
От переводчика:
Данный пост вышел летом 2022 года и является ответом разработчиков Redis на появление новой Redis-совместимой in-memory базы данных Dragonfly, которая использует многопоточную архитектуру для более простого вертикального масштабирования. Если интересно познакомится подробнее с некоторыми принципами внутреннего устройства Dragonfly, то милости прошу прочитать мой предыдущий перевод - Архитектура кеша DragonflyDB.
Redis — это фундаментальная технология, и поэтому мы время от времени встречаем людей, рассматривающих альтернативные архитектуры. Несколько лет назад эту тему подняла компания KeyDB , а недавно новый проект Dragonfly заявил, что является самым быстрым Redis-совместимым хранилищем данных в памяти. Мы верим, что эти проекты привносят много интересных технологий и идей, достойных обсуждения. Нам в компании Redis нравятся такого рода вызовы, поскольку они требуют от нас подтверждения архитектурных принципов, с которыми изначально был разработан Redis (снимаем шляпу перед Сальваторе Санфилиппо, также известному как antirez).
Хотя мы всегда ищем возможности для инноваций и повышения производительности и возможностей Redis, мы хотим поделиться своей точкой зрения и некоторыми размышлениями о том, почему архитектура Redis остается лучшей в своем классе для хранилища данных в памяти в режиме реального времени (кеш, база данных и все, что между ними).
Итак, в следующих разделах мы расскажем о наших взглядах на скорость и архитектурные различия в связи с проводимыми сравнениями. В конце этого поста мы также предоставили подробную информацию о тестах и сравнениях производительности с проектом Dragonfly, которые мы обсуждаем ниже и приглашаем вас просмотреть и воспроизвести их для себя.
Скорость
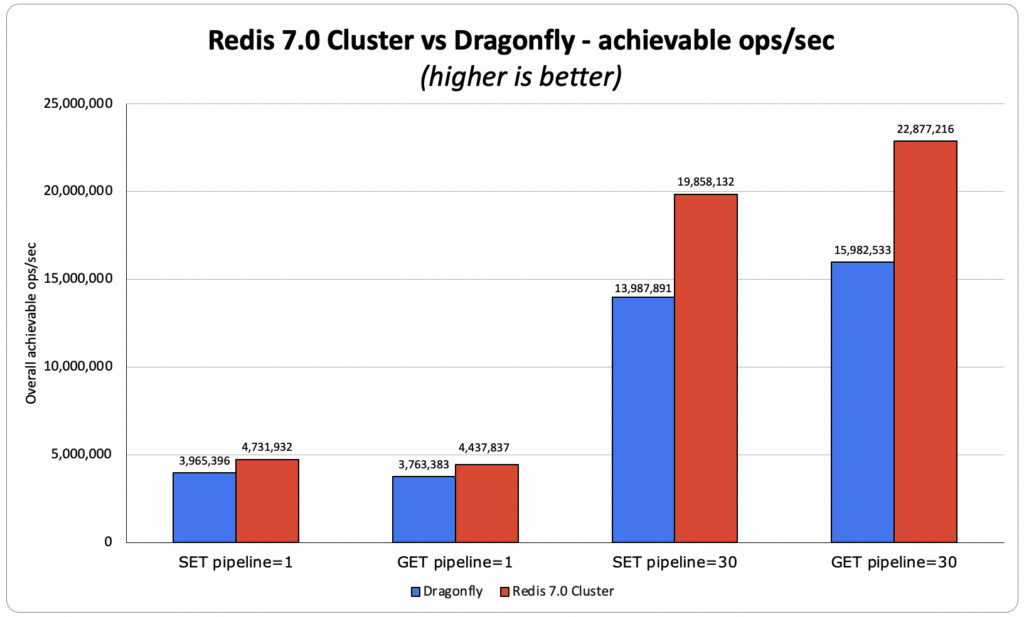
Бенчмарк Dragonfly сравнивает автономный экземпляр Redis с одним процессом (может использовать только одно ядро) с многопоточным инстансом Dragonfly, который может использовать все доступные ядра ВМ/сервера. К сожалению, это сравнение не отражает того, как работает Redis в реальном мире. Поэтому для более корректного и справедливого сравнения, мы сравнили Redis 7.0 Cluster с 40 шардами, который способен использовать большую часть ядер виртуальной машины, с Dragonfly. Мы использовали набор тестов производительности на самом большом типе инстанса, используемом командой Dragonfly в своих тестах, а именно AWS c6gn.16xlarge. В наших теста мы увидели, что Redis достигает пропускной способности на 18–40 % выше, чем Dragonfly, даже при использовании только 40 из 64 виртуальных ядер.

