

Не так давно у меня появился интерес узнать, какие вообще нынче есть подходы и отношения к Юнит тестированию. Сделано это было скорее в познавательных целях. Сравнив труды по популярности, я решил ознакомиться с книгой "Unit Testing: Principles, Practices, and Patterns (Vladimir Khorikov)". Я не ставлю своей задачей полностью рецензировать данный труд, но не могу не обратить внимание на некоторые тезисы данной книги, которые часто вижу и слышу и о которых хотелось бы поговорить.
Личное впечатление о книге
"Unit Testing Principles, Practices, and Patterns" является систематизацией опыта автора в тестировании. Причём в тестировании именно том самом, которым стоило бы заниматься разработчикам, не тестировщикам. А о том, почему стоило бы заниматься, мы ответили чуть ранее в нашей другой статье. Книга и правда большая и, возможно, весьма полезная джунам и новичкам.
Если зайти на страницу данного труда на Amazon, то в секции "часто покупается вместе с" незамедлительно появятся книги Clean Code, что не случайность. Данная книга, определённо, написана в похожем стиле и вдохновлена Робертом Мартином, а также ставит перед собой несколько схожую задачу — выверить на личном опыте грамотный подход к разработке. Подобный стиль написания может показаться многим весьма категоричным. Параллели здесь можно проследить и с Фаулером, ведь некоторые параграфы книги весьма точно пересказывают его статью "mocks aren"t stubs". Из той же статьи происходит несколько сомнительный "-изм" "мокисты" в противоположность "классикам" тестирования. Читателю предлагается не забыть взять это на вооружение для важных споров.
Я предлагаю взглянуть глубже на некоторые тезисы из данных статей, которые я нахожу спорными, либо непонятными мне лично.
Предмет дискуссии
По сути, речь идёт о том, что из себя должен представлять Unit тест. Упомянутые авторы предпочитают почти полностью отказаться от моков как таковых, тестирую классы только в своей совокупности. В противовес же им идёт подход, где все зависимости класса полностью "мокаются", в следствии чего наш класс тестируется в полной изоляции от всего остального. Если попробовать визуализировать этот простой вопрос, то выглядело бы это следующим образом.
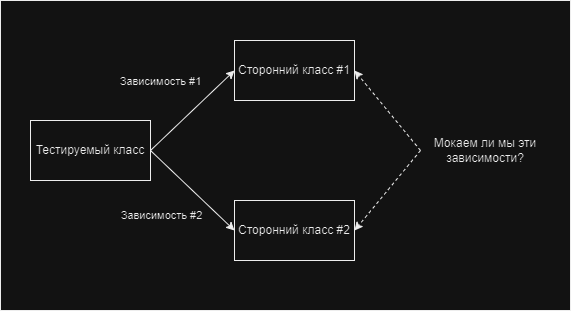
Я думаю, что при поиске примеров использования какой-нибудь популярной библиотеки на подобии "Mockito" можно было бы увидеть подобные примеры тестов. Но вернёмся к интересующим нас моментам.
Хрупкие тесты
Intra-system communications are implementation details because the collaborations your domain classes go through in order to perform an operation are not part of their observable behavior. These collaborations don't have an immediate connection to the client's goal. Thus, coupling to such collaborations leads to fragile tests.
Using mocks to verify communications between classes inside your system results in tests that couple to implementation and therefore fall short of the resistance-to-refactoring metric.
Хориков часто апеллирует к "хрупкости" тестов как к метрике, с которой стоит бороться. Имеется ввиду, что если тесты будут сильнее зависеть от внутренней технической имплементации классов, то это приведёт к более частым "красным" тестам. Частое возникновение такого поведения, как показано на примере, может привести к потере веры к тестам вместе с их последующими отключением и игнорированием.
Часто, сам применяя именно "мокистский" подход, я могу наблюдать обратное. Да и у меня самого желания взять и выключить "падающий" тест не возникало. Сухой инженерный подход к разработке пытается найти объяснения многим негативным практикам разработки именно во внутренней структуре написанного кода и полностью обходит стороной договорённости в коллективе, конфигурацию CI/CD, а также всевозможные поведенческие первопричины со стороны сотрудников (как то частичное или полное отсутствие интереса к тестам ввиду их непонимания). В настройках CI/CD на проектах с развитыми практиками тестирования зачастую нельзя добавить код в кодовую базу, если на проекте после изменения не проходят тесты. В таких ситуациях часто тесты запускаются автоматически на каждое изменение и в каждой ветке. А бдительность коллег на ревью гарантирует, что тесты нельзя просто выключить.
