
В жизни каждого инженера‑фронтендера наступает момент, когда осознаёшь: далее не обойтись без кэширования данных из API. Всё может начаться с самых невинных вещей: сохраняем предыдущую страницу с данными, чтобы кнопка «Назад» срабатывала мгновенно; реализуем простенькую логику отмены действия или обеспечиваем слияние нескольких состояний от различных запросов к API. Но все мы знаем, чем такое кончается. Один за другим возникают запросы на новые фичи, и вскоре мы уже не покладая рук реализуем кэши данных, индексы для работы вручную, оптимистические мутации и рекурсивную инвалидацию кэша.
Эти фичи явственно смахивают на внутренние механизмы баз данных. Действительно, в любом достаточно сложном клиентском приложении программисту непременно придётся реализовывать такое множество фич для управления данными, что эта работа будет напоминать построение предметно‑ориентированной базы данных. Такая дополнительная сложность удваивается в каждом проекте, над которым мы работаем, поэтому приходится тратить время на решение бизнес‑проблем, а радовать пользователя — уже как успеем.
Поэтому сегодня предлагаю вам составить мне компанию — и мы вместе рассмотрим распространённые паттерны работы с данными приложений, а также разберёмся, как они соотносятся с фичами баз данных. Далее мы рассмотрим решения, которые могли бы стать альтернативами этим паттернам — например, как сделать в клиентской части оптимизированный стек базы данных, который позволил бы нам сосредоточиться на разработке приложения, а не на мелкой возне с данными.
Добро пожаловать в мир эпизодического программирования баз данных.
Простенький кэш
Наше путешествие начнётся максимально скучным образом. Отправляем запрос от API на сервер и сохраняем его в локальной переменной. Потребность поступить так может возникнуть по целому ряду причин, но вот вам хороший пример: допустим, нужно как‑то обогнуть декларативные механизмы повторного отображения. Во многих современных веб‑приложениях используются декларативные фреймворки, например React, которые в силу самого своего внутреннего устройства по три раза отображают одни и те же рисунки, пока пользователь работает со страницей. Конечно же, нам не хочется выполнять запрос к API при каждой такой операции рендеринга — поэтому забрасываем эти данные в переменную. Вот пример с использованием React‑хуков:
const Newsfeed = () => {
const [{ loading, entries, error }, setEntries] = useState({
loading: true,
entries: [],
error: null,
});
useEffect(() => {
NewsfeedAPI.getAll()
.then((entries) => setEntries({entries }))
.catch((error) => setEntries({ error }));
}, []);
// отобразить загрузку, записи и состояния ошибок
return <div>...</div>;
};Для большей ясности этот пример упрощён. Лучше так не делайте, а пользуйтесь проверенными в боях библиотеками API, либо продолжайте штудировать источники о базах данных, оптимизированных для работы с клиентской частью! ????
В данном примере видим простейший кэш запросов к API, где запросы сохраняются при помощи хуков состояния, предоставляемых в React. Как только запрос к API завершается, мы кэшируем его результат (или ошибку), до тех пор, пока компонент не будет удалён и повторно добавлен в дерево.
Естественно, вскоре нам захочется добавить дополнительные возможности. Как правило, следующий шаг таков: кэш «поднимают» на вышестоящий уровень либо вообще выводят за пределы дерева UI.
Один из примеров такого подхода связан с использованием Redux, популярной библиотеки управления состоянием для React. Сущность Redux такова: при помощи этого инструмента пользователи могут консолидировать состояние и постепенно координировать атомарные изменения, вносимые в это состояние. Но со временем Redux развился в целую экосистему инструментов и паттернов, при помощи которых удобно управлять кэшированием данных API. Redux (или схожие инструменты) используются таким образом для централизации логики кэширования, координации обновлений и, что наиболее важно, чтобы различные компоненты могли совместно использовать различные результаты, хранящиеся в кэше.
По мере того, как наш скромный уровень кэширования усложняется и усложняется, он начинает менять облик: теперь это централизованная система хранения данных, координирующая работу рендерингового движка и действий пользователя, всё это — для эффективного выпаса данных. Можно сказать, что эта система начинает чем‑то напоминать базу данных…
