

Когда я проходил стажировку в Nullspace Robotics, мне повезло участвовать в проекте, нацеленном на расширение возможностей компании. Мы совместили системы обнаружения объектов и распознавания изображений для создания модели, классифицирующей детали конструктора Lego Technic в реальном времени.
В этой статье я расскажу о том, с какими сложностями столкнулся наш проект, и как мы довели его до успешного завершения.
В рамках реализации этого проекта мы с Эймосом Кохом провели всё лето 2022 года, обучая студентов программированию и роботостроению. Вот ссылки на наши аккаунты LInkedIn: Aveek, Amos.
Компания Nullspace Robotics является ведущей образовательной платформой по обучению студентов роботостроению и программированию в Сингапуре. Значительная часть её деятельности посвящена конструированию роботов из деталей Lego Technic, рассортированных по разным контейнерам. Можете представить, насколько сложно заставить 8-летнего ребёнка с безграничным зарядом энергии помочь разложить детали обратно по контейнерам, когда единственное, чего он хочет — это продолжать собирать из них что-нибудь ещё.
Компания поставила нам задачу разработать устройство, которое будет сортировать детали по категориям с минимальным вмешательством со стороны человека. Это бы позволило решить одну из ключевых проблем с повышением эффективности занятий по роботостроению.
Описание задачи
Наш проект включал три составляющих: обнаружение движущихся объектов в реальном времени, распознавание изображений и создание аппаратной части. Поскольку моя стажировка была ограничена по времени, основное внимание мы уделили первым двум пунктам, связанным с программным аспектом проекта.
Основной задачей была реализация обнаружения и распознавания движущихся деталей в одном фрейме. Для этого мы рассматривали два подхода: встраивание модели распознавания изображений в обнаруживающую объекты камеру или же разделение этих процессов.
В итоге мы решили их разделить. Такой подход подразумевал захват правильной картинки при обнаружении объекта и его классификацию с помощью модели МО. Совмещение этих процессов потребовало бы выполнения модели практически для каждого фрейма, чтобы распознавать обнаруженные объекты. Разделение же исключило эту необходимость, сделав всю операцию более гладкой и вычислительно эффективной.
Обнаружение объектов
В качестве основы программы для обнаружения объектов, а также для её подстройки под работу с деталями Lego, мы использовали описанные ниже идеи из других проектов.
Мы решили опереться на схожие принципы обнаружения объектов, так как наше устройство включало ленточный конвейер однородного цвета, на котором обнаружение любого движения было бы вызвано смещением деталей на ленте.
Помимо этого, мы использовали гауссово размытие и другие техники обработки изображений, которые применяли ко всем фреймам, в том числе сравнивая текущий с предыдущими. Дальнейшая обработка подразумевала выделение (обведение рамками) движущихся элементов:
for f in camera.capture_continuous(rawCapture, format="bgr", use_video_port=True):
frame = f.array # Берём необработанный массив NumPy, представляющий изображение
text = "No piece" # Инициализируем текст о присутствии/отсутствии детали
# Изменяем размер фрейма, преобразуем в оттенки серого и размываем
frame = imutils.resize(frame, width=500)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
# Если средний фрейм None, инициализируем его
if avg is None:
print("[INFO] starting background model...")
