

Введение
Я делала много вещей с компьютерами, но в моих знаниях всегда был пробел: что конкретно происходит при запуске программы на компьютере? Я думала об этом пробеле — у меня было много низкоуровневых знаний, но не было цельной картины. Программы действительно выполняются прямо в центральном процессоре (central processing unit, CPU)? Я использовала системные вызовы (syscalls), но как они работают? Чем они являются на самом деле? Как несколько программ выполняются одновременно?
Наконец, я сломалась и начала это выяснять. Мне пришлось перелопатить тонны ресурсов разного качества и иногда противоречащих друг другу. Несколько недель исследований и почти 40 страниц заметок спустя я решила, что гораздо лучше понимаю, как работают компьютеры от запуска до выполнения программы. Я бы убила за статью, в которой объясняется все, что я узнала, поэтому я решила написать эту статью.
И, как говорится, ты по-настоящему знаешь что-то, только если можешь объяснить это другому.
Содержание:
1. Основы
Одной вещью, которая удивляла меня снова и снова, является то, насколько компьютеры просты. Эта простота очень красива, но порой превращается в кошмар.
Архитектура компьютера
ЦП — это место, в котором происходят все вычисления. Он начинает "пыхтеть" как только вы включаете компьютер, выполняя инструкцию за инструкцией.
Первым массовым ЦП был Intel 4004, спроектированный в конце 60-х итальянским физиком и инженером Федерико Фарджином. Это была 4-битная архитектура, а не 64-битная, которая используется сегодня. 4-битная архитектура была гораздо менее сложной, чем современные процессоры, но многое осталось почти неизменным.
"Инструкции", выполняемые ЦП — всего лишь двоичные (binary) данные: байт или два для представления запускаемой инструкции (код операции — opcode), за которыми следуют данные, необходимые для выполнения инструкции. То, что мы называем машинным кодом (machine code) — всего лишь серия этих бинарных инструкций в виде строки. Assemble — это полезный синтаксис, облегчающий чтение и запись сырых (raw) битов людьми. Он всегда компилируется в двоичные данные, понятные ЦП.

Ремарка: инструкции в машинном коде не всегда представлены 1:1, как в приведенном примере. Например,add eax, 512преобразуется в05 00 02 00 00.
Первый байт (05) — это код операции, представляющий добавление регистра EAX к 32-битному числу. Остальные байты — это 512 (0x200) с порядком байтов little-endian.
Defuse Security разработали полезный инструмент для преобразования языка ассемблера в машинный код.
Оперативная память или оперативное запоминающее устройство (Random Access Memory, RAM) — это основное хранилище компьютера, большое многоцелевое пространство, где хранятся все данные, используемые программами, запущенными на компьютере. Это включает код самих программ, а также код ядра (kernel) операционной системы. ЦП всегда читает машинный код прямо из ОП. Код, не загруженный в ОП, не может быть выполнен.
ЦП хранит указатель инструкции (instruction pointer), который указывает на место в ОП, где находится следующая инструкция. После выполнения всех инструкций, ЦП возвращает указатель в начало, и процесс повторяется. Это называется циклом выборки-исполнения (fetch-execute cycle).
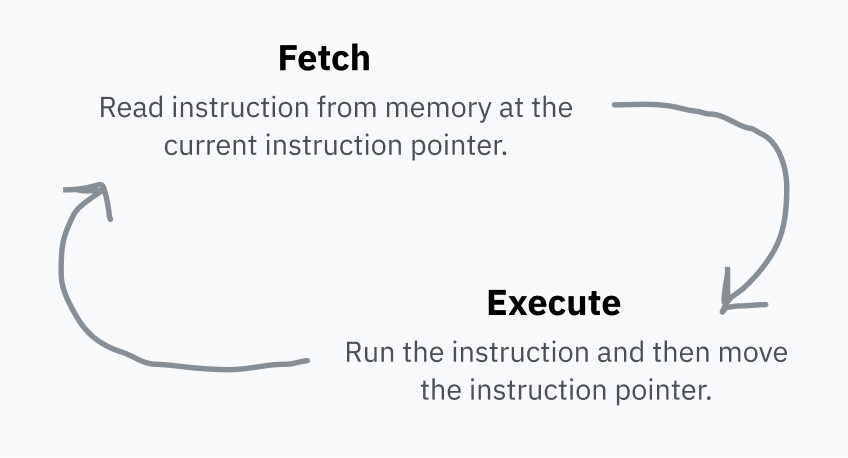
После выполнения инструкции указатель передвигается за нее в ОП и таким образом указывает на следующую инструкцию. Указатель инструкции двигается вперед, и машинный код выполняется в порядке его хранения в памяти. Некоторые инструкции могут заставить указатель переместиться (перепрыгнуть — jump) в другое место (выполнить другую инструкцию вместо текущей или выполнить одну из инструкций в зависимости от определенного условия). Это делает возможным повторное и условное выполнение кода.
Указатель инструкции хранится в регистре (registry). Регистры — это маленькие хранилища, которые являются очень производительными для чтения и записи ЦП. Каждая архитектура ЦП имеет фиксированный набор регистров, используемых для всего: от хранения временных значений в процессе вычислений до настройки процессора.
Некоторые регистры доступны из машинного кода напрямую, например, ebx на приведенной выше диаграмме.
Другие регистры предназначены только для внутреннего использования ЦП, но часто могут обновляться или читаться с помощью специальных инструкций. Одним из примеров такого регистра является указатель инструкции, который не может читаться напрямую, но может обновляться, например, для выполнения другой инструкции вместо текущей.
Процессоры наивны
Вернемся к вопросу о том, что происходит при запуске программы на компьютере. Сначала происходит некоторая магия — мы поговорим об этом позже — и мы получаем файл с машинным кодом, который где-то хранится. ОС загружает его в ОП и указывает ЦП переместить указатель на определенную позицию в ОП. Начинается цикл выборки-исполнения, и программа запускается!
Ваш ЦП получает последовательные инструкции браузера из ОП и выполняет их, что приводит к рендерингу этой статьи.
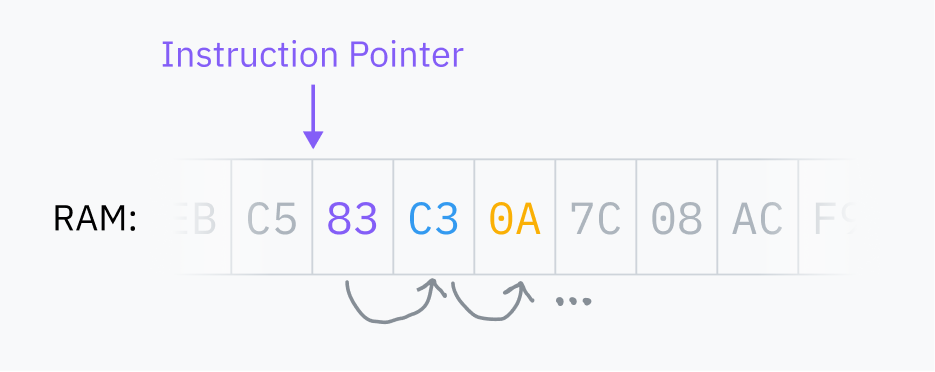
ЦП имеют очень ограниченный кругозор. Они видят только указатель текущей инструкции и немного внутреннего состояния. Процессы — это абстракции ОС, а не нечто, что понимают или отслеживают ЦП.
У меня это вызывает больше вопросов, чем ответов:
- Если ЦП не знает о многозадачности (multiprocessing) и выполняет инструкции последовательно, почему он не застревает в выполняемой программе? Как могут одновременно выполняться несколько программ?
- Если программа выполняется в ЦП, и ЦП имеет прямой доступ к ОП, почему код из других процессов или, прости господи, ядра не имеет доступа к памяти?
- Каков механизм, предотвращающий выполнение любой инструкции любым процессом? И что такое системный вызов?
Вопрос о памяти заслуживает отдельного раздела (см. раздел 5). Если коротко, то большая часть обращений к памяти проходит через слой неправильного направления (misdirection), который переназначает все адресное пространство. Пока мы будем исходить из предположения, что программы имеют прямой доступ ко всей ОП, и компьютеры могут запускать только один процесс за раз. Со временем мы избавимся от обоих этих предположений.
Пришло время прыгнуть в нашу первую кроличью нору – в страну, полную системных вызовов и колец безопасности (security rings).
Ремарка: что такое ядро?
ОС вашего компьютера, такая как macOS, Windows или Linux — это коллекция программного обеспечения, выполняющая всю основную работу. "Основная работа" — это общее понятие, и, в зависимости от ОС, может включать такие вещи, как приложения, шрифты, иконки, которые поставляются с компьютером по умолчанию.
Каждая ОС имеет ядро. Когда вы включаете компьютер, указатель инструкции запускает какую-то программу. Этой программой является ядро. Ядро имеет почти полный доступ к памяти, периферийным устройствам и другим ресурсам и отвечает за запуск ПО, установленного на компьютере (пользовательских программ).
Linux — это всего лишь ядро, которому для полноценной работы требуется множество пользовательских программ, таких как оболочки (shells) и серверы отображения (display servers). Ядро macOS называется XNU, а современное ядро Windows — NT Kernel.
Два кольца, чтобы править всеми
Режим (mode) (иногда именуемый уровнем привилегий (privilege level) или кольцом (ring)), в котором находится процессор, управляет тем, что разрешено делать. В современных архитектурах имеется, как минимум, два варианта: режим ядра/администратора (kernel/supervisor mode) и режим пользователя (user mode). Несмотря на то, что архитектура может поддерживать более двух режимов, как правило, используются только режимы ядра и пользователя.
В режиме ядра разрешено все: ЦП может выполнять любую поддерживаемую инструкцию и обращаться к любой памяти. В режиме пользователя разрешен только определенный набор инструкций, ввод/вывод (input/output, I/O) и доступ к памяти ограничены, многие настройки ЦП заблокированы. Как правило, ядро и драйверы запускаются в режиме ядра, а приложения — в режиме пользователя.
Процессоры запускаются в режиме ядра. Перед выполнением программы ядро инициализирует переключение в пользовательский режим.

Пример того, как режимы процессора проявляются в реальной архитектуре: в x86-64 текущий уровень привилегий (current privilege level, CPL) может читаться из регистра cs (code segment — сегмент кода). В частности, CPL содержится в 2 наименьших битах регистра cs. Эти 2 бита могут хранить 4 возможных кольца x86-64: кольцо 0 — это режим ядра, а кольцо 3 — режим пользователя. Кольца 1 и 2 предназначены для запуска драйверов, но используются только несколькими нишевыми ОС. Если, например, битами CPL являются 11, ЦП запускается в режиме пользователя.
Системный вызов
Программы запускаются в режиме пользователя, потому что им нельзя предоставлять полный доступ к компьютеру. Режим пользователя делает свою работу, предотвращая доступ к большей части компьютера, но программам требуется ввод/вывод, память и возможность взаимодействия с ОС! Для этого ПО, запущенное в пользовательском режиме, обращается за помощью к ядру ОС. ОС затем реализуют собственные меры защиты.
Если вы писали код, взаимодействующий с ОС, то должны быть знакомы с функциями open, read, fork и exit. Под несколькими слоями абстракций эти функции используют системные вызовы для обращения к ОС за помощью. Системный вызов — это специальная процедура, позволяющая программе запускать переход из пространства пользователя в пространство ядра, перепрыгивать из кода программы в код ОС.
Передача управления из пространства пользователя в пространство ядра выполняется с помощью функций процессора, которые называются программными прерываниями (software interrupts):
- При запуске ОС сохраняет "таблицу векторов прерываний" (interrupt vector table, IVT) (в x86-64 она называется "таблицей дескрипторов прерываний" (interrupt descriptor table)) в ОП и регистрирует ее с помощью ЦП. IVT представляет собой таблицу сопоставления номера прерывания (interrupt number) и указателя обработчика кода (handler code pointer).