Но это же безумие. Давайте лучше поговорим об индексах.
Как ускорить работу при помощи индексов
Когда около двадцати лет назад я впервые взялся за разработку веб‑приложений, я сразу же прикипел к подлинной красоте структурированных данных. Если данные в приложении организованы определённым образом, то само приложение может обходиться меньшим объёмом работы, в результате чего пользователю становится гораздо удобнее с ним обращаться. На тот момент мои взаимодействия с информацией, хранившейся в серверной части, абстрагировались при помощи баз данных. Именно базы данных позволяли относиться к индексам как к какому‑то волшебному порошку, которым мы спрыскиваем запросы, чтобы они летали. Так и было до тех пор, пока я не поступил на работу в SingleStore (бывшая MemSQL); там я обнаружил, как же сильно оптимизация данных в клиентской части напоминает работу с внутренностями обычной базы данных. Здесь отметим, что индексы в базах данных устроены очень сложно, и работа с ними не ограничивается всего лишь «хранением данных в каждой по‑своему». В индексе также собирается статистика, версионируются данные, происходит управление транзакциями, блокировками и многими другими вещами, чтобы обеспечить корректность и правильную интероперабельность с оптимизацией запросов. Так что, да, немного похоже на волшебный порошок.
Один из вариантов оптимизации, оказывающийся довольно результативным в клиентской части — сохранить взятые с сервера кэшированные данные в объекте, ключом которого служит ID. Такая ситуация зачастую возникает в силу самой структуры, которую имеет базовый API. Например, если в приложении используется REST API, нам часто приходится считывать данные целыми пакетами, а затем по мере необходимости обогащать конкретные объекты. Для этого требуется постоянное слияние результатов API в кэш, а такие операции пойдут проще, если объекты будут храниться по ID. Давайте рассмотрим кэш такого рода на примере:
const CACHE = {
"f3ac87": {
id: "f3ac87",
author: "@carlsverre",
title: "stop building databases",
description: "There comes a time in every software engineers life...",
createdAt: new Date(),
},
/*
"a281f0": { ... },
"2f9f6c": { ... },
...
*/
};
// извлечение по ID
console.log(CACHE["f3ac87"]);
// обновление по ID
CACHE["f3ac87"].title = "everyone is a database programmer";В вышеприведённом примере мы индексируем записи по ID в простом объекте JavaScript. Поскольку данные имеют такой «контур», мы оптимизируем систему для создания, чтения, обновления и удаления записей по их ID. Но каждая операция, при которой требуется просматривать множество данных (например фильтрация), означает, что проверить нужно каждую запись. Давайте улучшим эту структуру данных, чтобы можно было быстро подыскивать записи по дате:
const truncateTime = (date) => {
const clone = new Date(date);
clone.setHours(0, 0, 0, 0);
return clone;
};
const ENTRIES_BY_DATE = Object.groupBy(
Object.values(CACHE),
(e) => truncateTime(e.createdAt),
);
// фильтрация по дате == сегодня
console.log(ENTRIES_BY_DATE[truncateTime(new Date())]);В этом (втором) примере создаётся простейший индекс, где отслеживается та часть каждой записи в поле createdAt, где указан год/месяц/день. На самом деле, для этого сгодились бы разные структуры данных. Такой подход весьма легко применим в JS, но не слишком гибок. Например, если запрашивать целый диапазон данных, то без множественных обращений к ним не обойтись. Потенциально выигрышной структурой данных здесь представляется массив записей, отсортированных по дате, в сочетании с более сложной логикой запросов и обновления.
Итак, теперь у нас на фронтенде появилась возможность быстро искать записи, которые были опубликованы в указанную дату — но в обмен на эту возможность нам придётся поддерживать согласованность между двумя структурами данных: CACHE и ENTRIES_BY_DATE.
Рассмотрим, что же произойдёт, если мы начнём одновременно управлять несколькими такими индексами, и для каждого потребуется собственная логика сборки, обновления и выполнения запросов. Проверка корректности быстро становится ощутимым бременем на этапе тестирования и ревью кода. Если мы забудем как следует удалить или обновить запись в одном индексе, из‑за этого возникнут сложноуловимые баги. Вскоре окажется, что мы тратим больше времени на выстраивание инфраструктуры для управления всей этой сложностью, чем на развитие новых фич в приложении. Приходит время — и мы осознаём, что на самом деле мы выстраиваем базу данных.
