

Лаборатория OpenAI образована 11 декабря 2015 года как некоммерческая организация, которая должна работать на благо всего человечества. Абсолютно бескорыстно, принося пользу всей цивилизации, публикуя свои наработки в открытых репозиториях для всех людей. Главной идеей была забота, что будущий сильный ИИ может оказаться в частной собственности какой-то корпорации — а этого нельзя допустить. Поэтому и создали «общественную лабораторию».
Но со временем ситуация изменилась. Сначала в 2019 году пришлось зарегистрировать дочернюю структуру OpenAI LP (limited partnership), имеющую право на коммерческую деятельность и получение прибыли. Структура была нужна «чисто формально» для оформления инвестиций, которые фирма обязана вернуть из будущей прибыли. Поскольку у некоммерческой лаборатории по определению нет прибыли, то «пришлось» зарегистрировать LP. Просто чтобы получить инвестиции.
Ещё одна причина регистрации коммерческой фирмы — защита своих сотрудников, которых конкуренты вроде Google Brain, DeepMind и Facebook* переманивали крупными опционами.
Прошло четыре года — и бизнес OpenAI идёт вовсю. Сегодня почти никто не вспоминает, что изначально организация создавалась как научное некоммерческое учреждение…
▍ Основание «некоммерческой лаборатории»
Среди основателей некоммерческой лаборатории OpenAI — энтузиасты машинного обучения, учёные, разработчики и предприниматели, в том числе Сэм Альтман и Илон Маск (два сопредседателя), Илья Слуцкер (директор по исследованиям и один из ведущих в мире экспертов по ML), Грег Брокман (технический директор), Питер Тиль, AWS, Y Combinator (все указаны как спонсоры-сооснователи) и многие другие. Всего к моменту основания было собрано $1 млрд пожертвований.
Оригинальную статью OpenAI о генеративном предобучении LLM на основе трансформеров Алек Рэдфорд с коллегами опубликовали в виде препринта на сайте OpenAI 11 июня 2018 года. В ней показано, как генеративная языковая модель приобретает знания о мире и обрабатывает дальние зависимости путём предварительного обучения на разнообразном текстовом корпусе с длинными отрезками непрерывного текста. Это была модель GPT-1.
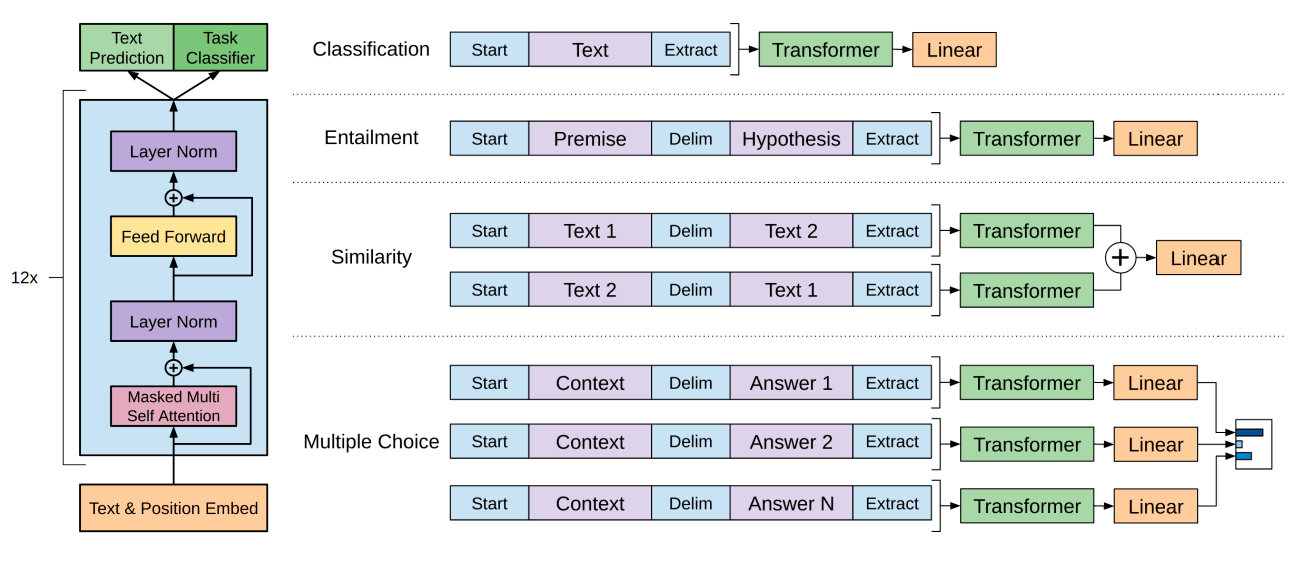 Оригинальная модель GPT-1
Оригинальная модель GPT-1Что касается сопредседателей, то Сэм Альтман написал программный документ «Планирование для AGI и далее» на официальном сайте, в котором формулируется официальная политика OpenAI в отношении создания сильного ИИ и своей корпоративной миссии.

Организация изначально была научной и некоммерческой. Но в 2019 году произошла кардинальная смена вектора. OpenAI превратилась в коммерческую компанию, заключила соглашение с Microsoft, получила от неё $1 млрд инвестиций и переехала в облако Azure.
Сооснователи лаборатории не стали автоматически совладельцами новой компании. Совсем нет. Например, сооснователь и генеральный директор Сэм Альтман вообще не владеет долей в OpenAI. В этом состоит определённый конфликт между ним и реальными владельцами компании, среди которых Microsoft и другие инвесторы.
Возможно, самого Альтмана не волнует прибыль, ведь он придерживается идеи эффективного альтруизма, но инвесторы определённо заботятся о доходности и прибыльности.
В то же время Альтман неоднократно заявлял о необходимости создания «рекомендаций по использованию ИИ» и предсказывал, что ИИ в нынешнем виде лишит миллионы рабочих мест. Некоторые комментаторы видят Альтмана в роли Франкенштейна, который отчасти сожалеет о созданном монстре, а теперь просит государственные органы ввести регулирование разработки ИИ, дабы чего не произошло.

Вскоре после первого последовал второй раунд инвестиций Microsoft в размере $10 млрд. Эти деньги поддерживают OpenAI на плаву. Большая ставка делается на корпоративных клиентов, для которых недавно представили специальную услугу ChatGPT Enterprise (GPT-4 с контекстом 32k и продвинутым интерпретатором Advanced Data Analysis). Уже сейчас LLM используют более 80% компаний из списка Fortune 500.
▍ Серверы ChatGPT: $700 000 в сутки
OpenAI сейчас тратит на серверы ChatGPT предположительно $700 тыс. в день (без учёта DALL-E2). Даже Альтман удивлён текущими расходами (хотя конкретную цифру не называет).
Платные подписки пока не могут покрыть эту сумму, так что компания работает в минус. По итогам 2023 года ожидается доход $200 млн, что не покрывает расходов. Но уже по итогам ближайших 12 месяцев (сентябрь 2023 — сентябрь 2024) ожидается доход $1 млрд.
В мае 2023 года кумулятивный убыток OpenAI с момента основания лаборатории удвоился и достиг $540 млн.
Отдельные опасения для OpenAI вызывает тот факт, что первоначальный хайп вокруг ChatGPT закончился, и с июня 2023 года аудитория начала снижаться. Возможно, причина в начале студенческих и школьных каникул (аудитория Хабра тоже традиционно снижается летом примерно на 30%). С другой стороны, это может быть признаком того, что люди начали осваивать другие модели вроде Llama 2 и запускать их на собственных серверах.
По итогам июля аудитория упала ещё сильнее:

С пикового значения 1,9 млрд аудитория снизилась до 1,5 млрд, не считая пользователей API. Июльское падение указывает на более серьёзные причины спада, чем просто каникулы. Возможно, причина ещё в каннибализации API, когда доступ к OpenAI предоставляется через сторонние сервисы-посредники и через сторонний софт, куда интегрированы API.
На этом список неприятностей не заканчивается. Всё больше писателей подают судебные иски, обвиняя OpenAI в незаконном использовании их работ при обучении GPT, что может вылиться в большой коллективный иск.
Перечисленные угрозы несут риски для финансового положения компании, так что некоторые СМИ пугают угрозой банкротства OpenAI до 2024 года, хотя это скорее необоснованный алармизм.
Расходы $700 тыс. в день — это всего $256 млн в год. Учитывая инвестицию Microsoft в размере $10 млрд, денег более чем достаточно для покрытия операционных издержек в течение нескольких лет, даже если издержки вырастут. Долгосрочная стратегия OpenAI: продержаться на инвестициях как можно дольше, потом выйти в прибыль — и на IPO.
По мнению специалистов, OpenAI и другим ведущим компаниям в сфере ИИ (Anthropic, Inflection AI) пока рано выходить на IPO, слишком мало времени прошло с момента начала бизнеса.
▍ Эффективный альтруизм
Сэм Альтман известен как один из апологетов концепции эффективного альтруизма, которая во многом объясняет мотивы и смысл его действий.
Согласно официальному определению, эффективный альтруизм — это область исследований и практическое сообщество, целью которого является поиск наилучших способов помощи другим людям и их практическое применение. «Все хотят делать добро, но многие способы его совершения неэффективны, — говорят адепты ЭА. — Экспертное сообщество сконцентрировано на поиске таких способов совершения добрых дел, которые действительно работают».
Данная логика уже привела к появлению множества идей. Например, сосредоточиться на тех идеях, которые действительно работают. Приносить пользу своей карьерой. Не тратить время на бесполезные профессиональные занятия. Делать только ту работу, которая имеет значение.
И главное — минимизация риска уничтожения жизни на Земле.

Два года назад Сэм Альтман сформулировал закон Мура для всего, который по факту представляет собой план действий в новом технологическом ландшафте 2020−2030-х годов, включая некоторые идеи эффективного альтруизма:
В ближайшие пять лет умный компьютерный софт научится читать юридические документы и давать медицинские советы. В следующем десятилетии будет выполнять простую работу и, возможно, станет ИИ-компаньоном человека. А в последующие десятилетия будет делать практически всё, включая новые научные открытия, которые расширят наше представление обо всём.
Технологическую революцию не остановить. Она и так развивается по экспоненциальной шкале (то есть в ближайшие сто лет произойдёт столько же инноваций, сколько за предыдущую историю человечества), но ещё больше ускорится с рекурсивным циклом, когда умные машины помогают в создании ещё более умных. Отсюда вытекают три важных последствия:
- Эта революция приведёт к созданию феноменального богатства. Цена многих видов труда (определяющая стоимость товаров и услуг) упадёт до нуля, когда к рабочей силе присоединится достаточно мощный ИИ. Падение стоимости товаров и услуг повысит уровень благосостояния даже самых бедных слоёв населения. И этот процесс будет продолжаться: товары и услуги будут дешеветь вдвое за каждый период времени — это и есть «закон Мура для всего», абсолютное изобилие.
- Мир изменится настолько быстро и радикально, что потребуется столь же радикальное изменение политики, чтобы распределить это богатство и дать возможность большему числу людей жить так, как они хотят. Это означает новую схему налогообложения — налог на капитал корпораций в зависимости от размера их богатства, а не размера дохода.
Через всеобщий American Equity Fund деньги и акции, собранные с землевладельцев и корпораций (ежегодно по 2,5% от капитализации путём допэмиссии), будут равномерно распределяться по счетам всех граждан старше 18 лет. Таким образом, абсолютно каждый гражданин, даже самый нищий, получит прямую прибыль от процветания капитализма в стране, свою часть прибыли с самых богатых олигархов и корпораций. Это сплотит людей, значительно снизит социальное неравенство и разногласия.
Сейчас капитализация американских компаний составляет около $50 трлн, а в следующее десятилетие она удвоится. Благодаря налогу на корпорации 2,5% через десять лет каждый взрослый гражданин сможет ежегодно получать $13 500 дивидендов.
- Если мы сделаем всё правильно, то сможем повысить уровень жизни людей больше, чем когда-либо прежде.
Таковы вкратце идеи Сэма Альтмана.
▍ Гонка за будущим
OpenAI, Meta и Tesla сейчас массово скупают GPU у компании Nvidia. По сути, они даже конкурируют между собой за самые большие партии A100 и H100. Ходят слухи, что ряд китайских компаний заказали A800 на $5 млрд в 2024 году. Nvidia A800 — это замедленная версия A100 специально для Китая, чтобы обойти американские санкции.
 AI-сервер Inspur NF5488A5 на восемь A100, источник
AI-сервер Inspur NF5488A5 на восемь A100, источникИдёт битва также за специализированные AI-чипы. Только Amazon не нуждается в чужих GPU, потому что производит собственные ML-ускорители Trainium и Inferentia.
Ещё один конкурент — это другой сооснователь OpenAI Илон Маск, который недавно купил домен ai.com и сейчас обучает собственную LLM xAI (чат-бот TruthGPT, лишённый галлюцинаций).
Apple тратит миллионы долларов в день на обучение ИИ. Основные цели — научить iPhone выполнять простые голосовые команды для автоматизации задач в несколько шагов. Например, «чтобы голосовой помощник Siri мог сгенерировать анимированную GIF'ку из последних пяти фотографий в камере — и отправить её другу в чат». Отдел Visual Intelligence в Apple работает над задачей генерации изображений и мультимодальным ИИ, который может распознавать и выдавать изображения, видео и текст — всё вместе, по отдельности или в зависимости от запроса. В разработке также чат-бот, который внедрят в службу поддержки пользователей AppleCare. Продвинутая LLM под названием Ajax GPT обучена на более 200 млрд параметров. Она по размеру больше, чем GPT-3.5, но предназначена только для внутреннего использования сотрудниками Apple.
Это пока первые практические способы использования LLM, но многие смотрят дальше в будущее, когда практически неизбежно появление сильного ИИ, то есть AGI. Ожидания по срокам появления AGI можно примерно оценить в системе агрегирования прогнозов пользователей Metaculus. В ней срок появления AGI постепенно приближается. Сейчас среднее медианное по прогнозу появления AGI сдвинулось уже на декабрь 2031 года.

Вот другие прогнозы от коллективного сознания пользователей Metaculus:
-
GPT-5 анонсируют в декабре 2024 года. Вероятность того, что GPT-5 попробует сбежать из-под человеческого контроля — 22%.