avg = gray.copy().astype("float")
rawCapture.truncate(0)
continue
# Аккумулируем взвешенное среднее между текущим фреймом и предыдущими
# Затем вычисляем отличие между текущим фреймом и скользящим средним
cv2.accumulateWeighted(gray, avg, 0.5)
frameDelta = cv2.absdiff(gray, cv2.convertScaleAbs(avg))
# Разделяем полученное изображение (thresholding), растягиваем разделённое изображение,
# чтобы заполнить пустоты, находим на нём контуры
thresh = cv2.threshold(frameDelta, conf["delta_thresh"], 255,
cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# Перебираем контуры
for c in cnts:
# Если контур слишком мал, игнорируем
if cv2.contourArea(c) < conf["min_area"]:
continue
# Вычисляем для контура рамку, отрисовываем её на фрейме и обновляем текст
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
piece_image = frame[y:y+h,x:x+w]
text = "Piece found"
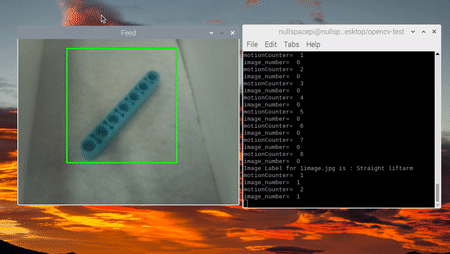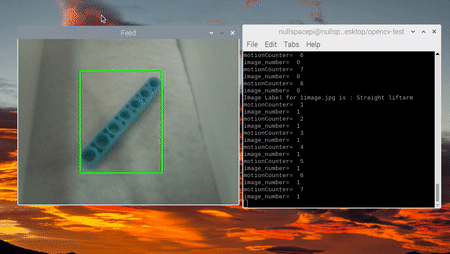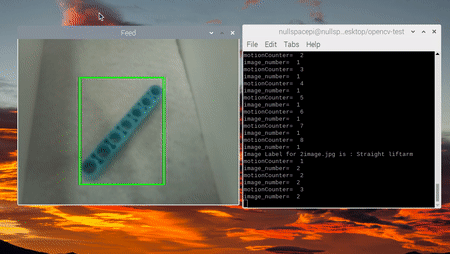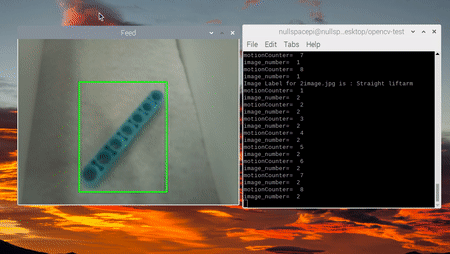
# cv2.imshow("Image", image)Чтобы убедиться, что движение действительно относилось к детали Lego, мы проверяли стабильность обнаружения с помощью счётчика движений. В ходе проверки определялось, было ли обнаружено движение в заданном числе фреймов, и только потом делался вывод, что оно действительно относилось к детали, а не являлось следствием шума. Затем итоговое изображение сохранялось и передавалось в CNN (Convolutional Neural Network, свёрточную нейронную сеть) для классификации.
if text == "Piece found":
# Для сохранения изображений рамок
motionCounter += 1
print("motionCounter= ", motionCounter)
print("image_number= ", image_number)
# Сохраняем изображение, если движение обнаружено в 8 и более последовательных фреймах
if motionCounter >= 8:
image_number +=1
image_name = str(image_number)+"image.jpg"
cv2.imwrite(os.path.join(path, image_name), piece_image)
motionCounter = 0 #reset the motion counter
# Классифицируем сохранённое изображение, подробности нижеРазработка модели
▍ Датасет
Датасет изображений деталей мы собрали сами, отказавшись от использования картинок из интернета, поскольку хотели воссоздать условия, при которых модель бы обнаруживала и классифицировала эти детали. В итоге мы собрали простую систему ленточного конвейера, используя исключительно детали Lego. В качестве двигателя для неё мы установили мотор Lego Spike Prime.

▍ Архитектура модели
Для решения основной задачи я применил модель МО, которую нашёл в репозитории Aladdinpersson на GitHub. Она состоит из свёрточных слоёв с последовательным уменьшением числа фильтров: 128-64-32-16. Это архитектурное решение нацелено на повышение качества распознавания объектов.
Мы не стали использовать предварительно обученную модель, а создали свою свёрточную сеть, потому что:
- Нам не требовалось извлекать из изображений глубокие признаки.
