
В первой части я сказал, что хеш таблица это немного LIST, SET и SORTED SET. Судите сами — LIST состоит из ziplist/linkedlist, SET состоит из dict/intset, а SORTED SET это ziplist/skiplist. Мы уже рассмотрели словарь (dict), а во второй части статьи будем рассматривать структуру ziplist — вторую наиболее часто применимую структуру под капотом Redis. Посмотрим на LIST — вторая часть его «кухни» это простая реализация связного списка. Это пригодится нам, чтобы внимательно рассмотреть часто упоминаемый совет об оптимизацию хеш таблиц через их замену на списки. Посчитаем сколько памяти требуется на накладные расходы при использовании этих структур, какую цену вы платите за экономию памяти. Подведём итоги при работе с хеш таблицами, при использовании кодировки в ziplist.
В прошлый раз мы закончили на том, что сохранённые с использованием ziplist 1,000,000 ключей заняли 16 мб оперативной памяти, тогда как в dict эти же данные потребовали 104 мб (ziplist в 6 раз меньше!). Давайте разбираться какой ценой:

Итак, ziplist — это двусвязный список. В отличие от обычного связного списка, здесь ссылки в каждом узле указывают на предыдущий и на последующий узел в списке. По двусвязному списку можно эффективно передвигаться в любом направлении — как к началу, так и к концу. В этом списке проще производить удаление и перестановку элементов, так как легко доступны адреса тех элементов списка, указатели которых направлены на изменяемый элемент. Разработчики Redis позиционируют свою реализацию как эффективную с точки зрения памяти. Список умеет хранить строки и целые числа, при этом числа хранятся именно в виде чисел, а не redisObject со значением. А если вы захотите сохранить строку «123» она будет сохранения как число 123, а не последовательность символов `1`,`2`,`3`.
Ключ и значения хранятся как расположенные один за одним элементы списка. Операции над списком это поиск ключа, через перебор и работа со значением, которое расположено в следующем элементе списка. Теоретически операции вставки и изменения выполняются за константное O(1). Фактически же любая такая операция в реализации Redis требует выделения и перераспределения памяти и реальная сложность напрямую зависит от количества уже использованной памяти. В данном случае помним про O(1) как идеальный случай и O(n) — как худший.
Давайте посчитаем её размер.
С заголовком всё просто — это ZIPLIST_HEADER_SIZE (константа, определена в ziplist.c и равна sizeof(uint32_t) * 2 + sizeof(uint16_t) + 1). Размер элемента — 5 * size_of(unsigned int) + 1 + 1не менее 1 байта на значение. Общий оверхед на хранение данных в такой кодировке для n элементов (без учёта значения):
Каждый элемент начинается с фиксированного заголовка, состоящего из нескольких фрагментов с информацией. Первый — размер предыдущего элемента и используется для перехода назад по двусвязному списку. Второй, кодировка с опциональной длиной самой структуры в байтах. Длина предыдущего элемента работает следующим образом: если длина не превышает 254 байта (она же константа ZIP_BIGLEN) то будет использован 1 байт для хранения длины значения. Если длина превышает или равна 254, будет использовано 5 байт. При этом первый байт будет установлен в константное значение ZIP_BIGLEN, чтобы мы понимали, что у нас длинное значение. Оставшиеся 4 байта хранят длину предыдущего значения. Третий — заголовок, который зависит от содержащегося в узле значения. Если значение строка — 2 первых бита заголовка поля заголовка будут хранить тип кодировки для длины строки, с последующим числом с длиной строки. Если значние — целочисленное, первые 2 бита будет выставлены в единицу. Для чисел используется ещё 2 бита, которые определяют, какой размерности целое в нём хранится.
Проверим и посмотрим на оборотную сторону сторону медали. Мы будем использовать LUA, так что вам не потребуется ничего кроме Redis, чтобы повторить этот тест самостоятельно. Сначала смотрим, что получается при использовании dict.