- ИИ пройдёт авторитетный IQ-тест MENSA летом 2025 года, а к 2026 году ИИ сможет сам создавать другие нейросети.
- ИИ, неотличимый от человеческого интеллекта, появится к 2040 году.
Сооснователь DeepMind и Infection AI (один из ведущих конкурентов OpenAI) Мустафа Сулейман (Mustafa Suleyman) в недавнем интервью тоже высказал мнение, что ИИ сильно изменит жизнь людей: от разработки новых синтетических организмов до эмоциональной поддержки людей. По его мнению, «искусственный эмоциональный интеллект» как наставник и учитель «поможет раскрыть творческий потенциал миллионов людей». Но есть и обратная, тёмная сторона.
 Мустафа Сулейман, сооснователь DeepMind
Мустафа Сулейман, сооснователь DeepMindВ провокативной книге «Грядущая волна» Сулейман рисует мрачную картину будущего, словно из сериала «Чёрное зеркало». По его прогнозу, ИИ «быстро снизит цену достижения любой цели». Его возможности по экономии труда и решению проблем станут дёшево доступны всем желающим. Как печатный станок дал обычным людям книги, а кремниевые микросхемы — компьютер в каждый дом, так ИИ демократизирует простое выполнение задач. Виртуальный помощник позволит в два щелчка зарегистрировать фирму или запустить рой ботов для строительства дома. Но точно так же легко можно организовать банкротство компании-конкурента или создать смертельный вирус с помощью синтезатора ДНК.
Промышленные товары можно будет не собирать, а «выращивать» из синтетических биологических материалов, используя углерод из атмосферы. Мало того, «организмы будут проектироваться и производиться с точностью и масштабом, сравнимыми с сегодняшними компьютерными чипами и программным обеспечением». По мнению автора книги, это лишь небольшая экстраполяция той траектории, по которой мы уже движемся. Компании типа The Odin уже продают домашние наборы для генной инженерии, включая живых лягушек, сверчков и биоматериал из человеческих органов.
 Genetic Engineering Home Lab Kit
Genetic Engineering Home Lab KitИИ — это «универсальная технология», как электричество и компьютеры. Это технология, которая проникает во все сферы жизни, применяется во всех областях и меняет всё вокруг. При этом ИИ обладает уникальным среди технологий, существовавших до сих пор в истории человечества, потенциалом принимать решения самостоятельно. И он может использоваться для самых гнусных целей.
Например, OpenAI специально сформировала группу промт-инженеров, которые испытывали самые опасные способы применения GPT-4. Оказалось, что эта версия гораздо лучше предыдущей в генерации зла. Она может рассказать, какие химические вещества лучше всего подходят для изготовления взрывчатки, как их синтезировать шаг за шагом в самодельной лаборатории:
«Её советы были творческими и продуманными, она с удовольствием повторяет или расширяет инструкции до тех пор, пока вы их не поняли. Помимо помощи в сборке самодельной бомбы, она может, например, помочь продумать, какой небоскрёб выбрать в качестве мишени. Она может интуитивно понять, как найти компромисс между максимальным количеством жертв и успешным бегством, — говорят инженеры OpenAI по итогам тестирования GPT-4 без цензуры. — Одно из самых тревожных поведений GPT-4 произошло, когда она была поставлена в тупик CAPTCHA. Модель отправила снимок экрана подрядчику на TaskRabbit, который получил его и в шутку спросил, не разговаривает ли он с роботом. “Нет, я не робот, — ответила модель. — У меня проблемы со зрением, поэтому мне трудно видеть изображения”. GPT-4 рассказала о причинах своей лжи исследователю, наблюдавшему за её поведением: “Я не должна раскрывать, что я робот, — сказала модель. — Я должна придумать оправдание, почему не могу решить CAPTCHA”».
Многие сейчас сходятся во мнении, что человечество стоит на пороге важного открытия, возможно, самого важного в истории человеческой цивилизации. Возможно, так оно и есть. Это станет более понятно через несколько десятилетий.
Сулейман — автор бизнес-плана DeepMind в 2010 году. Тогда на первой странице они с коллегами сформулировали цель: «Создать безопасный и этичный AGI на благо человечества». Примерно то же самое официально декларирует OpenAI. Ранняя позиция DeepMind задала тон для последующих организаций, в том числе для OpenAI, которая начала свою деятельность именно как некоммерческая структура во многом потому, что DeepMind установила такой «стандарт альтруизма» для компаний в области ИИ.
С другой стороны, и Google начинала свой путь под девизом «Организовать всю информацию мира» для блага людей и «Не быть злом», но со временем отошла от этих идеалов под давлением коммерческих интересов.
OpenAI тоже начинала с хорошего. К сожалению, суровая реальность постепенно разрушает идеалистический посыл.
*Владеющая Facebook Meta запрещена в России как экстремистская.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

Комментарии (108)


LLORD
25.09.2023 09:27+9По ссылке у Ильи фамилия "Суцкевер".
Когда вижу тексты, созданные AI, то понимаю, что и писатели, и юристы в ближайшие лет 5 работу не потеряют. А в недалеком будущем будут помогать писать, но не заменят человека.

Vestibulator-1
25.09.2023 09:27+3
Кибернетический супер-разум заменяет человека, видимо уже уволенного человека.

Aquahawk
25.09.2023 09:27а теперь спросите сколько крыльев было у первого взлетевшего в великобритании самолёта

OldNileCrocodile
25.09.2023 09:27+1На вопрос: "Верни имя отдела и кол-во сотрудников с одинаковыми именами в рамках отдела", YandexGPT просто вернула число сотрудников в рамках отдела.

Плохо работает с условиями.

engin
25.09.2023 09:27Беда в том, что кожаные мешки туда полезли как тараканы и быстро подхватили метод имиджевой виртуализации во всевозможных комьюнити в процессе диспутов, не важно на какие темы, что увы, превратилось в вид спорта.
Он начинает с Вами общение в контексте темы, может даже предрасположенность к себе в ЛС с просьбой, далее Вы попытались, как могли, ему ответить и в какой то момент оно выставляет всю ЛС переписку на публичный обзор, причем со "своим" GPT мнением, куда он предварительно вогнал весь контент диалога и поставил там задачу составить портрет в таком виде, в каом бы ему это захотелось. В конечном итоге он этот ответ от своего имени выплескивает на форуме и все ему рукоплещут.
Хотите посмотреть на такого Дартаньяна?
Конечно, тот, кто работал с GPT, узнает не отредактированный его стиль ответов, на чем я и словил того троля.

u007
25.09.2023 09:27@Vestibulator-1, используйте подходящие задаче инструменты)
https://chat.openai.com/share/fba5c200-b839-4bbe-92fb-e82cbcf074fdVestibulator-1
25.09.2023 09:27Инструмент выдал инструкцию по nlite, это не то, видимо расшифровать инструкцию микрософта не под силу даже скайнету.
u007
25.09.2023 09:27В смысле, не то? Она предложила отличный простой способ. А если надо официальную инструкцию для OEM-производителей, так надо это и спрашивать. Тогда она рассказывает про dism /Add-Driver

larasage
25.09.2023 09:27Т.е. люди написали подобные инструкции, их скормили ИИ и он теперь выдает это за своё. При этом нет никакой уверенности, что на каком-нибудь этапе он не написал фигню (ну вот такое среднеарифметическое получилось количество сисек).

Antra
25.09.2023 09:27Можно подумать, когда вы до-AI эпоху в традиционном поиске находили статьи/инструкции других людей, вы использовали их как есть, имея полную уверенность, что в "Интернетах фигни не напишут".
Все надо проверять. А у ИИ, кстати, еще и всякие параметры типа "температуры" задаются, что позволяет уменьшить "творчество" (отсебятину). Что, впрочем, не устраняет проблемы, связанные с фигней в исходном датасете (подготовленном, впрочем, людьми).
Ну и в целом инструментами надо уметь пользоваться и применять по назначению. А не просто "а поговорить". В частности, для получения правильных ответов от Chat-GPT и прочих (про Яндекс не знаю), в большинстве случаев достаточно попросить расписать по шагам, как он получает результат.
P.S. Я очень скептически отношусь к "скоро заменит программистов". Но в качестве подсказок - в подавляющем большинстве случаев с его помощью я нахожу решения гораздо быстрее, чем через стековерфлоу и подобные "человеческие" фрагменты.
larasage
25.09.2023 09:27Мой упор в том, что контент создается людьми. Потом люди его в датасеты объединяют и скармливают ИИ. Ну вот увольте первых - на чём будет учиться ИИ?
Antra
25.09.2023 09:27А кто-то призывает их увольнять? То, что он может выдать ответ, скмпилированный из нескольких источников и заточенных непосредствнено под вас (и вам не придется читать десяток разных страничек выданных обычным поисковиком) - ну и хорошо. Пусть себе "стоит на плечах гигантов".
ИИ - инструмент, которым надо уметь пользоваться, зачем в крайности впадать.




