
Недавно я купил б/у RTX 3090 для экспериментов с обучением нейронных сетей и выяснил, что карта сильно нагревается и потребляет много энергии.
Стоковый power limit составляет 390 Вт, но может быть увеличен до 480 Вт. GPU выделяет так много тепла, что начинает нагревать CPU.
Основным методом снижения нагрева является понижение напряжения (undervolting):
меньше напряжение => меньше мощность => меньше нагрев.
К сожалению, драйверы NVIDIA под Linux не поддерживают понижение напряжения. Поэтому единственным вариантом остается понижение лимита мощности (power limit).
Power limit - это максимальное количество энергии, которое может потреблять GPU. Этот предел поддерживается автоматически путем регулировки частот и напряжений, чтобы энергопотребление оставалось ниже указанного предела. Я снизил power limit до 250 Вт, и производительность упала не так сильно, как я ожидал. Я решил исследовать, как ограничение мощности влияет на различные DL задачи:
-
Training:
fp32
tf32
amp fp16
fp16 (.half())
-
Inference:
fp32
tf32
amp fp16
fp16 (.half())
TensorRT fp16
Все тесты проводились на vit_base_patch16_224 из библиотеки timm.
fp32 training batch_size=160 approx. 20GB of VRAM


280 Вт => 80 процентов от пиковой производительности (при 480Вт)
330 Вт => 90 процентов
380 Вт => 95 процентов
tf32
Написав
torch.backends.cuda.matmul.allow_tf32 = Trueмы можем указать pytorch использовать режим вычислений TF32. По сути, мы можем пожертвовать частью точности fp32, чтобы получить более быстрые матричные операции. Изображения ниже описывают, как это работает, и взяты из статьи в блоге NVIDIA. Операции TF32 могут быть ускорены Тензорными ядрами (Tensor Cores).

 с использованием TF32")
tf32 training batch_size=160 approx. 20GB of VRAM


230 Вт => 80 процентов от пиковой производительности (при 480Вт)
280 Вт => 90 процентов
320 Вт => 95 процентов
Как мы видим, тензорные ядра не только быстрее, но и гораздо более энергоэффективны.
amp (fp16)
С помощью torch.autocast мы можем указать pytorch использовать fp16 вместо fp32 для некоторых операций. Список операций можно посмотреть здесь. И снова мы обмениваем точность на производительность. Мы видим, что некоторые операции, такие как matmul, conv2d, автокастятся в fp16, но операции, требующие большей точности, такие как sum, pow, функции потерь и нормализации, автокастятся fp32.
С использованием fp16 есть одна проблема: иногда градиенты настолько малы, что не могут быть представлены в fp16 и округляются до нуля.
нулевой градиент =>нулевое обновление весов => обучение не происходит.
Поэтому мы умножаем значения функции потерь на коэффициент масштабирования (который оценивается автоматически), чтобы после backward pass получить ненулевые значения градиента.
Прежде чем использовать градиенты для обновления весов, мы конвертируем их в fp32 и убираем ранее примененное масштабирование, чтобы оно не влияло на скорость обучения (градиенты умножаются на learning rate, и если мы не уберем масштабирование, то реальный learning rate будет отличаться от заданного).
Если соблюдены определенные критерии, такие как версия cuBLAS/cuDNN и размерности матриц, операции будут выполняться тензорными ядрами. Критерии можно найти на слайдах от NVIDIA (стр. 18-19).
for images, labels in zip(data, targets):
optimizer.zero_grad()
with autocast(device_type='cuda', dtype=torch.float16):
outputs = model.forward(images)
loss = criterion(outputs,labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()amp (fp16) training batch_size=160 approx. 13GB of VRAM


250 Вт => 80 процентов от пиковой производительности (при 480Вт)
300 Вт => 90 процентов
350 Вт => 95 процентов
Энергоэффективность немного хуже, чем у tf32, потому что некоторые операции выполняются в fp32 и не используют тензорные ядра.
fp16 (.half())
Используя .half() на наших данных и модели, мы преобразуем их в fp16. Это быстрее, чем amp, но приводит к нестабильному обучению и может привести к большому количеству NaN'ов.
fp16 (.half()) training batch_size=160 approx. 11GB of VRAM