Выполним
и
В случае с encoding:hashtable (dict) затратили ~516 кб памяти и 18,9 мс на сохранение 10,000 значений, 7,5 мс на их чтение. С encoding:ziplist получаем ~81 кб памяти и 710 мс на сохранение, 705 мс на чтение. Для теста в 10,000 записей получили:
При этом важно понимать, что падение производительности не линейное и уже для 1,000,000 вы рискуете просто не дождаться итогов. Кто станет складывать в ziplist 10,000 элементов? Это, к несчастью, одна из первых рекомендаций от большинства консультантов. Когда игра ещё стоит свеч? Я бы сказал, что пока количество элементов лежит в диапазоне 1 — 3500 элементов вы можете выбирать, помня, что по памяти у ziplist всегда выигрывает от 6 раз и выше. Всё что больше — измеряйте на своих реальных данных, но к нагруженным системам реального времени это уже не будет иметь никакого отношения. Вот что происходит с производительностью чтения/записи в зависимости от размера хеша на dict и ziplist(gist на тест):
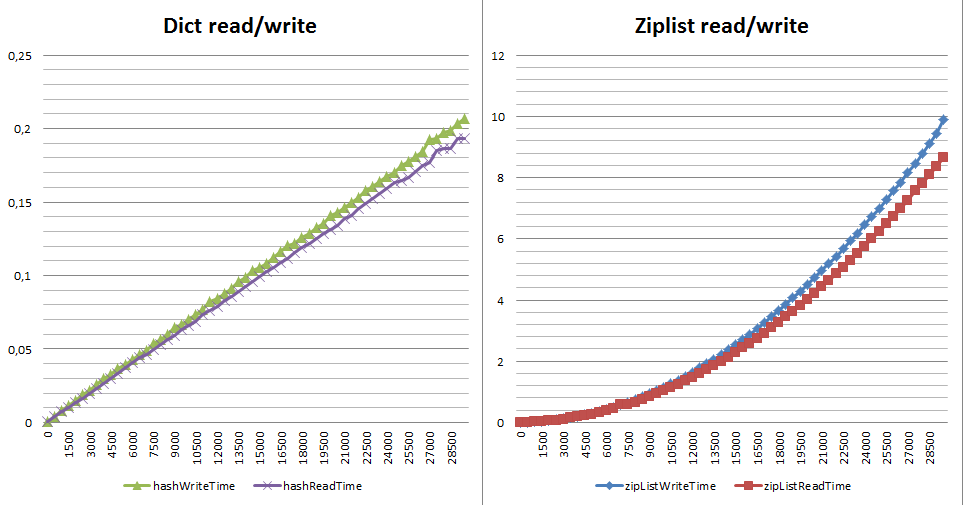
Почему так? Цена вставки, изменения длины элементов и удаления у ziplist чудовищная — это или realloc (вся работа ложиться на плечи аллокатора) или полное перестроение списка от n + 1 от изменённого элемента до конца списка. Перестроение — это очень много мелкофрагментных realloc, memmove, memcpy (см. __ziplistCascadeUpdate в ziplist.c).
Почему в статье про HASH важно поговорить про LIST? Дело в одном очень важном совете об оптимизации структурированных данных. Пошел он кажется от DataDog, точно сказать затрудняюсь. В переводе звучит так(оригинал):
И это весьма полезный совет. Очевидно, что список (LIST) поможет вам сильно сэкономить — минимум в 2 раз.
