
В данной серии статей я подробно расскажу о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
Краткое содержание предыдущей серии:
Вступление
Постановка задачи
Проектирование языка. Операторы жизненного цикла наборов данных
Проектирование системы типов
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.
1-bis. Проектирование языка. Операторы жизненного цикла наборов данных
Что у нас там ещё на фазе трансформации было? Ах да, SELECT и CALL.
CALL проще, поэтому начнём с него:
call_stmt
: K_CALL func_expr ( from_positional | from_named ) ( into_positional | into_named )
| K_CALL func_expr ( into_positional | into_named ) ( from_positional | from_named )
;
from_positional
: K_INPUT K_FROM? ds_name S_STAR?
| K_INPUT K_FROM? ds_name ( S_COMMA ds_name )*
;
from_named
: K_INPUT ds_alias K_FROM? ds_name ( S_COMMA ds_alias K_FROM? ds_name )*
;
into_positional
: K_OUTPUT K_INTO? ds_name S_STAR?
| K_OUTPUT K_INTO? ds_name ( S_COMMA ds_name )*
;
into_named
: K_OUTPUT ds_alias K_INTO? ds_name ( S_COMMA ds_alias K_INTO? ds_name )*
;Как можно догадаться по ключевому слову, CALL — это некий вызов. Что обычно вызывается в SQL? Хранимые процедуры вызываются.
Вот и у нас будет что-то похожее, однако, в отличие от, наши «хранимки» будут штукой чуть более продвинутой, нежели обычно. Решены они будут в том же духе, что и подключаемые функции адаптеров хранилищ и трансформаций, но, в отличие от тех, будут принимать на вход несколько наборов данных, а на выходе генерировать опять же несколько наборов. Поэтому назовём их отдельным словом «операции».
Как именно операции должны работать? Тут есть три возможных пути:
- Генерировать новые наборы данных из входных, делая какие-то особенные соединения, которые не могут быть эффективно выражены через SQL
JOIN. - Фильтровать переданные наборы данных по особому набору правил, которые не могут быть красиво выражены через предикаты SQL
WHERE, но не меняя структуру данных. При необходимости, можно собирать записи, не прошедшие фильтр, в отдельный набор. - Аугментировать одни наборы данных, подмешивая в них атрибуты из других наборов по каким-то внутренним особенным правилам, которые опять же не выражаются удобно через выражения в SQL
SELECT item list.
То есть, операции — это эффективные расширения языка, реализующие собственные наборы правил для SELECT-подобных манипуляций над наборами данных. Впрочем, ничего экстраординарного, в стандартных СУБД какой-нибудь Spatial JOIN тоже обычно делается через вызов библиотечной хранимки — вот и мы не станем выпендриваться.
Для большинства операций, занимающихся фильтрацией (и для простых аугментаций), без разницы, сколько наборов данных принимать. Сколько скормили, столько же на выходе и получим, в том же порядке, только отфильтрованных. Для них указывать входные будем из в предложении INPUT FROM "набор1", "набор2" или INPUT FROM "префиксНаборов/" *, и выходные точно так же OUTPUT INTO "результат1", "результат2" или OUTPUT INTO "префиксРезультатов/" *.
Для генераторов же (и сложных аугментеров с фильтрами, возвращающими отброшенные данные) важно как-то обозначить, какие наборы данных являются источником основных атрибутов, а какие вносят дополнительный вклад по правилам операции, а также на выходе что отфильтровано, а что не прошло. Поэтому предусмотрим, что обращаться к наборам данных такие операции смогут по некоему внутреннему имени через конструкцию INPUT "внутреннееИмя" FROM "наборДанных", "дополнительно" FROM "дополнительныйНабор". То же и для результата: OUTPUT "результат" INTO "наборРезультата", "отброшено" INTO "наборНеПрошедшего".
Впрочем, в некоторых случаях позиционные инпуты могут сочетаться с именованными аутпутами, или наоборот. От операции, которая и устанавливает правила своего вызова, зависит.
