

Привет, Хабр! Меня зовут Илья Нырков, я Presale-архитектор в VK Cloud. В своей работе я часто сталкиваюсь с проблемами клиентов при выкатке новых версий их проектов. Плохая документация (или зачастую ее отсутствие) приводит к нехватке информации о системных настройках, установленном ПО и его версиях на машине. Из-за этого диагностика и устранение регулярно возникающих проблем значительно усложняются.
Я расскажу о подходе к построению инфраструктуры при помощи незаменяемых компонентов. Опишу его основные преимущества и недостатки, а также приведу примеры ситуаций, в которых он будет наилучшим образом применим.
Immutable infrastructure следует использовать в облаке вместе с подходом Infrastructure as a code — управлением инфраструктурой и развертыванием приложений с помощью кода, а не ручных процессов.

Я буду объяснять общие принципы работы различных инструментов без акцента на индивидуальных особенностях каждого. Важно понимать, как устроены эти концепции, потому что любой инструмент может перестать быть опенсорсом (HashiCorp, мы смотрим на вас), появится более производительный для вашей конкретной задачи или понадобится разработка собственного.
В дальнейшем я напишу о том, как реализовать на практике Immutable-infrastructure-проект в облаке VK Cloud.
Теоретическая часть

Мутабельность (Mutability) — свойство объекта изменять свое состояние. В контексте DevOps его можно применять в случаях, когда нужно сохранить прежнее состояние системы и не думать о том, как поднять новую инфраструктуру. Можно применять обновления, патчи, менять размеры.
Допустим, у вас есть веб-сервер, который вам нужно обновить, для этого вы просто добавите изменения в текущую версию и выпустите обновление. Но что, если при обновлении что-то пойдет не так? Допустим, одна из команд в скрипте даст сбой? Вы останетесь с сервером с неподходящей вам версией. Это фактор риска, который в будущем может неожиданно выстрелить. Эти проблемы могут копиться в ходе многочисленных обновлений, из-за чего практически невозможно будет отследить изначальную проблему.
Преимущества:
- Не нужно каждый раз поднимать новую машину при изменении конфигурации.
- Быстрое развертывание обновлений, так как не нужно каждый раз поднимать инфраструктуру.
- Можно проводить кастомную настройку отдельных инстансов.
- Машины могут хранить состояние на диске.
Недостатки:
- Отсутствие документации версий инфраструктуры, трудно отследить проблемы, которые могли возникнуть из-за выкатки новой версии.
- При обновлении могут возникнуть ошибки из-за проблем с сетевым соединением, DNS, отсутствием ответа от репозиториев APT и т. п. В итоге обновление выполняется частично.
- Проблемы с откатом изменений к предыдущему состоянию, особенно если изменения затрагивают много различных зависимостей.
- Конфигурационный дрифт, разгоняемый страхом инженера менять что-либо инструментами автоматизации.
Иммутабельность (Immutable) — отсутствие возможности у объекта изменить его состояние, противоположность мутабельности. Когда можно вынести состояние системы, размещенной в инфраструктуре, в отдельные хранилища, то можно рассмотреть такой подход. Вернемся к примеру с веб-сервером, который нам нужно обновить. Вместо того чтобы загрузить обновление на имеющийся сервер, мы создаем новый образ виртуальной машины с этим обновлением. Его мы используем для поднятия обновленной машины с веб-сервером, а старую машину удаляем. Это позволяет задокументировать новое состояние машины в виде конфигурационного файла и получить неизменяемый артефакт — образ виртуальной машины, который в будущем будет проще мигрировать.
Преимущества:
1. Возможность версионирования деплойментов.
a. Можно отследить, в каком из обновлений возникла ошибка.
b. У инфраструктуры нет промежуточных состояний, которые могут возникнуть в изменяемой инфраструктуре из-за ошибки при обновлении.
2. Конфигурационные файлы выступают в качестве документации состояния инфраструктуры.
3. Упрощение конфигурации. Не нужно помнить, что и на какой машине установлено, если есть готовый образ, из которого она создана, со своим описанием в виде файла конфигурации.
4. Благодаря согласованной конфигурации машин проще выкатывать обновления и тестировать новые версии.
5. Инстансы с одним и тем же приложением одинаковы.
Недостатки:
1. Более медленный деплой новых версий по сравнению с Mutable-инфраструктурой, так как поднимаются новые машины.
2. Нельзя быстро исправить ошибку на какой-то отдельной машине, нужно пересматривать конфигурацию и собирать новый образ.
3. Необходимо отделить данные от инфраструктуры во избежание их утери во время выкатки новой версии.
4. При пересоздании ВМ с новой версией всё равно теряются данные RAM, например, текущего выполняемого запроса. Эту проблему можно решить путём удаления ВМ со старой версией только после того, как ВМ с новой версией будет окончательно инициализирована. Таким образом реализовано, например, обновления нод кластера Kubernetes в облачных провайдерах.
Виды инструментов Immutable infrastructure
Существует несколько подходов по построению иммутабельной инфраструктуры. Их объединяет то, что они используют какой-то декларативный язык вроде YAML для описания своего поведения.
1. Инструменты доставки конфигурации

