
Каждая стратегия масштабирования имеет свои плюсы и минусы. Почему бы не начать комбинировать их и оставить только плюсы? Поговорим об этом — как сделать хорошо, когда нельзя просто закопать — в контексте PHP.
Статья написана по мотивам моего доклада на Saint HighLoad++ 2023.
Меня зовут Игорь Титов, я системный инженер в Garage Eight. Расскажу, как мы переносили страшного старого монстра — legacy PHP-FPM-приложение — в Kubernetes и сколько при этом съели ёжиков.
Международная продуктовая IT-компания Garage Eight уже 11 лет разрабатывает целую экосистему финансовых продуктов и сервисов на зарубежных рынках. К 2023 году у компании насчитывается сотни тысяч активных пользователей в 183 странах, а также более 300 микросервисов.
Начало. Что такое PHP-FPM?
PHP-FPM (PHP FastCGI Process Manager) — это просто быстрый процесс-менеджер для PHP. Он написан в 2004 году и поддерживается до сих пор. К нему есть 1000 и 1 руководство по настройке. Отдельно отмечу возможность создания динамических, статических и «по вызову» процесс-пулов, которые можно использовать в зависимости от приходящей нагрузки, желаемого времени отклика приложения, когда нужно, снижая количество потребляемых вычислительных ресурсов, или наоборот - улучшая пользовательский опыт в приложении благодаря его скорости, чем мы в компании активно пользовались. Также есть много других настроек, например по времени выполнения запросов, ограничениям на количество открытых файлов, количеству дочерних процессов и т.д.
При работе с PHP-FPM есть возможность обрабатывать статику на стороне балансировщика, например Nginx, а динамику отправлять уже в PHP-FPM.
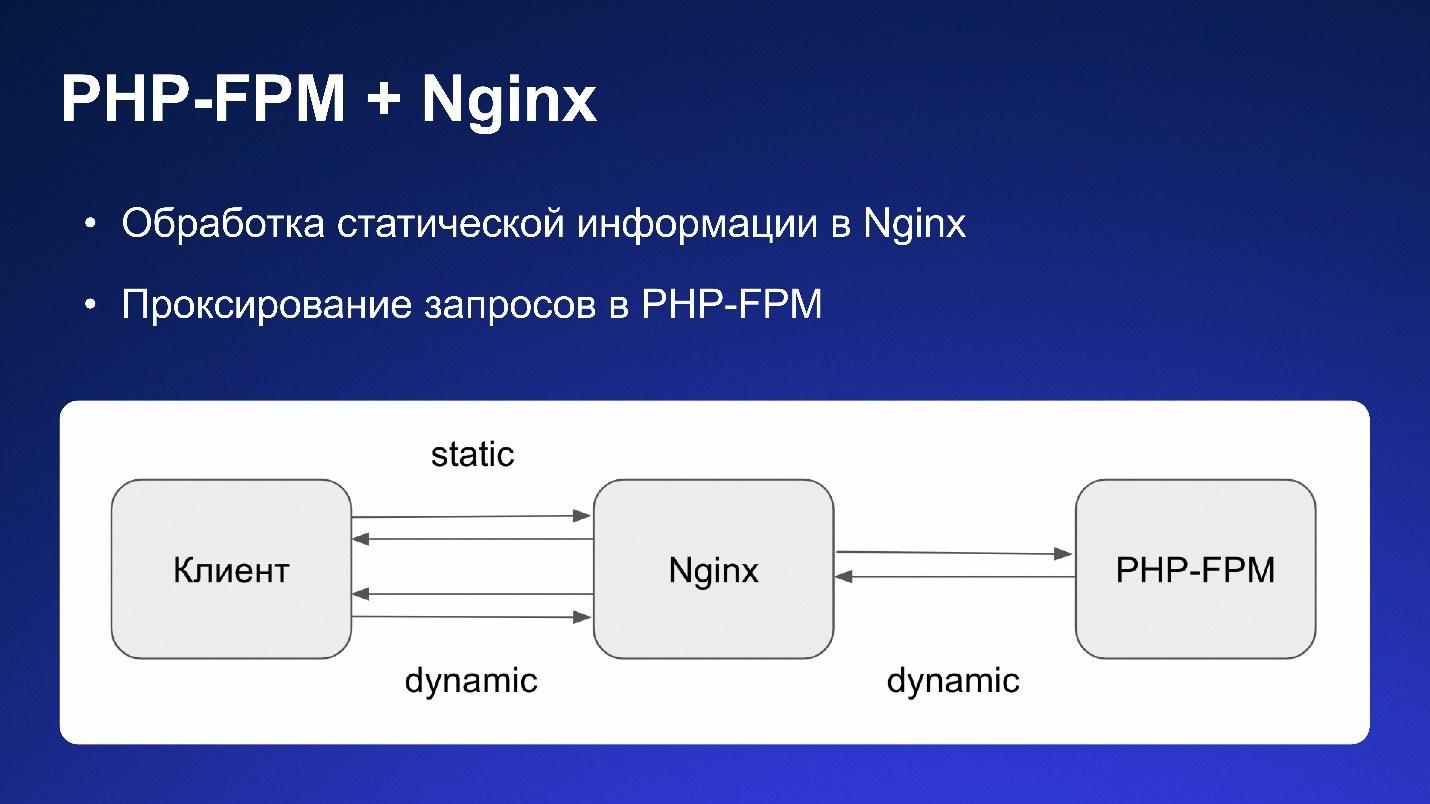
Вот на этом менеджере процессов и работает наше старое PHP-FPM-приложение.
Проблемы
Исторически в Garage Eight микросервисы разворачивались в «ванильный» Docker, мы даже не использовали Docker Compose.
Это были десятки виртуальных серверов с Docker’ом, на которых мы с помощью Ansible поднимали контейнеры микросервисов и следили за их доступностью. Масштабирование осуществлялось через разворот новых серверов с Docker и перенастройку Nginx. Самый страшный минус — периодически приходил трафик, нужно было оперативно расширяться. Как мы это делали?
Представим, что у нас есть облачный балансировщик нагрузки и пару Nginx, с помощью которых мы отправляем трафик на виртуальные машины с контейнерами, в которых запущено наше приложение. В этих контейнерах также есть свой Nginx, который обрабатывает статику, а динамику передаёт в PHP-FPM для дальнейшей обработки.

