
В данной серии статей я подробно рассказываю о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
Краткое содержание предыдущей серии, последней, посвящённой проектированию спецификации языка:
Операторы жизненного цикла наборов данных (продолжение)
Операторы контроля потока выполнения
Операторы управления контекстом исполнения
Операторы выражений
В данном эпизоде мы наконец-то перейдём к самому интересному — имплементации. Хорошо, когда есть развёрнутая постановка задачи, можно просто брать спеку, и писать код согласно плану.
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.
5. Имплементация. Краткое лирическое отступление перед тем, как
Давным-давно, на одном геоинформационном проекте жил-был инструмент, о котором я писал уже тут статью, так что можете себе представить, чё это за зверь такой был. История у него получилась долгая, трудная, и пересказывать её здесь ещё раз я не стану, но если попробовать дать сухую выжимку, то изначально это был набор проприетарных расчётно-аналитических алгоритмов под одной обложкой (сильно оптимизированных на достаточно низком уровне RDD API), плюс некоторая программная обвязка для запуска их по цепочке в едином контексте исполнения на Spark.
На позднем этапе к ним (как водится, по классическому остаточному принципу) добавились функции общего назначения — для упрощения организации процессов ETL, которые в какой-то момент стали отъедать слишком значительную долю усилий команды. Знакомо звучит? Верно, на чём делаем аналитику, на том же инструментарии выстраиваем и ETL. В нашем случае 40% времени и ресурсов уходит на ETL — столько же, сколько и на сам анализ. Такой вот проект.
В итоге получился вполне работоспособный комбинированный инструмент, вот только вместо нормального человеко-прочитаемого языка для конфигурации процессов в нём было прямое отражение внутренней объектной модели в Java Properties, или, того хуже, JSON.
Для примера, сериализованная в формате Java Properties ОМ с высоты птичьего полёта:

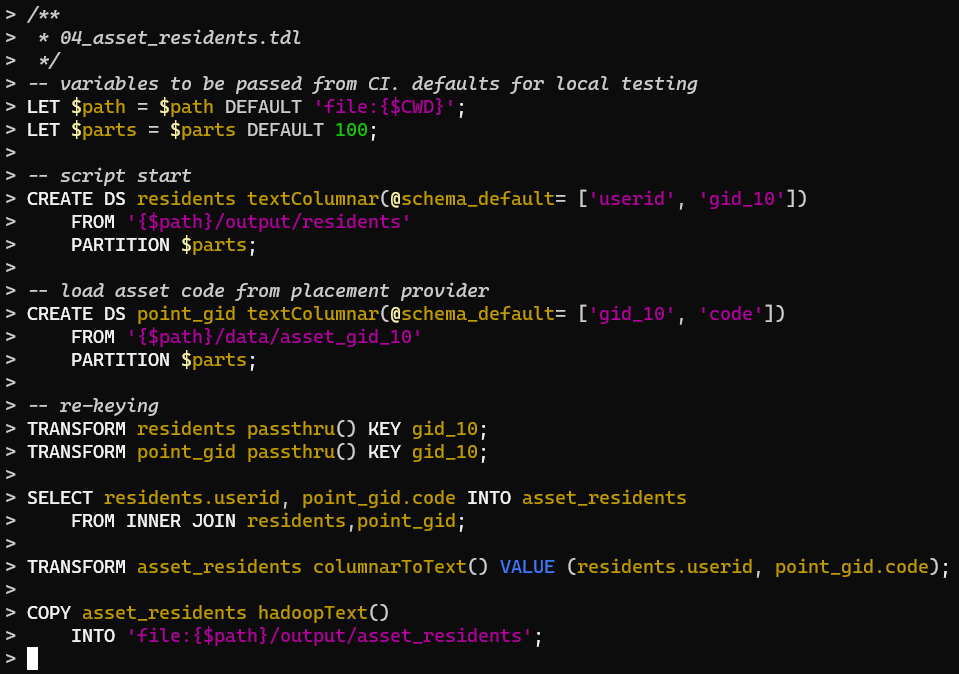
Шагов в этом процессе всего порядка 50, что совсем немного, а кода — десяток экранов. В JSON это дело выглядит ещё размашистее. Мало того, что писать (а тем более править) такие сериализованные ОМ тяжело, и сам объём сколько-нибудь продвинутого конфига превышает всякие разумные рамки, так и без обхода AST сделать вменяемый контроль потока выполнения, мягко говоря, непросто. В SQL такой же процесс из 50 шагов уместился бы в 50 операторов — примерно 2 экрана текста.