- Затем пользовательские программы могут использовать такие инструкции, как INT, указывающие процессору найти заданный номер прерывания в IVT, переключиться в режим ядра и переместить указатель инструкции на адрес памяти, указанный в IVT.
После завершения этого кода, ядро указывает ЦП переключиться обратно в режим пользователя и вернуть указатель инструкции в то место, где произошло прерывание. Это делается с помощью таких инструкций, как IRET.
Если вам интересно, то идентификатором прерывания для системных вызовов в Linux является 0x80. Список системных вызовов Linux можно найти здесь.
Интерфейсы оболочки: абстрагирование прерываний
Вот, что мы узнали о системных вызовах:
- программы, запущенные в режиме пользователя, не имеют доступа к вводу/выводу или памяти. Им приходится обращаться к ОС за помощью во взаимодействии с внешним миром;
- программы могут передавать управление ОС с помощью специальных инструкций, содержащих машинный код, таких как INT и IRET;
- программы не могут переключать уровни привилегий напрямую. Программные прерывания являются безопасными, поскольку процессор предварительно настраивается ОС относительно того, к какому коду ОС следует обращаться. Векторная таблица прерываний может настраиваться только в режиме ядра.
Программы должны передавать данные ОС при системном вызове. ОС должна знать не только то, какой системный вызов выполнять, но также располагать данными, необходимыми для его выполнения, такими как название файла (filename). Механизм передачи данных зависит от ОС и архитектуры, но, как правило, это делается посредством помещения данных в определенные регистры или в стек (stack) перед запуском прерывания.
Различия в том, как системные вызовы вызываются на разных устройствах означает, что реализация системных вызовов для каждой программы разработчиками является, по меньшей мере, непрактичной. Это также означало бы невозможность изменения ОС своей обработки прерываний во избежание поломки программ, рассчитанных на использование старых систем. Наконец, мы больше не пишем программы на языке ассемблера – нельзя ожидать от программистов перехода на assembly при каждом чтении файла или выделении памяти.
Поэтому ОС предоставляют слой абстракции поверх этих прерываний. "Переиспользуемые" высокоуровневые функции, оборачивающие необходимые инструкции на языке ассемблера, предоставляются libc в Unix-подобных системах и частью библиотеки под названием ntdll в Windows. Простой вызов этих функций не влечет переключения в режим ядра. Внутри библиотек код assembly передает управление ядру. Этот код гораздо более зависим от платформы, чем библиотечная обертка.
Когда мы вызываем exit(1) из C, запущенного на Unix, эта функция выполняет машинный код для запуска прерывания после помещения кода операции системного вызова и аргументов в правильный регистр/стек/что угодно. Компьютеры такие клевые!
Жажда скорости / CISC
Многие архитектуры CISC, такие как x86-64, содержат инструкции, предназначенные для системных вызовов, созданные из-за преобладания парадигмы системных вызовов.
Intel и AMD не очень хорошо координировали свои действия при работе над x86-64. Поэтому у нас имеется 2 набора оптимизированных инструкций системных вызовов. SYSCALL и SYSENTER являются оптимизированными альтернативами таких инструкций, как INT 0x80. Их инструкции возврата, SYSRET и SYSEXIT, предназначены для быстрого обратного перехода в пространство пользователя и продолжения выполнения кода программы.
Процессоры AMD и Intel имеют немного разную совместимость с этими инструкциями. SYSCALL, как правило, лучше подходит для 64-битных программ, а SYSENTER лучше поддерживается 32-битными программами.
Архитектуры RISC не имеют таких специальных инструкций. AArch64, архитектура RISC, которая применяется в Apple Silicon, использует только одну инструкцию прерывания для системных вызовов и программных прерываний.
Вот что мы узнали в этом разделе:
- процессоры выполняют инструкции в бесконечном цикле выборки-исполнения и не имеют ни малейшего понятия об ОС или программах. Режим процессора, обычно хранящийся в регистре, определяет, какие инструкции могут выполняться. Код ОС выполняется в режиме ядра и переключается на режим пользователя для запуска программ;
- для запуска исполняемого файла ОС переключается в режим пользователя и сообщает процессору входную точку кода в ОП. Поскольку программы имеют низкие привилегии, они вынуждены обращаться за помощью к коду ОС для взаимодействия с внешним миром. Системные вызовы – это стандартизированный способ переключения программ из режима пользователя в режим ядра и в код ОС;
- программы, как правило, используют эти системные вызовы путем вызова функций специальных библиотек. Эти функции являются обертками над машинным кодом для программных прерываний или специфических для архитектуры инструкций системных вызовов, которые передают управление ядру ОС и переключают кольца безопасности. Ядро делает свое дело, переключается обратно в режим пользователя и возвращается к коду программы.
Вернемся к вопросу о том, что если ЦП не отслеживает больше одного процесса и просто выполняет одну инструкцию за другой, почему он не застревает в запущенной программе. Как несколько программ могут работать одновременно?
Все дело в таймерах.
2. Нарезка времени
Предположим, что мы разрабатываем ОС и хотим, чтобы пользователи могли запускать несколько программ одновременно. У нас нет модного многоядерного процессора, наш ЦП может выполнять только одну инструкцию за раз.
К счастью, мы очень умные разработчики ОС. Мы выяснили, что конкурентность (concurrency) может имитироваться путем выполнения процессов по очереди. Если мы циклически перебираем процессы и выполняем по несколько инструкций из каждого, все процессы будут отзывчивыми и ни один из них не загрузит ЦП полностью.
Как вернуть управление из программного кода? После небольшого исследования выясняется, что большинство компьютеров содержат микросхемы (чипы) таймеров (timer chips). Мы можем запрограммировать чип таймера для переключение на обработчик прерываний ОС по прошествии определенного времени.
Программные прерывания
Ранее мы рассмотрели, как программные прерывания используются для передачи управления от пользовательской программы к ОС. Они называются "программными", поскольку произвольно запускаются программой – машинный код, выполняемый процессором в нормальном цикле выборки-исполнения, указывает ему передать управление ядру.
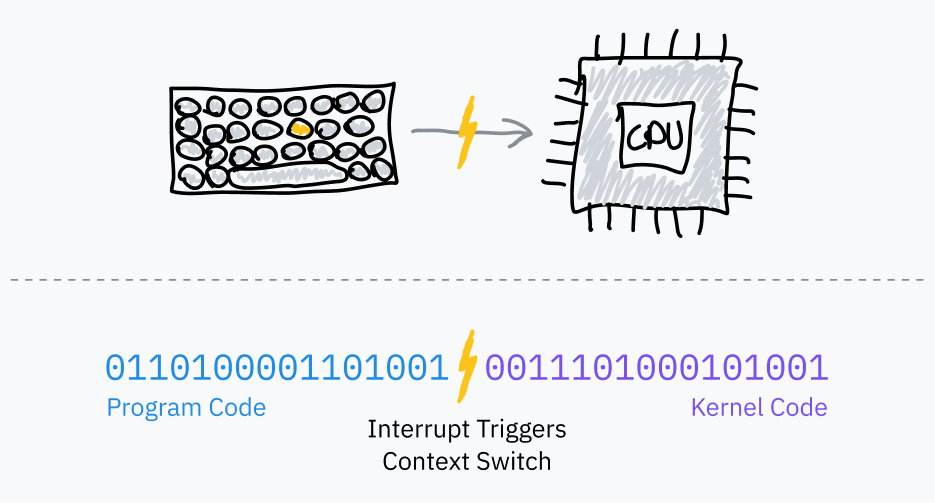
Планировщики (schedulers) ОС используют чипы таймеров, такие как PIT, для запуска программных прерываний в целях многозадачности:
- Перед началом выполнения кода программы, ОС устанавливает чип таймера для запуска прерывания по истечение определенного времени.
- ОС переключается в режим пользователя и переходит к следующей инструкции программы.
- Когда срабатывает таймер, ОС запускает программное прерывание для переключения в режим ядра, и переходит к коду ОС.
- ОС запоминает, где остановилось выполнение программы, загружает другую программу и повторяет процесс.
Это называется "вытесняющей многозадачностью" (preemptive multitasking); прерывание процесса называется "вытеснением" или "выгрузкой" (preemptive). Если вы, например, читаете эту статью в браузере и слушаете музыку на той же машине, ваш компьютер, вероятно, выполняет этот цикл тысячи раз в секунду.
Расчет временного интервала
Временной интервал (timeslice) – это период времени, в течение которого планировщик ОС позволяет процессу выполняться до его вытеснения. Простейшим способом определения временных интервалов является выделение каждому процессу одинакового интервала, например, в пределах 10 мс, и перебор задач по порядку. Это называется "циклическим планированием с фиксированным интервалом времени" (fixed timeslice round-robin scheduling).
Ремарка: забавные факты жаргона.
Временные интервалы часто называются "квантами" (quantums).
Разработчики ядра Linux используют единицу измерения jiffy для подсчета тиков таймера (timer ticks) с фиксированной частотой. Кроме прочего, эта единица используется для измерения длины временного интервала. Частота jiffy обычно составляет 1000 Гц, но может настраиваться при компиляции ядра.
Небольшим улучшением планирования с фиксированными временными интервалами является выбор целевой задержки (target latency) — оптимального наибольшего периода времени, необходимого процессору для ответа. Целевая задержка – это время, необходимое процессору для возобновления выполнения кода после вытеснения с учетом разумного количества процессов.
Временные интервалы вычисляются путем деления целевой задержки на количество задач. Такой подход лучше фиксированных интервалов, поскольку он устраняет ненужное переключение с меньшим количеством процессов. С целевой задержкой в 15 мс и 10 процессами каждый процесс получает 15/10 или 1.5 мс для выполнения. С 3 процессами каждый процесс получает 5 мс, а целевая задержка останется неизменной.
Переключение между процессами является дорогим с точки зрения вычислений, поскольку требует сохранения всего состояния текущей программы и восстановления другого состояния. В определенный момент слишком маленькие временные интервалы могут привести к проблемам с производительностью со слишком быстрым переключением между процессами. Распространенной практикой является установление нижнего порога (minimum granularity — минимальной степени детализации). Это означает, что целевая задержка превышается, если имеется достаточно процессов, чтобы минимальная степень детализации вступила в силу.
На момент написания статьи планировщик Linux использует целевую задержку в 6 мс и минимальную степень детализации в 0,75 мс.
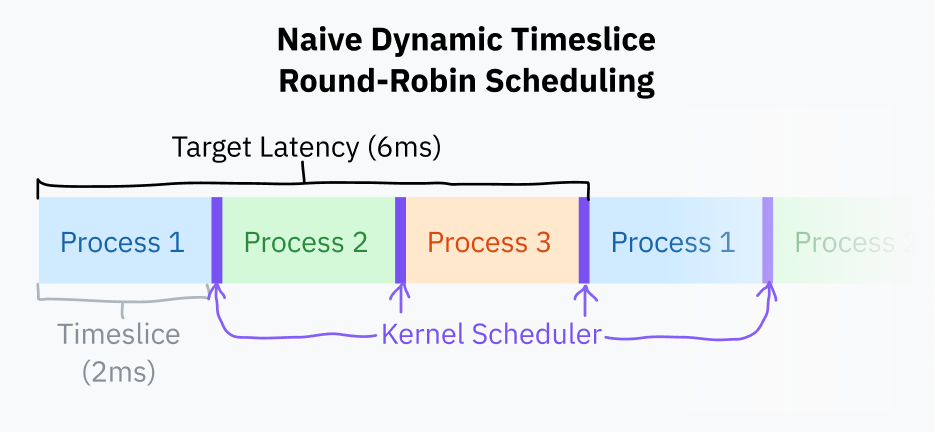
Циклическое планирование с этим базовым расчетом кванта времени близко к тому, что в настоящее время делает большинство компьютеров. Большинство ОС, как правило, имеют более сложные планировщики, которые учитывают приоритеты процессов и сроки (deadlines). Начиная с 2007 г., Linux имеет планировщик под названием "Completely Fair Scheduler" (полностью честный планировщик). CFS делает много очень причудливых вещей из области компьютерных наук, чтобы расставить приоритеты и разделить время ЦП.
При каждом вытеснении процесса ОС должна загрузить сохраненный контекст выполнения новой программы, включая ее среду памяти. Это достигается за счет использования ЦП другой таблицы страниц (page table) — связки (отображения — mapping) между "виртуальными" и физическими адресами. Это также предотвращает доступ одной программы к памяти другой.
Заметка 1: выгружаемость ядра
До сих пор мы говорили только о выгрузке и планировании пользовательских процессов. Код ядра может заставить программы "лагать", если обработка системного вызова или выполнение кода драйвера происходят слишком долго.
Современные ядра, включая Linux, являются выгружаемыми. Это означает, что они программируются так, что код ядра может быть прерван и запланирован по аналогии с пользовательскими процессами.
Это не очень важно, если вы не собираетесь писать ядро или что-то в этом роде, но знания никогда не бывают лишними.
Заметка 2: урок истории
Древние ОС, включая классическую macOS и версии Windows задолго до NT, использовали предшественника вытесняющей многозадачности. Тогда не ОС выгружала программы, а программы "уступали" (yield) ОС. Они запускали программное прерывание, как бы говоря "эй, ты можешь запустить другую программу". Эти явные уступки были единственным для ОС способом восстановления контроля и переключения к следующему процессу.
Это называется "совместной многозадачностью" (cooperative multitasking). Основным недостатком такого подхода является то, что вредоносные или просто плохо спроектированные программы могут легко заморозить (freeze) всю ОС и почти невозможно обеспечить согласованность задач, выполняемых в реальном времени.
3. Запуск программы
Мы рассмотрели, как процессоры выполняют машинный код, загружаемый из исполняемых файлов, что такое безопасность на основе колец и как работают системные вызовы. В этом разделе мы глубоко погрузимся в ядро Linux для того, чтобы выяснить, как программы загружаются и выполняются.
Мы будем рассматривать Linux x86-64. Почему?
- Linux – это полнофункциональная производственная ОС для десктопной, мобильной и серверной сред. У Linux открытый исходный код, что делает возможным его изучение во всех подробностях;
- x86-64 – это архитектура, которая используется в большинстве современных компьютеров.
Тем не менее, большая часть из того, о чем мы будем говорить, распространяется на другие ОС и архитектуры.
Стандартное выполнение системного вызова