200 Вт => 80 процентов от пиковой производительности (при 480Вт)
230 Вт => 90 процентов
270 Вт => 95 процентов
Это наиболее энергоэффективное решение: мы вообще не используем fp32.
Теперь рассмотрим inference.
fp32 inference batch_size=2048 approx. 21GB of VRAM


290 Вт => 80 процентов от пиковой производительности (при 480Вт)
350 Вт => 90 процентов
390 Вт => 95 процентов
tf32 inference batch_size=2048 approx. 21GB of VRAM


250 Вт => 80 процентов от пиковой производительности (при 480Вт)
300 Вт => 90 процентов
350 Вт => 95 процентов
amp (fp16) inference batch_size=2048 approx. 16GB of VRAM


260 Вт => 80 процентов от пиковой производительности (при 480Вт)
310 Вт => 90 процентов
360 Вт => 95 процентов
fp16 (.half()) inference batch_size=2048 approx. 11GB of VRAM


260 Вт =>80 процентов от пиковой производительности (при 480Вт)
310 Вт => 90 процентов
360 Вт => 95 процентов
TensorRT
Мы можем использовать фреймворк TensorRT для дальнейшей оптимизации нашего инференса.
В следующих экспериментах мы конвертируем нашу модель в onnx, оптимизируем его, преобразуем onnx в TensorRT и затем преобразуем модель TensorRT в pytorch jit. На данный момент преобразование модели pytorch сразу в TensorRT не работает для ViT, подробнее в этом issue.
TensorRT fp16 vs pytorch fp16 (.half()) batch_size=512
Batch size = 512, потому что не хватило VRAM для генерации TensorRT модели, которая поддерживает бОльший батч.
.half()
260 Вт => 82 процента от пиковой производительности (при 480Вт)
310 Вт => 90 процентов
360 Вт => 95 процентов
TensorRT fp16
290 Вт => 81 процент от пиковой производительности (при 480Вт)
340 Вт => 90 процентов
390 Вт => 95 процентов



Общие графики

")

")
Выводы
Если хотите чтобы GPU нагревался меньше:
используйте более низкую точность. Это не только быстрее, но и кривая производительность/мощность насыщается быстрее, а значит, вы можете снизить power limit без особого ущерба для производительности.
330-360 Вт - хороший диапазон для power limit. Может показаться, что отличие от стокового power limit незначительно, но даже такое уменьшение может заставить GPU работать немного прохладнее (3-5 градусов Цельсия) и уменьшить RPM вентиляторов.
В реальности прирост может быть еще больше. Например, сейчас я делаю инференс DDPM модели, и снижение power limit с 390 Вт до 300 Вт снижает скорость лишь на 8 процентов, причем утилизация GPU 100%.
Код для всех экспериментов можно найти на Github
Комментарии (14)

melodictsk
08.01.2024 16:26+2А изменение частоты памяти? В майнинге часто уменьшение частоты памяти даёт увеличение производительности. Связано с уменьшением задержек (таймингом). А алгоритмам, которые требуют больших последовательных обращений, наоборот необходим разгон.

