
Буквально на секунду представьте, что у вас есть парочка здоровенных кластеров Apache Kafka, каждый из которых держит по нескольку миллионов rps. И тут вас попросили зеркалировать топик из одного кластера в другой. Максимально близко к реалтайму, да ещё и с некоторыми специфическими условиями. Если стало страшно, интересно или страшно интересно, то это статья для вас.
Под катом я расскажу, что такое зеркалирование и зачем оно нужно. Как нам перестало хватать Mirror Maker’а. Поговорим о возможных решениях и выборе между ними. И дам подробную инструкцию, как вам развернуть такое решение у себя.

Привет, меня зовут Дмитрий, я старший инженер инфраструктурных сервисов в Ozon из команды Message Bus. Ключевая инфраструктурная единица нашего отдела — это шина данных на базе Apache Kafka. Вместе с командой платформенных сервисов мы решаем глобальную задачу по предоставлению Kafka as a service. Это значит, что продуктовой команде не нужно задумываться о масштабировании и отказоустойчивости — для них это само собой разумеющиеся возможности шины данных. Пользователь может ничего не знать о брокерах и количестве реплик, тонких настройках для каждого топика и других особенностях работы кластера Kafka. Вместо этого ему предлагается просто заказывать нужные сущности, выбирая из каталога шаблонов на портале, писать в топики любое количество сообщений любого объёма и вычитывать их с нужной скоростью.
Мы продолжаем серию рассказов об инфраструктуре вокруг Kafka. В прошлый раз мой коллега поведал на Хабре о том, как мы внедряли Cruise Control. А сегодня поговорим о выборе инструмента для зеркалирования топиков.
Под «зеркалированием» мы понимаем копирование данных из одного топика в другой, при этом не переставая эксплуатировать исходный топик — писать и читать из него. Такое копирование может понадобится и для того, чтобы один топик оказался в двух разных продуктовых кластерах. И для того, чтобы данные какого-нибудь топика из продуктового кластера, конечно, без персональных данных и бизнес-критичной информации, оказались в тестовом контуре. Где команды могут протестировать новые версии своих сервисов без опасения что-либо сломать, но с настоящими данными.
Как мы зеркалировали трафик раньше и сейчас
С чего мы начинали?
Изначально при поступлении запроса на зеркалирование трафика мы создавали сервис на виртуальной машине Mirror Maker, в котором указывали необходимые настройки кластеров и топиков. Так как направления зеркалирования были между различными средами, работало несколько сервисов. Следующим очевидным шагом мы перенесли эти сервисы в контейнеры Kubernetes. Теперь для добавления или удаления топиков нам требовалось создавать новый деплоймент, что занимало время на прохождение всех этапов сборки и развёртывания.
Как мы работаем сейчас?
У нас имеется кластер Brooklin Mirror Maker, в котором настроены подключения ко всем необходимым кластерам Kafka. В любой момент можно посмотреть, какие задачи запущены или остановлены. Добавление, удаление, остановка новых задач зеркалирования занимает не более 5-10 минут даже для неподготовленного пользователя.
Как возникла потребность в универсальном сервисе для зеркалирования топиков
Мы не начали эту историю с чистого листа — в компании успешно использовалось решение на основе Mirror Maker 1 для зеркалирования топиков. Обычно в тестовые контуры мы перенаправляли трафик из нескольких топиков для тестирования работы сервисов. При этом имена топиков совпадали, и проблем не возникало. Во время одного инцидента возникла потребность в «переливании» трафика между production-кластерами с изменением имени топика. Мы оказались не готовы в моменте решить эту задачу и нам пришлось идти более сложным путём. Тогда мы решили найти универсальное средство для решения таких задач в будущем.
Наши требования к системам зеркалирования:
Топик может быть реплицирован как между кластерами, так и в пределах одного кластера.
Имя топика назначения может отличаться от имени топика источника, таким образом можно организовать переименование топика в пределах одного кластера, не останавливая запись.
Конфигурации исходного топика и топика назначения могут отличаться. Таким образом можно уменьшить количество партиций в пределах одного кластера. Тогда как Kafka обычно позволяет только увеличение количества партиций.
Добавление/удаление топиков на репликацию должно быть максимально просто, чтобы эту задачу можно было передавать инженерам линии поддержки.
Репликатор в конечном итоге не должен использовать Zookeeper целевых кластеров Kafka, но может использовать отдельный для собственных нужд. Сейчас мы используем версии Kafka, требующие Zookeeper, но планируем переход на KRaft в будущем.
Очень хотелось бы иметь возможность фильтрации сообщений при репликации. Но это оставим как опциональное требование.
Сравнительная таблица систем зеркалирования
Mirror Maker — решение на Java от Apache Kafka.
Ureplicator — решение на Java от компании Uber.
Ureplicator Non Federative функционально аналогичен Mirror Maker.
Ureplicator Federative позволяет создавать направления из групп Non Federative.
Brooklin — решение на Java от компании LinkedIn.