Начнем с очень важного системного вызова — execve. Он загружает программу и, если загрузка прошла успешно, заменяет текущий процесс этой программой. Существует несколько других системных вызовов (execlp, execvpe и др.), но все они так или иначе основаны на execve.
Ремарка:execveat.execveна самом деле построен на основеexecveat, более общем системной вызове, запускающем программу с некоторыми настройками. Для простоты мы в основном будем говорить оexecve, который является вызовомexecveatс настройками по умолчанию.
Любопытно, что означаетve?vозначает, что одним параметром является вектор (список) аргументов (argv), аeозначает, что другим параметром является вектор переменных среды окружения (envp). Другие системные вызовы имеют другие суффиксы для обозначения различных сигнатур вызова.atвexecveat— это просто "at", определяющее локацию (location) для запускаexecve.
Сигнатура вызова execve выглядит так:
int execve(const char *filename, char *const argv[], char *const envp[]);- аргумент
filenameопределяет путь к запускаемой программе; -
argv— это завершающийся нулем (null-terminated) (последним элементом является нулевой указатель (null pointer)) список аргументов программы. Аргументargc, который часто передается в основные функции C, на самом деле вычисляется позже системным вызовом для нулевого завершения; - аргумент
envpсодержит другой завершающийся нулем список переменных среды окружения, которые используются в качестве контекста для приложения. Они… условно (по соглашению) являются парамиKEY=VALUE(ключ=значение). Условно. Я обожаю компьютеры.
Забавный факт! Знаете ли вы, что правило, согласно которому первым аргументом должно быть название программы, это всего лишь соглашение? execve не выполняет никаких проверок на этот счет! Первым аргументом будет то, что передается execve в качестве первого элемента в списке argv, даже если этот элемент не имеет ничего общего с названием программы.
Что интересно, execve содержит некоторый код, который предполагает, что argv[0] — это название программы. Мы подробнее поговорим об этом позже.
Шаг 0. Определение
Мы знаем, как работают системные вызовы, но мы не рассматривали примеров реального кода! Посмотрим как определяется execve в исходном коде ядра Linux:
// fs/exec.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/exec.c#L2105-L2111
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}SYSCALL_DEFINE3 — это макрос (macro) для определения кода системного вызова с тремя аргументами.
Мне стало любопытно, почему арность содержится в названии макроса. Я погуглил и выяснил, что это обходной путь (workaround) для решения некоторых проблем безопасности.
Аргумент filename передается в функцию getname(), которая копирует строку из пространства пользователя в пространство ядра и выполняет некоторые действия по отслеживанию использования. Она возвращает структуру (struct) filename, определенную в include/linux/fs.h. Эта структура хранит указатель на оригинальную строку в пользовательском пространстве, а также новый указатель на значение, скопированное в пространство ядра:
// include/linux/fs.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/fs.h#L2294-L2300
struct filename {
const char *name; /* указатель на скопированную строку в пространстве ядра */
const __user char *uptr; /* указатель на оригинальную строку в пространстве пользователя */
int refcnt;
struct audit_names *aname;
const char iname[];
};Затем execve вызывает функцию do_execve(). Это, в свою очередь, приводит к вызову функции do_execve_common() с некоторыми дефолтными настройками. Системный вызов execveat, упоминавшийся ранее, также вызывает do_execve_common(), но передает ей больше пользовательских настроек.
Ниже представлены определения do_execve() и do_execveat():
// fs/exec.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/exec.c#L2028-L2046
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
static int do_execveat(int fd, struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp,
int flags)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(fd, filename, argv, envp, flags);
}В execveat файловый дескриптор (тип идентификатора, указывающего на некоторый ресурс) передается сначала в системный вызов, а затем — в do_execveat_common(). Это определяет директорию, по отношению к которой выполняется программа.
В execve для аргумента файлового дескриптора используется специальное значение AT_FDCWD. Это общая (распределенная — shared) константа ядра Linux, которая указывает функциям интерпретировать названия путей по отношению к текущей рабочей директории. Функции, принимающие файловые дескрипторы, как правило, содержат явные проверки типа if (fd == AT_FDCWD) { /* ... */ }.
Шаг 1. Настройка
Мы добрались до do_execveat_common() — главной функции обработки выполнения программы.
Первой важной задачей do_execveat_common() является установка структуры под названием linux_binprm. Я не буду приводить полное определение этой структуры, но вот несколько важных замечаний:
- такие структуры данных, как
mm_structиvm_area_structопределены для подготовки управления виртуальной памятью для новой программы; -
argcиenvcвычисляются и сохраняются для передачи в программу; -
filenameиinterpхранят название файла программы и ее интерпретатора, соответственно. Сначала они равны друг другу, но в некоторых случаях могут меняться: одним из случаев, когда исполняемый двоичный файл отличается от названия программы, является запуск интерпретируемых программ, таких как скрипты Python, с шебангом (shebang). В данном случаеfilenameбудет содержать название файла, аinterp— путь к интерпретатору Python; -
buf— это массив, заполненный первыми 256 байтами выполняемого файла. Он используется для определения формата файла и загрузки скриптов шебангов.
"binprm" расшифровывается как "binary program" (двоичная программа, бинарник).
Присмотримся к буферу buf:
// include/linux/binfmts.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/binfmts.h#L64
char buf[BINPRM_BUF_SIZE];Как мы видим, его длина определяется через константу BINPRM_BUF_SIZE. Определение этой константы находится в include/uapi/linux/binfmts.h:
// include/uapi/linux/binfmts.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/uapi/linux/binfmts.h#L18-L19
/* sizeof(linux_binprm->buf) */
#define BINPRM_BUF_SIZE 256Таким образом, ядро загружает 256 байт выполняемого файла в этот буфер памяти.
Ремарка: что такое UAPI?
Вы могли заметить, что путь кода выше содержит/uapi/. Почему размер буфера не определяется в том же файлеinclude/linux/binfmts.h, в котором определяется структураlinux_binprm?
UAPI расшифровывается как "userspace API" (интерфейс пользовательского пространства). В данном случае это означает, что кто-то решил, что длина буфера должна быть частью публичного интерфейса ядра. В теории все UAPI является публичным, а все не UAPI является частным для кода ядра.
Код ядра и пространства пользователя изначально сосуществовали в одном месте. В 2012 г. код UAPI был перемещен в отдельную директорию как попытка улучшения поддерживаемости кода.
Шаг 2. Binfmt
Следующей важной задачей ядра является перебор обработчиков (handlers) "binfmt" (binary format — двоичный формат). Эти обработчики определяются в таких файлах, как fs/binfmt_elf.c и fs/binfmt_flat.c. Модули ядра также могут добавлять свои обработчики binfmt в пул (pool).
Каждый обработчик предоставляет функцию load_binary(), которая "берет" структуру linux_binprm и проверяет, понимает ли обработчик формат программы.
Это часто включает в себя поиск магических чисел в буфере, попытку декодировать запуск программы (также из буфера) и/или проверку расширения файла. Если обработчик поддерживает формат, он готовит программу для запуска и возвращает код успеха (success code). В противном случае, происходит ранний выход (early exit) и возврат кода ошибки (error code).
Ядро перебирает функции load_binary() каждого binfmt до тех пор, пока не достигнет успеха. Иногда это происходит рекурсивно. Например, если скрипт имеет определенный интерпретатор, и сам интерпретатор является скриптом, иерархия может быть такой: binfmt_script > binfmt_script > binfmt_elf (где ELF — это исполняемый формат в конце цепочки).
Скрипты
Я специально остановился на binfmt_script.
Вы когда-нибудь читали или писали шебанг? Эту строчку в начале скрипта, определяющую путь к интерпретатору?
#!/bin/bashЯ всегда считал, что это обрабатывается оболочкой, но нет! На самом деле шебанги являются "фичей" ядра, и скрипты выполняются с помощью тех же системных вызовов, что и другие программы. Компьютеры такие клевые!
Взглянем на то, как fs/binfmt_script.c проверяет, начинается ли файл с шебанга:
// fs/binfmt_script.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/binfmt_script.c#L40-L42
/* Файл не выполняется, если не начинается с "#!". */
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;Если файл начинается с шебанга, обработчик binfmt читает путь интерпретатора и любые разделенные пробелами аргументы после пути. Он останавливается по достижении новой строки или конца буфера.
Здесь происходит две интересные вещи.
Во-первых, помните буфер в linux_binprm, который заполняется первыми 256 байтами файла? Он используется не только для определения формата выполняемого файла, но из него также читаются шебанги в binfmt_script.
В ходе исследования я прочитал статью, описывающую этот буфер длиной 128 байт. В некоторый момент после публикации этой статьи размер буфера был увеличен до 256 байт! Почему? Я проверил логи редактирования строки кода, где определяется BINPRM_BUF_SIZE в исходном коде Linux, и вот что я обнаружил:

Поскольку шебанги обрабатываются ядром, и чтение происходит из buf вместо загрузки всего файла, они всегда обрезаются до длины buf. Вероятно, 4 года назад кого-то сильно раздражало, что его пути обрезаются до 128 байт, и они решили удвоить длину. Сегодня, если на Linux у вас есть шебанг, длиннее 256 символов, все, что следует за ними, будет полностью потеряно.

Представьте, что из-за этого у вас случился баг. Представьте, что вы пытаетесь выяснить причину поломки вашего кода. Представьте, что вы будете чувствовать, когда обнаружите, что причина лежит глубоко в ядре Linux. Горе следующему разработчику крупной компании, который обнаружит, что часть пути таинственным образом исчезла.
Во-вторых, помните, что argv[0] для названия программы – это всего лишь соглашение, поэтому вызывающий может передать любые argv в системный вызов, и они пройдут без модерации?
Так получилось, что binfmt_script – это одно из тех мест, где предполагается, что argv[0] – это название программы. argv[0] всегда удаляется, а вместо него (в начало argv) добавляется следующее:
- путь интерпретатора;
- аргументы для него;
- название файла скрипта.
Взглянем на пример вызова execve:
// аргументы: filename, argv, envp
execve("./script", [ "A", "B", "C" ], []);Гипотетический файл script содержит такой шебанг на первой строке:
#!/usr/bin/node --experimental-moduleМодифицированный argv, передаваемый в интерпретатор Node.js, будет выглядеть так:
[ "/usr/bin/node", "--experimental-module", "./script", "B", "C" ]После обновления argv обработчик завершает подготовку файла для выполнения путем установки linux_binprm.interp в значение пути интерпретатора. Наконец, он возвращает 0 в качестве индикатора успешной подготовки программы к выполнению.
Разные интерпретаторы
Другим интересным обработчиком является binfmt_misc. Он позволяет добавлять некоторые ограниченные форматы через настройки пользовательского пространства путем монтирования специальной файловой системы в /proc/sys/fs/binfmt_misc/. Программы могут производить специально отформатированные записи в файлы, находящиеся в этой директории, для добавления собственных обработчиков. Каждая конфигурация содержит информацию о том:
- как определять формат файла. Может определяться магическое число на определенном отступе (offset) или расширение файла для поиска;
- путь к исполняемому файлу интепретатора. Не существует способа определения аргументов интепретатора, для этого необходим скрипт-обертка;
- некоторые флаги конфигурации, включая один, определяющий, как
binfmt_miscобновляетargv.
Эта система binfmt_misc часто используется установками Java, настроенными на обнаружение файлов классов по их магическим байтам 0xCAFEBABE и файлам JAR по их расширению. В моей системе обработчик настроен на обнаружение байткода Python по расширению .pyc и его передачу соответствующему обработчику.
Это позволяет установщикам программ добавлять поддержку собственных форматов без написания высокопривилегированного кода ядра.
В завершение
Системный вызов всегда завершается одной из двух вещей:
- в конце концов, достигается исполняемый двоичный формат, который он понимает, и код выполняется. В этом случае происходит замена старого кода;
- или же после исчерпания всех возможностей в вызываемую программу возвращается код ошибки.
Если вы пользовались системой Unix, то могли заметить, что скрипты оболочки выполняются даже при отсутствии строки шебанга или расширения .sh.
$ echo "echo hello" > ./file
$ chmod +x ./file
$ ./file
hellochmod +x сообщает ОС, что файл является исполняемым. В противном случае, файл выполнить не получится.
Так почему скрипт оболочки выполняется как скрипт оболочки? Обработчики ядра не должны определять скрипты оболочки без явных меток!
На самом деле такое поведение не является частью ядра. Это обычный способ обработки ошибок оболочкой.
Когда мы выполняем файл с помощью оболочки и системный вызов проваливается, большинство оболочек повторяют выполнение файла как скрипта оболочки путем вызова оболочки с названием файла в качестве первого аргумента. Bash, как правило, использует себя в качестве интерпретатора, а ZSH обычно использует оболочку Борна.
Такое поведение является стандартным, поскольку оно определено в POSIX — старом стандарте, разработанном для обеспечения возможности переноса кода между разными системами Unix. Несмотря на то, что POSIX не в полной мере соблюдается большинством инструментов и ОС, многие его соглашения являются общепринятыми.
Если [системный вызов] проваливается из-за ошибки, аналогичной ошибке[ENOEXEC], оболочка должна выполнить аналогичную команду с названием команды в качестве первого операнда и другими аргументами, передаваемыми в новую оболочку. Если исполняемый файл не является текстовым, оболочка может пропустить выполнение этой команды. В этом случае оболочка должна записать сообщение об ошибке и вернуть статус выхода 126.
Источник: Shell Command Language, POSIX.1-2017.
Компьютеры такие клевые!
4. Elf
Теперь мы неплохо разбираемся в execve. В большинстве случаев ядро достигает программы, содержащей машинный код для запуска. Как правило, запуску кода предшествует некоторый процесс настройки, например, разные части программы должны загружаться в правильные места в памяти. Каждая программа нуждается в разном объеме памяти для разных вещей, поэтому у нас имеются стандартные форматы файлов для определения настроек программы для выполнения. Хотя Linux поддерживает много форматов, наиболее распространенным является ELF (executable and linkable format — исполняемый и связанный формат).
Ремарка: эльфы повсюду?
Когда мы запускаем приложение или программу командной строки на Linux, весьма вероятно, что запускается двоичный файл ELF. Однако, в macOS фактическим форматом является Mach-O. Mach-O делает тоже самое, что ELF, но имеет другую структуру. В Windows файлы.exeимеют формат Portable Executable, который следует той же концепции.
В ядре Linux "бинарники" ELF обрабатываются обработчиком binfmt_elf, который является более сложным, чем большинство других обработчиков, и содержит тысячи строк кода. Он отвечает за разбор (парсинг) определенных деталей из файла ELF и использование их для загрузки процесса в память и его выполнение.
$ wc -l binfmt_* | sort -nr | sed 1d
2181 binfmt_elf.c
1658 binfmt_elf_fdpic.c
944 binfmt_flat.c
836 binfmt_misc.c
158 binfmt_script.c
64 binfmt_elf_test.cСтруктура файла
Перед рассмотрением того, как binfmt_elf выполняет файлы ELF, давайте взглянем на сам формат файла. Файлы ELF, как правило, состоят из 4 частей:

