
Прошло уже около полугода как Meta* случайно слили свою языковую модель LLaMA. А недавно они сами выложили в открытый доступ ее 2-ую версию. Для понимания масштаба - на обучение Meta* потратили более 3 311 616 GPU часов. Это примерно 378 лет работы одной мощной видеокарты. В этой статье я расскажу как я смог бесплатно и без мощного железа дообучить LLaMA на диалогах с друзьями в ВК, чтобы сделать чат бота, который копирует наш стиль общения, оживляет разговор в чате и просто пишет странные и смешные вещи. В статье будет мало терминов, тут я простым языком расскажу как вы можете обучить большую языковую модель.

Те, кто интересовался темой языковых моделей, уже, наверное, знают, что первую версию llama энтузиасты почти сразу после слива оптимизировали для работы на обычных процессорах и на нейроускорителях Apple, которые стоят в их процессорах. При этом на M1 процессоре LLaMA стала работать очень быстро, выдавая более 10 токенов(токен - это слово, часть слова или буква) в секунду, это быстрее чем бесплатный ChatGPT на тот момент. Еще через пару недель ее дообучили ребята из Стэнфорда, чтобы она понимала концепцию вопрос-ответ и могла давать ответы и выполнять задачи.
Что потребуется для запуска нейронки
Есть две версии модели: LLaMA и LLaMA 2. LLaMA есть в размерах 7B, 13, 30B, 65B, LLaMA 2 - в размерах 7B, 13B и 70B. 7B весит примерно 13 гб, 65B - 120 гб. Но не торопитесь ужасаться, во-первых, как я уже писал, ее можно запустить не только на видеокарте, она хорошо работает и на процессоре, а во вторых, для запуска на обычных компьютерах применяют квантизацию (quantization) - это сжатие всех весов нейронов. В оригинальной версии вес каждого нейрона 16 бит, но их сжимают до 8, 4 и даже до 2 бит. Чаще всего используют сжатие до 4 бит, LLaMA 7B при таком сжатии весит 3.9 гб и требует немного больше 4 гб оперативной памяти и обычный процессор.
Что будем обучать и что потребуется
В данной статье я покажу как я дообучал LLaMA 7B и LLaMA 2 7B. Если готовы заплатить за аренду видеокарт, то можете обучить и модели покрупнее. Обучение будем проводить для нейронки в оригинальном размере (16 битовые веса), создав Lora модуль (не буду тут рассказывать, что это, если вкратце, то это алгоритм обучающий лишь несколько дополнительных слоев для нейросети, которые корректируют ее работу, это намного менее требовательно, чем полное дообучение). Для этого пока обязательно нужна видеокарта, то есть нужно около 15 гб видеопамяти.
На этом можно было бы остановиться, подумав, что за такое железо точно придется платить. Но пока изучал эту тему, я увидел, что один парень на гитхабе написал о возможности запустить обучение бесплатно на Google Colab. Честно говоря, я был в шоке, когда понял что google совершенно бесплатно дает доступ к машине с 13.6 гб оперативки, с Nvidia Tesla T4 на 16 гб видеопамяти, около 78 гб хранилища и очень быструю сеть (скорость загрузки нейросети там доходила до 200 мегабайт в секунду). Конечно всю эту радость дают не навсегда, а на неопределенный срок, и отнять это могут в любой момент. У меня получалось обучать по часа 4.

Данные для обучения
Для обучения я взял историю диалога с друзьями в ВК. В ВК можно получить по запросу все данные о себе, которые у них есть, в том числе истории всех переписок. Чтобы подготовить полученные данные, я воспользовался первым попавшимся на github репозиторием для парсинга сообщений в бэкапе вк и сделал форк с изменениями для создания датасета. Через код в Jypyter вы сможете получить json файл с датасетом для обучения.
Обучение
Для обучения можно воспользоваться этим проектом, я сделал от него форк, добавив шаблон для обучения на простом тексте (оригинальный репозиторий имеет шаблоны только для обучения концепции вопрос-ответ). Вот мой форк и вот проект которые вы можете запустить в гугл колабе, он подтянет мой форк. В первых нескольких полях вы можете поменять папку на Google Disk, куда будут сохраняться результаты обучения, нужно не меньше 300 мб. Также можете вместо модели "sharpbai/Llama-2-7b-hf" выбрать другую, например llama 7b первой версии (decapoda-research/llama-7b-hf), найти вы их можете на huggingface. Лучше всего брать те, которые разбиты на множество файлов (такие требуют меньше памяти при загрузке). Те, что не разбиты, не всегда загружаются на бесплатном google colab (требуется больше памяти).

Пакеты не всегда ставятся сразу в виртуальной машине, не стоит пугаться, иногда требуется нажать Runtime -> Restart runtime. На второй раз пакеты ставятся успешно.
После того как языковая модель скачается и загрузится в память, вы можете воспользоваться веб интерфейсом, чтобы настроить параметры обучения.
Ссылка будет выведена в формате: Running on public URL: https://...

Сразу можете переходить во вкладку Fine tuning, в поле Template выставлять "my_sample", в поле Format "JSON Lines". my_sample - это тот простой шаблон промптов, который я добавил, в нем нет ничего кроме input и output. Далее нужно либо скопировать содержимое файла датасета, либо открыть его, скопировав на машину google colab.

