

Привет, Хабр!
Основным языком разработки у нас, в TIMELESS, является TypeScript, как на frontend, так и на backend. Поэтому в рамках идеи типизации всего и вся для работы с БД мы выбрали Prisma, которая позиционирует себя как “Next generation ORM for Node.js and TypeScript”.
Спустя год применения Prisma хотелось бы поделиться опытом ее использования при работе с PostgreSQL из Node.js приложения.
Мы сосредоточимся на вопросах, которые выходят за рамки начальных гайдов. А если вам интересно ознакомиться с базовыми принципами работы с Prisma, то на хабре уже есть такие статьи, например: https://habr.com/ru/company/timeweb/blog/654341/
Все, сказанное ниже, проверялось на версиях:
Node.js v17.4.0
TypeScript v4.9.3
Prisma v4.6.1
PostgreSQL v13.7
Типизация
Для начала бы хотелось сказать, что при использовании Prisma у типизации почти нет компромиссов. Как-то обойти типизированные запросы без явного использования any нельзя. Создавать частично типизированные запросы тоже. Встроить SQL внутрь типизированных запросов не получается. Никакого функционала а-ля QueryBuilder Prisma также не предоставляет.
Вы либо используете строго типизированные findFirst, findMany, create, updateMany и так далее, либо пишите чистый SQL через $queryRaw, $executeRaw и другие. На этом варианты заканчиваются.
И это хорошо. Наконец-то, после сборки TypeScript кода с проверкой типов у нас появляется уверенность в том, что невалидных запросов к БД не случится, обращения к несуществующим поля не будет и так далее.
Совет. С ростом проекта и усложнением запросов к базе данных скорее всего количество нетипизированных запросов через $queryRaw будет расти. Именно эти части приложения являются первыми кандидатами для покрытия автотестами.
Миграции
Prisma достаточно молода сама по себе (релиз v1 был в январе 2018 года), поэтому нельзя сказать, что функционал покрывает тематику миграций со всех сторон. При этом достаточно твердая база уже есть:
Prisma умеет генерировать автоматические миграции на основе изменений, которые произошли в схеме (команда
prisma migrate dev).Миграции записываются в виде SQL-файлов. Не нужно учить какой-то кастомный синтаксис для миграций, а также можно написать свою собственную миграцию на чистом SQL (
prisma migrate dev --name my_super_migration).Результаты примененных миграций записываются в специальную табличку (
_prisma_migrations). Поэтому Prisma всегда может определить, какие миграции были произведены и какие ещё осталось накатить (prisma migrate status).Можно осуществлять squash миграций, если их накопилось слишком много. Не самый короткий, но достаточно простой алгоритм действий описан тут. Спасибо @Luchnik22.
Но некоторых возможностей действительно не хватает.
Во-первых, Prisma создает только миграции “вверх”. Встроенного механизма для отмены миграций или приведения базы к состоянию конкретной миграции в прошлом нет.
Во-вторых, Prisma может сгенерировать миграции, которые ломаются. Например, так произойдет при добавлении в таблицу колонки NOT NULL без значения по-умолчанию. Если в таблице уже будут данные, то такая миграция при накатке сломается. Prisma пытается указать на ошибку, но делает это, на мой взгляд, слишком мягко. Просто добавляет комментарий в миграцию о том, что может что-то пойти не так.
/*
Warnings:
- Added the required column `createdAt` to the `User` table without a default value. This is not possible if the table is not empty.
*/Совет. Будьте внимательны. Проверяйте все миграции вручную или напишите небольшой скрипт в CI, который будет проверять наличие таких Warnings-комментариев в новых миграциях.
Но давайте представим, что такая миграция все-таки проскочила до одного из окружений. Что произойдет? А случится вполне неприятная история: Prisma запишет в базу данных информацию о неудачном применении миграции и на этом всё. Дальнейшие попытки накатить эту миграцию повторно будут отбрасываться сразу. Единственный вариант - вручную исправить положение через prisma migrate resolve и указать, что миграция применена или откатилась.
Для PostgreSQL эти телодвижения кажутся лишними. После отмены транзакции все изменения и так не будут применены (и в схеме, и в самих данных). И этот ручной контроль над сломанными миграциями добавляет лишней головной боли, потому что не у каждого есть прямой доступ к боевому окружению приложения, опыт что-то крутить “на проде” и так далее.