ELF Header
Каждый файл ELF имеет заголовок. У него очень важная роль — передача такой базовой информации о бинарнике, как:
- для какого процессора он предназначен. Файлы ELF могут содержать машинный код для разных типов процессора, таких как ARM и x86;
- предполагается ли запуск бинарника как исполняемого файла или его загрузка другой программой как "динамически связанной библиотеки". Мы поговорим о динамическом связывании позже;
- входная точка исполняемого файла. Определяется, куда конкретно в памяти загружать данные из файла ELF. Входная точка – это адрес в памяти, указывающий, где в памяти находится первая инструкция машинного кода после загрузки всего процесса.
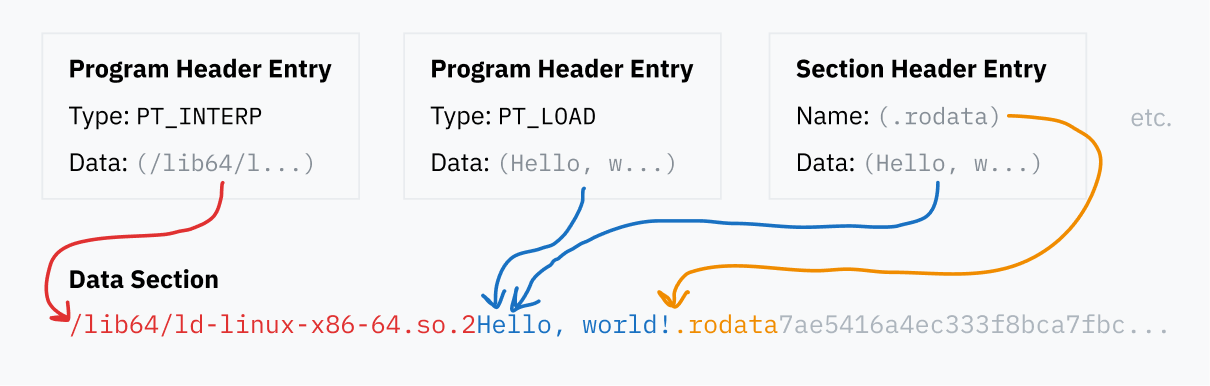
Заголовок ELF всегда находится в начале файла. Он определяет локации таблицы заголовков программы (program header table) и таблицы заголовков разделов (section header table), которые могут находиться в любом месте внутри файла. Эти таблицы, в свою очередь, указывают на данные, хранящиеся где-то в файле.
Таблица заголовков программы
Таблица заголовков программы — это серия записей (entries), содержащих детали загрузки и запуска бинарника во время выполнения (runtime). Каждая запись имеет поле type (тип), сообщающее, какие детали она определяет: например, PT_LOAD означает, что запись содержит данные, которые должны быть загружены в память, а PT_NOTE означает сегмент, содержащий информационный текст, который может никуда не загружаться.

Каждая запись содержит информацию о том, где находятся данные в файле, и иногда о том, как загрузить данные в память:
- она указывает на позицию данных в файле ELF;
- она может определять адрес памяти, в который должны быть загружены данные. Если данные не должны загружаться в память, этот сегмент остается пустым;
- 2 поля определяют длину данных: одно для длины данных в памяти, другое для длины области памяти для создания. Если длина памяти превышает длину файла, дополнительная память заполняется нулями. Это позволяет программам резервировать статическую память для использования во время выполнения. Эти пустые сегменты памяти обычно называются сегментами BSS;
- наконец, поле
flagsопределяет, какие операции разрешаются при загрузке в память:PF_Rделает данные доступными только для чтения,PF_W— для записи,PF_X— для выполнения в ЦП.
Таблица заголовков разделов
Таблица заголовков разделов – это серия записей, содержащих информацию о разделах. Информация о разделе – это как карта, отображающая данные внутри файла ELF. Это облегчает понимание предполагаемого использования частей данных программами вроде отладчиков.
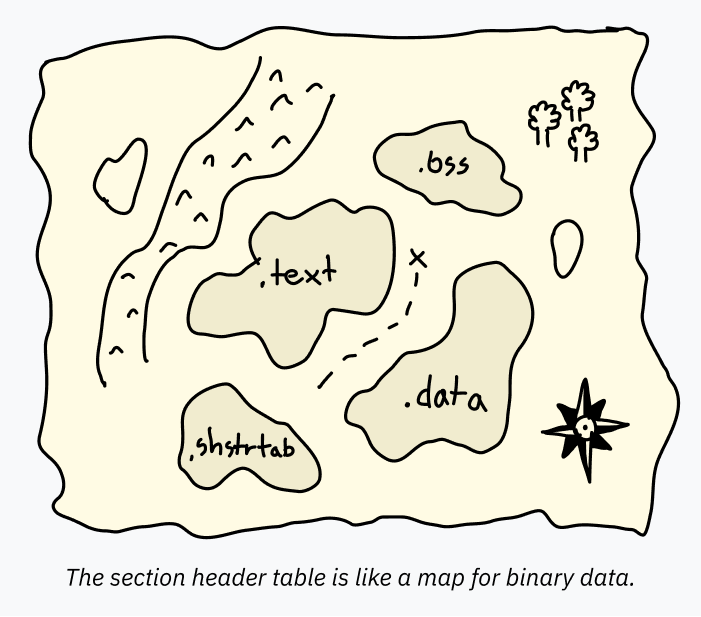
Например, таблица заголовков программы может определять большой набор данных для загрузки в память целиком. Один блок PT_LOAD может содержать как код, так и глобальные переменные! Для запуска программы их раздельное определение не требуется. ЦП начинает с входной точки и двигается вперед, извлекая данные по запросам программы. Однако, ПО типа отладчика для анализа программы должно точно знать, где начинается и заканчивается каждая часть данных, в противном случае, оно может попытаться декодировать строку "hello" как код (и поскольку строка не является валидным кодом, "взорваться"). Такая информация хранится в таблице заголовков разделов.
Хотя таблица заголовков разделов обычно включается, она на самом деле является опциональной. Файлы ELF могут прекрасно выполняться при полном удалении этой таблицы. Разработчики, которые хотят спрятать свой код, иногда намеренно удаляют или искажают ее в бинарниках ELF, чтобы затруднить их декодирование.
Каждый раздел содержит название (name), тип (type) и некоторые флаги, которые определяют, как данные должны использоваться и декодироваться. Стандартные названия обычно начинаются с точки по соглашению. Наиболее распространенными разделами являются:
-
.text— машинный код для загрузки в память и выполнения в ЦП. ТипSHT_PROGBITSс флагомSHF_EXECINSTRпомечает его как исполняемый. ФлагSHF_ALLOCозначает загрузку в память для выполнения; -
.data— инициализированные данные, жестко закодированные в исполняемом файле для загрузки в память. В этой секции может находиться, например, глобальная переменная, содержащая некоторый текст. Если вы пишете низкоуровневый код, это раздел, где "живет" статика. ТипSHT_PROGBITSпросто означает, что раздел содержит "информацию для программы". ФлагиSHF_ALLOCиSHF_WRITEобозначают его как доступную для записи память; -
.bss— ранее я упоминал, что обычно часть выделенной памяти начинается с нуля. Помещать кучу пустых байтов в файл ELF неразумно, для этого предназначен раздел BSS. О сегментах BSS полезно знать в процессе отладки. В таблице заголовков разделов есть запись, определяющая длину памяти для выделения. Типом здесь являетсяSHT_NOBITS, а флагами —SHF_ALLOCиSHF_WRITE; -
.rodata— это те же.data, но доступные только для чтения. В самой простой программе на языке C, запускающейprintf("Hello, world!"), строка "Hello, world!" будет находиться в разделе.rodata, а сам код отображения (printing code) — в разделе.text; -
.shstrtab— это забавный факт реализации! Сами названия разделов (такие как.textи.shtrtab) не включаются в таблицу заголовков разделов. Каждая запись содержит отступ (offset) к локации в файле ELF, содержащей ее название. Это облегчает парсинг записей таблицы благодаря их фиксированному размеру (отступ – это число фиксированного размера, а для включения в таблицу названия требуется строка переменного размера). Все эти данные о названиях хранятся в отдельном разделе.shstrtabс типомSHT_STRTAB.
Данные
Программа и записи таблицы разделов заголовков указывают на блоки данных внутри файла ELF, то ли загрузить их в память, то ли определить местонахождение кода, то ли просто именовать разделы. Все эти разные части данных содержатся в разделе "Data" файла ELF.
Краткое объяснение связывания
Вернемся к коду binfmt_elf: ядро заботится о двух типах записей из таблицы заголовков программы.
Сегменты PT_LOAD определяют, куда должны загружаться все данные программы, такие как разделы .text и .data. Ядро читает эти сущности из файла ELF для загрузки данных в память, чтобы программа могла быть выполнена ЦП.
Другим типом записей таблицы заголовков программы, о котором заботится ядро, является PT_INTERP, определяющим "время выполнения динамической компоновки" (dynamic linking runtime).
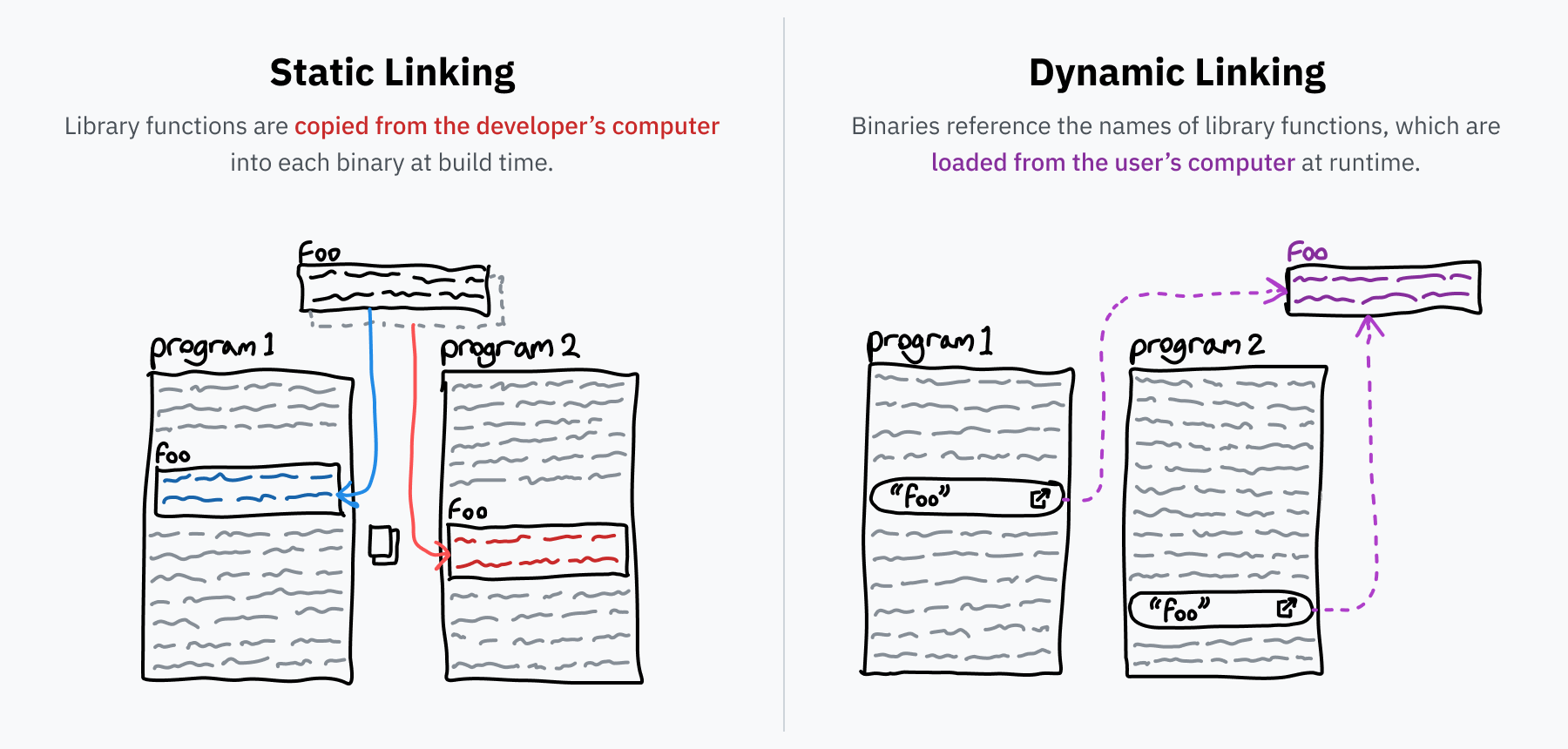
Начнем с того, что такое "связывание" или "компоновка" (linking). Программисты, как правило, пишут программы поверх библиотек повторно используемого кода, например, libc, о которой упоминалось ранее. При преобразовании исходного кода в исполняемый бинарник, программа вызывает компоновщик (linker), разрешающий все ссылки, определяя код библиотеки и копируя его в бинарник. Этот процесс называется "статическим связыванием" (static linking) – внешний код включается прямо в распространяемый файл.
Некоторые библиотеки являются очень популярными. Та же libc используется почти всеми программами, поскольку она представляет собой канонический интерфейс для взаимодействия с ОС через системные вызовы. Что делать? Включать отдельную копию libc в каждую программу на компьютере? Что если в libc появился баг? Придется обновлять все программы? Эти проблемы решаются за счет динамической компоновки.
Если статически связанной программе требуется функция foo() из библиотеки bar, копия этой функции включается в программу. Однако, при динамическом связывании в программу включается только ссылка, как бы говорящая "мне нужна foo() из bar". При запуске программы (при условии, что bar установлена на компьютере) машинный код функции foo() загружается в память по требованию (on-demand). При обновлении установки bar, новый код загружается в программу при ее следующем запуске без необходимости изменения самой программы.
Динамическая компоновка в дикой природе
В Linux динамически связанные библиотеки вроде bar, как правило, упаковываются в файлы с расширением .so (shared object – общий объект). Эти файлы .so являются такими же файлами ELF, как и программы. Заголовок ELF содержит поле, определяющее, чем является файл, исполняемым файлом или библиотекой. Кроме того, общие объекты содержат раздел .dynsym в таблице заголовков разделов, в котором содержится информация о том, какие символы (symbols) экспортируются из файла и могут быть динамически связаны.
В Windows библиотеки вроде bar упаковываются в файлы с расширением .dll (dynamic link library – динамически подключаемая библиотека). В macOS используется расширение .dylib (dynamically linked library — динамически подключенная библиотека). Также как приложения macOS и файлы .exe Windows, эти форматы немного отличаются от файлов ELF, но следуют той же концепции и технике.
Интересным отличием двух типов связывания является то, что при статическом связывании в исполняемый файл включается (загружается в память) только используемая часть библиотеки. В случае динамического связывания в память загружается вся библиотека. На первый взгляд, это кажется менее эффективным, но на самом деле это позволяет современным ОС сохранять больше пространства путем однократной загрузки библиотеки в память и распределения кода между процессами. Совместно использоваться может только код, поскольку библиотеке требуется разное состояние для разных программ, но экономия все равно может составлять порядка десятков и сотен МБ ОЗУ.
Выполнение
Вернемся к ядру, выполняющему файлы ELF: если исполняемый бинарник является динамически связанным, ОС не может сразу перейти к его коду, поскольку в наличии имеется не весь код — динамически связанные программы содержат только ссылки на функции необходимых им библиотек!
Для запуска бинарника ОС необходимо определить требуемые библиотеки, загрузить их, заменить все именованные указатели реальными инструкциями по переходу и затем запустить полный код программы. Это очень сложный код, глубоко взаимодействующий с форматом ELF, поэтому он обычно представляет собой отдельную программу, а не часть ядра. Файлы ELF определяют путь к программе, которую они хотят использовать (что-то типа /lib64/ld-linux-x86-64.so.2) в записи PT_INTERP таблицы заголовков программы.
После чтения заголовка ELF и сканирования таблицы заголовков программы, ядро настраивает структуру памяти для программы. Все начинается с загрузки в память всех сегментов PT_LOAD, статических данных, пространства BSS и машинного кода программы. Если программа является динамически связанной, ядро должно выполнить интерпретатор ELF (PT_INTERP), поэтому оно также загружает в память данные, BSS и код интерпретатора.
Теперь ядру необходимо установить указатель инструкции для ЦП с целью восстановления при возвращении в пространство пользователя. Если исполняемый файл является динамически связанным, ядро устанавливает указатель инструкции в начало кода интерпретатора ELF в памяти. Иначе, ядро устанавливает его в начало исполняемого файла.
Ядро почти готово к возврату из системного вызова (помните, что мы по-прежнему находимся в execve). Оно отправляет argc, argv и переменные среды окружения в стек для чтения программой при запуске.
После этого регистры очищаются. Перед обработкой системного вызова ядро сохраняет текущее значение регистров в стеке для его последующего восстановления при переключении обратно на пространство пользователя. Перед возвращением в пользовательское пространство, ядро заполняет эту часть стека нулями.
Наконец, системный вызов завершается и ядро возвращается в пространство пользователя. Оно восстанавливает регистры, которые теперь заполнены нулями, и переходит к сохраненному указателю инструкции. Этот указатель теперь является начальной точкой новой программы (или интерпретатора ELF), и текущий процесс заменяется новым!
5. Преобразователь
До сих пор все наши разговоры о чтении и записи в память были слегка невнятными. Например, файлы ELF определяют конкретные адреса памяти для загрузки данных, так почему не возникает проблем с процессами, которые пытаются использовать одинаковые адреса? Почему кажется, что каждый процесс имеет доступ к разной памяти?
Мы понимаем, что execve – это системный вызов, заменяющий текущий процесс новой программой, но это не объясняет, как несколько процессов могут запускаться одновременно. Это также не объясняет, как запускается самая первая программа – процесс, порождающий (spawn) другие процессы.
Память – это фикция
Оказывается, что когда ЦП читает из или пишет в адрес памяти, речь идет не о локации в физической памяти (ОП). Это место в пространстве виртуальной памяти (virtual memory space).
ЦП "общается" с чипом под названием блок управления памятью (memory management unit, MMU). MMU с помощью словаря переводит локации в виртуальной памяти в локации в ОП. Когда ЦП получает инструкцию о чтении из адреса памяти 0xAD4DA83F, он обращается к MMU для перевода адреса. MMU "смотрит" в словарь, находит совпадающий физический адрес 0x70B7BD74 и возвращает это число ЦП. После этого ЦП читает из этого адреса в ОП.