Принцип работы инструментов доставки конфигураций
Стартовым можно считать использование инструментов вроде Ansible, Puppet, Chef, Saltstack и др. При обновлении ПО мы удаляем старый и создаем новый сервер, отправляем на него конфигурацию либо сервер запрашивает ее самостоятельно. Стоит помнить, что, как и в остальных инструментах Immutable, хранилище стейта должно быть отделено от виртуальной машины с приложением, чтобы не потерять стейт после удаления ВМ и установки новой версии.
2. Готовые образы виртуальных машин (Golden image)

Процесс сборки готового образа с приложением
Подразумевает предварительную сборку образа на основе какого-то базового образа (одобренного в том числе ИБ) со всем ПО и зависимостями при помощи инструментов вроде Packer, Vagrant, средств создания снапшотов облака и других. Это реализация подхода Golden image. Имея собранный образ, можно легко масштабировать инфраструктуру, особенно в связке с инструментами IaC.
3. Контейнеризация

Позволяет упаковывать приложения и необходимые зависимости в изолированные контейнеры. Каждый из них содержит все необходимые библиотеки, зависимости, код и конфигурацию. Контейнеры более легковесны по сравнению со стандартными виртуальными машинами и легко переносимы между различными средами.
4. Оркестрация контейнеров

Архитектура типичного оркестратора контейнеров
Более продвинутый подход, являющийся продолжением предыдущего. Он решает проблему управления контейнерами, которых становится слишком много. Инструменты вроде Kubernetes (для которого в VK Cloud есть свой платформенный сервис) — Mesos, Nomad и т. п. — автоматизируют процессы развертывания, масштабирования и восстановления контейнеров. В данном случае мы уже мыслим в контексте контейнеров и их образов (и дополнительных абстракций в зависимости от оркестратора вроде Deployment или Service), а не виртуальных машин. Причем мы говорим о деплое приложений, а подготовка и настройка кластера — это отдельный вопрос.
Этапы деплоя новой версии
Чтобы правильно выбрать инструменты для построения иммутабельной инфраструктуры, нужно хорошо представлять этапы деплоя нового релиза вашего приложения. Рассмотрим их на примере CI/CD-пайплайна. Когда пушится коммит с каким-либо изменением, он должен пройти тесты, сборку и, возможно, другие этапы. После тестирования самого кода нужно собрать образ с приложением, который далее будет поднят на сервере. У любого собранного образа должен быть базовый образ, например Ubuntu.

Пайплайн деплоя новой версии в Immutable infrastructure
- На базовый образ устанавливаем необходимые изначальные инструменты вроде веб-серверов, агентов мониторинга, прокси и других.
- Следующим этапом идет загрузка кода и установка в образ всех необходимых зависимостей и библиотек.
- Собираем образ, проставляем метаданные в зависимости от приложения и отправляем в Terraform (или Pulumni например) с тегом коммита в имени.
- На стейдже на основе соответствующего конфигурационного файла через Terraform поднимаем инстансы с новой версией приложения. У VK Сloud есть свой провайдер.
- Поднятые инстансы с помощью механизма Autodiscovery извлекают из инструмента Service Mesh вроде Consul, Zookeeper, Eureka и т. п. необходимые переменные окружения с эндпоинтами БД, хранилищами метрик и именами бакетов S3, а также конфигурационные файлы. Для доступа в хранилище конфигураций в образ ВМ ставим соответствующие агенты, удовлетворяющие правилам ACL.
В итоге получаем инстансы с новыми версиями приложений. Важно, что мы не загружаем в образ всю дополнительную конфигурацию, иначе при изменении даже одного эндпоинта понадобится пересобирать весь образ, что займет очень много времени.
Управление конфигурациями и секретами
В основе построения Immutable-инфраструктуры стоит подход Service Mesh, который представляет собой дополнительный сетевой слой, позволяющий задавать правила общения приложений между собой (кто к кому может ходить, методы шифрования, сертификаты и т. д.), не изменяя кода этих приложений. Грубо говоря, это некоторый Control plane, с которым общаются инстансы с установленными прокси в виде Sidecar-контейнера или демона. Инстансы приложений тоже общаются между собой через этот прокси.
Рассмотрим задачи, которые помогает решить Service Mesh.
Обнаружение сервисов, или Discovery
Как определить, какой сервис по какому адресу доступен? По сути, имеется некоторый реджистри, в который обращается каждый новый инстанс сервиса и заявляет о себе, а также спрашивает об адресах других сервисов, в которые ему нужно обращаться.

