

В нашем документе может существовать множество таблиц. В таблицах есть колонки, строки, ячейки, и над каждым из этих элементов могут производиться операции вставки, удаления, перемещения и редактирования. В результате некоторых таких операций возникает необходимость пересчета формул. Изюминкой нашего редактора является то, что мы можем пересчитывать только те формулы, которые действительно нужно пересчитать. То есть формулы, значение которых могло измениться. Таким образом мы повышаем эффективность при редактировании больших документов, а также избегаем ситуаций, когда значение ячейки, содержащей, например, функцию RAND, изменяется при каждом редактировании документа.
КАК РАССЧИТАТЬ ФОРМУЛЫ?
Перед тем как начать вычисления, нам нужно собрать информацию об изменениях в таблице, определить, какие именно формулы следует пересчитать, и установить порядок расчета.
Рассмотрим простейший вариант: в пустую ячейку вводится формула «=2+2». В этом случае надо всего лишь вычислить значение этой формулы.
Более сложный вариант, когда формула ссылается на другую ячейку, как показано на рисунке 1. Допустим, что изменилось значение ячейки B2. Тогда необходимо каким-то образом определить, что существует формула в B1, ссылающаяся на нашу ячейку, и вычислить ее, а затем вычислить формулу в A1.
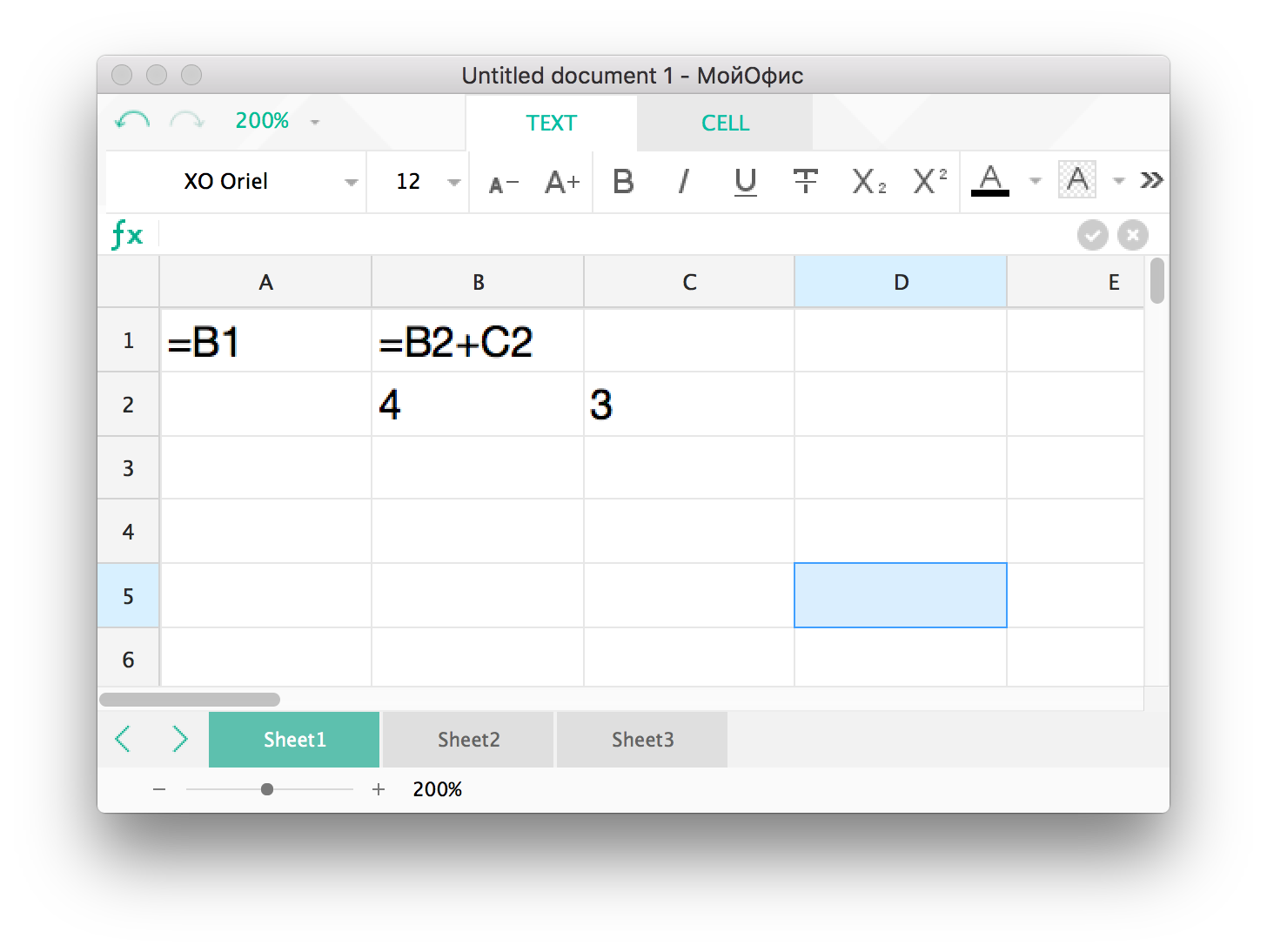
Рис. 1. Пример простой зависимости между формулами
В этом случае формулы необходимо рассчитывать строго в том порядке, в котором они друг на друга ссылаются. В противном случае мы будем использовать значение ячейки, которая еще не посчитана.
