
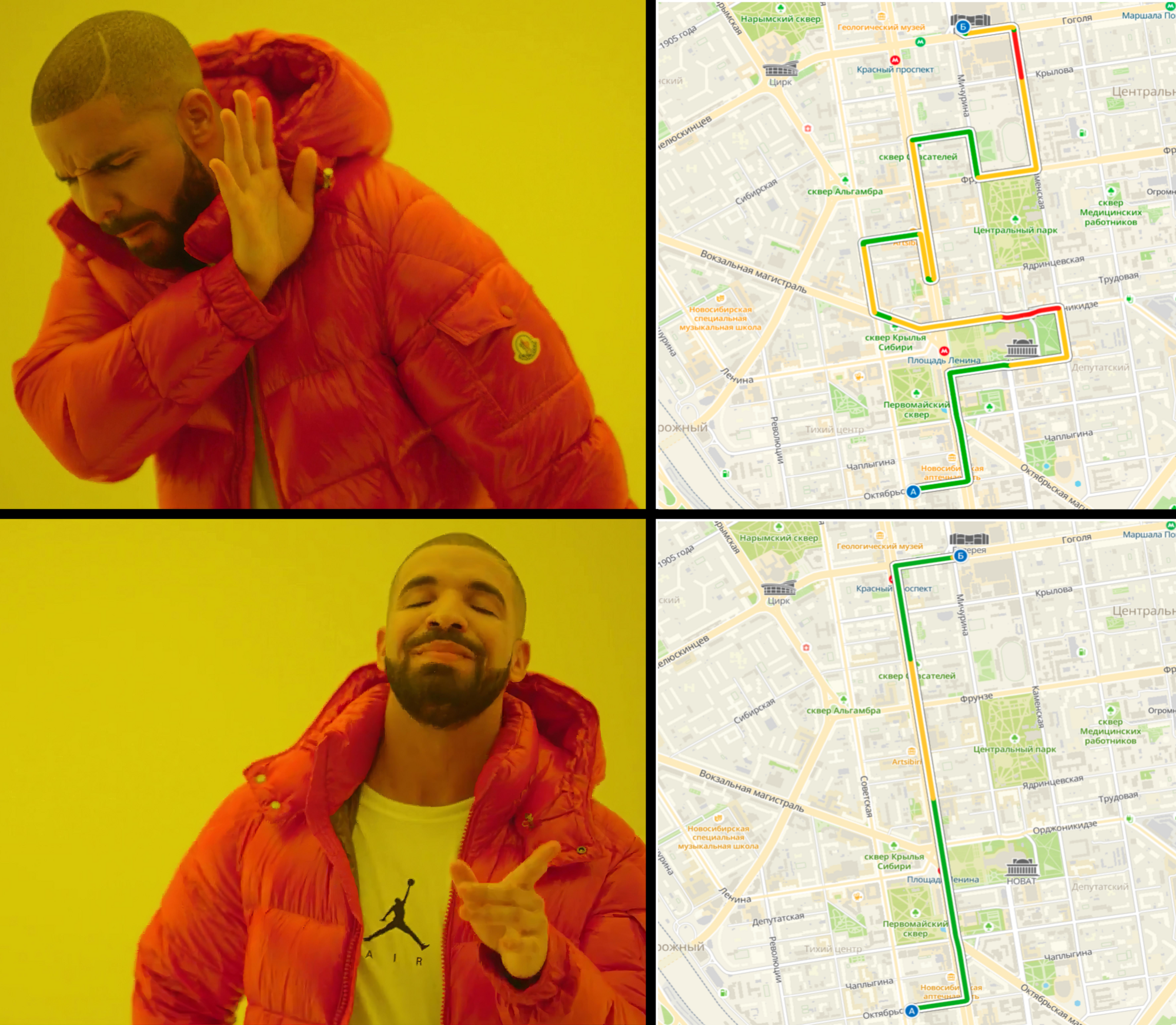
Хороший автомобильный маршрут из точки А в точку Б должен, с одной стороны, быть кратчайшим, а с другой — удобным для водителя. Как правильно вычислить время в пути мы уже рассказали, теперь — об удобстве маршрутов: что это такое, как его измерить и как мы его повышали.
Базовый алгоритм построения маршрутов
Дороги в городе представляются в виде дорожного графа, вершины которого — ключевые точки дорожной сети (перекрёстки, места изгибов и так далее), а рёбра — дорожные сегменты. Таким образом, считаем, что маршрут из А в Б — это путь в дорожном графе, начинающийся в вершине А и заканчивающийся в вершине Б.
Чтобы найти путь минимальной стоимости, в дорожном графе используется алгоритм А*: он вычислительно эффективный и находит оптимальный путь относительно выбранной функции стоимости.