Причём на кэшировании и индексировании данных наш путь не заканчивается! Независимо от обстоятельств, кто‑нибудь да заметит, что, опираясь на оптимистические мутации таких структур данных, можно добиться гораздо более удобного взаимодействия с сайтом.
Мутации в стиле «наполовину полного стакана»
Что же собой представляют оптимистические мутации? В принципе, их идея такова: сымитировать эффект некоторой операции на локальной машине, прежде чем сервер успеет ответить. Действуя так, можно создавать такие пользовательские интерфейсы, которые, как кажется, откликаются мгновенно, и задержка при передаче данных по сети в таком случае «устраняется». Разумеется, за это приходится платить: если серверу вздумается сделать что‑либо незапланированное (или если возникнет ошибка), то UI может потребоваться «откатить» это изменение, а пользователю подсказать, что требуется исправить проблемы. Исходя из того, что наш UI хорошо прогнозирует, что придёт с сервера (то есть, ошибки будут обрабатываться на стороне клиента, а логика клиента и сервера будет строго синхронизирована), оптимистические мутации могут стать мощным инструментом в арсенале фронтенд‑разработчика. Кроме того, это отличный способ прокачать навыки проектирования баз данных!
Давайте подробно разберём, как устроены оптимистичные мутации, и какие новые вызовы они перед нами ставят:
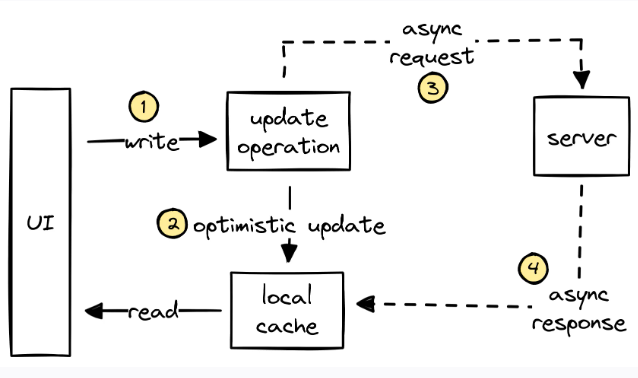
На вышеприведённой схеме прослеживается такой путь оптимистического обновления:
UI выдаёт операцию записи. В данном случае UI пытается обновить некоторый фрагмент данных.
Данное обновление оптимистически применяется к локальному кэшу — то есть делается допущение, что сервер в итоге одобрит это решение. В таком случае UI может сразу же повторно отобразить новое состояние.
Операция обновления асинхронно отправляется на сервер.
Наконец, сервер присылает в ответ результат обновления, который вливается в локальный кэш, затирая при этом более раннее оптимистическое обновление. В результате UI может повторно отобразиться (если это необходимо) и (остаётся надеяться) система остаётся в согласованном состоянии.
Чтобы гарантировать, что в рамках данного процесса будет поддерживаться согласованность, серверу приходится решить ряд проблем. Во‑первых, необходимо продублировать логику между клиентом и сервером, чтобы можно было оптимистично спрогнозировать результат. Далее каждую мутацию, выполняемую на лету, необходимо отслеживать — так можно справиться с асинхронными ошибками или разногласиями на сервере. Наконец, чтобы обеспечить пользователю максимальное удобство работы с интерфейсом, оптимистический участок кэша даже должен быть сделан достаточно долговечным, чтобы мы успевали согласовывать изменения, возникающие после перезапуска приложения. Для решения каждой из этих задач приходится дорого расплачиваться как рабочим временем программиста, так и временем, затрачиваемым на проверку корректности. Опять же, оказывается, что мы углубляемся в микроменеджмент данными, а не делаем для пользователей новые выдающиеся фичи.
Но эти проблемы блекнут в сравнении с той, к которой я хочу обратиться далее: это рекурсивная инвалидация кэша.
Рекурсивная инвалидация кэша
В любом достаточно высоконагруженном приложении некоторые компоненты данных будут неоднократно всплывать сразу во многих местах кэша:
const CACHE = {
projects: {
1: { id: 1, name: "build a spaceship", progress: 0.5, numTasks: 10 },
2: { id: 2, name: "to the moon", progress: 0.0, numTasks: 10 },
// ...
},
tasks: {
1: { id: 1, project: 1, name: "finish hull design", status: "pending" },
9: { id: 9, project: 1, name: "order bolts", status: "pending" },
// ...
},
users: {
1: { id: 1, name: "Carl", assignedTasks: [1] },
2: { id: 2, name: "ChatGPT", assignedTasks: [9] },
},
};В вышеприведённом примере мы кэшируем проекты, задачи и пользователей, занятых важной космической миссией. Так бывает: некоторые строят космические корабли. Некоторые пишут веб‑приложения. Некоторые создают веб‑приложение так, как будто это космический корабль. ???? Давайте обрисуем, что требуется сделать по завершении задачи для того, чтобы содержащийся на сервере кэш остался в согласованном состоянии:

Нам нужно проделать такие шаги:
Мы информируем сервер о том, что задача завершена.
Обновляем проект, так как степень его прогресса изменилась.
Готовность 60%! Теперь давайте проверим, присвоены ли новые задачи.
Чёрт возьми, работы ещё полно. Давайте посмотрим, в чём заключается новая задача.
В данном примере UI приходится сделать несколько оборотов после обновления; это делается, чтобы корректно инвалидировать все части кэша, которые потенциально могли измениться. Правда, определённо можно было бы создать и более сложный API, сокращающий эту многоходовку до одноходовки. В частности, данная проблема может решаться при помощи GraphQL, хотя, конечно, и это не идеальный вариант. В конечном итоге, из‑за такого подхода API или клиентская логика плотно зацепляется с нижележащей моделью данных. Давайте рассмотрим две причины, по которым это может быть плохо:
Во‑первых, здесь требуется, чтобы UI знал, какая часть кэша релевантна при каждой мутации. При увеличении масштабов такая конструкция может стать очень хрупкой, поскольку отношения и агрегации могут сказываться на многих участках локального кэша. Кроме того, по мере увеличения команды разработчиков эти проблемы могут перехлёстывать границы команд; ситуация может напоминать работу с мутабельными глобальными переменными в больших программных проектах.
Во‑вторых, в сочетании с оптимистическими мутациями становится гораздо сложнее воспроизводить серверную логику на стороне клиента с целью прогнозировать те изменения, которые произойдут на сервере. Например, в данном случае можно оптимистически забрать задачу 1 у пользователя 1 и нарастить прогресс, высчитав новое соотношение (можно работать с общим количеством задач). Обучая наши приложения прогнозировать эти вложенные изменения на локальной машине, клиент, естественно, всё в большей и большей степени дублирует стек серверной части.
Значит, мы делаем базы данных?
В любом достаточно сложном фронтендовом приложении программисту неизбежно приходится реализовывать настолько много фич для управления данными, что на выходе получается, фактически, предметно‑ориентированная база данных. Эта добавленная сложность дублируется в каждом из проектов, над которыми нам приходится работать. Приходится решать проблемы с бизнес‑логикой, а не создавать фичи, интересующие пользователей. Моя цель в данном случае — подсветить эти паттерны, к которым все мы привыкли, а затем спросить: где тот фронтендовый стек с оптимизированной базой данных, которого мы заслуживаем?
Я устал ждать — поэтому взялся решать эту проблему в лоб. Написал софт, который назвал SQLSync. SQLSync — это оптимизированный под фронтенд стек базы данных, построенный поверх базы данных SQLite. Возможно, SQLite — не самая распространённая база данных по количеству развёрнутых инстансов, но в топ‑пять наиболее часто развёртываемых софтверных модулей она входит по любой классификации. Кроме того, в моём инструменте есть движок синхронизации, идея которого почерпнута из Git и распределённых систем. Стек спроектирован таким образом, чтобы он бесшовно интегрировался с наиболее популярными фреймворками для клиентской части, в том числе, с React, Vue и Next.js. Цель SQLSync — решать наиболее сложные проблемы, связанные с управлением данными, чтобы разработчик в это время мог сосредоточиться именно на тех деталях приложения, благодаря которым оно приобретает уникальность.
В качестве демонстрационного примера, показывающего, на что способна SQLSync, предлагаю посмотреть это приложение для планирования задач. Весь уровень данных реализован в 60 строках Rust и в паре SQL‑запросов, рассеянных по разным компонентам. SQLSync даёт нам долговечный кэш, полный набор возможностей SQLite (индексы, ограничения, триггеры, оптимизацию запросов), оптимистические мутации, умную инвалидацию кэша и реактивные запросы.
Давайте коротко, но более углублённо рассмотрим, как в случае с SQLSync решается каждая из рассмотренных выше проблем по управлению данными.
SQLSync локально хранит данные в одной или нескольких базах данных SQLite. В данном случае мы гарантированно получаем долговечный кэш, который по устройству очень похож на те базы данных, которые мы используем на бэкенде. Но это долговечный кэш с суперспособностями!
Во‑первых, создавать индексы очень легко, и эти индексы автоматически синхронизируются с данными. Точно как и на бэкенде, эти индексы могут автоматически использоваться в базе данных для ускорения запросов.
