
Из каких соображений можно хранить данные в виде ячеистой сети

Во всех организациях, где мне доводилось работать, всегда понимали важность данных. Поэтому я видел, что руководство либо заинтересовано, либо прямо планирует создать платформу нового поколения для обращения с этими данными. Как правило, ставится цель перейти от сильно связанных интерфейсов и вариабельных потоков данных к целостной архитектуре, которая позволяла бы аккуратно связать всю экосистему. Речь идёт о распределённой облачной ячеистой топологии (data mesh), где данные можно группировать в зависимости от их предметной области, трактовать “данные как продукт,” организуя в каждой предметной области конвейерную обработку собственных данных. Такой подход отличается от перекачки данных (data plumbing), практикуемой на традиционных (монолитных) платформах, которые, как правило, отличаются сильной связанностью данных. Из-за этого зачастую замедляется поглощение, хранение, преобразование и потребление данных из централизованного озера или хаба.
Такая смена парадигмы в распределённой архитектуре данных сопряжена с некоторыми нюансами и требует учитывать факторы, которые связаны в основном со зрелостью организации, имеющимися навыками, структурой организации, предрасположенностью к риску, размерами организации и динамикой её развития. С учётом всех этих нюансов и соображений могут использоваться различные варианты ячеистой топологии.
❯ Управляемая ячеистая топология
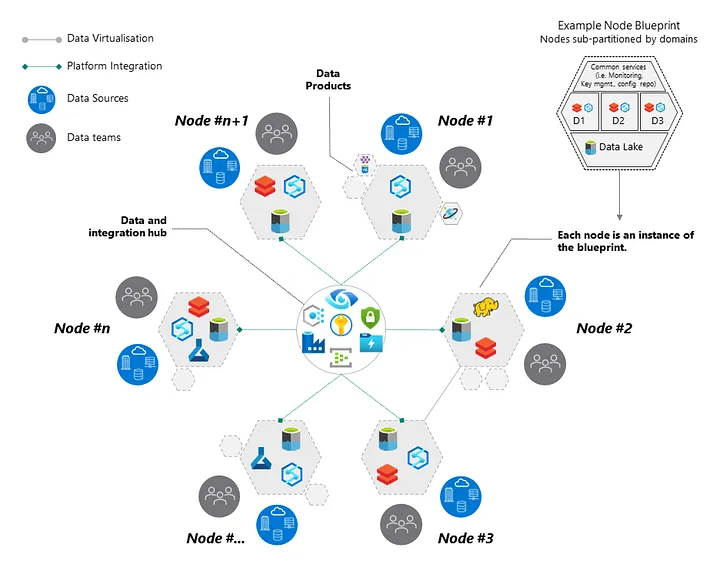
Первый паттерн называется «управляемая ячеистая топология» (governed mesh topology). Такая модель представлена на следующей картинке, и, как видите, различные предметные области данных сгруппированы здесь и представлены в виде узлов. Каждый узел, который можно рассматривать как предметную область, может действовать относительно других предметных областей в качестве поставщика и/или потребителя данных.
Описание
Data Virtualisation // Виртуализация данных
Platform integration // Платформенная интеграция
Data teams // Команды по работе с данными
Data Products // Данные-продукты
Data and Integration hub // Хаб для обработки и интеграции данных
Example Node Blueprint // Примерно так выглядит чертёж узла
Common services… // Общие сервисы – в частности, для мониторинга, управления ключами, конфигурирования, репозиториев
Data Lake // Озеро данных
Each node is… // Каждый узел – это экземпляр, воспроизведённый по чертежу
Node // Узел
Platform integration // Платформенная интеграция
Data teams // Команды по работе с данными
Data Products // Данные-продукты
Data and Integration hub // Хаб для обработки и интеграции данных
Example Node Blueprint // Примерно так выглядит чертёж узла
Common services… // Общие сервисы – в частности, для мониторинга, управления ключами, конфигурирования, репозиториев
Data Lake // Озеро данных
Each node is… // Каждый узел – это экземпляр, воспроизведённый по чертежу
Node // Узел
Рисунок автора Piethein Strengholt
В этой модели и в общепринятой практике экземпляры узлов создаются по чертежам, в которых заключены ключевые возможности, необходимые для извлечения пользы из данных (как то: хранение, мониторинг, управление ключами, ELT (извлечение, загрузка, преобразование), аналитические движки, автоматизация). Каждому узлу позволено использовать то множество технологий из чертежа, которое предпочтительно именно для данного узла и обусловлено теми требованиями, что предъявляются к этому узлу. В зависимости от требований допустимы вариации и существование нескольких версий чертежа – всё это делается, чтобы удовлетворить различные нужды разных предметных областей.
