

Данные, используемые для обучения моделей машинного обучения, должны быть идеально сбалансированы по всем категориям и классам. Однако суровая жизнь часто преподносит нам данные, в которых присутствует значительный дисбаланс. Такой дисбаланс может привести к нежелательным смещениям и ошибкам в моделях, что, в свою очередь, существенно снижает их эффективность и точность.
Существуют такие подходы к устранению дисбаланса какOversampling и Undersampling. Oversampling – это процесс увеличения количества примеров в менее представленных классах, в то время как Undersampling – это процесс уменьшения количества примеров в более представленных классах. Оба эти метода имеют свои преимущества и недостатки, и выбор между ними зависит от конкретной задачи и характеристик данных.
Методы Oversampling
Простое повторное использование данных (Random oversampling)
Простое повторное использование данных заключается в увеличении числа экземпляров класса-меньшинства путем случайного повторного выбора данных из этого класса до достижения желаемой пропорции между классами.
Прежде чем приступить к Random Oversampling, необходимо определить, что в задаче машинного обучения существует дисбаланс классов, то есть один из классов (обычно класс-меньшинство) имеет существенно меньше экземпляров, чем другой. Поскольку мы хотим балансировать классы, нам нужно выбрать класс, который нужно увеличить. Обычно это класс-меньшинство.
Нужно определить желаемую пропорцию между классами после применения Random Oversampling. Например, если у вас есть 100 экземпляров класса-меньшинства и 1000 экземпляров класса-большинства, вы можете решить достичь пропорции 1:2. Для достижения желаемой пропорции нужно случайно выбирать экземпляры из класса-меньшинства и добавлять их в обучающий набор данных. Это делается с повторением, то есть один и тот же экземпляр может быть выбран несколько раз.
И так продолжать добавлять случайно выбранные экземпляры до тех пор, пока не будет достигнута желаемая пропорция между классами. После выполнения Random Oversampling мы можем начать обучать нашу модельку на сбалансированных данных.
Random oversampling — это метод обработки данных, который увеличивает количество экземпляров в классе с меньшим представительством путём случайного дублирования образцов из этого класса. Это часто используется в ситуациях, когда данные несбалансированы, то есть один класс значительно менее представлен, чем другой.
Давайте создадим выдуманную задачу и рассмотрим пять различных способов её решения с помощью random oversampling в Python.
Допустим, у нас есть набор данных для задачи бинарной классификации с двумя классами: Класс 0 и Класс 1. Класс 0 значительно больше представлен, чем Класс 1. Наша задача — увеличить количество образцов в Классе 1 так, чтобы количество образцов в обоих классах стало приблизительно равным.
Генерация синтетических данных
Алгоритмы Генерации
SMOTE
SMOTE начинает с выбора случайного образца из меньшинства класса.
Для каждого образца алгоритм находит K ближайших соседей в пространстве признаков. Это значение K обычно задается пользователем (часто K=5). Случайно выбирается один из K ближайших соседей.
Создается синтетический образец, который находится на линии, соединяющей выбранный образец и его случайно выбранного соседа. Расстояние от исходного образца до синтетического определяется случайным образом.
Пусть x - исходный образец, xсосед - выбранный сосед, а xсинт - синтетический образец.
Синтетический образец создается по формуле:
где δ - случайное число в интервале [0, 1].
SMOTE первоначально разработан для работы с числовыми данными. Для категориальных данных требуются модификации алгоритма, например, SMOTE-NC (Non-Continuous).
Большее значение K может привести к большей разнообразности синтетических данных, но также может увеличить риск создания менее релевантных образцов.
ADASYN
Для каждого образца из меньшинства классов алгоритм оценивает, насколько сложно его классифицировать. Это обычно делается путем измерения количества образцов из доминирующего класса в его ближайшем окружении (например, среди K ближайших соседей).
На основе оценки сложности, каждому образцу из меньшинства классов присваивается вес, отражающий его важность в процессе генерации новых данных.