Совет. Старайтесь применять миграции к какой-то непустой базе данных в рамках CI, чтобы не пришлось разруливать сломанные миграции на проде.
Prisma и PgBouncer
При боевом использовании PostgreSQL запросы чаще всего идут не напрямую в БД, а через пулер соединений. Обычно это PgBouncer. Тогда Prisma добавляет нам немного проблем на этапе эксплуатации.
Во-первых, PgBouncer должен быть настроен на работу в режиме Transaction mode. Так нам предоставляется отдельное соединение под каждую транзакцию и именно в таком режиме Prisma умеет работать через пулер соединений.
Во-вторых, для обычных запросов в строке подключения необходимо указывать специальный параметр pgbouncer=true:
postgres://user:pswd@domain:6432/db?pgbouncer=trueТолько так Prisma будет сбрасывать prepared statements перед каждым запросом и оборачивать все запросы в транзакции, чтобы все работало корректно.
В-третьих, при накатке миграций необходимо обеспечить соединение без PgBouncer, потому что движок миграций рассчитан на работу напрямую с БД через одно соединение. Если вы используете какой-то облачный PostgreSQL, то для вас это скорее всего будут два разных url для подключения: через PgBouncer и напрямую к базе данных.
Совет. Продумайте заранее работу с переменными окружения, чтобы мигратор напрямую коннектился к БД, а приложение получало соединение через PgBouncer.
Официальная документация по данному вопросу тут: https://www.prisma.io/docs/guides/performance-and-optimization/connection-management/configure-pg-bouncer
findUnique vs findFirst
Типичным методом любой ORM является получение одной записи по каким-то критериям. Но в Prisma пошли дальше: на основе id сущности и всех уникальных полей выделяют отдельный метод findUnique, который получает запись именно по одному из уникальных ключей.
Это действительно удобно. Вы гарантированно получаете один уникальный объект, а не просто первый в выборке, если случайно ошиблись в фильтрах. Или, в случае изменения уникальных ключей, TypeScript укажет на запросы, которые нужно исправить.
Но, к сожалению, добавить дополнительные условия в такие запросы нельзя. Например, если вы пользуетесь техникой “soft delete” и помечаете записи удаленными, то вам придется писать дополнительный код.
Так не получится:
await prisma.user.findUnique({
where: {
id: 1,
deletedAt: { not: null }, // здесь ошибка
}
})Приходится писать так:
const user = await prisma.user.findUnique({ where: { id: 1 }})
if (!user || user.deletedAt) {
return null
}Совет. При всем удобстве интерфейса Prisma её все равно логично оборачивать в слой репозиториев, чтобы прятать внутри такие условия и другой дополнительный код.
Стоит сказать, что Prisma динамично развивается, и возможность добавлять дополнительные фильтры к основному уникальному появилась в preview режиме под названием UserWhereUniqueInput https://www.prisma.io/docs/reference/api-reference/prisma-client-reference#enable-the-ability-to-filter-on-non-unique-fields-with-userwhereuniqueinput
Include & Select в одном запросе
Только мы успели обрадоваться, что TypeScript проверяет всё максимально жестко и можно быть спокойными, как что-то связанное с Prisma стало падать в runtime. У нас это случилось при использовании include и select в одном запросе.
В нашей системе у каждого пользователя есть дашборд, на котором он видит краткую информацию информации о себе, а также прошедшие и будущие смены, статистику по зарплате, информацию по квестам и другое.