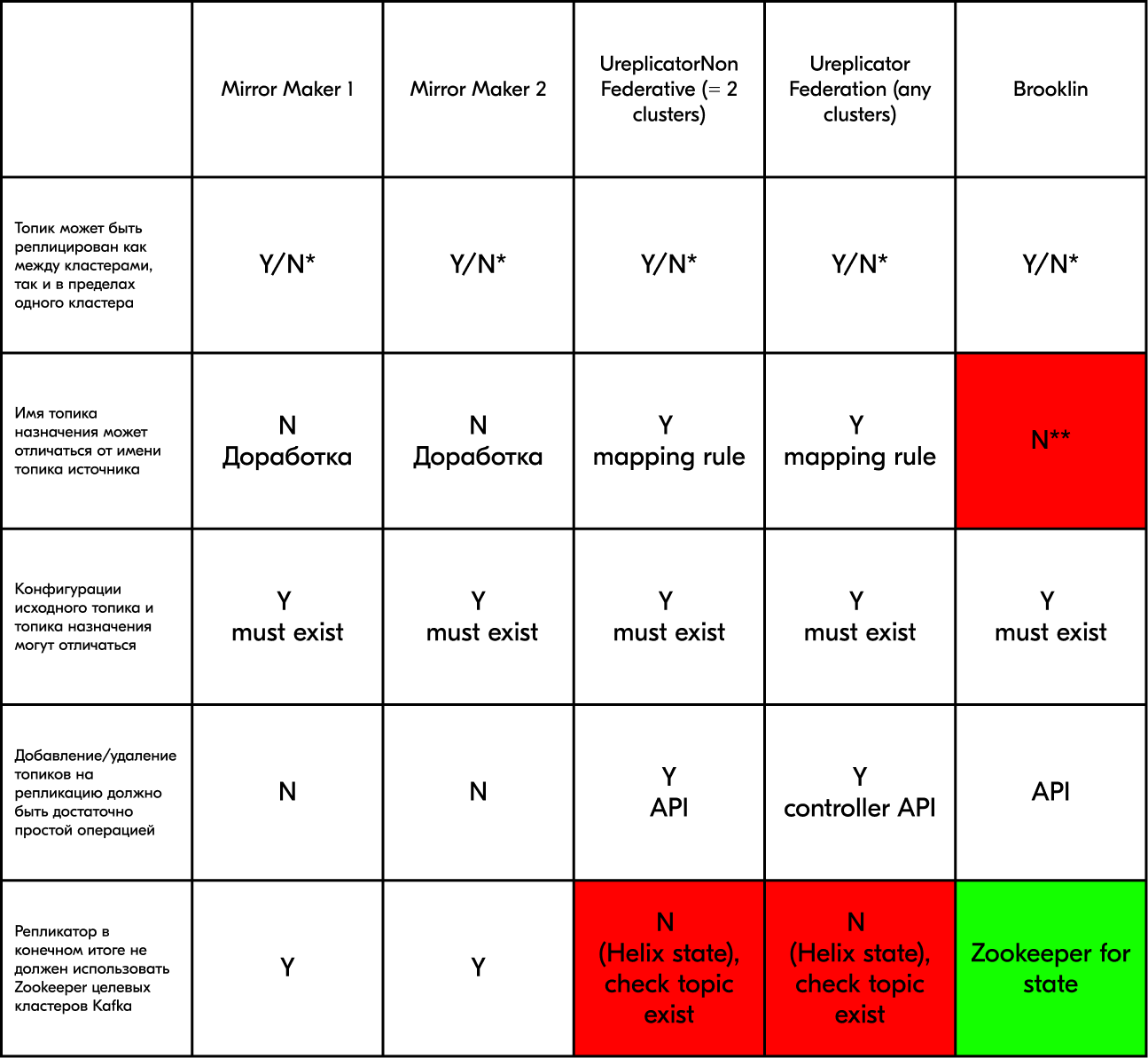
* Y — имена топиков совпадают в разных кластерах.
N — имя топика назначения должно быть другим в пределах одного кластера.
** Brooklin в оригинальном варианте не позволяет изменять имя топика назначения.
Исходя из сравнительной таблицы, ни одно решение не удовлетворяет требованиям, тем не менее в документации brooklin-rest-client есть ключ I - destination, что, возможно, позволит произвольно изменить название топика. Мы начали более внимательно смотреть на этот продукт.
Описание ключей brooklin-rest-client.sh
Console app to manage datastreams. |
|
-c,--connector <CONNECTOR_NAME> |
Name of the connector |
-d,--destination <DESTINATION_URI> |
Datastream destination uri |
-dp,--destinationpartitions <DESTINATION_PARTITIONS> |
Number of partitions in the destination |
-es,--eserde <ENVELOPE_SERDE> |
Name of the Serde to be used for Envelope. Config is optional. |
-f,--force |
force the entire datastream group to be paused/resumed |
-h,--help |
Display this message |
-ks,--kserde <KEY_SERDE> |
Name of the Serde to be used for key. Config is optional. |
-m,--metadata <DATASTREAM_METADATA> |
Datastream metadata key value pairs represented as json {"key1":"value1","key2":"value2"} |
-n,--name <DATASTREAM_NAME> |
Name of the datastream |
-nf,--noformat |
Print without formatting |
-o,--operation <DATASTREAM_OPERATION> |
Operation to perform accepted values [CREATE, READ, DELETE, READALL] |
-p,--partitions <NUM_PARTITIONS> |
Number of partitions in the source |
-ps,--pserde <PAYLOAD_SERDE> |
Name of the Serde to be used for payload. Config is optional. |
-s,--source <SOURCE_URI> |
Datastream source uri |
-sp,--sourcepartitions <SOURCE_PARTITIONS> |
the partitions which need to be moved |
-t,--transport <TRANSPORT_NAME> |
Name of the Datastream Transport to use, default kafka. |
-th,--targethost <TARGET_HOST> |
Name of the target host |
-u,--uri <MANAGEMENT_URI> |
Management service |
Изучаем Brooklin Mirror Maker
Стоит отметить, что Brooklin изначально создавался компанией LinkedIn для зеркалирования кластеров. Посмотреть результаты тестирования можно тут.