В сердце этой архитектуры представлены все решения, позволяющие организовать и контролировать управление данными. Здесь располагается каталог данных, политики обращения с ними, обязательные требования безопасности, возможности аудита, действующие в масштабах всей сетки, мониторинговые и вспомогательные сервисы для развёртывания и автоматизации. Управляемая сеть отличается от других топологических паттернов, так как обязывает, чтобы все действия по распределению данных маршрутизировались из центрального узла. Так, предметные области данных в рамках этой модели сначала позволяют принять данные продукты, а затем централизованно их распределить.
В этой структуре важно, что все централизованно распределяемые данные подразделяются по предметным областям, и логически они при этом изолируются, а не интегрируются. Перевод данных на язык предметной области происходит только на этапе потребления. То же самое можно сказать и о безопасности данных: модель нулевого доверия наследуется от предметной области, а ее соблюдение жестко навязывается при помощи метаданных.

Описание
Data Domains // Предметные области данных
Platform Services // Сервисы платформ
Data management // Управление данными
The data mesh…
Platform Services // Сервисы платформ
Data management // Управление данными
The data mesh…
- The data mesh: ячеистая топология интеллектуально распределяет данные-продукты по предметным областям. Хранилища данных, предназначенных для считывания, совместно используют вычислительные ресурсы. Так удаётся сократить расходы, решить проблемы с интероперабельностью и лучше справляться на уровне потребителей данных с проблемами, касающимися вариативных по времени и энергозависимых аспектов хранения.
- Data domains: в каждой из предметных областей с данными эксплуатируются собственные приложения или аналитические платформы, но в то же время соблюдаются общепринятые политики и стандарты.
- The central platform services: в рамках сервисов центральной платформы определяются те чертежи, в которых заключена базовая информация о безопасности, политиках, возможностях и стандартах.
- The central data management hub: в центральном хабе управления данными расположены каталог данных, политики обращения с ними, обязательные требования безопасности, возможности аудита, действующие в масштабах всей сетки, мониторинговые и вспомогательные сервисы для развёртывания и автоматизации, обнаружения данных, регистрации метаданных и т. п.
Рисунок автора Piethein Strengholt
Плюс подхода с управляемой ячеистой топологией в том, что такая топология лучше помогает справляться с проблемами, касающимися вариативных по времени и энергозависимых аспектов хранения, особенно актуальными для крупных потребителей данных. Таким образом, в предметной области можно как бы «слетать в прошлое», а сами «доставщики данных» управляются с привязкой к временным периодам, которые централизованно оркеструются. В то же время, если с качеством данных возникнут проблемы, то любое распространение данных можно заблокировать – например, если перекрестные идентификаторы из разных предметных областей не совпадают. Ещё одна выгода в том, что в такой конфигурации более эффективно организуется совместное использование (централизованных) вычислительных ресурсов. Для масштабируемости и работы с областями-потребителями, можно, например, организовать «сервис обработки архивных данных». Это будет централизованный сервис, оснащённый небольшим вычислительным аппаратом, доступный во всех предметных областях. С его помощью из каждой области можно будет планировать заготовку архивных данных, например, по дате соглашений о доставке, а также задавать область применения («ежедневно», «еженедельно», «ежемесячно»). При необходимости можно будет задавать и временные промежутки, атрибуты, наборы данных. При применении короткоживущих облачных обрабатывающих инстансов такая стратегия получается очень экономной. Наконец, вы избавляетесь сразу от огромной доли сетевого трафика. Если данные от всех предметных областей будут распространяться по принципу «точка-точка», то частные каналы и сервисные конечные точки будут лавинообразно умножаться. Эта проблема решается распределением данных из «центрального кэша».
Конечно, за такое централизованное распределение и повышенный контроль приходится платить – увеличиваются издержки на управление. Центральная платформа и обслуживающая её команда могут стать как раз тем узким местом, из-за которого вам придётся умерить амбиции. Здесь как раз кстати мы переходим к следующему паттерну.