Принцип работы service discovery в Service Mesh
Разделение сегментов сети сервисов
При таком подходе мы определяем, какой сервис с каким будет общаться. Это достигается с помощью прокси-серверов, разворачиваемых как Sidecar-контейнер или дополнительный демон, который будет пропускать весь трафик в приложение. Тогда приложению не нужно думать об изменении адресов — об этом думает прокси. Для безопасности используются Mutual TLS, то есть у каждого сервиса и у реестра есть свой прокси, что позволяет не реализовывать защиту на уровне приложения.
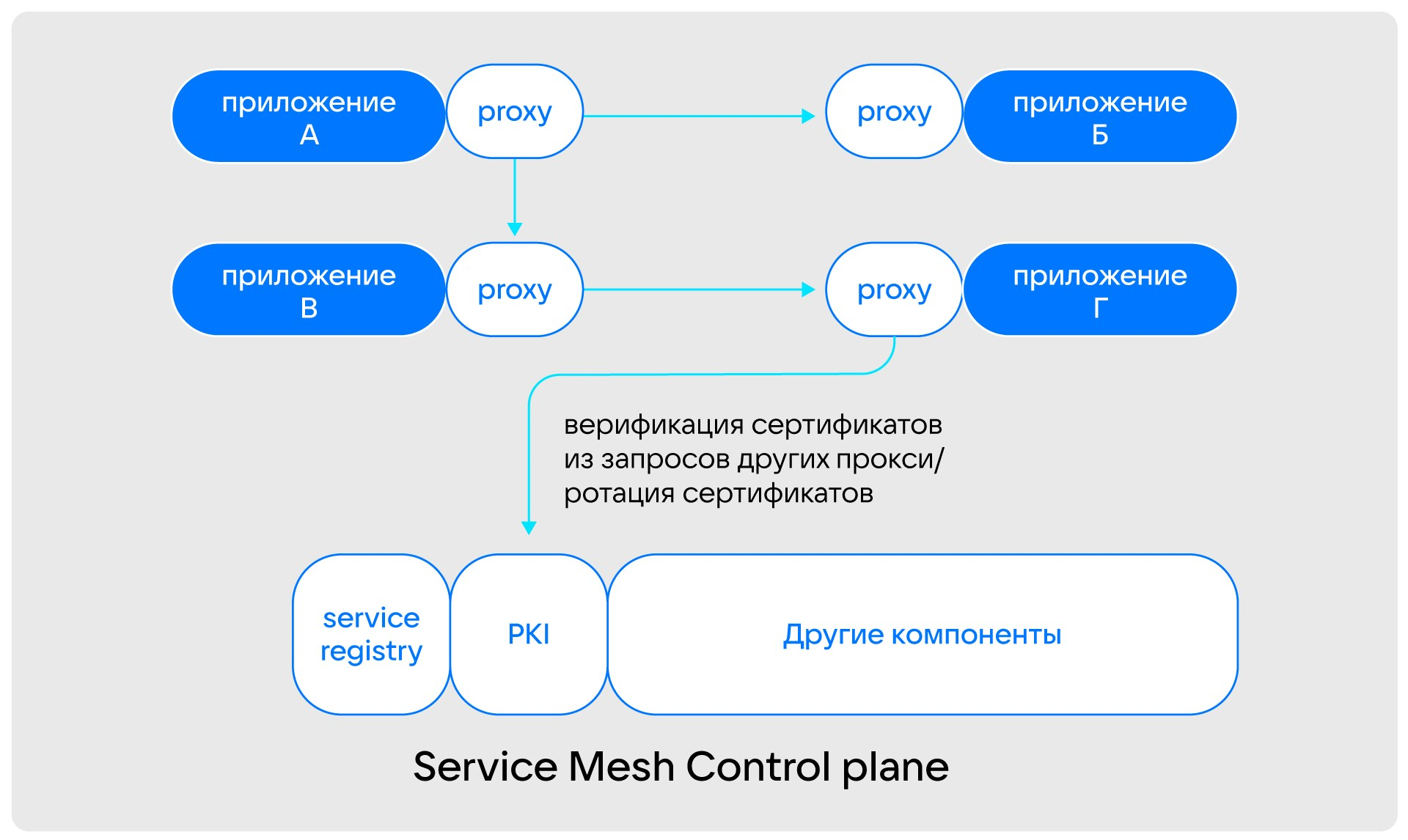
Сетевое взаимодействие инстансов в Service Mesh
Хранение и выдача конфигураций
Мы обеспечиваем удобный доступ к конфигурации, которая хранится в одном месте и может быть легко изменена. Не нужно вшивать ее в образ и тратить кучу времени на пересборку в случае изменений.