Но индексами дело не ограничивается! SQLite также наделяет нас всей силой языка SQL, на котором не составляет труда выражать сложные запросы, направляемые к нашим данным, а также делать триггеры, внешние ключи, ограничения и такие расширения как полнотекстовый поиск.
Сверх всего этого SQLSync прямо из коробки предоставляет механизм оптимистических мутаций. Это делается путём обработки мутаций в редьюсере, подобно тому, как это делается в Redux. Редьюсер можно написать на любом языке, пригодном для оптимистической работы на клиенте и допускающем дальнейшую компиляцию в WebAssembly. При помощи такого редьюсера SQLSync может оптимистически выполнять мутации на клиенте, а затем выполнять их на сервере в глобально согласованном порядке. Наконец, на клиенте выполняется операция, подобная Git Rebase — это делается для синхронизации клиента с сервером. Подробнее о том, как работает SQLSync, рассказано в лекции автора, прочитанной на конференции WasmCon 2023.
Одно из достоинств архитектуры SQLSync заключается в том, что в ней исчезает необходимость в рекурсивной инвалидации кэша. Написав всю логику мутации данных в редьюсере, можно легко организовать совместное использование этой логики сразу на клиенте и на сервере. Все изменения, вносимые в процессе мутации, автоматически становятся видны. Лучше того, благодаря синхронизации, устроенной по принципу «Git Rebase», при таком подходе на сервере можно выполнять иные изменения, нежели на клиенте — и при этом будет гарантировано, что клиент придёт к тому же согласованному результату, что и сервер. Благодаря этой мощной возможности разработчики могут вообще не забивать голову микроменеджментом данных.
Давайте общаться!
Я разрабатываю SQLSync, так как хочу упростить построение клиентских приложений, причём, так, чтобы нам не приходилось из раза в раз изобретать велосипед. Если наши с вами взгляды на будущее совпадают, не откажите в звёздочке для SQLSync на Github, присоединяйтесь к нашему каналу в discord или напишите мне. Хотелось бы услышать, как, на ваш взгляд, выглядит идеальная база данных, и как вам тот подход, при помощи которого описанные задачи решаются в SQLSync.
Прежние проекты
Тема использования базы данных (или методов базы данных) в клиентской части стека сегодня популярна. Я хотел бы подчеркнуть несколько конкретных статей, которые показались мне проницательными и важными.
Riffle
В эссе Riffle «Building data‑centric apps with a reactive relational database» авторы исследуют такую идею: что если хранить в единственной реактивной базе данных всё состояние, в том числе, состояние UI. В числе ключевых идей, которые вдохновили меня на написание этого поста, а также отразились в разработке SQLSync, такие:
Реактивные запросы обеспечивают чёткое представление о системе, а также хорошо сочетаются с такими декларативными инструментами, как React;
Решение технических проблем в разработке клиентских приложений на основе таких идей, которые зародились в сообществе разработчиков баз данных;
Почему полезно моделировать состояние при помощи реляционной модели данных и реальных индексов.
Instant.db
Степан, автор Instant.db, написал две изумительные статьи о базах данных в браузере.
Настоятельно рекомендую прочитать обе, так как в них затронуты многие из тех самых проблем, что и в этом посте, но больше внимания уделяется отношению между клиентским и серверным стеком. В конечном итоге, Степан чётко описывает мотивацию, которая привела к созданию Instant.db — графовой альтернативы Firebase.
CR-SQLite
CR‑SQLite от Мэтта Уонлоу — это расширение для SQLite, в котором используются бесконфликтные реплицируемые типы данных (CRDT) и причинно упорядоченные логи событий, поддерживающие согласованное слияние данных. Благодаря такому решению пиринговые приложения могут совместно хранить и обрабатывать данные в SQLite, и для этого не требуется центральный координатор. Кроме того, этот проект — захватывающий пример того, как можно гонять SQLite в браузере.
Кроме того, Мэтт исследует смежные идеи, например, инкрементные вычисления и упрощение работы с SQL при помощи typed‑sql. В целом, творческий импульс Мэтта вдохновляет, и я рекомендую вам познакомиться с теми проектами, над которыми он работает.
Комментарии (43)