После включения компьютер работает с физической ОП. Сразу после этого ОС создает словарь и указывает ЦП использовать MMU.
Этот словарь называется "таблицей страниц" (page table), а система перевода каждого адреса памяти называется "пейджингом" или "подкачкой" (paging). Записи таблицы страниц называются "страницами" (pages). Страница представляет собой связь определенной части (chunk) виртуальной памяти с ОП. Эти части всегда имеют фиксированный размер, у каждой архитектуры процессора он свой. Размер страницы x86-64 составляет 4 КБ, т.е. каждая страница определяет связь для блока памяти длиной 4096 байт (x86-64 позволяет ОС иметь большие страницы, размером 2 МБ или 4 ГБ, что повышает скорость преобразования адресов, но увеличивает фрагментацию и потери памяти).
Сама таблица страниц просто лежит в ОП. Хотя она может содержать миллионы записей, размер каждой записи составляет всего пару байт, поэтому она не занимает много места.
Для того чтобы включить подкачку при загрузке, ядро сначала создает таблицу страниц в ОП. Затем оно сохраняет физический адрес начала таблицы страниц в регистре под названием "базовый регистр таблицы страниц" (page table base register, PTBR). Наконец, ядро включает подкачку для преобразования всех адресов памяти с помощью MMU. В x86-64 старшие 20 бит регистра управления 3 (CR3) функционируют как PTBR. Бит 31 регистра CR0 (PG) устанавливается в 1 для разрешения подкачки.
Магия таблицы страниц заключается в возможности ее редактирования в процессе работы компьютера. Это позволяет каждому процессу иметь собственное изолированное пространство памяти, когда ОС переключает контекст от одного процесса к другому, важно привязать пространство виртуальной памяти к другой области физической памяти. Предположим, что у нас имеется два процесса: код и данные (вероятно, загруженные из файла ELF) процесса А находятся в 0x0000000000400000, а процесс Б получает доступ к коду и данным по тому же адресу. Эти два процесса даже могут быть экземплярами одной программы, поскольку между ними не возникает конфликтов из-за памяти! В физической памяти данные для процесса А лежат далеко от процесса Б, привязка к 0x0000000000400000 выполняется ядром при переключении процессов.
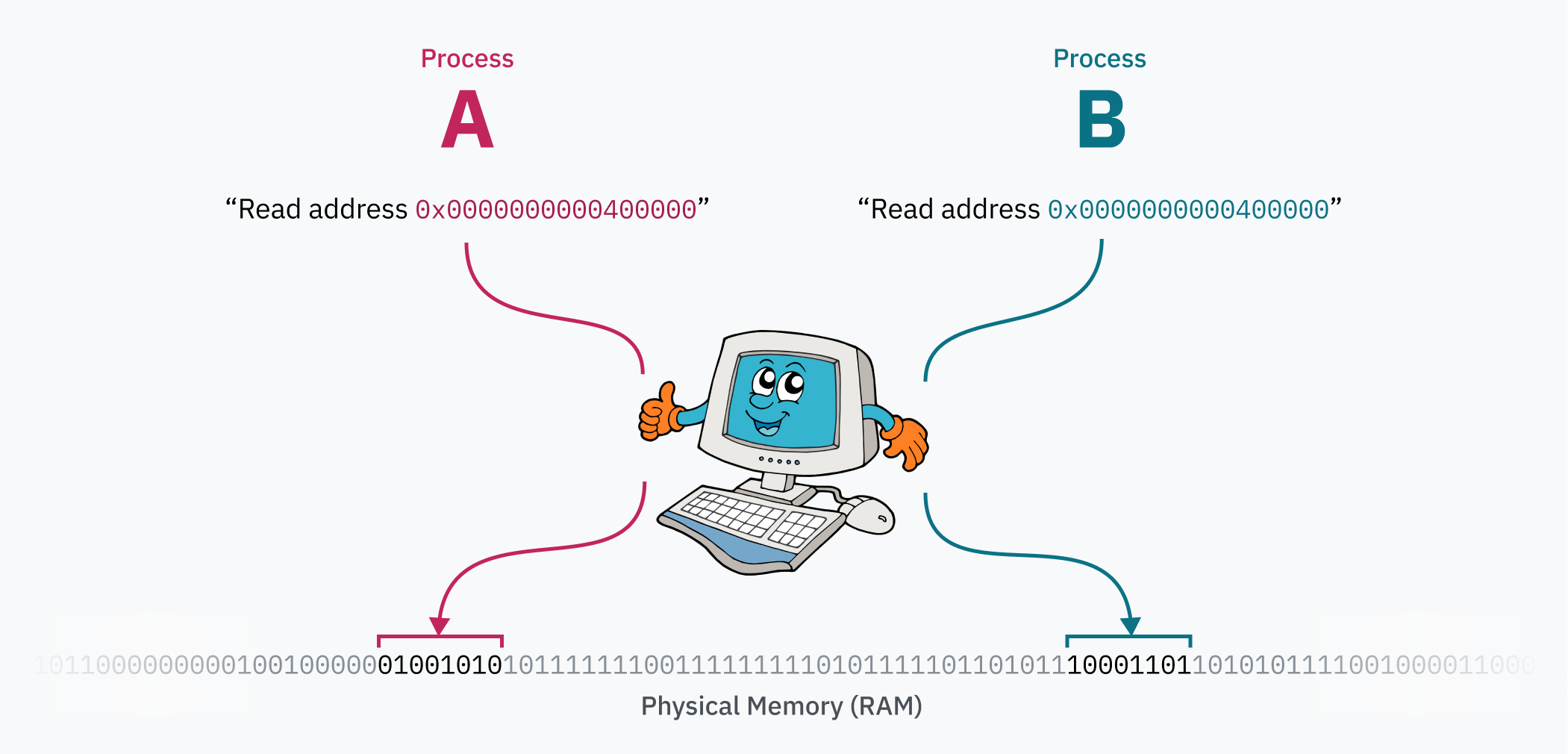
Ремарка: негативный факт о ELF.
В некоторых ситуацияхbinfmt_elfдолжен сопоставить первую страницу памяти с нулями. Некоторые программы, написанные для UNIX System V Release 4.0 (SVr4), ОС 1988 г., первой поддерживающей ELF, полагаются на читаемость нулевых указателей. Каким-то чудесным образом некоторые программисты все еще полагаются на такое поведение.
Похоже, разработчик ядра Linux, реализовавший это, был немного недоволен:
"Вы спрашиваете, зачем??? Ну, SVr4 отображает страницу как доступную только для чтения и некоторые приложения "зависят" от этого поведения. Поскольку у нас нет возможности их перекомпилировать, мы вынуждены эмулировать поведение SVr4. Вздох."
Безопасность подкачки
Изоляция процессов, обеспечиваемая подкачкой памяти, не только улучшает эргономику кода (процессам не нужно беспокоиться об использовании памяти другими процессами), но и создает уровень безопасности: одни процессы не имеют доступа к памяти других процессов. Это половина ответа на вопрос:
Если программы выполняются прямо в ЦП, а ЦП имеет прямой доступ к ОП, почему код не может получить доступ к памяти другого процесса или, прости господи, ядра?
Что насчет памяти ядра? На самом деле, ядру требуется хранить много собственных данных для отслеживания всех запущенных процессов и той же таблицы страниц. При каждом прерывании или запуске системного вызова, когда ЦП входит в режим ядра, ядро должно каким-то образом получить доступ к этой памяти.
Решение Linux состоит в том, чтобы всегда выделять верхнюю половину виртуальной памяти ядру, поэтому Linux называется ядром старшей половины (higher half kernel). Windows практикует похожую технику, а macOS… немного более сложная (прим. пер.: обратите внимание, что здесь три разных ссылки).