Работа с конфигурациями приложений в Service Mesh
Не стоит забывать про Sensitive-информацию вроде Credentials для баз данных, токенов API, TLS-сертификатов и т. д. Для нее нужно отдельное централизованное хранилище секретов, которое решает проблему «разбросанности» Sensitive-данных, то есть ситуации, когда они раскиданы по конфиг-файлам и манифестам, захардкожены в приложение, путем централизованного хранения их в зашифрованном виде и своевременного ротирования (обновления/замены).

Возможные источники секретов
Хранилище секретов должно предоставлять:
- полноценный сервис шифрования при хранении и передаче данных с ротацией ключей шифрования;
- гранулярный ACL для гибкой настройки доступов;
- Audit trail — журналирование событий доступа к хранилищу секретов;
- удобный API, в том числе для работы с шифрованием и отображением секретов, которые шифруются (содержимое, естественно, не отображается).

Архитектура хранилища секретов
У хранилища секретов несколько основных компонентов. Прежде всего это ядро, которое управляет другими компонентами и выполняет иные функции. Модуль аутентификации (auth) позволяет общаться с хранилищем секретов, которое, как правило, поддерживает большинство общепринятых стандартов вроде LDAP, Active Directory, Kubernetes Service Account и др. Storage data используется для хранения данных хранилища секретов и представляет собой обычную RDBMS, например MySQL, PostgreSQL и др. Audit logging и Audit data хранят информацию о том, кто и когда обращался к данным в хранилище секретов, в качестве бэкенда для этого может использоваться инструмент вроде Splunk. Secret management управляет различными модулями, каждый из которых отвечает за свой тип секретов; это могут быть креды для баз данных, Private key infrastructure (PKI), просто Key/Value и др.
Еще одной важной концепцией является динамический секрет (ротируемый) — уникальный для каждого экземпляра приложения (воркера) секрет, который позволяет в случае компрометации отследить конкретный воркер, где это произошло, перевыпустить для него секрет или пересоздать воркер. Это полезно, ведь, если бы был общий секрет для каждого типа приложения, а не для каждого отдельного воркера, приложению пришлось бы испытывать даунтайм в случае замены.
Service Mesh Control plane, по сути, является точкой входа для сервисов. В том числе через него идет обращение к сервису хранения секретов.

Взаимодействие Service Mesh со внешним хранилищем секретов
Мониторинг
Продолжая подход Service Mesh, для сборки логов и метрик можно установить на инстанс приложения агент мониторинга (Telegraf, Fluentbit, Node Exporter и другие). А чтобы не выпускать для него лишний TLS-сертификат, можно перенаправлять трафик через тот же агент прокси, который был установлен ранее.

Схема взаимодействия приложения и агентов мониторинга и прокси
Логи и метрики будут отправляться в Service Mesh Control plane, а оттуда в систему логгинга. Вначале находится агрегирующий слой, позволяющий объединить источники метрик и логов из различных приложений и задать правила их распределения по соответствующим хранилищам. Примеры таких инструментов: Cloud Logging, Fluentd, Calyptia и др.

Взаимодействие Service Mesh с системой мониторинга
В этой схеме данные агрегируются в долгосрочные и краткосрочные хранилища, а также в систему алертинга, которая оповещает администратора в случае инцидента — превышения порога по какой-то ключевой метрике вроде CPU Usage или заполненности диска. Долгосрочное хранение используют для архивирования логов за большой период времени для исторической аналитики в будущем. К ним будут редко обращаться, поэтому можно поместить их не на диск, а, например, в объектное хранилище S3 холодного типа. Краткосрочное хранилище используют для хранения логов и метрик за ограниченный период, например две недели. К ним будет обращаться интерфейс запросов или админка, где можно выставлять соответствующие фильтры и смотреть поведение приложений и системы в целом. Такая система мониторинга и логирования идеальна в ситуациях, когда для отладки любого экземпляра не требуется доступ по SSH.
Пример кейса Beamly