Brooklin использует кластер Zookeeper для хранения статуса и управления задачами.
Основные свойства приложения:
масштабируемость добавлением node-кластера;
простое управление кластерами источниками/получателями;
различные методы подключения к одному и тому же кластеру (PLAIN, SSL, SASL);
наличие API для управления задачами;
зеркалирование топиков с данными в любом направлении;
задача выполняется при недоступности части партиций;
возможность остановки/запуска задач или чтения партиций.
Возможности Brooklin
Brooklin — серверное приложение Java, разворачиваемое в кластере хостов, на каждом из которых может быть запущено несколько экземпляров приложения с одинаковым функционалом.
Термины
Datastream - описание соединения между двумя системами, источник и получатель.
Brooklin позволяет создавать любое количество Datastream для организации различных подключений источника и получателя.
Для обеспечения масштабируемости Brooklin партиционирует данные в разрезе Datastream либо представляет их как поток с единственной партицией.
Каждый блок партиционированных данных разбивается на несколько DatastreamTasks с ограниченным количеством партиций для обработки в целях повышения увеличения полосы пропускания.
Connector — абстрактное представление модулей для чтения данных.
Существует несколько реализаций Connector для чтения различных источников.
Каждый Connector связан с AssignmentStrategy, которая определяет, как разбиваются задачи в разрезе Datastreams и как задачи распределяются между запущенными приложениями Brooklin.
TransportProvider — абстрактное представление модулей для записи данных.
Существует несколько реализаций TransportProvider для записи данных в различные системы.
Brooklin Coordinator — модуль, отвечающий за управление различными Connector.
Объект Coordinator может быть только один в каждом запущенном приложении Brooklin.
В кластере Brooklin Coordinator допускается только один Leader, остальные являются ведомыми.
Brooklin использует Zookeeper для голосования в выборе Coordinator-лидера.
Leader отвечает за распределение задач между Coordinators.
Каждый Leader Coordinator связан с AssignmentStrategy для назначения задач Connector в разрезе Datastreams и DatastreamTasks.
Пример AssignmentStrategy — LoadbalancingStrategy-распределения DatastreamTasks между всеми Coordinators.
Архитектура

Серверное приложение Brooklin разворачивается на одном/нескольких серверах и использует ZooKeeper как единственное хранилище достоверной информации о Datastream и метаданных DatastreamTask.
Информация о запущенных приложениях Brooklin и назначенных DatastreamTask хранится в ZooKeeper.
Каждое приложение Brooklin предоставляет REST-интерфейс — Datastream Management Service (DMS).
Каждая сущность Brooklin открывает REST endpoint — aka Datastream Management Service (DMS) — который позволяет выполнить операции Create (создание), Read (чтение), Update (редактирование) и Delete (удаление) по HTTP-протоколу.
Процесс создания Datastream
Основные концепции создания Datastream представлены на рисунке.
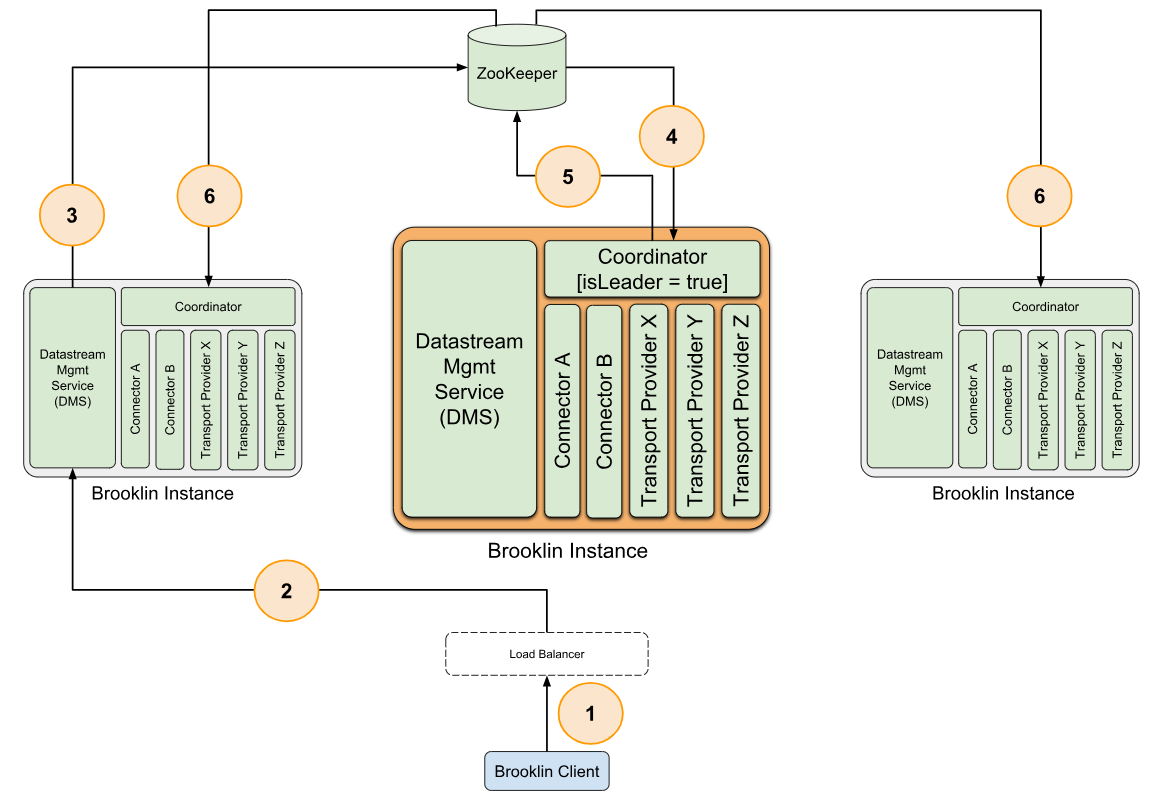
Клиент отправляет запрос на создание Datastream.