С точки зрения безопасности будет ужасным, если пользовательские процессы будут иметь доступ к памяти ядра, поэтому подкачка добавляет второй слой безопасности: каждая страница должна определять флаги разрешений (permission flags). Один флаг определяет, доступна область памяти только для чтения или также для записи. Другой флаг сообщает ЦП, что только ядро имеет доступ к области. Этот флаг используется для защиты всего пространства старшей половины ядра – на самом деле пользовательским программам доступно все пространство памяти ядра в карте виртуальной памяти, они просто не имеют соответствующих разрешений.

Сама таблица страниц фактически содержится в пространстве памяти ядра! Когда чип таймера запускает аппаратное прерывание для переключения процессов, ЦП переключает уровень привилегий и переходит к коду ядра Linux. Нахождение в режиме ядра (кольцо 0 Intel) позволяет ЦП обращаться к защищенной области памяти ядра. Затем ядро может писать в таблицу страниц (которая находится где-то в этой верхней половине памяти) для повторной привязки нижней части виртуальной памяти для нового процесса. Когда ядро переключается к новому процессу и ЦП входит в режим пользователя, его доступ к памяти ядра закрывается.
Почти любой доступ к памяти проходит через MMU. Что насчет указателей обработчика таблицы дескрипторов прерываний? Они также обращаются к пространству виртуальной памяти ядра.
Иерархическая подкачка и другие оптимизации
64-битные системы имеют адреса памяти длиной 64 бита, следовательно, 64-битное пространство виртуальной памяти имеет размер колоссальных 16 эксбибайт. Это невероятно много, намного больше, чем может похвастаться любой современный компьютер или компьютер ближайшего будущего. Насколько мне известно, больше все ОП (больше 1,5 патебайт — менее 0,01% от 16 ЭБ) было у суперкомпьютера Blue Waters.
Если запись в таблице страниц требуется для каждого раздела виртуальной памяти размером 4 КБ, потребуется 4 503 599 627 370 496 таких записей. С записями таблицы страниц длиной 8 байт потребуется 32 пебибайта ОП только для хранения таблицы. Как видите, это по-прежнему превышает мировой рекорд по объему ОП в компьютере.
Поскольку невозможно (или, как минимум, очень непрактично) иметь последовательные записи таблицы страниц для всего возможного пространства памяти, архитектуры ЦП реализуют иерархическое разбиение по страницам (иерархическую подкачку — hierarchical paging). В таких системах существует несколько уровней таблиц страниц со все более мелкой степенью детализации. Записи верхнего уровня охватывают большие блоки памяти и указывают на таблицы страниц меньших блоков, создавая древовидную структуру (tree). Отдельные записи для блоков 4 КБ или любого другого размера являются листьями (leaves) дерева.
В x86-64 исторически используется четырехуровневая иерархическая подкачка. В этой системе каждая запись в таблице страниц определяется путем смещения начала содержащей ее таблицы на часть (portion) адреса. Эта часть начинается со старших битов, которые работают как префикс, поэтому запись охватывает все адреса, начинающиеся с этих битов. Запись указывает на начало следующего уровня таблицы, содержащей поддеревья для этого блока памяти, которые снова индексируются следующим набором битов.
Разработчики четырехуровневой подкачки также решили игнорировать старшие 16 бит всех виртуальных указателей в целях экономии места в таблице страниц. 48 бит дают нам виртуальное адресное пространство размером 128 ТБ, что считается достаточно большим.
Поскольку первые 16 бит пропущены, "самые значащие биты" (most significant bits) для индексации первого уровня таблицы страниц фактически начинаются с 47-го, а не с 63-го бита. Это также означает, что приведенная выше диаграмма старшей половины ядра была технически неточной: начальный адрес пространства ядра должен быть изображен как середина адресного пространства размером менее 64 бит.
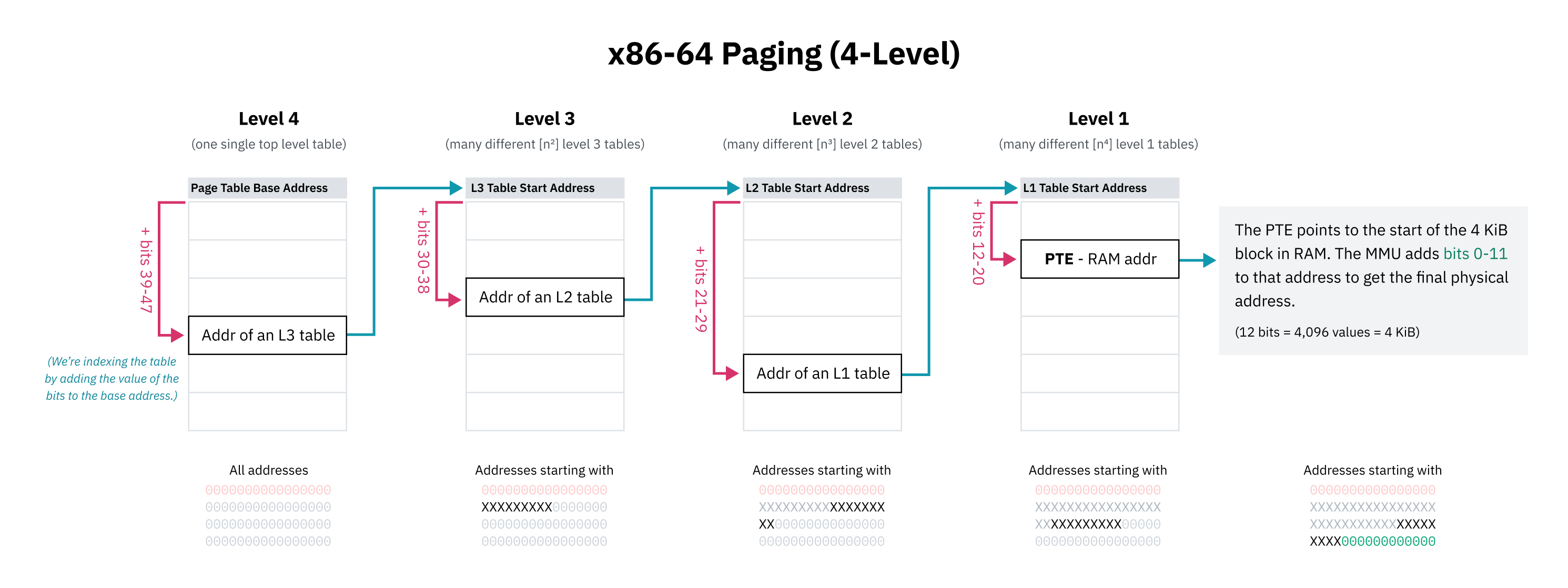
Иерархическая подкачка решает проблему с пространством, поскольку на любом уровне дерева указатель на следующую запись может быть нулевым (0x0). Это позволяет исключить целые поддеревья таблицы страниц – неотображаемые (unmapped) области не занимают место в ОП. Поиск по несвязанным адресам памяти быстро завершается ошибкой, поскольку ЦП возвращает ошибку, как только встречает пустую запись выше по дереву. С помощью флага присутствия (presence flag) записи таблицы страниц могут быть помечены как непригодные для использования, даже если адрес выглядит валидным.
Еще одним преимуществом иерархической подкачки является возможность эффективного переключения больших разделов виртуальной памяти. Большой участок виртуальной памяти может сопоставляться с одной областью физической памяти для одного процесса и с другой областью для другого процесса. Ядро может хранить оба отображения в памяти и просто обновлять указатели на верхнем уровне дерева при переключении процессов. Если бы вся карта пространства памяти хранилась в виде плоского массива записей, ядру пришлось бы обновлять множество записей, что было бы медленным и требовало бы независимого отслеживания отображений памяти для каждого процесса.
Я сказал, что x86-64 "исторически" использует четырехуровневую подкачку, потому что последние процессоры реализуют пятиуровневую подкачку. Пятиуровневая подкачка добавляет еще один уровень абстракции, а также еще 9 бит адресации для расширения адресного пространства до 128 ПБ с 57-битными адресами. Такая подкачка поддерживается Linux с 2017 г., а также последними серверными версиями Windows 10 и 11.
Ремарка: ограничения физического адресного пространства.
ОС не используют все 64 бита виртуальных адресов, а ЦП не используют все 64 бита физических адресов. Когда 4-уровневая подкачка была стандартом, процессоры x86-64 не использовали более 46 бит. Это означало, что физическое адресное пространство было ограничено всего 64 ТБ. Процессоры с 5-уровневой подкачкой используют до 52 бит, поддерживая физическое адресное пространство до 4 ПБ.
На уровне ОС выгодно, чтобы виртуальное пространство было больше физического. Как сказал Линус Торвальдс: "[виртуальное пространство должно быть больше физического], по крайней мере, в 2 раза, а лучше в 10 и более. Кто этого не понимает, тот дурак. Конец дискуссии".
Обмен и подкачка по требованию
Доступ к памяти может завершиться ошибкой по нескольким причинам: адрес может находиться за пределами допустимого диапазона, он может не отображаться в таблице страниц или он может содержать запись, помеченную как отсутствующая. Во всех этих случаях MMU инициирует аппаратное прерывание, которое называется "отказом страницы" (page fault), чтобы передать управление ядру.
В случаях, когда чтение действительно было невалидным или запрещенным, ядро завершает программу с ошибкой сегментации (segmentation fault, segfault):
$ ./program
Segmentation fault (core dumped)Ремарка: происхождение segfault.
"Ошибка сегментации" означает разные вещи в зависимости от контекста. MMU запускает аппаратное прерывание, которое называется "ошибкой сегментации", когда происходит чтение памяти без разрешения, но "ошибка сегментации" — это также название сигнала, который ОС посылает работающей программе с целью ее принудительного завершения в связи с нелегальным доступом к памяти.
В других случаях доступ к памяти может быть "намеренно" неудачным, что позволяет ОС заполнить память и передать управление ЦП для повторной попытки. Например, ОС может сопоставить файл на диске с виртуальной памятью, не загружая его в ОП, и произвести такую загрузку только при запросе адреса и возникновении ошибки страницы (page fault). Это называется "подкачкой по требованию" (demand paging).