shasoftX
06.12.2023 05:11Как я понимаю тут происходит отправка изменений на сервер, который их к себе применяет. Т.е. фактически с клиента уходят запросы, которые сервер выполняет. А как контролировать права выполнения таких запросов? Ведь пользователь может прислать что то, что сломает сервер.

nin-jin
06.12.2023 05:11+1Собственно, по той же причине crdt не позволяет волшебным образом избавиться от центрального сервера. Чтобы от него избавиться нужны цифровые подписи, что относительно дорогое удовольствие.

kipar
06.12.2023 05:11я так понимаю нет. SQLite компилируется в WebASM и запускается на стороне браузера. Во всяком случае демка с SQL запросами работает и с отключенным инетом.

flancer
06.12.2023 05:11+4Интересно, а чем IndexedDB не подошла для кэширования данных из API на фронте?

igor_suhorukov
06.12.2023 05:11Иногда действительно проще встроить базу данных в фронтэнд, чем пытаться самому переизобретать фичи базы данных в браузере. Я так недавно сделал c DuckDB WebAssembly.

DarthVictor
06.12.2023 05:11Потенциально выигрышной структурой данных здесь представляется массив записей, отсортированных по дате, в сочетании с более сложной логикой запросов и обновления.
Потенциально выигрышной структурой данных здесь представляется B-дерево.

username-ka
06.12.2023 05:11+4Статья вызывает вьенамский синдром. Кто Apollo (GraphQL) помянет - тому глаз вон.
Не стараюсь в критику - просто ИМХО - но я бы заменил всю статью на "просто не делайте так".
По мере роста сложности приложения главной проблемой на самом деле становится согласованность:
одна и та же сущность скачивается в пяти разных местах; при этом в каждом из этих мест нужен разный набор полей или вложенных объектов
а меняется эта сущность в трёх других местах
а ещё эта сущность может измениться в результате мутации в другой объект, который даже своим названием не намекает на такой сайд-эффект; иногда этот эффект ещё не существует, но появится через месяц в результате разработки совсем другой фичи.
В 80% случаев разработчик это увидит и поставит инвалидацию какой-то части кэша после выполнения мутации. Из оставшихся 20% - примерно половину в конце концов отловит тестирование. А ещё 10% - останется в приложении и будет накапливаться.
Конечно, есть разные стратегии по обеспечению согласованности, но все из них, что я видел, объединяет одно - они не работают, когда над проектом работает больше двух человек, или кто-то из них больше "творец", чем "ремесленник", и ему сложно удерживать в голове 100500 сложных вещей в один момент времени.
Данные можно и нужно кэшировать, и да, не через useState, а хотя-бы какой-нибудь tanstack-query или rtk (конкретно про SPA, не говорю тут про Server Components). Но - исключительно в рамках одной страницы. Перешёл на другую - лучше перезагрузить.
nin-jin
06.12.2023 05:11-1А LiveQuery и нотификации по WebSocket в этой линии времени ещё не изобрели? Вечно путаюсь в этой фронтенд-мультивселенной...
username-ka
06.12.2023 05:11+1Конкретно в этой линии уже было несколько циклов "придумали"->"оно сдохло".


Kazikus
06.12.2023 05:11В мире clojure (clojurescript для фронта) почти сразу был сделан заход на базу https://github.com/tonsky/datascript

Portnov
06.12.2023 05:11-1Ничонепонел. SQLite как-то запустили в браузере? переписали на яваскрипте? или на wasm странслировали?
...
может тогда не мелочиться и весь бэк вместе с postgres / mysql странслировать в wasm и засунуть в браузер?...