ADASYN генерирует больше синтетических данных для тех образцов, которые считаются более сложными для классификации. Процесс создания синтетических данных аналогичен SMOTE, но учитывает распределение весов.
Как и в SMOTE, синтетические образцы создаются путем линейной интерполяции между выбранным образцом и его случайно выбранным ближайшим соседом из меньшинства класса.
ADASYN, как и SMOTE, лучше всего работает с числовыми данными. Для категориальных данных потребуются модификации алгоритма.
Методы Undersampling
Случайное удаление данных (Random Undersampling)
В задачах классификации классы могут иметь разное количество примеров, и это может привести к смещению в обучении модели. Модель, обученная на несбалансированных данных, может иметь тенденцию предсказывать больший класс, игнорируя меньший.
Random Undersampling решает эту проблему, уменьшая количество экземпляров большего класса до уровня меньшего класса. Процесс заключается в случайном удалении части примеров из большего класса до достижения желаемого баланса.
Сначала нужно подготовить данные, должны быть размеченные данные с несбалансированными классами.
Надо оценить, насколько несбалансированными являются ваши классы. Это можно сделать, рассчитав отношение размера большего класса к размеру меньшего класса.
Следующий шаг это случайное удаление примеров из большего класса так, чтобы достичь желаемого баланса. Это может быть достигнуто путем случайного выбора примеров для удаления до тех пор, пока размер большего класса не сравняется с размером меньшего класса.
Для примера сгенерируем несбалансированный набор данных и применим к нему случайное удаление данных.:
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from imblearn.under_sampling import RandomUnderSampler
# Генерация синтетического набора данных
# Уменьшаем количество информативных признаков и убираем избыточные и повторяющиеся признаки
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=2, n_redundant=0, flip_y=0,
n_features=2, n_clusters_per_class=1,
n_samples=1000, random_state=10)
# визуализируем
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], label="Класс 0")
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], label="Класс 1")
plt.title("Исходный набор данных")
plt.xlabel("Характеристика 1")
plt.ylabel("Характеристика 2")
plt.legend()
# случ удаление данных
rus = RandomUnderSampler(random_state=42)
X_res, y_res = rus.fit_resample(X, y)
#визуализация данных после удаления
plt.subplot(1, 2, 2)
plt.scatter(X_res[y_res == 0][:, 0], X_res[y_res == 0][:, 1], label="Класс 0")
plt.scatter(X_res[y_res == 1][:, 0], X_res[y_res == 1][:, 1], label="Класс 1")
plt.title("Набор данных после Random Undersampling")
plt.xlabel("Характеристика 1")
plt.ylabel("Характеристика 2")
plt.legend()
plt.tight_layout()
plt.show()
Tomek Links
Tomek Links идентифицирует пары близких соседей, в которых один пример принадлежит классу меньшинства, а другой - классу большинства. Такие пары соседей называются Tomek Links. После их идентификации удаляется пример из класса большинства, что помогает уменьшить дисбаланс данных.
Процесс начинается с предварительной подготовки данных, должны быть размеченные данные с несбалансированными классами.
Для каждого примера данных мы вычисляем расстояния до всех остальных примеров. Затем для каждого примера из класса меньшинства мы ищем его ближайшего соседа из класса большинства и наоборот. Если расстояние между этими двумя примерами минимальное, они образуют Tomek Link.
После того как все Tomek Links были идентифицированы, мы удаляем примеры, которые находятся на концах этих связей из класса большинства. Это может быть сделано путем создания нового набора данных без этих точек.