Архитектурные различия
Немного поднаготной
Мы считаем, что на многие архитектурные решения, принятые создателями этих многопоточных проектов, повлияли болевые точки, с которыми они столкнулись в своей предыдущей работе. Мы согласны с тем, что запуск одного процесса Redis на многоядерной машине, иногда с десятками ядер и сотнями ГБ памяти, не позволяет использовать все ресурсы, которые доступны. Но это не соответствует тому, для чего был разработан Redis (хотя достаточно многие используют его именно таким способом).
Redis масштабируется горизонтально за счет запуска множества процессов (с использованием Redis Cluster) даже в контексте одного облачного экземпляра. В Redis (компании) мы развили эту концепцию и создали Redis Enterprise, который предоставляет дополнительный уровень контроля, позволяющий нашим пользователям запускать Redis с возможность масштабирования, с высокой доступностью, мгновенным переключением при сбое, сохранением данных и резервным копированием, включенными по умолчанию.
Мы решили поделиться некоторыми принципами, которые мы используем за кулисами, чтобы помочь людям понять, что мы считаем хорошими инженерными практиками по запуску Redis в продакшене.
Архитектурные принципы
Запуск нескольких экземпляров Redis на ВМ
Запуск нескольких экземпляров Redis на 1 ВМ позволяет нам:
Масштабироваться линейно, как по вертикали, так и по горизонтали, используя полностью неразделяемую архитектуру. Это всегда будет обеспечивать большую гибкость по сравнению с многопоточной архитектурой, масштабируемой только по вертикали.
Увеличьте скорость репликации, поскольку репликация выполняется параллельно в нескольких процессах.
Быстрое восстановление после сбоя ВМ за счет того, что экземпляры Redis новой ВМ будут одновременно заполняться данными из нескольких внешних экземпляров Redis.
Ограничьте каждый процесс Redis разумным размером
Мы не допускаем, чтобы размер одного процесса Redis превышал 25 ГБ (и 50 ГБ при запуске Redis на Flash ). Это позволяет нам:
Пользоваться преимуществами copy-on-write без лишних накладных расходов по памяти при форке Redis для репликации, снапшотов и перезаписи AOF-файлов. И “да”, если вы этого не сделаете, вы (или ваши пользователи) заплатят высокую цену, как показано здесь .
Легко управлять кластером, быстро переносите шарды, осуществлять перенос данных с одного шарда на другой, масштабировать и перебалансировать - поскольку каждый экземпляр Redis остается небольшим.
Горизонтальное масштабирование имеет первостепенное значение
Возможность запуска хранилища данных в памяти с горизонтальным масштабированием чрезвычайно важна. Вот лишь несколько причин почему:
Лучшая отказоустойчивость — чем больше узлов вы используете в своем кластере, тем надежнее будет ваш кластер (если речь идет о кластере с шардированием и репликацией - примечание переводчика). Например, если вы запускаете свой набор данных в кластере из 3 узлов, а один узел деградирует, это 1/3 вашего кластера не работает; но если вы запускаете свой набор данных в кластере из 9 узлов и один узел деградирует, это всего лишь 1/9 вашего кластера не работает.