В качестве функции стоимости удобно использовать время в пути (ETA): тогда найденный маршрут будет кратчайшим среди всех возможных. В простейшем случае время в пути складывается из двух факторов: времени проезда по рёбрам графа и дополнительного времени на совершение маневров при переходе из одной вершины графа в другую.

Про то, как мы вычисляем время в пути по ребру, можно прочитать в этой статье.
Что не так с алгоритмом
Проблема в выбранной функции стоимости — при построении маршрута мы не учитываем ничего, кроме времени в пути. Найденный маршрут может быть крайне неудобен, и пользователь не поедет по нему, несмотря на его оптимальность. Поэтому хочется добавить в функцию стоимости некоторые бизнес-правила, чтобы отбрасывать плохие маршруты ещё на этапе построения, а не на этапе пост-фильтрации.

Бизнес-логику реализуем с помощью штрафов — это дополнительное время на различные вариации построения. Завели на кольцо? Получаем за это 15 секунд штрафа. Пытаемся заехать на разбитую дорогу? Этот маленький манёвр будет стоить нам 5 минут. Увидели шлагбаум? Либо едем в объезд, либо плюсуем еще 60 минут.

В такой постановке удобно превратить время на совершение манёвров в штрафы за манёвры. Логика в определении размера штрафа может быть такой: сколько пользователь готов проехать лишнего времени по прямой, чтобы не совершать дополнительный манёвр? Так, может оказаться, что реальное время разворота всего 5 секунд, тогда как «психологическое» время — целых 60 секунд. Чем больше штрафы за повороты выберем, тем более прямыми будут получаться маршруты.
Важно понимать, что теперь полученная функция стоимости, хоть и представляется в секундах для удобства, не является временем в пути. И после построения маршрута итоговое время нужно вычислять отдельно. В итоге получаем такую функцию стоимости:
С помощью штрафов мы делаем маршруты немного длиннее, но при этом значительно более удобными. Удобными в том смысле, в котором его видим мы как разработчики. А что насчёт пользователей?
It’s Big Datain’ Time
Пользовательские предпочтения правилами описать уже гораздо сложнее. Например, на отказ от поездки по построенному маршруту может влиять множество факторов, о которых мы заранее не знаем или которые трудно оценить:
Дороги плохого качества: плохое покрытие, множество ям, отсутствующая разметка и так далее;
Непривычный маршрут: удобнее ездить по тем дорогам, по которым уже когда-то проезжал, поскольку знаешь, чего ожидать;
Сложные повороты или перекрёстки, которых хочется избежать в маршруте;
Личные предпочтения: какая-то альтернативная дорога просто может нравиться больше, даже если она не кратчайшая;
Системные ошибки в определении скоростей на некоторых дорогах (например, из-за недостатка данных), из-за чего построенный маршрут на самом деле не будет оптимальным.
К счастью, перечисленные проблемы обычно относятся только к некоторому участку маршрута, а не ко всему маршруту в целом. Поэтому пользователь во время поездки может съехать на дорогу, которая ему больше нравится (навигатор перестроит маршрут после съезда), вместо того, чтобы отказаться от поездки по навигатору вообще.