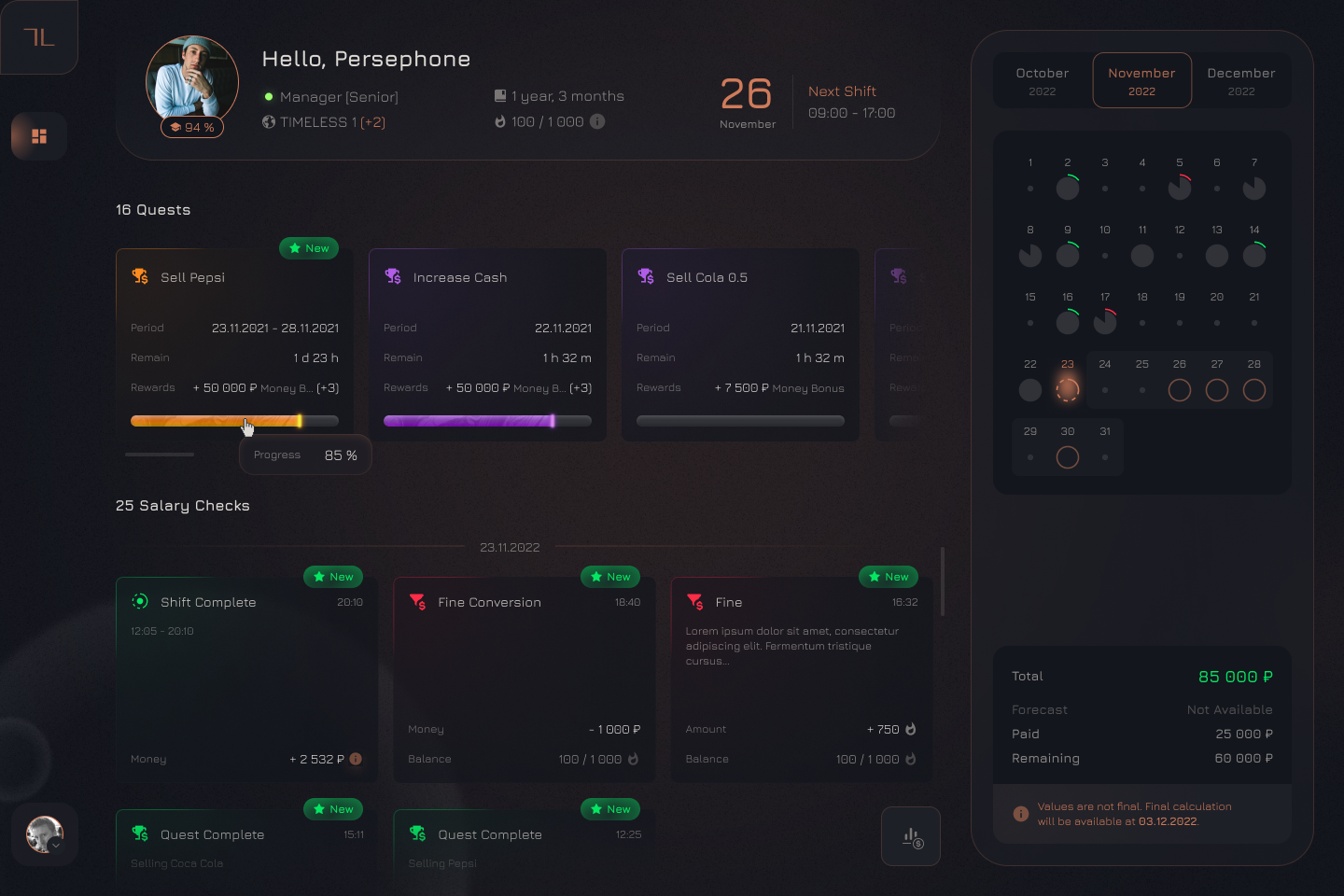
Соответственно, чтобы выбрать и пользователя, и связанные данные, мы воспользуемся JOIN. В Prisma такая операция выполняется через свойство include, в котором можно перечислить все связанные сущности, которые нам нужны:
await prisma.user.findUnique({
where: { id: 1 },
include: {
roles: true, // все роли пользователя
locations: true, // все локации, где он работает
},
})Затем мы решили, что в одном месте объявлено слишком много параметров или появилась необходимость переиспользовать аргументы для данного вызова. Так или иначе мы вынесли их в отдельную переменную константу:
const arg: Prisma.UserFindUniqueArgs = {
where: { id: 1 },
include: {
roles: true,
locations: true,
},
}
await prisma.user.findUnique(arg)А затем, как вишенка на торте, решили немного изменить запрос, воспользоваться select и перечислить только малую часть полей нашего объекта User, потому что другие нам не нужны:
const arg: Prisma.UserFindUniqueArgs = {
where: { id: 1 },
select: { id: true, name: true },
include: {
roles: true,
locations: true,
},
}
await prisma.user.findUnique(arg)Все прекрасно, TypeScript проблем не выдает. Только этот код падает в runtime с ошибкой:
Please either use
includeorselect, but not both at the same time
При объявлении аргументов непосредственно в месте вызова findUnique() ошибка выявляется на этапе проверки типов, если же код писать иначе, то увы.