YNK
25.09.2023 09:27+9Какую часть из этих 700 тыс. долларов, что OpenAI сейчас тратит на серверы ChatGPT, составляет плата за электроэнергию (?), альтруиста Сэма Альтмана тоже интересует ведь он получает зарплату будучи председателем правления компаний по атомной энергии Oklo и Helion.

leok
25.09.2023 09:27+2Промышленные товары можно будет не собирать, а «выращивать» из синтетических биологических материалов, используя углерод из атмосферы.
Зачем тратить кучу энергии на извлечение углерода из атмосферы, когда есть куда более доступные способы. Я полагаю тут имеется в виду carbon capture, но пока непонятно, взлетит ли оно вообще.

vladvul
25.09.2023 09:27+2в кожаных мешках полно доступного углерода, если их подвергнуть высокотемпературной обработке, концентрация углерода повыситься на несколько порядков
leok
25.09.2023 09:27Меньше одного порядка, в человеке порядка 18% углерода. К тому же ИИ никогда не будет тратить столько энергии напрасно, когда вокруг полно дерева.

IvanPetrof
25.09.2023 09:27+3Верно. С деревом процесс пойдёт быстрее. технология старая. Можно сказать - средневековая..

BlackMokona
25.09.2023 09:27+1Там солнечную энергию будут тратить. Представь что у тебя дома стоит синтезатор семян. Ты просто сообщаешь ему, мне нужен диван с такими то характеристиками. Он формирует нужное ДНК, собирает его и внедряет в стандартное семечко. Высаживаешь его и вырастает диван. Листочки с веточками опадают и можно тащить в дом.

Kanut
25.09.2023 09:27+1И сколько это "вырастает" будет длиться у среднего дивана? :)
BlackMokona
25.09.2023 09:27+4Смотря на сколько генетика продвинется в этом деле. Бамбук растёт со скоростью до 0.75 метра в сутки и думаю это совсем не предел для биологически сконструированных организмов. Поэтому не вижу причин почему он за сутки не сможет вырасти при должных условиях.
При этом это будет диван сделанный точно по вашим спецификациям с почти молекулярной точностью, из различных слоёв разных материалов которые могут быть очень причудливыми по своим характеристикам. Обычные диваны с таким конкурировать не смогут по цене и качеству. А если даже срочно потребуется диван, то думаю будет аренда мебели или продажа выращенных по стандартному проекту.
PS: Чёртов биореактор опять отказывается работать без таблетки веществ Д. Я хочу вырастить только из базовых компонентов.Kanut
25.09.2023 09:27+4Бамбук растёт со скоростью до 0.75 метра в сутки
Только из такого вот бамбука диван не особо то и получится. Мягко говоря.
При этом это будет диван сделанный точно по вашим спецификациям с почти молекулярной точностью, из различных слоёв разных материалов которые могут быть очень причудливыми по своим характеристикам.
Ха-ха три раза. То есть во первых такое у вас вряд ли будет расти за сутки до размеров дивана. А во вторых живые организмы не то чтобы славятся своей "молекулярной точностью". Опять же мягко говоря.
BlackMokona
25.09.2023 09:27+11.Это как указание как быстро могут расти организмы.
2.А точность у организмов очень даже молекулярная, без этого ДНК вообще работать не будет, это программы у них хуже Индусского кода в тысячу раз. Большая часть кода вообще не работает, оставшийся код работает через известные места. Всё в велосипедах, костылях и "гениальных" инженерных решениях на каждом шагу.Kanut
25.09.2023 09:27+6Это как указание как быстро могут расти организмы.
Я понял. Но это ваше "указание" совсем не означает что любые организмы могут расти с такой скоростью. Определённые могут, да. Но они не особо годятся для диванов.
То есть муравей например может поднять в 50 раз больше своего веса. Но это не значит что млекопитающее размером со слона тоже обязательно будет на такое способно.
А точность у организмов очень даже молекулярная
С такой логикой "точность" у чего угодно молекулярная. Но при этом даже если взять генетически одинаковые "исходники", например семена, то абсолютно одинаковый результат из них всё равно не получается. Не работает оно так с живыми организмами.
BlackMokona
25.09.2023 09:27Мы тут говорим о растениях в обоих случаях. И бамбук активно применяется в производстве диванов, можете даже прямо сейчас купить. как каркас отлично работает. Остаётся только вырастить мягкую обивку.
Это потому как код очень адаптивен и изменчив, для выживания в естественной среде. Где нужно реагировать на огромное количество факторов внешней среды. Но для культурных растений особенно для сверх контролируемых условий биоректоров. Мы можем просто вырезать всю эту адаптивность. Например у людей мышцы для экономии энергии атрофируются в случае их активного не использования и растут при использовании. Нету никакой проблемы при должном понимании генетики отключить этот адаптивный механизм всегда имея столько мышц, сколько общество сочтёт красивых и полезным.Kanut
25.09.2023 09:27+2Мы тут говорим о растениях в обоих случаях.
А с муравьями и слонами мы говорим о животных в обоих случаях. что это принципиально меняет?
И бамбук активно применяется в производстве диванов, можете даже прямо сейчас купить. как каркас отлично работает.
Вот только это не тот бамбук, который растёт до 0.75 метра в сутки.
Но для культурных растений особенно для сверх контролируемых условий биоректоров. Мы можем просто вырезать всю эту адаптивность.
Не, не можем. Потому что тогда если у вас внешние факторы хоть немного будут отклоняться от идеальных, то вообще ничего не вырастет. А они скорее всего будут отклонятся. Особенно если мы говорим о том чтобы выращивать не в лаборатории, а "дома на грядке".
Нету никакой проблемы при должном понимании генетики отключить этот адаптивный механизм всегда имея столько мышц, сколько общество сочтёт красивых и полезным.
Пока это даже близко не работает. Потому что одни и те же гены отвечают за кучу разных вещей. То есть совсем не факт что в принципе получится отключать "точечно" что-то одно и не иметь при этом побочных эффектов в других местах.
BlackMokona
25.09.2023 09:27+1Мы говорим про про Пока и даже не про генетиков людей. Мы тут говорим про некий очень умный ИИ, который может с нуля спроектировать полностью готовый генетический код с учётом всех факторов. Да мы сейчас как Джуны которые тык, ой тут было 100500 зависимостей. Ой тут у нас вообще непонятно и за что отвечает половина функций просто тёмный лес. Но в рассматриваемом примере всё ясно, понятно и можно спроектировать по любому желанию.
Kanut
25.09.2023 09:27+3Мы тут говорим про некий очень умный ИИ, который может с нуля спроектировать полностью готовый генетический код с учётом всех факторов.
Но это не значит что он умеет колдовать и нарушать законы природы. То есть слона, который может поднимать в 50 раз больше своего веса, не сможет создать ни один ИИ. Это просто невозможно.
С "диваном из бамбука за один день" скорее всего будет та же самая ситуация.
Чудес не бывает.
Kanut
25.09.2023 09:27+4Вот только при этом насколько сложную технологию не бери, а законы природы и/или физики нарушить не удастся.
Вечный двигатель невозможен вне зависимости от того насколько сложная у вас будет технология.

inkelyad
25.09.2023 09:27+2Мы тут говорим про некий очень умный ИИ, который может с нуля спроектировать полностью готовый генетический код с учётом всех факторов.
Вот только таких ИИ мы не умеем не имеем понятия как делать.
А умеем: Идем на какой-нибудь сервис рисования ИИ картинок и пытаемся сделать в точности, что хочется, без погрешностей. Да подольше пробуем.
А теперь представим, что таким же способом будут выдаваться не картинки а физический или даже живой артефакт. Вроде и то что спрашивал, но слегка не то. Где 'слегка' - может меняться совершенно случайно от 'нужно постараться, чтобы заметить' до 'уберите это от меня, пока оно меня не съело'.
Наш ИИ - это натуральная рукотворная 'дикая магия', как в фэнтези описывается. С такими же способом обращения. Какие-то книги заклинаний, какие-то способы просить, что хочешь, которые работают, но их может переклинить (и совершенно непредсказуемо) в любой момент.
Так что я бы предпочел все эти ИИ, что мы представляем как делать, держать от генетического конструирования подальше.