Но этот вариант может усложниться, если формулы образуют цикл, как показано на рисунке 2.
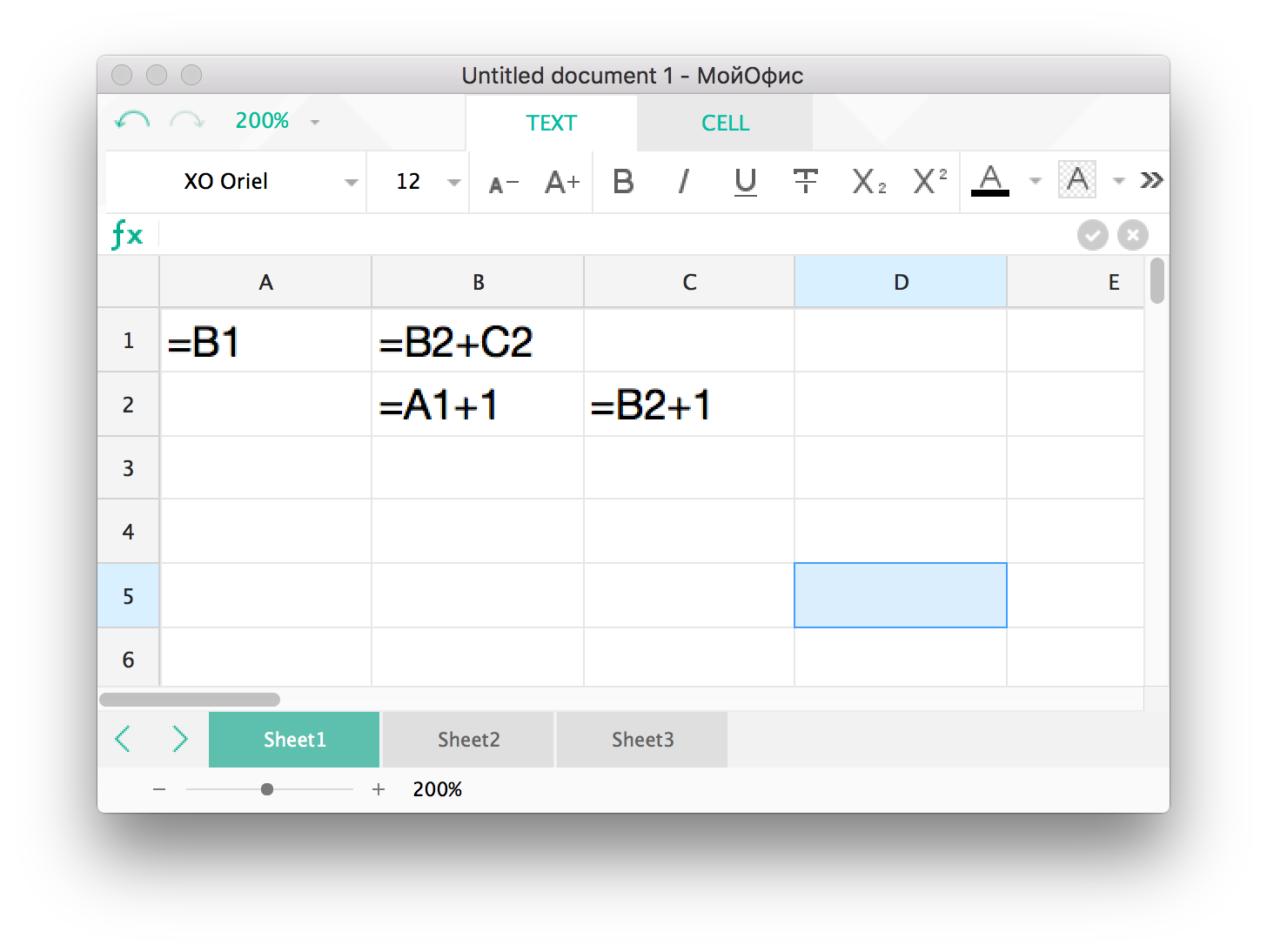
Рис. 2. Пример циклической зависимости между формулами
Прежде чем приступать к расчету, необходимо найти циклы и определить в них порядок расчета формул. Потому что цикл может быть не похож на кольцо, а являться сильно связным графом, где каждая вершина зависит от каждой. Различный порядок расчета формул в одном и том же цикле может привести к различным результатам. Мы гарантируем всегда одинаковый результат при пересчете циклических формул, чего не делают большинство других редакторов.
Существует два критерия выхода из цикла: достижение максимального количества итераций и достижение определенной точности результата вычисления. До тех пор пока цикл не вычислен, мы не можем продолжить вычисление зависящих от него формул.