Для каждой состоявшейся поездки мы сохраняем маршрут: набор рёбер, которые мы предложили пользователю, и набор GPS-точек, полученные от пользователя во время поездки. С помощью небольшой магии мы превращаем набор GPS-точек в трек — набор рёбер, по которым ехал пользователь:

Таких пар «маршрут-трек» у нас очень много, значит, самое время открыть Jupyter Notebook и придумать, как извлечь из этих данных что-то полезное.
Вероятность проезда по ребру
Во время построения маршрута алгоритм перебирает десятки тысяч рёбер, чтобы найти оптимальный путь. Поэтому какие-то тяжёлые модели не получится добавить без значительной просадки перфоманса. Нужно что-то простое и эффективное — желательно то, что можно вычислить заранее, до построения маршрута.
И это «что-то» нашлось. Встречайте — вероятность проезда по рёбрам графа. Её расчёт выглядит примерно так: для каждого ребра и пары «маршрут-трек» сначала находим следующее число:
edge |
есть в track |
нет в track |
есть в route |
1 |
0 |
нет в route |
null |
null |
Усредняем массив полученных значений, посчитанных по всем парам «маршрут-трек» (null игнорируем в расчете среднего), и получаем вероятность проезда по ребру с учётом того, что через него построен маршрут:
Есть одна проблема: мы ограничены теми рёбрами, через которые маршруты строятся, и для некоторых ребер никакая вероятность не посчитается. Плюс нам хотелось бы поднять эту вероятность для тех рёбер, которых нет в маршрутах, но которые часто встречаются в треках. Для этого немного модифицируем формулу:
edge |
есть в track |
нет в track |
есть в route |
1 |
0 |
нет в route |
1 |
null |
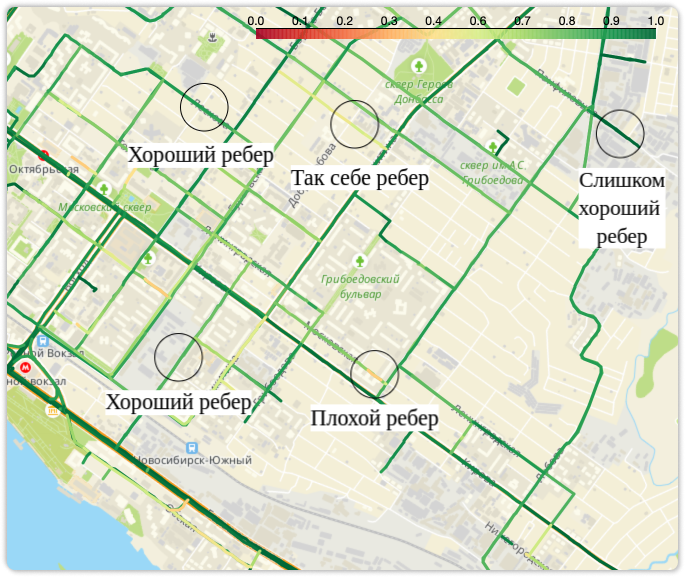
Получаем вот такие карты вероятностей проезда по рёбрам, которые можно анализировать на предмет того, где и почему встречаются «плохие» дороги с низким значением вероятности проезда:

— Нет, просто показываем
— Красивое...
Итак, мы научились считать некоторую характеристику, которая приблизительно показывает, насколько конкретное ребро нравится или не нравится пользователям. Давайте теперь использовать эту характеристику при определении «психологического» времени проезда по ребру, чтобы штрафовать рёбра за низкую вероятность проезда, например, вот так:
В качестве весовой функции может выступать любая неубывающая функция. Забегая вперёд, после серии экспериментов лучше всего себя показал вот такой зверь:
Идея есть, осталось её реализовать и посмотреть на результаты. Закрываем Jupyter Notebook и идём делать сервис.