- Мы хотели получить небольшую модель и уменьшить её сложность, параллельно сократив вычислительные затраты. Это должно было повысить эффективность выполнения CNN на Pi в качестве модели tflite (tensorflow lite).
Важным этапом была нормализация данных для обеспечения стабильной точности обучения, особенно с учётом разброса значений, получаемых на разных изображениях ввиду отличий в освещении.
В этой модели решающую роль играли различные слои, а именно ReLU,
Dense, softmax и Flatten. Например, активация ReLU была важна для классификации изображений, так как решала проблему с угасанием градиентов при распознании изображений. Полносвязные слои, напротив, являются типичными в моделях Tensorflow и способствуют формированию плотно связанных нейронных сетей. При этом функция активации softmax вычисляла вероятности для каждой категории датасета.В качестве функции потерь мы задействовали перекрёстную энтропию из библиотеки Keras, которая хорошо подходит для задач мультиклассовой классификации. За тонкую настройку модели отвечал алгоритм оптимизации Adam из той же библиотеки.
▍ Обучение и оптимизация
Количество эпох подбиралось тщательно, чтобы добиться удачного баланса между обучением и переобучением. При этом желательно было использовать не более 200, чтобы обеспечить оптимальную производительность модели. Для ускорения обучения мы использовали платформу Google Colab, которая предоставляет доступ к ресурсам GPU, значительно ускоряя обучение в сравнении с имеющимися у нас ноутбуками.
Вот общая архитектура модели:
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
1)),
layers.RandomRotation(0.2),
layers.RandomZoom(0.1),
])
model = keras.Sequential(
[
data_augmentation,
layers.Rescaling(1./255, input_shape = (img_height,img_width,1)), #Нормализация входных данных
layers.Conv2D(128, 3, padding="same", activation='relu'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Conv2D(64, 3, padding="same", activation='relu'), #Сколько единиц здесь должно быть – 16 или 32? Пробуем определить с помощью дополнительных данных
layers.MaxPooling2D(pool_size=(2,2)),
layers.Conv2D(32, 3, padding="same", activation='relu'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Conv2D(16, 3, padding="same", activation='relu'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Dropout(0.1),
layers.Flatten(),
layers.Dense(10,activation = 'relu'),
layers.Dense(7,activation='softmax'), # число выходных классов
]
)
model.compile(
optimizer=keras.optimizers.Adam(),
loss=[keras.losses.SparseCategoricalCrossentropy(from_logits=False),],
metrics=["accuracy"],
)
model_history = model.fit(x_train, y_train, epochs=200, verbose=2, validation_data=(x_test,y_test), batch_size=25) #Думаю, оптимальный размер пакета 25/32Результаты модели
Модель обучалась на 6000 изображений, охватывающих 7 категорий деталей Lego Technic, и достигла точности 93%. Ниже показаны графики, демонстрирующие прогресс обучения, а также матрица смешений для анализа производительности:
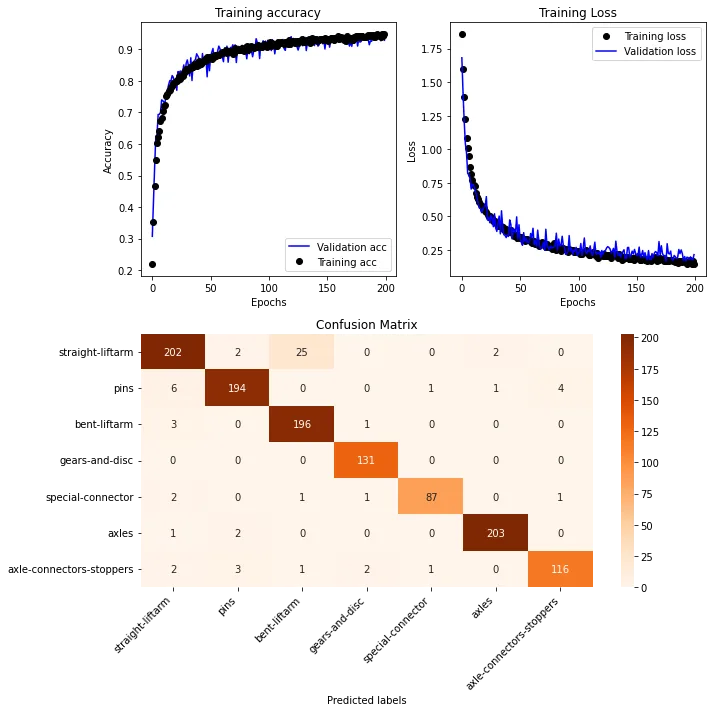
Спрогнозированные метки
Реализация модели на Raspberry Pi
На Pi нейронные сети эффективнее всего выполнять в виде модели tflite. Мы сохранили эту модель локально и затем загрузили на Pi.