После можете посмотреть превью данных для обучения во вкладке Preview. Еще на этой вкладке браузер меньше тупит, не пытаясь отобразить все данные для обучения.

Остается только выставить параметры обучения, в целом можно оставить по умолчанию, но вот поля, которые я менял:
Max Sequence Length - Влияет на максимальную длину текста в наборе датасета. Все данные из датасета, длина которых превышает эту, не будут использоваться в обучении. (На русском почти всегда длина это количество букв). Очень большое число может привести к переполнению памяти на бесплатной машине.
Train on Inputs - Эту галочку лучше поставить, чтобы модель обучалась и на input тексте, и на output.
Micro Batch Size - Грубо говоря, указывает количество данных, которое берется для обучения за раз. Очень большое число может привести к переполнению памяти на бесплатной машине. Я оставлял в основном 8.
Gradient Accumulation Steps - Не разбирался как работает, но я поднимал до двух. Судя по описанию, ускоряет обучение, как и Micro Batch Size, но не увеличивает потребляемый объем памяти.
Epochs - Количество эпох обучения. Можно смело ставить больше, все равно остановим обучение руками, или гугл сам остановит машину часа через 4.
Learning Rate - Коэффициент обучаемости, влияет на скорость, но слишком большой может привести к плохому обучению, я оставлял 0.0003.
Saved Checkpoints Limit - Максимальное число чекпоинтов, ставьте побольше.
Steps Per Save - Количество шагов перед сохранением бэкапа. Ставьте 200-300, чтобы почаще сохраняться и меньше терять в случае отключения машины гуглом.
LORA Model Name - Название папки на гугл диск, в которую будут сохраняться бэкапы.
Позже еще понадобится раздел Continue from Model для продолжения обучения с последнего чекпоинта.

В процессе обучения вы будете видеть примерно такой график. Я обычно дожидался ошибки примерно до 1.1. Дольше у меня не хватало терпения).
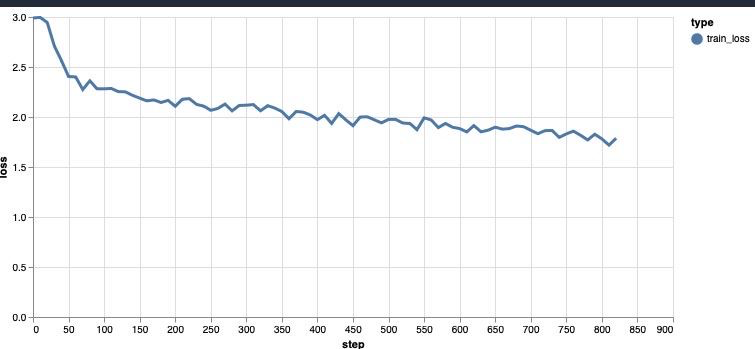
Теперь, зная как можно бесплатно дообучить llama, вы можете создать тупого бота симулирующего участника в диалоге с друзьями, он, конечно, не будет кидать мемы и понимать глубокий смысл, но может поугорать за компанию или написать тупую шутку. Можно попробовать сделать что-то и посерьезнее, например, ПО системы для написания ответов на письма или откликов на фриланс бирже. Применений может быть много, но стоит понимать что LLaMA 7B все же плоховата в работе с русским, так как мало его учила.

Спасибо больше за внимание, надеюсь статья была для вас полезна! Буду рад любым коментариям и дополнениям!
Я выложил пару сравнений работы дообученной и простой llama 2 7B в телеграм канале, который недавно создал, буду стараться там регулярно выкладывать интересные мысли про программирование, нейросети и информационную безопасность.
Также выложу там инфу про то, как я поднял llama на raspberry pi для бота в телеграмме.
* Meta - признана экстремистской организацией и запрещена в России.
Комментарии (7)

NJ884
17.08.2023 07:04+1Подскажите как применяют квантизацию (quantization) - для сжатие всех весов нейронов.

Pooper123
17.08.2023 07:04+1Любопытная вещь, однако. Спасибо за гайд, если когда-нибудь вернусь в ВК, обязательно воспользуюсь (ещё бы нормальные связи с друзьями для начала построить, чтобы они мне писали =)). Кстати, получается, по сообщениям в большинстве своём даже не будет понятно, что пишет нейронка, а не я сам?

Vadim170 Автор
17.08.2023 07:04Llama 7B весьма плоховата в понимании русского, так что умного много не напишет, будет понятно, что текст сгенерирован. Можете и не на диалогах вк обучать) можно и из других сервисов достать сообщения для обучения
Vadim170 Автор
17.08.2023 07:04Вообще у меня есть планы переобучить llama на русский с изменением ее структуры, чтобы и писала быстрее. может потом этим займусь, буду в телеграме об этом писать
diogen4212
не подскажете, в каком формате были данные для обучения? Как большая последовательность реплик в чате "Имя1: фраза1 Имя2: фраза 2" каждая реплика с новой строки, или какая-то более сложная структура (вроде такой? Не совсем понятно, что считать instruction, input и output)
Vadim170 Автор
Фразы я разделял просто новой строкой. Для обучения на стиль диалога не требуется instruction. В input я клал 8 фраз и 3 в output. Грубо говоря и это излишне сложно, так как обучалась она одинаков и на input и на output, можно и просто по несколько фраз в input кидать, если я не ошибаюсь.