Проблемы сходимости
Предвкушая невероятный успех от введения вероятностей, мы локально собрали первый прототип, начали строить маршруты и, применив метод пристального взгляда, поняли, что получается что-то не то. Новые маршруты слишком сильно отличались от старых, причем не всегда в лучшую сторону. Начали игнорировать какие-то очевидные короткие проезды, где-то, наоборот, стали избегать магистрали и предпочитать непонятные дороги.
Это происходило по двум причинам:
Рёбра графа сильно связаны между собой: изменение вероятности проезда на одном конкретном ребре повлечет за собой изменение вероятностей проезда на множестве других ребер графа;
Вероятность проезда по ребру — апостериорная: она зависит от алгоритма построения. Когда мы меняем алгоритм построения, автоматически меняются вероятности проезда по ребрам.
Получаем замкнутый круг:
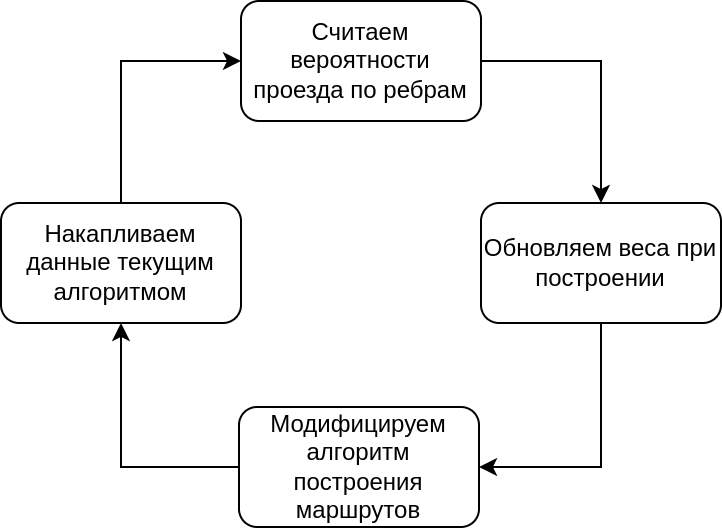
Всё указывает на то, что веса нужно подбирать итеративно до сходимости. Чтобы понять, что в нашем случае будет сходимостью, внимательно посмотрим на возможные значения вероятностей проезда.
Низкие и средние значения: пользователи редко проезжают по этому ребру в маршруте.
Вывод: мы слишком часто строим маршруты через это ребро. Нужно уменьшить вес при построении.Очень высокие значения: пользователи всегда проезжают по этому ребру в маршруте.
Вывод: либо это безальтернативный проезд, либо мы слишком редко строим маршруты через это ребро. Нужно увеличить вес при построении.Высокие значения: пользователи часто проезжают по этому ребру в маршруте, но иногда выбирают альтернативные проезды.
Вывод: ребро имеет оптимальную вероятность проезда. Вес при построении менять не нужно.
В идеале мы хотим, чтобы все рёбра имели высокое значение вероятности проезда, именно это и будем считать критерием сходимости. Каким методом оптимизации мы пользуемся? Конечно же, градиентным спуском! Будем итеративно двигать веса в нужную сторону тем сильнее, чем больше текущая вероятность отличается от оптимальной.
Чтобы помочь алгоритму быстрее сойтись к оптимуму, инициализируем веса не единицами, а в соответствии с типом дороги: например, магистралям поставим начальные значения повыше, а дорогам минимальной значимости — пониже. Кстати, такая начальная инициализация сама по себе сильно улучшает базовый алгоритм, даже без добавления вероятностей проезда.
Описываем удобство в цифрах
Прежде чем выкатывать изменения на прод, надо ответить на вопрос: как мы поймем, что стало лучше и удобнее? Есть два способа оценки:
Явный отклик: оценка маршрута в конце поездки, тапы на кнопку «Я знаю маршрут лучше»;
Неявный отклик: качество построенного маршрута на основе сопоставления маршрута и трека.

