
Предположим: вы полны желания изучить манящий массив данных. К счастью, для этого достаточно вашего компьютера. Итак, вы открываете блокнот Python или REPL, чтобы начать работать: какую библиотеку использовать? Естественно, вы можете обратиться к старой доброй Pandas. А как насчет новой модной библиотеки фреймов данных, например Polars или datatable? А ещё, для разнообразия, можно попробовать встроенный SQL с помощью DuckDB.
Давайте погрузимся в прекрасную область фреймов данных, чтобы сделать выбор!
PS: Используйте DuckDB, если вам удобно работать с SQL, Polars или Pandas с поддержкой PyArrow, если вам не нужно какое-то специфическое расширение NumPy, и задействуйте PyArrow в том случае, если вы не против ручной оптимизации.

Вступление
Итак, вы хотите писать код на Python и упростить проект, поэтому не будете задействовать отдельный SQL или распределенные системы. В этом случае имеет смысл выбрать между фреймворками dataframe и datatable. Давайте сравним четыре популярных: Pandas (любимчик публики), Polars (конкурент Pandas) , PyArrow (low level columnar) и DuckDB (в него встроен SQL).
Документация и экосистема
Как и при знакомстве с любой новой библиотекой, большое значение имеет простота использования и то, как быстро вы сможете приступить к разработке. Наиболее сильными соперниками в этом отношении являются Pandas и DuckDB.
Pandas имеет огромную экосистему, состоящую из документации, туториалов, вопросов и ответов. И если какой-то тип данных не является стандартным, то велика вероятность, что кто-то уже написал для него библиотеку. То, как DuckDB будет выглядеть в сравнении, зависит от вашего знакомства с SQL. Для тех, кто знаком с древними SQL-таинствами, она, вероятно, будет более быстрой в освоении, чем Pandas. Это вдвойне важно, учитывая обширность документации по DuckDB.
Polars также имеет обширную документацию. Однако он не может конкурировать с Pandas в плане экосистемы и поддержки (на StackOverflow к нему задается в 200 раз меньше вопросов). Сообщения об ошибках Polars могут быть полны загадок и тайн из-за использования дополнительных уровней абстракции (Rust и Arrow). Все это несколько усложняет эксперименты для начинающих пользователей.
Наконец, PyArrow — это заведомо низкоуровневый фреймворк. В значительной степени он задуман как строительный элемент для других библиотек. Это отражено в документации, которая носит более технический и менее обучающий характер. Однако если вы готовы приложить усилия, то вам откроется вся мощь инструмента.
Надо быстро бегать
Панды могут бегать со скоростью всего 30 км/ч, поэтому они не сравнятся со скоростью 80 км/ч и более, которую могут развивать некоторые утки... Постойте, нет, библиотеки Python, а не звери! Давайте попробуем еще раз.
Я проверил работу четырех библиотек, используя примерно 2,5 ГБ или 8 500 000 строк данных с таксономической информацией с наблюдениями за птицами. Первый тест выполняет простую операцию groupby, подсчитывая количество встреч для каждого вида, используя часть набора данных. На моем компьютере (M2 Pro MacBook, 16 ГБ оперативной памяти) это преобразование занимает вполне сравнимые 60 миллисекунд с PyArrow, 130 с Polars и 160 с DuckDB.
Интересно с Pandas: при использовании стандартного движка преобразование выполняется медленнее всех — более 1,6 секунды. Однако при использовании экспериментального движка PyArrow результаты меняются: Pandas выигрывает у всех, кроме PyArrow, занимая всего 80 мс.
Хотя абсолютные цифры не имеют большого значения, относительная разница между библиотеками весьма показательна. Это также хорошо видно на примере других простых операций и небольших наборов данных.