C ziplist мы уже разобрались, давайте смотреть REDIS_ENCODING_LINKEDLIST. В реализации Redis это очень простой(~270 строчек кода) не сортированный односвязный список (всё как в википедии). Со всеми его достоинствами и недостатками:
Ничего сложного — каждый LIST в такой кодировке это 5 указателей и 1 unsigned long. Так что накладные расходы это 5 * size_of(pointer) + 8 байт. А каждый узел это 3 указателя. Оверхед на хранение данных в такой кодировке для n элементов это:
В реализации linkedlist нет никаких realloc — только выделение памяти под нужный вам фрагмент, в значениях — redisObejct без каких либо хитростей и оптимизаций. По оверхеду памяти разница на служебные расходы между ziplist и linkedlist порядка 15%. Если рассматривать служебные данные плюс значения — в разы (от 2 и выше), в зависимости от типа значения. Так для списка в 10,000 элементов, состоящим только из цифр в ziplist вы потратите порядка 41 кб памяти, в linkedlist — 360 кб реальной памяти:
Давайте посмотрим на разницу в производительности при записи и получении элемента через LPOP (прочитать и удалить). Почему не LRANGE — его сложность обозначена как O(S+N) и для обеих реализаций списка это время константно. С LPOP же всё не совсем как написано в документации — сложность обозначена как О(1). Но что произойдет, если мне потребуется последовательное чтение чтобы считать всё:
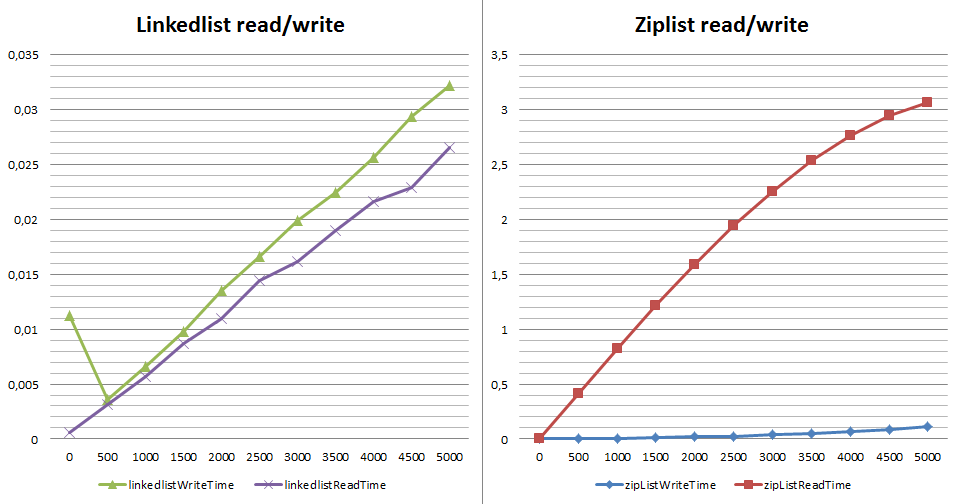
Что не так со скоростью чтения при использовании ziplist? Каждый `LPOP` — извлечение элемента c начала списка с его полным перестроением. К слову, если мы используем на чтении RPOP, вместо LPOP — ситуация не сильно изменится (привет realloc`у из функции обновления списка в ziplist.c). Почему важно? Команды RPOPLPUSH/BRPOPLPUSH популярное решение при организации очередей на базе Redis(например Sidekiq, Resque). Когда в такой очереди с кодировкой ziplist оказывает большое число значение (от нескольких тысяч) — получение одного элемента уже не константно и систему начинает «лихорадить».
В завершении пришла пора сформулировать несколько выводов:
Оглавление:
Материалы, использованные при написании статьи:
В прошлый раз мы закончили на том, что сохранённые с использованием ziplist 1,000,000 ключей заняли 16 мб оперативной памяти, тогда как в dict эти же данные потребовали 104 мб (ziplist в 6 раз меньше!). Давайте разбираться какой ценой:
Итак, ziplist — это двусвязный список. В отличие от обычного связного списка, здесь ссылки в каждом узле указывают на предыдущий и на последующий узел в списке. По двусвязному списку можно эффективно передвигаться в любом направлении — как к началу, так и к концу. В этом списке проще производить удаление и перестановку элементов, так как легко доступны адреса тех элементов списка, указатели которых направлены на изменяемый элемент. Разработчики Redis позиционируют свою реализацию как эффективную с точки зрения памяти. Список умеет хранить строки и целые числа, при этом числа хранятся именно в виде чисел, а не redisObject со значением. А если вы захотите сохранить строку «123» она будет сохранения как число 123, а не последовательность символов `1`,`2`,`3`.