❯ Гармонизированная ячеистая топология
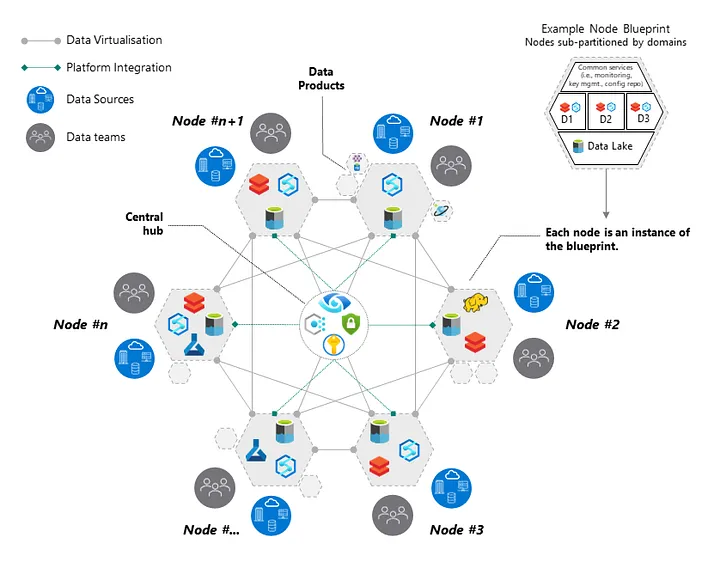
Второй паттерн – это гармонизированная ячеистая топология (harmonized mesh topology), автором этого термина является Джон Мэллиндер. В такой модели узлы действуют в основном самостоятельно. Данные распределяются по принципу точка-точка, но в то же время управляются. Вот как, например, это может работать на практике: сначала узел централизованно публикует свои метаданные. Таким образом остальные предметные области узнают, какие данные доступны на каких узлах – эту информацию можно взять из центральных репозиториев метаданных. Далее, после согласования контракта данных, а соответствующие предметные области предоставили нужные защищенные конечные точки, можно приступать к распределению данных по предметным областям. Центральный хаб данных в гармонизированной ячеистой топологии всё контролирует. Так мы позволяем каждой предметной области работать на собственной платформе, в то же время подчиняясь общим политикам и стандартам.
Описание
Data Virtualisation // Виртуализация данных
Platform integration // Платформенная интеграция
Data teams // Команды по работе с данными
Data Products // Данные-продукты
Central hub // Центральный хаб
Example Node Blueprint // Примерно так выглядит чертёж узла
Common services… // Общие сервисы – в частности, для мониторинга, управления ключами, конфигурирования, репозиториев
Data Lake // Озеро данных
Each node is… // Каждый узел – это экземпляр, воспроизведённый по чертежу
Node // Узел
Platform integration // Платформенная интеграция
Data teams // Команды по работе с данными
Data Products // Данные-продукты
Central hub // Центральный хаб
Example Node Blueprint // Примерно так выглядит чертёж узла
Common services… // Общие сервисы – в частности, для мониторинга, управления ключами, конфигурирования, репозиториев
Data Lake // Озеро данных
Each node is… // Каждый узел – это экземпляр, воспроизведённый по чертежу
Node // Узел
Рисунок автора Piethein Strengholt
Достоинства данной модели заключаются в повышенной гибкости и автономности в разных предметных областях. Недостаток модели – в увеличенном сетевом трафике и не столь эффективном использовании ресурсов, поскольку вся модель является федеративной. Кроме того, для работы с ней требуются более зрелые команды и отлаженная самообслуживаемая (облачная) инфраструктура, уже на ходу.