Легче масштабировать — гораздо проще добавить дополнительный узел кластер и перенести в него только часть набора данных. В отличии от вертикальное масштабирование, при котором необходимо поднять новый сервер и скопировать весь набор данных на него (и не забыть обо всех плохие вещи, которые могут произойти во время этого потенциально длительного процесса…).
Постепенное масштабирование гораздо более рентабельно — масштабирование по вертикали, особенно в облаке, обходится дорого. Во многих случаях вам нужно удвоить размер экземпляра, даже если вам просто нужно добавить несколько ГБ для ваших данных.
Высокая пропускная способность — в Redis мы видим много клиентов, которые выдерживают рабочие нагрузки с высокой пропускной способностью на небольших наборах данных, с очень высокой пропускной способностью сети и/или высоким PPS (количество пакетов в секунду). Подумайте о наборе данных объемом 1 ГБ с прецедентом использования более 1 млн операций в секунду. Имеет ли смысл запускать его на одноузловом кластере c6gn.16xlarge (128 ГБ с 64 ЦП и 100 Гбит/с по 2,7684 долл. США/ч) вместо трехузлового кластера c6gn.xlarge (8 ГБ. 4 ЦП до 25 Гбит/с по 0,1786 долл. США/ч каждый) менее чем на 20% от стоимости и гораздо более надежным способом? Возможность увеличить пропускную способность при сохранении экономической эффективности и повышении отказоустойчивости кажется простым ответом на этот вопрос.
Реалии NUMA — вертикальное масштабирование также означает запуск двухпроцессорного сервера с несколькими ядрами и большим объемом DRAM; эта архитектура на основе NUMA отлично подходит для многопроцессной архитектуры, такой как Redis, поскольку она больше похожа на сеть из небольших узлов. Но NUMA является более сложной задачей для многопоточной архитектуры, и, исходя из нашего опыта работы с другими многопоточными проектами, NUMA может снизить производительность хранилища данных в памяти на целых 80 %.
Ограничения пропускной способности хранилища — внешние диски, такие как AWS EBS, масштабируются не так быстро, как память и ЦП. На самом деле существуют ограничения пропускной способности хранилища, налагаемые поставщиками облачных услуг в зависимости от класса используемой машины. Таким образом, единственный способ эффективно масштабировать кластер, чтобы избежать уже описанных проблем и удовлетворить высокие требования к сохранности данных, — использовать горизонтальное масштабирование, т. е. добавлять больше узлов и дисков, подключенных к сети.
Эфемерный диск — это отличный способ запустить Redis на SSD (где SSD используется в качестве замены DRAM, но не в качестве постоянного хранилища) и получить доступ к затратам на дисковую базу данных при сохранении скорости Redis (см. сделать это с помощью Redis на Flash ). Опять же, когда эфемерный диск достигает своего предела, лучший способ, а во многих случаях и единственный способ масштабировать кластер — это добавить дополнительные узлы и дополнительные эфемерные диски.
Доступное оборудование — наконец, у нас есть много локальных клиентов, которые работают в локальном центре обработки данных, частном облаке и даже в небольших периферийных центрах обработки данных; в этих средах может быть трудно найти машины с более чем 64 ГБ памяти и 8 ЦП, и опять же единственный способ масштабирования — горизонтальное.
Итого
Мы ценим свежие, интересные идеи и технологии нашего сообщества, предлагаемые новой волной многопоточных проектов. Возможно даже, что некоторые из этих концепций могут появиться в Redis в будущем (например, io_uring , который мы уже начали изучать, более современные словари, более прикладное использование потоков и т. д.). Но в обозримом будущем мы не откажемся от базового принципа многопроцессной архитектуры без общего доступа, которую предоставляет Redis. Этот дизайн обеспечивает наилучшую производительность, масштабируемость и отказоустойчивость, а также поддерживает различные архитектуры развертывания, необходимые для платформы данных в памяти и в режиме реального времени.