Это позволяет существовать таким системным вызовам, как mmap, которые лениво (отложенно — lazily) отображают целые файлы с диска в виртуальную память. Джастин Танни недавно значительно оптимизировал LLaMa.cpp, среду выполнения языковой модели Facebook, заставив всю логику загрузки использовать mmap.
При выполнении программы и ее библиотек, ядро фактически ничего не загружает в память. Создается только файл mmap — когда ЦП пытается выполнить код, немедленно возникает ошибка страницы, и ядро заменяет страницу реальным блоком памяти.
Подкачка по требованию также позволяет использовать метод, известный под названием "обмен" (swapping) или просто "подкачка". ОС могут освобождать физическую память, записывая страницы памяти на диск, а затем удаляя их из физической памяти, но сохраняя их в виртуальной памяти с флагом присутствия, установленным в 0. При чтении этой виртуальной памяти ОС восстанавливает память с диска в ОП и устанавливает флаг присутствия обратно в 1. При этом, ОС может менять местами разделы ОЗУ, чтобы освободить место для памяти, загружаемой с диска. Операции чтения и записи на диск являются медленными, поэтому ОС стараются свести подкачку к минимуму с помощью эффективных алгоритмов замены страниц.
Интересным приемом является использование указателей на физическую память таблицы страниц для хранения локаций файлов в физической памяти. Поскольку MMU возвращает ошибку страницы, как только увидит отрицательный флаг присутствия, валидным является адрес или нет, значения не имеет.
6. Вилки и коровы
Прим. пер.: автор играет со словами "fork" и "cow".
Последний вопрос: откуда берется первый процесс?
Если execve запускает новую программу, заменяя текущий процесс, то как запустить новую программу отдельно, в новом процессе? Это важно, если мы хотим делать несколько вещей на компьютере одновременно: когда мы дважды кликаем по иконке приложения, оно запускается отдельно, в то время как программа, в которой мы работали ранее, продолжает работать.
Ответом является другой системный вызов: fork, лежащий в основе многозадачности. fork очень прост: он клонирует (копирует) текущий процесс и его память, не трогая сохраненный указатель инструкции, и затем позволяет обоим процессам продолжаться. Программы продолжают работать независимо друг от друга, а все вычисления удваиваются.
Новый запущенный процесс называется "дочерним" (child), а клонируемый — "родительским" (parent). Процессы могут вызывать fork несколько раз, порождая много детей (потомков). Каждый потомок нумеруется с помощью идентификатора процесса (process ID, PID), который начинается с 1.
Бездумное дублирование кода довольно бесполезно, поэтому fork возвращает разные значения для родительского и дочернего процессов. Для предка он возвращает PID нового дочернего процесса, а для потомка — 0. Это позволяет выполнять другую работу в новом процессе, так что разветвление (forking) действительно полезно.
pid_t pid = fork();
// С этой точки код продолжается как обычно, но через
// два "одинаковых" процесса.
//
// Одинаковых... за исключением PID, возвращаемого из `fork()`!
//
// Это единственный индикатор того, что мы имеем дело
// с разными программами.
if (pid == 0) {
// Мы находимся в дочернем процессе.
// Производим некоторые вычисления и передаем результат предку!
} else {
// Мы в родительском процессе.
// Продолжаем делать то, что делали.
}Разветвление процесса может быть немного сложным для понимания. Будем считать, что вы знаете, как оно работает. Если нет, то загляните на этот неприглядный сайт с хорошим объяснением.
Таким образом, программы Unix запускают новые программы, вызывая fork и запуская execve в новом дочернем процессе. Это называется "шаблоном fork-exec" (fork-exec pattern). При запуске программы наш компьютер выполняет примерно такой код:
pid_t pid = fork();
if (pid == 0) {
// Заменяем дочерний процесс новой программой.
execve(...);
}
// Если мы попали сюда, значит, процесс не был заменен. Мы находимся в родительском процессе!
// PID дочернего процесса хранится в переменной `pid` на случай,
// если мы захотим его убить.
// Здесь продолжается код родительской программы...Мууу!
Вы могли заметить, что дублирование памяти процесса только для того, чтобы ее отбросить при загрузке другой программы, звучит немного неэффективно. Дублирование данных в физической памяти – это медленный процесс, но не дублирование таблиц страниц, поэтому мы просто не дублируем ОП: мы создаем копию таблицы страниц старого процесса для нового процесса – отображение указывает на ту же самую нижележащую физическую память.
Но дочерний процесс должен быть независим и изолирован от родительского! Нехорошо, если потомок будет писать в память предка, и наоборот!
Представляю вам COW (copy on write – копирование при записи, cow – корова). COW позволяет обоим процессам читать из одних и тех же физических адресов до тех пор, пока они не пытаются осуществить запись в память. Как только процесс пытается это сделать, данная страница копируется в ОП. Это позволяет обоим процессам иметь изолированную память без клонирования всего пространства памяти. Это обуславливает эффективность паттерна fork-exec. Поскольку ни один из старых процессов не пишет в память до загрузки нового бинарника, память не копируется.
COW реализована, как и много других забавных вещей, через хаки страниц (page hacks) и обработку аппаратного прерывания. После клонирования страниц с помощью fork, он помечает (устанавливает соответствующие флаги) страницы обоих процессов как доступные только для чтения. Это запускает segfault (разновидность аппаратного прерывания), которое обрабатывается ядром. Ядро, дублирующее память, обновляет страницу для разрешения записи и возвращается из прерывания для выполнения повторной попытки записи.
В начале
Каждый процесс на компьютере является результатом клонирования-выполнения (fork-execed) родительской программы, кроме одного: процесса инициализации (init process). Процесс инициализации устанавливается ядром вручную. Это первая пользовательская программа при запуске и последняя при завершении.
Хотите увидеть клевый мгновенный черный экран? Если у вас macOS или Linux, сохраните свою работу, откройте терминал и убейте процесс инициализации (PID 1):
$ sudo kill 1Ремарка: знания о процессе инициализации, к сожалению, применимы только к Unix-подобным системам, вроде macOS или Linux. Большая часть того, что вы изучите далее, неприменима к Windows, архитектура ядра которой сильно отличается.
Процесс инициализации отвечает за создание всех программ и служб, которые составляют ОС. Многие из них, в свою очередь, создают собственные сервисы и программы.
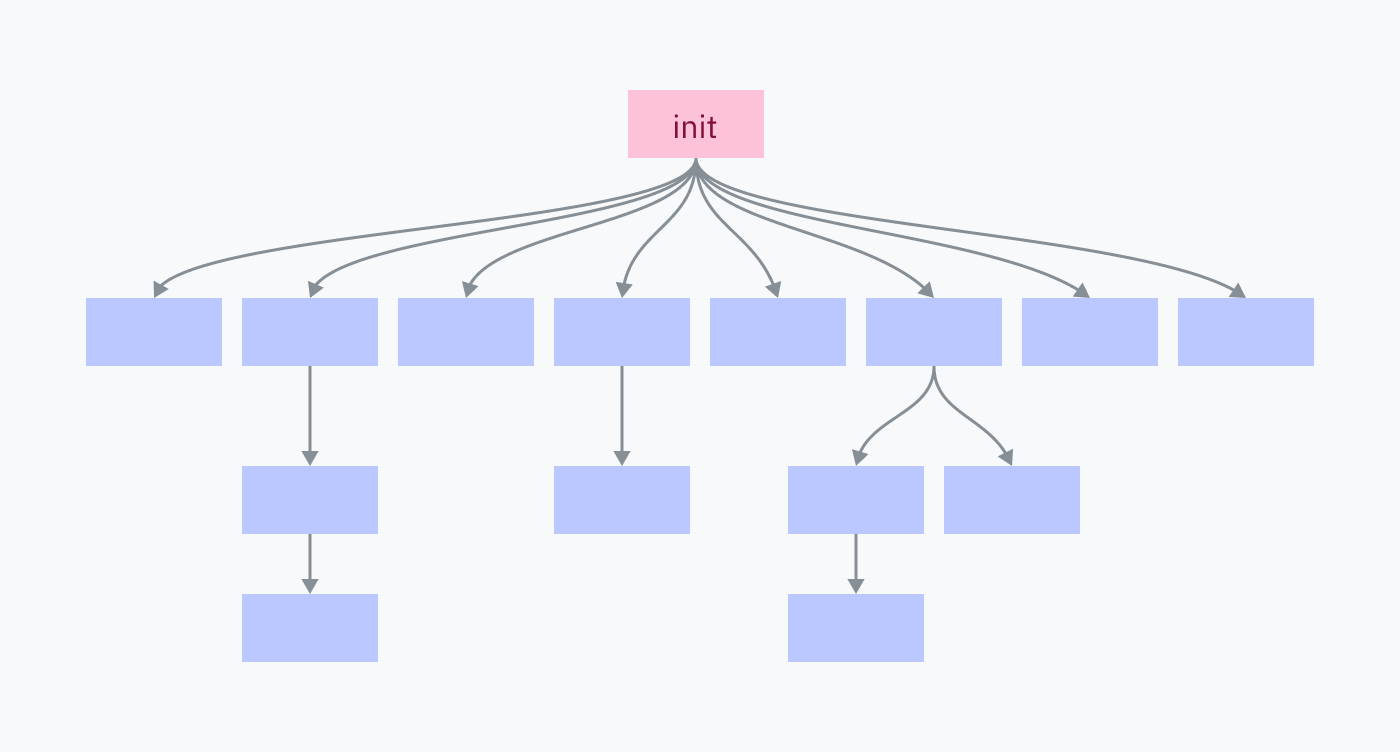
Завершение процесса инициализации завершает всех его потомков и всех их потомков, что приводит к завершению работы ОС.
Возвращаемся к ядру
Рассмотрим, как ядро запускает процесс инициализации.
Компьютер выполняет последовательность следующих вещей:
- Материнская плата поставляется с небольшим ПО, выполняющем поиск программы, которая называется "загрузчиком" (bootloader) в подключенных дисках. Она выбирает загрузчик, загружает его машинный код в ОП и выполняет этот код. Помните, что ОС еще не запущена. До запуска процесса инициализации многозадачности и системных вызовов не существует. В контексте, предшествующем инициализации, "выполнение" программы означает прямой переход к машинному коду в ОП без ожидания возврата.
- Загрузчик отвечает за обнаружение ядра, его загрузку в ОП и выполнение. Некоторые загрузчики, такие как GRUB, можно настраивать и/или выбирать между несколькими ОС. Встроенными загрузчиками macOS и Windows являются BootX и Windows Boot Manager, соответственно.
- Ядро запускается и приступает к выполнению большого количества задач по инициализации, включая установку обработчиков прерываний, загрузку драйверов и создания начального отображения памяти. Наконец, ядро переключается в режим пользователя и запускает программу инициализации.
- Теперь мы находимся в пространстве пользователя ОС! Программа инициализации выполняет скрипты инициализации, запускает сервисы и выполняет программы вроде оболочки/UI (user interface — пользовательский интерфейс).
Инициализация Linux
В Linux инициализация ядра (шаг 3) происходит в функции start_kernel в init/main.c. Эта функция вызывает более 200 других функций инициализации, поэтому я не буду включать в статью весь код, но рекомендую с ним ознакомиться. В конце start_kernel вызывается функция arch_call_rest_init:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L1087-L1088
/* Делаем остальное без "__init", теперь мы живы */
arch_call_rest_init();Ремарка: что значит без __init?
Функцияstart_kernelопределяется какasmlinkage __visible void __init __no_sanitize_address start_kernel(void). Странные слова__visible,__initи__no_sanitize_addressявляются макросами препроцессора C и используются ядром Linux для добавления различного кода и поведения в функцию.
В данном случае,__init– это макрос, указывающий ядру выгрузить функцию и ее данные из памяти по завершении процесса запуска для сохранения пространства.
Как это работает? Если не погружаться слишком глубоко в детали, само ядро Linux упаковано в виде файла ELF. Макрос__initпревращается в__section(".init.text"), директиву компилятора для помещения кода в раздел.init.textвместо обычного раздела.text. Другие макросы также позволяют данным и константам помещаться в специальные разделы, например,__initdataпревращается в__section(".init.data").
arch_call_rest_init – это всего лишь функция-обертка:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L832-L835
void __init __weak arch_call_rest_init(void)
{
rest_init();
}В комментарии говорится "делаем остальное без __init", поскольку rest_init не определяется с помощью макроса __init. Это означает, что она не выгружается для очистки памяти:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L689-L690
noinline void __ref rest_init(void)
{Далее rest_init создает поток (thread) для процесса инициализации:
/*
* Сначала нам нужно создать процесс, чтобы он получил pid 1, однако
* задача инициализации, в конечном итоге, захочет создать kthreads, которые,
* если мы запланируем их до kthreadd, будут OOPS.
*/
pid = user_mode_thread(kernel_init, NULL, CLONE_FS);Параметр kernel_init, передаваемый в user_mode_thread – это функция, которая завершает некоторые задачи инициализации и затем ищет валидную программу инициализации для выполнения. Эта процедура начинается с некоторых базовых задач настройки. Я пропущу большую часть кода, где это происходит, за исключением вызова free_initmem. Это то место, где ядро освобождает разделы .init!
free_initmem();Теперь ядро может найти подходящую программу для запуска:
/*
* Мы пробуем каждую, пока не достигнем успеха.
*
* Вместо init можно использовать оболочку Борна, если мы
* пытаемся восстановить по-настоящему сломанную машину.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (CONFIG_DEFAULT_INIT[0] != '\0') {
ret = run_init_process(CONFIG_DEFAULT_INIT);
if (ret)
pr_err("Default init %s failed (error %d)\n",
CONFIG_DEFAULT_INIT, ret);
else
return 0;
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");В Linux программа инициализации почти всегда находится или символически привязана к /sbin/init. Общими программами инициализации являются systemd, OpenRC и runit. kernel_init() по умолчанию обращается к /bin/sh, если не нашла ничего другого. Если она не находит /bin/sh, значит, что-то ужасно неправильно.
В macOS тоже есть программа инициализации! Она называется launchd и находится в /sbin/launchd. Попробуйте запустить ее в терминале и получите сообщение о том, что вы не являетесь ядром.
Здесь мы переходим к шагу 4 процесса запуска компьютера: процесс инициализации выполняется в пространстве пользователя и начинает запускать различные программы с помощью паттерна fork-exec.
Отображение памяти при клонировании
Мне стало интересно, как ядро Linux повторно отображает нижнюю часть памяти при клонировании процессов. Похоже, большая часть кода клонирования процессов содержится в kernel/fork.c. Начало этого файла подсказало мне правильное место для поиска:
// kernel/fork.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/kernel/fork.c#L8-L13
/*
* 'fork.c' содержит подпрограммы помощи (help-routines) для системного вызова 'fork'
* (см. также entry.S и др.).
* Клонирование является простым, когда вы его освоите, но
* управление памятью может быть стервой. См. 'mm/memory.c': 'copy_page_range()'
*/Похоже, функция copy_page_range() принимает некоторую информацию об отображении памяти и копирует таблицы страниц. При беглом просмотре функций, которые он вызывает, становится понятным, что здесь страницы делаются доступными только для чтения, чтобы стать страницами COW. Определение такой необходимости выполняется с помощью функции is_cow_mapping().
is_cow_mapping() определяется в include/linux/mm.h и возвращает true, если в отображении памяти есть флаги, указывающие, что память доступна для записи и не является распределенной (т.е. не используется несколькими процессами одновременно). Распределенная память не должна быть COW, поскольку она является общей. Полюбуйтесь немного непонятной маскировкой битов (bitmasking):
// include/linux/mm.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/mm.h#L1541-L1544
static inline bool is_cow_mapping(vm_flags_t flags)
{
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}Возвращаемся в kernel/fork.c, выполнение простой команды копирования для copy_page_range() приводит к одному вызову из функции dup_mmap()… которая, в свою очередь, вызывается функцией dum_mm()… которая вызывается функцией copy_mm()… которая, наконец, вызывается массивной функцией copy_process()! copy_process() — это ядро функции клонирования, и, в некотором смысле, суть того, как системы Unix выполняют программы — копирование и редактирование шаблона, созданного для первого процесса при запуске.
В заключение
Как выполняются программы?
На низком уровне: процессоры являются тупыми. Они содержат указатель на память и выполняют инструкции последовательно, пока не достигнут инструкции, указывающей им перейти куда-то еще.
Кроме инструкций перехода, последовательность выполнения инструкций также может нарушаться аппаратными и программными прерываниями. Ядра процессора не могут одновременно выполнять несколько программ, но многозадачность может имитироваться с помощью таймеров для повторяющегося запуска прерываний и переключения кодом ядра между разными указателями кода.
Кажется, что программы выполняются как целостные, изолированные единицы. Прямой доступ к системным ресурсам в режиме пользователя закрыт, пространство памяти изолировано с помощью подкачки, системные вызовы спроектированы таким образом, что предоставляют общий ввод/вывод без знания о реальном контексте выполнения. Системные вызовы — это инструкции, которые просят ЦП запустить некоторый код ядра, локация которого настраивается ядром при запуске.
Но… как выполняются программы?
После запуска компьютера ядро запускает процесс инициализации. Это первая программа, запущенная на высшем уровне абстракции, когда машинному коду не нужно беспокоиться о многих специфических деталях системы. Программа инициализации запускает программы, которые рендерят графическое окружение компьютера и отвечают за запуск другого ПО.
Для запуска программа клонируется с помощью системного вызова fork. Это клонирование является эффективным, поскольку все страницы памяти являются COW, и память не копируется в физическую ОП. В Linux за это отвечает функция copy_process().
Оба процесса проверяются на предмет клонированности. Если они являются клонированными, они используют системный вызов execve для обращения к ядру для замены текущего процесса новой программой.
Скорее всего, новая программа является файлом ELF, который парсится ядром для получения информации о том, как загружать программу и куда помещать ее код и данные в новом отображении виртуальной памяти. Ядро также может выполнять подготовку интерпретатора ELF в случае, когда программа является динамически связанной.
Затем ядро загружает отображение виртуальной памяти программы и возвращается в пространство пользователя с запущенной программой, что означает установку указателя инструкции ЦП в начало кода новой программы в виртуальной памяти.
Эпилог
Поздравляю! Теперь вы лучше понимаете, как работает компьютер. Я надеюсь, что вам было весело.
Позвольте вас проводить, подчеркнув, что знания, которые вы получили, реальны и актуальны. В следующий раз, когда вы задумаетесь о том, как компьютер запускает несколько приложений, я надеюсь, вы представите себе микросхемы таймера и аппаратные прерывания. Когда вы будете писать программу на каком-нибудь причудливом языке программирования и получите ошибку компоновщика (linker error), я надеюсь, вы вспомните, что такое компоновщик и за что он отвечает.
Комментарии (25)