Запрос перенаправляется через REST к Datastream Management Service любого приложения Brooklin.
Данные Datastream проверяются и записываются в соответствующую znode ZooKeeper, за изменениями которых следит Leader Coordinator.
Leader Coordinator получает уведомление о создании новой Datastream znode.
Leader Coordinator производит чтение метаданных нового Datastream и на основании AssignmentStrategy, ассоциированной с подходящим Connector, разбивает Datastream на одну или несколько DatastreamTasks. Назначение DatastreamTasks происходит на основании записи в ZooKeeper доступным Coordinator.
Coordinators, получив уведомление о новом назначении DatastreamTask, в соответствующих znodes немедленно приступает к обработке, используя соответствующие Connectors.
ZooKeeper
В дополнение к выбору Leader Coordinator приложения Brooklin актуализируют следующую информацию в ZooKeeper:
регистрация типов Connector;
метаинформация о Datastream и DatastreamTasks;
DatastreamTask-информация о состоянии (e.g. offsets/checkpoints, processing errors);
информация об активных нодах Brooklin;
DatastreamTask-назначения между нодами Brooklin.
Представление данных в Zookeeper

Структура
Каждый кластер Brooklin имеет одну znode верхнего уровня.
/dms – определения Datastreams (JSON).
-
/connectors
sub-znode для каждого зарегистрированного типа Connector;
/connectors/<connector-type>/ определения DatastreamTasks, обрабатываемые этим типом Connector, одна znode на DatastreamTask;
два подуровня /connectors/<connector-type>/<datastreamtask> znode: config and state;
config хранит назначения DatastreamTasks;
state хранит информацию о статусе Connectors (offsets/checkpoints).
-
/liveinstances
каждый экземпляр Brooklin создаёт инкрементальную эфемерную znodes для организации leader Coordinator;
значение каждой sub-znode — это имя хоста соответствующего Brooklin-приложения.
-
/instances
каждое приложение Brooklin создаёт персистентную znode. Znode представляется в виде имени машины и уникального номера в соответствии с /liveinstances;
так же создаются две sub-znode — assignments and errors;
assignments всех DatastreamTasks назначенных приложению Brooklin;
errors-сообщения об ошибках каждого приложения.
Процесс работы
Leader Coordinator наблюдает за изменениями в the /dms znode — создание, удаление и изменение Datastreams.
Каждый Coorindator наблюдает за изменениями соответствующей ему znode /instances для получения уведомления об изменениях в дочерних znode.
Leader Coordinator назначает DatastreamTasks приложениям Brooklin путём изменения в assignment znode-ветки /instances/<instance-name>.
Метрики
Метрики и доступны через JMX exporter (JmxReporter) или файлы CSV (CsvReporter).
Итак, приступаем:
Скачиваем скомпилированное приложение https://github.com/linkedin/brooklin/releases/download/4.1.0/brooklin-4.1.0.tgz
Скачиваем исходники, они пригодятся на следующих этапах https://github.com/linkedin/brooklin/archive/refs/tags/4.1.0.zip
Запускаем Zookeeper, Kafka, Brooklin по инструкции с сайта https://github.com/linkedin/brooklin/wiki/Mirroring-Kafka-Clusters
Создаём Datastream без переименования топика
brooklin-rest-client.sh -o CREATE -u http://localhost:32311/ -n first-mirroring-stream -s "kafka://devenv:9094/T1" -c kafkaMirroringConnector -t kafkaTransportProvider -m '{"owner":"test-user","system.reuseExistingDestination":"false"}' Успех
{
"Status": "READY",
"metadata": {
"owner": "test-user",
"system.reuseExistingDestination": "false",
"system.destination.KafkaBrokers": "devenv:9093",
"system.creation.ms": "1677876640811",
"group.id": "first-mirroring-stream",
"system.taskPrefix": "first-mirroring-stream",
"system.IsConnectorManagedDestination": "true",
"datastreamUUID": "4ebd97c0-48a1-4979-bc21-50cf34618c81"
},
"transportProviderName": "kafkaTransportProvider",
"destination": {
"connectionString": "kafka://devenv:9093/*"
},
"name": "first-mirroring-stream",
"connectorName": "kafkaMirroringConnector",
"source": {
"connectionString": "kafka://devenv:9094/T1"
}
}
Пробуем использовать ключи CLI
-d,–destination;
-dp,–destination partitions
brooklin-rest-client.sh -o CREATE -u http://localhost:32311/ -n first-mirroring-stream -s "kafka://devenv:9094/T1" -d "kafka://devenv:9093/T1" -dp 1 -c kafkaMirroringConnector -t kafkaTransportProvider -m '{"owner":"test-user","system.reuseExistingDestination":"false"}'Ошибка! Читайте дальше, как обойти это ограничение.