Приложение Redis 7.0 и сведения об эталонном тесте Dragonfly
Сводка контрольных показателей
Версии:
Мы использовали Redis 7.0.0 и собрали его из исходников
Dragonfly был собран из исходников 3 июня (hash=e806e6ccd8c79e002f721a1a5ecb847bd7a06489), как рекомендовано в https://github.com/Dragonfly/dragonfly#building-from-source .
Цели:
Убедится, что результаты Dragonfly воспроизводимы, и определить полные условия, в которых они были получены (учитывая отсутствие некоторых конфигураций в memtier_benchmark, версии ОС и т. д.). Подробнее см. здесь
Определить наилучшую достижимую производительность OSS Redis 7.0.0 Cluster на инстансе AWS c6gn.16xlarge в соответствии с тестом от Dragonfly.
Конфигурации клиента:
Решение OSS Redis 7.0 требовало большего количества открытых подключений к кластеру Redis, учитывая, что каждый поток memtier_benchmark подключен ко всем сегментам.
Решение OSS Redis 7.0 показало наилучшие результаты с двумя процессами memtier_benchmark , выполняющими тест, но на одной и той же клиентской виртуальной машине, чтобы соответствовать тесту Dragonfly)
Использование ресурсов и оптимальная конфигурация:
OSS Redis Cluster достиг наилучшего результата с 40 основными сегментами, что означает наличие 24 резервных виртуальных ЦП на виртуальной машине. Хотя машина не использовалась полностью, мы обнаружили, что увеличение количества осколков не помогло, а скорее снизило общую производительность. Мы все еще изучаем это поведение.
С другой стороны, решение Dragonfly полностью пополнило виртуальную машину, и все 64 VCPU достигли 100-процентного использования.
Для обоих решений мы варьировали клиентские конфигурации для достижения наилучшего возможного результата. Как видно ниже, нам удалось воспроизвести большинство данных Dragonfly и даже превзойти лучшие результаты для пайплайна, равного 30.
Это означает, что есть потенциал для дальнейшего увеличения показателей, которых мы достигли с помощью Redis.
Наконец, мы также обнаружили, что и Redis, и Dragonfly не были ограничены сетевым PPS или пропускной способностью, учитывая, что мы подтвердили, что между двумя используемыми виртуальными машинами (для клиента и сервера? использующие c6gn.16xlarge) мы можем достичь более 10M PPS и более 30 Гбит/с для TCP с полезной нагрузкой ~300 байт.
Анализ результатов
-
GET пайплайн 1 sub-ms:
OSS Redis: 4,43 млн операций в секунду, где и avg, и 50ая персентил достигли задержки менее миллисекунды. Средняя задержка клиента составила 0.383 мс.
-
Dragonfly заявила о 4 млн операций в секунду:
Нам удалось воспроизвести 3,8 млн операций в секунду при средней задержке клиента 0.390 мс.
Redis против Dragonfly — пропускная способность Redis выше на 10 % по сравнению с заявленными результатами Dragonfly и на 18 % по сравнению с результатами Dragonfly, которые нам удалось воспроизвести.
-
GET пайплайн 30:
OSS Redis: 22,9 млн операций в секунду при средней задержке клиента 2.239 мс.
-
Dragonfly заявила о 15 млн операций в секунду:
Нам удалось воспроизвести 15,9 млн операций в секунду при средней задержке клиента 3.99 мс.
Redis против Dragonfly — Redis лучше на 43% (по сравнению с воспроизведенными результатами Dragonfly) и на 52% (по сравнению с заявленными результатами Dragonfly)
-
SET пайплайн 1 sub-ms:
OSS Redis: 4,74 млн операций в секунду, где и avg, и p50 достигли задержки менее миллисекунды. Средняя задержка клиента составила 0.391 мс.
-
Dragonfly заявила о 4 млн операций в секунду:
Нам удалось воспроизвести 4 млн операций в секунду при средней задержке клиента 0.500 мс.