Сначала про явный отклик: итоговая оценка маршрута пользователем зависит не только и не столько от предложенной геометрии маршрута. Это будет мешать корректному анализу. Статистики по «Я знаю маршрут лучше» слишком мало, чтобы делать по ней какие-то далеко идущие выводы.
Поэтому основные метрики основаны на неявном отклике — его как раз очень много. В итоге мы остановились на трёх самых информативных метриках:
Процент времени, которое пользователь провёл на маршруте.
Процент длины маршрута, покрытого треком.
Количество перестроений маршрута во время поездки.
Предполагаем, что с удобного маршрута редко придётся съезжать, а если и придётся, то пользователь всё равно вернётся на изначальный маршрут через некоторое время.
Изменения начали проверять с помощью A/B-тестирования: на одном контуре использовали веса при построении маршрутов, на другом — не использовали. В течении нескольких итераций алгоритма метрики качества маршрутов росли, что сигнализировало о том, что алгоритм сходится к некоторому оптимуму.
 чаще ведёт на главные дороги города, несмотря на пробки. Забавный факт: время в пути для обоих маршрутов одинаковое.")
Когда убедились, что нет никаких серьёзных ошибок в построении, полностью выкатили изменения в тех городах, где достаточно данных для достоверного расчёта вероятностей. Чтобы учитывать изменения дорожного графа, мы не останавливаем итерации алгоритма и постоянно обновляем веса.
Вероятность совершения поворота
Если внимательно посмотреть на итоговую функцию стоимости при построении маршрута, может появиться непреодолимое желание добавить веса и на слагаемые во второй сумме:
Именно это мы и в итоге и сделали. Будем считать, что поворот — это пара рёбер в которой при переходе из
в
меняется направление движения. Таким образом, прямые проезды из одного сегмента дороги в другой мы не считаем поворотами.

Если посчитать характеристику, которая показывает вероятность проезда по паре ребер (с учётом, что она встречается в маршруте), то получим фактически то же самое, что уже посчитали до этого. Поэтому сделаем иначе — для каждого поворота в маршруте получим следующее число:
Вероятность совершения манёвра аналогично получается в результате усреднения вычисленных значений по всем парам «маршрут-трек».
Эта характеристика показывает, какова вероятность совершить поворот, если он был построен в маршруте и у пользователя была реальная возможность проехать по нему.

Дальнейшая судьба у этих вероятностей такая же, как у их старшего брата: итеративное обновление до сходимости, А/В-тестирование, замер метрик и попадание на прод. Только в этот раз всё прошло намного быстрее и более гладко, правда, и влияние на метрики было менее заметным. Главный профит от их добавления — это избегание при построении каких-то совсем неудобных поворотов, в особенности, разворотов.
Финал
Были также попытки перенести всё это на пешеходную маршрутизацию, но в ней идея использования вероятностей в таком виде не зашла и требует переосмысления. Сказывается недостаток данных и особенности функции стоимости, ведь для пешеходов мы, к сожалению, не считаем пробки, хотя где-то это было бы даже полезно.
В автомобильной маршрутизации мы достигли изначально поставленной цели: строить не только самые быстрые, но ещё и самые удобные для среднестатистического пользователя маршруты. Конечно, кроме вероятностей проезда было сделано ещё много всего для улучшения качества маршрутов: различные дополнительные штрафы при построении, модификация подбора и сортировки альтернативных маршрутов, ограничения на возможную геометрию… Но в первую очередь хотелось рассказать про самый интересный и «живой» компонент во всей схеме. Пока вы читали эту статью, возможно, он уже обновился :)
Комментарии (20)

Zara6502
05.09.2023 05:48+3Я обычно руководствуюсь не временем в пути как таковым, а движением в пути. То есть мне комфортнее ехать 12 минут, нежели проехать 4, а потом 7 минут тыркаться в пробке. Да, приеду в итоге быстрее на минуту, но в голове будет ощущение от торчания в пробке. Поэтому в большинстве своем игнорирую маршрут как таковой от навигатора и еду так, как знаю. Это конечно если знаю город (тут безусловно можно попасть на ремонт дороги, который навигатор учёл, а я не был в курсе, но такое редкость).
С помощью 2ГИС в качестве навигатора катаюсь уже больше 13-14 лет, нравится учет мелких улиц и дворовых проездов, например Яндекс упорно меня домой везёт по главной улице и потом дворами через 4 дома, причем там шлагбаум который мне никак не преодолеть, и такси он туда же вызывает (пешком идти 250 метров, вместо 30 если подать машину к моему же дому но с второстепенной улицы, причем с второстепенной можно уехать в три разных направления, а с главной только в одно с разворотом в 800 метрах), в итоге с такси стал вызывать их не к дому, а на точку на улице (писал в техподдержку, но они выслали мне какой-то гайд для модификации карты самостоятельно, даже не стал разбираться).