cause=BYOT is not allowed for connector kafkaMirroringConnector. Datastream: {Status=INITIALIZING, metadata={owner=test-user, datastreamUUID=48e04aec-54c3-47fe-8414-b104f903579f, system.reuseExistingDestination=false, system.IsUserManagedDestination=true}, transportProviderName=kafkaTransportProvider, destination={partitions=1, connectionString=kafka://devenv:9093/T1}, name=first-mirroring-stream, connectorName=kafkaMirroringConnector, source={connectionString=kafka://devenv:9094/T1}} (com.linkedin.datastream.server.dms.DatastreamResources) BYOT is not allowed
BYOT - bring your own topic (Использование собственных имен топиков)
Отключаем проверку BYOT:
Где: datastream-kafka-connector/src/main/java/com/linkedin/datastream/connectors/kafka/mirrormaker/KafkaMirrorMakerConnector.java
Комментируем строки:
// verify that BYOT is not used
// if (DatastreamUtils.isUserManagedDestination(stream)) {
// throw new DatastreamValidationException(
// String.format("BYOT is not allowed for connector %s. Datastream: %s", stream.getConnectorName(), stream));
//}Компилируем приложение, подробнее – тут.
./gradlew clean build -x test && ./gradlew releaseTarGz
Запускаем приложение и пробуем:
brooklin-rest-client.sh -o CREATE -u http://localhost:32311/ -n first-mirroring-stream -s "kafka://devenv:9094/T1" -d "kafka://devenv:9093/T2" -dp 1 -c kafkaMirroringConnector -t kafkaTransportProvider -m '{"owner":"test-user","system.reuseExistingDestination":"false"}' Всё хорошо:
{
"Status": "READY", - статус задачи
"metadata": {
"owner": "test-user", - владелец задачи
"system.destination.KafkaBrokers": "devenv:9093",
"system.reuseExistingDestination": "false",
"system.creation.ms": "1677886117163",
"group.id": "first-mirroring-stream", - консьюмер группа
"system.taskPrefix": "first-mirroring-stream",
"system.IsConnectorManagedDestination": "true",
"datastreamUUID": "70737cd3-cdc7-440e-9e8c-70851710feb7",
"system.IsUserManagedDestination": "true"
},
"transportProviderName": "kafkaTransportProvider", - транспортный провайдер
"destination": {
"connectionString": "kafka://devenv:9093/T2" – plaintext, топик destination
},
"name": "first-mirroring-stream", - название datastrema
"connectorName": "kafkaMirroringConnector", - название коннектора
"source": {
"connectionString": "kafka://devenv:9094/T1" – plaintext, топик source
}
}
Вернёмся к постановке задачи — требуется организовать зеркалирование трафика в любом направлении.
Пишем конфигурацию сервера применительно к Kafka:
brooklin.server.coordinator— параметры настройки серверной части (ноды);
brooklin.server.connectorNames — список настроенных подключений (consumers);
brooklin.server.transportProviderNames — список настроенных подключений (producers);
brooklin.server.connector — параметры настройки consumer;
brooklin.server.transportProvider — параметры настройки producer;
ssl.keystore.type — тип хранилища JKS;
bootstrap.servers — указать доступные сервер(а) для подключений. При запуске приложения производится проверка их доступности.
Так как в основе проекта лежит Kafka Mirror, можно указывать привычные настройки.
При необходимости можно настраивать и другие методы подключения SASL Plaintext, SASL SSL.
В приведённом примере у нас получится четыре варианта консьюмеров dev_plaintext,stg_plaintext,dev_ssl,stg_ssl и четыре конфигурации продюсеров dev_plaintext,stg_plaintext,dev_ssl,stg_ssl, которые мы можем комбинировать в любых вариациях подключения (consumer/producer) для любой задачи.