Примером компании, которая успешно применила подход Immutable infrastructure, является стартап Beamly. Они получили контракт с популярным западным шоу вроде нашего «Голосa»: Beamly сделали платформу онлайн-голосования за артистов. Проблема была в том, что продюсеры не предупреждали о голосованиях заранее, что привело к огромным и неожиданным нагрузкам. Для Beamly как для стартапа, которому повезло получить такой контракт, было очень важно показать, что им можно доверять такие большие системы, и неудача закончилась бы смертью стартапа.
В итоге они применили вышеописанные подходы при помощи облачной связки из Packer, Ansible и Consul и сделали следующие выводы:
- Immutable сначала сложна в построении, но она того стоит.
- Быстро скейлится вверх/вниз, когда все инструменты настроены. Можно снизить расходы на закупки железа, Beamly сэкономили 70%.
- Будьте прагматичны. Используйте Bootstrapping (прокидывание стартовых скриптов в виртуальную машину) для поднятия вашей инфраструктуры.
- Immutable упрощает управление изменениями (версии, архитектура, масштабирование) и делает их атомарными.
- Отсутствует конфигурационный дрифт и уникальные серверы.
Доверяйте своим инструментам Continuous delivery. Перестаньте все делать руками и тратить лишнее время. Если вы пока не готовы, продолжайте конфигурировать и править инструментарий, пока не добьетесь этого.
Вывод
Immutable infrastructure — недооцененный в СНГ, но стоящий подход. Он упрощает масштабирование, обновление и отслеживание конфигураций. Несмотря на сложность построения, в дальнейшем вам будет проще адаптироваться к росту нагрузки на ваш сервис и ускорить Time-to-market новых фич.
Комментарии (10)

chemtech
02.09.2023 03:39Отсутствие документации версий инфраструктуры, трудно отследить проблемы, которые могли возникнуть из-за выкатки новой версии.
Это применимо как изменяемой так и к неизменяемой инфраструктуре.
chemtech
02.09.2023 03:391. Возможность версионирования.
a. Можно отследить, в каком из обновлений возникла ошибка.
2. Конфигурационные файлы выступают в качестве документации состояния инфраструктуры.
Вы это можете делать и с изменяемой инфраструктурой.
chemtech
02.09.2023 03:393. Упрощение конфигурации. Не нужно помнить, что и на какой машине установлено, если есть готовый образ, из которого она создана, со своим описанием в виде файла конфигурации.
4. Благодаря согласованной конфигурации машин проще выкатывать обновления и тестировать новые версии.
5. Инстансы с одним и тем же приложением одинаковы.
Если использовать практики infrastructure as a code и идемпотентность, то эти пункты можно реализовать на изменяемой инфраструктуре.
chemtech
02.09.2023 03:391. Более медленный деплой новых версий по сравнению с Mutable-инфраструктурой, так как поднимаются новые машины.
Наоборот, более быстрый деплой по сравнению с Mutable инфраструктурой. Вы просто указываете новый образ, в котором уже был деплой приложений и библиотек когда вы его паковали, например, с помощью packer.
chemtech
02.09.2023 03:39Виды инструментов Immutable infrastructure
1. Инструменты доставки конфигурации
Стартовым можно считать использование инструментов вроде Ansible, Puppet, Chef, Saltstack и др.
Наоборот. Ansible, Puppet, Chef, Saltstack это инструменты для mutable инфраструктуры. Они подключаются к серверу и настраивают его.
Только в связке с packer это инструменты immutable инфраструктуры. Но в этом пункте вы это не упомянули.
chemtech
02.09.2023 03:39Стартовым можно считать использование инструментов вроде Ansible, Puppet, Chef, Saltstack и др. Стоит помнить, что, как и в остальных инструментах Immutable, хранилище стейта должно быть отделено от виртуальной машины
У Ansible, Puppet, Chef, Saltstack нет state, а у terraform есть. Но в пункте ничего про terraform не написано.
chemtech
02.09.2023 03:39Собираем образ, проставляем метаданные в зависимости от приложения
Собираем образ с помощью packer, проставляем метаданные в зависимости от приложения
chemtech
02.09.2023 03:39Продолжая подход Service Mesh, для сборки логов и метрик можно установить на инстанс приложения агент мониторинга (Telegraf, Fluentbit, Node Exporter и другие).
Продолжая подход Service Mesh, для сборки логов (Fluentbit) и метрик можно установить на инстанс приложения агент мониторинга (Telegraf, Node Exporter и другие).
chemtech
Спасибо за пост. Как связано понимание этих концепции и что любой инструмент может перестать быть опенсорсом? Скорее эти фразу стоило разделить на 2 предложения.