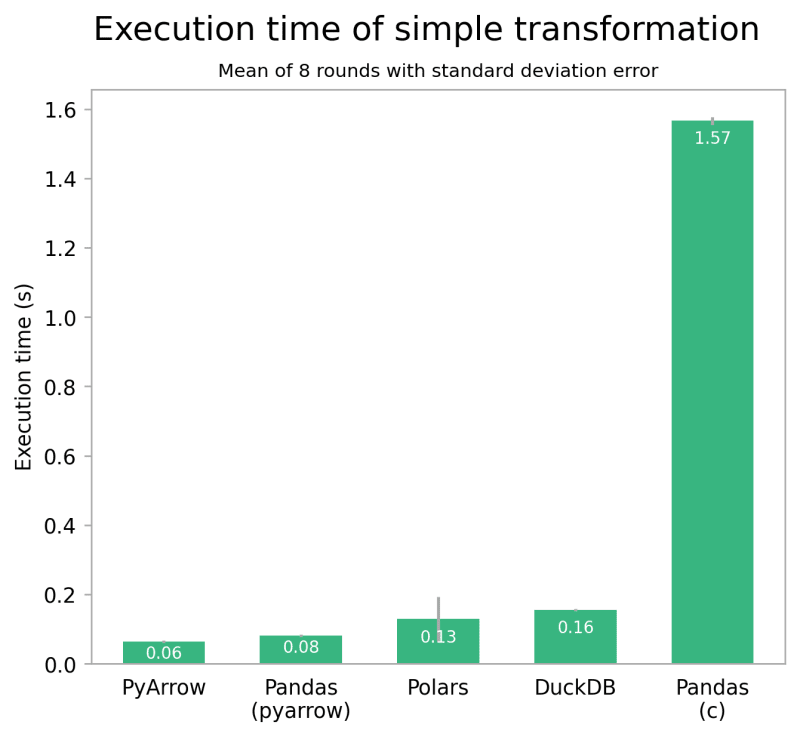
Ситуация несколько меняется, когда мы рассматриваем более сложное преобразование. Во втором тесте выполняется два объединения и несколько вычислений по столбцам, подсчитывается количество встреч каждого вида по таксону и в пределах определенной географической области. К сожалению, здесь пока нет возможности использовать движок PyArrow, поэтому остается только представить, что Pandas с PyArrow будет работать здесь аналогично Polars.
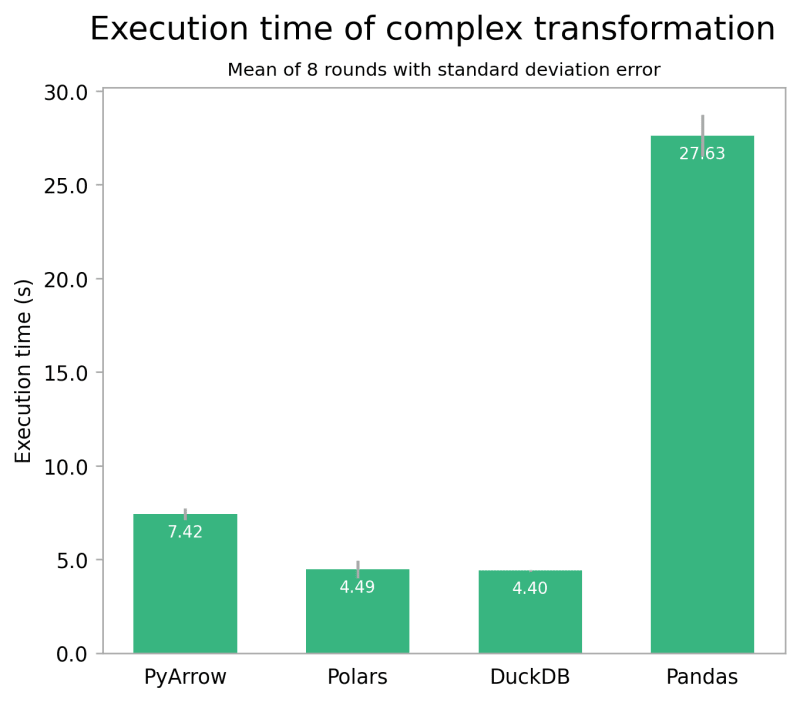
Однако общая картина обоих тестов одинакова: производительность Polars, DuckDB и, скорее всего, Pandas с PyArrow сопоставима, в то время как Pandas с движком по умолчанию работает значительно медленнее. Для очень маленьких наборов данных эта разница может быть незначительной. Но для средних наборов данных, таких как этот, и особенно для больших наборов данных или повторяющихся задач, эффект может быть значительным.