######################### Server Basics ##########################
brooklin.server.coordinator.cluster=brooklin
brooklin.server.coordinator.zkAddress=bmmzkp1:2181,bmmzkp2:2181,bmmzkp3:2181
brooklin.server.httpPort=32311
brooklin.server.connectorNames=dev_plaintext,stg_plaintext,dev_ssl,stg_ssl
brooklin.server.transportProviderNames=dev_plaintext,stg_plaintext,dev_ssl,stg_ssl
############################# dev_plaintext #############################
brooklin.server.connector.dev_plaintext.factoryClassName=com.linkedin.datastream.connectors.kafka.mirrormaker.KafkaMirrorMakerConnectorFactory
brooklin.server.connector.dev_plaintext.assignmentStrategyFactory=com.linkedin.datastream.server.assignment.BroadcastStrategyFactory
brooklin.server.transportProvider.dev_plaintext.factoryClassName=com.linkedin.datastream.kafka.KafkaTransportProviderAdminFactory
brooklin.server.transportProvider.dev_plaintext.bootstrap.servers=devkafkabroker1:9092
brooklin.server.transportProvider.dev_plaintext.client.id=dev_plaintext-producer
############################# stg_plaintext #############################
brooklin.server.connector.stg_plaintext.factoryClassName=com.linkedin.datastream.connectors.kafka.mirrormaker.KafkaMirrorMakerConnectorFactory
brooklin.server.connector.stg_plaintext.assignmentStrategyFactory=com.linkedin.datastream.server.assignment.BroadcastStrategyFactory
brooklin.server.transportProvider.stg_plaintext.factoryClassName=com.linkedin.datastream.kafka.KafkaTransportProviderAdminFactory
brooklin.server.transportProvider.stg_plaintext.bootstrap.servers=stgkafkabroker1:9092
brooklin.server.transportProvider.stg_plaintext.client.id=stg_plaintext-producer
############################# dev_ssl #############################
brooklin.server.connector.dev_ssl.factoryClassName=com.linkedin.datastream.connectors.kafka.mirrormaker.KafkaMirrorMakerConnectorFactory
brooklin.server.connector.dev_ssl.assignmentStrategyFactory=com.linkedin.datastream.server.assignment.BroadcastStrategyFactory
brooklin.server.connector.dev_ssl.consumer.security.protocol=ssl
brooklin.server.connector.dev_ssl.consumer.ssl.keystore.type=JKS
brooklin.server.connector.dev_ssl.consumer.ssl.truststore.type=JKS
brooklin.server.connector.dev_ssl.consumer.ssl.keystore.location=/opt/brooklin/config/dev_ssl.keystore.jks
brooklin.server.connector.dev_ssl.consumer.ssl.keystore.password=password
brooklin.server.connector.dev_ssl.consumer.ssl.truststore.location=/opt/brooklin/config/dev_ssl.keystore.jks
brooklin.server.connector.dev_ssl.consumer.ssl.truststore.password=password
brooklin.server.transportProvider.dev_ssl.factoryClassName=com.linkedin.datastream.kafka.KafkaTransportProviderAdminFactory
brooklin.server.transportProvider.dev_ssl.bootstrap.servers= devkafkabroker1:9093
brooklin.server.transportProvider.dev_ssl.client.id=dev_ssl-producer
brooklin.server.transportProvider.dev_ssl.security.protocol=ssl
brooklin.server.transportProvider.dev_ssl.ssl.keystore.type=JKS
brooklin.server.transportProvider.dev_ssl.ssl.truststore.type=JKS
brooklin.server.transportProvider.dev_ssl.ssl.keystore.location=/opt/brooklin/config/dev_ssl.keystore.jks
brooklin.server.transportProvider.dev_ssl.ssl.keystore.password=password
brooklin.server.transportProvider.dev_ssl.ssl.truststore.location=/opt/brooklin/config/dev_ssl.keystore.jks
brooklin.server.transportProvider.dev_ssl.ssl.truststore.password=password
############################# stg_ssl #############################
brooklin.server.connector.stg_ssl.factoryClassName=com.linkedin.datastream.connectors.kafka.mirrormaker.KafkaMirrorMakerConnectorFactory
brooklin.server.connector.stg_ssl.assignmentStrategyFactory=com.linkedin.datastream.server.assignment.BroadcastStrategyFactory
brooklin.server.connector.stg_ssl.consumer.security.protocol=ssl
brooklin.server.connector.stg_ssl.consumer.ssl.keystore.type=JKS
brooklin.server.connector.stg_ssl.consumer.ssl.truststore.type=JKS
brooklin.server.connector.stg_ssl.consumer.ssl.keystore.location=/opt/brooklin/config/stg_ssl.keystore.jks
brooklin.server.connector.stg_ssl.consumer.ssl.keystore.password=password
brooklin.server.connector.stg_ssl.consumer.ssl.truststore.location=/opt/brooklin/config/stg_ssl.keystore.jks
brooklin.server.connector.stg_ssl.consumer.ssl.truststore.password=password
#brooklin.server.connector.stg_ssl.consumer.ssl.key.password=
brooklin.server.transportProvider.stg_ssl.factoryClassName=com.linkedin.datastream.kafka.KafkaTransportProviderAdminFactory
brooklin.server.transportProvider.stg_ssl.bootstrap.servers=s stgkafkabroker1:9093
brooklin.server.transportProvider.stg_ssl.client.id=stg_ssl-producer
brooklin.server.transportProvider.stg_ssl.security.protocol=ssl
brooklin.server.transportProvider.stg_ssl.ssl.keystore.type=JKS
brooklin.server.transportProvider.stg_ssl.ssl.truststore.type=JKS
brooklin.server.transportProvider.stg_ssl.ssl.keystore.location=/opt/brooklin/config/stg_ssl.keystore.jks
brooklin.server.transportProvider.stg_ssl.ssl.keystore.password=password
brooklin.server.transportProvider.stg_ssl.ssl.truststore.location=/opt/brooklin/config/stg_ssl.keystore.jks
brooklin.server.transportProvider.stg_ssl.ssl.truststore.password=password
Пример создания Datastream с остановкой чтения партиций
Нам остаётся запустить приложение и проверить работоспособность.