Чтобы расшириться, мы добавляли новые виртуальные машины, на них разворачивали контейнеры с PHP-FPM, Nginx и настраивали балансировщики.

За всем этим должны были следить системные инженеры. Они отвечали в т.ч. за оценку приходящего трафика, его мониторинг и правила обработки.
Внедрение Kubernetes позволяло сильно упростить задачу масштабирования.
Но кроме масштабирования были и другие проблемы:
Падение контейнера с Nginx не вызывало падения контейнера с PHP-FPM. За этим тоже надо было следить - добавлять дополнительные метрики и правила в системе мониторинга.
Демоны приложения располагались в одном контейнере и могли отчаянно сражаться между собой за вычислительные мощности.
У всех монолитов, которые были написаны на этапе стартапа, была проблема с тем, что они разворачивались своими самописными Ansible-ролями. Деплой в Kubernetes решал эти проблемы использованием универсального Helm.
Build приложения проходил прямо во время деплоя. Нужно было скачать все зависимости, собрать имэйдж, сбилдить и стартануть контейнер.
Перенос Legacy PHP-FPM-приложения в Kubernetes
Вот так выглядел перенос приложения в Kubernetes, в общих чертах.
1. Разделение пулов
PHP-FPM-пулы разделили на разные деплойменты:
RPC,
PHP-Daemons,
API,
Static,
etc.
Отдельно стоит отметить кроны. Это были обычные Linux-кроны, которые хранились в Crontab и запускались по расписанию. В них было что-то типа Docker exec и прочего. При переезде в Kubernetes разработчики переписали их в Cronjobs и выделили для них отдельный Node-пул, чтобы они никак не влияли на другие сервисы. Для Cronjobs использовали spec.concurrencyPolicy, чтобы контролировать, сколько экземпляров может быть запущено под каждый из них. Благодаря тому, что кроны стали сущностью Cronjob, разработчики могли сразу применять их без дополнительных инструментов. Получали результаты Cronjob через Prometheus и в алерт-менеджере быстро настраивали алерты на падающие кроны.
2. Миграции
Миграции при развороте этого монстра стали выполнятся через хуки на pre-upgrade и pre-instal. Кто знаком с Kubernetes, знает, что под капотом это Kubernetes Job’ы.
Обращаю внимание, нужно правильно настроить тайм-ауты для миграций, потому что миграция может быть действительно долгой. Поэтому мы увеличили время с помощью activeDeadlineSeconds.
3. Консоль выполнения команд
Раньше мы просто заходили в Docker-контейнер и что-то выполняли, теперь мы сделали отдельный деплоймент с контейнером, куда можно зайти и в cli что-то выполнить. Всё по-прежнему просто, но сделано отдельным деплойментом.
4. Статика
Статика — это тоже отдельный деплоймент с контейнером, который мы заранее сбилдили, собрали образ и подложили. Статические запросы обрабатывает Nginx, как я упоминал выше.
С какими проблемами столкнулись?
AMQProxy
После переноса приложения в Kubernetes на нагрузке, нам почти удалось положить RabbitMQ. Оказалось, что мы забыли про AMQ-Proxy. PHP не любит рвать соединения с RabbitMQ, поэтому на каждой ноде должен быть дополнительный контейнер с AMQP. Его нам пришлось добавить в поды вместе с legacy PHP-приложением как sidecar-контейнер.
Надо не просто добавить, но и правильно управлять sidecar-контейнерами, потому что Kubernetes не поддерживает сложный жизненный цикл sidecar-контейнеров. На тот момент был большой Merge Request, который говорил, вот сейчас мы сможем поддерживать в Kubernetes v1.19 sidecar-контейнеры: время жизни, порядок запуска и остановки и т.д. По факту Merge Request был отклонен, и управление sidecar-контейнерами сводится к тайм-аутам. Мы настроили остановку AMQP только после того, как остановился PHP-FPM, чтобы не терять данные в RabbitMQ.
502-е на проде из-за преждевременной остановки подов
Мы перенесли приложение и начали периодически получать 502-е на проде. Ошибка прилетала во время деплоя. Выяснилось, что достаточно было добавить небольшой тайм-аут на preStop хуке, чтобы эта проблема ушла. Так наше приложение реагировало, что нужно чуть-чуть подождать перед остановкой. В итоге команда пришла к тому, что мы ждём 5 секунд, потом ещё 10 и только потом выполняем Graceful shutdown команду для PHP-FPM.