Также целесообразно использовать библиотеку более высокого уровня, например Polars или DuckDB, а не PyArrow, поскольку последняя требует гораздо более тщательной оптимизации производительности.
Удобство работы с кодом
Наконец, рассмотрим интерфейс, который предоставляют библиотеки. Pandas имеет, безусловно, самую большую область API, часто предлагая несколько способов достижения одного и того же результата. По моему опыту, это довольно грубое решение, которое также может запутать и привести к непоследовательности кода. Polars в этом отношении более категоричен, предлагая последовательный и предсказуемый API (философия Polars). Хотя иногда код Polars более сложен, в результате он может быть более читабельным. Как можно догадаться по названию, он, конечно, заимствует большинство концепций у Pandas, поэтому если вы уже знакомы с Pandas, то будете чувствовать себя вполне комфортно. Если же нет, то кривая обучения, скорее всего, будет более крутой.
Что же касается PyArrow, то его низкоуровневое ядро Arrow ярко выражено. Это заставляет вас думать в том же ориентированном на столбцы ключе, в котором данные обрабатываются внутри программы. Операции над данными также более явны, что — к лучшему или худшему — раскрывает абстракции, которые предоставляют библиотеки более высокого уровня.
Единственным интерфейсом DuckDB является SQL: вероятно, это глоток свежего воздуха для многих представителей сообщества data science. Вы можете использовать имеющиеся знания SQL, не изучая еще один фреймворк. Если вы еще не знакомы с SQL, это также может быть наполовину полным стаканом, поскольку вы будете осваивать особенно полезный навык. Кроме того, использование DuckDB в кодовой базе позволяет сократить разрыв между аналитиками и инженерами, поскольку язык является общим.
В заключение приведем простой пример из всех четырех вариантов:
"""Add a column to a table indicating whether a bird is of
the Anatidae family (ducks, geese, and swans)."""
# Pandas (with PyArrow)
import pandas as pd
df = pd.read_csv(
"bird_spot.csv",
engine="PyArrow",
dtype_backend="PyArrow"
)
df["is_anatidae"] = df["family"] == "anatidae"
# Polars
import polars as pl
df = pl.read_csv("bird_spot.csv")
df = df.with_columns([
(pl.col("family") == "anatidae").alias("is_anatidae")
])
# PyArrow
import pyarrow.csv
import pyarrow.compute as pc
table = pyarrow.csv.read_csv("bird_spot.csv")
table = table.append_column(
"is_anatidae",
pc.equal(table["family"], "anatidae")
)
# DuckDB
import duckdb
table = duckdb.query("""
SELECT *, family = 'anatidae' AS is_anatidae
FROM read_csv_auto('bird_spot.csv')
""").fetchall()Заключение
Надеюсь, я удовлетворил ваше любопытство относительно преобразований таблиц Python за пределами стандартной библиотеки. Вот мое личное мнение: для образовательных целей и случаев, когда расширяемость имеет первостепенное значение, Pandas по-прежнему является отличным выбором. А когда PyArrow станет использоваться по умолчанию, он может снова стать лучшим. Если вы предпочитаете идти по легкому пути повышения производительности при почти такой же простоте использования, выбирайте Polars для своего следующего проекта. Если вам нужна низкоуровневая библиотека, на которую можно опираться , то, возможно, вам подойдет PyArrow. А если вы ищете сочетание скорости Polars с вездесущностью и доступностью SQL, то DuckDB — поистине непревзойденный вариант.
Но самое главное — попробуйте сами! Я еще много чего не упомянул (H2O.ai's datatable, Modin, ClickHouse и др.). И вы всегда можете попробовать совершенно другой язык: может быть, попробовать DataFrames от Julia или R.
От редакции
Мы продолжаем серию вводных материалов для тех, кто уже смело работает с Python и готов погружаться в data-глубины. Для таких разработчиков и сисадминов мы подготовили курс «Data-инженер» — поток по нему стартует уже 4 сентября! Подробнее о курсе вы можете узнать на нашем сайте: https://slurm.io/data-engineer