Также немаловажно, что писался прежний инструмент несколькими разработчиками в условиях цейтнота, поэтому устроен был внутри весьма неряшливо, и пропускал кучу проверок. Аналитики быстро это просекли, и стали делать всякие грязные хаки, пользуясь дырами в коде. Смотришь потом на конфиги, задеплоенные на прод, и такой про себя «божечки-кошечки… штоэто?! как это, блин, вообще работает, и почему вщ это работает?!»
А вот новый инструмент, получивший бесхитростное наименование «Data Cooker ETL» (прямой перевод «готовим данные ETL»), разрабатывался уже с оглядкой на предыдущий опыт, уже с учётом всех предыдущих ошибок, без ограничений по времени, и по заранее прописанному плану. На проектирование языка у меня ушло несколько месяцев — с постоянными экспериментами в коде, для чего в прежний инструмент были добавлены две операции, реализующие SELECT отдельно для колоночных и для геометрических наборов данных, — не только как proof of concept, но и чтобы аналитики постепенно привыкали к ним в продакшене.
И, как говорится, хорошие художники без стеснения заимствуют, а гениальные внаглую крадут. Мне до гения далеко, но тем не менее, половина алгоритмов общего назначения из библиотеки прежнего инструмента послужила основой для большинства трансформаций в Data Cooker ETL, — после доработки и переосмысления, — а ещё некоторая часть функциональности была перенесена на уровень самого языка. И если вы подумали сейчас, что первые пару месяцев разработки на правом мониторе у меня было открыто окно IDE с новый проектом, а на левом со старым, и я периодически делал копипасту слева направо, то вы не ошибётесь. Значительная часть того, что не было сломано, перекочевало без значительных изменений.
Но вот ядро (то есть, интерпретатор диалекта SQL) было написано с нуля. От старого языка осталось только название, — Transform Definition Language, версия 4, — больше как оммаж, чем для сохранения преемственности.
SQL — это амальгамация нескольких domain specific языков, а именно — Data Definition Language, Data Manipulation Language, Data Control Language, и собственно Data Query Language, — каждый из которых является пересекающимся с остальными подмножеством языка. Плюс вендорские расширения, часто транзакционные и процедурно-ориентированные, тоже со своими частичными DSL. В нашем случае Transform Definition Language — это диалект SQL, который одновременно базируется на DDL, DQL, DCL, и имеет операторы для control flow.
Итак, любая имплементация инструмента для работы с данными начинается с модели представления этих данных.
6. Имплементация. Наборы данных в контексте исполнения
У нас SQL, как много раз говорилось, объектно-ориентированный, и записи наборов данных представляют собой объекты весьма свободной структуры. Мы должны уметь загружать не только произвольный JSON без схемы (и обращаться к любым атрибутам по имени, сколь глубоко вложенными бы они ни были), но также и явно колоночные данные, и геометрии нескольких видов, и непрозрачный текст/наборы байтов.
Поэтому интерфейс «запись» у нас будет выглядеть следующим образом:
public interface Record<T> extends Serializable {
ObjectMapper BSON = new ObjectMapper(new BsonFactory()).enable(DeserializationFeature.USE_JAVA_ARRAY_FOR_JSON_ARRAY);
List<String> attrs();
T put(Map<String, Object> payload);
T put(String attr, Object value);
byte[] asBytes(String attr);
Double asDouble(String attr);
Integer asInt(String attr);
Object asIs(String attr);
Long asLong(String attr);
String asString(String attr);
Map<String, Object> asIs();
Object clone();
}Здесь и далее весь Java код будет представлен в целях иллюстрации, в виде кратких выжимок со ссылками на полные исходники на Гитхабе.
Хранить произвольный JSON в памяти в развёрнутом виде проще всего в виде мапы, а сериализовывать в BSON. В первоначальных экспериментах для сериализации я длительное время использовал библиотеку Google FlatBuffers (вариант для Java), но на практике BSON оказался заметно быстрее, и даже в большинстве кейсов чуть-чуть компактнее, нежели FlatBuffers.Map.
Так что же у нас определено в интерфейсе записи?
- Метод, который вернёт список имён атрибутов верхнего уровня
attrs(), - метод, который вернёт все атрибуты верхнего уровня с их значениями как мапу
asIs(), - методы, которые установят значения атрибутов верхнего уровня по одному
put()и сразу пачкойput(мапа), - а также методы, которые вернут значение какого-то атрибута, приведя его к определённому базовому типу
as{Type}(), а так же без приведенияasIs().
Дальше уже можно написать конкретные имплементации, соответствующие нашей системе типов наборов дан…
Так-так, секундочку! Зачем интерфейс и отдельные имплементирующие классы? Почему бы не хранить всё в JSON (BSON) мапах, как сказано выше, тем более что геометрия у нас читается обычно из GeoJSON?