Всё это означает, что падения тестов их не обесценивают, но при некоторых обстоятельствах могут и помогать. Если код поменялся, даже если это внутреннее устройство одного лишь только класса, то поведение этого класса стоит перепроверить через тесты. Это и правда дополнительная рутина, но рутина служащая дополнительным барьером от возможных ошибок в коде. Стоит отметить, что и более высокоуровневые тесты также не всегда полностью защищены от этой проблемы, даже если она и матеарилизуется в меньшей степени. Скажем, высокоуровневые тесты могут опираться на контейнер с базой данных, что может часто привести к таймаутам на некоторых машинах и Flaky тестам.
Бизнес ценность
Tests shouldn't verify units of code. Rather, they should verify units of behaviour: something that is meaningful for the problem domain and, ideally, something that a business person can recognize as useful.
A test should tell a story about about the problem your code helps to solve, and this story should be cohesive and meaningful to a non-programmer.
Среди идеалистов разработки широко распространена поговорка, что любой код является ответственностью (liability), нежели чем ценностью (asset). Поэтому кода должно быть как можно меньше, а если уж код написали, то он должен быть как можно ценнее. А в идеальном мире, у нас должен существовать только код, выполняющий какие-то бизнесс процессы. Всё, что не нацеленно на выполнение задач бизнеса, считается прослокой либо скрепляющим более важные части кода "клеем" ("glue code"). Данный код, разумеется, должен быть минимизирован.
В обсуждениях чего-то столь высокоуровнено можно много где покривить носом, но всё же данные идеи являются в основе своей трудно оспоримыми. Не стоит забывать, что любой наш код мы пишем для достижения каких-то целей. Осознание последнего является важной частью карьерного роста разработчика. Логичным развитием данной мысли является, что и тест кейсы должны быть напрямую завязаны с бизнесс функцией приложения, фиксируя и валидируя указанные бизнес требования. Ну, то есть быть высокоуровневыми и иметь максимально возможное покрытие. А следовательно, выступать этакой своеобразной документацией к вашему коду, в том числе доступной менеджменту.
Из указанного выше также делается заключение, что тест должен представлять собой ценность для менеджмента в виде этакой динамической документации к коду.
Но давайте попробуем вспомнить, насколько часто мы слышим или видим, чтобы менеджеры проекта или же хотя бы тимлиды применяли тесты таким образом. А должно ли менеджеру или ПО, задач у которых в современном бизнесе и так много, вообще быть интересным чтение нашего кода? Сразу же также учтём, что многие менеджеры могут не разбираться в программировании как в дисциплине. Как правило, их интерес к программному продукту останавливается на том, какую бизнес задачу код выполнить может, а какую нет, и как качественно этот код это сделает. И получать такую информацию они предпочитают через несколько более высокоуровневый интерфейс — через разработчика. Ну или хотя бы через вашу борду. А разработик же в своём большинстве достаточно квалифицирован, дабы разобраться в свойствах программного кода. Очень часто такое бывает, что разбираться в этом коде дополнительно ему не приходится, ведь он сам его же и написал.
Именно в связи с этим является несколько избыточным закладывать в тестируемый код читаемость большую, нежели чем таковая нужна именно разработчику. Иначе говоря, программный код именно как код, нежели чем как продукт представляет интерес больше всего именно разработчику, в связи с чем должен быть удобен больше всего команде разработки. А потому и тест кейс на, скажем, коннектор к базе данных или же репозиторий не должен являться проблемным до тех пор, пока этот тест кейс полезен именно разработчику. Что и является первоначально хорошим поводом изолировать этот код от всего остального и протестировать отдельно.
Какой подход к тестированию лучше использовать?