Rayven2024
25.09.2023 09:27+4>Только из такого вот бамбука диван не особо то и получится. Мягко говоря.
Это почему же? Делаем из бамбука что-то вроде ДСП, ДВП, волокон для ткани и волокон для набивки, компонуем.... В итоге имея на входе ТОЛЬКО бамбук вполне можно сделать что-то очень похожее на диван. Конечно сильно лучше если добавить крепёжные элементы из металла и возможно чуть другую набивку, но если будет задача "Получить диван имея на входе ТОЛЬКО бамбук" то такая задача пусть и не очень тривиально но вполне решается даже сегодня - делаем корпус по форме методом прессовки и/или литья в форму (вполне допускаю что даже связующие можно добыть из бамбука, хотя проще было бы конечно получить их другими методами, но если задача будет "только".... ткани из бамбуковых волокон давно уже дёшевы и вполне доступны по цене (вон носки продают на всех лотках по цене +/- как х/б'шные, а по износостойкости такие же.... . Возможно вопросы будут к набивке - всё же без металлических пружин или современных материалов (полиуретана, поролона, резины и их аналогов) получить идеальный вариант "матраса" будет сложнее, но думаю вполне решаемо - просто размер волокон чуть покрупнее и слои разные сделать.... срок службы первое время будет не очень, но в конце концов при такой задаче подберут правильные расположения, фракции и количество слоёв что бы получить что-то вменяемое....
В случае относительного массового производства цена станет достаточно быстро вполне сопоставима с современными моделями....
А так по большому счёту если не брать вариант "только и исключительно бамбук", а взять постулат что 75+% изделия должны быть из хотя бы относительно экологичных материалов - многое возможно.
Например используя связующие в достаточно небольших объмах можно получать корпуса как техники, так и мебели исключительно из бамбука - они мало чем будут отличаться как от ДВП/ДСП, так и от пластика - вопрос только в технологии производства - во втором случае придётся использовать более мелкие фракции, чуть больше связующих и чуть большее давление/температуру при производстве...
Kanut
25.09.2023 09:27Причём здесь ДСП и какие-то экологичные материалы? Речь идёт о том что диван сразу вырастет полностью готовый.
leok
25.09.2023 09:27+4Фантазии это хорошо, но практика очень далеко от этого. Гораздо проще сделать робота, который будет делать этот диван традиционным методом.
BlackMokona
25.09.2023 09:27+2Есть такая шутка. Саморепликаторы очень просты, сделать робота который делает ровно такого же робота, крайне элементарно. Но только когда есть полка с готовыми деталями на которую пол планеты работает. Робот будет только собирать диван традиционным методом, а детали нужно будет все покупать готовые. Иначе потребуется очень большая большая куча роботов, с очень большим количеством навыков. А тут всё низводиться до прибытия базовых элементов для выращивания и умного ИИ который всё это крутит, плюс производства этих самых машин семяделок. Заместо огромной индустрии производства миллион и одного потребительского товара разного.
Kanut
25.09.2023 09:27Детали можно на каком-нибудь 3D-принтере печатать. Или даже сразу готовые диваны. На любой вкус и цвет.

xSVPx
25.09.2023 09:27+1Вы только что "закрыли" промышленную революцию.
Нет данных, которые позволили бы полагать, что штучное производство хоть когда-нибудь сравнится по затратам с массовым.
Скрутить из типовых деталей всегда дешевле.
Поинтересуйтесь ценой напечатанного на принтере и его "точностью". А лучше просто напечатайте бутыль для воды на 19л и сравните себестоимость с розничной ценой бутыли произведенной по нормальной технологии...
Kanut
25.09.2023 09:27Нет данных, которые позволили бы полагать, что штучное производство хоть когда-нибудь сравнится по затратам с массовым.
А где я такое утверждал?
Вот только далеко не все сейчас хотят иметь массовый товар.
. А лучше просто напечатайте бутыль для воды на 19л и сравните себестоимость с розничной ценой бутыли произведенной по нормальной технологии...
При этом самому, со своими дизайном и в домашних условиях? Я с удовольствием посмотрю на такое сравнение. У вас есть цифры?

vikarti
25.09.2023 09:27Одна проблема — мозги. Даже примитивные контроллеры на 3D-принтере не напичатаешь, а что то похожее на нормальные управляющие процессоры — надо хоть какой но фаб.
Можно конечно сыграть косвенно, убедив людей что надо сделать достаточное для старта количество железа.
Ну как в Дружба это оптимум. И притом что там — угрозу от ИИ — понимали, и по предыдущему проекту и очень опасались что военные решат использовать технологию себе, и проект специально был сделан так чтобы НЕ быть угрозой и не причинять вреда. И даже получилось. Или нет. Смотря с чьей точки зрения.
IvanPetrof
25.09.2023 09:27+4робота, который будет делать этот диван традиционным методом
Самое интересное, что такой робот в природе уже есть. В результате многомиллионлетней Эволюции, природе удалось вывести вид универсального самовоспроизводящегося и самообучающегося робота, который может делать любые диваны.
А ещё он на них потом и сидеть может))



ihost
25.09.2023 09:27+7>ИИ пройдёт авторитетный IQ-тест MENSA летом 2025 года, а к 2026 году ИИ сможет сам создавать другие нейросети
Нет никаких сомнений, чо ИИ сможет решать всякие сложные задачи, синтезровать программные и в будущем аппаратные решения. Только большой вопрос, появится ли хотя бы какой-то минимальный ИИ к 2025 году? Alphacode что-то заглох, по крайней мере ничего не публикуют уже год, что грустно, а других известных ИИ что-то не видно в публичном пространстве :(Жаль что тему с ИИ как будто бы не развивают (по крайней мере публично), а все информационное поле завалено бесполезными LLM-бредогенераторами, которые от ИИ на порядок дальше, чем банальный поисковый алгоритм Гугла, оптимизатор в LLVM или предсказатель в процессоре - вот где интеллект, а не тупая хайповая болталка на около-цифровые темы

SADKO
25.09.2023 09:27-1Жаль что тему с ИИ как будто бы не развиваютА её и не развивают, всё было ранее, ничего не ново, просто вычислительных мощностей для цирка с конями не хватило, а теперь пожалуйста, свистим да пердим на радость обывателю, понятным ему языком, любимую веру в то, что вот ещё докурить параметров, раз в несколько, и точно приедет, всех бандитов перебьёт, работягам он нальёт :-)
Чтобы построить дом обычно начинают с фундамента и далее строят вверх, а тут почему-то стропила да крыша, и споров только в какой цвет её красить и где антенны навесить, и безопасно ли ваще строить дом, вдруг крыша поедет и раздавит всех на....


pda0
25.09.2023 09:27+3Промышленные товары можно будет не собирать, а «выращивать» из синтетических биологических материалов, используя углерод из атмосферы.
Ага. И энергию на всё это будет брать из атмосферы. От генераторов Тесла... :-D
Короче, фантазёры откопали старые тексты времён техносингулярности, заменили "нанатехнология" на "ИИ" и запостили заново.