erley
21.08.2023 08:04+4Отличная работа по систематизации, спасибо!
Сохраню в закладках для сына-самоделкина :-)

domix32
21.08.2023 08:04+3Более удобный формат статьи
Таблица на треть экрана, половину от которой занимает навигация - ни разу не удобнее.

SalazarMAX
21.08.2023 08:04+2Начал читать и тут же споткнулся: «Код, не загруженный в ОП, не может быть выполнен.»
Что такое ОП? Оперативная память? Почему не ОЗУ, как принято? И вообще это утверждение мне видится неверным, оперативную память сначала надо проинициализировать, прежде чем с ней работать, откуда будет выполняться код сразу после нажатия на кнопку питания?

gena_k
21.08.2023 08:04Код, на загруженный в ОП(ОЗУ), может быть выполнен, если это код, прошитый в ПЗУ.

checkpoint
21.08.2023 08:04Неплохой материал для новичков, спасибо. Буду предлагать к почтению юным подаванам.
Вообщем, конечно, не плохо было бы углубиться еще на пару уровней в каждой главе. Но это уже будет не статья, я книга. И тут возник вопрос - а существует ли уже такая книга ?

damewigit
21.08.2023 08:04а существует ли уже такая книга ?
конечно, https://oz.by/books/more1028409.html
checkpoint
21.08.2023 08:04Полистал оглавление "Архитектура компьютера" от Э. Таненбаум, вроде как присутствуют все темы, должна быть толковой.
У меня есть уже два толмуда со словосочетанием "архитектура компьютера" в названии: "Компьютерная архитектура. Количественный подход" от Хеннесси и Паттерсона и "Цифровая схемотехника и архитектура компьютера" от Харрис и Харрис. Обе сосредоточены на устройствах микропроцессоров и выше почти не поднимаются. Книга Харрисов хороша ровно до середины, где повествование резко перескакивает от аппаратного устройства ПЛИС и ПЛМ сразу на систему команд RISC-V. Зачем такой финт - не ясно. Почему нельзя было постепено рассмотреть куски процессора в отдельности и плавно подвести к системе команд и дальше к программированию ? Книга Паттерсона неплоха, но это скорее диссертация вперемешку с историческим очерком - дано описание развития архитектур в хронологическом порядке, рассмотрены некоторые типовые узлы процессоров, масса формул, выкладок и графиков. Подходит больше для научных сотруников, нежели студентам. :-)
damewigit
21.08.2023 08:04У товарища Таненбаума есть еще такие же монументальные труды о сетях и операционнках (если нужно выше).
Вообще в Беларуси, почти на всех технарских компьютерных специальностях в универах по этим книгам учат. Интересно, думал что все про эти книги знают, но похоже это какая-то локальная особенность моей среды, раз вы раньше не натыкались.


Keroro
21.08.2023 08:04+2После выполнения всех инструкций, ЦП возвращает указатель в начало, и процесс повторяется. После выполнения инструкции указатель передвигается за нее в ОП и таким образом указывает на следующую инструкцию.
Как-то очень мутно написано. Если ЦП возвращает указатель в начало, значит программа зациклилась. Вся фишка в том что каждое чтение автоматически увеличивает счётчик команд ведь. Причем там внутри физически счётчик, никаких "указателей" и их "передвижения".

Rusrst
21.08.2023 08:04+1Всякие jmp, call, etc же как раз в него и пишут новые значения при вызове. А счётчик и правда вернётся в самое начало, если не будет инструкций его зацикливающих - т.е. пустая память, вся в nop.

diakin
21.08.2023 08:04В режиме ядра разрешено все: ЦП может выполнять любую поддерживаемую инструкцию и обращаться к любой памяти. В режиме пользователя разрешен только определенный набор инструкций, ввод/вывод (input/output, I/O) и доступ к памяти ограничены
А почему не выделить один процессор для ядра, а другой для user mode? Или одно из ядер процессора. И разделить память (шины) физически, чтобы из user mode в запрещенную память не залезть?

noppima
21.08.2023 08:04Нужно определиться в терминах. Суть в том, что нет такой единой сущности как "защищённая память". Есть физические страницы памяти, которые временно принадлежат каким-то процессам или ядру. И чтобы пресечь попытки одного процесса (из-за ошибки программиста или его злого умысла) подглядывать или что-то записывать в память другого процесса, ядро операционной системы "защищает" память каждого процесса от подобных действий. Придумано это было для разделения ресурсов (процессорных тактов, пространства оперативной памяти, доступа к переферицным устройствам).
Иначе, если отказаться от принципа разделения и защиты областей памяти каждого процесса друг от друга и, следуя вашему предложению, но довести его до логического конца, нужно будет строить некоторую аппаратную реализацию компьютера, в котором есть условно бесконечное количество процессоров, у каждого из которых есть своя собственная оперативная память и некий способ коммуникации между такими доменами. (Чем-то напоминает локальную сеть). Тогда каждый процесс получает свой выделенный процессор и всю оперативную память этого процессора, живёт в физическом адресном пространстве и ему никто не может помешать, как и он, собственно. А коммуникация с переферийными устройствами будет проходить через некоторый коммутатор-посредник, к которому имеет доступ каждый такой домен.Т.е. уже сейчас это можно реализовать в примитивном виде на каких-нибудь одноплатниках, но тогда у вас дома будет столько маленьких компьютеров в локальной сети, сколько процессов вы захотите запустить. И при этом, т.к. ресурсы одноплатников ограниченны, если у процесса закончилась оперативная память, то увы и ах, вам нужно его запустить заново на другом таком одноплатнике, но с большим количеством оперативной памяти. Т.е. идея начинает выглядеть абсурдно, т.к. каждая новая вкладка в браузере будет требовать своего микрокомпьютера с достаточным количеством ресурсов. А чтобы управлять всей этой сворой железа будет нужен какой-нибудь отдельный компьютер-супервайзер-мастер-майнд, который будет распоряжаться доступными одноплатниками и руководить функциями загрузки и запуска процессов, а также диспетчеризацией обмена данными и убийством процессов.
Дальше перефразируя по М.М. Жванецкого: "Чем ядро сейчас и занято, но без этих хлопот". Т.е. виртуализируя адресное пространство оперативной памяти и работая супервайзером.

performer
21.08.2023 08:04Эм.. странный вопрос :) с какой целью? Ядро - это та же библиотека, но которой можно больше чем всем )

Komrus
21.08.2023 08:04+2Ну это же классика:
Профессор: - Как работает трансформатор?
Студент: - У-у-у-у (изображает звук гудения трансформатора)
П: - Правильно
:))))

ris58h
21.08.2023 08:04+2Слишком сумбурно. Такую обширную тему в такой объём не уместить.
В цикле работы ЦП ничего не сказано про обработку прерываний, а это ключевой момент для понимания работы компьютера.


alexs963
Как работает компьютер, уровнем ниже: 1, 2, 3
MinimumLaw
Как глубока кроличья нора? (с)
Да, пожалуй если говорить про "глубокое погружение", то стоит опуститься и ниже. И до уровня дешифраторов/счетчиков/регистров, и до уровня стандартной логики. Другое дело, что на каждом шаге мы отбрасываем весьма существенные детали. Иначе это все не влезло бы в статью. Ибо "глубокому пониманию" надо учиться всю жизнь. И то не факт, что постигнешь.
Автору (или все же переводчику) стоит сказать спасибо. Материал полезный (хотя в таком виде и не уникальный). Правда, обычно мы идем все же от электронов к процессам в операционной системе. Но абсолютная высота горы не зависит от выбранной точки отсчета.
alexs963
Так это не для переводчика, а для тех кто заинтересуется темой. Есть еще видеокурс для тех кто захочет нырнуть в глубину.
MinimumLaw
Вообще, очень забавно наблюдать тенденции.
В мои 16 (ох, давно это было!) фактически универсальной отмазкой было "Чего с тобой разговаривать - ты даже до конца не понимаешь, как работает транзистор!" При этом, да, черт возьми, мало кто и тогда мог объяснить почему транзистор с двумя PN-переходами работает, а два встречно включенных диода - нет. И замечательное видео от Veritasium (к слову - есть лучше, но как всегда - в нужный момент не найти) появится еще не скоро.
Сейчас далеко не каждый системный программист-контроллерщик представляет себе внутренности того же STM32 с точностью до хотя бы регистров-дешифраторов, но говоря уже о стандартной логике или транзисторах. Ограничиваемся уровнями на выводах и неким "черным ящиком", который их обеспечивает.
Хорошо, что есть желающие опуститься ниже, а не только расти в ширь (как это в основном принято у прикладных программистов). Впрочем, жизнь меняется. Для того чтобы слушать радио или смотреть телевизор не обязательно было знать про лампы и реле. И даже создавать отличные радиоспектакли и телепередачи вполне получалось без этих знаний. Отчасти поэтому приятно скромно чувствовать себя истинным строителем храма, что бы остальные не думали по этому поводу.
checkpoint
Тут, на мой взгляд, Вы слегка перегибаете. Внутреннее устройство современных вычислетильных ядер (даже таких "простых" как Cortex M1) доступно очень ограниченному кругу лиц. Так, что знать устойство МК до дешифратора мало кто может по чисто организационным причинам. Но вот слепить своё вычислительное ядро из стандартной логики или написать на Verilog-е свой вариант RISC-V, я считаю, полезно каждому программисту и, тем более, железячнику. Почему таких вещей не преподают в наших профильных ВУЗах я радикально не понимаю, зато матана всякого разного-безобразного - до блевоты.
На счет строителей храма. Программисты и электронщики это современные жрецы и заклинатели, без их участия не работает ни один "волшебный шар" и именно поэтому они имеют полное право на привелегии, ровно как и физики, химики и специалисты по материаловедению и обработке материалов. Но почему-то в реальной жизни все получается строго наоборот.
MinimumLaw
Да, это именно то самый типовой комментарий, с комментариями на тему "почему так". На самом деле, внутренне устройство именно ядра не так и сложно. Во всяком случае в первом приближении. Без оптимизаций для максимальной производительности. Давайте спросим у людей в теме - допустим у присутствующего здесь @YuriPanchul.
Применительно к ARM'ам вообще сложно не ядро. Сложны шины, соединяющие периферийные блоки. И тут да - декомпозиция их вниз до транзисторов - это та еще забава.
Но речь-то даже не об этом. Внутренне устройство банальных I2C/SPI/UART/I2S в терминах регистров и стандартной логики уже не всякий системщик себе представляет. А уж интерфейсы посложнее, типа MIPI или USB - и того меньше, а уж PCIe - вообще магия даже для достаточно продвинутых.
Любимая забава, современный аналог той самой, про "как работает транзистор". Вот Arduino, вот документация на AVR, вот SPI интерфейс (стр. 136). Нарисуй его реализацию, начиная с регистров из документации. Без процессорного ядра. Без шин. Как думаете, много ли могут? Чтоб не спросить "вообще кто-нить может"? Или хотя бы попытается? И это при том, что в документации даже очень подробная структурная схема приведена.
Ладно, бросаю я ворчать. Все равно ворчанием делу не поможешь.
nameless323
Мне в свое время вот этот курс понравился. Тут начинается с физики, дальше устройство транзисторов, лоджик гейты и как на этом сделать простой процессор.