С технической точки зрения данная ошибка не далеко ушла от прямого использования any везде, где только можно. Но зрительно сложно определить, что в таком коде в принципе могут быть проблемы, особенно если TypeScript не замечает проблем.
Совет. Наверняка, есть и другие места, в которых можно легко добиться ошибки призмы в runtime, но у нас это случалось исключительно при совместном использовании include & select. Либо составляйте объект с ключами верхнего уровня на месте вызова методов призмы, либо больше инвестируйте времени в unit-тесты :)
Проблема N+1 запросов и батчинг в Prisma
Современный backend сталкивается с необходимостью реализации GraphQL API, а это при решении "в лоб" выливается в увеличение количества запросов к БД в угоду удобному получению данных на клиенте.
Сотрудники наших баров выходят на заранее запланированные смены, поэтому мы отображаем пользователей и все смены на месяц на одной странице:
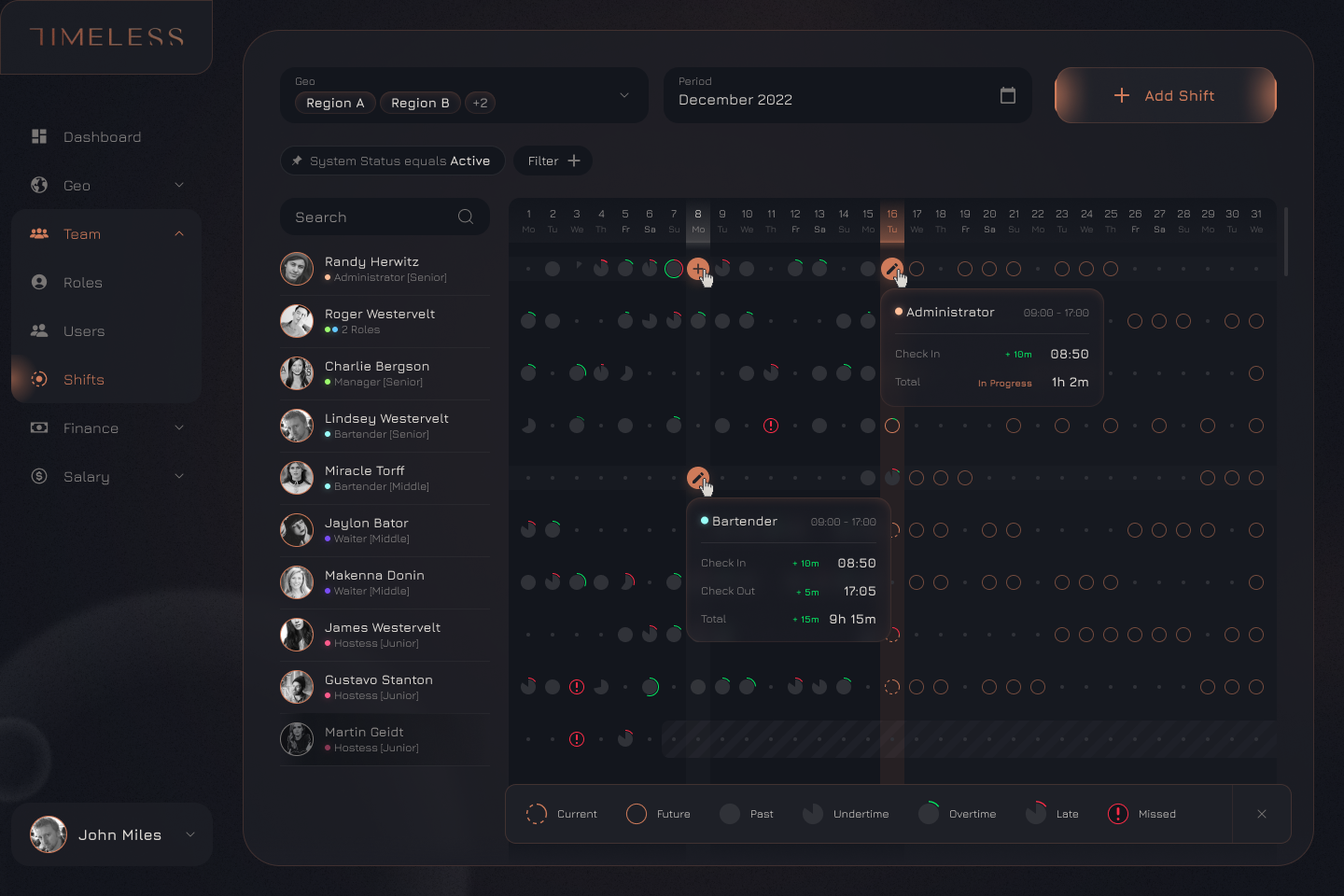
Давайте рассмотрим пример GraphQL-запроса пользователей и их смен:
query UsersWithShifts {
users {
id
name
shifts {
id
startedAt
finishedAt
}
}
}Резолвер users выполняет один запрос за списком пользователей:
await prisma.user.findMany()А затем в резолвере shifts для каждого пользователя необходимо выбрать все смены:
await prisma.shift.findMany({ where: { userId: user.id }})Так и получается N + 1 запросов, что не есть хорошо.
Это распространенная проблема и Prisma предлагает решение через Fluent API и батчинг запросов, которые начинаются через findUnique(). Запрос за сменами выше необходимо переписать с использование следующей конструкции:
await prisma.user
.findUnique({ where: { id: user.id }})
.shifts()Выглядит это контринтуитивно, но оптимизация подобных запросов выполняется в Prisma именно так. Сначала нужно ещё раз найти пользователя через findUnique(), а потом вытащить связанные с ним смены через .shifts().
В таком варианте изначальные дополнительные N запросов под капотом будут объединены в один запрос. Важным условием здесь является то, что вызов всех вложенных резолверов должен быть объединен в общий Promise.all(), иначе магия батчинга перестает работать.