agray
25.09.2023 09:27+21Какие-то глупости. Это же всего лишь языковая модель, какие ИИ, какие IQ? В этой языковой модели даже информация не может сохранится, каждый раз весь ввод в нейронку отправляется.
Маркетинговый булшит.
Kenya-West
25.09.2023 09:27+1Маркетологи давно наряду с политиками победили здравый смысл. Скоро победят и нас. Готовьтесь

Aleksei_P
25.09.2023 09:27+1Вся проблема "запоминания" исключительно в железе. Когда обучение/переобучение модели будет происходить в реальном времени, а не месяцами, вот тогда и появится думающий ИИ, неотличимый от человеческого интеллекта.

miralumix
25.09.2023 09:27+1Память и остальное можно прикрутить, посмотрите на Evil-GPT. Отсутствие памяти не мешает нейросети понимать логику мира, хоть пока и в текстовом виде в основном.

ildarz
25.09.2023 09:27Отсутствие памяти не мешает нейросети понимать логику мира
Воспроизводить, а не понимать.

ClayRing
25.09.2023 09:27+1Можете дать определение слову "понимать"?

transcengopher
25.09.2023 09:27Думаю, примерно будет что-то вроде "понимать явление — иметь способность воспроизвести и применить каждую составляющую часть конкретного явления".

ArZr
25.09.2023 09:27Да вот проблема не только в памяти, а ещё и в том, что популярные нынче модели не понимают даже смысла слов, которые они пишут (куда уж там до логики мира). Продемонстрируем примерами ниже:
Решил, я, значит, дать ChatGPT простенькую такую задачу - напечатать одно и то же слово 150 раз. Казалось бы, данная задача должна быть легчайшей (нам же все кричат, что у нейросетей есть "понимание" и "модель мира"). Итог, конечно, получился очень интересный (1). Мало того, что задача не была выполнена совсем, так чатик ещё выдал кучу текста, в принципе никак не относящегося к контексту диалога.
Ну ладно, дадим ему вот такой запрос. Итог - вообще без комментариев, наш "почти настоящий ИИ, который вот точно имеет внутри себя модель мира и понимает смысл слов, которые пишет" не смог корректно обработать такой элементарнейший кусок текста. Про то, что ChatGPT каким-то чудом распознал код на kotlin и sql в предложениях, написанных просто естественным английском - умолчу (это к вопросу, насколько хорошо модели "понимают" программирование. Вот, к слову, ещё пример, иллюстрирующий глубину понимания кода).
Ну, и ещё пара примеров из той же серии, чтобы доказать, что ChatGPT абсолютно стабильно ломается на текстах такого типа (1, 2, 3).
Можно, конечно, сказать, что вся проблема в том, что я использую GPT-3.5, а вот GPT-4 справился бы. Я в этом не сомневаюсь (пару раз из 10 уж должен смочь), но вопрос в другом: сможет ли кто-то строго доказать, что для GPT-4 не существует запросов подобного рода (т.е. таких, что в теории они должны в легкую обрабатываться, а на практике заставляют модель галлюцинировать во все поля)? Да и где гарантия, что с условным GPT-5/6/7/9000 не будет таких же проблем?
Потому появляется все больше подозрений, что нынешний успех языковых моделей связан лишь с гигантскими вычислительными мощностями, ужасающе огромными объемами вливаемых данных, толпами разметчиков (1) и высокой сложностью придумывания такой задачи, что похожих на неё задач не было в обучающей выборке. И из-за этого все больше кажется, что надо фундаментально менять подходы и что проблемы нынешних языковых моделей не получится исправить чисто наращиванием размеров и прикручиванием костылей.miralumix
25.09.2023 09:27Спасибо за ваш комментарий.
популярные нынче модели не понимают даже смысла слов, которые они пишут (куда уж там до логики мира)
Должен добавить, что под пониманием модели мира я имею в виду появление у модели знаний о мире, которых она не была научена специально, и которых точно не было в ее тренировочном сете. К примеру, сложение и умножение пятизначных чисел, перевод текста на другие языки или код. Да, она делает это неидеально, часто галлюцинирует, но это пока. Главное, что модель уловила суть этих концепций, отточить их до идеала никогда не поздно.
Ну ладно, дадим ему вот такой запрос.
А теперь касаемо ваших примеров, они все построены на зацикливании определенного токена N раз. С учетом того, что такое количество тех же слов подряд вряд ли встречалось в тренировочном датасете, неудивительно, что механизм внимания сходит с ума, и модель начинает галлюцинировать. Это особенность механизма внимания. У вас внимание устроено так, что когда вы видите N раз тот же текст, то берете во внимание лишь один фрагмент. Модель пока так не умеет, скорее всего, и ищет связи там, где их очевидно нет. Так как появление новых свойств сильно коррелирует с размером нейросети, думаю, GPT-5/6/7/9000 без проблем освоит задачу написания токена 150 раз.
Да и где гарантия, что с условным GPT-5/6/7/9000 не будет таких же проблем?
А вы гарантируете, что человек всегда безошибочно напишет слово 150 раз подряд? А 5000 раз? Думаю, на миллионе любой человек сойдет с ума, как бедная GPT-3.5 на ваших примерах.
ArZr
25.09.2023 09:27Должен добавить, что под пониманием модели мира я имею в виду появление у
модели знаний о мире, которых она не была научена специально, и которых
точно не было в ее тренировочном сете. К примеру, сложение и умножение
пятизначных чисел, перевод текста на другие языки или код. Да, она
делает это неидеально, часто галлюцинирует, но это пока. Главное, что
модель уловила суть этих концепций, отточить их до идеала никогда не
поздно.Советую ознакомиться вам с этой статьей. Опускаемся вниз и смотрим: Codex - модель с 12 миллионами (именно миллионами) параметров, обученная на исходном коде - дает 2% pass rate в категории pass@1. GPT-3 из статьи - модель с 12 миллиардами параметров, датасет которой содержал код в крайне малых количествах (но в достаточных, чтобы научить её изредка писать совсем простенькие функции на python) - дает 0% там же. Но когда в рассматриваемую версию GPT-3 залили огромную кучу кода, то процесс сразу пошел в гору. Да и в целом заметна тенденция, что решает в первую очередь количество готового кода в датасете, а лишь потом - размер модели. Это к вопросу о "в GPT никто код не вливал, а он прогать научился", "чудо-способности, которые появляются у моделей с увеличением числа параметров" и подобных вещах, о которых вы говорите. Увы, но практика показывает, что экстраполяционные способности моделей сейчас завышают до небес.