На самом деле, как правило, применять можно успешно любой из этих двух подходов, либо даже их комбинацию. Превосходства каждого из них легко продемонстрировать, а вот для выявить их недостатки зачастую весьма непросто. При этом очень часто забывается, что ваша среда разработки должна быть настроена на ваше же удобство, а не чьё-то другое. Если вам просто неудобно писать через, скажем, TDD, то попробуйте найти об этом компромисс с вами и вашими же коллегами.
Комментарии (10)


funca
03.09.2023 18:32+1Оба тезиса объединяет одна идея: код меняется при изменении требований, а требования чаще всего меняются в терминах вашего бизнеса (в смысле - предметной области, а не денег).
Поэтому если код и тесты писать (читай - производить декомпозицию) в бизнесовых терминах, то потом изменения будут даваться легче. Ну и читать проще, самим же разработчикам - менеджеры тут не причем.
На мой взгляд есть сильное заблуждение, что unit в OOP это обязательно отдельный класс. Класс может быть просто деталью реализации, которая сама по себе не несёт особой ценности в терминах вашей предметной области (DTO, например). Т.е. вы не можете про него сказать что-то вразумительное с точки зрения бизнес требований, не скатываясь на уровнь технических терминов - деталей реализации. Здесь тесты / моки в самом деле это пустая трата времени. Тестировать в изоляции нужно самостоятельные единицы, кторые что-то значат в вашей модели. А из скольки классов они состоят - одного или нескольких - это вопрос второстепенный.
ruomserg
А почему, позвольте, должно быть или то, или другое?! Меня учили как-то так:
Дополнительно, отмечу что для написания корректных тестов (и для решения проблемы "хрупких" тестов) — в мире придумана идеология 'Standard test environment'. Которая подразумевает что вы к своему проекту подключаете test-dependency, в которых специально обученные люди (BA или тест-инженеры) вам приготовили стандартные объекты из которых вы будете складывать окружение ваших тестов. То есть, если у вас зависимость "платежный шлюз", то вы не мокаете ее сами — а достаете готовый мок из тестовой библиотеки и запускаете. Поскольку этот мок настроен только на определенные запросы и ответы — у вас есть библиотека стандартных тестовых объектов (платежи, документы, и т.п.). И если вы именно эти объекты используете в своих тестах, то гарантируется во-первых, что всё со всем совместимо — и во-вторых, не надо лазить по кодам всех проектов и менять устаревшие данные в test/resources чтобы оживить тесты когда новые стори меняют существующую функциональность. Новую версию стандартной среды зарелизят, вы ее обновите в качестве зависимости в проекте — и если ваш код не сломался, значит все работает. А если сломался — ну значит надо чинить. А не так как обычно в проектах — в десяти местах мокается одно и то же, но разными способами. Потом оно ломается — и поди-пойми где правильно теперь, а где — нет...
И еще одна мысль — не тестируйте код. Тестируйте поведение. Если вы закладываетесь на определенное (нетривиальное — не надо тестить геттеры и сеттеры, а также стандартную библиотеку: их тестировали другие люди не глупее вас!) поведение кода — закрепите его тестом. Это помогает в разработке — легче собирать систему из заведомо работающих компонентов (и разбираться только с проблемами интеграции), чем из заведомо неработающих (и иметь геморрой и головную боль одновременно). Это помогает в понимании системы — тест явно показывает примеры, какие входные данные мы ждем, как примерно ведет себя окружение, и какой результат получается. Иногда просмотр тестов позволяет вообще не смотреть внутрь класса (если только не интересны детали реализации).
gordeevbr Автор
Добрый день! Это хорошие рассуждения.
Полагаю, можно начать с того, что единственное что вы "должны" - это в контракте с работодателем или с заказчиком, а остальное решается между разрабами, и решается очень по разному.
Описанное вами есть сугубо "мокистский" (очень не люблю это слово) подход. Только заместо "интеграционных" тестов я предпочитаю что-нибудь, что заходило бы через эндпоинты или через event listener, а проверяло бы HTTP Response, сайд эффекты в базе, события, или прочие внешние проявления поведения кода. Это ещё иногда называется фуникциональными тестами, системными, E2E, зависит от команды.
То, что вы называете "не рыба и не мясо" - как раз юнит тестирование по Фаулеру и Хорикову. У них "юнит" это не единица кода, а единица бизнес требований. Если вы почитаете их труды, то они вполне детально объясняют, в чём видят пользу последнего, что я и обсуждаю.