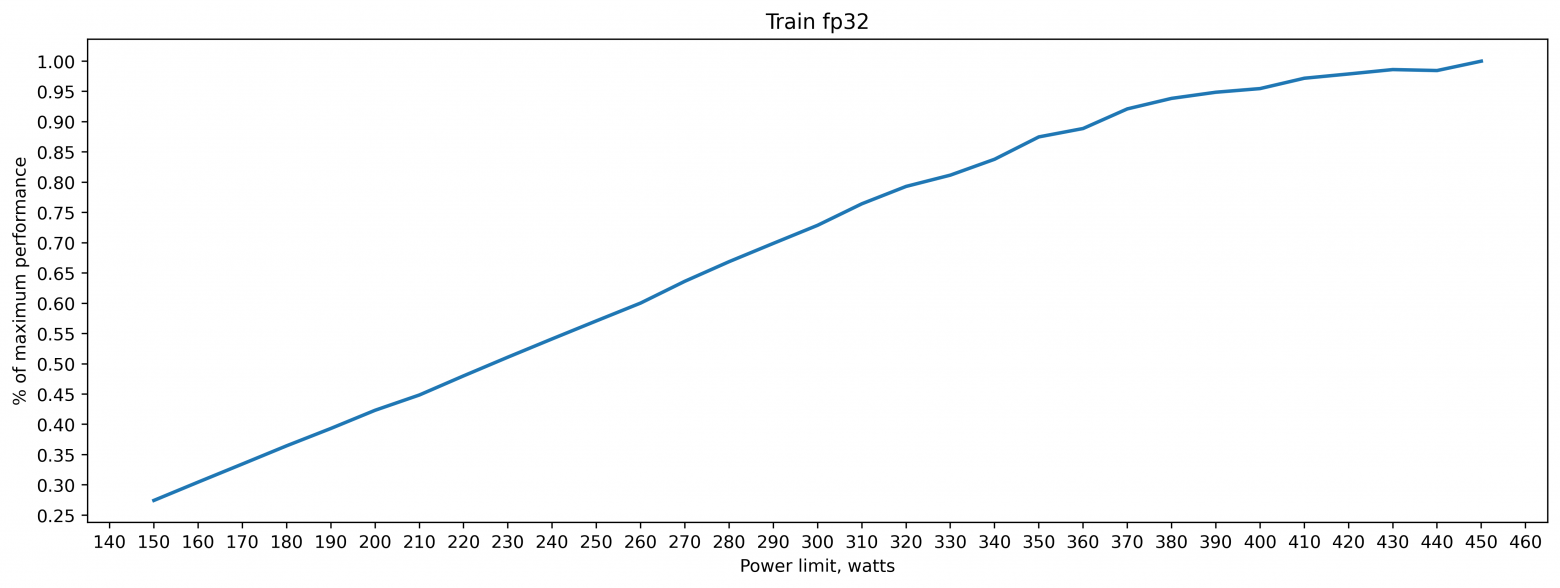
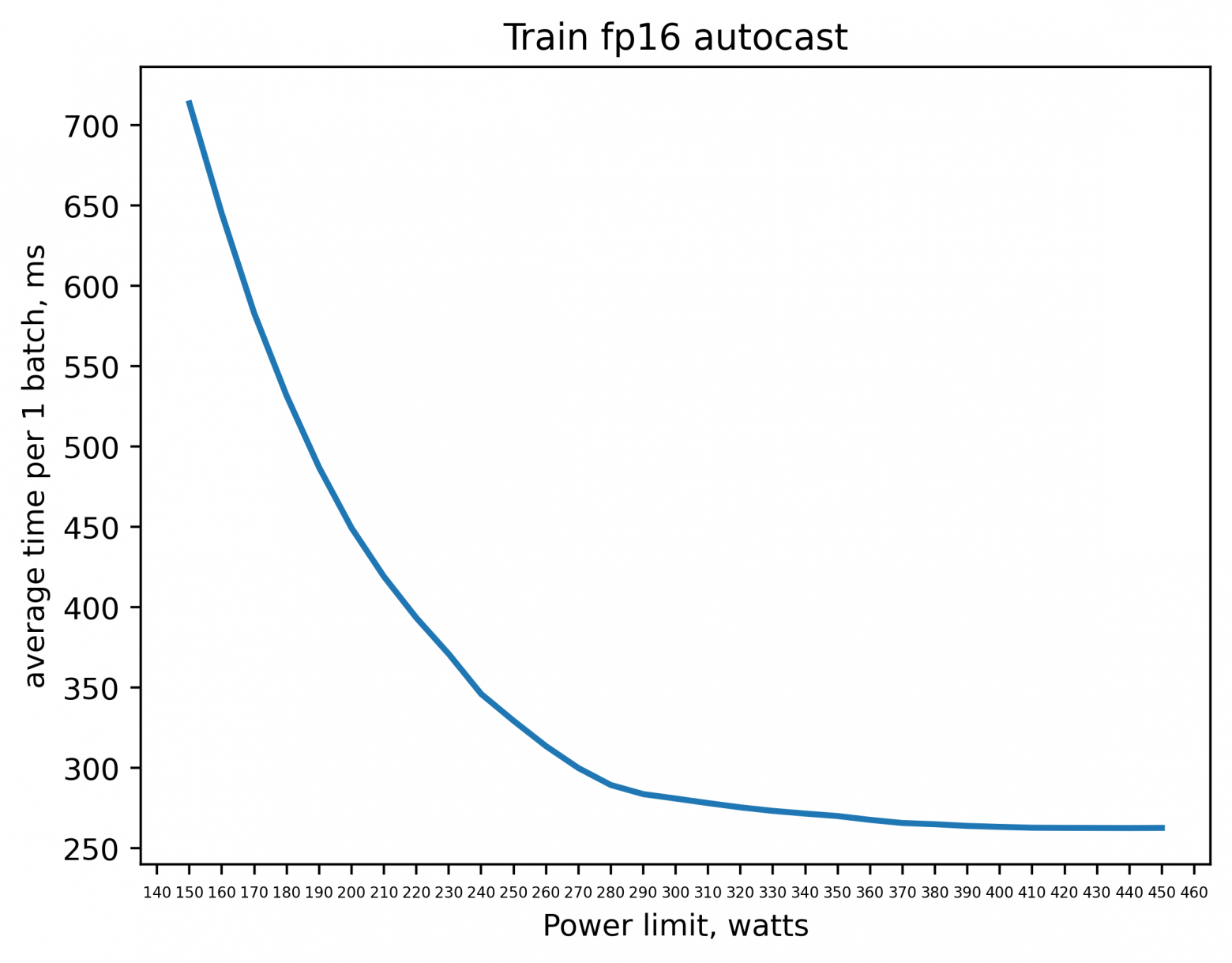
iiiytn1k
08.01.2024 16:26+5Прогнал несколько тестов на 4090:
Train fp32