Spaceoddity
06.12.2023 05:11+2

yrub
06.12.2023 05:11и как это связано с sql? написанож keyval-store, по сути просто мапа... в лучшем случае это используется как легальный способ сохранить что-то браузере
Spaceoddity
06.12.2023 05:11вы не туда смотрите))
а для "легального хранения" обычно используется localStorage
yrub
06.12.2023 05:11в принципе есть варианты с запуском через wasm, что конкретно в этом случаи хз, по-моему на хабре даже кто-то писал статью про это, как он сам делал



MiyuHogosha
06.12.2023 05:11Если уж так подходить, то любая программа - это либо траслятор, либо СУБД. Это абсолют и только ситхи судят абсолютами... ахем.

akamajoris
06.12.2023 05:11+1>Прекратите клепать базы данных
>Я устал ждать — поэтому взялся решать эту проблему в лоб. Написал софт, который назвал SQLSync. SQLSync — это оптимизированный под фронтенд стек базы данных,
:D

amateur80lvl
06.12.2023 05:11Чтобы ничего подобного не делать, у меня есть две отмазки:
за такое меня давно бы уволили
не каждому браузеру доступны 16 гигов оперативки
rukhi7
Вот интересно, мы уже несколько лет решаем задачу перевода данных из бинарного потока сохраненного в файле в базу данных для визуализации-навигации, анализа, редактирования,
и, соответственно, обратную задачу: построения бинарного потока по данным заданным в базе данных. То есть заполняет и/или редактирует базу данных человек, а использует данные алгоритм формирования-генератор бинарного потока данных.
Проблема в том что данные в такой базе данных получаются 3-х мерные: таблицы, которые по определению двухмерные меняются со временем, то есть надо хранить-формировать несколько таблиц одного типа сущностей по периодам времени на протяжении полного периода потока данных. Кажется SQL не очень подходит для таких 3-х мерных данных, или мы чего то не знаем?
PuerteMuerte
А что вы подразумеваете под этим? Что периодически меняется набор столбцов таблиц?
В таком случае - зависит от того, как вы работаете с этими данными. Если вам нужны какие-то связи по этим стоблцам, целостность данных и так далее, а меняются они нечасто, то можно продолжить использовать SQL, иметь какую-то одну родительскую таблицу и дочерние под каждую новую сущность.
Если у вас сложной логики нет, а надо работать на уровне сущности, ну, вида "извлёк сущности за какой-то период, что-то с ними сделал, положил обратно", ваш пациент - noSQL.
rukhi7
Нельзя сказать что это человек работает с данными, состав данных определяется спецификацией на поток данных , набором спецификаций на подпотоки которые содержатся в общем-сумарном потоке данных. Целостность данных в потоке обеспечивается контрольными суммами пакетов в которых данные передаются.
В базе данных, вроде как данные некому сломать, туда не должны попадать противоречивые данные, вроде как, вот на этапе преобразования из потока в базу эту непротиворечивость неплохо бы проконтролировать, конечно. Опять же это не входит в функциональность SQL кажется?
Вроде как все сущности статично определены спецификациями, правда они могут отсутствовать на некоторых периодах в потоке, как это отобразить в базу данных в таком случае? Варианты конечно есть, но что выбрать однозначно непонятно.
В основном связи между данными по разным периодам, но для одной и той же таблицы нет связей по значениям, какое то время одни значения в таблице, в следующий период меняются значения в таблице, сама таблица не меняется, и в общем то нет зависимости между старыми и новыми данными.
Не важно как часто они меняются - главное что они в принципе меняются и с этими изменениями их надо сохранять и потом визуализировать, и иметь возможность редактировать.
Вот начинаешь писать и осознаешь как тут все непросто, сколько разной функциональности надо поддерживать.
oracle_schwerpunkte
Серебряной пули нет, но есть варианты
https://habr.com/ru/articles/101544/ + комменты
igor_suhorukov
Apache Iceberg решает похожую задачу в аналитике больших данных.
rukhi7
да нет, нельзя сказать что у нас какие-то особо большие данные, таблицы максимум полей на 50 и таблиц штук 20 где-то надо сформировать из сохраненного трафика, проблема в том что нужно видеть несколько версий для некоторых из этих 20 таблиц в зависимости от позиции в трафике, и соответственно при редактировании надо иметь возвожность добавлять такие измененные таблицы для разных позиций в трафике,
то есть надо иметь возможность задавать диапазон длительности трафика на которых определены каждая из этих 20 таблиц, причем желательно независимо для каждой таблицы, как-то так.