Соответственно, возникает вопрос, что выбрать. Вы можете выбрать всё сразу, но это может быть черезчур. Хотя и такое бывает. Я предпочитаю искать компромисс.
Что касается практик внутри конкретного бизнеса, может доходить до крайнего. Например, весьма непринято погружаться в тестирование у некоторых консалтеров. Такие бизнесы могут ставить своей задачей выдать готовый прототип за 2-3 месяца и отдать его кому-либо на дальнейшее поддержание. Предложение "давайте лучше тестировать" тут могут встретить в штыки. Хотя, повторюсь, крайность.
ruomserg
E2E тесты я оставляю за скобками — их обычно пишут другие люди с другим инструментарием. Меня больше интересуют тесты, которые можно запустить из IDE или которые запускаются автоматически как часть любого билд-пайплайна (а-ля mvn verify). В больших приложениях (где микросервисы, message-oriented-middleware, и проч) — E2E это отдельная песня...
Что касается локальных тестов, то я вижу три их вида (мы активно используем spring-boot):
Юнит-тесты — не требуют поднятия контекста спринга и не требуют спринг-раннера для запуска тестов, зависимости мокаются и инжектятся через конструктор. Работают очень быстро, добавляют уверенности что мы не ошиблись реализуя логику нашего класса.
Semi-integration (ни-рыба ни-мясо) тесты. Поднимают ограниченный контекст спринга через бины @TestConfiguration, запускаются через спринговый раннер. Тестируют совокупности классов на реализацию сторей (или существенных их частей). Это тоже довольно дешево.
Интеграционные тесты — используя testcontainters, поднимают некоторые зависимости в реальности (база данных, middleware), а некоторые мокают на уровне API (wiremock). Данные для теста подаются через штатные точки входа в приложение (rest, middleware), и контролируются преимущественно через штатные же выходы. Дополнительно проверяются side-эффекты в БД. Это по времени существенно дороже из-за запуска тестовых контейнеров (но все-равно дешевле чем отлаживать вживую на серверах).
Ну и E2E (как четвертый вид, к которому я имею мало отношения) — это запуск всего созвездия сервисов (втч проверка правильности конфигураций их соединения между собой), и отработка целых сценариев взаимодействия. Такое обычно запускают в ночь, потому что оно работает от получаса до нескольких часов (смотря какой набор сценариев заказываешь у E2E спецов). Плюс эти самые спецы сейчас могут быть заняты чужой заявкой, и встанешь в очередь… В общем, если в твоем коде выявили ошибку на E2E — это уже "не первый класс, не чистая работа..." и тебе должно быть стыдно — потому что это твои локальные тесты должны такое ловить, а не последние safety check перед продакшеном… Позорнее может быть, только если с ручного тестирования бага на тебя прилетит!
gordeevbr Автор
У вас хороший сетап тестов, и я бы сделал так же. Но с чем именно вы спорите? ????
nin-jin
Гляньте этот доклад про тестирование: https://page.hyoo.ru/#!=2jggfw_at1ily
ruomserg
Я не согласен с подходом, что юнит-тесты не нужны. Проблема в том, что их обычно не умеют готовить (тестируют тривиальную функциональность типа геттера-сеттера или тривиальной математики, пытаются добиться 100% test coverage выворачивая наружу кишки класса, и так далее). Если же тестировать нетривиальное поведение, то таких проблем не возникает. Например:
В целом, я пришел к мысли что не надо искать новые технологии или серебряные пули — надо просто аккуратно использовать то, что имеем. И ситуация улучшится.
nin-jin
Вы так и не поняли суть фрактальности. Компонентный тест модуля без зависимостей ничем не отличается от модульного. А без кишок наружу вы зависимости не замочите.
На проде у вас никогда не будет чистого состояния, так что тестирование на чистом состоянии просто, но не релеватно.
ruomserg
А кто сказал, что тесты ведутся на чистом состоянии? Из объектов standard test environment можно перед тестом создать такое состояние, которое нужно. Можно и вообще произвольное, но это грозит проблемами с поддержкой тестов в будущем.