❯ Сильно федеративная ячеистая топология
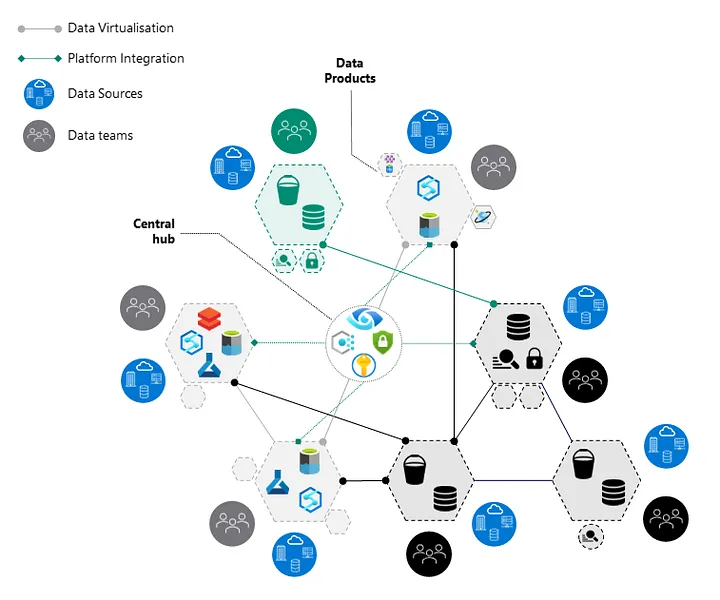
Последний подход можно назвать «сильно федеративной сеткой». В этой модели для предметных областей характерна сильная автономность, поэтому в каждой области может быть реализован собственный стек технологий, зависящий от окружения. Так приобретается огромная гибкость, важная для специализированных областей, областей, где продукт требуется быстро вывести на рынок, а также для экспериментов.
Описание
Data Virtualisation // Виртуализация данных
Platform integration // Платформенная интеграция
Data teams // Команды по работе с данными
Data sources // Источники данных
Data Products // Данные-продукты
Central hub // Центральный хаб
Platform integration // Платформенная интеграция
Data teams // Команды по работе с данными
Data sources // Источники данных
Data Products // Данные-продукты
Central hub // Центральный хаб
Рисунок автора Piethein Strengholt
В данном случае даже можно попытаться выстроить смешанную модель управления: распределение идёт через хабы, или по принципу «точка-точка», или в сочетании этих механизмов. В сущности, модель меняется, и благодаря этому достигается гибкость при работе с предметными областями. В каждой области можно выбрать, собрать и запустить, к примеру, любую базу данных или интеграционную платформу. При таком федеративном подходе все предметные области должны увязывать применяемые в них решения с центральным управляющим аппаратом, который централизованно регулируется. Такой подход может быть особенно полезен в областях, сравнительно слабо связанных с основным бизнес-объектом. Даже можно попробовать воплотить гибридную модель эксплуатации: например, центральная команда предоставляет те возможности, которые используются чаще всего, а команды из конкретных предметных областей отвечают за более специализированные возможности. При обеспечении всей работы метаданными, вы сохраняете необходимый уровень контроля и проникновения в тему.
Конечно, такая гибкость имеет свою цену. Станет сложнее обеспечивать сквозной контроль событий в системе, потребуется выстраивать дополнительные платформонезависимые абстракции, которые позволяли бы соблюдать ваши инфраструктурные стандарты.
❯ Качественный рост
Непросто выйти на такой уровень зрелости, где распределение данных и управление ими идёт гладко. Здесь придётся адаптировать корпоративную культуру, инвестировать в развитие централизованных возможностей и выбирать. Ни одно интеграционное решение, ни одна платформа не подойдёт на все случаи жизни. Реализация всех этих возможностей потребует стандартизации, выработки наилучших практик, распространять знания и опыт для поддержки команд разработчиков и прочих технарей. Кроме того, такие централизованные возможности подразумевают, что отдельные команды откажутся от права самостоятельно решать, какие паттерны интеграции и какой инструментарий им использовать. Это может спровоцировать отпор, с чем вам также придётся справляться. Наконец, при вписывании данных в такой ландшафт потребуется прагматичный подход к модернизации, а уйти от сильной связанности тяжело. Начиная с простых и небольших потоков данных, а затем постепенно наращивая их, можно донести до пользователей и специалистов предметной области достоинства новой архитектуры, а в конечном счёте – и конкурентные преимущества, которые в результате приобретёт организация.
Любую распределённую архитектуру требуется рассматривать в масштабах всего предприятия, иначе всего её потенциала не раскрыть. Команды, которые станут сами развёртывать сервисы для работы с данными и просто заменять одни разрозненные данные другими, рискуют столкнуться с «разрастанием данных» (data sprawl). Качество данных, их согласованность и возможность многократного использования данных, а также сильное управление – необходимые условия для роста.
Те топологии, которые мы рассмотрели в этом посте, помогут вам управлять крупномасштабными данными. Если хотите изучить эту тему подробнее, то рекомендую вам посмотреть книгу Data Management at Scale.