С комбинацией с другими методами андерсемплинга можно реализовать так:
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=42)
X_res_rus, y_res_rus = rus.fit_resample(X, y)
tl = TomekLinks()
X_res_final, y_res_final = tl.fit_resample(X_res_rus, y_res_rus)
# Визуализация
plt.figure(figsize=(18, 6))
plt.subplot(1, 3, 1)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title("Исходные данные")
plt.subplot(1, 3, 2)
plt.scatter(X_res_rus[:, 0], X_res_rus[:, 1], c=y_res_rus)
plt.title("После Random Undersampling")
plt.subplot(1, 3, 3)
plt.scatter(X_res_final[:, 0], X_res_final[:, 1], c=y_res_final)
plt.title("После применения Tomek Links")
plt.show()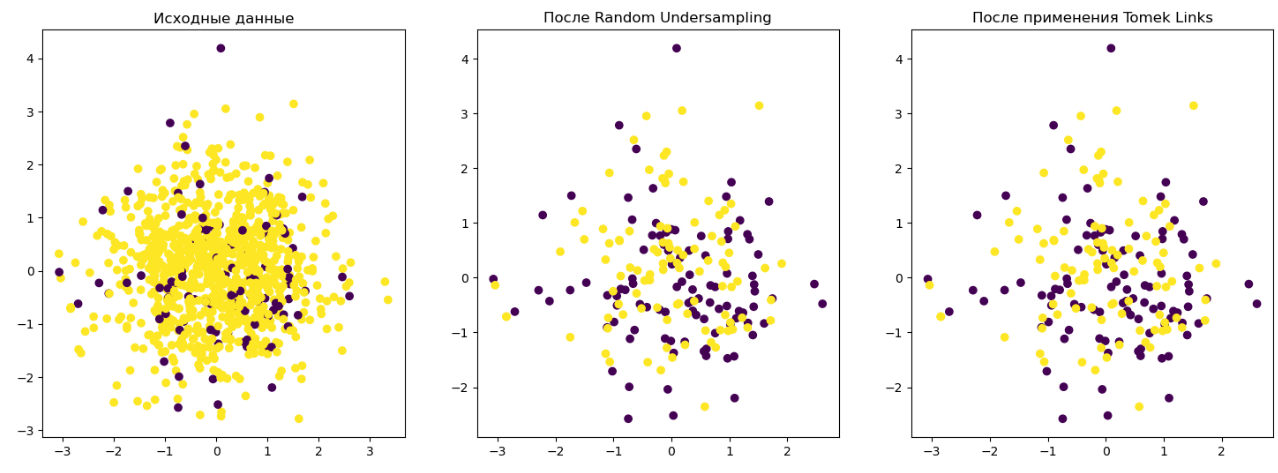
Сравнение Oversampling и Undersampling
Параметр / Метод |
Oversampling |
Undersampling |
|---|---|---|
Определение |
Увеличение количества образцов в менее представленном классе. |
Уменьшение количества образцов в более представленном классе. |
Цель |
Увеличить представленность редких классов. |
Уменьшить представленность доминирующих классов. |
Методы |
Synthetic Minority Over-sampling Technique (SMOTE), Adaptive Synthetic (ADASYN) |
Random Undersampling, Tomek Links, Cluster Centroids |
Преимущества |
Предотвращает потерю важной информации. Повышает разнообразие обучающих примеров. |
Уменьшает время обучения. Снижает риск переобучения на доминирующих классах. |
Недостатки |
Может привести к переобучению. Увеличивает время обучения. |
Может привести к потере важной информации. Уменьшает количество доступных данных для обучения. |
Применение |
Лучше подходит, когда количество данных ограничено. |
Предпочтительно, когда имеется большой объем данных. |
Примеры Использования |
Маленькие наборы данных, несбалансированные медицинские данные. |
Большие наборы данных, как в кредитном скоринге. |
Риски |
Синтетические данные могут не всегда адекватно отражать реальность. |
Возможность игнорирования важных шаблонов в данных. |
Выбор между oversampling и undersampling зависит от конкретной задачи, объема данных и их характеристик.
Больше практических навыков по работе с данными и машинному обучению можно получить в рамках онлайн-курсов. Заходите в каталог и выбирайте заинтересовавшее вас направление. А в календаре мероприятий вы сможете зарегистрироваться на бесплатные вебинары заинтересовавших курсов.