kkalmutskiy Автор
05.09.2023 05:48+2Мы пытаемся найти компромисс между тем, чтобы вести, с одной стороны, по удобным дорогам, а с другой стороны, поменьше стоять в пробках. Поэтому сейчас в том числе ушли от того, чтобы предлагать самый быстрый маршрут первым в списке: предлагаем лучший исходя из нескольких критериев. Добавить в этот список критерий "процент времени, проведенного в пробке" кажется интересной идеей
Zara6502
05.09.2023 05:48тут же по идее еще и расход топлива будет учитываться, ведь мелкие трогания и остановки кушают бензина больше чем постоянные 40-50 км/ч, летом это еще нагрев/перегрев двигателя (у меня была плавающая поломка, через 2 месяца только понял что она проявляется когда ползу в пробке, от перегрева вело пластиковый элемент).

hssergey
05.09.2023 05:48+1Что касается поворотов (правда, пользуюсь яндексом) - если показывает альтернативный маршрут, но для которого надо поворачивать на загруженной улице, то смотрю, насколько меньше время по альтернативному маршруту. Если отличается меньше чем на 10-15 минут, то поворачивать не буду, поеду как ехал.
kkalmutskiy Автор
05.09.2023 05:48+1Согласен, сложные маневры на загруженных улицах - большая проблема, введение вероятностей совершения поворотов в том числе помогают немного ее нивелировать, по крайней мере для тех поворотов, где стабильно напряженная дорожная ситуация

Wolframium13
05.09.2023 05:48Помню в эпоху динозавров, когда навигатор был отдельным прибором, там была настройка быстрый путь/простой путь.


antiquar
05.09.2023 05:48Считаете в Gurobi?
kkalmutskiy Автор
05.09.2023 05:48Большинство вычислений для вероятностей выполняется еще на этапе sql запроса, финальный процессинг уже на питоне


wslc
05.09.2023 05:48Что произойдет, если на высоковероятном ребре начнется ремонт? Как вы сможете это почувствовать?
То есть раньше у вас сработало бы переключение на другое ребро по трафику, а сейчас высокая вероятность ребра все равно погонит всех в пробку и вы здесь не получите фидбека, нужного для снижения вероятности. Как будто нужно отрубать вероятности, если скоростной профиль ребра существенно изменился.
kkalmutskiy Автор
05.09.2023 05:48Если все пользователи продолжат ехать по предложенному маршруту и никак иначе, то да, фидбека не будет и вероятности не пересчитаются. Такие ситуации мы обрабатываем на этапе пост-сортировки построенных маршрутов: например, если альтернативный маршрут будет значительно быстрее основного (самого удобного), то он станет основным. За счет этого построение все равно изменится и вероятности в итоге пересчитаются.
wslc
05.09.2023 05:48Даже если все пользователи будут знать о ремонте, у вас скорее всего есть лаг обработки данных порядка недели, поэтому весь этот период веса будут некорректно вести в ремонтирующуюся дорогу.
Мне правда интересно, почему это не считается проблемой. Обычно пользователи любят, когда им оперативно показывают дорожные события и как их обойти. Возможно, вероятности у вас сильно ограничены в разбросе и их влияние не так велико.
Повторюсь, что мне казалось бы естественным, снижать влияние вероятности, если ситуация несколько необычная, например, текущая скорость на эдже сильно отличается от исторической.

t278
05.09.2023 05:48+1почему для построения нужен интернет? Я нахожу сильно за городом. А построить маршрут (хоть примерный) не могу, нет связи.