А затем, что у нас объекты разных типов наборов данных имеют собственные правила для доступа к своим атрибутам. К примеру, тип Structured (== JSON без схемы) должен позволять добираться до глубоко вложенных атрибутов, среди которых могут быть, например, массивы. То есть, атрибут с именем "[2].name" для объекта вот такого вида
[
{"name": "Alba", "length": 956, "categories" : [9, 10, 12] },
{ "name": "Betula", "length": 443, "categories" : [9, 10, 66, 95] },
{ "name": "Cruda", "length": 747, "categories" : [5, 18, 4] },
]должен привести к выбору значения 'Cruda' (SQL-ная строка). А атрибут с именем "[1].categories[2:]" должен вернуть массив [66, 95] (SQL-ный числовой ARRAY).
В случае же, например, данных типа Columnar разбирать имя атрибута не нужно, а нужно просто вернуть значение колонки с заданным именем, ну или SQL-ный NULL, если такой колонки нет. Для PlainText имя атрибута вообще неважно, мы всегда вернём его полное содержание из byte[], приведённое к требуемому типу — тут вообще никакого маппинга нет.
Для геометрий же есть ещё и чисто геометрические данные, которые вообще не мутабельные, и перемешивать их с произвольными атрибутами совершенно не следует, то есть, надо хранить где-то близко, но отдельно.
Так вот, с учётом вышесказанного, классы записей будут свои для каждого типа, имплементирующие Record, и в качестве основы мы можем без зазрения совести использовать уже готовые базовые классы из Hadoop и JTS, расширяя их. А именно:
-
PlainText:class PlainText extends Text implements Record<PlainText> -
Structured:class Structured implements KryoSerializable, Record<Structured> -
Columnar:class Columnar implements KryoSerializable, Record<Columnar> - Геометрические:
interface SpatialRecord<T extends Geometry> extends Record<T>-
Point:class PointEx extends Point implements SpatialRecord<PointEx>, KryoSerializable -
Polygon:class PolygonEx extends Polygon implements SpatialRecord<PolygonEx>, KryoSerializable -
Track:class SegmentedTrack extends GeometryCollection implements Lineal, Iterable<Geometry>, SpatialRecord<SegmentedTrack>, KryoSerializable-
Geometryвыше это:class TrackSegment extends GeometryCollection implements Lineal, Iterable<Geometry>, SpatialRecord<TrackSegment>- И
Geometryвыше это снова тот жеPointEx, что и в типеPoint
- И
-
-
Класс записи типа Track выглядит немножко как смерть Кощеева, но не писать же свою библиотеку для геометрий — а JTS, хорошо известная, имеет абсолютный минимум зависимостей, и очень нам подходит. Text в PlainText — это хадуповский библиотечный Text.
Все конечные классы явно имплементируют интерфейс KryoSerializable — в качестве сериализатора мы будем именно его использовать, привяжемся явно. Штуки типа доступа к атрибутам без полной десериализации мы делать не собираемся — круг задач ETL таких вещей не предполагает, и мы всегда работаем с записью целиком.
Методы write() и read() можно глянуть на примере PolygonEx — чтобы слегка ужаснуться. Впрочем, не так уж и больно писать подобный код. Сериализация ведь вообще вещь низкоуровневая, поэтому при использовании FlatBuffers было ещё больше противной низкоуровневой возни с атрибутами (которые у нас могут быть любого типа), а BSON позволяет обойтись куда проще и легче — хоп и записал сразу мапу, хоп и прочитал сразу мапу.
Далее у нас идёт описание набора данных в контексте исполнения, то есть класс, который связывает спарковую JavaPairRDD<Object, <Record<?>> — наш "физический" уровень, и метаданные контекста, позволяющие доступ к атрибутам записи получить из более высокого уровня «системы типов SQL».
Приведу его здесь почти целиком, и прокомментирую интересные вещи:
public class DataStream {
public final StreamType streamType;
public final JavaPairRDD<Object, Record<?>> rdd;
private int usages = 0;
public final Accessor<? extends Record<?>> accessor;
public DataStream(StreamType streamType, JavaPairRDD<Object, Record<?>> rdd, Map<String, List<String>> attributes) {
accessor = streamType.accessor(attributes);
this.streamType = streamType;
this.rdd = rdd;
}
public DataStream(JavaPairRDD<Object, Record<?>> rdd) {
accessor = new PlainTextAccessor();
streamType = StreamType.PlainText;
this.rdd = rdd;
}
public int getUsages() {
return usages;
}
public int surpassUsages() {
if (usages < DataContext.usageThreshold()) {
usages = DataContext.usageThreshold();
}
if (rdd.getStorageLevel() == StorageLevel.NONE()) {
rdd.persist(DataContext.storageLevel());
}
return usages;
}
public int incUsages() {
if ((++usages == DataContext.usageThreshold()) && (rdd.getStorageLevel() == StorageLevel.NONE())) {
rdd.persist(DataContext.storageLevel());
}
return usages;
}
}Интересных вещей тут ровно две. Во-первых, поле типа Accessor<? extends Record<?>>.