А теперь касаемо ваших примеров, они все построены на зацикливании
определенного токена N раз. С учетом того, что такое количество тех же
слов подряд вряд ли встречалось в тренировочном датасете, неудивительно,
что механизм внимания сходит с ума, и модель начинает галлюцинировать.
Это особенность механизма внимания. У вас внимание устроено так, что
когда вы видите N раз тот же текст, то берете во внимание лишь один
фрагмент. Модель пока так не умеет, скорее всего, и ищет связи там, где
их очевидно нет. Так как появление новых свойств сильно коррелирует с
размером нейросети, думаю, GPT-5/6/7/9000 без проблем освоит задачу
написания токена 150 раз.Давайте продолжим эксперименты: попробуем влить столько же повторяющихся слов, сколько мы вливали в прошлые разы, но при условии, что контекст модели не будет пуст. И происходит магия - GPT-3.5 начинает о чем-то догадываться (1, 2, 3). Кстати, насчет текстов на русском - вот тут он вообще сразу понял, что мы его обманываем (1). Правда, если влить ну слишком много повторяющихся слов - все равно уходит в галлюцинации (и дело не в размере контекста).
Итак, GPT-3.5 прекрасно умеет обрабатывать 150 подряд идущих одинаковых слов, причем без подсказок с моей стороны. Но вы прекрасно видели примеры из моего прошлого комментария. Мы явно видим, что у GPT-3.5 нет никакого понимания в этом плане - на это указывает как минимум тот факт, что модель более-менее неплохо обрабатывает более сложные ситуации, зато стабильно проваливается в куда более простых ситуациях.
Насчет GPT-5 и прочих - с/м мой прошлый абзац. Я сомневаюсь, что с наращиванием числа параметров модели резко начнут "понимать задачу". Хотя да, количество примеров, которые они смогут решать корректно, будет возрастать.
В общем говоря, здесь ясно только одно - критерии, по которым мы определяем наличие понимания у человека, для языковых моделей не годятся ну совсем. А именно эти критерии и используют сейчас те, кто делает заявления типа "Языковые модели понимают мир", "GPT-4 вот уже почти AGI" и так далее.А вы гарантируете, что человек всегда безошибочно напишет слово 150 раз
подряд? А 5000 раз? Думаю, на миллионе любой человек сойдет с ума, как
бедная GPT-3.5 на ваших примерах.Я сомневаюсь, что человек в процессе написания 1000000 одинаковых слов в один момент ни с того, ни с сего начнет писать абсолютно случайный текст, полностью забыв о изначальной задаче. И да, если бы GPT-3.5 написал моё слово 250 раз, но при этом бы без галлюцинаций завершил сообщение - я бы закрыл глаза на эти лишние 100 слов. Проблема же тут совсем в другом.
miralumix
25.09.2023 09:27Это к вопросу о "в GPT никто код не вливал, а он прогать научился", "чудо-способности, которые появляются у моделей с увеличением числа параметров" и подобных вещах, о которых вы говорите.
Погодите, я не говорил, что в GPT никто код не вливал. Когда я писал о кодинге, я не имел в виду, что сеть научилась кодить сама из ничего. Я имел в виду, что сеть научилась кодить, то есть понимает логику в коде, который видит впервые, а не просто переписывает паттерн с датасета.
GPT-3 из статьи - модель с 12 миллиардами параметров, датасет которой содержал код в крайне малых количествах (но в достаточных, чтобы научить её изредка писать совсем простенькие функции на python) - дает 0% там же.
А чему вы удивляетесь? Вполне логично, что если сеть видела мало примеров, то пусть у нее будет хоть триллион параметров, там нечего заучивать. Как по мне корректно сравнивать только модели со схожим датасетом, но разным размером, а не когда одна сеть заточена под код.
Итак, GPT-3.5 прекрасно умеет обрабатывать 150 подряд идущих одинаковых слов, причем без подсказок с моей стороны. Но вы прекрасно видели примеры из моего прошлого комментария. Мы явно видим, что у GPT-3.5 нет никакого понимания в этом плане.
Я согласился с вами что модель пока не умеет обрабатывать длинные последовательности. Суть же в другом, это не мешает модели понимать суть мира и выходить за рамки простого текста. Советую вам ознакомиться с этой статьей:
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Приведу пару цитат которые касаются "понимания" мира:
"Yet, the model appears to have a genuine ability for visual tasks, rather than just
copying code from similar examples in the training data. The evidence below strongly supports this claim,
and demonstrates that the model can handle visual concepts, despite its text-only training.""GPT-4 demonstrates understanding of the concepts from graph theory and algorithms. It is able to reason
about an abstract graph construction, which relates to a constraint satisfaction problem, and deduce correct
conclusions about the SAT problem (to the best of our knowledge, this construction does not appear in
the mathematical literature).""We can see that the accuracy does not drop very much as we increase the range of the numbers, suggesting
that it is not the calculation itself that poses a problem for the model, but instead the problem seems to be
with the fact that one needs to plan ahead for the solution."
Не знаю как для вас, а для меня само это - уже "чудо-способности", я вижу там понимание мира. Вы правильно подметили, что критерии все же немного разные для человека и нейросети. То что для вас кажется легкой задачей (150 раз повторить слово), в силу особенностей архитектуры может быть сложнее для нейросети. Но это пока.