Tatooine
05.09.2023 05:48+1Имхо, при построении маршрута еще очень важно учитывать:
Количество светофоров - чем их меньше тем лучше
Количество поворотов, особенно левых.
Лично я снес ваш навигатор - очень стал раздражать в последнее время разными особенностями работы:
Из предлагаемых нескольких маршрутов выбираю один определенный. Начинаю ехать. В определенный момент понимаю что в процессе езды навигатор перестроил маршрут меня не предупредив и приходится ехать куда мне нужно нужным маршрутом что бы маршрут перестроился обратно. При этом, навигатор может многократно предложить развернуться и поехать по тому маршруту что мне не нужен.
Неоднократно навигатор предлагал другие маршруты которые были якобы лучше, при этом по километражу и/или времени они были более длительные, либо вели через дворы или какие-то мелкие улочки, через которые ехать крайне неудобно.
Когда сворачиваешь навигатор чтобы зайти в другое приложение вверху остаётся "несмахиваемое окно" навигатора, как правило дико мешающее. Точнее как несмахиваемое, я его смахиваю, а оно обратно вылезает через секунду.
Про пешеходную навигацию я вообще молчу - не зря ходит анекдот: здесь аккуратно перебегите через шестиполосное шоссе, там будет дырка в заборе прикрытая картонкой, обычно там спит бомж, его нужно будет попросить подвинуться и пролезь в ту дырку в заборе. Потом просто идите напрямую через кладбище и т.п.

Nick0las
05.09.2023 05:48Спасибо за статью. Теперь логика раьоты стала понятней. Есть несколько вопросов:
А вводятся ли дополнительные штрафы на ребра графа и переходы между ребрами не из статистики а из внешних источников (информация от пользователей о ДТП, от дорожных служб о ремонтах, и.т.п.)?
Вы не думали сделать индивидуальные настройки для пользователя чтобы пользователь мог выбирать насколько ему комфортны проекды по разбитым дорогам, сложные маневры и прочие особенности маршрута, ... ?

Didimus
05.09.2023 05:48Что у вас в центре Москвы? У конкурента очень плохо.
Есть ли предупреждение о превышении скорости? Вот чтобы постоянно трещало, как дозиметр. Конкурент отключил этот функционал в рамках преступного сговора
aixx
у меня два вопроса к 2GIS немного не по теме статьи.
1) Например маршрут 1 час. Мы выезжаем еще до начала пробки, и маршрут прокладывается без учета того, что через полчаса, как раз там где мы будем ехать, будет ужасная пробка. Несмотря на то что ее сейчас там нет. Она там каждый день. И нужно было сразу ехать другим маршрутом, зная об этом заранее на основе прошлых данных.
2) научиться понимать скорость движения не только в среднем по всем полосам, а по каждой полосе многополосной дороги. Например трехполосная дорога, одна полоса налево, вторая прямо, третья направо. Вы же знаете какая машина куда едет, так и считайте три разные средние скорости. Чтобы не было такого: вот тут едем, тут быстро. А на самом деле там быстро только в правом ряду, а нам налево где стоять еще 10 минут на перекрестке.
есть у вас такое? нет? сделаете? чушь?
kkalmutskiy Автор
1) Мы сейчас стараемся это учитывать: предсказываем скорости на дорогах на час вперед и при построении маршрута берем именно те скорости, которые будут в момент, когда пользователь будет проезжать это место. Соответственно, если прогнозные скорости будут низкими, то мы предложим другой, более быстрый маршрут :)
2) Да, это отличная идея и мы хотим в итоге к этому прийти, работаем в этом направлении
Didimus
А вы считаете, скольких вы отправили на пустую сейчас дорогу? Постоянно вижу, как все едут по навигатору и с пустой широкой дороги сворачивают на узкий переулок, чтобы вернуться обратно в следующем квартале