Train tf32


Train fp16 amp

Train fp16 half



Интересно, что кривые tf32 и fp16 amp практически одинаковые.
Текстовые результаты
fp32_train = [(150, 1916.85302734375), (160, 1726.422119140625), (170, 1572.1138916015625), (180, 1442.38671875), (190, 1337.249755859375), (200, 1242.3446044921875), (210, 1172.5013427734375), (220, 1095.2509765625), (230, 1029.110595703125), (240, 971.7257690429688), (250, 921.0980224609375), (260, 875.9171752929688), (270, 826.3692626953125), (280, 786.3384399414062), (290, 752.35595703125), (300, 721.5491943359375), (310, 688.0049438476562), (320, 663.115478515625), (330, 647.8905029296875), (340, 627.601806640625), (350, 601.1165161132812), (360, 591.7486572265625), (370, 570.9195556640625), (380, 560.3616333007812), (390, 554.3623657226562), (400, 550.8558349609375), (410, 541.1676025390625), (420, 537.27685546875), (430, 533.3079223632812), (440, 534.1802368164062), (450, 525.8939208984375)] tf32_train =[(150, 1130.47998046875), (160, 1045.67822265625), (170, 958.404052734375), (180, 872.135498046875), (190, 801.3380737304688), (200, 733.6597290039062), (210, 674.9171752929688), (220, 630.9574584960938), (230, 591.8206787109375), (240, 557.5418090820312), (250, 529.1500244140625), (260, 503.8023986816406), (270, 482.4733581542969), (280, 464.09136962890625), (290, 453.2052917480469), (300, 446.3533630371094), (310, 442.28253173828125), (320, 438.00335693359375), (330, 433.1138610839844), (340, 430.9553527832031), (350, 430.3887023925781), (360, 423.78192138671875), (370, 421.5494384765625), (380, 418.23504638671875), (390, 417.9413757324219), (400, 417.5173034667969), (410, 416.3753662109375), (420, 414.67138671875), (430, 414.67596435546875), (440, 415.1285095214844), (450, 415.0179443359375)] fp16_amp_train = [(150, 713.5382080078125), (160, 644.8378295898438), (170, 582.9127807617188), (180, 531.542724609375), (190, 487.0350646972656), (200, 449.3820495605469), (210, 419.1130065917969), (220, 393.4111633300781), (230, 370.9094543457031), (240, 346.04071044921875), (250, 329.3534851074219), (260, 313.56951904296875), (270, 299.94134521484375), (280, 289.3700866699219), (290, 283.7044982910156), (300, 281.9547424316406), (310, 278.1085205078125), (320, 275.4595947265625), (330, 273.2633972167969), (340, 271.5821228027344), (350, 270.0470886230469), (360, 266.6712646484375), (370, 265.72222900390625), (380, 264.9597473144531), (390, 263.90924072265625), (400, 263.3031921386719), (410, 262.78692626953125), (420, 262.68572998046875), (430, 262.64483642578125), (440, 262.59173583984375), (450, 262.6723327636719)] fp16_half_train = [(150, 432.8243103027344), (160, 380.8467712402344), (170, 346.6760559082031), (180, 312.84552001953125), (190, 287.2230529785156), (200, 266.4410400390625), (210, 248.6437225341797), (220, 235.57911682128906), (230, 225.4227752685547), (240, 218.5994415283203), (250, 215.1365509033203), (260, 212.386962890625), (270, 210.07582092285156), (280, 208.22596740722656), (290, 206.6107177734375), (300, 205.4788055419922), (310, 204.30592346191406), (320, 203.26885986328125), (330, 202.8826904296875), (340, 202.81948852539062), (350, 202.8431396484375), (360, 202.87684631347656), (370, 202.7930450439453), (380, 202.87242126464844), (390, 202.78543090820312), (400, 202.8188934326172), (410, 202.78146362304688), (420, 202.84884643554688), (430, 202.83177185058594), (440, 202.92153930664062), (450, 203.05181884765625)]В прикладных задачах (инференс и обучение лор/dreambooth в SD, обучение моделей RVC (в большинстве случаев работа с fp16 и bf16)) работаю с лимитом мощности в 70%. Разница в производительности по сранению со стоковыми 450 Вт на уровне погрешности, но при этом тепловыделение меньше на 135 Вт, что даёт снижение температуры GPU на 10 градусов.