В ветке 1.х Redis вместо dict в словаре использовался zipmap — незамысловатая (~140 строк) реализация связного списка, оптимизированная на экономию памяти, где все операции занимают O(n). Эта структура не используется в Redis (хоть и находится в его исходниках и поддерживается в актуальном состоянии), при этом часть идей zipmap легли в основу ziplist.
Ключ и значения хранятся как расположенные один за одним элементы списка. Операции над списком это поиск ключа, через перебор и работа со значением, которое расположено в следующем элементе списка. Теоретически операции вставки и изменения выполняются за константное O(1). Фактически же любая такая операция в реализации Redis требует выделения и перераспределения памяти и реальная сложность напрямую зависит от количества уже использованной памяти. В данном случае помним про O(1) как идеальный случай и O(n) — как худший.
+-------------+------+-----+-------+-----+-------+-----+
| Total Bytes | Tail | Len | Entry | ... | Entry | End |
+-------------+------+-----+-------+-----+-------+-----+
^
|
+-------------------+--------------+----------+------+-------------+----------+-------+
| Prev raw len size | Prev raw len | Len size | Len | Header size | Encoding | Value |
+-------------------+--------------+----------+------+-------------+----------+-------+
Посмотрите на эту структуру в исходниках
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
typedef struct zlentry {
unsigned int prevrawlensize, prevrawlen;
unsigned int lensize, len;
unsigned int headersize;
unsigned char encoding;
unsigned char *p;
} zlentry;
Давайте посчитаем её размер.
Ответ на вопрос сколько памяти будет использовано на самом деле, зависит от операционной системы, компилятора, типа вашего процесса и используемого аллокатора(в redis по умолчанию jemalloc). Все дальнейшие расчёты я привожу для redis 3.0.5 собранном на 64 битном сервере под управлением centos 7.
С заголовком всё просто — это ZIPLIST_HEADER_SIZE (константа, определена в ziplist.c и равна sizeof(uint32_t) * 2 + sizeof(uint16_t) + 1). Размер элемента — 5 * size_of(unsigned int) + 1 + 1не менее 1 байта на значение. Общий оверхед на хранение данных в такой кодировке для n элементов (без учёта значения):
12 + 21 * n
Каждый элемент начинается с фиксированного заголовка, состоящего из нескольких фрагментов с информацией. Первый — размер предыдущего элемента и используется для перехода назад по двусвязному списку. Второй, кодировка с опциональной длиной самой структуры в байтах. Длина предыдущего элемента работает следующим образом: если длина не превышает 254 байта (она же константа ZIP_BIGLEN) то будет использован 1 байт для хранения длины значения. Если длина превышает или равна 254, будет использовано 5 байт. При этом первый байт будет установлен в константное значение ZIP_BIGLEN, чтобы мы понимали, что у нас длинное значение. Оставшиеся 4 байта хранят длину предыдущего значения. Третий — заголовок, который зависит от содержащегося в узле значения. Если значение строка — 2 первых бита заголовка поля заголовка будут хранить тип кодировки для длины строки, с последующим числом с длиной строки. Если значние — целочисленное, первые 2 бита будет выставлены в единицу. Для чисел используется ещё 2 бита, которые определяют, какой размерности целое в нём хранится.
Расшифровка заголовка, для желающих заморочиться
| Как лежит | Что лежит | |
|---|---|---|
| |00pppppp| | 1 | Строка, значение который меньше или равно 63 байта (т.е. sds с REDIS_ENCODING_EMBSTR, см. первую часть серии) |
| |01pppppp|B1 байт| | 2 | Cтрока, значение который меньше или равно 16383 байт (14 бит) |
| 5 | Строка, значение который больше или равно 16384 байт | |
| |11000000| | 1 | Целое, int16_t (2 байта) |
| |11010000| | 1 | Целое, int32_t (4 байта) |
| |11100000| | 1 | Целое, int64_t (8 байт) |
| |11110000| | 1 | Целое со знаком, которое «влезет» в 24 бита (3 байта) |
| |11111110| | 1 | Целое со знаком, которое «влезет» в 8 бит(1 байт) |
| |1111xxxx| | 1 | Где xxxx лежит между 0000 и 1101 означает целое, которые «влезет» в 4 бита. Без знаковое целое от 0 до 12. Декодированное значение по факту от 1 до 13, ведь 0000 и 1111 уже заняты и мы всегда вычитаем 1 из декодированного значения, чтобы получить искомое. |
| |11111111| | 1 | Маркер конца списка |
Проверим и посмотрим на оборотную сторону сторону медали. Мы будем использовать LUA, так что вам не потребуется ничего кроме Redis, чтобы повторить этот тест самостоятельно. Сначала смотрим, что получается при использовании dict.