Также мы забыли про внутренние тайм-ауты:

Необходимо отметить, что эти пороговые значения тоже влияют на правильное выключение подов с PHP-FPM.
Кроме этого, есть Graceful shutdown тайм-аут для подов. По умолчанию он 30 секунд. Если ваше приложение не останавливается за это время, то Kubernetes дезинтегрирует его. Это время мы тоже увеличили.
По итогу стало ступенчатое изменение тайм-аутов и получилась вот такая картина:

Просто ждём 15 секунд, уверенные в том, что за это время наше приложение точно обработает все оставшиеся запросы, это ожидание меньше максимального времени выполнения запроса в PHP, потом дожидаемся, когда PHP-FPM точно завершит все процессы и лишь в конце позволяем Kubernetes уничтожить наш под. В этом случае мы избегаем путаницы с тайм-аутами, никто не прикончит приложение раньше.
502-е на проде из-за автомасштабирования
Но на этом проблемы не закончились. Что-то пошло не так и ошибки 502 на проде продолжались. Виновным в этом оказался Horizontal Pod Autoscaler (HPA):

Мы его подключили в процессе, когда решали проблемы с тайм-аутами. Он позволяет быстро масштабировать приложение при нагрузке.
На первый взгляд в его конфигурации, указанной выше, всё просто, но представим, что Horizontal Pod Autoscaler расширил деплоймент до 60 реплик. Во время деплоя мы снижаем их количество до 20, в результате получаем гору 502-х, а потом начинаем по автомасштабированию опять растягиваться до 60 по правилам масштабирования.
Так это выглядело в Grafana:

Мы отреагировали и поправили поведение при масштабировании:

Оно позволяет нам правильно управлять Horizontal Pod Autoscaler: если автомасштабирование включено, используем не реплики, а параметры автомасштабирования.
В качестве альтернативы и костыля можно деплоиться в максимальное количество реплик (установить значения в Replicas в ReplicaSet и Max Replicas в Horizontal Pod Autoscaler одинаковыми), а уже после деплоя Horizontal Pod Autoscaler установит количество реплик в зависимости от нагрузки.
Однако в документации говорится, что так делать неправильно.
Гибридное масштабирование
По Horizontal Pod Autoscaler есть подробная документация, в которой описана безопасная процедура переезда с ReplicaSet на Horizontal Pod Autoscaler.
Обратите внимание, рецепт из документации может не сработать - так было у нас. Поэтому для таких процедур вашего PHP-FPM приложения или любого legacy-приложения при переезде на Horizontal Pod Autoscaler лучше выбрать окно регламентных работ.
В Horizontal Pod Autoscaler версии 2 добавили возможность управлять поведением масштабирования, позволяющем плавно или наоборот скачкообразно увеличивать или уменьшать количество реплик в Deployment.
А ещё дополнительно мы добавили динамические пулы в конфигурацию php-fpm.

Теперь есть возможность немного вырасти внутри пода и при этом не запрашивать Horizontal Pod Autoscaler сразу, а запросить только в тот момент, когда трафика слишком много.
Наконец, мы добавили Cluster Autoscaler в Google почти на всех пулах. При этом мы можем вырасти кластерно горизонтально.