Зато нам не нужно контролировать права пользователей, и не нужно параллельной работы пользователей. Пользователь либо человек, либо парсер потока который преобразует поток в данные базы данных, или генератор потока который преобразует данные из базы в поток. Никогда не нужно чтобы они одновременно работали. Хотя можно наверно и до этого дойти, но пока бы решить простую задачу.
igor_suhorukov
Так меньший объем данных не мешает использовать те же технологии, если они решают задачу. Просто посмотрите насколько применимо к вашим схемам БД Apache Iceberg и projectnessie
imdragon
Такие таблицы называются медленно меняющимся измерением. Современные SQL платформы работают с таким.
Ivan22
SQL про них ничего не знает, это паттерн проектирования
SergeyProkhorenko
Знает кое-что: https://www.ispras.ru/preprints/docs/prep_30_2017.pdf https://www.youtube.com/watch?v=0nBqpZLc4xc
Но все обходятся "велосипедами", то есть, паттерном проектирования, а именно, полями start_date и end_date в таблицах с "историчностью", причем start_date входит в ключ, а для актуальных данных end_date = NULL, либо end_date = '9999-12-31'
rukhi7
прежде чем рассматривать как применять язык запросов, хотелось бы определиться со структурой-способом хранения данных.
У меня вот такая проблема, например:
Есть таблица сущностей на 300 или 500 или 1000 строк - 15 полей,
Сущности в ней могут меняться каждые 350 МИЛЛИсекунд (каждую треть секунды), проблема в том что в течении например 20 секунд она не меняется и для анализа на интерфейс человеку надо выводить ЦЕЛУЮ таблицу подписанную диапазоном времени для которого она действует (хотелось бы),
Если мы анализируем трафик скажем за 10 минут (час, ...) нам неплохо бы видеть просто список точек в которых произошли изменения, можно с некоторой статистикой которая убирается в строчки, которые подписывают эти моменты изменений,
Возникает вопрос как хранить такие изменения:
переписывать целую таблицу если поменялись только пара полей из 300х15?
или
хранить только сами изменения например в виде "имя поля:новое значение:время", но тогда возникает проблема когда у нас меняется например половина таблицы.
Мы в своем проекте сделали первое пока.
А вот буржуи в таких случаях пишут что надо искать компромис, вот где он этот компромис? Где его искать?
nin-jin
На экран у вас влезет лишь несколько десятков строк - их и синхронизируйте в реальном времени. А остальные лишь по мере прокрутки
Ivan22
В этом кейсе явно нужна субд с поддержкой инмемори таблиц
500 или 1000 строк это очень маленький объем, с таким можно все целиком переписывать.
для больших объемов возможен вариант - копить лог, а раз в N единиц времени обновлять всю таблицу и очищать лог.
kemsky
Есть datomic, в ней можно смотреть данные в разрезе времени и отдельных транзакций. Можно перейти на события и строить агрегаты за любые периоды.
rukhi7
и мне кажется теперь что даже GIT как база данных в какой то степени подходит под мою задачу если таблицу хранить в текстовом виде!
Вряд ли нам все это подойдет, потому что нам нужна не просто локальная база данных, нам нужна временная база данных в памяти.
Нужна какая то библиотека которая позволяет задать, описать структуру таблиц и/или дерева объектов для сохранения и навигации по ним, и чтобы дальше наполнять эту структуру данными, а потом иметь возможность навигации по ним...
Просто в статье, в начале крупным шрифтом написано:
и я на это повелся!
но потом все возвращается к общению с сервером:
А тут главная проблема будет связана не с функциональностью базы данных, а с функциональностью для работы с сервером по сети (работа с данными на удалении).
Вот если бы вместо библиотеки для работы по сети иметь библиотеку для работы с локальной (а не удаленной!) базой данных.
Получается я что-то напутал, меня начальный посыл статьи ввел в заблуждение.
nin-jin
https://www.npmjs.com/package/mol_db
Ivan22
широта распространения этих расширений говорит сама за себя
me21
А почему в таблице не ввести колонку "период времени"?
rukhi7
завести то можно, только этого не достаточно, потому что вместе с каждым уникальным периодом времени надо хранить еще и уникальное содержимое всей таблицы (как контейнера) которое и должно меняться в зависимости от этого периода и которые все(!) таблицы с изменяющимся содержимым надо помнить и хранить в базе данных или иметь возможность размножать при редактировании.
Raspy
Звучит как OLAP представление, где единственным дополнительным вектором будет отрезок времени.