Что касается ключей записей наборов, то для фильтров и аугментеров они будут сохраняться, а для генераторов подключаемая функция будет задавать их опять же по собственным правилам — это дело должно быть отражено в документации по операции. Количество партов также унаследуется от одного из исходных наборов, который будет являться «предковым».
Примеры:
CALL timezone(
@source_tz_default = 'GMT',
@source_ts_format = 'yyyy''-''MM''-''dd'' ''HH'':''mm''+''ss',
@dest_tz_default = 'Europe/Samara',
@source_ts_attr = timestamp,
@dest_ts_format = 'yyyy''-''MM''-''dd'' ''HH'':''mm''+''ss'
)
INPUT "source/RU/Volga/" *
OUTPUT "timezoned/RU/Volga/" *;
CALL dwellTime(
@signals_userid_attr=userid,
@target_userid_attr=userid,
@target_grouping_attr=gid
)
INPUT signals FROM populationGx, target FROM audienceGx
OUTPUT INTO dwellers;
CALL areaCovers
INPUT points FROM populationGx, polygons FROM geometries
OUTPUT target INTO covered, evicted INTO non_covered;Расширения для SELECT, которые скрываются в коде вызываемых функций, мы разобрали. Значит, теперь можно и сам SELECT разобрать.
В любом уважающем себя SQL оператор запросов SELECT является основным оператором, и его описание — это всегда страшно длинная портянка, полная подпунктов для каждого из предложений и вариантов. Посмотрим, что же с ним получается у нас:
select_stmt
: K_SELECT K_DISTINCT? ( S_STAR | what_expr ( S_COMMA what_expr )* )
( K_INTO ds_name K_FROM from_scope | K_FROM from_scope K_INTO ds_name )
( K_WHERE where_expr )?
( K_LIMIT limit_expr )?
;
limit_expr
: L_NUMERIC S_PERCENT?
;
what_expr
: expression ( K_AS type_alias? alias )?
;
from_scope
: ds_name
| join_op ds_name ( S_COMMA ds_name )+
| union_op ds_name ( S_COMMA ds_name )+
| union_op ds_name S_STAR
;
union_op
: K_UNION ( S_CAT | S_XOR | S_AND )?
;
join_op
: ( K_INNER | K_LEFT K_ANTI? | K_RIGHT K_ANTI? | K_OUTER )? K_JOIN
;
where_expr
: type_alias? expression
;А не так уж и страшно. Сейчас объясню синтаксис со стороны семантики.
У запроса есть такая штука, как его собственный жизненный цикл: любой движок разбивает запрос на некоторый набор специфичных для себя примитивов, которые затем группирует в этапы, выполняемые в определённом порядке. Выбор конкретных примитивов, как и порядок выполнения, управляется оптимизатором запросов. Посмотреть на это дело можно, вызвав в любой классической СУБД операторEXPLAINдля любого запроса. Все эти вотIndex Scan,HashAggregate,LocalRelation, и тому подобные странно выглядящие штуки — это и есть примитивы движка.
В некоторых СУБД, чтобы вмешаться в логику выполнения запроса, заменив одни примитивы другими, или поменяв их порядок, оптимизатору можно указать хинты, и Spark SQL в этом плане ничем не отличается. А вот у нас, с нашим не-аналитическим SQL, все эти сложности особенно ни к чему. Мы же всегда итерируемся по набору полностью, а не агрегируем и не вычисляем (хотя, можем и повычислять, но об этом позже).
Так что наш ЖЦ запроса будет строго фиксированным, и это фича:
- Сначала формируем набор данных
FROM(три взаимозаменяющих примитива: простой итератор,JOIN,UNION) - Применяем предикат
WHERE. - Вычисляем список выражений в
SELECT. - Накладываем констрейнт
DISTINCT. - Накладываем констрейнт
LIMIT.
Оптимизацию предусмотрим только одну: SELECT * FROM "одинНабор" без предикатов или констрейнтов будет повторно регистрировать существующий набор в контексте под другим именем. Все остальные случаи будут выполняться честно, без мухлежа, в указанном фиксированном порядке. Как приятное побочное последствие такого жёстко определённого порядка, мы сможем, к примеру, в предикате WHERE использовать результат JOIN, чего нормальные SQL движки обычно делать не позволяют — как раз из-за динамического формирования порядка этапов.
