

Может, кому-то из вас покажется это удивительным, но текст, аналогичный тому, что вы видите на картинке (а это бирманский язык) тоже можно распознать. Некоторое время назад по интернету ходил забавный комикс про различие азиатских языков, но он слишком неприличный, чтобы публиковать его в корпоративном блоге :) О том, зачем нам понадобилось распознавать бирманский и с какими проблемами пришлось при этом столкнуться, – под катом.
Республика Мьянма (ранее – Бирма) – государство в Юго-Восточной Азии. В 1962-2010 гг. в стране действовала военная диктатура, а в последние 5 лет Мьянма стала открываться для внешнего мира – активизировалось торговое и культурное сотрудничество.

Понятно, что в таких условиях у соседей появилось много возможностей для того, чтобы мониторить ситуацию в стране – мало ли что.
В какой-то момент один из наших партнеров (а работаем мы в Юго-Восточной Азии много и активно – и в основном через партнёров) принёс нам проект – от нас требовалось сделать распознавание символов (OCR) бирманского языка. Конечный заказчик планировал делать мониторинг бирманских печатных СМИ – сначала распознавать, а потом переводить автоматическим переводчиком на английский язык.
В бирманском есть много диалектов, при этом существует некоторый набор букв, который используется в официальных сообщениях, в прессе и т.п. Он составляет примерно 30% от всех букв, используемых в регионах, в него входят 33 согласных буквы и 12 дополнительных знаков. Распознавать нам предстояло картинки, на которых были тексты, напечатанные именно этим набором букв в самом популярном начертании (шрифт Myanmar 3), кегль – не меньше 10. Изображения могли быть серыми, чёрно-белыми или цветными, разрешение – не меньше 300 dpi. Например, такие:

На первом этапе нам нужно было показать точность распознавания в 75%, на втором – не менее 94%.
Людей, владеющих бирманским, в нашей разношерстной лингвистической компании не нашлось, поэтому разработчикам, которым достался проект, пришлось знакомиться с языком самим и с нуля.
Бирманское письмо – слоговое, в основе его лежит силлабический алфавит — каждая согласная буква «по умолчанию» произносится вместе с гласным звуком [a]. Другие гласные звуки обозначаются с помощью отдельных букв или вспомогательных знаков над, под, перед, после или даже вокруг согласной буквы (примеры см. в таблице ниже).
Кстати, оказалось, что бирманские буквы такие круглые вот почему – когда бирманское письмо зарождалось, писали на пальмовых листьях, и начертание прямых линий повредило бы листья.
Бирманский язык — тоновый. Тон – это знак, который указывает, как произносить слог – и от этого зависит значение слога. Выделяют три основных тона (высокий, низкий и скрипучий), а также еще два других тона (взрывной и пониженный). Тон обозначается на письме с помощью специальных сочетаний символов. В таблице показано, как пишутся сочетания согласной буквы
 с некоторыми гласными в каждом из трёх основных тонов.
с некоторыми гласными в каждом из трёх основных тонов.
То есть бирманский язык – язык с двойной диакритикой (дополнительные символы могут располагаться одновременно как под, так и над основным). Это, как мы увидим дальше, имеет большое значение при распознавании.
Кроме того, некоторые согласные в определенных сочетаниях могут образовывать лигатуры.

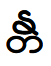
Желающим углубиться в тонкости бирманского рекомендуем довольно подробные статьи в википедии про бирманский язык и бирманское письмо, а мы на этом остановимся и покажем, как эти особенности создавали нам дополнительные трудности в «подключении» бирманского в нашу технологию OCR.
Напомним вкратце, как вообще происходит распознавание. Мы получаем картинку с текстом, обрабатываем её (исправляем искажения, переводим в ч/б), затем на странице определяются блоки (заголовки, текст, сноски, картинки, таблицы и т.д.), потом текстовые блоки разбираем на отдельные строчки, строчки – на слова, слова – на буквы, буквы распознаём, дальше по цепочке собираем все обратно в текст страницы. Поскольку в обработке изображений и в разбиении на блоки в случае с бирманским языком не было ничего специального, начнём рассказывать сразу с деления на строки.
Из-за двойной диакритики на наших текстах плохо выделялись короткие строки – и вот почему. В наших алгоритмах есть дополнительные характеристики строчек, одна из них – базовая линия, на которой находятся основные символы. Базовую линию нужно выделять, чтобы правильно строить гипотезы относительно тех или иных символов и, соответственно, лучше их распознавать.
Для выделения базовой линии мы пользуемся статистикой: анализируем гистрограммы (проекции чёрных точек на вертикаль), ищем пики. На гистограммах европейских языков хорошо видны 3 выраженных пика, которые образуют основу строки (базовую линию и высоту строчных букв):

