происходит их совместная работа.