Что касается примитивов формирования пересечений и объединений, сиречь JOIN и UNION. Тут есть где развернуться.
В случае с UNION будем брать перечисленные наборы данных в указанном порядке, и…
-
UNION CAT(по умолчанию) — просто сольём все записи из всех наборов в один, -
UNION AND— возьмём только те записи, которые есть во всех наборах, -
UNION XOR— возьмём только те записи, которые есть лишь в одном из наборов.
Чтобы объединять записи наборов, они должны быть одного и того же типа, и обладать одним и тем же набором атрибутов верхнего уровня. По идее, требование жестковато, но зачем нам потом всякие неожиданности при обращении к набору смешанных типов, особенно если с несовпадающими атрибутами? Мы же не враги нашим аналитикам, поэтому искусственно ограничим. (Хотя, впоследствии, может быть, и передумаем.)
В случае с JOIN интересней. Вспомним: в любом наборе данных каждая запись у нас всегда обладает ключом, который ей задала та функция, которая создала этот набор (адаптер хранилища, трансформ, или операция). Записей без ключа не бывает. Вот по этому ключу мы и можем соединять записи из разных наборов.
Всего джойнов у нас будет шесть видов. Четыре прямых:
-
INNER JOIN(по умолчанию) — и ежу понятно, -
LEFT JOIN— и ужу понятно, -
RIGHT JOIN— и полутора метрам колючей проволоки понятно, -
OUTER JOIN— ….
При прямом джойне всё равно, какого типа соединяемые наборы. Тип результата будем наследовать от того, который участвует в соединении первым (то есть, обычно самый левый, но для правого самый правый), добавляя в клон записи атрибуты из всех записей последующих наборов с совпадающими ключами (или проставляя NULL для отсутствующих атрибутов).
И ещё два вычитающих джойна:
-
LEFT ANTI JOIN— будем последовательно вычитать записи по совпадающим ключам, просматривая наборы слева направо, -
RIGHT ANTI JOIN— справа налево.
В этих случаях записей в результате будет не больше, чем в первом из исходных.
Количество партов в результате соответствует правилам Spark RDD API: оно либо соответствует первому набору, либо равно сумме количества партов участвующих наборов — для OUTER.
Ну и не забываем, что наш SELECT объектно-ориентированный, и обращаться в нём мы сможем к различным уровням атрибутов участвующих объектов (например, WHERE Segment _points > 99), как и генерировать атрибуты на различных уровнях (что-нибудь вроде SELECT $currCat AS Track "category").
Примеры запросов:
SELECT *
FROM tracks_typed INTO "typed/pedestrians"
WHERE Segment _track_type='pedestrians';
SELECT userid, lat, lon, timestamp,
_output_year_int AS year,
_output_month_int AS month,
_output_dow_int AS dow,
_output_day_int AS day,
_output_hour_int AS hour,
_output_minute_int AS minute,
gid_9,
_hash AS gid_10
FROM timezoned INTO accuracy_filtered
WHERE accuracy LIKE '(:?\d|\d\d)\.?.*?';
SELECT * INTO nhours FROM timezoned WHERE hour IN $N_HOURS;
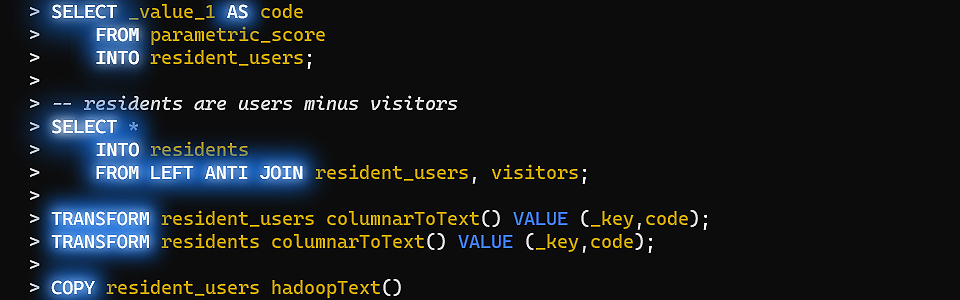
SELECT * INTO residents
FROM LEFT ANTI JOIN resident_users, visitors;
SELECT residents.userid, point_gid.code INTO asset_residents
FROM INNER JOIN residents, point_gid;Прекрасно, наборы мы по-всякому оттрансформировали. Можно загружать. То есть, выгружать.