По факту мы получили в legacy-приложении гибридное масштабирование:

То есть мы можем вертикально подтянуться за счёт процессов PHP-FPM, обработать резкий всплеск трафика, а если этого будет не хватать, включим Hozontal Pod Autoscaler и начнём расти в количестве реплик в Deployment. А если этого не хватит, мы можем расти кластерно. Кроме того мы можем прогнозировать сколько будет трафика с помощью аналитиков и заранее масштабироваться ручными способами. Например, в Horizontal Pod Autoscaler сделать 240 реплик, вместо 140.
Проблемы после переноса
Nginx-матрёшка.
У провайдера Nginx на балансировщиках нагрузки, наши балансировщики тоже Nginx, Nginx в Ingress и Nginx в нашем PHP-FPM-приложении. Получается, что при дебаге нужно раскрутить длинную цепочку Nginx и их конфигураций, чтобы понять, что происходит.
Kubernetes-пробы.
Приложение очень старое, написано, условно, на коленке, уже почти не поддерживается. Все readiness-пробы совпадают с liveness-пробами. Казалось бы, просто проверяем доступность TCP-порта, если он доступен, значит, можно трафик отправлять. Но на самом деле это не всегда так - доступность порта не означает доступность приложения для исполнения пользовательских запросов.
У нас есть стартап-пробы, которые с помощью тайм-аутов просто ждут, когда поднимется под. Да, это неправильно, можно написать healthcheck, который будет на любой запрос по url отвечать 200 - что тоже, не совсем верно.
Чтобы окончательно всё решить, можно добавить работающие healthcheck endpoint или просто прогревать приложение в postStart, результаты записывать в файл, а потом с помощью стартап-пробы ходить в этот файл и проверять в нём результаты «прогрева».
Итог
Хотелось бы, чтобы те, кто переносит или переносили legacy-приложения на в Kubernetes, воспользовались нашим опытом и смогли избежать ошибок, которых не смогли избежать мы. И, как и мы, смогли обнаружить некорректное поведение приложения раньше попадания на прод.
Советы:
→ Корректно завершайте процессы в контейнерах (Graceful shutdown).
→ Помните, Sidecar-контейнеры бывают коварны. Надо уметь их правильно завершать, иначе вы можете просто потерять часть реальных пользовательских данных или данных для аналитики.
→ Помните про тайм-ауты на всех уровнях. Например, Kubernetes может остановить ваш контейнер до того, как процесс реально завершен.
→ Помните про конфликт ReplicaSet и Horizontal Pod Autoscaler, что при переходе с ReplicaSet на Horizontal Pod Autoscaler есть шанс, что все поды схлопнутся до одного единственного, а это «не очень хорошо».
→ Делайте больше мониторинга, алертинга, логирования. Это позволит вам решать проблемы.
Большая благодарность команде Rubik’s Cube из Garage Eight, которые много работали над legacy-приложением и нашим системным инженерам, которые знают, когда надо остановить процесс, чтобы этого не сделал кто-нибудь другой в момент, когда ты того не ждёшь.
Mission accomplished
Terminating…
Комментарии (5)

alecx
22.09.2023 13:45Спасибо за статью. Тоже приходилось решать похожую задачу. Единственное, специально отключил динамические пулы в fpm: не думаю что они полезны в подах. Если вы определяете limits/requets ресурсов по памяти, то помоем лучше сразу ставить столько, сколько влезает в под. Постольку fpm не шарит ресурсы с другими, как в случае настоящего сервера, то и смысла расти а потом сжиматься динамически особо нет. Плюс мониторинг проще.
p.s. Интересно было бы еще добавить подтему мониторинга: на какие метрики и для чего смотрите а первую очередь.

FreZZZeR Автор
22.09.2023 13:45Наша задача была ещё и в том, чтобы мгновенно реагировать на выбросы, при этом не съедая много ресурсов. В этом ключе, лучшим решением было использовать динамические пулы, поскольку старт подов по автоскейлеру слишком тяжёлый по времени

Sigest
22.09.2023 13:45Расскажите, пожалуйста, как вы прикрутили мониторинг/сбор метрик для prometheus к php-fpm подам? Мне сейчас предстоит такая задача, я не программист на php и немного теряюсь в инструментах. Пока нашел вариант через sidecontainer, где-то в документации к prometheus, но смущает, что ссылка ведет на гитхаб репу, которая обновлялась очень давно
ufoton
После долгих экспериментов мы остановились на ngnix unit вместо php-fpm в контейнерах.
FreZZZeR Автор
Мы тоже его в своё время рассматривали, но переезд на него посчитали слишком дорогим для легаси