Во-вторых, встроенный счётчик использований набора данных, который при превышении заданного в параметре контекста исполнения @usage_threshold количества меняет уровень персистентности RDD со StorageLevel.NONE на тот, который тоже задан в параметре контекста исполнения @storage_level. Помните оператор OPTIONS? Вот для настройки этих параметров он и используется.
Ну, со счётчиком-то просто. А вот дополнительный аксессор зачем, да ещё и с отдельным полем типа StreamType? А затем, что уровней атрибутов у нас может быть несколько, и это даже вынесено в синтаксис языка. Точнее, во всех типах, кроме Track, он один — верхний, а в Track их три: сам трек, его сегменты, точки сегментов. На каждом уровне они собственные, и метаданные о них надо где-то и хранить по отдельности, как и контролировать доступ к нужному уровню атрибутов объекта записи.
Если не выносить аксессор в отдельный класс, пришлось бы делать отдельные подтипы DataStream для каждого типа наборов данных, но и номенклатура енума StreamType несколько больше, чем типы наборов данные, перечисленные сами по себе. Впрочем, речь о ней пойдёт чуть позже.
Хорошо, с контекстом наборов данных разобрались. Теперь можно подумать о переменных и параметрах.
7. Имплементация. Переменные, настройки контекста исполнения, и метаданные параметров подключаемых функций
Приводить код классов VariablesContext (контексты переменных), OptionsContext (настройки контекста исполнения, устанавливаемые через оператор OPTIONS), и Configuration (параметры любой из подключаемых функций — адаптеров хранилищ, трансформаций, операций) я здесь полностью не буду.
Но все эти контексты очень похожи: любые наборы параметров на физическом уровне представлены как простой HashMap<String, Object>, и конкретный класс всего лишь обеспечивает интерфейс для получения значения параметра по его имени в заданном типе из системы типов переменных, производя приведение на лету. Различаются только правила, по которым производится приведение значения к нужному типу.
Для контекстов переменных и параметров контекста исполнения достаточно методов getArray(), getString(), getNumber(), — и в случае с VariablesContext необходимо обращаться к родительскому контексту, если он есть, а переменной с указанным именем в текущем инстансе не обнаружилось. Ведь как мы помним, операторные скобки BEGIN … END у нас порождают внутренний контекст переменных.
Что же касается класса Configuration, то здесь у нас уже подключаемые функции диктуют правила, по которым следует разбирать параметры. Классы этих функций имеют метод meta(), возвращающий, помимо прочей мета-информации, описание параметров в виде инстанса мапы Map<String, DefinitionMeta> definitions:
public class DefinitionMeta {
public final String descr;
public final String type;
public final String hrType;
public final Object defaults;
public final String defDescr;
public final Map<String, String> values;
public final boolean optional;
public final boolean dynamic;
}Для каждого параметра у нас предусмотрено:
- его описание,
- Java тип (по умолчанию
String, также поддерживаютсяString[],Boolean, наследникиNumberиEnum— согласно системе типов параметров), - человеко-читаемый тип,
- значение по умолчанию с описанием (если параметр необязательный),
- перечень возможных значений с описаниями (если Java тип является енумом),
- наконец, пара флагов, указывающих на необязательность параметра и на возможность вычисления его имени динамически в рантайме.
Для удобной установки есть всего этого дела существует билдер, так что проще будет сразу на примерах проиллюстрировать, что имеется в виду, и как оно выглядит в итоге:
new DefinitionMetaBuilder()
.def(NAME_PROP, "Feature property with road name")
.def(TYPE_PROP, "Feature property with target road type")
.def(WIDTH_PROP, "Feature property with road width (i.e. number of lanes)")
.def(ROAD_TYPES, "Target road types", String[].class,
new String[]{"primary", "secondary", "tertiary"}, "Default target road types")
.dynDef(TYPE_MULTIPLIER_PREFIX, "Multipliers to adjust road width for each target type (i.e. lane width in meters)", Double.class)
.build()TRANSFORM osm_road_geometries geoJsonToRoadMap(@name_prop='NAME',
@type_prop='HIGHWAY',
@width_prop='LANES',
@road_types=['primary','primary_link'],
@type_multiplier_primary=2.6,
@type_multiplier_primary_link=2.6);— тут у нас первые три параметра обязательные, и имеют Java тип String (по умолчанию), 4-й необязательный (типа String[]), с указанным значением по умолчанию, а последний параметр должен вычисляться в рантайме: каждое из значений четвёртого параметра добавляется к префиксу, и полученный параметр должен иметь тип Double. Трансформ geoJsonToRoadMap, кстати, генерирует покрытие дорожной сети полигонами из выгрузки OpenStreetMap в формате GeoJSON.