Выполним
multi
time
eval "for i=0,10000,1 do redis.call('hset', 'test', i, i) end" 0
time
и
multi
time
eval "for i=0,10000,1 do redis.call('hget', 'test', i) end" 0
time
Вывод из redis=cli
config set hash-max-ziplist-entries 1
+OK
config set hash-max-ziplist-value 1000000
+OK
flushall
+OK
info memory
$225
# Memory
used_memory:508536
multi
+OK
time
+QUEUED
eval "for i=0,10000,1 do redis.call('hset', 'test', i, i) end" 0
+QUEUED
time
+QUEUED
exec
*3
*2
$10
1449161639
$6
948389
$-1
*2
$10
1449161639
$6
967383
debug object test
+Value at:0x7fd9864d6470 refcount:1 encoding:hashtable serializedlength:59752 lru:6321063 lru_seconds_idle:23
info memory
$226
# Memory
used_memory:1025432
multi
+OK
time
+QUEUED
eval "for i=0,10000,1 do redis.call('hget', 'test', i) end" 0
+QUEUED
time
+QUEUED
exec
*3
*2
$10
1449161872
$6
834303
$-1
*2
$10
1449161872
$6
841819
flushall
+OK
info memory
$226
# Memory
used_memory:510152
config set hash-max-ziplist-entries 100000
+OK
multi
+OK
time
+QUEUED
eval "for i=0,10000,1 do redis.call('hset', 'test', i, i) end" 0
+QUEUED
time
+QUEUED
exec
*3
*2
$10
1449162574
$6
501852
$-1
*2
$10
1449162575
$6
212671
debug object test
+Value at:0x7fd9864d6510 refcount:1 encoding:ziplist serializedlength:59730 lru:6322040 lru_seconds_idle:19
info memory
$226
# Memory
used_memory:592440
multi
+OK
time
+QUEUED
eval "for i=0,10000,1 do redis.call('hget', 'test', i) end" 0
+QUEUED
time
+QUEUED
exec
*3
*2
$10
1449162616
$6
269561
$-1
*2
$10
1449162616
$6
975149
В случае с encoding:hashtable (dict) затратили ~516 кб памяти и 18,9 мс на сохранение 10,000 значений, 7,5 мс на их чтение. С encoding:ziplist получаем ~81 кб памяти и 710 мс на сохранение, 705 мс на чтение. Для теста в 10,000 записей получили:
Выигрыш по памяти в 6 раз ценой проседания по скорости записи в 37,5 раз и в 94 раза по чтению.
При этом важно понимать, что падение производительности не линейное и уже для 1,000,000 вы рискуете просто не дождаться итогов. Кто станет складывать в ziplist 10,000 элементов? Это, к несчастью, одна из первых рекомендаций от большинства консультантов. Когда игра ещё стоит свеч? Я бы сказал, что пока количество элементов лежит в диапазоне 1 — 3500 элементов вы можете выбирать, помня, что по памяти у ziplist всегда выигрывает от 6 раз и выше. Всё что больше — измеряйте на своих реальных данных, но к нагруженным системам реального времени это уже не будет иметь никакого отношения. Вот что происходит с производительностью чтения/записи в зависимости от размера хеша на dict и ziplist(gist на тест):
Почему так? Цена вставки, изменения длины элементов и удаления у ziplist чудовищная — это или realloc (вся работа ложиться на плечи аллокатора) или полное перестроение списка от n + 1 от изменённого элемента до конца списка. Перестроение — это очень много мелкофрагментных realloc, memmove, memcpy (см. __ziplistCascadeUpdate в ziplist.c).