Дополнительные проблемы возникают с функциями типа INDIRECT и FORMULA, которые не имеют прямой зависимости от ячейки. Чтобы определить, от чего зависит формула, содержащая подобную функцию, необходимо сначала вычислить значение параметра функции. А если эта формула попала в цикл, который изменяет значение параметра функции и вместе с ним зависимость формулы на каждой итерации, то оказывается, что граф зависимостей между формулами может изменяться динамически во время расчета.
Из вышесказанного составим следующий алгоритм расчета формул:
- Определить, какие ячейки были изменены.
- Найти формулы, которые ссылаются на эти ячейки.
- Построить граф зависимостей между формулами.
- Найти циклы в графе.
- Установить порядок расчета формул.
- Посчитать формулы с возможностью распараллеливания расчета.
- Если в формуле обнаружена неявная связь и в результате расчета эта связь изменилась, необходимо выполнить алгоритм с начала.
КАК НАЙТИ ФОРМУЛЫ ДЛЯ ПЕРЕСЧЕТА
В представленном выше алгоритме расчета формул выполнение первого пункта тривиально. Рассмотрим подробнее второй шаг: как определить, какие формулы ссылаются на нашу ячейку.
Так как размер таблицы огромен – 1.7*10^10 ячеек, а формула может ссылаться на целый столбец или целую строку, например «=A:B», то хранить обратную связь от каждой ячейки к формуле не имеет смысла. Перепроверять все формулы каждый раз, когда изменилась ячейка, тоже неэффективно. Мы решили хранить данные о том, на какие ячейки ссылается каждая формула. Таким образом для каждой таблицы храним ссылки в виде координат левого верхнего и правого нижнего угла диапазона. Теперь для ссылки A:B координаты будут выглядеть так (0, 0; 1, 1 048 576), где 1 048 576 – максимально возможное число строк. Когда мы узнаем, что изменилась ячейка (COL, ROW), можно определить, в какие диапазоны она попадает.
Допустим, что у нас в документе существует N ссылок, а изменилось M ячеек. Тогда максимально возможный размер ответа на вопрос «Какие формулы нужно пересчитать?» может быть M*N, если вдруг окажется, что все диапазоны пересекаются и все ячейки попали в каждый из диапазонов. Но это редкий случай. Чаще всего диапазоны разрежены и мы можем подумать над тем, как оптимизировать поиск, чтобы не перебирать все диапазоны для каждой из ячеек. Простой и понятный способ немного ускорить поиск – алгоритм заметающей прямой.
Пусть каждый диапазон имеет два события – начало и конец. Отсортируем события по координате Х. Все изменившиеся ячейки (точки) также отсортируем по Х. Далее представим вертикальную прямую, которую мы сдвигаем вдоль оси Х от точки до точки, и поддерживаем коллекцию диапазонов, с которыми пересекается наша прямая. Для коллекции диапазонов мы выбрали хэш-таблицу, потому что она наиболее эффективна, если требуется добавлять и удалять элементы в случайном порядке. При пересечении событием начала диапазона добавим его в коллекцию, при пересечении конца – удалим его. Таким образом для каждой из точек мы всегда знаем, в какие диапазоны она попадает по оси Х. Среди них обычным перебором найдем те, которые подходят по Y.
Рассмотрим пример на рисунке. Цветными квадратами обозначены диапазоны, а точками на оси X – события. Пройдем по списку событий до точки 1 и увидим, что мы вошли в красный, синий и зеленый диапазоны. После этого проверим каждый из них по оси Y и определим, что точка попадает только в красный и синий. Дальше перемещаемся к точке 2 по X. Сначала видим, что красный диапазон закончился, удаляем его из списка, затем удаляем зеленый. Добавляем желтый. Точка 2 попадает в желтый и синий диапазоны по оси X, то же самое выполняется и для Y.

Рис. 3. Схема работы алгоритма заметающей прямой в применении к поиску вхождения точек в двумерные диапазоны
Хотя в худшем случае время работы алгоритма составит M*N, в среднем алгоритм должен работать гораздо быстрее. В условиях разреженной таблицы время работы может приближаться к N+M*log(M). Для хранения данных требуется M+N памяти. Очевидно, что это минимально возможные затраты. Также есть поле для дальнейших оптимизаций, которые мы решили отложить, если не столкнемся с проблемами в производительности.
Выше мы упомянули, что поиск диапазонов по оси Y выполняется обычным перебором. Но если большое количество точек и диапазонов совпадают по оси Х, можно применить алгоритм заметающей прямой и для поиска по оси Y. Для этого необходимо для текущих диапазонов создать отсортированный по оси Y список событий. Точки сортировать не нужно, предполагается, что они уже были отсортированы ранее по X и Y. Тогда время поиска по оси Y составит N*log(N)+M, оптимизацию можно применить при таких M и N, когда выполняется условие N*log(N)+M < M*N.
В следующих статьях мы продолжим рассказывать о том, как решали задачи построения графа зависимостей между формулами, искали циклы и устанавливали порядок вычисления формул в циклах и в графе, о возможных проблемах и их решениях при вычислении функций с неявными зависимостями, а также о распараллеливании вычислений.
До встречи.