Оператор COPY уже даже и расписывать не нужно, потому что все синтаксические элементы мы уже полностью покрыли:
copy_stmt
: K_COPY K_DS? ds_name S_STAR? func_expr K_INTO expression
;Впрочем, даже и в семантике ничего нового. Те же подключаемые функции адаптеров хранилищ с параметрами как у CREATE, такое же поведение со star syntax, как у TRANSFORM.
Ну и раз это финальный шаг ЖЦ набора данных, именно он в большинстве случаев запустит всю цепочку накопленного кода вызовов Spark, и в конце концов материализует набор данных в физическое представление в хранилище.
О самом языке осталось рассмотреть совсем немного. Управляющие структуры, служебные операторы, и вычисление выражений… упс, это всё-таки ещё много.
3. Проектирование языка. Операторы контроля потока выполнения
Классический аналитический SQL — это язык в большей степени декларативный, который описывает, что мы хотим получить, а не то, как именно мы хотим это получить.
Но у нас-то кейс несколько иной, — мы описываем некий процесс, — так что без элементов императивности в виде расширений для контроля потока выполнения уже не обойтись. К тому же, у нас уже есть поддержка переменных, так что сделать циклы и ветвления, управляемые переменными, вполне логично.
Итак, с оператора определения переменной LET и начнём:
let_stmt
: K_LET var_name S_EQ let_expr
| K_LET var_name S_EQ array
| K_LET var_name S_EQ sub_query
;
sub_query
: K_SELECT K_DISTINCT? what_expr K_FROM ds_name ( K_WHERE where_expr )? ( K_LIMIT limit_expr )?
;
let_expr
: ( is_op | between_op | in_op | comparison_op | var_name | L_NUMERIC | L_STRING | S_NULL | S_TRUE | S_FALSE | S_OPEN_PAR | S_CLOSE_PAR | expression_op | digest_op | random_op | bool_op | default_op )+
;Этот оператор создаёт, переопределяет, либо уничтожает (в случае LET $VAR_NAME = NULL;) переменную в текущем контексте исполнения. В глобальный контекст исполнения скрипта переменные могут быть переданы извне (через командную строку), а операторные скобки будут определять дочерний контекст, переменные в котором, определённые через LET, смогут экранировать родительские с тем же именем.
Тип переменной определяется динамически в результате выполнения выражения, литералом массива, или результатом "подзапроса" — упрощённой формы SELECT, которая выберет только какое-то одно выражение из одного набора данных. (Удобная вещь, в сочетании с оператором выражений IN ею делаются broadcast joins.)
Примерчик того, что будет писаться в начале скрипта (оператор DEFAULT возвращает правый операнд, если левый является NULL):
-- variables to be passed from CI. defaults for local testing
LET $path = $path DEFAULT 'file:{$CWD}/data';
LET $parts = $parts DEFAULT 100;
LET $tz = $tz DEFAULT 'Europe/London';
LET $taskNo = $taskNo DEFAULT 'local';Примерчики определения массивов:
LET $types = ['pedestrians', 'cars_city', 'cars_highway', 'cyclists'];
LET $N_HOURS = SELECT hour FROM r_mults;Получив переменную типа массив, мы можем проитерироваться по ней:
loop_stmt
: K_LOOP var_name S_IN? array K_BEGIN then_item ( K_ELSE else_item )? K_END K_LOOP?
| K_LOOP var_name S_IN? var_name K_BEGIN then_item ( K_ELSE else_item )? K_END K_LOOP?
;
then_item
: ( statement S_SCOL )*
;
else_item
: ( statement S_SCOL )*
;Операторные скобки BEGIN … ELSE и ELSE … END LOOP определяют дочерние контексты выполнения, в первом из которых операторы повторяются для каждого значения переменной контроля цикла, указываемой в LOOP $VAR_NAME, а во втором — ровно один раз в том случае, если массив имеет нулевую длину. Впрочем, ветка ELSE, как ей и положено, необязательная.