# Просмотр datastreams
curl -s http://brooklin:32311/datastream | jq
# Создание datastream
curl -X POST -H "Content-Type: application/json" -d @opendatacollecting http://brooklin:32311/datastream
cat <<EOF > opendatacollecting
{
"metadata": {
"owner": "test-user", - владелец задачи
"group.id": "bmm_opendatacollecting ", - название консьюмер группы
"system.reuseExistingDestination": "false",
"system.IsConnectorManagedDestination": "true",
"system.IsUserManagedDestination": "true",
"system.destination.identityPartitioningEnabled": "false", - точное соответствие данных в партициях при зеркалировании
"system.auto.offset.reset": "latest" – c какого места начинаем читать топик
},
"transportProviderName": "stg_ssl", - название транспортного провайдера
"destination": {
"connectionString": "kafkassl://stgkafkabroker1:9093,stgkafkabroker2:9093/opendatacollecting_product" –тип подключения (SSL),список брокеров, имя топика destination
},
"name": "TICKET-1374", - название datastream
"connectorName": "dev_ssl", - название коннектора
"source": {
"connectionString": "kafkassl://devkafkabroker1:9093,devkafkabroker2:9093/opendatacollecting " – тип подключения (SSL),список брокеров, имя топика source
}
}
EOF
# Пауза datastream
curl -X POST http://brooklin:32311/datastream/TICKET-1374?action=pause
# Запуск datastream
curl -X POST http://brooklin:32311/datastream/TICKET-1374?action=resume
# Удаление datastream
curl -X DELETE http://brooklin:32311/datastream/TICKET-1374
# Пауза консьюма партиций (1-19) from 20 (остается консьюм 0 партиции) задача должна быть в статусе READY
curl -X POST -H "Content-Type: application/json" -d @stopopendatacollecting http:// brooklin:32311/datastream/TICKET-1374?action=pauseSourcePartitions
cat <<EOF > stopopendatacollecting
{
"sourcePartitions" : {
"opendatacollecting ": "1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19"
}
}
EOF
# Запуск консьюма остановленных партиций
curl -X POST -H "Content-Type: application/json" -d http:/brooklin:32311/datastream/TICKET-1374?action=resumeSourcePartitionsПример графиков работы системы
Графики Rate консьюма по типу connector/Datastream
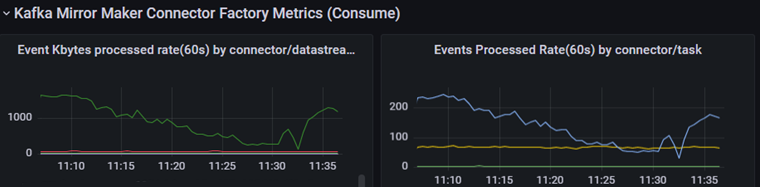
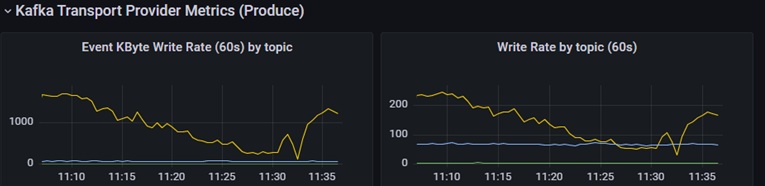
Графики Rate продюса по топикам
Пример файла настроек экспортера jmx_prometheus.yaml
rules:
# Base pod metrics
- pattern: 'java.lang<type=OperatingSystem><>(FreePhysicalMemorySize|TotalPhysicalMemorySize|SystemCpuLoad|ProcessCpuLoad|OpenFileDescriptorCount|AvailableProcessors|TotalStartedThreadCount)'
name: java_lang_OperatingSystem_$1
type: GAUGE
# Consumer metrics by tasks
- pattern: 'kafka.consumer<type=consumer-metrics, client-id=(.+)><>(connection-count|consumer-metadata-request-rate|failed-authentication-rate|incoming-byte-rate|network-io-rate|outgoing-byte-rate|request-rate|response-rate)'
name: kafka_consumer_$2
labels:
clientid: "$1"
# Brooklin metrics
- pattern: metrics<name=Coordinator.isLeader><>Value
name: brooklin_isleader
- pattern: metrics<name=Coordinator.numRebalances><>FiveMinuteRate
name: brooklin_numRebalances_FiveMinuteRate
# devkafka.numDatastreamTasks
- pattern: metrics<name=(\w+).numDatastreamTasks><>Value
name: brooklin_numDatastreamTasks
labels:
connector: "$1"
# Kafka Connector Metrics
# devkafka.KafkaConnectorTask.dev-mirroring-2.numTopics
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).numTopics><>Value
name: brooklin_KafkaConnectorTask_numTopics
labels:
connector: "$1"
task: "$2"
# devkafka.KafkaConnector.numTaskRestarts
- pattern: metrics<name=(\w+).KafkaConnector.numTaskRestarts><>Value
name: brooklin_KafkaConnector_numTaskRestarts
labels:
connector: "$1"
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).errorRate><>(FifteenMinuteRate)
name: brooklin_KafkaConnectorTask_errorrate_FiveMinuteRate
labels:
connector: "$1"
task: "$2"
# devkafka.KafkaConnectorTask.aggregate.numPartitions
# devkafka.KafkaConnectorTask.dev-mirroring-2.numPartitions
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).numPartitions><>Value
name: brooklin_KafkaConnectorTask_numPartitions
labels:
connector: "$1"
task: "$2"
# devkafka.KafkaConnectorTask.aggregate.rebalanceRate Count
# devkafka.KafkaConnectorTask.dev-mirroring-2.rebalanceRate
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).rebalanceRate><>Count
name: brooklin_KafkaConnectorTask_rebalanceRate
labels:
connector: "$1"
task: "$2"
# devkafka.KafkaConnectorTask.aggregate.stuckPartitions
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).stuckPartitions><>Value
name: brooklin_KafkaConnectorTask_stuckPartitions
labels:
connector: "$1"
task: "$2"
# devkafka.KafkaConnectorTask.dev-mirroring-2.eventsByteProcessedRate
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).eventsByteProcessedRate><>Count
name: brooklin_KafkaConnectorTask_eventsByteProcessedRate
labels:
connector: "$1"
task: "$2"
# devkafka.KafkaConnectorTask.dev-mirroring-2.numPolls
- pattern: metrics<name=(\w+).KafkaConnectorTask.(.+).numPolls><>FiveMinuteRate