from tflite_runtime.interpreter import Interpreter
# Загружаем модель TFLite и выделяем тензоры
interpreter = Interpreter(model_path="lego_tflite_model/detect.tflite") # Вставляем в модель путь
interpreter.allocate_tensors()После цикла
for счётчика движений подходящие изображения передавались на классификацию в нейронную сеть:# После if text == "Piece found":
# Открываем изображение, изменяем его размер и увеличиваем контраст
input_image = Image.open('lego-pieces/'+ image_name)
input_image = ImageOps.grayscale(input_image)
input_image = input_image.resize((128,128))
input_data = img_to_array(input_image)
input_data = increase_contrast_more(input_data)
input_data.resize(1,128,128,1)
# Прогоняем np.array изображения через модель tflite. На выходе получаем вектор вероятностей
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
# Получаем индекс максимального значения в векторе вероятностей
# Этот индекс будет соответствовать созданному выше вектору меток (то есть значение индекса 1 будет означать, что объект, скорее всего, относится к labels[1])
category_number = np.argmax(output_data[0])
# Возвращаем метку классификации изображения
classification_label = labels[category_number]
print("Image Label for " + image_name + " is :", classification_label)
else:
motionCounter = 0 # Сбрасываем счётчик движений для поиска новых объектовКлючевым моментом здесь была гибкость. Счётчик движений можно скорректировать либо под захват изображений с целью построения датасета, либо для установки порога, определяющего, когда изображение нужно захватить для классификации.
Демонстрация
Кульминацией наших усилий стала демонстрация общей точности готовой системы, сопровождённая фотографиями и видео её работы. Важнейшим компонентом здесь выступил ленточный конвейер:

Предстоящие доработки
Программная часть: в дальнейшем также планируется добавить модель проверки качества, которая поможет убедиться в использовании для классификации подходящих изображений.
Аппаратная часть: модели однозначно не повредит более качественная камера, способная делать более детальные снимки. Кроме того, конвейерную систему, временно собранную для тестирования и демонстрации, нужно будет расширить для размещения большего числа деталей. Ещё надо придумать способ разделять несколько деталей Lego так, чтобы в кадр попадала только одна деталь. В сети есть похожие проекты, где подробно разбираются возможные решения этой задачи.
Заключение
Работа в Nullspace Robotics стала моим первым опытом построения собственной нейронной сети для практических задач. Я уже занимался подобным в рамках обучающих курсов, но создавать модель для производственных нужд, когда требуется учитывать такие факторы, как ресурсы, решаемые задачи и подстройка датасета под цели проекта — это совсем другое дело. Я планирую продолжить своё путешествие в мир машинного обучения и задействовать последние технологии ИИ для создания более инновационных решений.
Весь код, а также изображения датасета и дополнительную информацию можете найти в репозитории GitHub или на HuggingFace.
Скидки, итоги розыгрышей и новости о спутнике RUVDS — в нашем Telegram-канале ????