Пример цикла:
LOOP $type_name IN $types BEGIN
TRANSFORM "typed/{$type_name}" columnarToPoint(@lat_column=lat, @lon_column=lon);
CALL proximity
INPUT points FROM "typed/{$type_name}", pois FROM points
OUTPUT target INTO "sog/{$type_name}";
TRANSFORM "sog/{$type_name}" pointToColumnar();
END;В данном случае TRANSFORM можно было бы вынести из цикла и записать в форме со star syntax:
TRANSFORM "typed/" * columnarToPoint(@lat_column=lat, @lon_column=lon);Но если переменная $types вдруг содержит не все возможные суффиксы наборов "typed/", то мы выполнили бы неожиданные преобразования для некоторых из них. Так что цикл полезен своей явностью.
С ветвлениями примерно та же самая петрушка:
if_stmt
: K_IF let_expr K_THEN then_item ( K_ELSE else_item )? K_END K_IF?
;Выражение под IF вычисляется, приводится к булю, и в случае TRUE выполнится ветка THEN … ELSE (ну или THEN … END IF), иначе ELSE … END IF (если она вообще есть).
Честно говоря, в продакшене я ни разу не видел, чтобы наши аналитики его использовали. Хотя, конкретный кейс есть, но о нём позже.
Больше нам никаких операторов для управления потоком выполнения не потребуется. Осталось дать возможность настроить сам контекст.
4. Проектирование языка. Операторы управления контекстом исполнения
Раз мы стараемся обойтись без внешних зависимостей, то наш контекст выполнения — это тонкая надстройка над контекстом Spark. Следовательно, выстраивать какую-то развесистую инфраструктуру для настройки поведения Spark не имеет никакого смысла — у него и штатных крутилок чуть более чем дофига.
Тем не менее, иногда полезно бывает что-нибудь маленечко подтюнить в контексте конкретного скрипта, не залазя в настройки Spark. Для этого мы предусмотрим оператор OPTIONS:
options_stmt
: K_OPTIONS params_expr
;Синтаксис установки настроек такой же, как у параметров любой функции, но сам список настроек будет зависеть от конкретной сборки, режима выполнения, окружения, и т.п. факторов. А ещё для этого оператора мы сделаем context pull — то есть, при парсинге скрипта будем вытаскивать все встреченные OPTIONS, где бы они не находились, извлекать из них все настройки, и применять к каждой последнее установленное значение. То есть, действовать они будут всегда на глобальный контекст конкретного скрипта, по сути, инициализируя его перед выполнением логики скрипта.
Например:
OPTIONS @log_level = 'WARN', @storage_threshold = 3;О конкретных настройках поговорим, когда будем рассказывать о контексте исполнения и режимах работы получившегося инструмента.
Наконец, последний запланированный оператор, ANALYZE:
analyze_stmt
: K_ANALYZE K_DS? ds_name S_STAR? ( K_KEY property_name )?
;Иногда аналитикам нужно бывает уже прямо на этапе загрузки данных понять, что именно за данные им пришли из внешнего мира. То есть, узнать базовые статистики качества данных: сколько записей приходится на каждое уникальное значение ключа, или, к примеру, какова медиана этой цифры. И как она меняется при накладывании тех или иных фильтров. Поставщики, как мы знаем, коварны, и иногда продают в качестве данных такой лютый бред, что даже начинать инджестить его всерьёз никакого смысла нет, не то, что анализировать.
Оператор ANALYZE будет брать набор данных (или несколько, по префиксу), материализовывать, и пробегаться по нему, накапливая следующие показатели в специальном наборе данных с зарезервированным именем _metrics:
- имя набора,
- его текущий тип,
- текущее количество партов,
- общее кол-во записей,
- кол-во уникальных значений выбранного атрибута (или ключа записи, если атрибут не указан в предложении KEY),
- среднее кол-во записей на уникальный ключ,
- медиану кол-ва записей на уникальный ключ.