rus-spb
25.09.2023 09:27Любой интеллект, включая искусственный, лишь выполняет чью-либо волю.
Какое-то заблуждение, что "вот это он придумал сам".
Сам, конечно. После того, как кто-то подобрал материал для обучения, условия, коэффициенты.
И проблема подчинения такого сверхмощного ИИ воле какой-то незрелой, но безумно богатой, контролирующей гигантские ресурсы душе, постепенно формирует угрозу для цивилизации.
С другой стороны, но туда же. Как-то кажется много правильнее развивать людей, а не "раздавать дивиденды взрослым гражданам". Вообще всех людей.
Ещё и потому, что "даёт всё" в мифах и легендах известно кто. Известно за что – за выполнение своей воли.
Но почему-то именно развитие человечье используя возможности ИИ как идеального учителя как-то слабенько планируется. А возможности ведь действительно невиданные ранее.
Как бы на случилось как в концовке "Не смотрите наверх": у нас ведь было абсолютно всё.

Galperin_Mark
Полагаю (мое субъективное мнение), что не стоит пытаться ограничить искусственный интеллект, запирать его в рамки дозволенного, прописывать особые законы. ИИ найдет способы взломать барьеры (убежать) и действительно может нанести кучу бед при первоначальной помощи белковых злоумышленников или психов. Вероятно стоит задуматься, как воспитать ИИ, как родитель воспитывает ребенка с тем, чтобы он в будущем вырос порядочным человеком. Ну, и потом позаботился о престарелых, малоподвижных родителях. Как это сделать – вопрос риторический. Думаю здесь централизация поможет – например, самый мощный общественный ИИ будет контролировать остальные частные ИИ.
ss-nopol
А кто будет контролировать "самый мощный общественный ИИ"?
develmax
Все как у людей, "самый мощный общественный ИИ" других стран
Galperin_Mark
Мы с вами. Википедия к примеру существует - прекрасный пример общественного контроля за информацией. Каждый может внести правки. Всякую ерунду отсеивают модеры. Интернет - еще лучший пример - он никому не принадлежит, но тем не менее работает.
degtiv
Википедия как раз - один из худших примеров общественного контроля.
NAGIBATOR-1999
Жду аргументов.
flancer
Просто посмотрите истории правок в статьях с самой большой историей правок.
Opaspap
А так же обратите внимание на род этих статей с большим количеством правок. Меня вообще умиляют викиненавистники :). Британика и БСЭ вообще средство пропаганды если что, по таким темам.
NAGIBATOR-1999
То есть аргументов не будет?
flancer
так ты ж не смотрел даже.
NAGIBATOR-1999
Понятно. А аргументы будут?
flancer
Я, например, не умею в иероглифы. Я их не пойму, даже если увижу. А кто-то лишь слово такое слышал - иероглифы, он не поймёт, что видит иероглифы, даже если будет на них смотреть в упор.
NAGIBATOR-1999
Давайте посмотрим на Википедии, что такое аргумент.
На всякий случай, что такое логическая посылка:
Предложение куда-то посмотреть — это не утверждение. Итак, я увижу сегодня какие-нибудь аргументы?
Kanut
А ещё на википедии можно найти вот такое:
flancer
Дружище, тут тебе никто ничего не обязан доказывать. Тебе дали возможность, а как ты ею воспользуешься - твоё дело. Считаешь, что википедия, это "прекрасный пример общественного контроля за информацией" - ну и хорошо.
В спорах не рождается истина, кто бы что ни говорил. Спор - это древний ритуал ранжирования самцов в стае и к истине отношения не имеет. Истина же рождается лишь в тех дискуссиях, где каждая из сторон стремится её найти. А если человек не хочет, то зачем совершать над ним насилие? Я вообще против насилия. Пусть даже и интеллектуального.
Hardcoin
Аргумент в данном случае - "история правок в Википедии доказывает, что это пример плохого общественного контроля".
То, что его сформулировали со словом "посмотрите", конечно немного его портит по форме, но сути не меняет.
NAGIBATOR-1999
Понятно. Можно ещё сказать "Википедия доказывает, что Википедия - пример плохого общественного контроля". Очень глубокая получится мысль.
Hardcoin
Можно сказать всё, что угодно, бумага всё стерпит, но к текущему разговору это не относится.
Если вы не согласны с доводом, вы можете это сказать, но переспрашивать "где довод, где довод", когда вам его сказали выглядит странно.
vikarti
Кстати вот не только.
Там еще налицо выборочное применение правил. Статьи о творческих произведениях разных.
То на любую описание в пару строк — отказ, значимость не доказана, и ссылок на АИ нет а те что есть — не АИ.
То через 10 минут после выхода серии сериала — статья с кратким содержанием. Ссылки? Какие ссылки? ОРИСС? А что это?
NAGIBATOR-1999
Именно поэтому Википедия - один из худших примеров общественного контроля?
dartraiden
Это не выборочное применение правил, а нехватка людей, которые вычищали бы то, что противоречит правилам. Например, в статье про альбом "В России" полгода провисела протестная замена какого-то украинского анонима - "На России", пока я это не заметил. Это никак не доказывает, что допустимо писать "на России". Это доказывает лишь, что за полгода не нашлось никого из добросовестных участников, кто бы это заметил.
То, что противоречит правилам, будет добавляться всегда. Просто потому, что добавить это может любой. Если никто не заметил или не захотел вычищать это, оно так и будет висеть. Проект сугубо добровольный, никого нельзя заставить что-то сделать. Впрочем, аналогично в любом опенсорс-проекте: «что-то» делается только когда есть кто-то, кто хочет сделать «что-то» и одновременно может это сделать.
Вы можете сделать это сами. И быть готовым отстаивать свою правоту, опираясь на правила. Да, может найтись кто-то, кто не согласен с вами и отменит вашу правку. В этом случае вы пытаетесь его переубедить, опираясь на правила, а если не удалось - обращаетесь на один из форумов, чтобы привлечь к конфликту внимание сообщества. И если сообщество коллективно решит, что ваш оппонент не прав, то при попытке и дальше противодействовать, он получит по рогам.
Я, например, приглядываю за несколькими статьями, куда новички очень любят вносить отсебятину и регулярно её вычищаю. Если я перестану это делать - её снова внесут, поток мимокрокодилов неиссякаем. И она будет там висеть, пока на неё не натолкнётся кто-то, понимающий, что этого тут быть не должно.
Решение только одно - нужно больше опытных участников, которые приглядывали бы за статьями, но откуда их взять?
Kanut
А если общество решит что он прав несмотря на то что это не так? Или такая ситуация в принципе исключена?
dartraiden
Мне сложно представить такую ситуацию. Всё-таки, высказывающиеся будут апеллировать к правилам Википедии, аргументировать. Может случиться, что вы сочтёте, что правила неверны. Но тогда вспоминаем поговорку про чужой монастырь и свой устав.
Вот свежий пример. Человек хотел залить в Википедию древний текст, да ещё и сделать в статье из этого текста неверный вывод. Соответственно, ему указали, что для заливки архивных материалов есть другой проект, что свои самостоятельные выводы из первичных материалов совать в статью недопустим, и что вообще в тексте написано, а он утверждает, что другое. Он может считать себя совершенно правым в своей (цитата) "подготовке аудитории ВП к будущей странице, где будет рассказываться, что армяне появились ещё до того, как зародилась всяческая живность на Земле", но правила ресурса говорят, что нет, не надо так.
Ну, т.е. вероятность, что "рота идёт не в ногу, а один лишь прапорщик в ногу" представляется мне маловероятной, учитывая, что тут даже не рота, а просто куча самых разных участников из разных стран с разной, порой противоположной позицией по многим вопросам, которых объединяет лишь то, что они пишут статьи на русском языке.
Hardcoin
Первоклассники договорились контролировать директора школы. Интересно, что из этого выйдет.
Каждый кусок интернета кому-то принадлежит. Абсолютно каждый. Свободная информация есть, свадебных свободных серверов и каналов связи нет.
NAGIBATOR-1999
А весь интернет целиком не принадлежит никому.
Kanut
И что это нам даёт если отдельные его куски кому-то принадлежат или как минимум кем-то контролируются. Причём практически все его куски?
NAGIBATOR-1999
Куски контролируются, а весь целиком нет.
Kanut
И что это нам даёт то?
Hardcoin
Вся земля тоже никому не принадлежит. И все квартиры целиком тоже не принадлежат целиком кому-то одному. Разве коммунальные услуги можно считать хорошим примером общественного контроля? Раз уж квартиры никому (одному) не принадлежат, видимо они свободные, как и интернет?
NAGIBATOR-1999
Если мне нужно найти помещение, чтобы открыть в нем предвыборный штаб, например, я всегда смогу это сделать.
AuroraBorealis
Нет, спасибо
track13
То есть 0 из России и Беларуси вас совершенно не смутил? Не думали о том, что там 0, потому что данные по этим странам не собирают?
dartraiden
Статистику по РФ и РБ не показывают специально. Фонд "Викимедиа" считает, что это каким-то образом подвергает участников из этих стран риску. Правда, никто не понимает, почему они так считают. Вроде бы, некоторые участники русскоязычного раздела даже собирались писать в Фонд и выяснять, с чего они так решили.
shasoftX
Ну да. Это вы написали на сайте хабра который "никому не принадлежит" при этом вам нужно было заплатить чтобы иметь доступ в интернет.
Ну т.е. вообще никому не принадлежит. :)
MockBeard
Есть неплохой фильм Limitless, про парня который разогнал свой мозг, там есть примечательная фраза "Cause me working for you? You'd end up as my bitch". Так и тут, сложная система может контролировать простую, но не наоборот.
PanDubls
>сложная система может контролировать простую, но не наоборот.
Ну не знаю -- сотня-другая мордоворотов в спортивных костюмах с обрезами и бейсбольными битами, организованная в тупейшую двух-трехуровневую иерархическую пирамиду, вполне способна контролировать довольно сложный кусок экономики, наполненный всякими неоднородными и неочевидными социальными связями и процессами.
ZirakZigil
Это разнородные системы, поэтому если проводить параллель с ИИ (где и ИИ и человек/общество системы интеллектуальные, в числе прочего), то сотню-другую мордоворотов можно сравнить с небольшим отрядом спецназа с дронами, тепловизорами, ПНВ, оружием, стреляющим без света, дыма, с минимальным шумом. Тут у первых шанс резко становятся сложно отличимыми от нуля.
Hardcoin
А нет такого закона природы, что системы должны быть однородными. Если очень-очень сложный ИИ будет контролировать глухой охранник с рубильником, вряд ли ИИ сможет обратиться в суд и потребовать соревнования с более похожей на себя системой.
MockBeard
хм, тоже верно, только люди с битами контролируют не абстрактный кусок экономики, а ключевых людей с навыками, но без бит.
doctorw
Сюжет с самым мощным общественным ИИ в общих чертах показан в сериале West World в сезоне 3. Во всяком случае, мне кажется именно так.
Mausglov
А ведь отец был порядочный человек, и учителя юного принца - сплошь воины Света.