Другой пример:
new DefinitionMetaBuilder()
.def(CALC_RESULTS, "List of resulting column names", String[].class)
.dynDef(SOURCE_ATTR_PREFIX, "Column with Double values to use as series source", String.class)
.dynDef(CALC_FUNCTION_PREFIX, "The mathematical function to perform over the series", KeyedMath.class)
.dynDef(CALC_CONST_PREFIX, "An optional constant value for the selected function", Double.class)
.build()CALL keyedMath(@calc_results=[sum, mean, rms, min, max, mul],
@source_attr_sum=score1, @calc_function_sum=SUM, @calc_const_sum=-15.,
@source_attr_mean=score1, @calc_function_mean=AVERAGE,
@source_attr_rms=sum, @calc_function_rms=RMS,
@source_attr_min=score2, @calc_function_min=MIN,
@source_attr_max=score2, @calc_function_max=MAX,
@source_attr_mul=sum, @calc_function_mul=MUL, @calc_const_mul=3.5
) iNPUT scores OUTPUT scores_shift_stats;— здесь первый обязательный параметр определяет суффиксы для групп из трёх параметров типов String, enum KeyedMath, и Double, совместно определяющих агрегирующую функцию для вычисления по выбранной колонке записей под одинаковым ключом.
(И да, конкретно эта операция keyedMath расширяет наш ни разу не аналитический SQL в ту степь, где водятся злобные, дикие и мохнатые GROUP BY. Впрочем, ровно как и было обещано…)
Ну так вот, имея в рантайме метаданные о параметрах функции, мы можем эти параметры провалидировать ещё до вызова самой функции — а с учётом того, что функция наша может быть подсунута сторонним имплементером через classpath, это даёт нам возможность упасть с исключением более-менее грациозно. А не бухнуться с NPE или мискастом на строке такой-то.
Хотя метод Configuration.get() из-за такого подхода выглядит, откровенно говоря, некрасиво:
public <T> T get(String key) {
DefinitionMeta defMeta = definitions.get(key);
if (defMeta == null) {
for (String def : definitions.keySet()) {
if (key.startsWith(def)) {
defMeta = definitions.get(def);
break;
}
}
}
if (defMeta == null) {
throw new InvalidConfigurationException("Invalid parameter " + key + " of " + descr);
}
Class<T> clazz;
try {
clazz = (Class<T>) Class.forName(defMeta.type);
} catch (ClassNotFoundException e) {
throw new InvalidConfigurationException("Cannot resolve class '" + defMeta.type + "' for parameter " + key + " of " + descr);
}
Object value = holder.get(key);
if (value == null) {
value = defMeta.defaults;
}
if (value == null) {
return null;
}
if (Number.class.isAssignableFrom(clazz)) {
if (value instanceof Number) {
return (T) value;
}
try {
Constructor c = clazz.getConstructor(String.class);
return (T) c.newInstance(value);
} catch (Exception e) {
throw new InvalidConfigurationException("Bad numeric value '" + value + "' for " + clazz.getSimpleName() + " parameter " + key + " of " + descr);
}
} else if (clazz.isEnum() && (value instanceof Enum)) {
return (T) value;
} else {
String stringValue = String.valueOf(value);
if (String.class == clazz) {
return (T) stringValue;
} else if (Boolean.class == clazz) {
return (T) Boolean.valueOf(stringValue);
} else if (clazz.isEnum()) {
return (T) Enum.valueOf((Class) clazz, stringValue);
} else if (String[].class == clazz) {
if (value instanceof String[]) {
return (T) value;
}
return (T) Arrays.stream(stringValue.split(",")).map(String::trim).toArray(String[]::new);
}
}
throw new InvalidConfigurationException("Improper type '" + clazz.getName() + "' of a parameter " + key + " of " + descr);
}Но ради удобства конечного пользователя какой только жути не напишешь… Однако, пожалуй, это единственное место во всей кодовой базе, которое на той же Scala выглядело бы действительно приятнее. Но у нас в облаке сидит 11 жаба, и если оно в таком виде там работает, уже хорошо.
Что ж. Всю обвязку общего плана мы разобрали, можно наконец и к самому интерпретатору приступать.
8. Имплементация. Интерпретатор, контекст исполнения, операторы выражений
Как ранее говорилось, всю грязную низкоуровневую работу по автомагической генерации лексера и парсера по грамматике / визитора AST берёт на себя ANTLR. Нам остаётся лишь дёргать сгенерированные им классы, и аккуратно имплементировать логику, преобразующую синтаксические примитивы SQL в жонглирование несколькими контекстами, вычисление выражений, и вызовы кода на Spark RDD API.