Вызывая ANALYZE для набора данных на разных этапах его ЖЦ, мы сможем проследить за его эволюцией — каждый такой вызов добавит новую запись.
В будущем к этим показателям я планирую добавить ещё и имена родительских наборов, чтобы сделать data lineage. Но это когда-нибудь потом.
Следует понимать, что оператором языка данный ж0стко материализующий механизм сделан не абы по какой причине, а чтобы можно было прямо в скрипте принимать решения о прекращении процесса ETL, если базовые показатели какого-то набора данных вдруг резко отличаются от ожидаемых. Вот тут-то нам и нужен управляющий оператор IF, после SELECT FROM _metrics.
А все остальные служебные и отладочные средства для выявления аномалий отдаются на откуп команд REPL, про который расскажем в последующих частях.
С операторами языка уровня скрипта разобрались. Можно перейти к выражениям, в том числе и россыпью.
5. Проектирование языка. Операторы выражений
На уровне синтаксиса, — в отличие от имплементации, — в данном разделе многое не расскажешь, но парочка синтаксических изысков у нас всё ещё осталась, потому что в SQL есть некоторое количество peculiarities в некоторых операторах выражений, которые приходится выносить в особые правила для парсера:
is_op
: S_IS S_NOT? S_NULL
;
between_op
: S_NOT? S_BETWEEN L_NUMERIC S_AND L_NUMERIC
;
in_op
: S_NOT? S_IN array
| S_NOT? S_IN var_name
| S_NOT? S_IN property_name
;Этот исторически сложившийся синтаксис с NOT, появляющимся в не самом очевидном месте, общеизвестен, так что придётся и его поддержать.
Остальные же операторы выражений в основном попадают в суповой набор выражений россыпью:
expression_op
: S_CONCAT
| ( S_PLUS | S_MINUS | S_STAR | S_SLASH | S_PERCENT | S_PIPE | S_CARET | S_TILDE | S_HASH | S_AMPERSAND | S_QUESTION | S_BANG | S_GT | S_LT | S_EQ )+
;Но для собственного удобства мы заведём ещё пару особых случаев, чтобы было можно, во-первых, использовать кроме символов ключевые слова, а во-вторых, выхватывать их из общего потока, и обрабатывать отдельно:
comparison_op
: S_REGEXP
;
bool_op
: S_NOT | S_AND | S_OR | S_XOR
;
default_op
: S_DEFAULT | S_COLON
;
digest_op
: S_DIGEST
;
random_op
: S_RANDOM
;Полную таблицу операторов выражений, их приоритеты и правила вычисления можно найти в разделе Language Operators текущей формальной спецификации языка, расширенным пересказом которой первые части данного цикла статей и являются.
Ох, ну и напроектировали. Простой, маленький и компактный доменно-специфический язык. Встречайте, TDL4!
А почему он TDL, почему 4, и о самом вкусном — имплементации, вы узнаете в следующей части. Не переключайтесь, продолжение следует!
Исходники: https://github.com/PastorGL/datacooker-etl
Промо-страница: https://pastorgl.github.io/datacooker-etl
Группа в Телеграме: https://t.me/data_cooker_etl
И ещё одна группа в Телеграме, участники которой во многом и надоумили меня взяться за разработку данного проекта: https://t.me/hadoopusers
Yo1
ИМХО не хватает внятного интро. Пролистал первую часть, так и не понял где описывается схема, как описывается результирующая таблица. что и как происходит если, результат трансформации не пихается в результирующую таблицу. зато куча подробностей по командам, которые нафиг не нужны без понимания общей идеи. и начинать стоит с чего-то простенького, "полигоны с аутлайнами торговых центров — инстансы объектов JTS " разбираться в геоданных врятли многим интересно.
PastorGL Автор
Схема нигде не описывается, так как её нет. В первом же требовании — we're flying schema-less.
Если на что-то надо ссылаться, имена указываются ad hoc. Если не надо, то и имена не нужны. Тем более типы.
Таблиц, кстати, тоже нет. Есть наборы данных, они объектные. Об этом тоже прямо говорится много раз.