В бирманском языке большое количество символов, выходящих за границы основной части строки, вносят дополнительные значимые пики в гистограмму. Поэтому алгоритмы, настроенные на распознавание европейских языков, не совсем правильно определяли основные параметры строки.
В первых двух строках базовая линия найдена правильно, в третьей – неправильно:

Чтобы правильно определять строки в бирманском языке, пришлось дополнительно настраивать алгоритм.
После того как выделены строки, мы начинаем искать в этих строках промежутки между словами и знаками. Так же строится гистограмма, только горизонтальная, ищутся промежутки и определяется, что из них является пробелами, а что — расстоянием между символами. С определением пробелов в бирманском проблем практически не было – их в этой письменности немного, но есть (в отличие от того же тайского, где пробелов почти нет – да, мы умеем распознавать тайский, а также около 200 других языков).
После определения пробелов начинаем работать с фрагментами текста («словами» — хотя это слово не очень применимо к бирманскому, в нем пробелами разделяются части предложения), начинаем распознавать каждый фрагмент отдельно. Фрагменты надо разделить на символы. На гистограмме снова ищем пики и впадины (впадины – это возможные точки деления). Некоторые точки деления более-менее очевидны, для проверки других применяются специальные эвристики. В европейских языках гистограмма выглядит примерно так:

Из-за того что в бирманском много полукруглых символов, мы получаем много «лишних» пиков и впадин, это затрудняет выделение промежутков, но и с этой проблемой мы справились.

Более подробно общая теория выделения строк и символов описана в этом посте.
После определения точек деления каждый символ начинаем распознавать отдельно. В статье мы употребляем слово «символы», потому что оно всем понятно и известно. Но это сделано только для упрощения текста, на самом деле мы распознаем не символы, а графемы. Графема – это конкретный способ графического представления символа. Отношение между символами и графемами достаточно сложное – в европейских языках одной графеме может соответствовать несколько символов (маленькая «с» и большая «С» в латинице и кириллице – это все одна графема), а одному символу может соответствовать несколько графем (буква «a» в разных шрифтах может быть обозначена разными графемами).

Стандартного списка графем не существует, мы его составляем сами и для каждой графемы задан список символов, которым она может соответствовать. Преобразование из графем в символы происходит уже после распознавания символов на этапе генерации вариантов распознавания слов.
В бирманском, как мы уже упоминали, очень много диакритики, и большая часть вспомогательных символов при написании сливается с основным символом, образуя лигатуры:

В общих случаях, если мы распознаём символ с диакритикой, и диакритика на изображении отделена от основного символа, у нас работает такой алгоритм: распознаем сначала основной символ, потом диакритику, потом соединяем и получаем одну графему. Если мы имеем дело с лигатурой, то мы сразу пробуем распознать её целиком. Распознавание происходит путем сравнения символа с эталонами и выбора наиболее подходящих (похожих вариантов) – подробнее об этом мы писали здесь. Поскольку в бирманском очень много лигатур, мы должны были обучить наши алгоритмы гораздо большему (чем в среднем для нового языка) количеству новых графем (добавлено порядка 3500 графем).
Когда мы распознали графему (то есть поняли, что наше сочетание символов – это она), мы должны оттранслировать её в виде символов юникода (чтобы потом собрать символы в слова, слова в текст и так далее). В европейских языках здесь всё просто – распознаём символы по порядку, один за другим, и в таком же порядке «отдаём» обратно. С лигатурами в бирманском языке дело обстоит гораздо сложнее.
Есть определенный порядок написания букв, который нужно соблюдать при работе с текстовыми редакторами, чтобы Windows правильно преобразовывал в лигатуры (да и просто в сложные «слова») то, что пользователь напечатал. Некоторые символы должны набираться (печататься) в конце слога – тогда Windows поставит их в начало слога и слог будет написан правильно.
Например, чтобы в текстовом редакторе получить вот такое слово:

надо набрать следующую последовательность символов

тогда Windows правильно отобразит слово. Если вручную написать этот символ

первым, получим ошибку (ошибки выделены пунктирной линией):
Чтобы собрать вот такую лигатуру
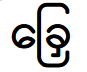
надо обязательно соблюдать следующий порядок символов:
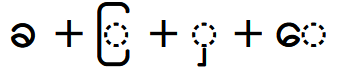
В бирманском языке для слов, пришедших из языка пали, принято двухуровневое написание согласных
И таких случаев в бирманском очень много.
Соответственно, эти же правила должны соблюдаться при трансляции распознанных символов, чтобы Windows правильно их понял и автоматически собрал, – и этим правилам мы должны были обучить наши алгоритмы.
Для проверки соблюдения этих правил нашей технологии есть посткоррекция. Работает она так: после того как мы все распознали, мы идем по тексту и проверяем порядок символов в соответствии с правилами языка. Как мы уже писали выше, бирманский – очень хорошо структурированный язык, и правил в нём достаточно.
Вот, собственно, и все сюрпризы, которые нам преподнёс бирманский язык. Всю работу мы проделали за 4 месяца и достигли в итоге точности распознавания в 97% (против 94%, которые мы обещали заказчику). В перспективе, скорее всего, добавим описание других шрифтов.
Комментарии (21)

RZimin
01.12.2015 13:20+1Молодцы, но вот гложет вопрос. Не могу не спросить. Сколько ненормативных выражений выучила проектная команда? :)

luciana
01.12.2015 13:37+11Если честно, команда такая интеллигентная, что я стесняюсь спрашивать :)
Вот вам в качестве компенсации тот самый комикс с переводом на русский. Он тоже хорош


madkite
01.12.2015 17:50+4С японским не так всё просто. Японцы то для корней слов юзают кандзи — это такая же «хитроумная хрень, которая атакует здания» как у китайцев, у них же и позаимствованная.



safari2012
01.12.2015 14:49-1монголы вроде с 1941 года и до сих пор кириллицу используют…
madkite
01.12.2015 16:36Во Внутренней Монголии (автономный край в составе Китая) до сих пор вроде продолжают использовать старомонгольское письмо.

tyomitch
02.12.2015 00:48Теперь уже и в независимой Монголии переходят с кириллицы на (старо)монгольское письмо.
Вот, например, монгольские тугрики выпуска 2002 г.: ни буквы кириллицей.

safari2012
02.12.2015 14:29+2Да, действительно, старомонгольский алфавит стали плавно возвращать.
Но вы «наполовину» ошибаетесь, вся обратная сторона этой банкноты на кириллице.



TheTony
02.12.2015 09:05+2Спасибо за материал!
Вот стало интересно: а можно ли узнать частоту появления лигатур в языке и при формировании базовой линии модифицировать ее положение исходя из просчитанных значений (текущей базовой линии) + потенциальных появлений лигатур в тексте? Скорректировав таким образом изначальную базовую линию…luciana
02.12.2015 11:08+2Универсальный механизм коррекции базовой линии в зависимости от количества лигатур ( если понимать под лигатурой основной символ + диакритика ) настроить довольно проблематично, потому, что часть лигатуры, которая располагается ниже базовой линии бывает очень разная по форме и размерам. Например, для вьетнамского языка это только точка под основным символом и корректировать базовую линию для вьетнамского не надо. Проще настроить механизм для каждого языка отдельно.

stalkerg
08.12.2015 11:48+1Большое спасибо, очень интересно!
Как то раз мне пришлось немного углубится в бирманский т.к. преподавал у группы студентов от туда.
Главная трудность была, что они не понимали русскую интонацию вопросительного приложения, по этому я стал разбираться как обозначается вопросительные приложения на бирманском. Нашёл одну частичку, которую произносил в конце приложения и вроде все сразу всё понимали.
IamKarlson
Очень плохо так делать: заинтересовать картинкой и не показать
poxu
Я зашёл в топик ради этого комментария!
luciana
Я верила в читателей и не ошиблась :)