— Как нарисовать сову.jpg:
public class TDL4Interpreter {
// полный скрипт или выражение россыпью
private final String script;
// контекст исполнения
private DataContext dataContext;
// параметры контекста исполнения, и глобальный контекст переменных
private final OptionsContext options;
private VariablesContext variables;
// сюда попадут синтаксические ошибки
private final TDL4ErrorListener errorListener;
// создать и установить окружение интерпретатора
public TDL4Interpreter(String script, VariablesContext variables, OptionsContext options, TDL4ErrorListener errorListener);
// проинтерпретировать как полный скрипт в контексте исполнения
public void interpret(DataContext dataContext);
// проинтерпретировать как выражение россыпью — тут контекст исполнения не нужен
public Object interpretExpr();
// распарсить с проверкой синтаксиса (без разницы, выражение или полный скрипт)
public TDL4.ScriptContext parseScript();
/* А тут у нас 1000 с лишним строк кода высокой цикломатической сложности, то есть,
switch внутри if внутри if внутри циклов (и т.д.) в приватных методах */
}Впрочем, 1000 с лишним строк кода интерпретатора занимаются лишь только той половиной SQL, которая не предполагает обращения к Spark, а именно:
- разбор синтаксиса и базовые проверки,
- вызов механизма вычисления выражений россыпью,
- интерполяция строк,
- контроль потока выполнения,
- вызов расширений языка (то есть, CALL "операция"), и передача им управления.
Рассматривать мы их не будем, потому что код там скучный. Реально скучный. Если что, можете сами в этом убедиться, но я предупредил.
Сама же трансляция и вызов Spark RDD API, — то есть, контекст исполнения как таковой: работа с данными в общем виде, — это задача отдельного класса:
public class DataContext {
// собственно, Spark
protected final JavaSparkContext sparkContext;
// параметры контекста...
private static StorageLevel sl = StorageLevel.fromString(storage_level.def());
private static int ut = Integer.parseInt(usage_threshold.def());
// ...с геттерами
public static StorageLevel storageLevel();
public static int usageThreshold();
// наши зарегистрированные в контексте наборы данных
protected final ListOrderedMap<String, DataStream> store = new ListOrderedMap<>();
// создаём и привязываемся к Spark
public DataContext(final JavaSparkContext sparkContext);
// иннициализируем из OPTIONS
public void initialize(OptionsContext options);
// вернуть имена всех наборов
public Set<String> getAll();
// вернуть имена по префиксу для star syntax, или по списку
public ListOrderedMap<String, DataStream> getAll(String... templates);
// зарегистрировать новый набор
public void put(String name, DataStream ds);
// используется в тестах. да, у нас есть цель обеспечить полное тестовое покрытие
public Map<String, DataStream> result();
// CREATE inputName adapter(params) FROM path PARTITION partCount BY partitioning;
public void createDataStreams(
String adapter,
String inputName,
String path,
Map<String, Object> params,
int partCount, Partitioning partitioning);
// COPY outputName adapter(params) INTO path;
public void copyDataStream(
String adapter,
String outputName,
String path,
Map<String, Object> params);
// TRANSFORM dsName converter(params)
// SET COLUMNS(newColumns) KEY keyExpression~keyAfter PARTITION partCount;
public void alterDataStream(
String dsName,
StreamConverter converter,
Map<String, List<String>> newColumns,
List<Expression<?>> keyExpression,
boolean keyAfter,
int partCount,
Configuration params);
// проверить, если ли указанный набор данных
public boolean has(String dsName);
// SELECT
public JavaPairRDD<Object, Record<?>> select(
boolean distinct, // DISTINCT
List<String> inputs, UnionSpec unionSpec, JoinSpec joinSpec, // FROM
final boolean star, List<SelectItem> items, // aliases or *
WhereItem whereItem, // WHERE
Double limitPercent, Long limitRecords, // LIMIT
VariablesContext variables);
/* ...тут ~600 строк кода — самый большой и сложный метод во всём движке */
// LET $var = SELECT
public Collection<Object> subQuery(
boolean distinct,
DataStream input,
List<Expression<?>> item,
List<Expression<?>> query,
Double limitPercent, Long limitRecords,
VariablesContext variables);
/* ...а тут всего порядка 50 */
// ANALYZE dataStreams KEY counterColumn;
public void analyze(Map<String, DataStream> dataStreams, String counterColumn);
// разрегистрировать набор данных в контексте (никуда не денется, но имя освободится)
public void renounce(String dsName);
}Вынесен он в отдельный класс намеренно, дабы не перемешивать разбор и трансляцию примитивов в Spark RDD API.