name: brooklin_KafkaConnectorTask_numPolls_FiveMinuteRate
labels:
connector: "$1"
task: "$2"
# Kafka Mirror Maker Connector metrics
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).numTopics><>Value
name: brooklin_KafkaMirrorMakerConnectorTask_numTopics
labels:
connector: "$1"
task: "$2"
# metrics:name=devkafka.KafkaMirrorMakerConnector.numTaskRestarts
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnector.numTaskRestarts><>Value
name: brooklin_KafkaMirrorMakerConnector_numTaskRestarts
labels:
connector: "$1"
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).errorRate><>(FifteenMinuteRate)
name: brooklin_KafkaMirrorMakerConnectorTask_errorrate_FiveMinuteRate
labels:
connector: "$1"
task: "$2"
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).numPartitions><>Value
name: brooklin_KafkaMirrorMakerConnectorTask_numPartitions
labels:
connector: "$1"
task: "$2"
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).rebalanceRate><>Count
name: brooklin_KafkaMirrorMakerConnectorTask_rebalanceRate
labels:
connector: "$1"
task: "$2"
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).stuckPartitions><>Value
name: brooklin_KafkaMirrorMakerConnectorTask_stuckPartitions
labels:
connector: "$1"
task: "$2"
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).eventsByteProcessedRate><>Count
name: brooklin_KafkaMirrorMakerConnectorTask_eventsByteProcessedRate
labels:
connector: "$1"
task: "$2"
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).numPolls><>FiveMinuteRate
name: brooklin_KafkaMirrorMakerConnectorTask_numPolls_FiveMinuteRate
labels:
connector: "$1"
task: "$2"
# Kafka Mirror Maker Connector metrics
- pattern: metrics<name=(\w+).KafkaMirrorMakerConnectorTask.(.+).eventsProcessedRate><>Count
name: brooklin_KafkaMirrorMakerConnectorTask_eventsProcessedRate
labels:
connector: "$1"
task: "$2"
# Producer metrics
- pattern: metrics<name=EventProducer.(.+).eventProduceRate><>Count
name: brooklin_EventProducer_eventProduceRate
labels:
connector: "$1"
- pattern: metrics<name=EventProducer.(.+).totalEventsProduced><>Count
name: brooklin_EventProducer_totalEventsProduced
labels:
connector: "$1"
# Topic metrics
- pattern: metrics<name=KafkaTransportProvider.(.+).eventByteWriteRate><>Count
name: brooklin_KafkaTransportProvider_eventByteWriteRate
labels:
topic: "$1"
- pattern: metrics<name=KafkaTransportProvider.(.+).eventWriteRate><>Count
name: brooklin_KafkaTransportProvider_eventWriteRate
labels:
topic: "$1"
Какие были проблемы на этапе запуска
Основной сложностью при сборке приложения без доступа к интернету является разрешение зависимостей, которые вам потребуется разместить в локальном Artifactory. Один из коротких путей получения требуемого списка — собрать приложение с доступом к интернету, перенаправив запросы через прокси-сервер или Nginx.
Файлы, в которых потребуется изменить пути репозиториев:
gradle/buildscript.gradle — указать локальный Artifactory;
gradle/wrapper/gradle-wrapper.properties — указать локальный Artifactory;
gradle/maven.gradle — отключить Artifactory publishing.
Выводы
Внедрение Brooklin значительно упростило администрирование задач зеркалирования трафика. Основное преимущество — возможность оперативно направлять данные в любой кластер с изменением имени топика, при необходимости можно уменьшить количество партиций чтения, возможность паузы и возобновления задач.

Итоговая сводная таблица:

* Y — имена топиков совпадают в разных кластерах.
N — имя топика назначения должно быть другим в пределах одного кластера.
** Brooklin в оригинальном варианте не позволяет изменять имя топика назначения.
Y/Y - имя топика назначения должно быть другим в пределах одного кластера.
Планы на будущее
Разработка веб-интерфейса для взаимодействия через API позволит визуализировать и автоматизировать постановку, удаление и учёт задач зеркалирования трафика. Требования к функционалу уже подготовлены.
Ограничение доступа к API планируется организовать посредством Keycloak Gatekeeper для аутентификации запросов пользователей и сервисов в Keycloak.
Комментарии (4)

Legoti4
27.09.2023 10:14А чем не подошел kafka-connect с подключенным к нему MM и дополнительными трансформами?

alecx
27.09.2023 10:14Т.е. Вы наивно выключили проверку, не разобравшись зачем тут она была, не задали вопрос разработчикам в открытом проекте на Github, пошли с этим в HiLoad продакшн и надеетесь что все будет хорошо?
То ли я старею, то ли этот мир несется куда то не туда...
Legoti4
А чем не подошел kafka-connect с подключенным к нему MM и дополнительными трансформами?
mdaff Автор
Привет, мы использовали MM на первых этапах, в соответствии с постановкой задачи мы выбрали централизованное решение для выполнения всех задач в любой комбинации кластеров (подключений к ним) с возможностью горизонтального масштабирования, минимальными затратами на добавление задач зеркалирования или конфигурирования, обеспеченив отказоустойчивость.