Совет: Преждевременная оптимизация — это зло, но использование такого подхода в Prisma при реализации GraphQL почти не вредит читаемости кода и избавляет от лишних N запросов к БД.
Официальная документация по данному вопросу здесь: https://www.prisma.io/docs/guides/performance-and-optimization/query-optimization-performance#solving-n1-in-graphql-with-findunique-and-prismas-dataloader
Итого
Prisma отлично показывает себя в качестве ORM. Ускоряет нас и в части написания запросов, и при создании миграций. А мощная типизация помогает избежать каких-то глупых ошибок или заведомо неверных запросов при постоянно растущей кодовой базе.
Минусы стандартны для всех ORM:
Есть уникальные подводные камни, как и везде, но их не так уж и много в повседневной работе;
Не любой запрос, который можно написать на SQL, можно написать на Prisma. Но такова цена скорости, удобства и типизации.
В целом проект очень активно развивается, возможно в скором времени Prisma можно будет называть лучшей ORM в экосистеме Node.js и TypeScript.
Luchnik22
Спасибо за статью, в своё время тоже наступили на эти же грабли в наших продуктах.
Про миграции - не вижу проблем в том, что их много + нужно проводить миграции так, чтобы не нужно было мигрировать обратно, а можно было просто запустить старую версию бекенда (мы этим пару раз пользовались, как раз без отката базы данных), а разработать универсальный механизм отката миграций, который бы всех устраивал, как по мне невозможно. Если вас действительно беспокоит количество миграций, то squash всё же есть
Попробуйте ещё в свой стек добавить NexusJS, возможно меньше будет беспокоить N+1 и скорее всего почувствуете небольшой прирост в скорости написания новых фичей
arusakov Автор
Спасибо за комментарий.
Про откат миграций действительно вопрос дискуссионный, не каждую миграцию можно откатить и тд. Но так скажем новым адептам призмы будет не лишним знать такой нюанс, особенно если они пришли с опытом инструментов, где такое так или иначе присутствует.
За squash отдельное спасибо, внесу обновление в статью.