Redis против Dragonfly — Redis лучше на 19**%** (мы воспроизвели те же результаты, что и Dragonfly)
-
SET пайплайн 30:
OSS Redis: 19,85 млн операций в секунду при средней задержке клиента 2.879 мс.
-
Dragonfly заявила о 10 млн операций в секунду:
Нам удалось воспроизвести 14 млн операций в секунду при средней задержке клиента 4.203 мс)
Redis против Dragonfly — Redis лучше на 42% (по сравнению с воспроизведенными результатами Dragonfly) и на 99% (по сравнению с заявленными результатами Dragonfly)
Команды memtier_benchmark , используемые для каждого варианта:
GET pipeline 1 sub-ms
Redis:
2X: memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram
Dragonfly:
memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
GET pipeline 30
Redis:
2X: memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram –pipeline 30
Dragonfly:
memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
SET pipeline 1 sub-ms
Redis:
2X: memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram
Dragonfly:
memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
SET pipeline 30
Redis:
2X: memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram –pipeline 30
Dragonfly:
memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30Детали инфраструктуры
Мы использовали один и тот же тип ВМ как для клиента (для запуска memtier_benchmark), так и для сервера (для запуска Redis и Dragonfly), вот спецификация:
-
ВМ :
-
AWS c6gn.16xlarge
aarch64
ARM Neoverse-N1
Количество ядер на сокет: 64
Количество потоков на ядро: 1
NUMA-узлы: 1
-
Ядро: Arm64 Kernel 5.10
Установленная память: 126
Мой канал в телеграмм про разработку и не только ;-)
Комментарии (7)

mikegordan
05.09.2023 09:21Я так понимаю ДрагонФлай просто обертка над форком многопоточного редиса - LevelDB?
И странный вопрос в общем у топика если давно есть LevelDB , многие им пользуются .
И еще "Итог" в середине статьи - это конечно...

arusakov Автор
05.09.2023 09:21Декларируется, что Dragonfly написан с нуля, а не является чьим-о форком.
Вопрос с одной стороны риторический, потому что вряд ли кто-то будет сейчас именно переписывать Redis. С другой стороны создатели продолжают топить, что потоки от лукавого, однопоточный Redis крут, масштабируйтесь горизонтально и все в таком роде :)
ufoton
Лучшая отказоустойчивость — чем больше узлов вы используете в своем кластере, тем надежнее будет ваш кластер. Например, если вы запускаете свой набор данных в кластере из 3 узлов, а один узел деградирует, это 1/3 вашего кластера не работает; но если вы запускаете свой набор данных в кластере из 9 узлов и один узел деградирует, это всего лишь 1/9 вашего кластера не работает.Ну во всём мире это ухудшение отказоустойчивости.
arusakov Автор
А в какой логике это ухудшает отказоустойчивость?
В логике авторов данные всегда размазаны по Redis Cluster равномерно, соответственно если одна машина выходит из строя, то чем больше машин было в кластере изначально, тем большая часть данных по прежнему доступна.
wslc
Вероятность, что хотя бы одна машина выйдет из строя растет при количестве машин, то есть если буквально читать, как написано в переводе, то мы чаще будем сталкиваться с недоступностью в части данных.
В оригинале используются слова "not performing" - здесь это употреблено в контексте репликации, то есть когда данные на всех узлах одинаковы. Соответственно, вы теряете в скорости чтения, но доступность всех данных сохраняется.
P.S.
Также по тексту "multiprocessing" переведено как "многопроцессорная", хотя здесь это "многопроцессная" в противопоставлении с многопоточной.
arusakov Автор
Спасибо за "многопроцессный", исправил.
Да, если добавить пометку, что речь про шардированный и реплицированный Redis Cluster, то абзац станет менее спорным :)
ufoton
Тогда же нужно добавить, что данных в таком кластере в два раза меньше. Или памяти нужно в 2 раза больше. Так что выводы по стоимости становятся не такими однозначными.