Половина методов контекста исполнения один в один совпадают с операторами жизненного цикла наборов данных SQL, что логично. Другая часть вызывается:
- интерпретатором при проверках на наличие набора данных и его типа,
- тестовой обвязкой, которая наследует от него свой
TestDataContext, - и REPL, в котором есть как относительно безобидные отладочные команды типа
\SHOW DS, так и вовсе ж0стко вмешивающиеся в логику контекста исполнения, например,\RENOUNCE— но об этом позже.
Разбирать код второй компоненты в подробностях в рамках данной статьи также нет смысла — он достаточно запутан, но при этом тоже крайне однообразен. Даже DataContext.select(), который, казалось бы, как сердце движка SQL, должный быть чем-то особенным, в реальности очень скучен, и тупо имплементирует фазы ЖЦ запроса в нашем фиксированном порядке. Вдобавок, самая первая версия (ещё в предыдущем инструменте) занимала под 2к строк, а современное состояние схлопнуто втрое, так что можете себе представить, насколько этот код трудно раскуривается.
Третья и последняя компонента, отвечающая за разбор выражений россыпью, аналогично, вынесена в отдельный набор классов.
Во-первых, внушительного размера enum, в котором собраны (с бору да по сосенке — но большей частью из PostgreSQL) все нужные нам операторы выражений:
public enum Operator {
TERNARY1, DEFAULT, TERNARY2,
OR, XOR, AND, NOT, RANDOM,
IN, IS, BETWEEN,
EQ, EQ2, NEQ, NE2, GE, GT, LE, LT,
LIKE, MATCH, REGEX,
DIGEST, HASH,
HASHCODE,
BOR, BXOR, BAND, BSL, BSR,
CAT,
ADD, SUB,
MUL, DIV, MOD,
ABS, EXP,
BNOT;
// извлечь аргумент из стека в нужном типе
private static int popInt(Deque<Object> args);
private static long popLong(Deque<Object> args);
private static double popDouble(Deque<Object> args);
private static boolean popBoolean(Deque<Object> args);
// заглянуть в стек насчёт NULL
private static boolean peekNull(Deque<Object> args);
// символ оператора
private final String op;
// его приоритет
public final int prio;
// кол-во аргументов
public int ariness = 2;
// правая ассоциативность
public boolean rightAssoc = false;
// особая обработка NULL
public boolean handleNull = false;
// конструкторы
Operator(String op, int prio);
Operator(String op, int prio, int ariness, boolean rightAssoc, boolean handleNull);
// есть такой оператор? вернуть null, если нету
public static Operator get(String op);
// тогда вызовем его
public Object op(Deque<Object> args);
// а тут реализуем логику конкретного оператора
protected abstract Object op0(Deque<Object> args);
// вычислим выражение и явно приведём к булю для предикатов WHERE и IF
public static boolean bool(AttrGetter props, List<Expression<?>> item, VariablesContext vc);
// вычислим во всех остальных случаях
public static Object eval(AttrGetter props, List<Expression<?>> item, VariablesContext vc);
}Вычисляются у нас выражения методом eval() — простой стековой виртуальной машиной, которая пробегается по списку лямбд в RPN (переданному через List<Exression<?>>), заряженному текущим контекстом переменных (аргумент VariablesContext vc) и снабжённому ссылкой на геттер текущего объекта записи (AttrGetter props), если это нужно / возможно. А то в выражениях SELECT у нас есть текущая запись, а в LET или списке параметров функций нет, и соответствующий AttrGetter будет null (Java null, не путать с SQL NULL).
Сам список лямбд, как уже несколько раз упоминалось, собирается в RPN стек при помощи классического алгоритма Shunting Yard (о таком я в одной из предыдущих статей рассказывал, так что просто сошлюсь — тут оно всё то же самое).