qwertyforce Автор
08.01.2024 16:26+1Спасибо за тесты!
А когда fp16 amp тестили, там tf32 было выключено?










hardtop
08.01.2024 16:26+2Полезное исследование. Я даже свою 3060 переодически ограничиваю по ТДП. А тут столько мощи при 250 Вт. Тоже задумался о 3090.

Slava715
08.01.2024 16:26+2"К сожалению, драйверы NVIDIA под Linux не поддерживают понижение напряжения. Поэтому единственным вариантом остается понижение лимита мощности (power limit)."
Можно снизить напряжение так:
nvidia-settings -a /GPUGraphicsClockOffsetAllPerformanceLevels=100qwertyforce Автор
08.01.2024 16:26+1конкретно эта команда увеличит clock на 100, но да, есть такой метод, но он довольно костыльный
как я понял суть такая: сделать power limit, и затем разогнать частоты.
Мне он не понравился, решил просто лимит понижатьSlava715
08.01.2024 16:26+1Да, так и есть, карта будет упираться в максимальные частоты.
Забыл добавить что вместе с этим можно зафиксировать максимальные частоты:
nvidia-smi -pm 1
nvidia-smi -lgc 100, 2000

snakers4
08.01.2024 16:26+1Стоковый power limit составляет 390 Вт, но может быть увеличен до 480 Вт. GPU выделяет так много тепла, что начинает нагревать CPU.
Правильно понимаю, что у вас карты не выбрасывают воздух наружу?
subprocess.run(["nvidia-smi","-pl",str(pwr)])
Это делать надо делать просто при каждой загрузке?
qwertyforce Автор
08.01.2024 16:26+1>Правильно понимаю, что у вас карты не выбрасывают воздух наружу?
Выбрасывают, но окружение все равно нагревается
>Это делать надо делать просто при каждой загрузке?
ага, или можно какой-нибудь сервис сделать для systemd, чтобы он при загрузке запускалсяsnakers4
08.01.2024 16:26+1Прикольно. Проблемы со сбросом тепла у нас не стоит, но запомню, слышал про эту фишулю, но пока надобности не было тестить.
kovserg
А вариант улучшить теплоотвод не рассматривали?
hardtop
Корпус должен быть сильно продуваемым (сверзху вентиляторы на выдув), да и всё равно видюшка дует прямо в кулер проца. Так что часто надо ставить водянку на проц. Да и все равно вентили на 3090 будут шуметь, дабы отвести сво 400Вт тепла. Мне, например не сильна важно, за сколько там условный whisper сделает транскрибацию - за 2 мин или за 2.5 минут - зато тише.
qwertyforce Автор
В корпусе 3 вентилятора на вдув, 1 на выдув.
Поменял термопрокладки на Fehonda, термопасту на Thermal Grizzly Kryonaut Extreme
Стало лучше, но все равно слишком много тепла выделяется, решил понижать мощность
taktike
Имхо маловато, у меня 3080 под нагрузкой с такой конфигурацией как у вас (3 вдув - 1 выдув) грелась весьма хорошо, добавил сверху еще два вентилятора вдув-выдув (не уверен что оптимально) и стало сильно приятнее жить (на 10-15 градусов)