Почему в статье про HASH важно поговорить про LIST? Дело в одном очень важном совете об оптимизации структурированных данных. Пошел он кажется от DataDog, точно сказать затрудняюсь. В переводе звучит так(оригинал):
Вы храните в Redis данные своих пользователей, например `hmset user:123 id 123 firstname Иван lastname Иванов location Томск twitter ivashka`. Теперь, если создать ещё одного пользователя, вы в пустую потратите память на имена полей — id, firstname, lastname и т.д. Если таких пользователей много — это много выкинутой памяти (мы уже имеем считать сколько — для этого набора полей 384 байта на одного пользователя).
Итак, если у вас
- У вас много объектов, скажем от 50,000 и выше.
- Ваши объекты имеют регулярную структуру (по сути всегда все поля)
Можно воспользоваться концепцией именованных кортежей из питона — линейный список с доступом только на чтение, вокруг которого построить хеш таблицу «руками». Грубо говоря «fisrtname» — это значение по 0 индексу списка, «lastname» по первому и т.д. Тогда создание пользователя будет выглядеть как `lpush user:123 Иван Иванов Томск ivashka`.
И это весьма полезный совет. Очевидно, что список (LIST) поможет вам сильно сэкономить — минимум в 2 раз.
Как и в HASH — с помощью list-max-ziplist-entries/list-max-ziplist-val вы управляете каким внутренним типом данных будет представлен конкретный list ключ. Например, при list-max-ziplist-entries = 100 ваш LIST будет представлен как REDIS_ENCODING_ZIPLIST, пока в нём будет менее 100 элементов. Как только элементов станет больше, он будет конвертирован в REDIS_ENCODING_LINKEDLIST. Настройка list-max-ziplist-val работает аналогично hash-max-ziplist-val (см. первую часть).
C ziplist мы уже разобрались, давайте смотреть REDIS_ENCODING_LINKEDLIST. В реализации Redis это очень простой(~270 строчек кода) не сортированный односвязный список (всё как в википедии). Со всеми его достоинствами и недостатками:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
Ничего сложного — каждый LIST в такой кодировке это 5 указателей и 1 unsigned long. Так что накладные расходы это 5 * size_of(pointer) + 8 байт. А каждый узел это 3 указателя. Оверхед на хранение данных в такой кодировке для n элементов это:
5 * size_of(pointer) + 8 + n * 3 * size_of(pointer)
В реализации linkedlist нет никаких realloc — только выделение памяти под нужный вам фрагмент, в значениях — redisObejct без каких либо хитростей и оптимизаций. По оверхеду памяти разница на служебные расходы между ziplist и linkedlist порядка 15%. Если рассматривать служебные данные плюс значения — в разы (от 2 и выше), в зависимости от типа значения. Так для списка в 10,000 элементов, состоящим только из цифр в ziplist вы потратите порядка 41 кб памяти, в linkedlist — 360 кб реальной памяти:
config set list-max-ziplist-entries 1
+OK
flushall
+OK
info memory
$226
# Memory
used_memory:511544
eval "for i=0,10000,1 do redis.call('lpush', 'test', i) end" 0
$-1
debug object test
+Value at:0x7fd9864d6530 refcount:1 encoding:linkedlist serializedlength:29877 lru:6387397 lru_seconds_idle:5
info memory
$226
# Memory
used_memory:832024
config set list-max-ziplist-entries 10000000
+OK
flushall
+OK
info memory
$226
# Memory
used_memory:553144
eval "for i=0,10000,1 do redis.call('lpush', 'test', i) end" 0
$-1
info memory
$226
# Memory
used_memory:594376
debug object test
+Value at:0x7fd9864d65e0 refcount:1 encoding:ziplist serializedlength:79681 lru:6387467 lru_seconds_idle:16
Давайте посмотрим на разницу в производительности при записи и получении элемента через LPOP (прочитать и удалить). Почему не LRANGE — его сложность обозначена как O(S+N) и для обеих реализаций списка это время константно. С LPOP же всё не совсем как написано в документации — сложность обозначена как О(1). Но что произойдет, если мне потребуется последовательное чтение чтобы считать всё:
Что не так со скоростью чтения при использовании ziplist? Каждый `LPOP` — извлечение элемента c начала списка с его полным перестроением. К слову, если мы используем на чтении RPOP, вместо LPOP — ситуация не сильно изменится (привет realloc`у из функции обновления списка в ziplist.c). Почему важно? Команды RPOPLPUSH/BRPOPLPUSH популярное решение при организации очередей на базе Redis(например Sidekiq, Resque). Когда в такой очереди с кодировкой ziplist оказывает большое число значение (от нескольких тысяч) — получение одного элемента уже не константно и систему начинает «лихорадить».