Какие лямбды нам нужны для вычислений наших выражений? Ну, соответствующие классы выглядят следующим образом:
public interface Expression<T> extends Serializable {
}
public final class Expressions {
@FunctionalInterface
public interface SetItem extends Expression<Set<Object>> {
Set<Object> get();
}
public static SetItem setItem(Object[] a);
@FunctionalInterface
public interface BetweenExpr extends Expression<Boolean> {
boolean eval(final Object b);
}
public static BetweenExpr between(double l, double r);
public static BetweenExpr notBetween(double l, double r);
@FunctionalInterface
public interface InExpr extends Expression<Boolean> {
boolean eval(Object n, Object h);
}
public static InExpr in();
public static InExpr notIn();
@FunctionalInterface
public interface IsExpr extends Expression<Boolean> {
boolean eval(Object rv);
}
public static IsExpr isNull();
public static IsExpr nonNull();
@FunctionalInterface
public interface PropItem extends Expression<Object> {
Object get(AttrGetter obj);
}
public static PropItem propItem(String propName);
@FunctionalInterface
public interface VarItem extends Expression<Object> {
Object get(VariablesContext vc);
}
public static VarItem varItem(String varName);
public static VarItem arrItem(String varName);
@FunctionalInterface
public interface StringItem extends Expression<String> {
String get();
}
public static StringItem stringItem(String immediate);
@FunctionalInterface
public interface NumericItem extends Expression<Number> {
Number get();
}
public static NumericItem numericItem(Number immediate);
@FunctionalInterface
public interface NullItem extends Expression<Void> {
Void get();
}
public static NullItem nullItem();
@FunctionalInterface
public interface OpItem extends Expression<Object> {
Object eval(Deque<Object> args);
}
public static OpItem opItem(Operator op);
@FunctionalInterface
public interface StackGetter extends Expression<Deque<Object>> {
Deque<Object> get(Deque<Object> stack);
}
public static StackGetter stackGetter(int num);
@FunctionalInterface
public interface BoolItem extends Expression<Boolean> {
Boolean get();
}
public static BoolItem boolItem(boolean immediate);
}Они напрямую соответствуют следующим языковым конструкциям:
- литералам строк (
StringItem),Numeric-ов (NumberItem), булей (BoolItem) иNULL(NullItem), - по 2 шт. для «странных» SQL-евских конструкций, которые бывают в вариантах с
NOTи без —BETWEEN(BetweenExpr),IN(InExpr), иIS(IsExpr), - 2 шт. для получения значения переменных массивов и не массивов (
VarItem), - литералам для доступа к атрибутам записи через имя (
PropItem), - литералам массивов (
SetItem), - для получения остальных операторов выражений (не-«странным»,
OpItem), - и наконец, взятие аргументов со стека (
StackGetter).
Таким образом, из «супа литералов», которым мы определили «выражение россыпью» в синтаксисе языка, на этапе парсинга мы отсортировываем операторы и их аргументы в RPN, кладём их на стек, сразу превращая в лямбды, а на этапе интерпретации передаём нужный нам контекст, и пробегаемся по стеку сверху вниз, вычисляя уже конечное значение выражения.
Результат первого этапа (стек лямбд) кешируется, так как они не захватывают контекст. Можно было бы ещё добавить сокращённое вычисление для булевых операций, но это тема для какой-то из последующих доработок.
Ну что ж. С ядром движка мы ознакомились. Теперь можно и о механизме расширения говорить чуть более предметно.
Однако, на сегодня уже многовато получается, так что продолжим в следующий раз. Не переключайтесь!
Исходники: https://github.com/PastorGL/datacooker-etl
Промо-страница: https://pastorgl.github.io/datacooker-etl
Группа в Телеграме: https://t.me/data_cooker_etl
И ещё одна группа в Телеграме, участники которой во многом и надоумили меня взяться за разработку данного проекта: https://t.me/hadoopusers
Комментарии (7)

igor_suhorukov
14.09.2023 14:47@PastorGLвот что я не смог выразить на SparkSQL до сих пор, так это FSM. У тебя есть идеи как это можно без своего движка DSL сделать? Как бы ты это реализовал?
Я пробовал через Spark UDAFs, но столкнулся с тем, что Spark может вызвать у функции merge операцию.

PastorGL Автор
14.09.2023 14:47Это что-то из рубрики «ненормальное программирование»? Не, у нас в этот раз рубрика другая.
igor_suhorukov
14.09.2023 14:47Да почему же ненормальное?) Задача поведенческой аналитики. Дать пользователем возможность выражать на SQL метрики по каждому стейту самим
PastorGL Автор
14.09.2023 14:47Аналитика — это не моя область экспертизы. Я делаю инструменты для автоматизации работы аналитиков, но не занимаюсь ею сам. И описываемый проект покрывает только ETL процессы, но не более того.
Впрочем, если выдать мне white paper с описанием алгоритма расчёта какой-то метрики, я могу покумекать, и чё-нить имплементировать. Правда, имплементация будет на жабе. А чтобы вытащить её в уровень DSL, нужная серьёзная работа по генерализации задачи.

miksoft
14.09.2023 14:47+1Мы пытались на SparkSQL сделать распределение платежей по просроченному кредиту на погашение самого кредита и процентов по нему. Так и не получилось. Пришли к выводу, что нужны или иерархические запросы, или переменные, или процедурное расширение, но ничего этого в SparkSQL нет (или мы об этом не знаем).
igor_suhorukov
Йахууу! Все пути для аналитиков ведут в SQL