В завершении пришла пора сформулировать несколько выводов:
- У вас не выйдет использовать ziplist в хеш таблицах с большим числом значений (от 1000), если вам всё ещё важна производительность при большом объеме записи.
- Если данные в вашей хеш таблице имеют регулярную структуры — забывайте про хеш таблицы и переходите к хранению данных в списках.
- Какой бы вид кодировки вы не использовали — Redis идеален для цифр, приемлем для строчек с длиной до 63 байт и не однозначен при хранении строк большего размера.
- Если в вашей системе много списков, помните, что пока они маленькие (до list-max-ziplist-entries) — вы тратите мало памяти и всё, в целом, приемлемо по производительности, но как только они начнут расти — память может резко вырасти от 2 раз и выше скачком, а сам процесс смены кодировки будет занимать весомое время (пересоздание с последовательной вставкой + удаление).
- Будьте осторожны с представлением списка (настройки list-max-*), если используете список для построения очередей или активной записи/чтением с удалением. Или иначе, если вы используете Redis для построения очередей на базе списков — выставляйте list-max-ziplist-entries = 1 (памяти всё равно потратите всего лишь чуточку больше)
- Redis никогда не отдаёт память, уже выделенную системой. Учитывайте накладные расходы на служебную информацию и стратегию изменения размера — при активной записи вы можете сильно увеличивать фрагментацию памяти из-за этой особенности и тратить до 2-х раз больше оперативной памяти, чем рассчитываете. Это особенно важно, когда вы запускаете N экземпляров Redis на одном физическим сервере.
- Если вам важно хранить разнородные по объему и скорости доступа данные на одном Redis — подумайте над тем, чтобы немного дописать код Redis и перейти на настройку list-max-* параметров на каждый ключ, вместо сервера.
- Кодировки одного и того же типа данных на master/slave могут различаться, что позволяет вам гибче подходить к требованиям — например, быстро и с большим расходом памяти на чтение, медленнее и экономнее по памяти на слейве или наоборот.
- Накладные расходы при использовании ziplist минимальны, хранить строки дешевле в ziplist чем в любой другой структуре (оверхед zlentry всего 21 байт на строку, в то время как традиционное представление redisObject + sds строка — 56 байт).
Оглавление:
- Под капотом Redis: Строки
- Под капотом Redis: Хеш таблица (часть 1)
- Под капотом Redis: Хеш таблица (часть 2) и Список
Материалы, использованные при написании статьи:
Scratch
Сегодня, кстати, вышел релиз Redis 3.0.5 для Windows
misterion
Они начиная с 3.0.3 наконец-то отказались от dlmalloc в пользу jemalloc и порт стало реально рассматривать для боевого применения. С другой стороны там какой-то ад с тем как они обошли fork для сохранения данных на диск. Разработчики порта называют его point-in-time heap snapshot. Они там здорово заморочились — я давно смотрел описание, как это сделано, в исходники глубоко не заглядывая. Самая спорная часть при использовании на бою — при сохранении они могут «выжрать» до 3-х раз больше памяти, чем нужно linux версии. При этом такое поведение считается нормальным, т.к. swap файл в windows легко может быть до 3-х раз больше, чем реальное количество оперативной памяти. Как по мне — это приемлемо только если использовать Redis под LRU cache или не использовать сохранение вовсе.